XML テクノロジを使いやすくする
オラクル・ホワイト・ペーパー
XML テクノロジを使いやすくする
概要 ... 3
はじめに ... 3
XML解析 ... 5
DOM XML解析 ... 5
DOM 3.0 Load and Save ... 5
DOM 3.0 Validation ... 8
SAX XML解析... 11
SAX出力のシリアライズ ... 11
XSL変換... 12
組込みグループ化機能... 13
一時ツリー... 13
複数の結果文書... 14
文字マッピング... 14
XMLスキーマ検証... 15
XMLスキーマ検証インタフェース ... 15
JAXB CLASS GENERATOR ... 16
XMLパイプライン・プロセッサ... 17
XML テクノロジを使いやすくする
概要
過去 5 年間にわたり、XML の評判は最新のビジネス・アプリケーションにおいて 高まり続けています。XML テクノロジにより、ビジネス・データへのアクセスや データ交換についての増え続ける要求に応えるインフラストラクチャが、ビジネ スにもたらされます。しかし、XML テクノロジの複雑さによって、アプリケーショ ンの開発やメンテナンスに高いコストがかかる可能性があります。 コスト削減になるよう XML テクノロジの使用を簡素化するため、Oracle XDK (XML Developer’s Kit)10g では、既存の XML 標準サポートを拡張し、XML の作 成、アクセス、変換や検証を簡素化する新しい技術および機能を導入しています。はじめに
企業が合併や買収または業務提携ネットワークの構築による取引先との提携強化 によってその事業を拡大する場合、様々な人々によって様々な時期と場所で開発 されたアプリケーションをまとめる必要があります。その場合、ビジネス・デー タ交換のフレームワークを確立するため、標準のデータ形式が必要です。XML (Extensible Markup Language: 拡張マークアップ言語)は、広く受け入れられてい る業界標準であり、B2B(Business-to-Business)や B2C(Business-to-Customer)、 EAI(Enterprise Application Integration: エンタープライズ・アプリケーション統合) などのアプリケーションの構築でのニーズに応える実質的なパラダイムを提供し ます。 一方、新しい技術を採用してビジネスを前進させる場合、企業は、単にレガシー・ アプリケーションを捨てて新しいアプリケーションに置き換えるわけにはいきま せん。XML は、メタデータとデータの組合せにより、新しいシステムでのレガ シー・データの使用や、プラットフォームおよびアプリケーション全体における データ共有を容易にします。 インターネットの登場により、ローカル・ビジネスに国内だけでなく世界中から 競争が持ち込まれるようになりました。今日のビジネスでは、もはや、取引を紙 文書のみに頼ることはできません。インターネットを通じたビジネスに、XML は、 企業の取引データ管理に対して強力なデータ抽象化を提供します。 現在のコンテンツ公開では、その用途は Web ページの表示に限定されません。コ ンテンツを、異なるメディア・タイプやデバイス・タイプ間で利用可能にする必 要が増大しています。XML でネットワーク上に「情報のアイランド」を作成した 場合、企業は、コンテンツの表現形式を、携帯情報端末用の WML 形式や印刷可 能な PDF 形式、さらに対話型グラフィックス用の SVG(Scalar Vector Graphics) 形式へと、柔軟に変換できます。XML は、ビジネス境界の拡張やレガシー・アプリケーションの統合、新しいビジ ネス・システムの創出のために、多くの企業で幅広く使用されています。しかし、 現在の XML テクノロジの利用は決して簡単ではありません。 第一に、XML は単純だと思われがちですが、実際は、XML 文書の作成および読 込みは単に XML 要素の開始タグ、終了タグ、属性を指定するだけにとどまらな いため、それほど単純ではありません。内部エンティティ、外部エンティティ、 パラメータ・エンティティ、PCDATA、CDATA など、XML の新しい概念をすべ て習得するにはかなり時間を要します。言うまでもなく、XML スキーマや XSLT、 XPath、Namespaces、XQuery の標準規格など、関連する規格も多数あり、XML の 習得をさらに難しくしています。 