Speaker Verification with Non-Audible Murmur Segments
4
0
0
全文
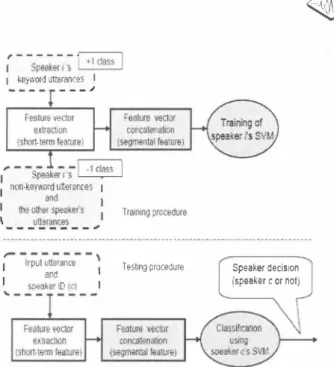
(2) INTERSPEECH 2006. -. ICSLP. ゆ ' -- -. ιflî電通、. -:- -^ Speaier i 5. j. ss I LーよよニニニJ +l cla. I keyw出4国tarances 1 ーーーー- --ー'. J hぶ … 一. ,. -- ・・曲・・-. 1. 1 Spaaker;-5 Lーιニ;ニニ:...J 1 non-keyw�� ti立erances 1 目 and. I I仇he日01酌h叫剖叫k的 Tf悶 mn川pr悶dωure 陀 . \ uJ凶tt旬er陪an児c臼es , I. - 1c 出s. ;. ,園田園圃圃圃幽園、. I. 1 れDpUu Il uneran u er ancce e tt. ._,. I. Testlng抑制u陪. � n � A���' r. II ID Ic1 speaker 、ーーーーーーーー. 11. Spea鳩r decision fspea同r C or nolj. ë'. -←十一一同. Figure 3: method.. Training and testing proc巴dures of the SVM-based. H-. Figure 1: Comparison of spec甘ograms and waveforms of normal speech(top)如d NAM(bottom).. term feature vectors extracted from the training utterances. The concatenation is assumed to represent keyword-speci白c acoustic features well. In testing as in 仕aining, concatenations of n short term feature vectors are made for each utterance and used as in put vectors. SV恥1 gives a con白dence index for each input vector, which is called the 'margin'. The confid巴nc巴 index averaged over the test utterance is compared with a threshold to judge spe討cer identity.. 3. Experiments. 3.1. Data description and experimental conditions. The NAM data was collected for 19 male and 10 female speakers who uttered keyword phrases. Each keyword phrase was a concatenation of two place names of Japanese prefectures (e.g., “To匂o-Saitama " and “ Kyoto-N訂正'). The u町rances were recorded at the sampling rate of 16 kHz in three sessions over a six month period. The interval between sessions was three months. In each session,巴ach speaker uttered her/his own keyword 16 times and uttered 30 keywords of other spe討cers twice. A Mel frequency ceps廿al coefficient (MFCC) vector of 31 components, consisting of 15 MFCCs plus th巴江 自rst derivatives and the 白rst derivative of the normalized log energy, was derived once every 10 ms over a 25-ms Hamming-windowed speech segment. Cepstrum mean nor malization was applied. The仕aining data set of each speaker was composed of the data u口ered by speakers of the same gender in two sessions. The data for each session consisted of 10 keywords for the +1 class and 30 non-keyword u口eranc巴s of th巴 spe心cer and utterances of the other sp巴akers for the -1 class(in d巴tail,190 utterances of the other male spe紘ers when the speはer was male and 90 utterances of the other. We conducted speaker verification experiments using keyword utterances and confirmed the 巴ffectiveness of NAM segment input. We also evaluated the robustness against session-to-session varia tions by comparing the performances of our SVM-based method with the conventional GMM-based method. female speakers when the speaker was female) In testing, we used keyword utterances uttered in a sessi on that was different from the training sessions. The test data set for each speaker consisted of 6 keyword utterances of the speaker and non-keyword u悦erances of the other speakers(in detail. 114 non keyword u口erances of the other male speakers when the speaker was male and 54 non-keyword utterances of the other female spe必匂rs when the spe必cer was female). The former utterances should be accepted and the la口er ones should be r句ected as false statements. The threshold for speaker decision was speaker de pendent and set a posteriori. Thus. all evaluations were gender dependent. For SVM. we used SVM1ight which is a toolkit provided by. ーーー・ . .. Figure 2: NAM microphone and its attachment method.. Cornell University [7]. The polynomial kernel function (1) was. 2115. 司i r「u.
