統計的学習に基づく推薦方式に関する研究
A Study on the Recommendation Method based on Statistical Learning
2012 年 7 月
早稲田大学大学院 基幹理工学研究科 数学応用数理専攻 情報理論研究
桑田 修平
第1章 序論 1
1.1 はじめに . . . . 1
1.2 本研究の目的 . . . . 2
1.3 本論文の構成 . . . . 3
第2章 準備 4 2.1 履歴データの定義 . . . . 4
2.1.1 時系列形式での表現 . . . . 4
2.1.2 行列形式での表現 . . . . 5
2.2 問題設定 . . . . 6
第3章 従来研究 7 3.1 従来の推薦手法 . . . . 7
3.2 最近傍法に基づくアプローチ . . . . 8
3.2.1 k近傍法(kNNs) . . . . 8
3.2.2 Unified method with Similarity Fusion(SF) . . . . 8
3.3 確率モデルに基づくアプローチ . . . . 9
3.3.1 多項分布モデル(MULTI) . . . . 9
3.3.2 混合多項分布モデル(MIXMULTI) . . . . 10
3.3.3 Aspect Model(AM) . . . . 10
3.3.4 User Rating Profile Model(URP) . . . . 11
第4章 本研究の概要 12 4.1 従来の推薦方式における視点 . . . . 12
4.2 本研究における視点 . . . . 12 i
4.3 提案する推薦方式の全体像 . . . . 13
4.3.1 時間的な視点と空間的な視点の両方を考慮した推薦手法 . . . 13
4.3.2 空間的な視点を考慮した推薦手法1 . . . . 15
4.3.3 空間的な視点を考慮した推薦手法2 . . . . 16
4.4 本研究の意義 . . . . 17
第5章 ベイズ決定理論に基づくユニバーサルマルコフ決定過程モデル 19 5.1 はじめに . . . . 19
5.2 問題設定 . . . . 21
5.3 準備:マルコフ決定過程モデル . . . . 22
5.4 従来手法 . . . . 23
5.5 提案手法 . . . . 25
5.5.1 マルコフ決定過程モデルの一般化 . . . . 26
5.5.2 履歴データを用いた最適な推薦ルールの学習 . . . . 27
5.5.3 履歴データの蓄積について . . . . 30
5.6 評価実験 . . . . 32
5.6.1 実験手順 . . . . 33
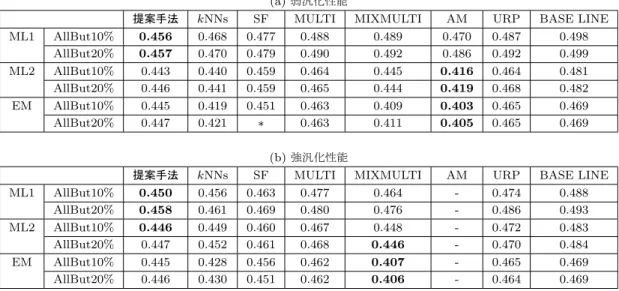
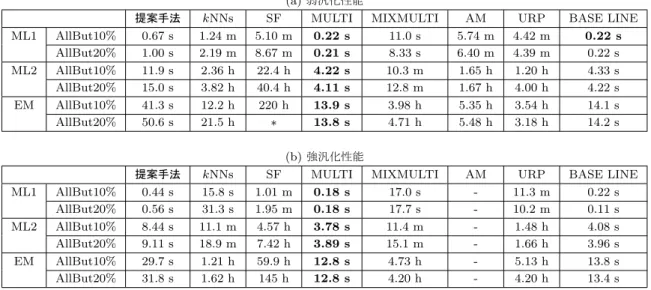
5.6.2 結果と考察 . . . . 34
5.7 本章のまとめ . . . . 38
第6章 一括予測型協調フィルタリング 39 6.1 はじめに . . . . 39
6.2 問題設定 . . . . 41
6.2.1 データの定義 . . . . 41
6.2.2 目的 . . . . 41
6.2.3 評価尺度 . . . . 42
6.3 提案手法 . . . . 44
6.3.1 ランダムな欠損 . . . . 44
6.3.2 周辺評点分布に基づく評点予測 . . . . 44
6.3.3 予測アルゴリズム . . . . 46
ii
6.4.2 従来手法 . . . . 50
6.4.3 結果と考察 . . . . 51
6.5 本章のまとめ . . . . 55
第7章 ディリクレ過程混合モデルに基づく共クラスタリング 56 7.1 はじめに . . . . 56
7.2 問題設定 . . . . 58
7.3 従来研究 . . . . 59
7.3.1 非負行列因子分解に基づく手法 . . . . 59
7.3.2 グラフの分割に基づく手法 . . . . 60
7.3.3 確率モデルに基づく手法 . . . . 60
7.3.4 従来手法の共通点 . . . . 61
7.4 無限関係モデル . . . . 61
7.4.1 購入履歴の生成に対するモデル . . . . 62
7.4.2 クラス数の生成に対するモデル . . . . 62
7.4.3 無限関係モデルにおける同時分布 . . . . 63
7.4.4 学習アルゴリズム . . . . 64
7.4.5 無限関係モデルの問題点 . . . . 65
7.5 提案手法 . . . . 65
7.5.1 購買履歴の生成に対するモデル . . . . 65
7.5.2 提案手法における同時分布 . . . . 67
7.5.3 学習アルゴリズム . . . . 68
7.6 実験 . . . . 70
7.6.1 人工データ実験 . . . . 71
7.6.2 実データ実験 . . . . 75
7.6.3 実験結果まとめ . . . . 78
7.7 本章のまとめ . . . . 79
iii
第8章 考察 80 8.1 第6章で提案した推薦方式の応用 . . . . 80 8.2 第7章で提案した推薦方式の応用 . . . . 81
第9章 結論 82
9.1 まとめ . . . . 82 9.2 今後の課題 . . . . 83 9.3 将来の展望 . . . . 83
付 録A 第7章に関する付録 84
A.1 ディリクレ過程 . . . . 84 A.2 提案手法におけるZ, W の事後確率の導出 . . . . 85
参考文献 87
謝辞 94
研究業績 96
iv
4.1 各提案手法の位置づけ . . . . 18