第二に、DOM や SAX などの汎用 XML プログラミング・インタフェースは、ビ ジネス・ロジックではなく XML 文書の操作に焦点を当てています。そのため、 アプリケーション開発者にとってビジネス・データの処理は困難です。 その一方で、XML が持つ拡張可能な特性ならびに業界で設計のガイドラインが不 足しているために、同じビジネス・データが様々な方法で表現されています。そ のため、XML メタデータ処理に関する効果的な戦略がなく、また、各文書ベース での XML 処理は効果的ではありません。Oracle XDK 10g は、新しい XML の開発 機能と XML アプリケーション開発を簡素化する技術のセットを提供することに よって、これらの問題に対処します。これには、次のものが含まれます。 • XML 解析を簡素化する DOM 3.0 および SAX のシリアライズ・インタ フェース • より高度な機能によって XSL 変換を簡素化する XSLT および XPATH 2.0 のサポート • XML データをアプリケーション・ロジックによる直接操作が可能なオブ ジェクトへバインドすることにより、XML 処理を簡素化する JAXB(Java Architecture for XML Binding)サポート
• アプリケーションで SAX XML 解析する場合にメタデータ定義を問い合 せ、効率よいストリーム・ベースの XML メタデータ処理を可能にする XML スキーマ検証インタフェース。この新しい技術によって、様々な形 式の XML 文書に関する「オープンな」コンテンツ処理を容易に行えます。 • 再利用可能なコンポーネント・フレームワークを確立する XML パイプラ イン・プロセッサ(XML Pipeline Processor)。このフレームワークは、ビ ジネス・アプリケーション用の XML リソースの宣言型パイプライン処理 をサポートします。
XML 解析
XML パーサーは、XML 文書を読み込み、XML のコンテンツや構造体へのプログ ラム方式のアクセスを提供するコンポーネントです。XML 解析は、XML データ の処理およびアクセスに必要な最初のステップです。Oracle XDK 10g では、DOM (Document Object Model)と SAX(Simple API for XML)の両規格に関する既存の
XML パーサーのサポートが拡張されています。
DOM XML 解析
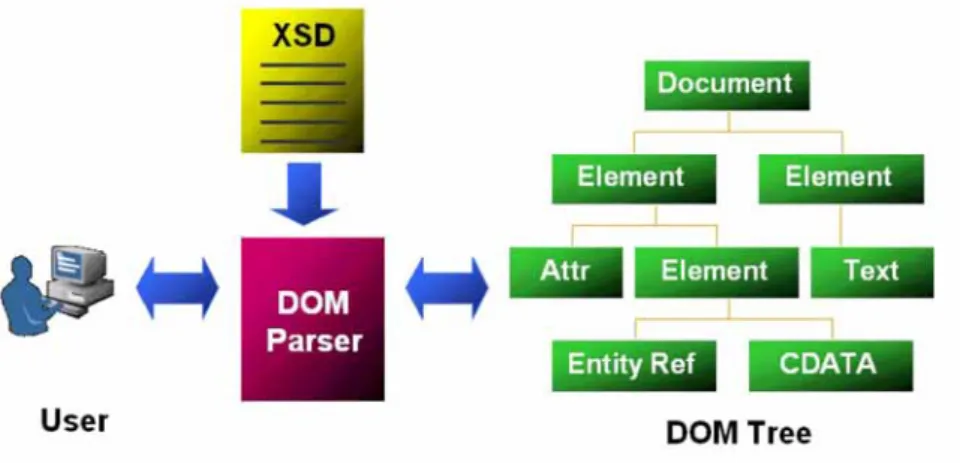
DOM は、おそらく今日使用される XML 操作用の API として最もポピュラーなも のです。図 1 に、XML 文書が DOM によってオブジェクト・ベース形式で表現さ れる様子を示します。 図 1: DOM XML 解析 DOM インタフェースは XML データにアクセスするためのオブジェクト・ベース の API のセットで、そのインタフェースは Java、C、C++、JavaScript、PL/SQL な どの言語全体で機能します。現在の XDK DOM 実装では、Java、C、C++における W3C DOM Level 1 と DOM Level 2 の両勧告をサポートしていますインメモリーDOM オブジェクト・ツリーは、大容量の XML 文書の処理にメモリ・ コストが高くなるにもかかわらず、世界中の本番アプリケーションで使用されて います。それは、このオブジェクト・ツリーによって、XML のコンテンツや構造 体への迅速なアクセスや動的更新が可能なためです。これらの操作は、XML の編 集や変換に必要です。Oracle XDK 10g では、DOM 3.0 Load and Save および DOM 3.0 Validation の導入によって、DOM 規格のサポートが拡張されています。
DOM 3.0 Load and Save
アプリケーションの移行には高いコストがかかるため、移植性は最新のビジネ ス・システムにとって重要です。W3C の DOM レベル 1 および DOM レベル 2 の 規格には、XML データのロードや DOM オブジェクトのシリアライズに関する定 義がないため、DOM パーサーに関する入出力の処理に、開発者はベンダー固有の コードに頼らざるを得ません。しかし、これでは XML アプリケーションの移植 性がなくなります。さらに、DOM ツリーは入力した XML の何倍ものサイズにな る可能性があるため、アプリケーションには、メモリー内の XML 領域を削減す るフレキシブルな DOM 構築プロセスが必要です。
