1
コンピュータ囲碁を用いた
思考の可視化に関する研究
Pang Yuanfeng
電気通信大学大学院 情報理工学研究科
情報・ネットワーク工学専攻
博士(工学)学位申請論文
2021 年 3 月
2
コンピュータ囲碁を用いた
思考の可視化に関する研究
博士論文審査委員会
主査 伊藤 毅志 准教授
委員 小林 聡 教授
委員 村松 正和 教授
委員 中山 泰一 教授
委員 保木 邦仁 准教授
委員 池田 心 准教授
3
Abstract
It has been pointed out that there is a big difference between the thinking
process of game program and human, and that humans cannot easily
understand the game program. Therefore, in this paper, we conducted two
different visualization studies.
The first visualization study focuses on helping humans' understanding. In
the recognition and learning of Go, Go terms play important roles. However,
it is a big burden for beginners to memorize these terms. In this research, we
propose a system for automatic display of Go terms corresponding to game
records. In order to identify the terms, it needs to recognize not only the
"placement" of stones but also the combination of knowledge including the
"momentum" of stones. We implemented them by using the Go program "Ray".
We have realized a system that automatically displays the relatively
frequently used terms. When the performance of the system was evaluated
by a professional player, it showed a high matching rate over 90% against the
judgment of a professional shogi player.
The second visualization study focuses on understanding the thinking process
of artificial intelligence. Deep learning for the game of Go achieved
considerable success with the victory of AlphaGo against Ke Jie in May 2017.
Thus far, there is no clear understanding of why deep learning performed so
well in the game of Go. In this paper, we introduce visualization techniques
used in image recognition that provide insights into the function of
intermediate layers and the operation of the Go policy network. When used
as a diagnostic tool, these visualizations enable us to understand what occur
s during the training process of policy networks. Further, we introduce a
visualization technique that performs a sensitivity analysis of the classifier
output by occluding portions of the input Go board, and revealing parts that
important for predicting the next move. Further, we attempt to identify
important areas through Grad-CAM and combine it with the Go board to
provide explanations for next move decisions.
4
要旨
囲碁は探索空間が膨大であるばかりか局面の認識が難しく評価関数の作成が困難で あるため,これをプレイする囲碁プログラムの発展は他のゲームに比べ大きく遅れて いた.90 年代以降,ニューラルネットワークなどの様々な学習技術も試みられてきた が2000 年以降に渡り顕著な進歩は見られなかった.2006 年に提案されたモンテカル ロ木探索の手法は,この分野における大きなブレークスルーとなり,置碁ではあるが プロ棋士と良い勝負をするレベルにまでになった.その後2014 年頃まで,徐々に強 くはなってきていたものの,人間のトップ棋士を超えるレベルに至るにはさらなる技 術革新が必要であると思われてきた.2015 年以降,深層学習を用いた囲碁の手の予測 に関する研究が散見されるようになり,2016 年に DeepMind 社が開発した深層学習 と強化学習手法を用いたアルファ碁(英: AlphaGo)という囲碁プログラムが登場する と,事態は一変する.それまでの囲碁プログラムは,当時最強と言われたものでも, プロ棋士に対して3 子~4子程度の棋力差があったが,AlphaGo は,欧州囲碁選手権 を3 連覇した樊麾二段と対局し,一気に 5 戦全勝を収めた.囲碁の世界でコンピュー タ囲碁がプロ棋士に互先で勝利を収めたのは史上初である.その後,2017 年には,よ り進化したAlphaGo が当時の世界チャンピオンである柯潔九段に勝利したばかりか, 「人間の棋譜を一切使わず,ルールだけを教えられた状態」からコンピュータ囲碁を 強くする手法を用いて,さらに棋力の高いとされるアルファ碁ゼロ(英: AlphaGo Zero)を発表した.これが囲碁界に与えた衝撃は大きく,近年のゲームプログラムの 技術は,深層学習をともなう機械学習を利用した手法が主流となっている.このよう に,機械学習の導入とコンピュータの計算能力の向上に伴い,多くのゲームにおい て,人間を超えるという目標は達成されるようになった. しかし,ゲームプログラムと人間の思考過程には大きな違いがあり,ゲームプログ ラムの考えていることを人間が簡単には理解できないという問題が指摘されている.5 そこで,本研究では,コンピュータ囲碁の思考過程の理解を助けるための可視化につ いて,2 つの異なる研究を行った. 一つ目は,囲碁用語に着目した研究である.囲碁の認知科学的研究から,囲碁の知 識の理解や学習において,囲碁用語が果たしている役割が大きいことは指摘されてき た.しかし初学者が囲碁用語を覚えることは難しい.そこで,著者は,着手に対応し て囲碁用語を表示するシステムを提案した.囲碁用語の判定には,石の単なる「位置 関係」だけでなく,石の「勢力や進出方向」などの局面判断を必要とするものがあ る.本論文ではこれを実現するために囲碁プログラム“Ray”を用いた.その結果, 先行研究を参考に比較的利用頻度の高い囲碁用語を視覚的に表示するシステムを実現 した.その性能をプロ棋士に評価してもらったところ,判定システムの用語判定結果 とプロ棋士が判定した用語の結果と比べて90%を超える高い一致率を示した. 二つ目は,学習した内容が理解しにくい囲碁プログラムの深層学習において,学習 した内容を可視化する手法の提案を行った.近年,急速に発達したゲームプログラム を用いてゲームの状況や情報を提示する可視化思考支援の研究が進められている.人 工知能技術,特に機械学習の発展に伴い,機械学習に関するこのような可視化技術に 対する社会的な期待も高まっている.しかし,コンピュータ囲碁が用いている深層学 習モデルは,なぜその結果が導かれたかについて人間は理解できない場合が多い.こ こでは,画像認識と自然言語処理分野において深層学習を解釈するための可視化手法 を転用して,コンピュータ囲碁におけるポリシーネットワークと呼ばれる深層学習モ デルの可視化実験を行う.そして,その可視化結果を分析することによって,ポリシ ーネットワークの学習プロセスを考察した.具体的には,まず,可視化手法の実装と 今後の実験で用いるために考慮し,独自の囲碁ポリシーネットワークを構築した.そ して,五種類の可視化手法(フィルタ重みの可視化,特徴マップの可視化, Deconvnet による可視化,入力閉塞による可視化,Grad-CAM による可視化)を実装
6 し,上記で構築したポリシーネットワークの可視化実験を行い,画像認識のネットワ ークの可視化結果と囲碁のポリシーネットワークの可視化結果の共通点と相違点につ いて考察した.また,可視化結果に基づいて,訓練時のポリシーネットワークの変化 の分析を行った.最後に,可視化手法の応用例としてポリシーネットワークを改良 し,評価実験を行った.可視化の分析結果によると,一層目の各フィルタの学習スピ ードがそれぞれ異なるため,一層目のレイヤーが用いる学習率の改良を行った.改良 前と改良後の可視化結果とモデル精度を比較することで,可視化手法によるポリシー ネットワークの分析はポリシーネットワークの学習率の調整にとって有用であること を示した.また,可視化結果を分析することによって,以下の3つのポリシーネット ワークの特徴が明らかになった. 1)囲碁のポリシーネットワークは盤面全体の幅広い情報を処理するだけでなく,盤 面上の特定の石のパターンにも非常に敏感であること. 2)Deconvnet という可視化を用いる場合,次の一手の周辺は活性化される.さら に,学習プロセスが進むにつれて,活性化されるエリアは鮮明になっていく.. 3)Grad-CAM の可視化手法を適用すると,ポリシーネットワークは隅と端を重視し ている.
