Abstract
This paper aims to address issues regarding assignment of English proficiency levels to a learner corpus compiled from a university English course in Japan. The course in question uses computer-mediated communication (CMC) for the dual purpose of providing lesson materials based on current news stories and collecting student written output to develop the learner corpus. In order to assign proficiency levels to individual texts within a learner corpus of CMC, a learner-centred method and a text-centred method of level assignation are compared and discussed with the preliminary results highlighting possible issues and the potential usage of both methods.
Keywords: Computer-mediated Communication (CMC), Writing, Proficiency,
Learner corpus, Second Language Acquisition (SLA)
要 旨 本研究では、コンピューター・メディア・コミュニケーションを用いた大学英語クラス において、学生のライティングから英語学習者コーパスを構築し、英語ライティング評価 基準を作成するための基礎研究を行った。本稿では、教材配布とコンピューター・メディア・ コミュニケーションの機能を持つクラスウェブサイトから、学習者コーパスを構築し、分 析を行った。コンピューター・メディア・コミュニケーションの特徴に留意し、学習者属 性と英語テキストを用いる評価方法を比較検討し、コンピューター・メディア・コミュニ ケーションを英語ライティングとして評価する基準設定の可能性と問題点について考察し た。
1. Introduction
For a number of years, scholars have strived to transfer insights gained from Learner Corpus Research (LCR), which is the collection and annotation of student oral or written discourse, to the study of second language acquisition (SLA) and the practice of English language teaching (ELT), and to offer suggestions for future uses of LCR. (Granger, 2001; Tono, 1999; Meunier, 2010). Several issues remain pertinent, however, for researchers interested in the overlap between LCR and both SLA and ELT. For example, there has been a call to expand the types of tasks and genres of learner data collected,
―研究論文―
Assigning Proficiency Levels to Computer-mediated Communication:
Preliminary Results from a Learner Corpus of Japanese University Students’ Writing
some of which may better reflect the real-world forms of native-produced data often found in reference corpora (Granger, 2009). Meanwhile, as L1 interference may manifest itself differently at different levels of proficiency (Jarvis & Pavlenko, 2008), the assigning of learner proficiency within an individual corpus remains an important point of contention to resolve (Carlsen, 2012).
This paper addresses the way to assign proficiency levels to individual texts within a learner corpus of computer-mediated communication (CMC) by comparing the results of a learner-centred method and a text-centred method of level assignment. The paper will highlight the preliminary findings of the research based on a learner-centred approach using individual learner profiles and a text-centred approach using a rating scale derived from a Performance Decision Tree (PDT). The paper will conclude that a text-centred approach to level assignment is a better indicator of learner capacity to write online, and suggest that the use of PDTs may carry validity in assessing corpus texts from other discourse types.
2. CMC in the language classroom
The learner corpus in this study is from a course designed for classes of non-English majors at universities in Japan. The course has used a teacher created website, News Based English, of current news articles, which students read each week and then add their reactions as comments. The decision to use news articles as class materials was based on the research conducted by Marchand (2013), which investigated lexical bundles recurring in a corpus of reader comments on the BBC’s Have Your Say website. Marchand suggests that the repetitiveness of the lexical bundles present in the texts could, with reference to Krashen’s (2004) case for “narrow reading”, provide comprehensible input that is aided by the repeated exposure to familiar lexis and grammatical structures.
The news articles are thus provided online so that the input from the articles engenders output in the form of student comments on the blog. This was considered to be pedagogically appropriate, since digital technology seems an effective way of connecting the current population of students with the recent popularity of blogging and social networking by communicating in “their own language” (Erbaggio et al., 2012). The course was also expected to facilitate engagement with the materials and increase motivation (Marchand & Rowlett, 2014), as recent studies based on tasks involving CMC have shown that blog users profess to find a great deal of enjoyment in communicating and sharing their knowledge with others with a sense of community identification and belonging (Hsu & Lin, 2008). Furthermore, pedagogical uses of CMC can be said to promote knowledge sharing by connecting learners with contexts beyond the classroom, which has been found to have an effect on both the development of individual and critical voices as well as
individual accountability in learning (Du & Wagner, 2007). Designing a course that uses comprehensible input through a computer-mediated communicative environment would thus facilitate opportunities for this kind of interaction, and push learners to produce linguistically attentive comments in dialogue with each other.
