修 士 論 文 の 和 文 要 旨
研究科・専攻 大学院 情報理工学研究科 情報・ネットワーク工学専攻 博士前期課程 氏 名 山岸 徹平 学籍番号 1931151 論 文 題 目 分散協調キャッシュサーバ処理のFPGA オフロード 要 旨 動画配信サービスの普及やコンテンツの高画質化によりインターネット通信量が増大している.一般的な動画配信サービスではCDN(Content Delivery Network)と呼ばれる大規模キャッ
シュネットワークを使用したコンテンツ配信が行われている.CDN 内の通信量削減手法とし て,複数のキャッシュサーバを組み合わせて動作する分散協調キャッシュが提案されている. 分散協調キャッシュでは,各キャッシュサーバにコンテンツを分散して配置し,サーバ間でコ ンテンツを共有することで実効キャッシュ容量を拡大する.しかし,サーバ間でコンテンツ検 索リクエストやデータの通信の頻度が増大し,ボトルネックとなる.また,5G ネットワークの 普及に伴い,低遅延ネットワークを用いたアプリケーションの需要が増大している.低遅延通 信では通信ノードでのソフトウェア処理がオーバヘッドになりやすい. ビックデータ解析など演算あたりの計算量が多い処理の高速化のために,ネットワークやス トレージに接続した FPGA を用いた専用ハードウェアによるアクセラレーションが行われて いる.我々の研究室では,Interconnected-FPGAs と呼ぶ複数の FPGA ボードを光ネットワー クで結合したシステムを開発している.Interconnected-FPGAs では,ネットワークインタフ ェースやフラッシュストレージがFPGA ボードに接続されており,主記憶を介さずに高速なデ ータ転送が可能である.また,データ経路上で演算を行うことが可能である. 本研究ではInterconnected-FPGAs を用いて,分散協調キャッシュサーバ処理の一部を専用 ハードウェアにオフロードすることにより低遅延化を図る.FPGA 上でキャッシュ制御を行う ためにHCC(Hardware Cache Controller)と呼ぶモジュールを実装し,FPGA ボード直結の光 ネットワークとフラッシュストレージを使用することで,FPGA を使わないソフトウェア実装
に比べて無負荷レイテンシが約85%削減されることを確認した.さらに,FPGA ボード搭載の
DRAM をキャッシュ領域として使用することで,ソフトウェア実装と比べて無負荷レイテンシ
令和
2
年度修士論文
分散協調キャッシュサーバ処理の
FPGA
オフロード
大学院情報理工学研究科
情報・ネットワーク工学専攻
学籍番号
: 1931151
氏名
:
山岸 徹平
主任指導教員
:
吉永 努 教授
指導教員
:
湯 素華 准教授
提出年月日
:
令和
3
年
1
月
25
日
目 次
第1章 序論 1 第2章 関連研究 2 2.1 分散協調キャッシュ . . . 2 2.2 専用ハードウェアによる処理の高速化. . . 4 第3章 本研究の概要 6 第4章 分散協調キャッシュサーバの実装 7 4.1 分散協調キャッシュサーバの動作 . . . 7 4.2 実装の概要 . . . 7 4.3 本研究で使用するFPGAボード . . . 11 4.4 ソフトウェアによる実装 . . . 13 4.5 SSDアクセスとノード間通信をFPGAオフロードする実装 . . . 15 4.6 キャッシュ制御をFPGAオフロードする実装 . . . 17 4.6.1 FPGA内のハードウェアの構成 . . . 19 4.6.2 HCC内部のモジュール構成 . . . 20 4.6.3 ホスト計算機でのキャッシュ制御処理 . . . 23 4.7 DRAMをキャッシュ領域として使用する実装 . . . 24 第5章 評価 25 5.1 計算機環境 . . . 25 5.2 レイテンシ評価 . . . 26 5.2.1 レイテンシ測定手法. . . 26 5.2.2 無負荷レイテンシ測定結果 . . . 27 5.3 スループット評価 . . . 30 5.4 リソース評価 . . . 30 第6章 結論 32謝辞 33
図 目 次
2.1.1コンテンツの色タグとキャッシュされるサーバの対応 . . . 3 2.2.1 Interconnected-FPGAsの概要 . . . 5 4.2.1実装(1)ソフトウェアによる実装の構成 . . . 8 4.2.2実装(2) SSDアクセスとノード間通信をFPGAにオフロードした場合の構成 . . . . 8 4.2.3実装(3)キャッシュ制御をFPGAにオフロードした場合の構成 . . . . 9 4.2.4実装(4)キャッシュ領域にDRAMを使用した場合の構成 . . . . 9 4.3.1 FPGAボードAPX-7142改 . . . 12 4.3.2 FPGAボード搭載PCクラスタ . . . 12 4.4.1実装(1)の処理の流れ . . . 14 4.5.1実装(2)の処理の流れ . . . 16 4.6.1実装(3)の処理の流れ . . . 18 4.6.2 FPGA内部のモジュール構成 . . . 19 4.6.3 HCC内部のモジュール構成 . . . 21 4.6.4ダイレクトマップでのアドレスの対応. . . 22 4.6.5ダイレクトマップでのBRAMとSSDのデータ構造 . . . 22 4.7.1 DRAMキャッシュ実装時のHCC内部のモジュール構成 . . . 24 5.2.1レイテンシの測定の流れ . . . 26 5.2.2無負荷レイテンシの測定結果 . . . 27 5.2.3実装(1)のレイテンシ . . . 28 5.2.4実装(2)のレイテンシ . . . 28 5.2.5実装(3)のレイテンシ . . . 29 5.2.6実装(4)のレイテンシ . . . 29 5.3.1 512MB転送時のスループット測定結果 . . . 31表 目 次
4.1 各手法の比較 . . . 10
4.2 FPGAボードの仕様 . . . 11
5.1 計算機環境 . . . 25
第
1
章
序論
動画配信サービスの普及やインターネットに接続されるデバイス数の増加,コンテンツの高画
質化により,インターネット通信量が増大しており,5年間で約3倍になると予測されている[1].