5.1 実験結果:モデルを1つに固定した場合と提案手法の割引総利得(真 のモデルを含む場合.値は理論値に対する比を表す). . . . . 35
5.2 実験結果:モデルを1つに固定した場合と提案手法の割引総利得(真 のモデルを含まない場合.値は理論値に対する比を表す). . . . . . 35
5.3 実験結果:同じ商品を2回購入しない場合(真のモデルを含む場合. 値は理論値に対する比を表す). . . . . 37
5.4 実験結果:モデルベースアルゴリズムとの比較結果(値は理論値に対 する比を表す). . . . . 37
6.1 提案する評点予測アルゴリズム . . . . 47
6.2 MovieLensとEachMovieデータセット . . . . 49
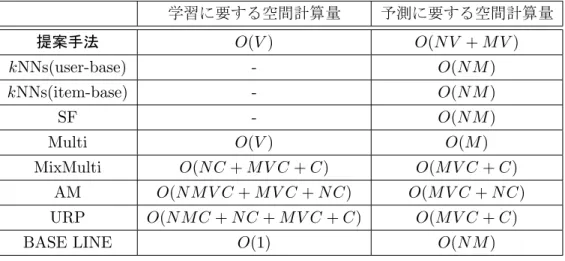
6.3 各手法の予測精度.値が小さいほど予測精度が良いことを意味する. 51 6.4 各手法の予測に要した計算時間.要した時間が短いほどスケーラビリ ティが良いことを意味する. . . . . 52
6.5 予測対象の全評点の予測に要する計算量(computational complexity). 54 6.6 予測に要する空間計算量(space complexity). . . . . 54
7.1 ギブズサンプリングに基づく学習アルゴリズム. . . . 69
7.2 人工データ作成に用いたパラメータ値(パターンI). . . . . 70
7.3 人工データ作成に用いたパラメータ値(パターンII). . . . . 72
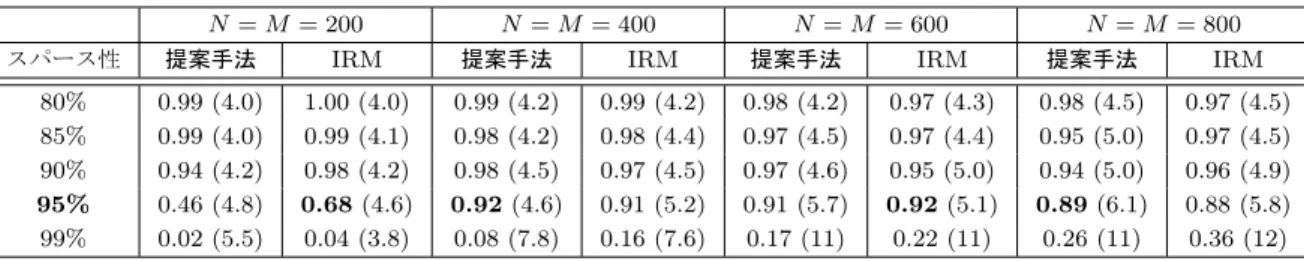
7.4 提案手法と無限関係モデル(IRM)の共クラスタリング性能比較(パ ターンI). . . . . 73
v
7.5 提案手法と無限関係モデル(IRM)の共クラスタリング性能比較(パ ターンII).. . . . 74 7.6 提案手法により得られたアイテムクラスごとの映画タイトル(一部) 76
vi
5.1 マルコフ決定過程モデルにおける変数間の関係を表すイメージ図 . . . 22
6.1 評点行列R(N = 6, M = 5, V = 5). . . . . 42
6.2 評点行列Rにおける各周辺評点分布(N = 6, M = 5, V = 5).(a)評 点済みと(b)未評点の分布間のKLダイバージェンスを最小化するこ とで,未評点箇所の値を予測する. . . . . 43
7.1 提案手法による共クラスタリング結果. . . . . 77
7.2 無限関係モデルによる共クラスタリング結果.. . . . 77
7.3 上位Lアイテムクラスに対する各手法の再現率. . . . . 79
vii
1
第 1 章 序論
1.1 はじめに
産学両面において,推薦(レコメンデーション)システムに関する様々な研究が盛 んに行われている[1, 40, 58, 59, 60].そこでは,過去に購入された商品等によって表 現される大量の履歴から,機械学習やデータマイニング等のデータ分析技術を利用し て,ユーザごとに推薦商品を決定するためのルール(推薦ルール)を自動で導出する 研究が進められている.特に,Amazon.com等のEC(Electronic Commerce,電子 商取引)サイトにおいては既に実用化が始まっている.また,最近では,Hadoop[44]
を利用することで,大規模なデータに対しても簡単に推薦方式を実装できるように もなっている[31].
ここで,殆どの従来手法に共通する点として,推薦を行いたいユーザ(推薦対象 ユーザ)と商品の購入履歴が類似している別のユーザ(もしくはユーザグループ)の 購入商品履歴に基づいて,推薦対象ユーザに対する推薦商品を決定することが挙げ られる(ユーザではなく商品を軸にした手法も考えられている).従って,推薦対象 ユーザへの推薦商品を考える際,ユーザ本人の購入商品履歴だけでなく,別のユー ザの購入商品履歴も利用しているという点で,履歴に関するユーザの広がりがある と捉えることができる.言うなれば,従来手法は, 空間的 な視点に基づく推薦方 式と意味づけることができる.さらに,その他の共通点として,推薦対象ユーザに 対して推薦する商品は,過去にどのような商品を推薦してきたかに関わらず,毎回 独立に決定され,かつ,推薦した結果が評価されていない点が挙げられる.ECサ イトの例で言うと,クリック率やコンバージョン率などの指標によって評価される こともあるが,推薦手法とは独立に実施されており,推薦手法自体は推薦した結果 に対する評価を考慮していない.すなわち,1回きりの推薦を想定した手法であり,
空間的な視点と対比した表現を用いると,従来手法においては,推薦に関して 時
間的 な要素は殆ど考慮されてこなかった.
しかし,推薦システムが実際に適用されることの多い電子商取引サイトを考える と,同じユーザに対して時間間隔を空けて推薦を繰り返し行うことが想定される.そ のようなサイトにおいては,ただ単にその時に購入して貰えそうな商品を1度だけ 推薦するのではなく,当該サイトをより長く利用して貰えるような商品を継続して 推薦していくことが重要となる.そのため,推薦ルールの導出にあたっては,次に 示すような, 時間的 な視点を考慮する必要がある.すなわち,推薦対象ユーザに 対して,これまでどのような商品を推薦し,その結果,どのような効果が得られて きたか,言い換えると,ある時点までの購入商品履歴のみならず,過去の推薦商品 履歴についても,それらの前後関係を踏まえた上で,推薦ルールを導出する必要が ある.推薦することの効果を,より現実に即した形で評価できる枠組みを検討すべ きである.