2.1 CMC corpus
Prior to investigation, a CMC-based corpus was assumed to be worth researching for two reasons. Firstly, research into a corpus of native English-speaker CMC suggests that its grammatical and lexical features differ significantly from both written and spoken registers of English, although overall its features may be considered as an intermediary register between the two (Yates, 1996; Murray, 2000; Marchand, 2013). This suggests that CMC could provide an interesting bridge between the more typical types of learner corpora, while at the same time being facilitative of processes beneficial to SLA from an interactionist perspective (Smith, 2004). Secondly, digital technology is often considered to be effective in engaging with today’s students, as blogging and social networking are modes of communicating that many language learners use in their daily lives (Alm, 2006). Therefore, a CMC learner corpus is not only readily comparable to native-speaker online communication, but also replicates real-world behaviour in the learners’ L1.
While the assumptions listed above relate to the advantages of a CMC-based learner corpus and ELT, in order to make the research more relevant for the field of SLA, the designation of proficiency levels was seen to be of critical importance, and the most appropriate way to assign proficiency levels to individual corpus texts with a CMC-based corpus was the focus of investigation. In order to fulfill this task, the results of a learner-centred method and a text-learner-centred method of level assignment (Carlsen, 2012) were used to make a comparison. The learner-centred approach uses a methodology similar to the one outlined in Pendar and Chapelle (2008), where identifiable traits from individual learner profiles such as the academic year are used to automatically assign levels of proficiency. The text-centred approach uses a rating scale derived from a Performance Decision Tree (PDT) that has been rationalized as effective in rating learner performances in other contexts (Fulcher et al., 2011). The rationales behind the methods used to assign proficiency are given together with a brief discussion on the preliminary results of this study.
2.2 The compilation of CMC corpora
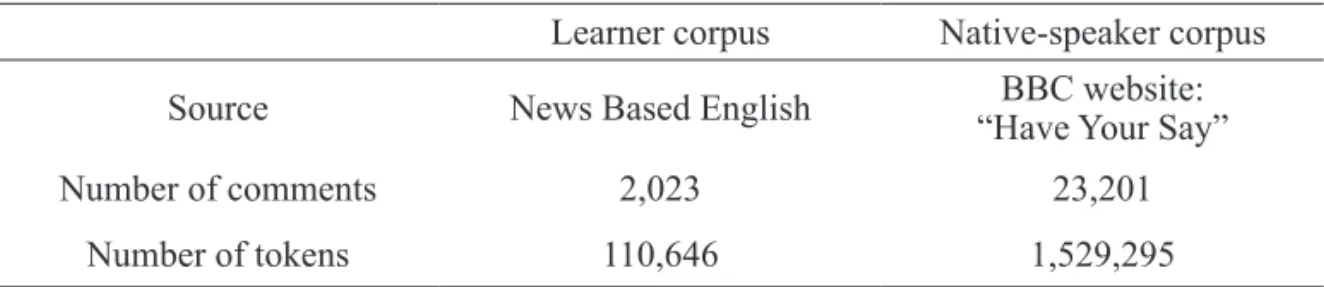
Comments posted on the News Based English website and on the BBC Have Your Say website have been collected separately to create two corpora. The corresponding sizes of the two corpora are shown in Table 1 below.
Table 1: Corpus data
Learner corpus Native-speaker corpus Source News Based English “Have Your Say”BBC website:
Number of comments 2,023 23,201
Number of tokens 110,646 1,529,295
The learner corpus is growing year by year, and had reached around 110,000 tokens (that is, the number of words) in size as of the end of the 2013 academic year. The native-speaker corpus was created from the collected data from the year 2001 (for details see Marchand, 2013), and is fixed in size at over 1.5 million tokens.
Even though the discrepancy in the time when the corpus texts were written will affect the news topics, thereby changing the lexical content, the two corpora are comparable in a general sense. In the News Based English course, the learners are asked to write their comments reacting to a news story online in their own time. The learners’ comments, although part of classwork, were not assessed during the course, and this served as a similar writing condition to Have Your Say online communication. Since news stories serving as a prompt for the corpus texts and the writing conditions are similar for both corpora, it can be assumed that the task setting and conditions of the learner corpus data form a good match with those of the reference corpus.