通信量の増加はネットワークの輻輳の原因となる.動画の通信量削減手法として,キャッシュサー バの利用が挙げられる.一般的な動画配信サービスでは,CDN(Content Delivery Network)と呼ば れる大規模キャッシュネットワークを使用したコンテンツ配信が行われている.インターネット通 信量に占めるCDNの割合は,2022年には約72%に増加すると予測されている.通信設備を増強 することで,ある程度の通信量増大には対応できるが,通信設備の増強には多大なコストがかか る.そのため,CDN内の通信効率改善が必要となる. CDN内の通信効率改善の手法として,分散協調キャッシュが提案されている.単純なキャッシュ サーバは単体で動作することを前提としているため,これを複数台並べるだけでは,キャッシュ容 量拡大の効果が薄い.分散協調キャッシュでは,複数のキャッシュサーバを協調して動作させ,実 効キャッシュ容量を拡大する.中島らは,色タグを用いた分散協調キャッシュにより,通信量を削 減する手法を提案した[2].しかし,分散協調キャッシュサーバは,単体のキャッシュサーバと比 べると他のキャッシュサーバへのキャッシュ検索リクエストやコンテンツ転送の処理が増加する. 大規模な分散協調キャッシュネットワークでは,逐次的に複数のキャッシュサーバへのコンテンツ 検索を行う場合がある.これらの分散協調キャッシュサーバ処理をソフトウェアで実行すると,低 遅延応答へのオーバヘッドとなる. ビックデータ解析などの演算あたりの計算量が多い処理を高速化するために,FPGAなどの専用 ハードウェアが用いられている.さらに,複数台のFPGAボードを相互接続し,低遅延でノード間 通信が可能なシステムが提案されている.我々の研究室では,Interconnected-FPGAsと呼ばれる複 数のFPGAボードを光ネットワークで結合した計算機システムを開発している[3]. Interconnected-FPGAsでは,ネットワークインタフェースやフラッシュストレージがFPGAボードに接続されて おり,主記憶を介さずに高速なデータ転送が可能である.また,データ経路上での演算が可能で ある.
本研究では,Interconnected-FPGAsを用いて,FPGAボード間の専用ネットワークとFPGAボード
直結のフラッシュストレージを使用し,ハードウェア上でキャッシュ制御を行うためのHCC(Hardware
第
2
章
関連研究
2.1
分散協調キャッシュ
単独で動作するキャッシュサーバを単に複数台並べただけでは,コンテンツの重複が発生し,効 率的な通信量削減効果が期待できない.そこで,複数台のキャッシュサーバを組み合わせて効率的 にキャッシュを行う分散協調キャッシュサーバが提案されている. Wangらは,リングネットワークにおいてコンテンツとサーバに整数のIDを割り当て,コンテ ンツのIDとサーバのIDをそれぞれkで割った剰余が等しいときにキャッシュをすることで,実効 キャッシュ容量をk倍にするアルゴリズムを提案した[4].ハッシュ値を用いた分散協調キャッシュ では,実効キャッシュ容量が拡大されるが,特定のコンテンツに人気が集中した場合,特定のサー バやその周辺の経路の負荷が増大する. より効果的に通信量削減を実現するためには,キャッシュサーバのトポロジやコンテンツのアク セス頻度に基づいたコンテンツ配置が重要になる.Liらは,ネットワークトポロジ,キャッシュ容 量,通信コスト,アクセス確率などの制約条件をもとに,遺伝的アルゴリズムを用いて,全体の 通信量が最小となるようなコンテンツの配置を決定する手法を提案した[5].しかし,遺伝的アル ゴリズムによるコンテンツ配信の計算には長時間を要する.Liらはフランスのネットワークを対 象に遺伝的アルゴリズムを用いてコンテンツ配置の計算を行ったが,10台のPCクラスタを用い て10時間程度の時間を要している.動画コンテンツのアクセス傾向は1時間で40%から60%程度 変動するため,過去のアクセスパターンをもとに求めたキャッシュ配置と計算後の最適な配置との 乖離が大きく,実用的ではない. 中島らは,色タグと呼ばれる制御情報をサーバとコンテンツに付与することで,短時間の計算 で遺伝的アルゴリズムによる通信量削減効果に近いコンテンツ配置を実現する手法を提案した[2]. 色タグはサーバには1色付与し,コンテンツには人気度に応じた色数を付与する.キャッシュサー バは,コンテンツの色タグの中にキャッシュサーバの色タグが含まれていた場合,キャッシュする. コンテンツの色タグの付与数は,人気度が高いものほど色タグの付与数を増やす.図2.1.1に3色 の色タグを使った場合にそれぞれのキャッシュサーバにキャッシュされるコンテンツの対応を示す. 人気度の高いコンテンツは,複数のサーバに保持されることで,特定のサーバへの負荷集中を減ら すことができる.人気度の低いコンテンツは,サーバを分散して保存することにより,キャッシュHigh
Mid
Low
Red
Server
Server
Green
Server
Blue
Po
pu
la
rit
y
図2.1.1:コンテンツの色タグとキャッシュされるサーバの対応 容量を拡大することができる. 一般的な動画配信サービスでは,動画ファイルの一部のデータを逐次取得することで,動画全 体のダウンロードが完了する前に再生をすることができる.また,再生の中断や特定のシーンに 移動が発生するため,再生位置によってアクセス頻度が異なる.そこで,動画ファイルを複数の チャンクと呼ばれる単位に分割し,チャンクごとにアクセス頻度に基づいた色タグを付与し,分 散協調制御を行う研究も存在する[6]. 5Gの通信規格ではD2D(Device-to-device)通信という端末同士の通信が可能である.モバイル端 末をキャッシュとして利用し,D2D通信を使用した協調キャッシュが提案されている[7]. 分散協調キャッシュ制御では,単独で動作するキャッシュサーバと比べて,キャッシュサーバ間 の検索リクエストやコンテンツ転送の頻度が増大する.さらにチャンク分割により,動画を分割 し細かい単位で制御することで,検索するファイル数が多くなり,ボトルネックとなりうる.レ イテンシやスループットの低下はQoE(Quality of Experience)の低下につながる.YouTubeの離脱 率の調査では動画の再生中に再バッファリングにより動画が一時停止した場合の離脱率は,動画2.2
専用ハードウェアによる処理の高速化
ビックデータ解析など演算あたりのデータ量が多い処理は主記憶へのデータ転送がボトルネッ
クとなりやすい.そこで,ネットワークやストレージに接続したFPGAで専用ハードウェアが演
算を行う仕組みが提案されている.
Xilinx社ではFPGAのボードを用いて分散メモリキャッシュサーバの高速化が行われている[9].
これは,NICとDRAMの間にFPGAによる専用ハードウェアを挿入し,キャッシュ検索を行うも
のである.また,SSD自体に専用ハードウェアを挿入することでリレーショナルデータベースの
クエリ処理を行うことができるSmart SSDが提案されている[10].このようにネットワークイン
タフェースやストレージの近くに専用ハードウェアを挿入することで,プロセッサの負荷を減ら すことができる.
Microsoft社は,Catapultと呼ばれる複数のFPGAボード相互接続したシステムで検索エンジン
の高速化を行っている[11].飯塚らは,FiCと呼ぶ複数のFPGAを高速シリアルリンクで接続し
たFPGAクラスタをクラウドでの計算基盤として使用する提案を行っている[12].
我々の研究グループでは,光ネットワークとストレージを持つFPGAボードを複数台組み合わせた
Interconnected-FPGAsと呼ぶシステムを開発している[3].図2.2.1に2ノード構成の Interconnected-FPGAsの構成例を示す.計算ノードはホスト計算機とPCI-Expressに接続されたFPGAボードで
構成される.FPGAボードにはフラッシュストレージと光ネットワークインタフェイスが搭載され
ている.Interconnected-FPGAsの特徴として,In-datapath ComputingとDirect Data Transmissionが
挙げられる.In-datapath Computingは,ストレージやネットワークからホスト計算機の主記憶など
へデータを転送する経路上で演算を行うことである.主記憶にデータを転送してプロセッサによっ
て処理される部分をFPGA上にオフロードすることで,プロセッサの負荷を下げることができる.