ただし,実際には,推薦対象ユーザ1人分の購入商品履歴と推薦商品履歴の数は 非常に少ないことが殆どであり,わずかな履歴から有用な推薦ルールを導出するこ とが困難になる場合が多い.そのため,履歴数の少なさを補うために,別のユーザ の購入商品履歴と推薦商品履歴を利用することが必須となる.
1.2 本研究の目的
以上をまとめると,推薦ルールの導出時には,今回新たに導入する 時間的 な 視点と従来手法における 空間的 な視点の両方に基づき,購入商品履歴と推薦商 品履歴の両履歴から,推薦ルールを学習する方式を検討することが重要である.
そこで,本論文では,
• 空間的な視点:推薦対象ユーザ以外のユーザの履歴も利用する.
• 時間的な視点:時間的な情報を含めた履歴を利用する.
推薦した結果,得られる効果を評価する.
同一ユーザに対して行われた複数回の推薦に対する効果を,
それらの順序も踏まえて評価し,その評価値を直接最大化する.
第 1章 序論 3
の考えに基づいた推薦方式の例として,3つの手法を提案する.1つは,空間的な視 点と時間的な視点の両方に基づく手法であり,残りの2つは,空間的な視点に基づ く手法である.ここで,空間的な視点に基づく2手法は,それぞれ単独でも推薦ルー ルの導出が可能であるが,1つ目の提案手法(空間的/時間的な視点の両方を併せ 持つ手法)に対するサブルーチンとしても転用可能な手法となっている.
なお,利用する履歴データには個人情報が含まれるため,当該データの扱いには 十分注意する必要がある.例えば,個人が特定できないようにマスキング処理を実 施することや,データを扱える分析者を限定すること,さらには,外部とは遮断さ れた分析環境を用意することなどが考えられる.本論文においては,これらの処理 が事前に施されたことを前提として議論を進めるものとする.
1.3 本論文の構成
本論文の構成は次のとおりである:まず第2章で,本論文全体を通して扱う履歴 データに関する定義を行い,第3章で従来の推薦方式を概説する.続いて第4章で 本研究の概要を説明した後,第5章から第7章において,提案する3つの推薦方式 の詳細をそれぞれ説明する.そして第8章において,第6章と第7章で提案する推 薦方式に関する応用について述べ,最後に第9章でまとめと今後の課題について述 べる.
第 2 章 準備
2.1 履歴データの定義
本論文で扱う履歴データに関する定義を行う.時系列形式で表現する場合と行列 形式で表現する場合があるため,それぞれ定義する.この章では,本論文を通して,
共通して使用する変数のみ定義する.各章に閉じて使用する変数については,該当 する章においてそれぞれ定義するものとする.
2.1.1 時系列形式での表現
ユーザの購入商品履歴とそのユーザに対する推薦商品履歴の2種類の履歴データ がN 人分あるものとする.ただし,両履歴においては,ユーザiごとに以下に示す ような順番が分かっているものとする.
ani−1(i), xni−1(i), . . . , a−2(i), x−2(i), a−1(i), x−1(i), a0(i), x0(i), i= 1,2, . . . , N.
ここで,at(i)(t=· · · ,−2,−1,0)は,時点tにおいてユーザiに対して推薦された商 品を表し,xtは商品atが推薦された後にそのユーザiが購入した商品をそれぞれ表 すものとする.niはユーザiの履歴数を表す.
また,購入商品と推薦商品はいずれも同じ商品集合Iに含まれるものとし,
xt(i), at(i)∈ I ={1,2, . . . , M}, t=. . . ,−2,−1,0,1,2, . . . , i= 1,2, . . . , N, 時点tまでのユーザiの購入商品履歴,および,推薦商品履歴をそれぞれxt(i), at(i)と 表す.さらに,両履歴をまとめた履歴データをD(i)で表し,ユーザN人分をまとめ てDで表すものとする:
D={D(1),D(2), . . . , ,D(N)}={x0(i), a0(i)}Ni=1.
第 2章 準備 5
2.1.2 行列形式での表現
評点行列
N 人のユーザが M 個のアイテムに対して与えた評点からなる N 行 M 列の評 点行列をR とする.R の (i, j) 要素 ri,j は,i 番目のユーザのj 番目のアイテムに 対する評点を表す.評点ri,j は {1,2, . . . , V}の離散値をとり,値が大きいほど良い 評価を意味するものとする.ただし,未評価であるri,j の値は0とする.また,ˆri,j はri,j の予測値を表す.以降,iをユーザインデックス,j をアイテムインデックス とし,特にアクティブユーザのインデックスをiact,ターゲットアイテムのインデッ クスをjtarとする.
ユーザi が既に評価した(未評価の)評点の集合をRiobs(Rimis)と表す.同様に,
アイテムj に対して既に評価が与えられた(未評価の)評点の集合を Rjobs(Rjmis) と表す.また,評点行列R において,既に評価が与えられた(未評価の)評点の集 合をRobs(Rmis)と表す.さらに,予測対象の評点集合をRtar(Rtar ⊆ Rmis)と おく.
ここで,既評価の評点数 #{Robs}は,未評価の評点数 #{Rmis} に比べてはるか に小さいことに注意する(#{Robs} ≪#{Rmis}).ここで,#{}は集合の要素数を 表す.推薦問題においてベンチマークデータとしてよく用いられる映画の評価データ においては,評点行列Rの約95% 以上の評点が未評価である.ただし,予測対象と する評点数は既評価の評点数とほぼ同等であるものとする(#{Rtar} ≈#{Robs} ≪
#{Rmis}).
購買行列
N 人のユーザとM 個のアイテムからなる,N×M 行列の購買行列をBとする.
ただし,Bの第(i, j)要素bi,jは,ユーザiとアイテムjの購買関係,
bi,j =
{ 1, ユーザiはアイテムjを購入済, 0, ユーザiはアイテムjを未購入,
を表す.評点行列の場合と同様に,購入された履歴数(bi,j= 1である要素数)は,行 列全体のサイズN ×Mと比べて非常に少なく,行列が疎である性質を持つ.
2.2 問題設定
ユーザの履歴データをもとに,次に推薦する商品を定めるためのルール(推薦ルー ル)を自動で抽出する問題を考える.個別の設定については,章ごとに説明するも のとする.
7
第 3 章 従来研究
3.1 従来の推薦手法
従来の推薦手法は,以下のように3つのタイプに分けて説明することができる [1, 54]:
1. メモリーベースアルゴリズム:
利用者間の購買履歴データの類似性をもとに推薦する商品を決定する.協調 フィルタリング[25, 35, 36, 46]などが提案されており,購買履歴が類似してい る利用者の間で人気のある商品を推薦する.最近傍法に基づくアプローチとも 呼ばれる.