3. Assigning proficiency levels to CMC
Although the comparability of the learner and reference corpora have so far afforded insights into some features of Japanese L1 learners’ typical usage of English (Marchand & Akutsu, forthcoming), the findings are somewhat limited to a descriptive nature. This is mainly because all the data was treated as a whole without any consideration for the range in proficiency levels exhibited by the learners. Without a level-based classification of the learner corpus, it would be difficult to extend the results of further corpus analyses, especially in the analysis of any interlanguage development. Therefore, the key issue of assigning proficiency levels to the learner corpus will be the focus of the remainder of this paper: first, by looking at background considerations, then by explaining the method used to assign proficiency to the CMC learner corpus, before finally analysing some preliminary results to verify the usefulness of employing binary decision trees for Language Testing and Assessment (LTA).
A learner corpus, which is a compilation learner produced text for computer-based analysis, is at its most useful when there is some indication of the proficiency level of the individual corpus texts. With no precedent for measuring learner proficiency in a
CMC learner corpus available, three basic criteria for making such an assignment were determined: to follow established practice, to be practical and easy to implement, and to reference native-speaker norms.
3.1 Follow established practice
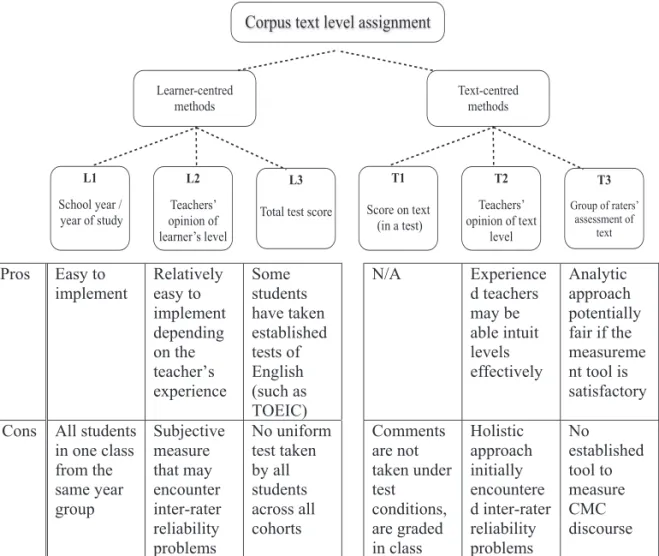
It was considered important to take account of established practice when thinking about assigning proficiency levels, as the CMC learner corpus is a relatively new addition to LCR. In a discussion on the general state of proficiency descriptions in learner corpora, Carlsen (2012) has made the distinction between learner-centred methods and text-centred methods of level assignment in LCR as in Figure 1, which shows the various methods of proficiency-level assignment. The relative advantages and disadvantages in the context of the CMC corpus have been added by the authors (Figure 1).
Of the learner-centred methods, L1 seemed to best serve our purposes. L2 was considered to be hampered by inter-rater reliability problems, while L3 would provide only an incomplete picture since not all the learners have taken an external test of English language proficiency. However, even L1 has problems as previous studies using the institutional status of each learner have traced many examples of marked inter-learner variability in each proficiency level grouping (Thewissen, 2013; Callies, 2013). As for the text-centred methods, T3 was identified as being the most suitable based on the fact that there was no data available for T1 as the comments on the blog were not taken under test conditions nor graded in class. The holistic approach of T2 was initially piloted by the teachers involved in the News Based English course, but it became immediately apparent that without any specific parameters in place, there was little consistency in the ratings. Therefore, T3 was deemed to be the most favourable method available under the current condition. Proficiency ratings derived from T3 will be compared with level designation using L1 and L3 in section 5.
Another aspect of established practice was the incorporation of the key concept of complexity, accuracy, and fluency (CAF) into the rating method. Since first introduced by Skehan (1989), CAF has become an important construct in applied linguistics for assessing learner performance and progress, or for indicating levels of proficiency (Skehan, 1998; Ellis, 2008; Housen & Kuiken, 2009). The continued support for this notion in LTA is based on the belief that L2 proficiency is componential in nature, and that the multi-dimensional aspect of CAF can sufficiently cover the complexities of such an organic entity as L2 interlanguage (Housen & Kuiken, 2009; Norris & Ortega, 2009).
3.2 Be practical and easy to implement
Rating individual corpus texts is naturally a time-consuming and labour-intensive task, so the second criterion for assigning proficiency is to make the task as practical as possible, aiming for a streamlined version of any rating tool developed that could be used by the learners themselves in self-diagnosis. The rating device should take into account that the majority of student produced texts are as short as 50 words in length on average, but numerous in number requiring an individual rater to process them one by one. Therefore, the rating tool should be simple to use and not overly taxing on the rater. As will be explained in full in section 4.1, this was achieved by using binary decision trees requiring the rater to only make a yes-no judgment at each branch.
