Sequential‑multi‑agent強化学習による非明示的な 下位概念の習得
著者 小室 光広
出版者 法政大学大学院情報科学研究科
雑誌名 法政大学大学院紀要. 情報科学研究科編
巻 15
ページ 1‑6
発行年 2020‑03‑24
URL http://doi.org/10.15002/00022724
Supervisor: Prof. Yuji Sato
Sequential-multi-agent 強化学習による非明示的な下位概念の習得
Implicit Low-level Concept Acquisition Using Sequential-multi-agent Reinforcement Learning
小室 光広 Mitsuhiro Komuro
法政大学大学院情報科学研究科 E-mail: [email protected]
Abstract
This paper proposes a new learning method using multi-agents in reinforcement learning for dynamic environments. Previous method shows the model accuracy can be improved by using deep neural networks at learning the reward value Q of reinforcement learning.
On the other hand, it takes several million steps before learning convergence, and it is not easy to adjust to appropriate hyperparameters. To remedy this problem, we propose a Sequential-multi-agent reinforcement learning model consisting of multiple Internal Agents and Core Agent to solve the task. Internal agents have independent parameter settings and durable values to assist the learning of the Core Agent. For the evaluation data, we have used a Pong game from the Atari video games that is used in the reinforcement learning algorithm evaluation. In the experiment, we conduct comparative evaluation the game score and the number of game frames for the proposed method and Deep-Q Network (DQN) Single Agent. The experimental results show the potential of the proposed method can learn a subordinate concept effective for game scoring without giving an explicit teacher signal.
1. はじめに
昨今,盛んに研究されている機械学習技術は大量の入 力データに対して期待するラベル付けされたデータを教 師信号として与え学習させる教師付き学習,少量のラベ ル付きデータに基づきラベル無しデータを用いて自己学 習する半教師付き学習,ラベル無しデータからデータ間 の相関により学習を行う教師なし学習の 3つに分類され る.また,教師無し学習には環境とやり取りをしながら 学習を行う強化学習やデータ間の相関関係から分類する クラスタリングが存在する.一般に強化学習を除く他の 機械学習手法では事前に大量のデータを用意する必要が あ り , 特 に 教 師 付 き 学 習 で は デ ー タ へ の ラ ベ ル 付 け (annotation)が大きな負担となっている.一方,教師なし 学習の一つである強化学習は事前にデータを用意するこ となく,解くべきタスク環境と解くための Agent を定義 することで学習を行うためデータの用意やラベル付けと
いった負担はほとんどない.加えて,強化学習は Google DeepMindのAlphaGo [1]やAlphaZero [2]などにおける学 習部分で使用されその精度の高さが報告されている.精 度 良 く 学 習 す る た め の ア ル ゴ リ ズ ム と し て Deep-Q Network (DQN) [3]が提案されている.しかしながら,一 般に強化学習はその学習や収束に時間(Execution timeの意 ではない)がかかることが知られている.
そこで本研究では学習収束性能向上を目的とし,マル チエージェントによる実現手法を検討する.本稿ではタ スクを解くCore agentとCore agentの学習を補助する異な るパラメータ設定がされた 複数の耐久値付き Internal Agentを用いたSequential-multi-agent強化学習モデルを提 案する.異なるパラメータ設定の Agentを複数用いるこ とで,Core agentの環境に対するAction選択の方針に多様 性をもたせることができ,得られた多様な知識を利用す ることで学習収束性が向上すると考えるためである.
2. 先行研究とその問題点
先行研究 [3]では,ある状態においてAgentが取った行 動の評価値であるQ値を学習するQ学習と呼ばれる強化 学 習 手法 に おい て, 多 層から 構 成さ れ る Deep-Neural
Networksを用いて学習することで精度向上を試みる手法
を提案している.この手法では,各ステップで得られた 環境の状態,Agent の行動,報酬を Experience として Replay Memoryに保存し,Replay Memoryからランダムに サ ン プ ル さ れ た Experience を DQN に 学 習 さ せ る Experience ReplayやAgentが取るべき最適なActionの選 択のために𝜀-greedy法が用いられている.
また,Q学習における過大評価を防ぐための先行研究 [4]ではDouble Deep-Q Networks (DDQN)と呼ばれるモデル が提案されている.環境に対するAgentのAction選択と
Actionに対する評価を別のDQNが行うことで過大評価を
防いでおり,実験に用いたゲームタスクにおいてDQNと 比較しスコアが向上したことを示している.