2. モデルベースアルゴリズム:
購買履歴データに対して確率モデルを当てはめ,得られたモデルをもとに推薦 する商品を決定する.顧客セグメントを潜在クラスによって表現した潜在クラ
スモデル[17, 55, 56]などが提案されており,購入される確率の高い商品を推
薦する.確率モデルに基づくアプローチとも呼ばれる.
3. ハイブリッドアルゴリズム:
メモリーベースアルゴリズムとモデルベースアルゴリズムを足し合わせた手法 [39].
以降,メモリーベースアルゴリズムとして代表的な最近傍法に基づくアプローチ と,モデルベースアルゴリズムとして代表的な確率モデルに基づくアプローチを概 説する.
3.2 最近傍法に基づくアプローチ
このアプローチでは,類似ユーザを評点履歴データベースから抽出し,類似ユー ザの評点済みの評点を用いて予測を行う.アルゴリズムが単純なため実装が容易で,
実用化されている[25, 35].ここで,類似ユーザに基づいて予測を行う手法[35]に対 して,最近では,類似アイテムに基づいて予測を行う手法[25, 11, 36]も提案されて いる.後者は,評点行列Rを転置した行列に対して,従来通りの最近傍法に基づく 予測手法を適用する手法である.以降,類似ユーザ(類似アイテム)に基づく手法 をuser-base(item-base)と呼ぶ.通常,ユーザ数N よりもアイテム数Mの方が少 ないため,類似ユーザを探索するよりも類似アイテムを探索する方が計算時間の点 で優れている.以下,このアプローチに基づく2つの従来手法について説明する.
3.2.1 k 近傍法( kNNs )
何らかの類似尺度を用いて抽出したk人(個)の類似ユーザ(アイテム)のター ゲットアイテム(アクティブユーザ)に対する評点を,類似度によって重みづけた 値により予測を行う[25, 35, 36].具体的には以下の式により予測値を求める.
user-base : rˆiact,jtar =
∑k
i=1Wiiact(ri,jtar−r¯i)
∑k
i=1|Wiiact| + ¯riact, item-base : rˆiact,jtar =
∑k
j=1Wjj
tar(riact,j−r¯j)
∑k
j=1|Wjjtar| + ¯rjtar. ここで,Wii
actはアクティブユーザiactとユーザiの類似度を表す.同様に,Wjj
tarは ターゲットアイテムjtarとアイテムjの類似度を表す.
kNNsを適用する際には,使用するデータに依存して,類似性を測る対象,類似 尺度,近傍数kを決定する必要がある.
3.2.2 Unified method with Similarity Fusion ( SF )
user-base kNNsとitem-base kNNsを統合,拡張した手法である[43].類似ユーザ と類似アイテムからなる評点行列に存在する全ての評点済みの評点(Rnnsとおく)
第 3章 従来研究 9
と,個々の評点に対する重みを用いた重み付き平均により予測する.そのため,類 似ユーザのターゲットアイテムに対する評点や,類似アイテムのアクティブユーザ に対する評点だけでなく,類似ユーザの類似アイテムに対する評点も予測式に取り 込まれることになる.予測式は以下で表される.
ˆ
riact,jtar = ∑
ri,j∈Rnns
Wii,j
act,jtarfiact,jtar(ri,j), fiact,jtar(ri,j) = ri,j −(¯ri−¯riact)−(¯rj −¯rjtar).
ここで,Wii,j
act,jtarはriact,jtarに対するri,jの重みを表す.
SFは,1つの評点を予測するごとに,類似ユーザと類似アイテムの抽出を行う必 要がある.
3.3 確率モデルに基づくアプローチ
このアプローチでは,各評点が生成される確率モデルを仮定し,過去のデータを もとに学習したモデルを用いることで,将来の評点を予測する[17, 27, 26, 45, 48]. 予測対象の評点が離散値(1,2, . . . , V)であることから,各評点が従う分布として多 項分布が仮定される.評点を予測する際には,以下で定義されるmedian rating[27],
{ r
Pr{riact,jtar < r} ≤ 1 2, 1
2 ≤Pr{riact,jtar > r} }
, や,評点の平均値,
∑V r=1
rP r{riact,jtar =r},
が,riact,jtar の予測値rˆiact,jtar として用いられる.以下,このアプローチに基づく4 手法について説明する.
3.3.1 多項分布モデル( MULTI )
ユーザに依存せず,各アイテムの評点分布に対して1つの多項分布を仮定するモ
デル[27].多項分布のパラメータ(各評点の出現確率)は式(6.2)により計算する.
アイテムjの評点が従う多項分布をp(ri,j|j)で表すと,ユーザiの評点が従う結合評 点分布は以下で表される.
p(ri,1, ri,2, . . . , ri,M) =
∏M j=1
p(ri,j|j)δ(ri,j̸=0).
3.3.2 混合多項分布モデル( MIXMULTI )
ユーザは幾つかの嗜好の似通ったグループ(潜在クラス)に分かれると仮定する
モデル[27].つまり,同じ潜在クラスに属すユーザの評点は,アイテムごとに同一の
多項分布に従うと仮定する.ユーザiの評点が従う結合評点分布は以下で表される.
p(ri,1, ri,2, . . . , ri,M) =
∑C c=1
p(zc)
∏M j=1
p(ri,j|j, zc)δ(ri,j̸=0).
ここで,p(zc)はクラスzcが生起する確率,p(ri,j|j, zc)はクラスzcにおけるアイテ ムjの評点が従う多項分布をそれぞれ表す. 明らかに予測精度はクラス数Cに依存 する.
3.3.3 Aspect Model ( AM )
ユーザはC個の潜在クラスに分かれ,同じ潜在クラスに属すユーザの評点は,ア イテムごとに同一の多項分布に従うと仮定するモデル[17, 27].MIXMULTIと異な る点は,AMではアイテムごとにユーザが属すクラスが異なること(ユーザが複数 のクラスに属すこと)を許している点である.ユーザiの評点が従う結合評点分布 は以下で表される.
p(ri,1, ri,2, . . . , ri,M) =
∏M j=1
∑C c=1
p(zc|i)p(ri,j|j, zc)δ(ri,j̸=0). (3.1) ここで,AMは潜在クラスの出現確率をユーザで条件付けるため,新規ユーザに対 して予測を行う場合にはモデルの再学習が必要であること(生成モデルではないこ と)に注意.このモデルは情報検索の分野で考案されたpLSA[18]を推薦問題に適用 したモデルである.