DOM 3.0 Load and Save では、DOM パーサーの入力およびシリアライズのプロセ スを標準化することによって、これらの問題を解決し、規格に完全に適合し移植 性がある DOM XML アプリケーションを構築できます。
Oracle XDK 10g では、XML データ・ソースでの読込みに、新しい 2 つのインタ フェース、createLSInput および createLSParser が提供されています。出力では、 新しい LSOutput および LSSerializer インタフェースを使用して DOM オブジェク トをシリアライズできます。
XDK DOM 3.0 Load and Save の新しいインタフェース DOMParserFilter は、入力 した XML コンテンツをフィルタリングして、カスタマイズした DOM を構築でき ます。
DOM XML アプリケーションのスケーラビリティ向上のために、Oracle XDK 10g では、DOM 3.0 Load and Save で非同期 XML DOM 解析も行えます。次の例は、非 同期 DOM 解析の使用法を示しています。 import org.w3c.dom.ls.LSParser; import org.w3c.dom.ls.LSInput; import org.w3c.dom.ls.LSLoadEvent; import oracle.xml.parser.v2.XMLLSParser; import org.w3c.dom.events.Event; import org.w3c.dom.events.EventListener; import oracle.xml.parser.v2.XMLDocument; import oracle.xml.parser.v2.XMLDOMImplementation; …
public class DOMAsynLoading implements EventListener { static DOMAsynLoading test;
boolean parseFlag=true;
public static void main (String[] args) { test = new DOMAsynLoading();
test.testParse("src/xml/book.xml"); }
public void testParse(String input) { short mode;
DOMImplementationLS impl = new XMLDOMImplementation();
mode = DOMImplementationLS.MODE_ASYNCHRONOUS; LSParser parser = impl.createLSParser(mode, null); try { ((XMLLSParser)parser).addEventListener("ls-load", (EventListener)test, false); } catch(Exception e) { e.printStackTrace(); }
LSInput inp = impl.createLSInput(); try {
URL url = createURL(input); inp.setSystemId(url.toString());
System.out.println("Asynchronous DOM parsing..."); parseFlag = false;
Document doc = parser.parse(inp); // Other Application Code
// Neen DOM Document while(!parseFlag) { try {
System.out.println("Waiting for the DOM Parsing...");
Thread.sleep(10); } catch(Exception e) {
} }
} catch(Exception e) { e.printStackTrace(); } }
public void handleEvent(Event evt) {