3.3 Reference native-speaker norms
One of the advantages of the CMC learner corpus was that the learner texts could be closely compared to authentic native-speaker produced ones from the BBC corpus of
CMC. It would be beneficial, therefore, to have proficiency measurement tools based on a corpus-driven approach referencing the native-speaker corpus.
4. Performance Decision Trees (PDT)
Following the three criteria, proficiency levels were assigned by employing a text-centred approach of automated and interpretative measures of CAF. The simple binary decision trees were created based on the lexical, grammatical, structural, and functional features revealed by corpus analysis of the native-speaker reference corpus (Appendix 1). The decision to use binary decision trees as the main mechanism for assigning proficiency in the CMC corpus was based on the use of performance decision trees (Fulcher et al., 2011) in assessing learner performance in an oral task, which was modified to fulfil the needs and aims of assessing the CMC corpus.
4.1 PDT for accuracy
In the proposed scheme for assigning proficiency to the learner corpus, each performance decision tree (PDT) is sequentially connected to each other in terms of their importance and sequencing (Appendix 1). In the case of the CMC, accuracy was seen as fundamental to assigning proficiency mainly for communication purposes as comments with poor accuracy easily hinder CMC as a whole. The final outcome of the PDT for accuracy therefore determines not only the base level of proficiency for the text, but also whether there are further checks of the PDTs for fluency and complexity.
First, a comment with very poor accuracy (Example 1) is automatically rated as level 1.
Example 1: Comment with very poor accuracy News Headline Japanese Losing Ability to Write ‘Kanji’ Due to Emails Comment 1
I am the one person. I think that there are a lot of Chinese characters that have been forgotten because I do not so study the Chinese character after it enters a university. I think that urging it so that the school may work on the Chinese character authorization etc. more positively is a shortcut to the solution of this problem.
Rating Level 1 (A=1, F= n/a, C=n/a)
Secondly, a comment with low accuracy (Example 2) is rated as level 1 with an additional check for fluency, on the grounds that perhaps attempts at more fluency have adversely affected overall accuracy. However, the text has low enough accuracy to indicate that the learner has not reached the stage where complexity should be considered as a measure.
Example 2: Comment with low accuracy plus check for fluency News Headline Japanese Man Kills Two in Hope of the Death Penalty
Comment 2
When I heard this news, I was very sad. Because the crime was took place in Osaka.
And I think about the Death Penalty. I think the death penalty is abolished. The reason why I think so is people who exploit for themselves increase. So I think the death penalty should be abolished. Rating Level 1 (A=1, F=0, C= n/a)
Finally, a comment with reasonable accuracy (Example 3) may be rated as level 1 or 2, and warrants additional checks for both fluency and complexity.
Example 3: Comment with reasonable accuracy plus check for fluency and complexity News Headline Chin Jobs Head Cosmetic-surgery List in the US
Comment 3
I can understand why there are people who would like to change their body or face by plastic surgery. They believe that if they gat their ideal bodies and faces, they could get their ideal lives. But, I think that plastic surgery is not good. Our bodies and faces are given by our parents. If we change our bodies and faces by performing operations on those, they must unpleasant. So, I don’t think I would like to have any plastic surgeries.
Rating Level 3 (A=1, F=1, C=1)
The consequence of accuracy is of primary importance among the PDTs as shown in the three examples above.
4.2 PDT for fluency
The PDT for fluency was given a less prominent weighting than accuracy and complexity due to the nature of the corpus texts. The CMC learner corpus is essentially composed of written texts, with no restrictions placed on the learners regarding what or how much they should write. Fluency in writing is notoriously difficult to measure (Wolfe-Quintero et al., 1998), especially when the texts are not produced under test or timed conditions. Nevertheless, a word count measure was chosen using the reference corpus as a yardstick. In the native-speaker corpus, the average word count per comment was 65 with a standard deviation of 35. Therefore, a learner text with a word count greater than 100 (native-speaker mean + 1 SD) was automatically scored 1 for fluency. On the other hand, a text with a word count less than 30 (mean - 1 SD) was automatically scored 0 for fluency.
in length, so a second measure regarding clause length was also used to determine fluency. Average clause length was one of several measures identified by Wolfe-Quintero et al. (1998) as an indicator of fluency, but in the CMC corpora, only the longest clause was considered. This is because a clause of more than 11 tokens in length or longer would normally indicate, at the very least, a complex noun phrase in the subject position, suggesting a certain fluency in composing ideas.