7
目次
序論 ... 12 研究の背景 ... 12 ゲームプログラム研究の歴史と機械学習 ... 12 人工知能における解釈 ... 16 研究の目的と貢献 ... 18 論文の構成 ... 20 関連研究 ... 22 囲碁プログラムに関する研究 ... 22 囲碁用語に関する研究 ... 26 深層学習の可視化に関する研究 ... 28 関連研究のまとめと本研究の位置づけ ... 318 セクション1 ... 33 囲碁学習支援のための用語判定システムの提案 ... 34 目的... 34 提案手法 ... 34 対象とする囲碁用語とその分類 ... 36 位置関係による分類 ... 37 局面の解析対象による分類 ... 37 提案システム ... 38 囲碁用語抽出部 ... 39 用語表示部 ... 48 評価実験 ... 50 考察... 52 おわりに ... 53
9 セクション 2 ... 55 ポリシーネットワークの作成 ... 56 データ ... 56 ネットワークの構造 ... 57 訓練結果 ... 59 ポリシーネットワークの可視化 ... 62 フィルタの重みの可視化 ... 62 特徴マップの可視化 ... 66 Deconvnet による可視化 ... 69 入力遮蔽による可視化 ... 73 Grad-CAM による可視化 ... 79
10 可視化結果によるモデルの改良 ... 83 概要... 83 実験条件 ... 83 結果... 84 まとめ ... 88 結論 ... 90 発表実績 ... 93 参考文献 ... 94 謝辞 ... 100 関連論文の印刷公表の方法及び時期 ... 101
11
12
序論
研究の背景 ゲームプログラム研究の歴史と機械学習 コンピュータの登場以来,「人間の知能と同等,もしくはそれを上回る人工知能を作 る」という目標の実現に向けて研究が行われてきた.しかし,人間の知能を直接測定 し評価することは難しいばかりか,すべての分野で人間を上回る汎用人工知能の実現 はもっと難しい.そこで,まず特定のタスクに問題を絞り,人工知能を人間の知能と 比較することで技術の進歩を測ってきた.特定のタスクとして,ゲームはルールが明 確であるばかりか,その性能を勝敗という形で測りやすいため,人工知能の研究対象 として古くから用いられてきた.人工知能という言葉が使われる前の1949 年に,シ ャノン(英: Claude Elwood Shannon)はコンピューターチェスが,人工知能の研究 の対象として適していることを指摘している[Shannon 1950].論文の中で,彼はゲー ムを研究対象とする意義を説明し,その研究の範囲を明確にした.また彼はミニマッ クス探索(英: minimax search)法も提唱しており,彼のこの業績は,その後のゲー ムを題材とした人工知能の研究に大きな影響を与えた.ミニマックス探索法は,両方 のプレイヤが以降のゲームにおいてすべての合法手を考慮し,その中から双方が最善 の手をプレイすることを想定した探索の手法である.ゲームのルールに基づいて,現 在のゲーム局面から未来のゲーム局面を先読みして,ゲームの終わりに向かって合法 的な経路のツリー(ゲーム木)を構築する.さらに,探索空間の広いゲームにおいて は,全ての葉を訪問して探索結果を求めることはできないため,各ゲーム局面を評価 する評価関数(英: evaluation function)という考え方が提案され,任意の深さまで探 索することで妥当な手を選ぶ手法も提案された.その後,ミニマックス探索法の効率 的な枝刈り手法であるアルファ・ベータ法(英: alpha-beta pruning)[Edwards13 1961]など多くの探索の効率化の手法が提案されて,ミニマックス法はゲームプログラ ムの標準的な手法となった.これらのゲームプログラム技術の発展に伴い,ゲームプ ログラムの研究はチェスライクゲームだけでなく,チェッカー(英: checkers) [Samuel 1959]やオセロ,バックギャン (英: backgammon)や囲碁[Bernd 1993]などの プログラム研究に広がっていった. 局面を評価する評価関数は,探索や枝刈りの効率化にも関わるため,ゲームプログ ラムの強さに大きく影響する.当初,評価関数のパラメータは,開発者の経験にもと づいて手動で設定されてきた.その後,強いプレイヤの棋譜を利用して,評価関数の パラメータを自動的に調整する手法が考えられ,チェスの分野では,1980 年代に活躍 していたDeep Thought[Berliner 1989]の開発に用いられた.しかし,評価項目自体 はまだ研究者によって設計されていた.その後,ニューラルネットワーク(英: neural network)の研究の発展とともに, 1980 年代後半に, Gerald Tesauro と Terrence Sejnowski はニューラルネットワークを用いて,バックギャンの評価関数を作成する 手法を提案し,Neurogammon というバックギャン AI を作成した[Tesauro 1989]. Neurogammon は 1989 年に開催されたコンピュータオリンピアード(英: Computer Olympiad)において優勝したが,まだ人間プロ選手に勝てるレベルに至らなかった. また,そのニューラルネットワークで用いられていた特徴は,人間の手作業によって 設計されていた.その後,1992 年には強化学習を用いて開発された TD-Gammon が 現れ,初めて世界チャンピオンに匹敵する強さとなった[Tesauro 1995].強化学習を 導入することによって,TD-Gammon は,局面の情報を直接的利用できるようにな り,人間による手作業を大幅に省くことが可能となった.この手法を他のゲームに適 用しようとする試みはあったが,他のゲームでは既存手法を上回る性能がなかなか出 せなかった.性能の向上が見られなかった理由としては,当時のハードウエアの計算 能力が不足していたためニューラルネットワークを用いて評価関数を作成する場合,
14 探索できる空間に限りがあったことが挙げられる. 一方,チェスの分野では,IBM がチェス専用ハードウエアであるディープ・ブルー (英: Deep Blue)を開発して,人間のトップを超えるプログラムの実現を目指した. その結果,1997 年に世界チャンピオンのガルリ・カスパロフ(英: Garry Kasparov) を相手に勝ち越した[Campbell 2002].この特別なハードウエアの計算資源は,評価関 数のための機械学習ではなく,ゲーム木の膨大な探索に用いられていた. 同じチェスライクゲームである将棋の分野では,持ち駒再利用のルールの影響もあ りチェス以上に合法手が多いばかりか評価関数の設計も難しかった.将棋においては 2006 年の Bonanza の登場以降、評価関数の精度の向上に機械学習法が有効であると いうことが明らかとなった[保木 2006][Hoki 2014].将棋の初期の機械学習は,プロ 棋士や強いアマチュアの棋譜を教師データとした学習が中心であったが,近年ではコ ンピュータ同士の自己対戦により棋譜を生成し,浅い探索による評価値を深い探索に 近づけるように学習させる教師なし学習の手法が主流となり[金澤 2016],人間のトッ ププレイヤを遥かに凌ぐ性能を示すようになっている. それに対して,囲碁の分野では合法手が非常に多く探索が困難であるばかりか,局 面評価関数の設計が絶望的に難しかった.チェスライクゲームは,駒の性能があり, 盤上のKing の危険度をパラメータとして設定しやすいために,学習すべき内容をコ ンピュータに記述することが比較的やりやすい.しかし,囲碁は一つ一つの石には意 味がなく,これがつながることによって意味を形成する.その意味は高度に抽象的で あるため,記述することが難しい.このような石のつながりの重要性を認識するプロ グラムを書くことは困難を極めたが,2006 年ごろに,乱数シミュレーションを行うモ ンテカルロ木探索(英: Monte Carlo Tree Search)という手法が現れ,コンピュータ囲 碁は急速に棋力を高くした.モンテカルロ木探索では,有望そうな候補手を用いて膨 大な乱数対戦を終局まで行って勝敗を調べ各候補手の勝率を求めて,最も勝率の高い
15