第 3章 従来研究 11
3.3.4 User Rating Profile Model ( URP )
式(3.1)中のp(zc|i)をp(zc|θ)p(θ;γ)で置き換えることでAMを拡張し,厳密に生 成モデル化したモデルである[27, 26].ここで,p(θ;γ)はγを既知のハイパーパラ メータとするディリクレ分布を表す. ユーザiの評点が従う結合評点分布は以下で表 される.
p(ri,1, ri,2, . . . , ri,M;γ) =
∫
θ
p(θ;γ)
∏M j=1
∑C c=1
p(zc|θ)p(ri,j|j, zc)δ(ri,j̸=0)dθ.
URP は AM のように新規ユーザに対する予測を行う度にモデルを再学習する必要 はないが,推定すべきパラメータ数が増え,学習はAM に比べて複雑になる.
第 4 章 本研究の概要
4.1 従来の推薦方式における視点
殆どの従来手法に共通する点は,推薦を行いたいユーザ(推薦対象ユーザ)と商 品の購入履歴が類似している別のユーザ(もしくはユーザグループ)の購入商品履 歴に基づいて,推薦対象ユーザに対する推薦商品を決定することにある(ユーザで はなく商品を軸にした手法も考えられている).従って,推薦対象ユーザへの推薦 商品を考える際に,そのユーザの購入商品履歴だけでなく,別のユーザの購入商品 履歴も利用しているという点で,ユーザに関する広がりがあると捉えることができ る.言うなれば,従来手法は, 空間的 な視点に基づく推薦方式であると意味づけ ることができる.なお,購入商品履歴は,1年前に購入された商品も,昨日購入さ れた商品と区別されることなく,同じ購入履歴として利用される.さらに,その他 の共通点として,推薦対象ユーザに対して推薦する商品は,過去にどのような商品 を推薦してきたかに関わらず,毎回独立に決定され,かつ,推薦した結果が評価さ れていないことが挙げられる.つまり,1回きりの推薦を想定した手法であり,空 間的な視点と対比した表現を用いると,従来手法においては,推薦に関して 時間 的 な要素は殆ど考慮されていない.
4.2 本研究における視点
しかし,推薦システムが実際に適用されることの多い電子商取引サイトを考える と,商品の推薦は1 回きりではなく,同じユーザに対して推薦を複数回に渡って行 うことが想定される.そこでは,当該サイトをより長く利用して貰うことが重要と なる.
第 4章 本研究の概要 13
そのため,推薦ルールの導出にあたっては,次に示すような, 時間的 な視点を 考慮する必要がある.すなわち,推薦対象ユーザに対して,これまでどのような商 品を推薦し,その結果,どのような効果が得られてきたか,言い換えると,ある時 点までの購入商品履歴のみならず,過去の推薦商品履歴についても,それらの前後 関係を踏まえた上で,推薦ルールを導出する必要がある.
• 空間的な視点として,
推薦対象ユーザ以外のユーザの履歴も利用する.
• 時間的な視点として,
時間的な情報を含めた履歴を利用する.
推薦した結果,得られる効果を評価する.
同一ユーザに対して行われた複数回の推薦に対する効果を,
それらの順序も踏まえて評価し,その評価値を直接最大化する.
などである.
ただし,実際には,推薦対象ユーザ1人分の購入商品履歴と推薦商品履歴の数は 非常に少ない.そのため,推薦ルールの導出時には,今回新たに導入する 時間的 な視点と従来手法における 空間的 な視点の両方に基づき,購入商品履歴と推薦 商品履歴の両履歴から,推薦ルールを学習する方式を検討することが重要である.
4.3 提案する推薦方式の全体像
本論文においては,上記考えに基づいた推薦方式の例として,3つの推薦手法を 提案する.1つは,空間的な視点と時間的な視点の両方に基づく手法であり,残り の2つは,空間的な視点に基づく手法である.以降で,提案する3つの推薦手法の 概要を述べる.
4.3.1 時間的な視点と空間的な視点の両方を考慮した推薦手法
1つ目の推薦手法として,履歴の順序を考慮した確率モデルをもとに,推薦対象 ユーザ以外の履歴も利用して推薦ルールを統計的に学習することで, 時間的な視点
と空間的な視点の両方を考慮した手法を提案する.
具体的には,時間的な視点を導入するため,マルコフ決定過程モデルを利用する.
ここで,マルコフ決定過程モデルとは,現在の 状態 と,その時に実施した 行 動 に依存して,次の 状態 への遷移が確率的に定まる確率過程である(この確 率は状態遷移確率と呼ばれる.現在の状態とそのときにとった行動を条件部に持つ,
次の時点の状態に関する条件付確率である).なお,状態が遷移する度に,遷移後 の状態に紐づく 利得 が得られる.そこで,商品の購入等のユーザの反応結果を 状態 ,商品の推薦を 行動 ,商品が売れた時に得られる収入を 利得 とする ことで,マルコフ決定過程モデルを推薦問題へ適用する.推薦ルールは,割引総利 得を最大化するようなルールとして得る.ここで,割引総利得とは,将来に渡って 得られる利得の重み付き期待値であり,直近で得られる利得ほど大きな重みが与え られる.
推薦問題へ適用するためのマルコフ決定過程モデルの一般化
ただし,既存のマルコフ決定過程モデルは,上述した通り,次に遷移する状態は,
直前の状態とその時に実施した行動にのみ依存するという制限を持つ.すなわち,次 に購入する商品は,直前に購入した商品とその時に推薦された商品にのみ依存する モデルしか表現できない.しかし,実際には,2つ前に購入した商品や,3つ前に推 薦された商品等,過去の様々な時点における履歴に依存して,次に購入する商品が 定まると考える方がより自然である.故に,既存のマルコフ決定過程モデルを一般 化したもとで,推薦問題へ適用する.ただし,一般化とは,直前の状態や行動だけ でなく,状態と行動に関して過去の任意の時点の履歴を条件部に持つことが表現可 能な状態遷移確率を設定することを意味する.
統計的決定理論に基づく最適な推薦ルールの学習
以上の内容は,状態集合や状態遷移確率など,全ての変数は既知であるもとでの 議論である.本論文では,さらに,推薦問題への適用を想定し,状態遷移確率を未 知とした問題を検討する.ここで,状態遷移確率が未知であるとは,状態遷移確率
第 4章 本研究の概要 15
の構造自体が未知であることを意味する.そのため,解くべき問題は,履歴データ から推薦ルールを求める問題に変わり,推薦ルールの導出手順を新規に検討する必 要が生じる.なお,状態遷移確率を未知とした問題設定はこれまでにも考えられて いるが,状態遷移確率の構造自体は既知の場合に限られている.