Direct Data Transmissionは,FPGA間の光ネットワークによるデータ転送である.ホスト計算機の
主記憶を介さずにデータを転送することで,低遅延なノード間通信を実現できる.
Interconnected-FPGAsを用いた応用例として,リレーショナルデータベースの演算の実装が行われており,性能
NIC
NW-IF
DRAMMain Memory
FPGA
Flash
Storage
Computing Node
PCI
Express
CPU
Direct Data
Transmission
In-datapath
Computing
NIC
NW-IF
DRAMMain Memory
FPGA
Flash
Storage
Computing Node
PCI
Express
CPU
図2.2.1: Interconnected-FPGAsの概要第
3
章
本研究の概要
大規模な分散協調キャッシュネットワークでは,逐次的に複数のキャッシュサーバへのコンテン ツ検索を行う場合がある.これらの分散協調キャッシュサーバ処理をソフトウェアで実行すると, 低遅延応答へのオーバヘッドとなる.コンテンツを取得するまでの遅延が増加はQoEの低下を招 く.この問題を解決するために,本研究ではキャッシュサーバ処理の一部を専用ハードウェアで実 現することにより低遅延化を行う. 具体的には,ネットワークとストレージが密に結合されたInterconnected-FPGAsを使用する. ネットワークは,FPGAボード上に搭載された専用の光ネットワークインタフェースを使用する. また,キャッシュ領域として,FPGAボードに接続されたSSDやDRAMを使用する.ネットワー クインタフェース,SSD,DRAMのプロトコル処理はFPGA上に実装されたハードウェアで行う. ハードウェアでプロトコル処理を行うことで,ソフトウェアと比較して低遅延に処理を行うことが できる.また,DMA転送を行うことで,SSDやDRAMから読み出したデータを専用ネットワー クにCPUを介さずに転送することが可能である. このように分散協調キャッシュサーバの処理をハードウェアにオフロードすることで,キャッシュ 処理の低遅延化を行う.第
4
章
分散協調キャッシュサーバの実装
4.1
分散協調キャッシュサーバの動作
分散協調キャッシュは複数のキャッシュサーバが協調動作することでキャッシュサーバ間でコン テンツを共有する.各キャッシュサーバにはクライアントが接続されており,コンテンツ要求リク エストを受け付ける.キャッシュサーバはクライアントからリクエストを受信すると,リクエスト されたコンテンツの色タグに基づいてルーティングを行う.コンテンツの色タグが自身のサーバ の色タグと一致する場合,自身のキャッシュサーバでコンテンツ検索を行う.コンテンツの色タグ が自身のサーバの色タグと一致しない場合は,周辺のキャッシュサーバにリクエストを転送し,コ ンテンツの取得を試みる.コンテンツを取得できた場合は,クライアントにコンテンツを転送す る.近隣のキャッシュサーバに存在しない場合は,上流のキャッシュサーバや配信サーバからコン テンツを取得して,クライアントに転送する.このとき,コンテンツの色タグが自身のキャッシュ サーバと一致する場合はコンテンツをキャッシュする.4.2
実装の概要
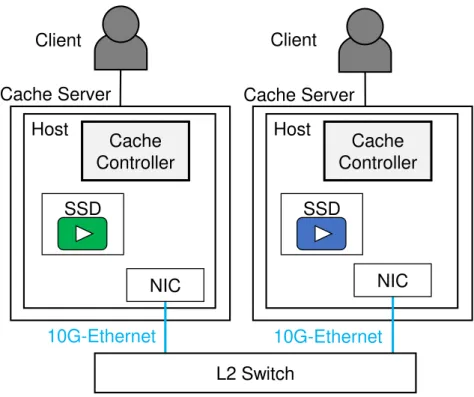
本研究では,色タグによる分散協調キャッシュを実装し,処理の一部をInterconnected-FPGAsに オフロードすることで低遅延化を図る.段階的に低遅延化のための手法を取り入れ,以下の4種 類の実装を行った. (1) ソフトウェアによる実装 (2) SSDアクセスとノード間通信をFPGAにオフロードする実装 (3) さらにキャッシュ制御をFPGAにオフロードする実装 (4) さらにキャッシュ領域にDRAMを使用する実装 それぞれの実装の構成を図4.2.1,図4.2.2,図4.2.3及び図4.2.4に示す.また,各実装でのキャッ シュ処理,データ転送及びコンテンツ保存先を表4.1に示す.Client
Host
Cache
Controller
Client
Host
Cache
Controller
10G-Ethernet
10G-Ethernet
NIC
L2 Switch
NIC
Cache Server
Cache Server
SSD
SSD
図4.2.1:実装(1)ソフトウェアによる実装の構成FPGA
Board
DRAM
NW I/F
Host
FPGA
Board
DRAM
Cache
Controller
NW I/F
Host
Cache
Controller
Client
Client
Cache Server
Cache Server
GiGA CHANNEL
SSD
SSD
FPGA
Board
HCC
DRAM
NW I/F
Host
FPGA
Board
HCC
DRAM
Cache
Controller
NW I/F
Host
Cache
Controller
Client
Client
Cache Server
Cache Server
GiGA CHANNEL
SSD
SSD
図4.2.3:実装(3)キャッシュ制御をFPGAにオフロードした場合の構成FPGA
Board
HCC
DRAM
NW I/F
Host
FPGA
Board
HCC
DRAM
Cache
Controller
NW I/F
Host
Cache
Controller
Client
Client
Cache Server
Cache Server
GiGA CHANNEL
SSD
SSD
表4.1:各手法の比較
実装手法 キャッシュ制御 データ転送 コンテンツ保存先
実装(1) Host PC 10G-Ethernet Host接続のSSD
実装(2) Host PC GiGA CHANNEL FPGA接続のSSD
実装(3) FPGA Board GiGA CHANNEL FPGA接続のSSD 実装(4) FPGA Board GiGA CHANNEL FPGA接続のSSDとDRAM
実装(1)では,キャッシュ制御部をホスト計算機上のソフトウェアで実装し,キャッシュサーバ間
はL2 Switchを経由し,10G-Ethernetで接続されている.コンテンツはホスト計算機のマザーボー
ドに接続されたSSDに格納する.