手を選ぶという手法である.2006 年初めてモンテカルロ木探索を実装した囲碁プログ ラム「Crazy Stone」が登場した[Coulom 2007a].Crazy Stone は第 11 回コンピュー タオリンピアードの囲碁の9 路部門で優勝し,翌 2007 年の第 12 回コンピュータオリ ンピアードにおいては,19 路部門で同様の手法を用いた MoGo と Crazy Stone が優 勝と準優勝になり,一躍モンテカルロ木探索の手法がコンピュータ囲碁の主流となっ た[美添 2008].その後,コンピュータ囲碁は徐々に強くなり,その手法を改良した囲 碁プログラム「Zen」は 2016 年に行われた第 4 回電聖戦において小林光一名誉棋聖を 相手に公開対局に3 子局で勝利し,アマチュア 6 段程度の棋力があると認定されるに 至った[加藤 2017]. 一方,1990 年代以降,ニューラルネットを用いて囲碁の次の一手を予測したり,局 面を評価したりするための研究も多数あったが,2010 年代半ば頃までは,ハードウエ アの処理の限界などもあり,実際にニューラルネットを使用した顕著な研究成果は見 られなかった.ところが,2014 年に,Christopher Clark のグループ[Clark 2015]と DeepMind のグループ[Maddison 2014]が,教師あり学習手法を用いて次の一手を予 測する畳み込みニューラルネットワーク(英: Convolutional Neural Network)の成 果を発表した.これらの畳み込みニューラルネットワークを用いた手法では,プロ棋 士の棋譜の次の一手の一致率は55%を超えた.それまでの手法では次の一手の一致率 はせいぜい40%台前半だったので,飛躍的な一致率の伸びであった[伊藤 2016].そ の2 年後,2016 年には DeepMind 社が開発した深層学習と強化学習手法を用いたア ルファ碁(英: AlphaGo)に関する論文が発表され,欧州囲碁選手権を 3 連覇した樊麾 二段と2015 年 10 月に対局し 5 戦全勝したことがその棋譜とともに公表され衝撃を与 えた[Silver 2016].囲碁界でコンピュータがプロ棋士に互先で勝利を収めたのはこれ が史上初である.翌2017 年には,改良を加えた AlphaGo が当時の世界最強棋士であ る柯潔九段に挑み3 戦全勝と圧勝した.さらに,DeepMind 社は「人間の棋譜を一切
16
使わず,ルールだけを教えられた状態」からコンピュータ囲碁を強くする手法を示 し,それまでのAlphaGo よりも強い「アルファ碁ゼロ(英: AlphaGo Zero)」を開発 したことを発表した[Silver 2017a].また同年,同じ開発チームは汎用化された AlphaGo Zero の手法を使用して,囲碁のみならず,チェスや将棋の世界チャンピオン プログラムを超える性能を示すAlphaZero を発表した[Siler 2017b]. 近年のゲームプログラムの技術は,深層学習を含んだ機械学習を利用した手法が主 流になってきている.このように,コンピュータの計算能力の発展に伴った機械学習 の導入により,殆どのゲームにおいてゲームプログラムが人間を超えるという目標が 達成されるようになってきた. 人工知能における解釈 近年の人工知能技術,特に機械学習の発展に伴い,人工知能の思考を理解する技術 の社会的な応用への期待が高まっている.しかし,人工知能の思考過程は必ずしも人 間のそれとは同じでなく,ニューラルネットワークなど機械学習モデルはブラックボ ックスと言われているように,複雑な仮説集合をもつモデルを用いた場合には,なぜ そのような結果となったのかについて人間は理解できない場合が多い.そのため,近 年,人工知能のモデルを解釈する研究への注目が増えてきている. 本論文では,解釈の定義について,以下の引用「解釈は,人間に説明を与えるプロ セスである.」(英: “Interpretation is the process of giving explanations to
Human ”)に準拠するものとする[Kim 2017].すなわち,人間の理解を助けるために 人間に説明を与える手段,手続き,方法についての広い意味で用いることにする. 膨大な探索に基づくコンピュータの思考と人間の思考の違いについては、以前から 指摘されてきた.伊藤は当時のコンピュータ将棋とプロ棋士の思考を比較して,人間 の思考が大局観に基づくトップダウン的な思考が中心であるのに対して、コンピュー タ将棋は膨大な探索中心のボトムアップ的な手の選択であることを指摘している[伊藤
17 2007].近年評価関数の機械学習が進んだものの,コンピュータは基本的には膨大な探 索に裏打ちされた手の選択を行っているので,コンピュータ将棋の解釈という問題は 変わらずに残されている. 一方,機械学習モデル自体の精度は高くなっており,その結果への信頼度が高まっ ている中,具体的で重要な判断を伴う問題について,多くの場合,最終的に決定を下 すのは人間である.人工知能を利用する上で,その精度だけでなく,機械学習モデル がデータから学習した知識を人間が理解できる形で表現する技術も求められている. たとえば,医師が深層学習モデルに基づいて患者の診断を行う場合,そのモデルが患 者のどんな病症に基づいてそのような判断を行うのかを理解する必要がある.そのモ デルの内容が説明できない場合,インフォームドコンセントの観点から患者に十分な 情報を提供できないため,多くの応用現場でそのモデルの利用を使うことが困難とな る. モデルを解釈する意義として,以下の三つが考えられる.一つ目は,教育や学習支 援への応用である.人工知能の判断の結果を可視化して,その判断の結果を人間にと って理解しやすい形で提示することで,より優秀な考え方や判断手法を得ることが可 能となる(学習支援としての意義).二つ目は,モデルを解釈することによって,人間 はモデルを理解し,さらにモデルの精度を上げることができる(モデルの改良として の意義).三つ目は,銀行,保険,医療といった規制の厳しい業界では,導き出される 結果に貢献した要因を理解することが重要であるため,モデルを解釈することが必要 とされる(信頼性向上としての意義). また,精度が高い反面,解釈が困難な代表的な手法としては深層学習が挙げられ る.そのため,近年深層学習を解釈する研究が盛んに行われている.その方向性に は,タスクの内容とデータ分布を考えずに計算機理論に基づいて深層学習の理論を追 求する研究と,タスクの内容とデータ分布を特定し,可視化結果とデータ分析に基づ
18
いてモデルの精度を解釈する研究の二つの方向性の研究が見られる.前者の研究とし ては深層学習の汎化誤差 (英: generalization error)についての研究が挙げられる [Hardt 2016] [Mou 2018].計算論的学習理論の一つである PAC 学習の理論による と,学習モデルの汎化誤差の変化範囲とモデルの複雑さは負の相関関係である.つま り,モデル複雑性が高ければ,モデル精度は下がると思われてきた.しかし,深層学 習の場合,ニューラルネットワークの複雑性が高ければ,モデル精度が上がる場合も ある.そのため,深層学習の汎化能力を再定義(英: rethinking generalization)しよ うとする研究が行われている.後者の研究としては,自然言語処理と画像認識の分野 など特定のタスクに限定することによって,深層学習への理解を深める研究が挙げら れる.例えば,自然言語処理の分野に置いて,回帰型ニューラルネットワーク (英: Recurrent Neural Networks)は文章の長距離依存性(英: Long-range dependence, ゼロ代名詞の照応関係や構成素の移動といった言語現象,引用句・角括弧など)に関 する処理を解析する研究がある[Karpathy 2015].Karpathy らは長距離依存性を追跡 するメモリセル(「ニューロン一個分」の一次元の情報しか記憶できない)を用いて, 照応関係のある文を可視化した.また,可視化手法を用いることで,深層学習モデル の概念生成プロセスを分析する研究もある.このような可視化手法は,隠れ層に含ま れている複雑な情報を人間が理解できる画像に変換することで,人間の深層学習に対 する理解を深めることを助けている. 研究の目的と貢献 本研究では,囲碁プログラムの思考過程を可視化する技術について,以下の二つの 研究を行った. 一つ目(第3章の内容)は,囲碁用語の理解を助ける可視化に着目した研究であ る.囲碁は他のゲームに比べて専門用語が非常に多いことで知られている.また,過