Document doc = ((LSLoadEvent)evt).getNewDocument(); try { ((XMLDocument)doc).print(System.out); parseFlag = true; } catch(Exception e) { e.printStackTrace(); } } 非 同 期 DOM 解 析 の 設 定 に は 、 ア プ リ ケ ー シ ョ ン で 、 DOMBuilder.addEventListener() 関数を使用して DOMbuilder に EventListener を 登録し、処理モードを DOMImplementationLS.MODE_ASYNCHRONOUS に設定 する必要があります。こうすることで、DOM XML 解析がバックグラウンド処理 で実行できます。DOM XML の解析後、DOM パーサーは、HandleEvent()コール バック関数をコールしてアプリケーションに通知し、メモリー内の DOM 文書の コンテンツ・ハンドラを戻します。
図 2 に、DOM 3.0 Load and Save の機能フローを示します。この機能フローでは、 DOM 入出力プロセスを標準化することによって、移植性がある XML を実装でき、 コンテンツをフィルタリングしてスケーラビリティに関する DOM オブジェクト のフットプリントを減少できます。さらに、DOM 3.0 Load and Save での非同期 DOM 解析は、XML 処理のマルチスレッド処理がサポートします(これにより、 スケーラビリティが向上します)。
DOM 3.0 Validation
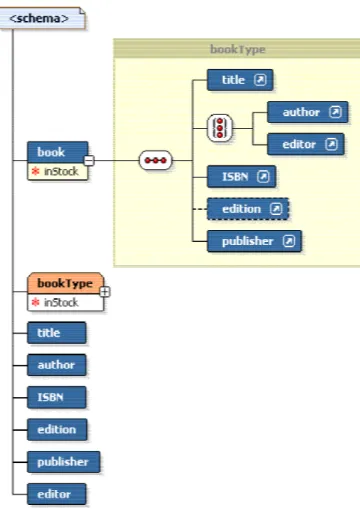
基幹業務アプリケーションでは、企業または業界の標準規格に従って XML 文書 が作成されることと、できるだけ早くエラーを特定できることが重要です。図 3 に示すように、DOM 3.0 Validation では、XML スキーマからのメタデータ定義の 取得、DOM 処理の妥当性の問合せ、XML スキーマに照らした DOM 文書または サブツリーを検証できます。 図 3: DOM 3.0 Validation 図4 は、書籍一覧文書用に定義された XML スキーマの例(book.xsd)です。図 4: book.xml の XML スキーマ
DOM 3.0 Validation の API を使用すると、XML DOM ツリーを更新する際にアプ リケーションで XML 文書を解析し、メタデータを問い合せできます。たとえば、 次の文書を考えます。
<?xml version = '1.0'?> <book inStock="Yes">
<title>Compilers: Principles, Techniques, and Tools</title>
<author>Alfred V.Aho, Ravi Sethi, Jeffrey D. Ullman</author> <ISBN>0-201-10088-6</ISBN> <edition>Second</edition> <publisher>Addison Wesley</publisher> </book> 対話型の DOM 3.0 Validation を提供するようアプリケーションを構築できます。 コマンドは、「Element_Name DOM_Functions」という形式でフォーマットされま す。たとえば、「XML スキーマで定義された要素」の検索に、次のような問合せ を DOM パーサーに送信できます(この問合せで、doc は DOM 文書を指します)。
?doc getDefinedElements publisher author edition editor book title ISBN 「使用可能な親要素あるいは子要素」、「要素のコンテンツ・タイプ」、「使用可 能な兄弟関係の要素」などの問合せが、すべて使用できます。次の例では、使用 可能な子要素と、<book/>要素の必須属性がチェックされます。 ?book getAllowedChildren publisher ISBN editor title edition author ?book getRequiredAttributes inStock XML スキーマ定義を使用して、XML 要素の列挙値も一覧表示できます。 ?edition getEnumeratedValues First Second Third Fourth Fifth DOM 操作の前に、DOM パーサーに対し、メタデータ定義に照らした操作が正当 かどうかを確認する問合せを行えます。次の例は、「<author/>要素をその親であ る<book/>から削除できるかどうか」を問い合わせています。