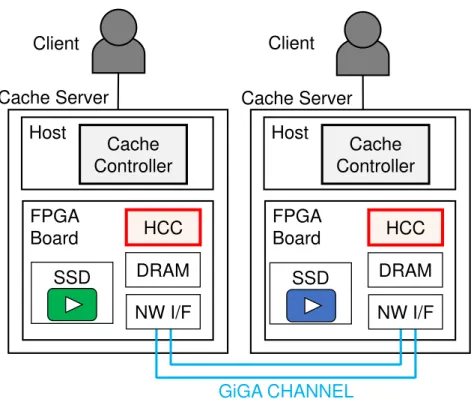
実装(2)では,図4.2.2の赤枠に示す部分にFPGAボードを接続し,キャッシュサーバ間の通信
をFPGAボード搭載の専用ネットワークであるGiGA CHANNELを使用する.また,コンテンツ
はFPGAボードに接続されたSSDに格納する.この実装ではキャッシュ制御はソフトウェアで実
行し,FPGAはGiGA CHANNEL通信プロトコル処理とSSDアクセスのみを担当する.
実装(3)では,FPGA上でキャッシュ制御を行うために図4.2.3の赤枠部分に示すHCC(Hardware Cache Controller)と呼ぶモジュールを実装し,実装(2)で述べた通信プロトコルとSSDアクセスに 加え,キャッシュ制御処理の一部をハードウェアで行う. 実装(4)では,さらにFPGAボードに搭載されたDRAMをキャッシュ領域として使用する処理 を追加する. それぞれの実装の詳細について,4.4,4.5,4.6及び4.7で述べる.
4.3
本研究で使用する
FPGA
ボード
本研究ではAVALDATA社のAPX-7142改を使用する.APX-7142改はAPX-7142[14]に搭載さ
れているSASポートに4台のSSDをSATA接続できるように改造したものである.FPGAボード
の仕様を表4.2に示す.FPGAボードの外観を図4.3.1に示す.
FPGAボードには光ネットワークインタフェースが搭載されており,GiGA CHANNELと呼ばれ
る独自のプロトコルで,リング状に接続したボード間の通信が可能である.搭載されているDRAM
はGiGA CHANNEL経由で同期され,共有メモリとして利用可能である.SASポートに接続され
たSSDは,ストライピングによって4台同時にアクセスすることにより高速にデータの読み書き が可能である. また,このFPGAボードはホスト計算機とPCI-Expressで接続されており,ホスト計算機から FPGAボード上の共有メモリとのデータ転送やFPGA上のローカルレジスタへのアクセスが可能 である.FPGAボードを取り付けたホスト計算機を相互接続して図4.3.2の写真に示すようなPC クラスタを構成する. 表4.2: FPGAボードの仕様 Product APX-7142改
FPGA Device Stratix V GX
5SGXMA3K1F40C2N
DRAM DDR3 800 MHz, 2 GB
Flash Storage SAS connecter extends 4 SATA ports TOSHIBA THNSNH060GCST 60GB× 4 Network Proprietary GiGA CHANNEL Optical token ring network 14 Gbps× 2ch
PCIe I/F Gen2× 8 Lane
Internal Bus Proprietary AVAL-bus 256 bits-width, 125MHz
図4.3.1: FPGAボードAPX-7142改
4.4
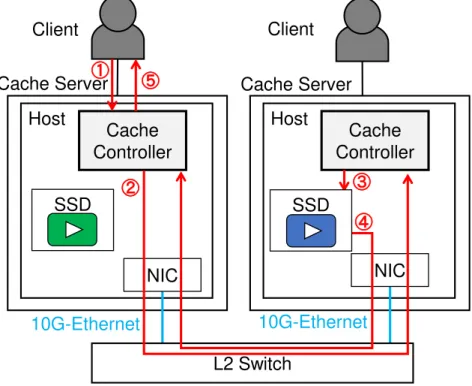
ソフトウェアによる実装
分散協調キャッシュサーバのプロトタイプ実装が先行研究[15]にて行われている.このプロト タイプ実装と同等な処理を行うキャッシュサーバをC++言語を使用して実装を行った.HTTP通信 のライブラリとしてBoostライブラリ[16]に含まれるBeastを使用している.キャッシュサーバ間 の通信は10G-Ethernetを使用する. キャッシュ処理の流れの例を図4.4.1に示す.この例では,緑色の色タグが設定されたのキャッ シュサーバに接続されたクライアントが,青色の色タグをもつキャッシュサーバにキャッシュされ ているコンテンツを取得する例である.図中の番号での処理内容は下記の通りである. 1 O クライアントがキャッシュサーバに対してコンテンツ要求リクエストを送信 2 O 今回は青色のコンテンツが要求されており,サーバの色タグと一致しないため, 他のキャッシュサーバにリクエストを転送 3 O 青色のキャッシュサーバでコンテンツ検索を行い,要求されたコンテンツが格納されていた ため,SSDに読み出し命令を発行 4 O SSDからコンテンツを読み出し,緑色のキャッシュサーバに転送 5 O 緑色のキャッシュサーバがクライアントにコンテンツを転送Client
Host
Cache
Controller
Client
Host
Cache
Controller
10G-Ethernet
10G-Ethernet
NIC
L2 Switch
NIC
Cache Server
①
Cache Server
②
③
④
⑤
SSD
SSD
4.5
SSD
アクセスとノード間通信を
FPGA
オフロードする実装
キャッシュサーバにFPGAボードを接続し,ストレージアクセスとFPGAボード間通信をFPGA
にオフロードする.FPGAボード間通信に使用するGiGA CHANNELは,28Gbpsでの通信が可能
であり,10G-Ethernetより高速に通信可能である.また,FPGAボードに接続されたSSDはスト ライピングによって高速に読み書きが可能である.GiGA CHANNELのプロトコル処理やSSDの SATAプロトコル処理は,FPGA上の専用ハードウェアで実行される. キャッシュ処理の流れの例を図4.5.1に示す.図中の番号での処理内容は下記の通りである. 1 O クライアントがキャッシュサーバに対してコンテンツ要求リクエストを送信 2 O 今回は青色のコンテンツが要求されており,サーバの色タグと一致しないため, FPGAボードの専用ネットワークを用いて他のキャッシュサーバにリクエストを転送 3 O 青色キャッシュサーバのキャッシュコントローラで共有メモリをポーリングし,他ノードか らのリクエストを受信する 4 O ホスト計算機上のキャッシュコントローラでコンテンツ検索を行い,コンテンツが見つかっ たため,FPGA上のSSDにデータ転送命令を発行 5 O FPGAボードに接続されたSSDからコンテンツを読み出し,専用ネットワークにより共有メ モリに転送 6 O FPGAボード上の共有メモリからホスト計算機にコンテンツを転送 7 O ホスト計算機からクライアントにコンテンツを転送 この実装では,サーバ間の通信やストレージアクセスはハードウェアによって処理されるが,コ ンテンツ検索やデータ転送命令などのキャッシュ制御をソフトウェアで行っている.ソフトウェア で制御処理を行うことに加え,ホスト計算機とFPGAボード間での通信も発生するため,オーバ ヘッドが生じる.