19 去の認知科学的研究から熟達化するにつれて多くの囲碁の専門用語を使えるようにな ることも知られている[小島 1999].このことは,囲碁という複雑なゲームの人間の理 解において専門用語が果たしている役割が大きいことを示している.近年の強くなっ た囲碁プログラムを用いてより正確な専門用語の判定ができることを確認し,囲碁の 初学者向けに適切な囲碁用語を自動表示するシステムの構築を目指した.そして,囲 碁プログラムの根幹をなすモンテカルロ木探索によって得られる石の最終的な配置を 統計的に示すモンテカルロオーナーを用いて,囲碁の石の勢いや発展性を認識し,囲 碁用語の正確な意味の理解を助けるシステムを提案した. 二つ目(第4~6章の内容)は,人工知能の思考を理解するための可視化に着目し た研究を行った.囲碁プログラムも深層学習の結果選ばれた手の意味を人間が理解す ることは難しい.本研究では,画像認識と自然言語処理分野において深層学習の解釈 可能性を高める可視化手法を用いて,囲碁プログラムが利用しているポリシーネット ワークという深層学習モデルの可視化の実験を行う.そして,その可視化の結果と囲 碁用語データを分析することによって,ポリシーネットワークの学習プロセスを考察 する.この目標を達成するために,まず,本研究では,可視化手法の実装と今後の実 験の実施を考慮し,独自の囲碁ポリシーネットワークを構築した(第4章の内容).そ して,五種類の可視化手法(フィルタの重みの可視化,特徴マップの可視化, Deconvnet による可視化,入力閉塞による可視化,Grad-CAM による可視化)を実装 し,上記で構築したポリシーネットワークの可視化実験を行い,画像認識のネットワ ークの可視化結果と囲碁のポリシーネットワークの可視化結果の共通点と相違点を考 察した(第5章の内容).また,可視化結果に基づき,訓練によっておきるポリシーネ ットワークの変化について,分析を行った.さらに,可視化結果の応用例としてポリ シーネットワーの改良実験を行った(第6章の内容).可視化の分析結果によると一層 目各フィルタの学習スピードはそれぞれのため,一層目のレイヤーが用いる学習率の
20 改良を提案した.改良前と改良後の可視化結果とモデル精度を分析することで,可視 化手法によるポリシーネットワークの分析はポリシーネットワークの学習率の調整に とって有用であることを示した. まとめると本研究の貢献は下記の四つである. 1. 十分に強くなった囲碁プログラムを利用して,囲碁用語を正確に判定し,わか りやすい形で提示するシステムを作り,その精度を囲碁の専門家に評価させて その有効性を示した. 2. 囲碁のポリシーネットワークを訓練させて,訓練中保存されたモデルを利用し て,各学習時点に,ポリシーネットワークにどのような変化が発生したかを分 析した. 3. 画像認識の分野に使われている可視化手法を囲碁のポリシーネットワークに適 用した.また,画像認識の場合の可視化結果と囲碁のポリシーネットワークの 可視化結果の比較を行った. 4. 複数の可視化手法を用いて,ポリシーネットワークの特性を明らかにした.さ らに,その特性にしたがって,より精度の高いモデルを作成の可能性を検証し た. 論文の構成 本論文はつぎのように構成されている.第1 章では,研究背景および研究目的,本 論文の構成について述べる.第2 章では,関連研究として,コンピュータ囲碁を用い た囲碁用語に関わるこれまでの研究,深層学習の解釈可能性を高めるための可視化手 法に関する研究を説明する.本論文の目的を遂行するための2 つの異なったアプロー チの研究を第3 章(セクション1:人の理解を助ける可視化)と第 4 章~6 章(セク ション2:人工知能の思考を理解するための可視化)に分けて述べる.第3 章では,
21 初学者の囲碁プレイヤの理解を助ける可視化の研究として,囲碁学習支援のための用 語判定システムを提案する.第4~6章では,人工知能の理解を助けるための囲碁プ ログラムにおける深層学習の可視化技術について説明する。第4 章では,提案したコ ンピュータ囲碁のポリシーネットワークの作成について述べ,第5 章では,これまで の可視化手法を踏まえ,本研究が行ったコンピュータ囲碁のポリシーネットワークの 可視化実験を紹介する.第6 章では可視化の分析結果による新しいモデル構造の提案 と評価実験について述べる.最後に第7 章において,本論文の成果をまとめる.
22
関連研究
囲碁プログラムに関する研究 囲碁プログラムの歴史を見ると,モンテカルロ木探索と深層学習の二つの大きな技 術革新によって大きく発展してきたと言える.ここではモンテカルロ木探索以降の技 術について概観する. モンテカルロ法の研究自体は1940 年代から始められ,ゲームの研究としては 1980 年代にAbramson らによって,三目並べやリバーシやチェスを題材にして通常の評価 関数の代わりにモンテカルロ法を用いる手法が示されている[Abramson 1987].これ を囲碁で用いたのはBrügmann で,初めてモンテカルロ法をコンピュータ囲碁に応用 した.しかし,単純なモンテカルロ法の利用ではコンピュータ囲碁はなかなか強くな らず,主流の研究対象とはならなかった.しかし,2006 年に Coulom がモンテカルロ を木探索に適用する手法としてモンテカルロ木探索を提唱すると,この手法は革新的 な発展を遂げた[Coulom 2007a] [Gelly 2006].その後,モンテカルロ木探索の性能を 高める手段として,1回ごとのプレイアウトの質を高めることが強さの実現において 重要な意味を持つことが示され,プログラムの強化が進められていった.プレイアウ トの質を高めるためには手の予測器が必要であるが,局面の一部のパターンを用いた 予測器は限界があり,なかなか良い予測器が作れなかった. 一方,深層学習の研究は画像処理の分野などで徐々に大きな成果を収め始めてい た.2012 年のコンピュータビジョンコンペティション(英:ILSVRC,ImageNet Large Scale Visual Recognition Challenge)で優勝した深層学習は,研究と投資の巨 大な波を引き起こした.深層学習の技術とハードウエアの進歩が相まって,深層学習 をコンピュータ囲碁に適用しようとする初の試みが,Clark らによってなされた [Clark 2015].彼らは人間がプレイした囲碁の棋譜から抽出した 1,650 万の局面情報23 と次の一手のペアをデータセットとして利用し,教師あり学習の訓練手法で深層学習 のモデルを作成した.彼らが構築したモデルの入力は盤面情報とあらかじめ設定され た特徴で,出力は合法手の次の一手として選択される確率である.2014 年以前,特徴 構築手法(英:feature construction)やニューラルネットワークを用いた次の一手を 予測するモデルは多数あるが,彼らが作成したモデルの予測精度は40%を超え,以前 のすべてのモデルの精度を上回った.さらに,従来の方法で実装されたコンピュータ 囲碁(GNU_Go)と対戦した結果,勝率は 85%を超えた.大量な囲碁知識を基づいて 作成されたGNU Go に対し,優勝した深層学習の予測モデルでは棋譜データセットの み利用している.そのため,深層学習はコンピュータ囲碁の棋力への大きな貢献は期 待されていた.同年,Maddison らはネットワークの構造を変え,より複雑なニュー ラルネットワークを用いて訓練した[Maddison 2014].その結果,深層学習による次 の一手を予測するモデルの精度は55%まで上がった.さらに,GNU Go と対戦した結 果,勝率は97%を超えることを示した.また,Maddison らは深層学習の予測モデル の対戦棋譜を分析し,深層学習による次の一手の予測モデルは基本な布石と定石と手 筋などを理解しているように見えると報告した.しかし,深層学習のモデルの次の一 手の予測精度は高くなったものの,棋力はそれほど高くなかった.既存のMCTS 手法 を用いたコンピュータ囲碁(100,000 回ロールアウト/一手)と対戦する場合,深層学 習による次の一手を予測するモデルの勝率は10%にとどまっていた.そのため,強い コンピュータ囲碁を求めていたMaddison らは MCTS 手法の探索部分に深層学習モデ ルを導入し,二つ手法を組み合わせることにした.その結果,この手法と単に深層学 習モデルだけを用いた手法を対戦させたところ,勝率は87%まで上昇した.その後ほ どなくして,人間のプロ棋士を互先(ハンディキャップなし)で破った初のコンピュ ータ囲碁AlphaGo が登場した[Silver 2016].翌 2016 年 3 月には,世界最強レベルの 棋士の一人であったイ・セドルとの五番勝負で4 勝 1 敗と大きく勝ち越して,大きな
24
成功を収めた.同時に,Aja らが入った DeepMind の研究チームは AlphaGo の開発 過程を公開した.論文の中の実験結果によると,アルファ碁のイロレーティング(棋 力)はそれまでの最強と言われていたコンピュータ囲碁に大きく勝ち越す成果を上げ た.
AlphaGo の成功要素は下の三つに集約される.