(3) INTERSPEECH 2006 - ICSLP. � us巴d.. k(x,y). = (x!y+l)". (EERs) were 0.04% for male speakers and 1 . 1 % for female speak ers. These values are roughly 1/20 and 1/2 of those for male and fe male speakers,respectively, with 25-ms-Iong segments. These re sults indicate that 145-ms-Iong segments can efficiently represent both speaker- and keyword-speci白c acoustic features and that the performance is higher for text-dependent ve目白cation using key words.. (1). The power was chosen to be s = 7. To enable us to perfoπn effective computation with 64-bit precision, the data was so scaled that all the elements of feature vectors lay in the interval [-0.5,0.5]. In the GMM-based method, we used HTK(ver3.2), which is a toolkit provided by Cambridge University[8]. A GMM was made for each spe広er using the keyword utterances of the speaker. Then, we made a universal-background GMM using all keyword u目erances of all speakers to normalize the likelihood values of the speはer GMM[9J. 80th GMMs w巴re 32-Gaussian-mixture diago nal covariance mod巴Is, because those models showed the best per formance in preliminary experiments using 32- and 64-Gaussian mixture models. The collective log-likelihood ratio between the speaker and the universal-background GMMs was compared with a threshold to judge speaker identity.. 3.3. Training over muItiple sessions. Table 1 comp紅白the EERs for the SVM- and GMM-based methods when training data recorded in two sessions and one ses sion, respectively, was used. As input vectors, 25-ms-Iong short term feature v巴ctors were used. Table 1: EERs (%) for SVM- and GMM-based methods with train ing data recorded in one and two sessions (M: EER for male speak ers,F: EER for female speakers). 3.2. Use of NAM segments. Method SVM GMM. Figures 4 and 5 show the detection e汀or tradeoff (DET) curves piled and averaged over male and female speakers with NAM seg ments with lengths of 25 ms (one short-term feature vector), 45 ms (three vectors), 85 ms (7 vectors),and 145 ms (13 vectors).. 一jEER 11% 45円、s IEER: 1.1%) 85 ms (EER: 0. 4% 145 ms (EER: 0.0%). 0.15. 2 8. I. I I. 2 se凶削5 l . l (M), 2.2 (F) 3.9 (M), 5.2 (F). For the SVM-based method, the EERs were greatly reduced by using training data recorded in two sessions. Whe口紅創ning data recorded in one session was used, the SVM-based method per foロned as weJl as or slightly better than the GMM-based method. This result indicates that for the SVM-based method using NAM, session-independent speaker-specific acoustic features can be ef fectively captured by using training data recorded in multiple ses slOns.. j -ーーーーーー. 0.25. l session 6 9 (M), 8.9 (F) 8.8 (M), 18.0 (F). 0.1. 4. Discussion 0.05. 。. 立. 一一干�. o. T. 0.05. 4.1. Effect of the first derivatives of MFCCs. 、. 』一一一一 一 一 0.1. 0.1 5. 0.2. In the experiments, NAM segments were created by concate nating several short-term feature vectors consisting of 15 MFCCs plus their自rst derivativ巴s and the first derivative of the noπnaliz巴d log energy. However, one may consider that 出e segments incJuded information about the first derivatives of MFCCs (ムMFCCs) com puted in terms of five successive MFCC vectors. Th巴refore, we conducted experiments using a NAM segment of a concatenation of several feature vectors consisting of only 15 MFCCs and exam ined the effect of .t.MFCCs Table 2 lists the EERs with and without .ó.MFCCs for NAM segments of various len♂hs. With .ó.MFCCs, the numbers of di mensions of NAM segment vectors with lengths of 25,45, 85,釦d 145 ms were 31, 93, 217,初d 403 (=31 dim. x13 vectors), respec tively. Without ð.MFCCs, 出e numbers of dimensions of NAM segment vectors with lengths of 45, 85, and 145 ms were 45, 105, and 195 (=15 dim. x13 vectors), respectively. Although the EERs withムMFCCs were slightly better than those without ð.MFCCs, the difference in the EERs was rather small. On the other hand, when ムMFCCs are us巴d,the cost of SVM calculation is almost double. In limited computational environments, it may not be nec essary to involveムMFCCs in NAM segments. 0.25. False alarm probability. Figure 4: DET curves piled and averaged over male spe必cers.. 。. 。. 0.05. 0.1. 0.15. 0.2. 0.25. False alarm probability. Figure 5: DET curves piled and averaged over female spe必cers 4.2. Effect of keywords. In speaker verification using NAM data, keyword utterances can be utiliz巴d safely because NAM is inaudible,. Therefore, our method was evaluated using non-keyword utterances uttered by. As the segment length became longer, the verification p巴rfor mance b巴came better. The best result was obtained with 145-ms long segments, for which the mean values of the equal e打or rates. 2116. 。。 「hu.