4.3 PDT for complexity
The first measure of the PDT for complexity looks at whether the learners have satisfied the basic functional purpose of writing a comment. As befitting a website entitled Have Your Say, Marchand (2013) found that displaying stance towards a news story was the most prominent function of highly recurrent language (lexical bundles) found in the native-speaker corpus. Successfully expressing personal stance in the context of the learner corpus, however, requires a degree of sophistication as is exemplified in Examples 4a and 4b. Although both learners in these examples are expressing a similar stance regarding the Nobel Peace Prize, the comment in Example 4b shows an opinion beyond general platitudes and ideas that were found in the lesson materials.
Examples 4a: Evidence of personal stance News Headline EU Wins Nobel Peace Prize
Comment
I disagree with the novel peace prize of this year. Surely it is wonderful to keep being without war for 60 years. However it is a part of the EU. The EU also have bad aspects, for example economic crisis. Moreover the novel prize should be given to only individuals, because prizing organizations is difficult and can cause many critics.
Rating Level 2 (A=1, F=0, C=1)
Examples 4b: Evidence of personal stance News Headline EU Wins Nobel Peace Prize
Comment 4
Some critics say the reason why EU got the award of the 2012 Nobel Peace Prize is that it will encourage European countries to tackle with the difficulties they are facing now, such as economic crisis. There’s no denying that it is a good thing to encourage individuals or organizations to strive hard, but is there any justification for the Nobel Peace Prize to do so? I don’t think so. Nobel Peace Prize should be seperate from the political or economical matter happening in the counrty or in the world. They should focus only on whether the deed of the actor is appropriate for being commended. Using this argument, I also disagree with when President Barack Obama was awarded the Peace Prize in the matter of contributiion to the peace of Afganistan. He hasn’t really done anything
to the peace of Afganistan ( some say he made Afganistan more dangerous place) and at this time the prize was awarded just as an encouragement as well.
Rating Level 5 (A=2, F=1, C=2)
The second measure for assessing the complexity of the corpus texts was overall sentence length. To date, many studies have used T-unit length as a measure of complexity (Wolfe-Quintero et al., 1998; Ortega, 2003), but for our purposes, sentence length was preferred for two reasons. Firstly, there were relatively few instances of clausal co-ordination in both the native-speaker and learner data, which means that T-unit length actually equalled sentence length for a majority of texts in both corpora. Secondly, in keeping with the desire to keep rating manageable, it is a far simpler proposition to calculate sentence-length automatically, so it appears to be the easiest method to employ for the CMC texts. As the native-speaker norm for mean sentence length was found to be 18.6 with a standard deviation of 7, anything above 12 (greater than Mean - 1 SD) could be regarded as approaching native-speaker level of complexity.
Finally, in order to assess the sophistication of the language used on a lexical level, the raters were asked to intuitively judge such things as the richness of the vocabulary on display and the naturalness of collocations. As this is based on the raters’ individual judgement as advanced users of English, more detailed analysis of the definitions of sophisticated language and on the raters’ language proficiency are required in order to validate this method.
5. Text-centred ratings vs. learner-centred profiles
By the end of academic year 2013, 279 learners had contributed to the CMC learner corpus. At the time of writing, all the comments made by 174 of those learners had been rated using the PDTs described above, representing just over 60 % of the corpus. Three example texts from the corpus, and the judgements made along each branch of the PDTs can be seen in Appendix 2.
This section will compare and contrast the results of the ratings derived from the text-centred approach using the raters’ assessment text using the PDTs (T3 from Figure 1), institutional status such as school year (L1 in Figure 1) and profiles derived from TOEIC scores (L3 in Figure 1), the last of which was not available for all the learners who contributed to the corpus. The examples in Appendix 2 are listed in order of proficiency as if designated by L3. The comment in appendix 2.1 comes from a student who had achieved a TOEIC score of 930, but the text itself is only 32 words long, with no long clauses or evidence of complex language. The comment in appendix 2.2 shows more
evidence of complexity in the writing, but not necessarily fluency (90 words in length), and the comment in appendix 2.3 shows a combination of good fluency (162 words long) with reasonable complexity, while still maintaining good accuracy. However, following a learner-centred scheme based on TOEIC scores, the comment in appendix 2.1 would be classified as coming from a more proficient learner than those from appendices 2.2 and 2.3 in turn. If the comments were to be ordered in terms of the year of study of the student, that is, their institutional status, then the order of assumed proficiency would be 2.3 followed by 2.1 and finally 2.2. However, the text-centred rating produces a different ordering of proficiency (2.3 first, followed by 2.2 then 2.1), which on face value seems to be a fairer reflection of the learners’ true online writing ability.