?book canRemoveChild author VAL_FALSE スキーマに基づき、DOM パーサーはこの操作が無効と返します。 最後の例として、文書のシリアライズ前、または別の XML 処理に渡す前に、編 集または新しく作成した文書の妥当性を次のようにチェックします。 ?doc validateDocument VAL_TRUE ?edition nodeValidity VAL_TRUE DOM 3.0 Validation により、XML 文書またはサブツリーの妥当性をチェックする API が提供されます。これらの DOM パーサーからのガイダンスによって、XML 編集はさらに強固になります。
SAX XML 解析
SAX 解析はイベント・ベースの XML 解析で、startDocument や endDocument な どのイベントを一連のコールバック関数に返します。(図 5) 図 5: SAX XML 解析 DOM XML 解析と比べ、SAX はストリーム・ベースの XML 処理で、インメモリー・ オブジェクトを作成しません。この軽量の XML 解析は、大きい XML 文書を取り 扱う場合に効果的です。ただし、その場で XML コンテンツの更新はできず、動 的アクセスとしては効果がありません。そのため、SAX 解析は、通常、大容量の XML 文書からコンテンツを取得して、フィルタリングして検索する場合に使用さ れます。
SAX 出力のシリアライズ
現在のことろ、SAX パーサーの使用には一連のコールバック関数を扱う必要があ り、一定量の作業が要求されます。図 6 のように、データベースに SQL 問合せを 送信して XSU から SAX のストリーミング出力を受け取る場合、管理が必要なハ ンドラが多数あるため、この追加作業はかなり面倒です。 図 6: データベース問合せのストリーミング出力Oracle XDK 10g では、SAX 出力をシリアライズする新しい Java インタフェース、 oracle.xml.parser.v2.XMLSAXSerializer を導入してこのプロセスを単純化してい ます。この新しいインタフェースでは、コンテンツ配信プロセスをより簡素化す る幅広い出力オプションも提供します。出力オプションにより、体裁のよい出力 書式の要否、XML 宣言やエンコーディングの情報、CDATA セクションとしてコ ンテンツ設定が必要な要素がある場合はその要素、DTD の system-id と public-id などについて指定できます。この新しい機能では、単純にそれを別のタイプの SAX のコンテンツ・ハンドラとして使用します。たとえば、次のように、XSU SAX 出 力インタフェースに登録できます。 OracleXMLQuery.getXMLSAX(sample); これによって、問合せで返された結果セットから無制限に XML ドキュメントを 生成できます。これまで、同じ文書の作成には、XSU で DOM を作成することが 必要でした。
XSL 変換
図 7 に示すとおり XSL 変換(XSLT)では、入力した XML 文書に XSLT スタイル シートを適用して、テキスト出力に関する書式設定セマンティックを適用します。 図 7: XSL 変換 Oracle XDK 10g では、Java XSL プロセッサにより、幅広い新機能および拡張機能 が提供されています。これらの機能は、XSLT 2.0 および XPATH 2.0 の W3C 草案 に定義されているものです。このホワイト・ペーパーでは、効率的で強力な XSL 変換を可能にする、いくつかの使いやすい機能の一覧を示します。 • 簡単かつ効果的にコンテンツをグループ化できる、新しい組込みグルー プ化機能のサポート • ノード・セット変換の余分な作業をなくす、新しい一時ツリーのサポー ト• 1回の XSL 変換で複数の出力文書を作成する新しい機能のサポート • エラーが発生しやすい文字のエスケープ処理をなくす、新しい文字マッ ピングのサポート これらの XSLT 2.0 新機能は、XSLT 変換を単純化する一方で機能性を充実させ、 設計および処理を最適化します。
組込みグループ化機能