一方,これらの手法は学習収束までに 200 万ステップ 程度かかっており,より複雑なタスクでは更にステップ 数を要すると考えられる.また,Single-agent であること
から,Agent の最適なハイパーパラメータはタスク依存
でありタスクが変わった際のハイパーパラメータ調整な どを試行錯誤で行う必要があり困難となる.
3. Sequential-multi-agent強化学習 3.1モデルアーキテクチャ
本研究では強化学習における学習収束性向上を目的と し,タスク環境とAgentをCore EnvironmentとCore Agent,
Core Agentの学習を補助する𝑛個のInternal AgentとInternal Environmentで構成する Sequential-multi-agentモデルを提 案 す る . 先 行 研 究[3][4]は ,Q 値 推 定 を Deep-Neural
Network により行う DQN,DDQN を内部に持つ Single
Agent で構成した強化学習モデルであった.本提案モデ
ルではDQN,DDQNをAgentの内部ニューラルネットワ
ークとして使用するが,Single AgentではなくMulti Agent とすることで,多様なタスク知識獲得による学習収束性 向上を狙う.
本モデルでは,タスク知識をより多様に,より早期に 習得することで学習収束性の向上を狙う.Internal Agent が0番目から𝑛番目まで学習し,Best Internal Agentを選択 する.Core Agentにおけるタスク知識を多様とするため Best Internal Agentに選ばれたInternal Agentが得たAction,
State,Reward を組とするタスク知識を Core Agent の Replay MemoryにPushする.加えて各Internal Agentはハ イパーパラメータで定義された耐久値を持っている.一 般に機械学習や強化学習におけるハイパーパラメータ設 定は経験や試行錯誤に基づき最適なパラメータを設定す る.一方,本モデルでは異なるハイパーパラメータ設定 を持つ複数の Internal Agentが存在するため,Core Agent の学習に影響を与えないよう耐久値を設定する.耐久値 はInternal AgentからBest Internal Agentを選択する際使用 し,選択されなければそのInternal Agent減少する.また,
Best Internal Agentに選択されたInternal Agentの耐久値は
Internal Agentの総数が1になるまでの間,選択されたタ
イミングで Hyperparameterによって指定した値だけ回復 する.Best Internal Agentに選ばれる回数が少なければ少 ないほどそのInternal Agentが持つハイパーパラメータ設 定は有用では無い と考え, 耐久値が 0 以下になった
Internal Agent は学習途中であっても次ステップ以降の
Core Agent における学習に影響を与えないよう破棄する.
この考え方は遺伝的アルゴリズム(GA)のエリート保存戦 略に着想を得ている.
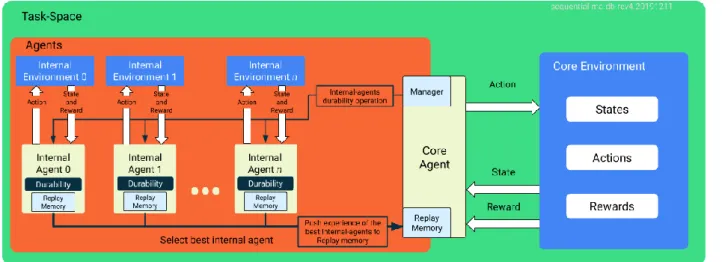
3.2モデルの学習とInternal Agentの選択方法 図 1に提案する耐久値付きマルチエージェントモデル を示す.図 1 においてメインの学習ループは Internal Agent の学習,Best Internal Agentを選択,Core Agent の Replay Memoryにタスク知識を Push,Core Agent 学習の 順で行われる.このアルゴリズムフローをここではシー ケンシャルと呼ぶこととする.学習タスクは Open-AI Gymに含まれるATARIのPong[5]の実装バリエーション であるPongNoFrameSkip-v4を用いる.Pongは2人のプレ イヤーが上下に動く棒を使用しボールを打ち合うゲーム である.PongNoFrameSkip-v4 は Open AI Gymにおける Pong実装のうち,FrameのSkipが生じない環境である.
学習ループ中のBest Internal Agent選択手法には0ステッ プ目を除き GA においてよく用いられるルーレット選択 を適用する.GA におけるルーレット選択は個体の評価 値に基づきルーレット幅を決定する.決定したルーレッ ト幅でルーレットテーブルを作成しランダムに選択する.