5.1 PDT proficiency ratings and institutional status
The News Based English course has up to now been taught at three separate universities in Japan, and three different year groups in each case (see Table 3). This means that the learners from each university, by default their texts, would be categorised into three distinct proficiency levels if using institutional status and a learner-centred approach (L1). This is because in Japan, with its compulsory English education at secondary and, as in all three universities in this study, at tertiary level, university grade is a good proxy for the number of years learners have studied English.
A quick overview of some texts from any cohort would reveal the inadequacy of this approach in failing to account for inter-learner variation within each group. Furthermore, Table 3 reveals how inconsistent this approach is when compared with the text proficiency ratings.
Table 3: Institutional status and a learner-centred approach
No. of learners Year Department Proficiency average (SD)
University 1 72 2 Computer Science 1.50 (0.68)
University 2 68 1 Law 2.71 (1.05)
University 3 34 3 Commerce 2.86 (0.84)
While the learners from University 3, all third-year students, had the highest average proficiency score, they were closely followed by the first-year students from University 2, and both had considerably higher average ratings than the second-year students of University 1. The relatively high standard deviation in each group further confirms the extent of inter-learner variation that would be missed if the learners’ proficiency were simply defined by their year group.
5.2 PDT proficiency ratings and learner profiles
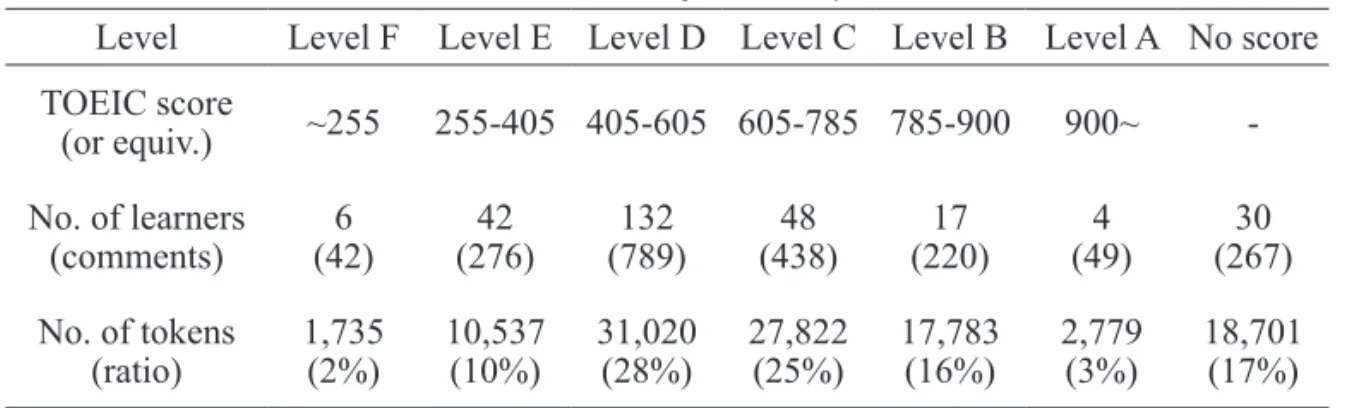
To get a more refined view than the one offered from looking at institutional status, our preferred learner-centred approach for assigning proficiency (L3) was to make use of learners’ self-declared TOEIC scores (or their equivalent) as part of their profiles. Cut points for each level were decided with reference to the data provided by online guides to the TOEIC test website (Exam English) and students were categorised into six levels of proficiency. Table 4 shows the number of students and comments in each level, with Level F the lowest and Level A the highest category.