1. ポリシーネットワーク(英:the policy network):最初に,深層学習の教師あ り学習で3000 万の盤面情報と次の一手のペアデータを利用し,次の一手を予 測する深層ニューラルネットワーク作成した.次に,強化学習を用いて自己対 戦でこのニューラルネットの棋力を改善した.この特別なニューラルネット (ポリシーネットワーク)は,85%の確率で MCTS を用いた既存のコンピュー タ囲碁を打ち破ることができた.
2. ロールアウトネットワーク(英:the rollout network):作成したポリシーネッ トワークの速度は遅いため,大量なシミュレーションが行うMCTS 手法への応 用は困難である.DeepMind の研究チームは,ポリシーネットワークを基礎と してより快速なロールアウトネットワークを作成した.ロールアウトネットワ ークの特徴は,低い精度と高計算速度のため,MCTS 手法との併用を可能にし た.
3. バリューネットワーク(英:the value network): DeepMind の研究チームは ポリシーネットワークとロールアウトネットワークを作成した上,さらに,ポ リシーネットワークを自己対戦させ,大量の棋譜を生成した.教師あり学習手 法で生成された棋譜を利用し,バリューネットワークを構成した.ポリシーネ ットワークとロールアウトネットワークは次の一手を予測するモデルに対し, バリューネットワークは局面の勝率を予測するモデルである. 論文の中の実験結果(図1)によると,AlphaGo は複数の効果的な手法(ポリシー
25
ネットワーク+ロールアウトネットワー+クバリューネットワーク)に基づいて設計 されたコンピュータ囲碁であり,単一の手法と比べ,イロレーティング(棋力)は大 幅に向上した.
さらに,2017 年,DeepMind の研究チームはポリシーとバリューネットワークを組 み合わせた上,残差ネットワークの構造を利用したAlphaGo Zero を開発した[Silver 2017a].AlphaGo Zero は,人間の対戦棋譜の代わりに自己対戦の棋譜のみを使って AlphaGo より高い棋力を実現した.完全に教師なし学習で人間を上回る囲碁プログラ ムを実現したと言える. 深層学習を用いたポリシーネットワークとロールアウトネットワーとクバリューネ ットワークが囲碁の棋力向上に大きく貢献したことから,深層学習は画像認識だけで なく,囲碁というゲームタスクにも適していることが示された.また,先行研究であ 図1 ポリシーネットワークとロールアウトネットワークとバリューネットワーの組み合わせとア ルファ碁のイロレーティング(棋力)の関係(AlphaGo の論文より引用)
26 るClark らは自身の研究の中で一層目のフィルタの重みの可視化結果を分析し,一部 のフィルタの可視化結果が垂直方向と水平方向に対して対称性があることを示唆して いる [Clark 2015].しかし,Clark らの研究の目的は次の一手を予測するモデルの精 度であったため,可視化実験の結果は提案手法の補助的な説明として位置づけられて おり,明確な議論はなされていない.その後行われたMaddison らの研究において も,深層学習による次の一手の予測モデルは基本な布石と定石と手筋などを理解して いるように見えることが指摘されていたが[Maddison 2014],その理由について具体 的な分析は行われていない. 囲碁用語に関する研究 人は囲碁を打つ場合,盤面を認識し,その人の持つ知識に基づいて石を打つ.盤面 を認識するときにも,その人の持っている知識の範囲で認識を行っている.局面の認 識や着手の選択の際に,熟達するほど囲碁用語を用いて考えていることが指摘されて いる.さらに,学習する際にも,石の繋がりや意味を囲碁用語という枠組みで捉え学 んでいく.すなわち,囲碁を打つという行為には,「認識」「理解」,そして「着手」, さらには「学習」に至るまで,囲碁用語が深く関わっている.石の繋がりのようなイ メージ的な知識をラベル化するために,囲碁用語が果たしている役割は大きい. 小島らは,人間が囲碁の用語の獲得を行う理由を,「効率的に記憶するため」と「知 識の精度を上げるため」という2点に着目した[小島 1990].そして,この仮定に基づ いたパターンの知識からの用語の獲得について,以下の3つの方法を提案した. 1. 知識に頻繁に生じる複数の石の配置を囲碁用語で置き換える(圧縮) 2. 類似した複数の知識を一つの知識にまとめる(一般化) 3. 一般的過ぎる知識を修正するための用語の詳細化(詳細化) 小島らは,「圧縮」「一般化」「詳細化」という3種類の囲碁用語の獲得方法によっ
27 て,囲碁の知識は取得され,精緻化されていくと考えた. 一方,これらの囲碁用語を学習することは,非常に難しい.囲碁用語を専門に解説 する本も出ているが,囲碁用語とその用語に関する説明が書かれているだけで,専門 書を読むだけでは,囲碁用語を実際の石の視覚的イメージと関連付けて,その意味を 学習することは難しい.また,囲碁のテレビ番組や解説などでも,これら囲碁用語が 飛び交っているが,それぞれの囲碁用語を丁寧に教えてくれるものは少なく,使われ ている用語から意味を理解して自分で概念を獲得していくしか無い.いずれも初心者 にとっては非常に大きな壁である. 本研究では,囲碁用語を視覚的に提示するシステムを提案することで,囲碁を学習 する初心者が囲碁用語とその視覚的イメージを結びつけて学習できるシステムを提案 する. 囲碁用語を読み上げてくれるシステムとしては,市販の囲碁ソフトにも搭載されて いる.国内最強ソフトの「天頂の囲碁」は,棋譜を入力すると着手に対応する囲碁用 語を読み上げる機能がある[天頂の囲碁6 2016].しかし,読み上げる囲碁用語は,非 常に基本的なものに限定されていて,判断が難しい囲碁用語を読み上げることは避け ている. また,囲碁用語の抽出を目指した研究としては,宍戸らの機械学習を用いた手法が ある[宍戸 2015].宍戸らは,囲碁の“形”を表現する単語をコンピュータに認識させる ために,教師ありの機械学習を用いて,盤面と着手から単語を導く手法を提案してい る.学習データを収集するために,トップアマチュアを6名使って60 局もの棋譜にタ グを付けさせるという作業を行わせている.これは,実施するのに大きなコストがか かる.また,回収した学習データの中,各用語の出現頻度には,大きな差が見られ た.そのため,出現頻度の低い用語に対し,機械学習では精度の高い分類は困難であ ると考えられる.単純な位置関係を示す用語(「ケイマ」,「コスミ」など)は,座標の
28 計算によって,比較的容易に抽出できる反面,局面の理解を必要とする用語(「カカ エ」,「オサエ」など)の判断には,局所的な読みや死活判定など局面解析が必要のた め,抽出は困難になる傾向が見られた. 深層学習の可視化に関する研究 2012 年のコンピュータビジョンコンペティション(英:ILSVRC ,ImageNet Large Scale Visual Recognition Challenge)で深層学習のモデルが優勝した以来, 様々な視点から深層学習モデルがうまく機能する原因を考察する研究が行われてき た.現在の深層学習の可視化の手法は,主に二つに分けられる.一つは,前向きの計 算に利用されるフィルタ(英:filter)と特徴マップ(英:activation map)を可視化 し,数値の変化を観察する直接的な手法である.もう一つは,逆計算や投影など方法 によって,低レベルの特徴マップを元の画像の空間に逆方向に伝搬させるという間接 的な手法である.この可視化結果を観察することによって,元の画像から抽出される 特徴を理解することが可能になる. 前者の中で,一般的な可視化手法はフィルタの重みのマトリックスを可視化する手 法である.深層学習が利用している畳み込み層のフィルタと画像の間の内積の計算を 行うため,これらのフィルタの重みを可視化することによって,フィルタはどのよう に画像情報を抽出するかを理解することが可能になる.前節で紹介したClark らの囲 碁研究の中で利用された可視化手法はこの手法である.しかし,レイヤーが深くなる とフィルタの機能は抽象的になるため,可視化対象は画像空間に直接投影する最初の レイヤーのフィルタに限定される.入力画像に直接接続されていないため,深いレイ ヤーを可視化する場合,別の方法を利用する必要がある.他に,中間層の特徴マップ を可視化する手法もある.特徴マップを調べることで,活性化の領域を元のイメージ と比較し,ネットワークが学習する特徴を確認することが可能となる.この手法で特