この際,ルーレット幅が大きければ大きいほどその個体 は選択されやすくなる.本モデルではBest Internal Agent に選択された回数に基づきルーレットテーブルを作成す る.Best Internal Agent となる回数が多ければ多いほど Best Internal Agentとして選択されやすくなる.0ステップ 目ではBest Internal Agentに選ばれたInternal Agentは存在 しないため全Internal Agentからランダムに選択する.ま たルーレット選択はルーレット幅に基づくランダム選択 アルゴリズムであるため,ルーレット幅が小さい場合で あ っ て も 選 択 す る 可 能 性 が あ る . し た が っ て ,Best Internal Agent ではない Internal Agent の Action,State,
Rewardの情報をCore Agentに取り入れる事ができ,Core
AgentがReplay Memoryに持つ知識に多様性を持たせるこ
とが可能となる.実装は学習ループを自己定義可能な機 械学習ライブラリであるPyTorchを用いて行う.
図 1 提案するSequential-multi-agentモデル
4. 評価実験 4.1 実験手法
実験では,提案するモデルにおけるInternal Agentで使 用するニューラルネットワークを,複数の層から構成さ れる畳み込みニューラルネットワーク(CNN)構造を持つ DQNの他にDDQN[4]を用いATARIのPongを解くべきタ スクとして行う.本実験では,Sequential-multi-agentにお けるBest Internal Agent選択手法の変更や異なる学習率を 与えることで Core Agentに対しどのような影響を与える か比較する.本比較実験は合わせて 7つ行う.実験 1は DQN,DDQNを内部に持つInternal Agentをそれぞれ2つ ずつ用意し,それぞれの学習率を1𝑒 − 3と1𝑒 − 4,Core Agent の学習率を 1𝑒 − 4 とする.実験 1における Core
Agent のニューラルネットワークは先行研究[3]と同一の
ネットワーク構成とするため,バッチ正規化処理層が含 まれていない DQN を用いる.実験 2は実験 1の Core
Agentのみを用いて学習する.実験3はルーレット選択に
おけるルーレットテーブルをInternal Agentが各Stepで獲 得したトータル報酬値に基づいて作成し,実験 1と同様 の条件で学習する.実験4はCore Agentのニューラルネ ットワークをDDQNに変更し,実験1と同様の条件で学 習する.実験5は実験4のCore Agentのみを用いる.実 験6は実験1と同様の条件だが,全Agentの学習率が1𝑒 −
4として行う.実験 7は実験 6 と同様の条件とし,Core
Agentのニューラルネットワークを DDQNに変更し学習
する.Core AgentとInternal AgentへのRewardの付与は
PongにおいてAgentが得点を取れば1.0,得点を取られれ
ば-1.0,得点に関係しない動作中は0.0として学習ループ を実行する.表 1に実験環境を,表2に実験におけるデ フォルトハイパーパラメータを示す.なお,Single agent は表1に示す実験環境で再現した結果を用いる.
4.2. 実験結果
表3に実験1から実験7における400 Episodes実行した ときのGame frame数とRewardを示す.また,図2,図3 に提案モデルと先行研究[3]である Single Agentモデル,
トータル報酬値に基づくルーレットテーブルによるルー レット選択法を適応した提案モデルの実験結果を示す.
加えて,図4,図5にDDQNをCore Agentのニューラル ネットワークとする Sequential-multi-agent とその Single
Agent モデル実験結果を示す.図 6,図 7に全 Internal
Agent及びCore Agentの学習率を1𝑒 − 4とするSequential- multi-agentと,学習率を1𝑒 − 4とし,DDQNをCore Agent のニューラルネットワークとしたときの実験結果を示す.
最後に図 8 に Sequential-multi-agent モデルにおける各 Internal Agentの耐久値遷移を示す.図2,図4,図6は各 EpisodeにおけるGame frame数の関係である.図3,図5,
図7は各条件下においてCore AgentがEpisode毎で獲得し たRewardの推移を示している.図8はSequential-multi- agentモデルにおいてStep毎のInternal Agent耐久値遷移 を示している.