GiGA CHANNEL
FPGA
Board
DRAM
NW I/F
Host
FPGA
Board
DRAM
Cache
Controller
NW I/F
Host
Cache
Controller
Client
Client
Cache Server
①
Cache Server
②
⑥
④
③
⑦
DRAM
NW I/F
SSD
SSD
⑤
図4.5.1:実装(2)の処理の流れ4.6
キャッシュ制御を
FPGA
オフロードする実装
実装(2)に加えて,FPGA上でキャッシュ制御の行うためのモジュールHCC(Hardware Cache
Con-troller)を実装する.処理の流れを図4.6.1に示す.図中の番号での処理内容は下記の通りである. 1 O クライアントがキャッシュサーバに対してコンテンツ要求リクエストを送信 2 O 今回は青色のコンテンツが要求されており,サーバの色タグと一致しないため, FPGAボードの専用ネットワークを用いて他のキャッシュサーバにリクエストを転送 3 O 青色キャッシュサーバのFPGA上のHCCでリクエストを受信し,コンテンツが見つかった ため,SSDにデータ転送命令を発行 4 O FPGAボードに接続されたSSDからコンテンツを読み出し,専用ネットワークにより共有メ モリに転送 5 O FPGAボード上の共有メモリからホスト計算機にコンテンツを転送 6 O ホスト計算機からクライアントにコンテンツを転送 この実装では,キャッシュサーバはホスト計算機を経由せず,FPGA上に実装されたHCCによっ てキャッシュ制御処理を行うため,実装(2)に比べてオーバヘッドを削減することができる.
FPGA
Board
DRAM
NW I/F
Host
FPGA
Board
DRAM
Cache
Controller
NW I/F
Host
Cache
Controller
Client
Client
Cache Server
Cache Server
HCC
HCC
GiGA CHANNEL
④
①
②
③
⑥
⑤
SSD
SSD
図4.6.1:実装(3)の処理の流れ4.6.1
FPGA 内のハードウェアの構成
FPGA内部のモジュールの構成を図4.6.2に示す.各モジュールはFPGA内部に構成された
AVAL-BUSSW(クロスポイント・バススイッチ)に接続されている.これらのモジュールのうちHCC及
びSATA I/Fは我々の研究室で実装したものである.その他のモジュールはアバールデータ社のIP
を使用する.
HCCは,Host I/FまたはNW I/Fからリクエストを受信する.リクエストを受信すると,HCCはコ
ンテンツ検索を行い,コンテンツがヒットした場合は,DMAコントローラにDMA(Direct Memory
Accees)転送命令を発行する.DMAコントローラは,SATA I/Fを通じてSSDからコンテンツデー タを読み出し,NW I/FとDRAM I/Fにデータを転送する.NW I/FとDRAM I/Fの両方にデータ
を転送することで全ノードのDRAMにデータが書き込まれる.データ転送が完了またはコンテン
ツミスとなった場合は,DRAM I/FとNW I/Fにレスポンスを送信する.コンテンツデータやレス
ポンスをNW I/FとDRAM I/Fの両方に送信するためにSHRMC(Share Memory Controller)という モジュールを追加している.
また,FPGA上にホスト計算機から書き換え可能なLocal Register が実装されている.Local
RegisterはHCCと接続されており,サーバの色タグ情報などHCCの動作に必要なパラメータを設
定するために使用する.
Host I/F NW I/F DRAM I/F SATA I/F
AVAL-BUSSW Request Path
Response Path Content Data Path
Local Register SHRMC HCC DMA Controller SHRMC 図4.6.2: FPGA内部のモジュール構成
4.6.2
HCC 内部のモジュール構成
HCC内部のモジュール構成を図4.6.3に示す.受信したリクエストはFilter,Search,Transferの
3つのモジュールでパイプライン的に処理される.Filterモジュールでは色タグの検索,Searchモ
ジュールではコンテンツの検索,Transferでは,SSDのデータ転送制御を行う.3つのモジュール
から発行されたレスポンスがResponseモジュールに転送され,各ノードの共有メモリに書き込ま
れる.それぞれのモジュールの間にはFIFOが接続されている.Transferモジュールでは,SSDの
データ転送を行うため,他のモジュールに比べて時間を要する.SSDのデータ転送待ちが発生す
ると,SearchモジュールとTransferモジュールの間のFIFOにリクエストが蓄積される.Filterモ
ジュールやSearchモジュールがResponseモジュールに接続されているため,SSDデータ転送中で
あっても,FilterモジュールやSearchモジュールは次のリクエストのレスポンスを送信することが
できる.
Filterモジュールでは,リクエストに含まれるコンテンツの色タグと予め設定したサーバの色タ
グを比較する.FPGAボードの仕様上,GiGA CHANNELに送信したデータはすべてのノードに
送信される.コンテンツの色とサーバの色が一致しない場合は,コンテンツ検索をする必要がな いため,リクエストを受信した直後にFilterモジュールを使って,コンテンツとサーバの色タグを 比較する.色タグがマッチした場合はコンテンツ検索をするためにSearchモジュールにリクエス トを転送する.マッチしなかった場合はマッチしなかったことを示すレスポンスを発行する. SearchモジュールではコンテンツIDの検索を行う.キャッシュされているコンテンツはBRAM(Block RAM)に記録されている.BRAMはダイレクトマップ方式のキャッシュディレクトリの実装に使 われている.各コンテンツは固有のコンテンツIDが割り当てられている.また,1つのコンテン ツをチャンクと呼ぶ単位に分割して転送制御を行っている.チャンク単位で管理することにより, コンテンツ内の人気シーンのみをキャッシュすることが可能になる.コンテンツをチャンクに分割 し,先頭から番号を振ったチャンク番号とする.コンテンツの検索には,コンテンツIDとチャン ク番号を組み合わせたアドレスを使用する. コンテンツIDの総数が20bit,チャンク番号が8bitである場合の例を示す.コンテンツIDが 12345(16進数),チャンク番号が03(16進数)の場合アドレスは1234503(16進数)となる.ダイレク
トマップのアドレスの割り当てをタグ16bit,インデックス8bit,オフセット4bitとするとき,ア
ドレスとの対応は図4.6.4のようになる.
このアドレスのデータが格納されているときのBRAMとSSDのデータ構造について図4.6.5に
示す.BRAMにはキャッシュされているコンテンツのタグが格納されている.コンテンツ検索時
に,インデックスに対応するBRAMアドレスを参照し,BRAMに対応するタグが格納されている
納されているため,キャッシュヒットとなる.キャッシュヒットした場合は,対応するSSDのアド レスからコンテンツを読み出す.SSDの内部はチャンク毎に領域を区切っており,インデックス とオフセットに対応する領域からコンテンツを取り出す. キャッシュヒットした場合は,Transferモジュールにリクエストを転送する.タグが一致しない 場合はコンテンツミスとなるため,コンテンツミスを表すレスポンスを終了する. Searchモジュールでは,コンテンツ更新リクエストを送ることでコンテンツ更新が可能である. コンテンツを更新する際に,インデックスが競合した場合は新しいものが登録され,古いものが 追い出されLRU(Least Recently Used)による制御となる.