すなわち,一般化したマルコフ決定過程モデルにおいて,何時点前の履歴に依存 して次に購入する商品が決定するかを事前に把握することは通常困難である.そこ で,マルコフ決定過程モデルにおける状態遷移確率の構造は事前には未知(条件付 き確率の条件部に入る変数群が未知)としたもとで,推薦対象ユーザ以外の履歴も 利用した推薦ルールの導出法を提案する.具体的には,統計的決定理論(特にベイ ズ決定理論)に基づいて推薦ルールを学習する手法を提案する:割引総利得を最大 化するのではなく,未知であるモデルとモデルパラメータに関する事前分布で割引 総利得をさらに平均化したベイズ期待効用を最大化することにより,ベイズ基準の もとで最適な推薦ルールを得る.人工データを用いた評価実験により,従来の推薦 方式や,既存のマルコフ決定過程モデルを用いた場合よりも,より多くの割引総利 得が得られることを確認する.
1つ目の推薦手法では,推薦ルールの導出時に,推薦対象ユーザ以外の時間情報 を含んだ履歴が利用され,かつ,推薦することの効果を利得によって表現した効用 関数をもとに推薦ルールが導出されており,冒頭に述べた2つの視点を考慮した手 法となっている.特長として,既存の確率モデルを拡張した点,さらに,最適性を 保証した推薦ルールの導出法を示した点が挙げられる.
4.3.2 空間的な視点を考慮した推薦手法 1
2つ目の推薦手法として,商品購入履歴ではなく,購入した商品に対する評価値
(例えば,1〜5点満点評価などの離散値)を利用した手法を提案する.つまり,空 間的な視点に基づき,推薦対象ユーザ以外のユーザの評価値履歴も利用して統計的 学習を行うことで,推薦対象ユーザが未購入である商品に対する評価値を予測する
(欠損値を補間する方法として捉えることもできる).推薦する商品としては,予測 された評価値の大きい商品が選択される.
具体的には,まず,全ての評価値が与えられた状態から,ランダムに欠損が発生
した結果,今現在の評価済み履歴が得られているとの仮定を置く.すると,評価済 みの履歴から算出されるユーザごとの評点分布,商品ごとの評点分布,および,全 評点に対する評点分布(いずれも多項分布によって表現される)が,予測対象の未 評価商品に対して同様に算出されるそれぞれの評点分布と類似していると見なせる.
そこから,評点済みの履歴に対する各評点分布と,未評価商品に対する各評点分布 との間の類似度を最小化する問題に帰着させることにより予測値を一括して求める.
ここで,分布間の類似度として,分布間の擬距離を表すKLダイバージェンスを用 いる.映画に対する評価値履歴データを用いた実験の結果,未評価商品に対する評 価値の予測精度は,従来の代表的手法とほぼ同程度であるが,計算時間の面で顕著 な優位性を持つことを示す.
提案手法の特長は,従来手法が評価値の予測を商品ごとに独立に行うのに対して,
提案手法は予測対象の評価値に対する予測値を互いに依存させ,予測対象の評価値 全てを一括して高速に予測する点にある.
4.3.3 空間的な視点を考慮した推薦手法 2
3つ目の推薦手法として,空間的な視点に基づき,推薦対象ユーザ以外の商品購入 履歴も含めたモデル学習に基づく手法を提案する.ここで,提案手法は,ユーザと 商品を同時にクラスタリング(共クラスタリング)することができる確率モデルに 基づく.共クラスタリングの結果,同じ商品を購入しているユーザクラスタと,同 じユーザに購入されている商品クラスタが同時に得られ,得られたクラスタごとに 推薦ルールを定めることができる(例えば,同じクラスタに属す他のユーザがよく 購入している商品を含む商品クラスタ中の商品を推薦する).
具体的には,ユーザと商品の共クラスタリングにディリクレ過程混合モデルを用 いる.ここで,ディリクレ過程混合モデルとは,複数の分布を足し合わせることで 表現される混合分布において,その混合数についても確率分布(ディリクレ過程事 前分布)を仮定するモデルである.ここで,混合数はクラスタ数に対応する変数で ある.これにより,各分布のパラメータだけでなく分布の混合数についても,パラ メータ学習として履歴から統計的に学習することが可能となる.提案手法は,ユー ザ(もしくは商品)クラスタごとに商品(もしくはユーザ)クラスタ数次元の多項
第 4章 本研究の概要 17
分布を仮定し,互いに同じクラスタを選択しあったときに購入行動が生じると仮定 したモデルに基づいて共クラスタリングする.実データを用いた実験により,ディ リクレ過程混合モデルに基づく従来手法(無限関係モデル)と比べて,より精度の 高い推薦ルールが得られることを示す.
提案手法の特長は,商品購入履歴のような欠損を含むデータが表現可能な確率モ デルに基づいている点にある.
4.4 本研究の意義
商品を推薦した結果,ユーザにどのような反応(行動)を示して欲しいか,とい う推薦すること自体の本来の目的について,当該分野ではこれまで殆ど考慮されて こなかった.しかし,推薦の本質とは,推薦対象ユーザとの1対1のやり取りの中 で得た,当該ユーザのこれまでの反応をもとに,次の推薦商品を決定することにあ る.また,推薦する目的を明確にすることで,推薦問題において,初めて最適性につ いて論じることができるようになった.本研究により,“真の推薦”が初めて実現可 能となったと言える.
推薦手法に関する研究が始まった頃は,ユーザの反応履歴を蓄積することは技術 的に困難な面もあったが,ここ最近では,推薦履歴やその反応履歴を蓄積する仕組 みが整備されつつある.従って,本論文で主張する2 つの視点に基づく推薦方式の 研究や実用化は今後さらに進んでいくものと考えられ,本研究は,新たな研究の方 向性におけるひとつの礎として意味のある研究であると言える.
提案する3つの推薦手法を表4.1に整理する.
表 4.1: 各提案手法の位置づけ
PPPPPPPPPPPP 空間的な視点 時間的な視点
従来手法[1]
最適性の保証なし 第6章 従来手法[16]
第7章
最適性の保証あり 第5章
19
第 5 章 ベイズ決定理論に基づくユニ バーサルマルコフ決定過程モ デル
推薦問題を扱うためのより一般化されたマルコフ決定過程モデルに対して,ベイ ズ基準のもとで最適な推薦ルールを履歴データから求める方法を提案する.提案手 法の特徴は,ある商品を推薦した後に何が買われたのかを考慮していること,さら に,一回の推薦結果だけでなく一定期間内に行った複数の推薦結果を評価している 点にある.ここで,従来の推薦手法と大きく異なる点は,推薦ルールを求めるため のプロセスを統計的決定問題として厳密に定式化したことにある.その結果,推薦 する目的に対して最適な推薦が行えるようになった.人工データを用いた評価実験 により,提案する推薦手法の有効性を示す.