Table 4: Levels by learner profile
Level Level F Level E Level D Level C Level B Level A No score TOEIC score (or equiv.) ~255 255-405 405-605 605-785 785-900 900~ -No. of learners (comments) (42)6 (276)42 (789)132 (438)48 (220)17 (49)4 (267)30 No. of tokens (ratio) 1,735(2%) 10,537(10%) 31,020(28%) 27,822(25%) 17,783(16%) 2,779(3%) 18,701(17%) Using this classification of learner proficiency, a box plot was created comparing learner profile levels based on TOEIC scores with ratings of the corpus texts produced by learners at each level. The result demonstrates the poor correlation that exists between them, as shown in Figure 2. If the text proficiency ratings and learner profile levels correlated well, we would expect to see the box plots to broadly follow the dotted parallel lines up the chart, with the lowest average rated texts being produced by learners of Level F, and the highest ratings coming from texts written by Level A learners.
Figure 2: Learner profile levels and text ratings
As in Figure 3, there was a marked tendency for the profile levels to exaggerate proficiency. The pie graph shows that over 70 per cent of the texts were rated below the learner profile levels, while only 20 per cent ended up matching the learner-centred marker of proficiency.
Figure 3: Tendency for learner profile levels against proficiency
It becomes clear that proficiency levels obtained through learner profile do not reliably indicate the proficiency rating of the CMC texts. This could be an argument for a
weakness in assigning proficiency by the text-centred method proposed in this paper. However, the discrepancy between the two methods could be better explained by the fallacies of this learner-centred approach. Most of the students reported that they had taken the paper-based ITP variant of the TOEIC test, which has a pronounced focus on testing the receptive skills of listening and reading. The competencies required to do well on this format of the TOEIC test do not really match the communicative demands of CMC discourse, so it may not be surprising to note that being proficient in the former does not necessarily imply proficiency in the latter.
6. Conclusion
This paper has explained the development of a learner corpus based on a relatively new genre type in LCR, and the method used to assign proficiency levels to that corpus. The use of CMC in a language teaching context was outlined, followed by a discussion on the subsequent construction of the CMC learner corpus and its favourable comparability to a native-speaker corpus from a BBC news website forum.
For this preliminary study of assigning proficiency levels to the learner corpus, a text-centred method was chosen utilizing the binary decision trees of CAF to describe proficiency levels. As the preliminary results demonstrate, there are some discrepancies in the relationship between proficiency levels derived from learner profiles and those coming from text ratings, with the prima facie evidence suggesting that the text-centred approach offers a much truer reflection of learner proficiency at writing online. In fact we would argue that comparing the text-centred approach with learner-centred approaches exposes the latter as rather inadequate at capturing the inter-learner variation in proficiency.
To develop this line of enquiry, the use of PDTs as a measurement tool itself requires further testing by more raters in order to judge its reliability and validity as a construct. Especially in the branches of the CAF trees, it may be necessary to modify or adjust the questions in order to properly assign proficiency levels based on the characteristics of CMC. Although the procedure outlined here is specific to a learner corpus of CMC in a particular context, it would be insightful to see whether a similar approach could be adapted to fit other learner corpora and other genres of communication. For example, the weighting of each PDT could be adjusted to better fit the nature of discourse under analysis so that fluency would probably become the primary focus of a spoken corpus. In this way and with a more refined version of the text-centred rating tool in place, not only could CMC corpora potentially make greater contribution to an in-depth analysis of interlanguage development, but also some further insights into the design and compilation of corpus data can be achieved.
Notes/付記
This research received a grant from, and was supported by, the Institute for Language Education Research and Development at J. F. Oberlin University.
本研究は、桜美林大学言語研究所より研究運営助成を受けたものである。
For this research paper, T. Marchand was responsible for data collection and preliminary analysis, while S. Akutsu was responsible for secondary analysis. All sections were written in collaboration.
References
Alm, A. (2006). CALL for autonomy, competence and relatedness: Motivating language learning environments in Web 2.0. The JALT CALL Journal 2(3): 29-38.
BBC. (2001-2014). Have Your Say [online]. Available at http://www.bbc.co.uk/news/have_ your_say/ [Accessed 11 January 2015].
Callies, M. (2013). Advancing the research agenda of Interlanguage Pragmatics: The role of learner corpora. In J. Romero-Trillo (Ed.), Yearbook of corpus linguistics and pragmatics 2013: New domains and methodologies, New York: Springerl, 9-36. Carlsen, C. (2012). Proficiency level – a fuzzy variable in computer learner corpora.
Applied Linguistics 33(2), 161-183.
Du, H. S., & Wagner, C. (2007). Learning with weblogs: Enhancing cognitive and social knowledge construction. IEEE Transactions of Professional Communication, 50(1), 1-16.