コンテンツヒットした場合はデータ転送を行う.アバールデータ社のIPであるDMACに転送 命令を送ることで,SSDから共有メモリにコンテンツデータの転送をすることができる.
HCC
Search BRAM Response リクエスト FIFO FIFO FIFO FIFO FIFO FIFO レスポンス Matched Unmatched Hit Missed Filter Done DMA Controller Transfer 図4.6.3: HCC内部のモジュール構成1234502
コンテンツID
(20bit)
チャンク番号
(8bit)
タグ
(16bit)
インデックス
(8bit)
オフセット
(4bit)
図4.6.4:ダイレクトマップでのアドレスの対応 BRAM (タグ格納)00
01
︙
50
︙
FF
1234
SSD (チャンクデータ格納)00
01
︙
50
︙
FF
0
1
2
…F
図4.6.5:ダイレクトマップでのBRAMとSSDのデータ構造4.6.3
ホスト計算機でのキャッシュ制御処理
HCCを使った場合のホスト計算機でのキャッシュ制御処理は,ソフトウェアでの制御に比べて 単純になる.HCCは共有メモリを経由して,リクエストとレスポンスの送受信を行う.ホスト計 算機上のキャッシュコントローラは,FPGAボードの共有メモリにリクエストを送信し,レスポン スが書き込まれるまでDRAMをポーリングする.レスポンスが完了し,キャッシュヒットしてい る場合は,コンテンツデータを共有メモリから読み出す.キャッシュ検索やコンテンツ転送,ノー ド間通信は,FPGAボード側で行われる. リクエストには,コンテンツID,チャンク番号,色ビット,送信元ノードID,リクエスト番号, チャンクサイズ,コンテンツ格納DRAMアドレスが含まれる.レスポンスには,コンテンツサイ ズ,検索結果,完了フラグが含まれる. レスポンスは共有メモリに書き込まれる.共有メモリは,すべてのノードで共有されるため,同 じアドレスに書き込むとデータが上書きされる.そこで,リクエスト送信ノードID,リクエスト 番号,レスポンス送信ノードIDによってレスポンスを書き込む共有メモリのアドレスを変える実 装をしている.このような実装を行うことで,複数のノードが同時にリクエストを送ってもレス ポンスのアドレスが競合しない.また,リクエスト番号を変えてリクエストを送ることで,1つの ノードが複数のリクエストを送ってもレスポンスのアドレスが競合しない.同時に送られたリク エストは,HCCのFIFOに蓄積され,順に処理される.4.7
DRAM
をキャッシュ領域として使用する実装
実装(3)では,FPGAボードに接続されたSSDをキャッシュ領域として使用している.FPGAボー ドにはDRAMが搭載されており,現在共有メモリとして使用している.DRAMはSSDに比べて 容量は小さいが高速にアクセス可能である.DRAMの容量は限られているため,人気度の高いチャ ンクを保持することで,効率的なコンテンツ転送を行うことができる. このDRAMの一部をキャッシュ領域として使用する実装を行った.キャッシュ領域として使用す るDRAMの領域は共有メモリとしては使わず,それぞれのノードで別のコンテンツを保存する. DRAMキャッシュを実装した場合のHCC内部のモジュール構成を図4.7.1に示す.SSD用とDRAM用の2つのTransferモジュールを実装し,Searchモジュールの検索結果によって使用する
転送モジュールを選択する.Searchモジュールでは,SSD用のBRAMとDRAM用のBRAMの
両方を同時に検索し,DRAMにヒットした場合は,DRAMモジュールにリクエストを転送する. SSDのみにヒットした場合はSSD用モジュールにリクエストを転送する. キャッシュ更新時は,ライトスルー方式でDRAMとSSDの両方にコンテンツを書き込む.この ような実装をすることでDRAMでキャッシュが追い出された場合でも,SSDからキャッシュを取 り出すことが可能となる.
HCC
Search BRAM Response リクエスト FIFO FIFO FIFO FIFO FIFO FIFO レスポンス Matched Unmatched Hit Missed Filter Done DMA Controller Transfer (DRAM) FIFO Hit Transfer (SSD) FIFO DMA Controller Done 図4.7.1: DRAMキャッシュ実装時のHCC内部のモジュール構成第
5
章
評価
5.1
計算機環境
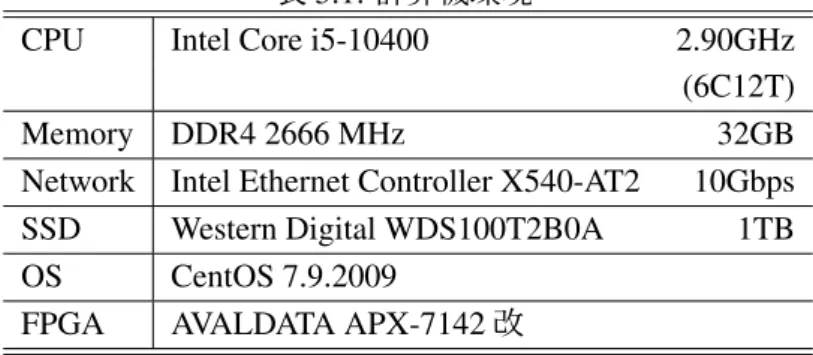
本研究で使用したFPGAをボードと計算機の仕様をそれぞれ表4.2,表5.1に示す.