XSLT 2.0 では、<xsl:for-each-group>要素を使用してグループ化する項目を選択で きます。この要素には、多くの<xsl:sort>要素(グループのソートに使用)を、そ れに続く特定のグループのコンテンツを作成する指示とともに含むことができま す。<xsl:for-each-group>命令は、選択した項目のグループ化方法を決定する次の 4 つの属性のうち 1 つを持ちます。 • group-by … 項目が表示された順序(選択した際の順序)が無視されま す。 • group-adjacent … 値が同じ隣接した項目のみがグループ化されます。 • group-starting-with … 各グループの最初のノードと一致するパターン を保持します。 • group-ending-with … 各グループの最後のノードと一致するパターンを 保持します。 グループのメンバーを current-group() 関数で返すことができます。一時ツリー
XSLT 1.0 では、XSL 変数および中間 XSL 変換の結果は、単純に文字列です。し たがって、ユーザーは、XPath 式を使用したコンテンツにアクセスできず、XSL 処理のモジュール化は困難です。XSL プロセッサでは、前述の結果のフラグメン トを文書ツリーに変換する Oracle XDK の ora:node-set() 関数など、新たな拡張機 能が提供されています。ベンダー提供の拡張機能を使用する場合の問題は、XSL スタイルシートの移植性がなくなることです。 XSLT 2.0 では、一時ツリーを導入することによりこの問題を解決しています。一 時ツリーは、<xsl:variable>、<xsl:param>、<xsl:withparam> 要素を評価すること で構成されます。一時ツリーは、文書ノードであるため、XPath 式でアクセスし たり、<xsl:apply-templates> 要素、<xsl:for-each> 要素、Key() 関数、id() 関数に よって処理できます。この機能によって、ノード・セットの変換が必要なくなり、XSLT のユーザは、 複雑な変換処理を複数のステップに分割したり、XML 文書の繰返し処理ができる ようになります。
複数の結果文書
XSLT 1.0 アプリケーションでは 1 回の変換から複数の結果文書を作成できないた め、通常、特定の変換から作成するページをパラメータで指示し、毎回、別個の 変換を使用していました。特に、同じ計算を各ページで繰り返す必要がある場合 には、これらの処理には多くの時間がかかります。 Oracle XDK では、<ora:output> 拡張を提供して、これらの操作を簡素化します。 ただし、XSL のスタイルシートの移植性を損なう問題は残っています。 Oracle XDK 10g で は 、 そ の よ う な 操 作 に 対 し て XSLT 2.0 の 新 し い <xsl:result-document> 要素を利用できます。この要素を使用して、XSLT 出力に ページ番号を付け、各文書に変換結果の一部のみを含むことができます。たとえ ば、CD カタログの変換には、各 <CD/> 要素を別の結果文書として作成できます。 この機能により、ユーザーは HTML(Hypertext Markup Language)のフレームを使 用するページを簡単に生成できます。さらに、SVG(Scalable Vector Graphics)の グラフィックス、CSS(Cascading Style Sheets)のスタイルシートなど、メイン出 力によって参照される補足ファイル、またはメイン出力に関するメタ情報を含む ファイルも作成できます。文字マッピング
XSLT 1.0 では、文字のエスケープ指定は使用方法が難しく、エラーが起こりがち でした。XSLT 2.0 では、<xsl:character-map> 要素を使用して最上位レベルのス タイルシートで文字マッピングを宣言することにより、この問題を解決します。 出力時にエスケープしてはならないマップ文字の定義には、<xsl:charactermap> 内の<xsl:output-character>要素を使用します。 これらの文字は通常、Unicode の外字用の領域(#xE000 と#xF8FF の間)に属しま す。たとえば、テキスト・ノードまたは属性ノードに#xE001 という文字が出現し た場合は、常に、出力時にその文字を「<%」という文字列に置換するように明記 して、生成 JSP コードに文字マップを設定できます。同様に、#xE002 という文字 が出現したときは、常に、出力時にその文字を「%>」という文字列に置換する指 定が必要になります。 テキスト・ノードまたは属性が一時ツリーにコピーされる場合でも、エスケープ されない文字が確実に維持されるため、文字マップの使用が disable-output-escaping の使用より、ずっと確実です。(このため、XSLT 2.0 では disable-output-escaping の使用は推奨されません。)さらに、XSL プロセッサでは、文字マップを使用し たほうが、より一貫した結果が得られます。XML スキーマ検証