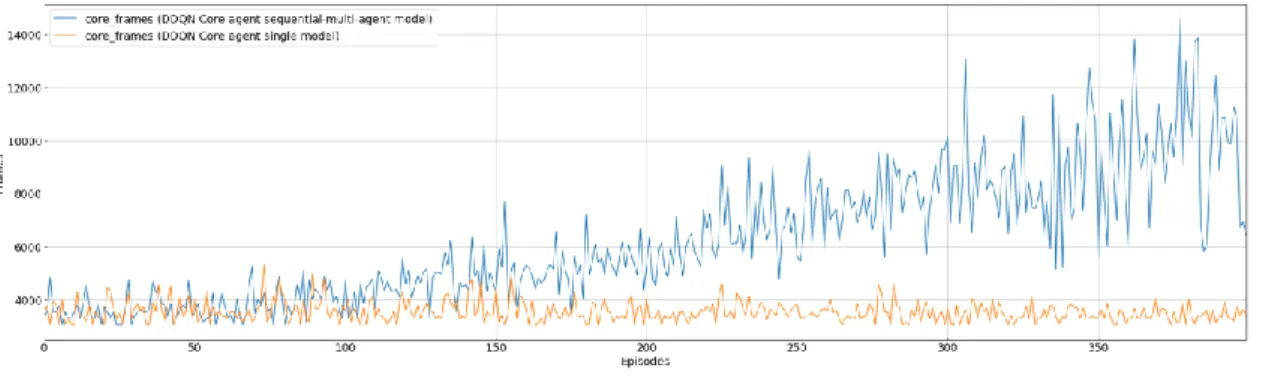
まずGame FramesとEpisodesの関係について,図2の Sequential-multi-agentモデルは,序盤Frame数が3500か
ら 4000 付近で推移しており,Episodeが進むに連れ振動 しつつ100 Episode付近よりSingle Agentを除き上昇して いることを示している.Single Agent モデルは指定した 400 Episode中Sequential-multi-agentモデルと同様のFrame 数上昇は見られなかった.図4ではCore Agentのニュー ラ ル ネ ッ ト ワ ー ク を DDQN に 変 更 し た 場 合 で も , Sequential-multi-agentモデルが図2と同様に振動しつつ上 昇し,Single Agentモデルは3500 Frames付近で推移して いることを示している.図 7はDDQN,バッチ正規化処 理層を含まないDQNをCore Agentのニューラルネットワ ークとする各モデルにおいても 70 Episode付近から上昇 していることが示されている.
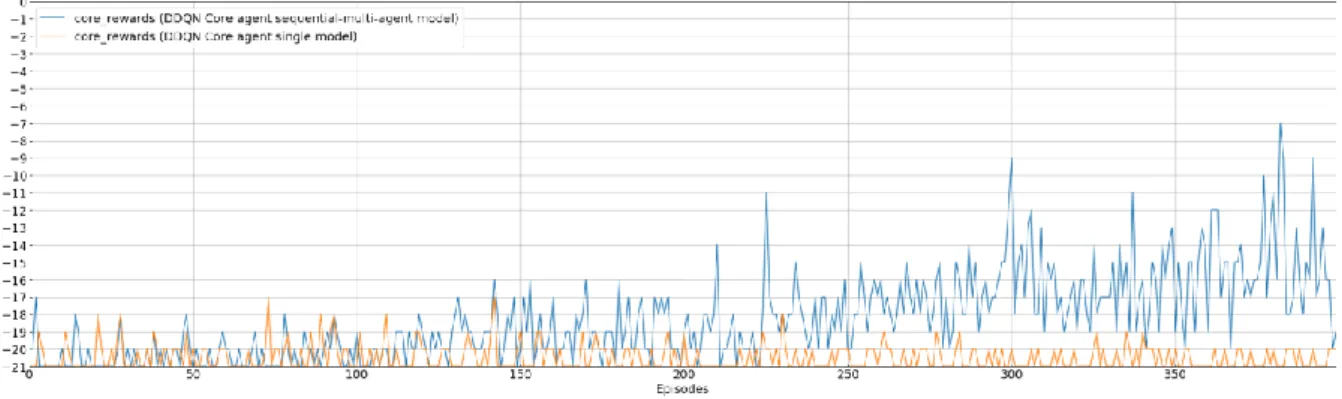
次に.RewardとEpisodesの関係についてである.図3 は全条件でReward値が負値であるため,ベンチマークゲ ームの勝負には負けているが,Single Agentを除き,後半
のEpisodeに近づくに連れ振動しながら上昇していること
が示されている.一方,Single agentの結果は-21から-18 で推移している.図 5は図 3と同様に Sequential-multi-
agent では獲得できたRewardが振動しつつ上昇している
ことを示している.Single Agentについても図3と同様に 実験を通して-17より上昇することは無かったことが示さ れている.図7ではDDQNとバッチ非正規化処理層を含
まないDQN,いずれのニューラルネットワークであって
も,獲得できるReward値の下限が上昇していることが示 されている.また,図 7に示されている 2つの実験では 他の実験と比較し,獲得できるRewardの振動幅が大きい ことも示されている.