5.1 はじめに
従来の推薦手法は,以下のように3つのタイプに分けて説明することができる [1, 54]:
1. メモリーベースアルゴリズム 2. モデルベースアルゴリズム 3. ハイブリッドアルゴリズム
ここで,上記3つのタイプに属す殆どの従来手法に共通する特徴として,商品を 推薦した結果を考慮していない点を挙げることができる.つまり,過去に購入した
商品履歴(以降,購入商品履歴と呼ぶ)のみから次に推薦する商品を決める手法が 殆どであり,ある商品を推薦した結果どのような商品が購入されてきたかを踏まえ て,次に推薦する商品を決めていない.つまり,推薦した商品の履歴(以降,推薦 商品履歴と呼ぶ)を考慮していない.
また,別の共通点として,推薦は1回のみ行うことを想定している点が挙げられ る.しかし,会員制のECサイト等を考えると,同じユーザに対して,推薦は1回 限りではなく複数回,継続的に行うことが想定できる場合もある[19].
そこで,本章では,上記2点を考慮した推薦手法を提案する.すなわち,ある商 品を推薦した後に何が買われたのかを考慮し,さらに,一時点の推薦結果だけでな く一定期間内に行った複数の推薦結果を評価する推薦手法を提案する.
ここで,その2点を考慮した従来手法として文献[16]がある.文献[16]では,マ ルコフ決定過程[50, 57]をベースにした推薦手法を提案しており,推薦商品履歴や推 薦を複数回行うことが考慮されている.具体的には,直近に購入された3つの商品 からなる順列をマルコフ決定過程モデルの1つの“状態”と見なし,次に購入される 商品は,1時点前の状態とその時に推薦された商品によって確率的に定まるものと 仮定する.そして,その仮定のもとで,将来に渡って得られる“利得”を最大化する
“定常政策”を求めている.ここで,定常政策は推薦ルールに該当し,商品3個分の
購入商品履歴ごとに推薦する商品が1つ定まる.
これに対して,本章では,商品購入履歴と推薦商品履歴を考慮するための,より 一般化されたマルコフ決定過程モデル(ユニバーサルマルコフ決定過程モデル)を 提案する.さらに,提案するモデルに対して,事前に得られている履歴データを用 いて,最適な定常政策(推薦ルール)を求める方法を提案する.ここで,マルコフ 決定過程モデルベースの従来手法[16]を含め,従来の推薦手法と大きく異なる点は,
推薦ルールを求めるためのプロセスを統計的決定問題として厳密に定式化したこと にある.本章では特に,ベイズ決定理論に基づいて最適な推薦ルールを求める方法 を提案する.提案手法を用いることにより,推薦する目的に合わせて,統計的決定 の観点で常に最適な推薦が行えるようになる.
本章の構成は次のとおりである:まず,5.2節において,本章で扱う推薦問題を定 義し,5.3節で,提案手法がベースとして用いるマルコフ決定過程モデルの概要を説 明する.続いて5.4節で,マルコフ決定過程モデルをベースにした従来手法[16]を
第 5章 ベイズ決定理論に基づくユニバーサルマルコフ決定過程モデル 21
説明した後,5.5節で一般化したマルコフ決定過程モデル(ユニバーサルマルコフ決 定過程モデル)を提案し,さらに,統計的決定理論に基づいて最適な推薦ルールを 導出する方法を提案する.5.6節で人工データを用いた評価を行い,最後に5.7節で まとめる.
5.2 問題設定
本節では,本章が対象とする推薦問題を定義する.各変数の定義は,第2章の定 義(時系列形式による表現)に従うものとする.
本節では,履歴データDを蓄積したもとで,履歴(x0, y0)を持つ推薦対象ユーザ に対する推薦商品を自動で決めるためのルール(推薦ルール)を求める問題を考え る.ここで,推薦対象ユーザは,履歴データDに含まれるN人のユーザとは異なる ユーザであるものとする.以下に,本節で想定する推薦の流れを整理する:
1. N 人分の履歴データDを蓄積する.
2. 履歴データDから推薦ルールを求める.
3. 2.で求めた推薦ルールを用いて,推薦対象ユーザに対して商品を推薦する.
4. 推薦対象ユーザが反応を示す(商品を購入する,何も購入しない等).
5. (3.と4.を繰り返す).
なお,推薦ルールの更新は考えないものとする1.また,各時点では常に1個の商品 を推薦するものとする(複数個への拡張は自然に行われる).さらに,推薦対象ユー ザによる同一商品の購入は1度きりでも複数回でも良いものとする.
以上の設定のもとで,本章では,一定期間内に行った複数の推薦結果を評価する.
すなわち,時点t= 1以降に購入された商品x1, x2, . . . がもたらす利益を最大にする 推薦ルールを求めることを本章の目的とする.
1本章では,商品が購入される度に得られる履歴データを用いて推薦ルールを逐次更新することは 想定しない.実際,推薦ルールの更新は,月に1回更新する等,定期的に行われる場合が多い.
利得系列 行動系列 状態系列
時点
図 5.1: マルコフ決定過程モデルにおける変数間の関係を表すイメージ図
5.3 準備:マルコフ決定過程モデル
本節では,従来手法及び提案手法がベースとして用いるマルコフ決定過程モデル の概要を説明する.ここで,(有限)マルコフ決定過程モデルは,以下の4つの要素 で構成される確率過程である:
• 有限状態集合:S ={1,2, . . . , S},
• 有限行動集合:A ={1,2, . . . , A},
• 状態遷移確率:{p(s|s′, a)|s, s′ ∈ S, a∈ A},
• 利得集合:{r(s, a)|s∈ S, a ∈ A}.
各構成要素間の関係を5.1に示す.5.1が示すとおり,時点tの状態st∈Sは,1つ 前の時点の状態st−1∈ Sと時点tでの行動at∈ Aにのみ依存して確率的に定められ る.つまり,時点tの状態stは,条件付確率p(st|st−1, at)に従って定まる(この条 件付き確率は状態遷移確率と呼ばれる).ここで,時点tにおける行動atは,時点 tでの状態stに基づいて決定される.このとき,状態に基づいて次の行動を定める ルールを政策d(st)と呼ぶ.さらに,行動atを選択したもとで状態stに遷移した場 合には,利得r(st, at)が得られるものとする.