Oracle XDK 10g の Java XML スキーマ・プロセッサでは、W3C 勧告となっている XML Schema 1.0 が 完 全 に サ ポ ー ト さ れ 、 XMLParser.SCHEMA_LAX_VALIDATION オ プ シ ョ ン ま た は XMLParser.SCHEMA_STRICT_VALIDATION オプションによる XML スキーマ 検証が、LAX モードと STRICT モードの両方で提供されます。ただし、XML ス キーマ・プロセッサの用途は文書の検証に限定されません。XML スキーマ文書に はメタデータ情報が豊富に用意されているため、拡張により、より複雑な XML 文書処理を実行できます。XML スキーマ検証インタフェース
Oracle XDK 10g では、Java XML スキーマ・プロセッサが再構築され、新しい XML スキーマ検証インタフェースが提供されています。このインタフェースでは、SAX XML の解析中、XML スキーマ・プロセッサからメタデータ情報や検証処理ステー タスを同時取得できます。 XSDValidator.getCurrentMode()を使用して現在の検証ステータス(LAX および STRICT ) を 取 得 し た り 、 XSDValidator.getElementDeclaration() や XSDValidator.getAttributeDeclarations() などの API を使用して XML の要素や属 性コンテンツ・タイプを検索したり、XSDValidator.getAnnotation() を使用して関 連 XML スキーマの注釈を取得することができます。 図 8: XML メタデータ処理のストリーミング 新しいメタデータ処理モデルを利用して、図 9 にあるような、XML メッセージの 「オープンな」XML 処理が可能な、XML メッセージング・アプリケーションを構 築できます。図 9: XML メッセージのデモ 取引先とのネットワークを構築する場合には、XML データが異種であることは避 けられず、新しいアプリケーション要件が生じます。しかし、様々な XML 文書 に個別に対処するのは非効率です。 このアプリケーションは、XDK の新しいストリーミング・メタデータ処理インタ フェースによって、XML 文書のオープンなコンテンツ分析および変換が簡単にな ることを示しています。デモでは、この技術を Oracle Streams Advanced Queuing 10g および Oracle XML DB 10g とシームレスに統合することで、トランザクション型 で高可用かつ安全な XML メッセージ管理を企業に提供できることも実証してい ます。
JAXB CLASS GENERATOR
Oracle XDK 10g では、JAXB(Java Architecture of XML Binding)1.0 の規格を完全 サポートしています。このサポートは、ユーザーが、XML スキーマ検証オプショ ンを持つ Java オブジェクト・インタフェースを通じて、XML スキーマおよびマー シャリング/アンマーシャリング XML 文書に基づく Java クラスを生成すること により行われます。新しい JAXB Class Generator では、XML スキーマの注釈と内 部のカスタマイズ・ファイル両方を使用して、生成された Java クラスをカスタマ イズできます。
図 10: DOM による XML 要素作成と、JAXB XML アンマーシャリングによる XML 要素作 成の比較 図 10 で示すとおり、文書構造ではなく XML コンテンツのビジネス・ロジックと 直接結びつく JAXB オブジェクト・バインディング・インタフェースによって、 XML 処理が大いに簡素化されます。
XML パイプライン・プロセッサ