最後に図 8は Sequential-multi-agentモデルにおける各 Internal Agentの耐久値のうち3つが260000 Steps付近ま でに0となることを示している.なお,300000 Steps以降 は DQN0 以外存在せず ,変 化しないた め,グラ フは 300000 Stepsまでを示している.
5. 考察
図2,図 3より,Pongゲームタスクにおける勝負には 先行研究モデル,提案モデルいずれも負けているが, 先 行研究のモデルと比較して学習後半における各Episodeの
Game Frame 数が上昇してい ることがわかる.また,
Internal AgentがEpisode毎に獲得した報酬値の合計に基づ き作成したルーレットテーブルによるルーレット選択を 用いる提案モデルでも上昇が見られた.本実験において,
学習中の Frame 数が後半にかけて増加していることは学
習後半のベンチマークゲームにおいて継続するラリー数 が増加していることを示している.提案した Sequential-
multi-agent モデルでは与えられたタスクに関する Action
に対して(本実験では Pongについて得点を取ったか取ら れたか)のみRewardを付与しているが,AgentのAction選 択指針に関係するReward付与とは直接関与しない部分に おいて明示的な教師信号与えず「勝負に勝つためラリー を続ける」という下位概念を学習していることを示して いる.これは重要な結果であり,Sequential-multi-agentに おける複数のInternal Agentの取ったAction, State, Reward を学習初期にCore AgentのReplay Memoryに追加するこ とでCore Agentの環境Stateに対するActionのとり方に関
する知識が増加し,環境Stateに応じた適切な選択できて い る た め で あ る と 考 え ら れ る . 加 え て ,Reward は Sequential-multi-agentにおいて振動しながら上昇している ことから,Core Agent 自身が前述の獲得した下位概念を 用いて,タスクに有用な Action選択を適切に学習してい るためであると考える.
図4,図5よりCore Agentにおけるニューラルネット
ワークを DDQN に変更した場合でも,提案手法である Sequential-multi-agentではGame Framesの増加が確認でき た.図2と同様に実験4でも複数のInternal Agentからタ スク知識が提供されることで,下位概念を非明示的に獲 得していると考える.また,Single Agentの獲得 Reward 幅は図 2示した先行研究[3]と比較し拡大している箇所が 見られる.これは先行研究で提案されているバッチ非正 規化処理層を含まない DQNから先行研究 [4]で提案され ているDDQNへニューラルネットワークを変更したこと で生じたと考える.
図6,図7より,全Agentの学習率を一律1𝑒 − 4にした
場合,及びその Core Agent ニューラルネットワークを DDQNにした場合でも振動しつつFrame数の増加が確認 された.これも図2での実験と同様にCore Agentが持つ タスク知識が複数のInternal Agentによる追加で増加した ためであると考える.また,図 2の実験における学習終 盤と比較すると,Frame 数の上限と下限が低いことが確 認された.これは,全 Agentの学習率を一律にしたため,
異なるパラメータがInternal Agentのニューラルネットワ ークのみとなり,Agentの種類が減少したためであると 考えられる.一方で,本実験結果は図2と比較し,Frame 数増加のEpisodeが100 Episode以前である事がわかる.
これは本実験のベンチマークゲームが動的問題であり,
各Internal Environmentにおける環境Stateが異なることか ら,同一パラメータを持つ複数のInternal Agentによりパ ラメータ依存のタスク知識を多く獲得できたためと考え られる.よって,実験2と実験6を比較したときi) 多様 なパラメータを持つ複数のInternal Agentでは学習終盤で の最終的な Frame 数の下限は高いが,学習序盤の増加タ イミングは遅く,ii) 同一パラメータを持つ複数のInternal
Agentでは学習終盤のFrame数の下限は低いが,学習序盤
の増加タイミングは早くなるというトレードオフ関係に あると推察される.