上に示した4つの要素全ての値が既知であるもとで,最適な政策d(st)を求める 種々の方法が提案されている(価値反復法,動的計画法など[2]).ここで,最適な
第 5章 ベイズ決定理論に基づくユニバーサルマルコフ決定過程モデル 23
政策とは,以下の式で表される割引総利得(一定期間の間に得られる利得の総和),
∑T t=1
γt−1r(st, at), (5.1)
を最大化する政策であることを意味する.ただし,現在の時点をt= 0とし,γ(0<
γ <1)は割引率を表す.式(5.1)は,一定期間内に得られる全ての利得において,直
近に得られる利得ほど重視することを意味している.
5.4 従来手法
本節で設定した問題に対する従来手法として文献[16]がある.具体的には,以下の ような対応付けを行うことで,マルコフ決定過程モデルを推薦問題に適用している:
• 推薦対象ユーザが購入する商品xt(t=. . . ,−2,−1,0,1,2, . . .)は,以下に示す 状態遷移確率に従うものとする:
xt∼p(xt|xt−3, xt−2, xt−1, at;θ). (5.2) ここで,θは,状態遷移確率を規定する未知のパラメータである.式(5.2)は,
直前に購入された3つの購入商品履歴(xt−3, xt−2, xt−1)とその時に推薦された 商品atに依存して,次の商品xtが選択されることを表している.
• 商品xtが購入されることで得られる利益を,時点tにおける利得r(xt)とし
(利得関数の引数に行動aが含まれないことに注意),将来に渡って得られる 利得の合計を最大化する推薦ルールを求める.ここで,割引総利得は以下で表 される:
∑∞ t=1
γt−1r(xt).
• 履歴(x0, a0)を持つ推薦対象ユーザに対する推薦ルールを,定常政策dとして 表現する:
at=d(xt−3, xt−2, xt−1).
ここで,定常政策とは,時点に依存せずに当該時点の状態のみによって選択す べき行動が定まる政策である.つまり,直前に購入された3つの購入商品履歴 のみから,その時点での推薦商品が定まる.
• 推薦した結果,何も購入されなかった場合には利得を0とする.さらに,その 場合には状態は変化しないものとし,前の時点と同じ状態にいるものとして次 に推薦する商品を定める.
上記の対応付けは,商品3個分の購入商品履歴(xt−2, xt−1, xt)を1つの状態stと見 なしたマルコフ決定過程モデルとして解釈できる(5.1参照).
ここで,定常政策dは,以下に示す期待割引総利得Vを最大化することで求めら れる[2].
V((x−2, x−1, x0), d, θ)
=
∑∞ t=1
γt−1r(xt)p(xt|xt−3, xt−2, xt−1, at=d(xt−3, xt−2, xt−1);θ). (5.3) ただし,(x−2, x−1, x0)は推薦対象ユーザの初期状態s0を表す.
文献[16]で提案されている,推薦ルールの導出手順を以下に示す:
1. N 人分の履歴データDを蓄積する.
2. 履歴データDからパラメータθの最尤推定量θˆを求める.
3. 2.で求めたパラメータの推定値を式(5.2)に埋め込んだもとで,価値反復法を適
用する.すなわち,商品3個分の順列によって表現される状態を{x(1)x(2)x(3)} と置いたとき(x(1), x(2), x(3)∈ I),期待割引総利得Vから導かれる以下のベ ルマン方程式,
Vl+1({x(1)x(2)x(3)}) = max
j∈I
∑
x(4)∈I
p(xt=x(4)|st−1 ={x(1)x(2)x(3)}, at=j; ˆθ)
× {
r(x(4)) +γVl({x(2)x(3)x(4)})} ,
を用いて,状態ごとの評価値V({x(1)x(2)x(3)})を求める.ここで,添え字l, l+ 1 は,計算上のループ回数を表すインデックスを表し,評価値Vの値が収束する
第 5章 ベイズ決定理論に基づくユニバーサルマルコフ決定過程モデル 25
まで繰り返しVlの値をVl+1の値で更新する.そして,最終的に得られた評価 値V∗をもとに,推薦ルール(状態ごとに推薦する商品aを定めたルール)を 求める:
a = d({x(1)x(2)x(3)}),
= arg max
j∈I
∑
x(4)∈I
p(xt=x(4)|st−1 ={x(1)x(2)x(3)}, at=j; ˆθ)
× {
r(x(4)) +γV∗({x(2)x(3)x(4)})} .
なお,文献[16]では,初期の履歴データDには推薦商品履歴は含まれないものと し,購入商品履歴のみから近似的に状態遷移確率を求める手法を提案している.具 体的には,推薦された商品は,推薦されなかった場合と比べて購入される確率が上 がる,という仮説を置いたもとで,混合多項分布を当てはめることで状態遷移確率 を求める.ただし,実際に推薦を行っていくことで推薦商品履歴が蓄積された後は,
上記に示した手順のとおり,最尤推定により状態遷移確率が更新されるため,本章 では,前述した近似的な算出法については考えないものとする.
文献[16]では,マルコフ決定過程モデルを用いた推薦ルールの方が,従来の推薦 方式(モデルベースアルゴリズム)よりも,より多くの割引総利得が得られること を実験的に示している.すなわち,1人のユーザに対して推薦を複数回行うような 場合には,商品を推薦した後のユーザの反応,及び,一定期間内に行った複数の推 薦結果を考慮することの有用性が示されている.しかし,文献[16]では,既存のマ ルコフ決定過程モデルをそのまま推薦問題へ適用するに留まっており,より多くの 推薦問題への適用を考えた場合,より表現能力の高いマルコフ決定過程モデルを用 いる必要がある.また,その有効性は実験的に示されただけである.
5.5 提案手法
本節では,文献[16]におけるマルコフ決定過程モデルを,より一般化したマルコ フ決定過程モデル(一般状態マルコフ決定過程モデルと呼ぶことにする)を提案す る.さらに,提案する一般状態マルコフ決定過程モデルに対して,履歴データDか ら,統計的決定理論に基づき最適な定常政策dを求める方法を提案する.
![表 4.1: 各提案手法の位置づけ PPP PPP PPP PPP 空間的な視点 時間的な視点 従来手法 [1] 最適性の保証なし 第 6 章 従来手法 [16] 第 7 章 最適性の保証あり 第 5 章](https://thumb-ap.123doks.com/thumbv2/123deta/9785309.1868623/26.892.234.655.545.793/各提案手位置づけ空間視点時間視点従来手法最適保証なし従来手法.webp)