Ellis, R. (2008). The Study of Second Language Acquisition. 2nd ed. Oxford: Oxford University Press.
Erbaggio, P., Gopalakrishnan, S., Hobbs, S., & Liu, H. (2010). Enhancing student engagement through online authentic materials. International Association for Language Learning Technology, 42(2), 27-51.
Exam English. (2014). [online] Available at http://www.examenglish.com/TOEIC/index. php [Accessed 10 January 2015].
Fulcher, G., Davidson, F., & Kemp, J. (2011). Effective rating scale development for speaking tests: Performance decision trees. Language Testing 28(1), 5-29.
Granger, S. (2008). Learner corpora in foreign language education. In N. V. Deusen-Scholl & N. H. Hornberger (Eds.), Encyclopedia of language and education (Vol. 4, pp. 337-351). Berlin: Springer.
Granger, S. (2009). The contribution of learner corpora to second language acquisition and foreign language teaching: a critical evaluation. In K. Aijmer (Ed.), Corpora and language teaching. Amsterdam & Philadelphia: John Benjamins, 13-32.
Petch-Tyson, S. (Eds.) Computer Learner Corpora, Second Language Acquisition and Foreign Language Teaching. Amsterdam & Philadelphia: Benjamins, 3-33. Housen, A., & Kuiken, F. (2009). Complexity, accuracy and fluency in second language
acquisition. Applied Linguistics 30(4), 461-473.
Hsu, C., & Lin, J. C. (2008). Acceptance of blog usage: The roles of technology acceptance, social influence and knowledge sharing motivation. Information & Management 45, 65-74.
Jarvis, S., & Pavlenko, A. (2008). Crosslinguistic influence in language and cognition. New York: Routledge.
Krashen, S. 2004. The case for narrow reading. Language Magazine 3(5): 17-19.
Marchand, T. (2013). Speech in written form? A corpus analysis of computer-mediated communication. Linguistic Research, 30(2), 217-242.
Marchand, T., & Akutsu, S. (forthcoming). The compilation and use of a CMC learner corpus for Japanese university students.
Marchand, T., & Rowlett, B. (2014). Course design in the digital age: learning through interaction with news-based materials. Language Education in Asia 4(3).
Meunier, F. (2010). Learner corpora and English language teaching: Checkup time. Anglistik: International Journal of English Studies, 21(1), 209-220.
Murray, D. (2000). Protean communication: The language of computer-mediated communication. TESOL Quarterly 34(3): 397-421.
Norris, J., & Ortega, L. (2009). Towards an organic approach to investigating CAF in instructed SLA: The case of complexity. Applied Linguistics, 30(4), 510-532. Ortega, L. (2003). Syntactic complexity measures and their relationship to L2 proficiency:
A research synthesis of college-level L2 writing. Applied Linguistics, 24(3), 492– 518.
Pendar, N. & Chapelle, C. (2008). Investigating the promise of learner corpora: Methodological issues. CALICO Journal 25: 189-206.
Skehan, P. (1989). Individual differences in second language learning. London: Edward Arnold.
Skehan, P. (1998). A cognitive approach to language learning. Oxford: Oxford University Press.
Skehan, P. (2009). Modelling second language performance: Integrating complexity, accuracy, fluency, and lexis. Applied Linguistics, 30(4), 555-578.
Smith, B. (2004) Computer-mediated negotiated interaction and lexical acquisition. Studies in Second Language Acquisition 26(3): 365-398.
Thewissen, J. (2013). Capturing L2 accuracy developmental patterns: Insights from an error-tagged EFL learner corpus. The Modern Language Journal, 97(Suppl. 1),
77-101.
Tono, Y. (1999). Using Learner Corpora in ELT and SLA Research. Paper presented at the Symposiumon the Roles of Corpora in Language Teaching and Language Engineering of the 12th World Congress of Applied Linguistics (AILA), Tokyo. Wolfe-Quintero, K., Inagaki, S., & Kim, H. (1998). Second language development in
writing: Measures of fluency, accuracy & complexity. Honolulu: University of Hawaii Press.
Yates, S. (1996). Oral and written linguistic aspects of computer conferencing: A corpus-based study. In Herring, S. (Ed). Computer-mediated communication: Linguistic, social, and cross cultural perspectives (29-46). Amsterdam & Philadelphia: John Benjamins.