図8よりSequential-multi-agentでは学習序盤から中盤の 間で4つのInternal Agentのうち学習率1𝑒 − 4に設定した DQNを持つInternal Agent以外耐久値が0となり破棄され ていた.学習序盤から中盤の間で破棄されていたことか ら設定した耐久値が本タスクの学習にそぐわないハイパ ーパラメータ設定を持つInternal Agentを適切に破棄し,
学習終盤において Core Agentに影響を与えることは無か ったと考えられる.本実験では多様なパラメータを持つ
複数のInternal Agentを用いて学習を行い,耐久値によっ
てInternal Agentを適切に制御できていると考えられるこ
とから,タスク依存である適切な Hyperparameter探索に も効果があると考えられる.特に,タスクに対して実装 者が何らかのタスク固有知識を持っており,指向的に
Hyperparameter を設定したい場合有用であると考える.
これは,いくつかの Hyperparameter 候補を本モデルの
Internal Agent として設定し,学習中に耐久値及びルーレ
ット選択により適切に処理されると考えるからである.
本実験結果より,タスクを変更した場合でも学習序盤の Internal AgentにおけるAction,State,Reward等のタスク 知識をうまく活用することで,本実験と同様の結果が得 られると考える.
以上の 実験 より, 多様 なパ ラメー タを 持つ Internal Agentのタスク知識がCore AgentのReplay Memoryへ有効 に作用したと考えられることからInternal Agentを増やす ことでより多くのタスク知識を得られるのではないかと 考える.また,前述のトレードオフ関係を念頭に,同一 パラメータのInternal Agentを一定セットずつ用意し,全 体として多様なパラメータ設定とすることで Step数の増 加を速めつつ Frame 数の下限を上昇させることが可能と 考える.
6. まとめ
本稿では,強化学習における学習収束性向上を目的と し,タスクを解く Core Agentと異なるハイパーパラメー タ設定を持つ複数のInternal Agentで構成するSequential-
multi-agent モデルを提案した.実験の結果,学習収束性
の向上に関して明らかな効果は見られなかったが,本研 究ではラリーを続けるというPongタスクを解くために必 要な下位概念を明示的な教師信号なく学習できる可能性 を示した.今後の課題として,Internal Agent を増やし,
より多様なハイパーパラメータ設定とすることで学習収 束性が向上,下位概念の学習を早める可能性を調査する ことが必要である.
文 献
[1] David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwie-ser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Made-leine Leach, Koray Kavukcuoglu, Thore Graepel & Demis Hassabis, “Mastering the game of Go with deep neural net-works and tree search”, Nature vol.529, pp.484–489, 2016.
[2] David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, Demis Hassabis, “A general rein-forcement learning algorithm that masters chess, shogi, and Go through self-play”, Science, vol.362, issue 6419, 2018.
[3] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antono- glou, D. Wierstra, and M. Riedmiller. “Playing Atari with deep reinforcement learning”. NIPS ’13 Workshop on Deep Learning, 2013.
[4] Hado van Hasselt, Arthur Guez, and David Silver. “Deep Reinforcement Learning with Double Q-Learning”, AAAI.
Vol. 16. 2016.
図2 Sequential-multi-agentとSingle Agent,トータル報酬値に基づくルーレットテーブル条件下での Game frames と Episodes の関係
図3 Sequential-multi-agentとSingle Agent,トータル報酬値に基づくルーレットテーブル条件下での Rewards と Episodes の関係
図4 DDQNをCore Agentのニューラルネットワークとする
Sequential-multi-agentとSingle AgentモデルにおけるGame FramesとEpisodesの関係 表 3 400 Episode実行した時のGame frame数とReward値
表 2 デフォルトハイパーパラメータ
Batch size 32
Initial agent durability 1000 The number of episodes 400
Initial replay memory 10000
表1 実験環境OS Ubuntu 18.04.3
CPU Intel(R) Core(TM) i9-9960X CPU @ 3.10GHz
GPU GeForce RTX 2080 Ti
Memory 64GB
図5 DDQNをCore Agentのニューラルネットワークとする
Sequential-multi-agentとSingle AgentモデルにおけるRewardsとEpisodesの関係
図6 全Agentの学習率を𝟏𝒆 − 𝟒としたときのSequential-multi-agentと Core Agentの ニューラルネットワークをDDQNにしたときのGame Frames と Episodes 関係
図7 全Agentの学習率を𝟏𝒆 − 𝟒としたときのSequential-multi-agentと Core Agentの ニューラルネットワークをDDQNにしたときのRewards と Episodes 関係
図8 Sequential-multi-agentにおける各Internal Agent耐久値の遷移