29 徴を識別すると,ネットワークが学習した内容を把握することができる.また,2015 年にYosinski は,提案されてきた直接的な可視化手法を基づいて,深層学習モデルの 可視化ツールを開発した[Yosinski 2015].彼らは中間層の特徴マップに対し可視化実 験を行い,初期の層のチャネルでは色やエッジなどの単純な特徴を学習していて,深 い層のチャネルでは目や鼻などの複雑な特徴を学習していることを指摘した. 一方,逆計算や投影など間接的な方法もある.その中,低レベルの特徴のある画像 を元の画像の空間に逆方向に伝搬させる手法が進められてきた.2014 年に,Zeiler ら は,逆畳み込み(英:transposed convolution)という可視化手法を提案した[Zeiler 2014].逆畳み込みは畳み込み層に返ってきた特徴マップ上の勾配を逆に畳み込むこと でもう一つ前の層に勾配を伝える手法である.すなわち,逆畳み込みという操作は畳 み込みの反対の操作である。これらはフィルタ、カーネル、ストライドを畳み込みレ イヤーと同様に機能するが、たとえば3x3 入力ピクセルから 1 出力にマッピングする 代わりに、1 入力ピクセルから 3x3 ピクセルにマッピングする。逆畳み込みをするこ とによって,低レベルの特徴がある特徴マップを元の画像の空間に逆方向に伝搬させ ることを可能にしている.また,逆畳み込みは途中から逆計算を行うことができるた め,中間層の可視化も可能となる.一方,Zeiler らは画像のデータセットに対して遮 蔽(オクルージョン)実験(英:occlusion experiment)を行った.遮蔽実験は,深 層学習モデルに送る前に画像の一部をマスキングし,ヒートマップという形で各マス キングされたエリアの中心に正解の予測順位を描画する可視化手法である.入力画像 にパターンに対応するエリアがマスキングされると,正解の判断確率が下がるという 特性は予測順位のヒートマップに反映される.さらに,彼らはこれらの可視化手法を 診断手段として利用し,よりも優れた深層学習モデルの構造の提案と評価を行った. その後,2015 年に Zhou らは CAM(英:Class Activation Mapping)という可視化 手法を提案した[Zhou 2016].CAM は深層学習モデルの最後の全結合層(英:full
30
connected layer)を GAP 層(英:Global Average Pooling)に変換し,出力層の重み を畳み込み層に逆投影する手法である.この可視化手法を利用することによって,画 像認識の結果に影響を与えるエリアを表示することができる.しかし,CAM を利用す る場合,最後の全結合層をGAP 層に変換する必要があるため,モデルの再訓練に時 間がかかる.Selvaraju らは CAM 手法を基づいて Grad-CAM という可視化手法を提 案した[Selvaraju 2017].CAM はモデルの全接続層を GAP に変え,モデルを再訓練 することによって,直接的に重みを獲得する.それに対して,Grad-CAM は勾配の全 領域平均(英:Global Average)を使用し,間接的に重みを計算する.勾配を利用 し,重みを計算するため,Grad-CAM という手法は再訓練する必要はないというメリ ットがある.また,Grad-CAM 手法は最終結果の後に ReLU 層を追加することによっ て,画像認識の結果にポジティブな影響を与えるエリアを表示することができる.ま た,2017 年に Chu らは畳み込みニューラルネットワークでなく,ResNet(英: Residual Network)という深層学習モデルを用いた可視化実験を行った[Chu 2013]. 視覚実験と分析することによって,彼らはResNet の可視化可能性を証明し,ResNet のスキップ接続構造(英:Skip Connection)の機能を明らかにした. 同時に違う精度のモデルの可視化結果を比較する研究も行われていた[Yu 2014]. Wei Yu らの Alexnet と VGG の可視化結果の比較実験において,Alexnet(精度: Top1 = 63%,Top5 = 85%)と VGG(精度:Top1 = 74%,Top5 = 92.7%)の画像認 識精度の差は 10%を超えたが,Alexnet と VGG の可視化の結果には幾つかの類似点 があることが指摘された.Alexnet の可視化結果と VGG の可視化結果から見ると, Alexnet と VGG 深層学習モデルが低レベルから高レベルまで徐々にパターン認識能力 を獲得することが分かった. 深層学習モデルの可視化について,最近の研究では様々な成果が上がっている.こ の可視化手法は他の深層学習を用いている研究分野でもうまく機能することが期待さ
31 れている. 関連研究のまとめと本研究の位置づけ 上述の通り,コンピュータ囲碁はモンテカルロ木探索と深層学習の技術を組み合わ せた手法で人工知能の成功例として,人間を遥かに超えるプログラムを実現してき た.しかしながら,実現された囲碁プログラムによって人間の熟達化に関連する囲碁 用語の理解を高めることができるのか,深層学習モデルがどのように棋譜データから 囲碁知識を抽出しているのかは明らかにされていない. そこで,本研究では,コンピュータ囲碁を題材に,ゲームAI の思考過程を可視化す る技術として以下の二つの研究を計画した. 一つ目は,囲碁用語に着目した研究である.囲碁の初学者が囲碁用語を理解して覚 えるためには具体的な着手に対応する石のパターンを可視化して伝えてやる必要があ る.第3章で行う着手に対応する適切な囲碁用語を自動表示するシステムでは,近年 強くなってきた囲碁プログラムを利用した囲碁用語の認識を高める手法を提案し,初 学者向けの学習支援システムを構築した.この研究は,近年のコンピュータ囲碁が人 間の学習に関連している囲碁用語の認識に貢献しうることを検証している. 二つ目は,深層学習において学習した内容が理解しづらいという問題点に着目し, 深層学習を用いた囲碁プログラムの学習プロセスを明らかにすることを目的として, 画像認識の可視化手法を囲碁プログラムに応用する研究を進めた.まず,可視化実験 を円滑に行うために改めて簡単なポリシーネットワークを構築して,ネットワークの 訓練を行った.そして,これまでの可視化手法を踏まえ,作成されたコンピュータ囲 碁のポリシーネットワークの可視化実験を行い,ポリシーネットワークの各学習時点 にどのような変化が発生したかについて分析を行った.また,画像認識の場合の可視 化結果と囲碁のポリシーネットワークの可視化結果も比較した.最後に,可視化結果
32
に基づいて,より精度の高いポリシーネットワークを作成する方法についても考察し ていく.