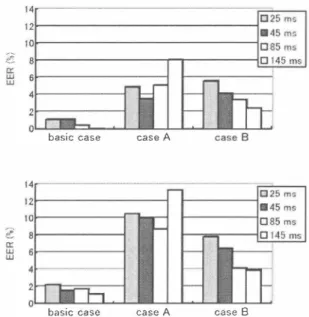
(4) INTERSPEECH 2006 - ICSLP. ゆ 5. Conclusions. Tab1e 2: EERs (%) with and withoutムMFCCs (M: EER for ma1e speakers, F: EER for fema1e speakers) Segment 1ength 25 ms 45 ms 85 ms 145 ms. We investigated speaker veri自cation using NAM segments, which enable us to take a text-depend巴nt ven白catlOn strategy us ing a keyword phrase. The proposed method with long ( l 45-ms) segments was found to be e仔巴ctive, especia1ly when using train ing data uttered in two sessions, and reduced the EERs to half or less those obtained with the method using short (25-ms) seg ments. We discussed the effect ofムMFCCs and showed that long segments can represent almost the sam巴 information inムMFCCs and that NAM segments can b巴 constructed with on1y MFCCs in env江onments where computational resources are limited. More over, the effectiveness of keywords was demonstrated for several cases of fa1se utterances. If impersonation is of prime importance, medium-length segments (from 45 to 85 ms) shou1d be selected as input vectors. lf incorrect keywords are of prime importance, longer segments (e.g., 145 ms) are more suitable. We p1an to conduct experiments using data recorded in a larger numbers of sessions and eva1uate our method in practice by using data utt巴red by impostors who were not used to train the sp巴aker SVM. Since NAM data inc1udes internal body sounds such as heart beats, which contain person-specific information, we will investi gate new effective features of the interna1 sounds.. withムMFCCs I withoutムMFCC 1 . 1 (M), 2.2 (F) 1.5 (M), 2.9 (F) 1 . 1 (M), 1.5 (F) 0.4 (M), 1.7 (F) 0.7 (M), 1.1 (F) 0.0 (M), 1 . 1 (F) 0.0 (M), 1 . 1 (F). oth巴r spe心(ers as false utterances (“basic case "). To examine the effect of using keywords, we conducted experiments using the fo110wing sets of fals巴U伐erances. basic case: case A: case B:. non-keyword utterances uttered by other speはers keyword u口巴ranc巴s uttered by other sp巴akers [impersonation] non-keyword u口erances uttered by the (claimed) speaker [inco汀ect keywords]. Figure 6 shows the EERs in the basic case and in cases A and B for ma1e and female speakers. The EERs in the basic case were much smaller than those in cases A and B for various NAM seg m巴nt 1engths. As the 1ength became 10nger, the EERs in case A increased while those in case B decreased. These resu1ts con自rm the e仔ectiveness of the strategy in which keywords are availab1e. W hi1e longer segments are e仔巴ctive for distinguishing different keyword utterances, the discriminative power on the same key word utterances by different speakers decreases. lf case A is of prime importance, segments of medium length from 45 to 85 ms shou1d be sel巴cted as input vectors. If case B is of prime impor tance, longer (e.g., 145-ms) segments are more suitable.. 