表5.1:計算機環境
CPU Intel Core i5-10400 2.90GHz
(6C12T)
Memory DDR4 2666 MHz 32GB
Network Intel Ethernet Controller X540-AT2 10Gbps SSD Western Digital WDS100T2B0A 1TB OS CentOS 7.9.2009
5.2
レイテンシ評価
5.2.1
レイテンシ測定手法
本研究では,無負荷レイテンシの測定を行った.無負荷レイテンシは,リクエストを1回だけ 発生させたときのレイテンシである.リクエスト数が増加し,サーバへの負荷が増加すると,レ イテンシは増加する.そのため,無負荷レイテンシはレイテンシの下限である. リクエストを送信してから最初のコンテンツデータが返ってくるまでのレイテンシを測定した. レイテンシが小さいほど,最初のデータを速く入手することができ,速く再生し始めることがで きる. レイテンシの評価では,2台のマシンを使用し,それぞれクライアントとキャッシュサーバとす る.処理の流れを図5.2.1に示す.クライアントはキャッシュサーバに対して,コンテンツを要求 する.キャッシュサーバは,コンテンツの色タグを判別し,コンテンツIDを検索し,コンテンツ データの転送を行う. クライアント側では,リクエストを送信してからコンテンツデータの最初の1バイトを受信す るまでの時間を測定する.サーバ側では,リクエストを受信してからコンテンツデータの最初の1 バイトを送信するまでの時間を測定する.この2つの時間の差分を求めることで通信による遅延 を測定する. ホストPC上のソフトウェアでのレイテンシ測定は,処理実行前と実行後の時刻の差分を算出 して行った.FPGA上のモジュールのレイテンシ測定は,FPGA上にクロックカウンタを実装し,Signal Tap II Logic Analyzerと呼ばれる実機で動作している回路の波形を観測するツールを用いて, 処理が終わるまでの時間を調べた. クライアント キャッシュサーバ リクエスト 色タグ検索 コンテンツ転送 コンテンツID検索 コンテンツデータ
①
②
③
④
リクエスト送信 コンテンツ受信 図5.2.1: レイテンシの測定の流れ5.2.2
無負荷レイテンシ測定結果
実装(1)から実装(4)において測定した無負荷レイテンシの測定結果を図5.2.2に示す. ソフトウェア実装では,クライアントでの遅延は626µsとなり,サーバでの遅延は80µsとなっ た.通信プロトコル処理を含むEthernet通信による遅延は546µsとなり,測定した遅延の大部分 を占める. 実装(2)の場合は,全体の遅延は272µsとなった.サーバ側の遅延は146µsと実装(1)より増加 している.これは,ソフトウェアでキャッシュ制御をしており,コンテンツデータの読み出しには ホストPC側からFPGAボード上のSSDに対して命令を送る処理が発生するためオーバヘッドが 生じている.通信の遅延時間に関しては,FPGAボード間の専用ネットワークを使用することで, 減少している. 実装(3)では,全体の遅延時間は154µsに短縮された.サーバでの処理遅延,通信での遅延とも に短縮されている.サーバ側での処理時間98µsのほとんどは転送処理にかかる時間である.転送 処理にかかる時間は,SSDに対して転送命令を発行し,最初のデータがNW I/Fに入力されるまで の時間である. 実装(4)では,全体の遅延時間は70µsとなった.コンテンツデータをDRAMから取り出すこと で,サーバ側の転送処理時間が0.67µsと大幅に減少し,サーバ側での処理遅延は0.80µsとなった. また,実装(3),実装(4)においてクライアント側とキャッシュサーバ側のFPGAボード間のNW I/Fによる遅延は約4µsとなり非常に低遅延であることを確認した. 0 100 200 300 400 500 600 700 ④FPGA(NW+DRAM+HCC) ③FPGA(NW+SSD+HCC) ②FPGA(NW+SSD) ①Software コンテンツ取得のレイテンシ [μs] サーバ処理遅延 通信遅延 図5.2.2:無負荷レイテンシの測定結果Host PC Host PC Cache Controller クライアント 10G-Ethernet SSD キャッシュサーバ HTTP
Client NIC NIC
リクエスト コンテンツ ① ② 色検索 ③ ID検索 ④ 転送処理 ⑤ ⑥ クライアント遅延:
626μs (①to⑥) サーバでの遅延(②to⑤):80μs色検索:0.8μs (②to③) ID検索:23μs (③to④) 転送処理:57μs (④to⑤) 図5.2.3:実装(1)のレイテンシ Host PC Cache Controller FPGA Board DRAM HCC SSD GiGA CHANNEL クライアント NW I/F Host PC FPGA Board DRAM SSD キャッシュサーバ NW I/F ① ⑤ ⑥ クライアント遅延: 272μs (①to⑥) サーバ処理遅延:146μs (②to⑤) 色検索:1μs (②to③) ID検索:23μs (③to④) 転送処理:122μs (④to⑤) Cache Controller ② ③ ④ 色検索 ID検索 転送処理 図5.2.4:実装(2)のレイテンシ
Host PC Cache Controller FPGA Board DRAM HCC SSD GiGA CHANNEL クライアント NW I/F Host PC FPGA Board DRAM SSD キャッシュサーバA NW I/F HCC
Filter Search Transfer ① ② ⑦ ⑥ ③ ④ ⑤ ⑧ クライアント遅延: 154μs (①to⑧) サーバ処理遅延:98μs (③to⑥) 色検索:0.04μs (③to④) ID検索:0.09μs (④to⑤) 転送処理:98μs (⑤to⑥) クライアント側FPGA遅延: 102us (②to⑦) 図5.2.5:実装(3)のレイテンシ Host PC Cache Controller FPGA Board DRAM HCC SSD GiGA CHANNEL クライアント NW I/F Host PC FPGA Board DRAM SSD キャッシュサーバA NW I/F HCC
Filter Search Transfer ① ② ⑦ ⑥ ③ ④ ⑤ ⑧ クライアント遅延: 70μs (①to⑧) サーバ処理遅延:0.80μs (③to⑥) 色検索:0.04μs (③to④) ID検索:0.09μs (④to⑤) 転送処理:0.67μs (⑤to⑥) クライアント側FPGA遅延: 3.9us (②to⑦) 図5.2.6:実装(4)のレイテンシ
5.3
スループット評価
コンテンツをチャンクに分割し,チャンク単位でコンテンツ要求リクエストを送ったときのス ループットを測定した.1コンテンツあたりのキャッシュ容量は,512MBと設定した.動画配信サー ビスYouTubeの動画の長さを調査した論文では,ほとんどの動画が15分以内にであるという調査 結果がある[17].また,YouTubeの画質毎のビットレートを調査した論文では,Full HD(1080p)の MP4形式の動画のビットレートは3.7Mbps程度であるという調査結果が出ている[18].3.7Mbps のビットレートの15分の動画サイズは約416MBである.4K動画などさらに高解像度の動画や長 時間の動画ではさらに動画サイズが大きくなるが,今回は1コンテンツあたりのキャッシュサイズ を512MBに設定した.また,チャンクサイズは4MBに設定した. 512MBのコンテンツのすべてのチャンクがキャッシュされており,先頭からすべてのチャンク を取得するときのスループットを図5.3.1に示す. 実装(1)でのスループットは,1049MB/sとなった.使用しているSSDの読み出しスループットは 約560MB/sだが,それを上回っている.これは,OS側でSSDのストレージのデータがDRAM上 にキャッシュされ,DRAMから読み出しされているためである.実装(1)において,OSのDRAM キャッシュクリアを実行し,SSDからコンテンツを転送した場合のスループットは501MB/sと なった. 実装(2)では,転送スループットは,709MB/sとなり,実装(3)では1068MB/sとなった.FPGA ボードに接続したSSDの読み出しスループットは約1100MB/sとなっており,その値に近いスルー プットが出ることを確認した.実装(2)で,転送スループットが709MB/s程度になる原因として は,SSDから共有メモリに転送する処理と共有メモリからホストPCに転送する処理がパイプラ イン化されていないからである.HCCでは複数のリクエストを逐次処理することによって,HCC によるSSDのデータ読み出しとホストPCによる共有メモリの読み出しを同時の行うことができ るため,スループットが向上する.5.4
リソース評価
実装(4)におけるFPGAのリソース使用量を表5.2に示す.リソース使用量はIntel社のFPGA
設計・開発ソフトウェアであるQuartusを用いて調べた.FPGA全体のロジック使用量は64%であ
り,そのうちHCCで使用している使用量は16%である.BRAMの使用量もFPGA全体で28%で,
そのうちHCCで使用している使用量は2.4%となっている.リソース使用量には余裕があるため,
1049 501 709 1068 0 200 400 600 800 1000 1200 ①Software w/ DRAM cache ①Software w/o DRAM cache