33
セクション1
34
囲碁学習支援のための用語判定システムの提案
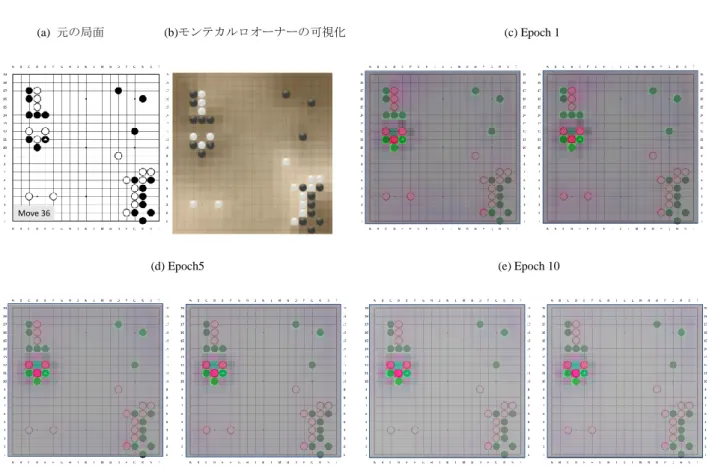
本章では著者が行った囲碁用語に着目した研究ついて説明する.著者は着手に対応 する適切な囲碁用語を自動表示するシステムを提案し,初学者向けの学習支援システ ムを構築した.本研究は発表実績:関連論文(学位論文を構成する論文)[1]に関連し たものである. 目的 人間の囲碁の熟達化において,囲碁用語が果たしている役割は大きい.本研究で は,近年発展してきた囲碁プログラムを用いることで,囲碁用語の認識の精度を高め て,初学者向けに適切な囲碁用語を提示するシステムの構築を目指す. 提案手法 本研究ではコンピュータ囲碁の局面認識で用いられているモンテカルロオーナーと いう概念を利用して,局面解析手法を提案する.モンテカルロオーナーとは,プレイ アウトの最終局面の石配置を統計的手法で計算することで,盤面上の石の生き残る確 率を示す値である[Coulom 2007b].モンテカルロオーナーにより,盤上のすべての点 が終局時にどちらの色に属している可能性が高いのかを推察することができる.座標 p のモンテカルロオーナーの値 MC Owner(p)は,次の式(1)(2)で求められる. P(𝑛𝑖, 𝑝) = { 1(𝑠𝑡𝑎𝑡𝑒(𝑝) = black) 0(𝑠𝑡𝑎𝑡𝑒(𝑝) = blank) −1(𝑠𝑡𝑎𝑡𝑒(𝑝) = white) (1) MC Owner(𝑝) = 100 × ∑P(𝑛𝑖, 𝑝) 𝑛 𝑛 𝑖=1 (2)35 𝑛:プレイアウトの総数 𝑛𝑖:𝑖番目のプレイアウト 𝑠𝑡𝑎𝑡𝑒(𝑝):座標pの状態 P(𝑛𝑖, 𝑝): 𝑖番目のプレイアウト時の点pの状態 例えば,図2 左の局面のモンテカルロオーナーを計算すると,図 2 右のようなマト リックスが得られる.モンテカルロオーナーが取る範囲は+100 から-100 であり, -100 に近いほど白地になる確率が高く,+100 に近いほど黒地になる確率が高いこ とを意味する.このモンテカルロオーナーを用いることで局面解析を助ける情報を得 ることが出来る. そこで,本研究の囲碁用語の抽出では,石の位置関係と囲碁プログラム「Ray」の モンテカルロシミュレーションを用いて計算したモンテカルロオーナーの結果を合わ せることで局面解析を行い,判別が難しい囲碁用語の抽出を可能にする手法を提案す る.さらには,その石の関係を視覚的に表示することで,囲碁用語の獲得を支援する システムの実現を目指す. なお,「Ray」は小林祐樹氏により開発された囲碁プログラムであり,インターネッ トを利用したネット碁対局サイトKGS では二段程度の実力のプログラムである[KGS 2017].KGS における二段という棋力は,日本の道場では一般にアマチュア三段から 図2 モンテカルロオーナー
36 四段程度の棋力であることが知られており,初心者向けの囲碁用語の判定をするため には十分な棋力であると想定できる.「Ray」はネット上で公開されているが[Ray 2020],開発者に直接連絡して,本研究での使用についての許諾を得ている. 対象とする囲碁用語とその分類 対象とする囲碁用語としては,実用性から出現頻度が比較的高いものから優先する 必要があると考えた.宍戸らの先行研究では,トップアマチュアを6 名使い 60 局の 棋譜,総手数11526 手の局面に対する囲碁用語を調べている. これらの用語の中から,「ツケ」,「トビツケ」,「ハサミツケ」など類似の用語を同一 のものとして分類し直したものが表1である.なお,表1の中の「点」とは,盤上の 絶対的位置としての「星」「天元」「小目」「目はずし」「高目」「三々」を指す.本研究 では,この表1から,出現比率の高いものから順に,出現比率0.5%以上のもの 36 個 の用語を対象とすることにした. 表1 囲碁用語と出現比率(宍戸ら,2015 より引用)
37 これらの囲碁用語を見ると,単純に石の位置関係のみで表現できるものと,石の勢 力や死活判定,地の推定などといった局面解析を必要とするものに分類されることが 確認された.以下では,それぞれの分類について,説明する.
位置関係による分類
対象とする用語を位置関係により分類した.大別すると表2 のように以下の 4 つに 分けられる. 1) 石の絶対位置…「天元」「星」「小目」などの囲碁盤面上の絶対的な位置を表 す用語. 2) 自分の石同士の関係…「トビ」「コスミ」など,自分の石の相対的な位置関係 を表す用語. 3) 自分の石と相手の石との相対的な関係…「ツケ」「デ」「ハサミ」など,自分 の石と相手の石との相対的な位置関係を表す用語. 4) その他…「アタリ」「ヌキ」など,直接的な相手の石を捕獲に関連する用語.局面の解析対象による分類
研究で対象とする36 個の用語の中で,上述の位置関係だけで表現できない用語が 表2 囲碁用語の位置関係による分類38 11 個あった.これらの囲碁用語を判別するためには,局面の解析が必要となる.そこ で,必要となる囲碁局面の解析内容をもとに,以下3 種類に分類した. a) 石の死活判定:特定の石に関する死活判定. b) 列の進出の判定:特定の縦横線に対し,石がその線に沿って進出しているか 否かに関わる判定. c) 地の所属の推定:特定の範囲に対し,その地がどちらの地になる可能性が高 いかに関わる推定. プロ棋士へのインタビューなども行って,囲碁用語と必要となる局面解析の対応関 係をまとめたものを表3 に示す. 提案システム 提案システムは,図3 のように,大別すると「用語抽出部」「用語表示部」の二つの 表3 囲碁用語と必要となる局面解析の対応関係
39 部分から構成される.提案システムに,GOGUI という囲碁のユーザーインターフェ ースにより,棋譜という形で局面とそれに対する着手が入力されると,石の絶対的な 位置,及び石の繋がりや相対的な位置関係がルールベースによるパターンマッチング で判断される.それと同時に囲碁プログラム「Ray」が呼び出され,モンテカルロオ ーナーの値が与えられる.用語抽出部では,これらの情報にもとづいて局面解析を行 い,対応する囲碁用語が同定される.囲碁用語が同定されれば,用語表示部では,確 定した囲碁用語に対応する視覚的な表示を実現していく.以下では各部について詳し く説明する.