6. References [1] http://www.nist.gov/sp巴echltests/spklindex.htm, Speaker Recognition Evaluations.. NIST. [2] D. A. Reynolds, “'An Overview of Automatic Speaker Recog nition Techno10gy, " In Proc. Internationa1 Conference on Acoustics, Speech, and Signa1 Processing in Orlando, FL, IEEE, pp. IV: 4072-4075, 2002. [3] Y. N心E勾ima, H. Kashioka, N. Campbell, K. Shikano, "Non Audible Murmur (NAM) Recognition, " IEICE Trans. Infor mation and Systems, Vol. E89-D, No. 1, pp目ト8, 2006.. 、 ・p d p 刷 、. [4] M. Kojima, H. Kawanami, H. Saruwatari, T. Matsui and K. Shikano, “Speak巴r Verification using Non-Audib1e Murmur, " In Proc. Symposium on Cryptography and Information Secu rity (SCIS1906), 2D1-4, 2006 (in Japanese).. basic. case. case. [5] A. Waibe1, T. Hanazawa, G. Hinton, K. Shikano, K. Lang, “Phoneme Recognition Using Time-De1ay Neura1 Networks, " IEEE Trans. ASSP, Vol. 37, No. 03, pp. 328-339, 1989. . [6] V. N. Vapnik, ‘The Nature of Statistica1 Learning Theory,". A. Springer, 1995 l7] Thorsten Joachims: SV M1ight Support Vector Machine, Version 6.01, http://www.cs.comell.eduIPeop1e/tjlsvm_light/ index.html, Cornell University, Department of Computer Science. 2004. }r、 .1". [8] http://htk.eng.cam.ac.ukl, Toolkit (HTK). basic case. case. A. The. Hidden. Markov. Mode1. [9] T. Matsui and S. F町Ul, “A simi1arity normalization method for speaker veri白cation bas巴d on a posteriori probabiト ity, " ESCA Tutorial and Research Workshop on Automatic Sp巴必cer Recognition Identi白cation Veri白cation, pp. 59-62, 1 994.. case B. Figure 6: Ma1e (top) and female (bottom) speakers' EERs (%) in several cases for false utterances: basic case with non-keyword ut terances of other spe必cers, case A with keyword utterances of other spe必cers, and case B with non-keyword utterances of the spe心cer.. nHd Fhu -ai. 2117.
(5)
図

関連したドキュメント
Effect of gemcitabine on the expression of apoptosis-related genes in human pancreatic cancer cells.
reported that gemcitabine-mediated apoptosis is caspase- dependent in pancreatic cancers; Jones et al [14] showed that gemcitabine-induced apoptosis is achieved through the
We concluded that the false alarm rate for short term visual memory increases in the elderly, but it decreases when recognition judgments can be made based on familiarity.. Key
patient with apraxia of speech -A preliminary case report-, Annual Bulletin, RILP, Univ.. J.: Apraxia of speech in patients with Broca's aphasia ; A
They contain examples of real analytic foliations of codimension 2 on closed manifolds of any given dimension greater than 2 such that B 1 consists of finitely many compact leaves,
4.3. We now recall, and to some extent update, the theory of familial 2-functors from [34]. Intuitively, a familial 2-functor is one that is compatible in an appropriate sense with
Correspondence should be addressed to Salah Badraoui, [email protected] Received 11 July 2009; Accepted 5 January 2010.. Academic Editor:
We find the criteria for the solvability of the operator equation AX − XB = C, where A, B , and C are unbounded operators, and use the result to show existence and regularity
In the previous discussions, we have found necessary and sufficient conditions for the existence of traveling waves with arbitrarily given least spatial periods and least temporal