②FPGA(NW+SSD) ③FPGA(NW+SSD+HCC) 転送スループット [MB/ s] 図5.3.1: 512MB転送時のスループット測定結果 表5.2: FPGAのリソース使用量 Capacity Total HCC Logic utilization 128300 82425 (64%) 1264.5 (16%) Block RAM [Kbit] 19140 5445.7 (28%) 461.8 (2.4%)
第
6
章
結論
本研究では,分散協調キャッシュサーバの処理の一部をInterconnected-FPGAsを使用し,専用 ハードウェアによってオフロードすることで無負荷レイテンシが短縮されることを確認した.FPGA 上でキャッシュ制御を行うHCCというモジュールを実装し,FPGAボード間の専用ネットワーク とFPGAボード直結のSSDを使用することで,ソフトウェアによる実装と比べてレイテンシを約 75%削減されることを確認した.さらに,FPGAボード上のDRAMをキャッシュ領域として使用 することで,ソフトウェア実装に比べてレイテンシが約89%削減されることを確認した. 5Gなどの低遅延なネットワークを使用した場合で経路上のキャッシュサーバでの遅延が大きい 場合,低遅延なネットワークの意味がなくなってしまう.通信経路上に存在するキャッシュサーバ での処理が低遅延化されることで,クライアントがコンテンツを取得する時間が短縮され,通信 の品質が向上する. 現在のキャッシュ検索処理はダイレクトマップとLRUを用いているため,コンテンツ更新時は 必ず古いものが追い出される.今後,コンテンツのアクセス頻度を用いたLFUなど,他の検索ア ルゴリズムや追い出しアルゴリズムの実装について検討する.また,今後の課題として,複数分 散協調キャッシュサーバで構成するより大きなネットワークでの実験や平均レイテンシの評価が挙 げられる.謝辞
本研究を進めるにあたり,熱心なご指導を頂きました吉永努教授に深く感謝申し上げます. 本研究の一部は,電気通信大学とTIS株式会社による共同研究課題「超スマート社会のための 高効率ネットワーク技術の研究開発」の支援を受けて行われました.研究に関してご指摘くださ いましたTIS株式会社の吉見真聡氏に深く感謝いたします. 最後に,研究について様々な指摘や議論,ご協力をくださいました吉永・策力木格研究室の皆 様に厚く御礼申し上げます.参考文献
[1] Cisco annual internet report (2018–2023).
https://www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/ white-paper-c11-741490.pdf, Accessed 2021-01-22.
[2] Takuma Nakajima, Masato Yoshimi, Celimuge Wu, and Tsutomu Yoshinaga. Color-Based Coop-erative Cache and Its Routing Scheme for Telco-CDNs. IEICE Transactions on Information and
Systems, Vol. E100.D, No. 12, pp. 2847–2856, December 2017.
[3] M. Yoshimi, R. Kudo, Y. Oge, Y. Terada, H. Irie, and T. Yoshinaga. Accelerating olap workload on interconnected fpgas with flash storage. In 2014 Second International Symposium on Computing
and Networking, pp. 440–446, 2014.
[4] Zhan Wang, Hai Jiang, Yi Sun, Jun Li, Jing Liu, and E. Dutkiewicz. A k-coordinated decentralized replica placement algorithm for the ring-based CDN-P2p architecture. In The IEEE symposium on
Computers and Communications, pp. 811–816, June 2010.
[5] Z. Li and G. Simon. In a Telco-CDN, Pushing Content Makes Sense. IEEE Transactions on
Network and Service Management, Vol. 10, No. 3, pp. 300–311, September 2013.
[6] 岡田浩希,城間隆行,中島拓真,策力木格,吉永努. チャンク分割コンテンツ配置を用いた分散
協調色キャッシュ. 信学技報, Vol. 117, No. 314, pp. 3–8, November 2017.
[7] J. Cai, X. Wu, Y. Liu, J. Luo, and L. Liao. Network coding-based socially-aware caching strategy in d2d. IEEE Access, Vol. 8, pp. 12784–12795, 2020.
[8] H. Nam, K. Kim, and H. Schulzrinne. Qoe matters more than qos: Why people stop watching cat videos. In IEEE INFOCOM 2016 - The 35th Annual IEEE International Conference on Computer
Communications, pp. 1–9, 2016.
[9] Michaela Blott, Kimon Karras, Ling Liu, Kees Vissers, Jeremia B¨ar, and Zsolt Istv´an. Achieving 10gbps line-rate key-value stores with fpgas. In 5th USENIX Workshop on Hot Topics in Cloud
[10] Jaeyoung Do, Yang-Suk Kee, Jignesh M. Patel, Chanik Park, Kwanghyun Park, and David J. De-Witt. Query processing on smart ssds: Opportunities and challenges. In Proceedings of the 2013
ACM SIGMOD International Conference on Management of Data, SIGMOD ’13, p. 1221–1230,
New York, NY, USA, 2013. Association for Computing Machinery.
[11] Andrew Putnam and et al. A reconfigurable fabric for accelerating large-scale datacenter services.
SIGARCH Comput. Archit. News, Vol. 42, No. 3, p. 13–24, June 2014.
[12] 飯塚健介,天野英晴. Alexnetのマルチfpgaシステムへの分割検討と実装. 信学技報, Vol. 119, No. 147, pp. 91–95, July 2019.
[13] 川原尚人,吉見真聡, 策力木格,吉永努. ネットワーク結合型マルチFPGAボードを用いた集
約演算クエリ処理. 電子情報通信学会技術研究報告;信学技報, Vol. 116, No. 240, pp. 29–34, September 2016.
[14] APX-7142. https://www.avaldata.co.jp/products/network/item/apx-7142, Accessed 2021-01-22.
[15] 中島拓真,岡田浩希,策力木格,吉永努. 色タグ情報に基づく分散協調キャッシュおよびチャン
ク分割キャッシュ制御のプロトタイプの実装. 信学技報, Vol. 117, No. 314, pp. 9–14, November 2017.
[16] Boost c++ libraries. https://www.boost.org/, Accessed 2021-01-24.
[17] X. Che, B. Ip, and L. Lin. A survey of current youtube video characteristics. IEEE MultiMedia, Vol. 22, No. 2, pp. 56–63, 2015.
[18] K. Ragimova, V. Loginov, and E. Khorov. Analysis of youtube dash traffic. In 2019 IEEE
In-ternational Black Sea Conference on Communications and Networking (BlackSeaCom), pp. 1–5,
発表論文
[1] 山岸徹平,吉見真聡,策力木格,吉永努“ 分散協調キャッシュサーバ処理のFPGAオフロード,”