囲碁用語抽出部
囲碁用語抽出部では,石の位置関係と囲碁プログラム「Ray」のモンテカルロオー ナーの値を合わせて,局面解析が行われ,対応する囲碁用語が抽出される.石の位置 関係のみからルールベースによって用語が判別されるものと,局面解析による分類が 必要とされる用語の二種類がある.ここでは,本研究で重要な局面解析として,「石の 死活判定」,「列の進出の判定」,「地の所属の推定」の3種類を用いた用語判別につい て,それぞれ説明する. 図3 提案システムの概要40 特定の石の死活判定:特定の石の死活判定は,「無条件生き」「無条件死」「先手で 死」の3つに分けられる.判定方法は,以下のように二段階に分けて行われる. 段階1:自分の手番であるとして,ある相手の石が殺せそうかどうかを判定する. その石が殺せそうかどうかは,打った後のその位置のモンテカルロオーナーの値を調 べて,その符号で判定する.自分の手番でも相手の地になる確率が高ければ(相手の 色の符号と一致)「無条件生き」と判定される.そうでなければ(自分の色の符号と一 致),段階2に進む. 段階2:次に相手の手番だとして,その石が生きるかどうかを調べてみる.相手の 手番でも自分の地になる確率(自分の色の符号と一致)が高ければ,「無条件死」と判 定される.相手の手番で,相手の地になると判断された場合は,自分の手番なら死な ので「先手で死」と判断される. 判定メソッドは,以下のようになる. 判定条件:判定する石pの位置. 判定結果:判定する石の死活状態state_dead_or_alive(p). この二段階のアルゴリズムは以下となる: set turn( te ) == -s
If owner (MC Owner(𝑝,𝑡𝑒,turn( 𝑡𝑒 ))) == s
state_dead_or_alive(𝑝) =「無条件生き」 set turn( te ) == s
If owner (MC Owner(𝑝,𝑡𝑒,turn( 𝑡𝑒 ))) == -s
state_dead_or_alive(𝑝) =「無条件死」 else state_dead_or_alive(𝑝) =「先手で死」
41 手番(te):手数 te の手番(「自分」or「相手」)
p:判定する石の位置
s:判定する石の所属(「自分」or「相手」, -s はsの逆)
MC Owner(𝑝,𝑡𝑒, turn):手数 te,手番 turn の場合,判定する石の位置𝑝のモンテ カルロオーナー値
owner(MC Owner):MC Ownerの符号が表す所属(「自分」or「相手」)
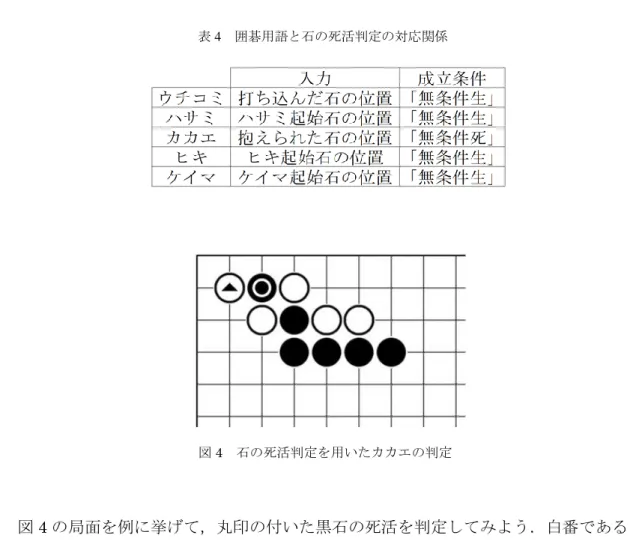
表3 に挙げた囲碁用語に対応する石の死活判定に必要な入力とその成立条件をまと めたものを表4 に示す. 図4 の局面を例に挙げて,丸印の付いた黒石の死活を判定してみよう.白番である として,モンテカルロオーナーの値を調べてみると,-56 となり,白地になる確率が 高い(白の色の符号と一致)と判断され,段階2 に進む.段階 2 では,黒番であると して,モンテカルロオーナーの値を調べる.それでも-14 と白地になる確率が高い 表 4 囲碁用語と石の死活判定の対応関係 図4 石の死活判定を用いたカカエの判定
42 (白の色の符号と一致)ので,「無条件死」と判断される. 位置情報のみから判定すると,図4 の三角の白の着手に対応している囲碁用語は 「カカエ」か「アタリ」である.「カカエ」の定義は「抱き抱えるように相手の一子を 取り込む形.相手の石をほぼ逃げられない形にする手のこと」とされている.そのた め,「カカエ」を判定するためには,抱き抱えられた丸印の黒石の死活判定が必要とな る.抱き抱えられた石が「無条件死」の場合,白の着手は「カカエ」であると判定さ れ,それ意外の場合は単なる「アタリ」と判定されるべきである.図4 の黒石は「無 条件死」と判定されるため,ここの白の着手は「カカエ」と判定される. 列の進出の判定:盤上のモンテカルロオーナーの値は,一手着手するごとに変化す る.列の進出とは基本的に石の強い勢力から,弱い勢力に侵入するため,進出先のモ ンテカルロオーナーの変化は進出元のより激しくなると考えられる.判定する線に沿 って,その石の位置からその両方向の値が変化しなくなる位置,もしくは盤端まで, その変化の差分を平均し,その2つの平均値を比較することで,石が線に沿って,進 出しているか否かの判定を行うことが出来る.その石の方向への平均値の変化の方が 大きければ,進出と判定される. 判定メソッドは,以下となる. 判定条件:判定する石の位置p と判定する列 line. 判定結果:判定する線p に沿って,進出しているかどうか state_line. アルゴリズムは以下となる:
MC_line_Diff(𝑝,𝑡𝑒,𝑙𝑖𝑛𝑒) = MC_line(𝑝,𝑡𝑒,𝑙𝑖𝑛𝑒) − MC_line(𝑝,𝑡𝑒 − 1,𝑙𝑖𝑛𝑒1) If |Mean(dir_out(p,MC_line_Diff)) |>|Mean(dir_in(p,MC_line_Diff)) |
state_line = 「進出」 else
43
te:手数
p:判定する石の位置
line:判定する列
MC_line(p,te,line):手数te、判定する列lineのモンテカルロロオーナー値の列 dir_in(p,MC_line) :line の進出方向(外側)のモンテカルロロオーナー値の列 dir_out(p,MC_line) : line の内側モンテカルロロオーナー値の列
表3 に挙げた囲碁用語と進出判定の局面解析の成立条件をまとめたものを表 5 に示 す. 例えば,図5(a)に対する(c)の黒石は水平の三線(盤の端から二番目の線)に向かっ て,進出しているか否かを判定するためには三線に着手の両側のモンテカルロオーナ ーの平均値の差分を比較することで判定できる.これもその方向への平均値の変化が 大きければ,進出と判定される.手数te,座標 p におけるモンテカルロオーナーの値 の差分Diff は以下の関係式で求められる.
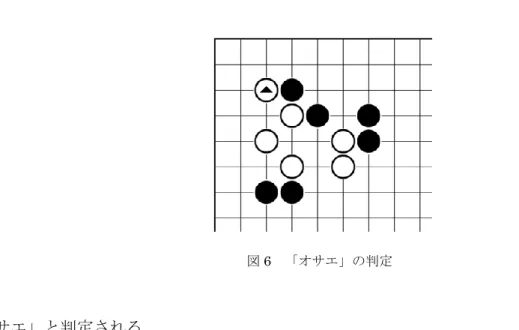
Diff(𝑝,𝑡𝑒) = MC Owner(𝑝,𝑡𝑒) − MC Owner(𝑝,𝑡𝑒 − 1) MC Owner(𝑝, 𝑡𝑒):手数 te,座標𝑝のモンテカルロオーナー値 図5 を例に挙げて説明しよう.三角の黒石が三線に沿った進出かどうかを判定する ため,三線のモンテカルロオーナーの値を調べる.このとき,調べる範囲は,盤端ま でか,打つ前後のモンテカルロオーナーの値の差分が0になる部分までとする.その 値は (b)と(d)のように示される.(d)の局面の場合,三角の黒石を打つ前後の三線のモ 表 5 囲碁用語と列の進出判定の対応関係
44 ンテカルロオーナーの値の差分は左側が{70,70,84},右側が{80,40,20,22}となり,三角 の黒を打つことにより,この黒石の左側の空間の平均値は右側の空間の平均値に比べ て大きくなったことがわかる.これは,左側は右側の空間より黒地になる確率は高く なったことを意味している.つまり,図5 の黒石は三線に沿って右側から左側へ進出 していることが判定できる. 位置情報だけから判定すると,図6 の三角の白の着手に対応している囲碁用語は 「オサエ」や「ハネ」が考えられる.「オサエ」の定義は「相手の石が進出してくるの を止めるように打つ手.形式としてはハネの形になるもの,マガリの形になるものな どが含まれる.あくまで進出を止めるニュアンスの手段の総称」である.そのため, 図6 の白の一手の「オサエ」の判定には,打つ前の局面(図 5(c))における黒の進出 方向を調べる必要がある.黒石は三線に沿って右側から左側へ進出しようとしてい (a) 一手前の局面 (b) 対応のモンテカルロオーナー (c) 現局面 (d) 対応のモンテカルロオーナー 図5 石の進出の判定
45 る.また,ここでこの白の着手はこの進出を止めているため,図6 の白の着手は「オ サエ」と判定される. 地の所属の推定:地の所属の推定は特定の範囲に対し,その地はどちらの地になる 可能性が高いかに関する推定のことである.本システムでは,範囲内の地のモンテカ ルロオーナーの値によって,地の所属を推定する. 判定メソッドは,以下となる. 判定条件:判断を行う範囲内の位置𝑝𝑛(1 ~ n). 判定結果:判断する範囲の所属state. アルゴリズムは以下となる: avg MC Owner(𝑝𝑛) = ∑𝑛𝑖=1MC Owner(𝑝𝑛) 𝑛
state(avg MC Owner)={黒(avg MC Owner > 0) 白(avg MC Owner < 0) 𝑛: 範囲内地の総数
p
𝑖: 𝑖番目の位置
state(MC Owner):MC Owner が表す所属