XML アプリケーションには、XML 解析、XML スキーマ検証、XSL 変換など、様々 な処理が含まれます。各処理のための一連のインタフェースを扱うには、開発期 間、学習時間などが必要です。 XML 開発者の XML 処理時間を節約するために、Oracle XDK 10g では W3C ノー トの XML Pipeline Definition Language Version 1.0 に対する新しい XML パイプライ ン・プロセッサを提供しています。 Oracle XML パイプライン・プロセッサの使用で必要なことは、パイプライン文書 を XML で作成することのみです。この文書で、使用可能な XML 処理コンポーネ ントの使用を宣言し、XML 処理への入出力を指定し、処理の関係を記述します。 現在の Oracle XML パイプライン・プロセッサでは、使用可能なコンポーネントと して、XML 文書を解析する DOM XML パーサーおよび SAX XML パーサー、XML スキーマ検証に使用する XML スキーマ・プロセッサ、XML 文書を変換する XSL プロセッサ、および XML をシリアライズのためにバイナリ形式に圧縮する XML コンプレッサが含まれています。 実行時パイプライン・コントローラは、再利用可能なコンポーネント・フレーム ワークに基づいて構築されます。図 11 に示すとおり、パイプライン文書の記述に 従って連鎖的な XML 処理が実行され、結果が返されます。図 11: XML パイプライン・プロセッサ Oracle XML パイプライン・プロセッサに組み込まれた最適化機能により XML 処 理を最適化することで、開発者の時間はさらに節約されます。
結論
XML テクノロジが持つ柔軟性と幅広い適用範囲により、ビジネスでは、基幹業務 アプリケーションに XML インフラストラクチャが使用され始めています。過去 5 年間にわたり、ソフトウェアのベンダーと世界のエンドユーザー企業の両方が、 XML 対応のデータベース・アプリケーションの構築に莫大な投資を行ってきまし た。 データを XML 形式で表示することにより、より有効かつ柔軟にビジネスに活用 できます。しかし、一方では、XML の処理で発生するオーバーヘッドや、同じビ ジネス・データが様々な方法で表現されることによって、XML データの処理や共 有をいっそう複雑にしています。また、既存の標準が提供する現行の XML 処理 インタフェースと機能は、ビジネス・アプリケーションの増え続ける要件を満た そうとする場合に、面倒だったり不十分だったりします。 Oracle XDK 10g では、XML テクノロジの使用を非常に簡単にする機能を導入した うえで、標準を満たし、拡張する XML インフラストラクチャ・コンポーネント を提供します。このように、Oracle XDK 10g は、現在および将来のエンタープラ イズ・アプリケーションの要件を満たすインフラストラクチャとして機能します。XML テクノロジを使いやすくする 2005 年 9 月 著書: Jinyu Wang 寄稿者: Mark Scardina Oracle Corporation World Headquarters 500 Oracle Parkway Redwood Shores, CA 94065 U.S.A. 海外からのお問合せ窓口: 電話: +1.650.506.7000 ファックス: +1.650.506.7200 www.oracle.com
Copyright © 2005, Oracle. All rights reserved.
この文書はあくまで参考資料であり、掲載されている情報は予告なしに変更されることがあります。 オラクル社は、本ドキュメントの無謬性を保証しません。また、本ドキュメントは、法律で明示的または暗黙的に記載 されているかどうかに関係なく、商品性または特定の目的に対する適合性に関する暗黙の保証や条件を含む一切の保証 または条件に制約されません。オラクル社は、本書の内容に関していかなる保証もいたしません。また、本書により、 契約上の直接的および間接的義務も発生しません。本書は、事前の書面による承諾を得ることなく、電子的または物理 的に、いかなる形式や方法によっても再生または伝送することはできません。
Oracle、JD Edwards および PeopleSoft は Oracle Corporation および関連会社の登録商標です。他の製品名は、それぞ れの所有者の商標です。