修士学位論文
題 名:
サポートベクターマシンを用いた格付と 倒産の予測
頁 1~ 15
指導教員:室町 幸雄
平成28年 1月12日提出
首都大学東京大学院
社会科学研究科経営学専攻
学修番号:14877228
氏
ふりがな名 :阿部 あ べ 巨 きよ 仁 ひと
サポートベクターマシンを用いた格付と倒産の予測
阿部 巨仁
∗2016 年 1 月 12 日
1 はじめに
企業の格付は格付会社が信用力をある一定の基準に基づき判断して、決定されている。その用途 は、金融機関では融資を実行するか否かの判断の要素として用いられるほか、貸付金の利率の決定 等にも用いられる。格付はA、B、C等の記号によって表現され、格付会社のアナリストが経営陣 とのミーティング、財務分析、業界分析等を行い、金融商品または企業・政府等の信用力をある一 定の基準に基づいて評価し決定している。つまり、格付は公開されている財務情報だけではなく、
非公開の情報を含んでいると考えられる。一方、その分析方法及び評価方法は非公開であり、格付 機関のアナリストの主観も入り得るため、企業に対する格付けが各格付企業によって異なることも ある [2] 。
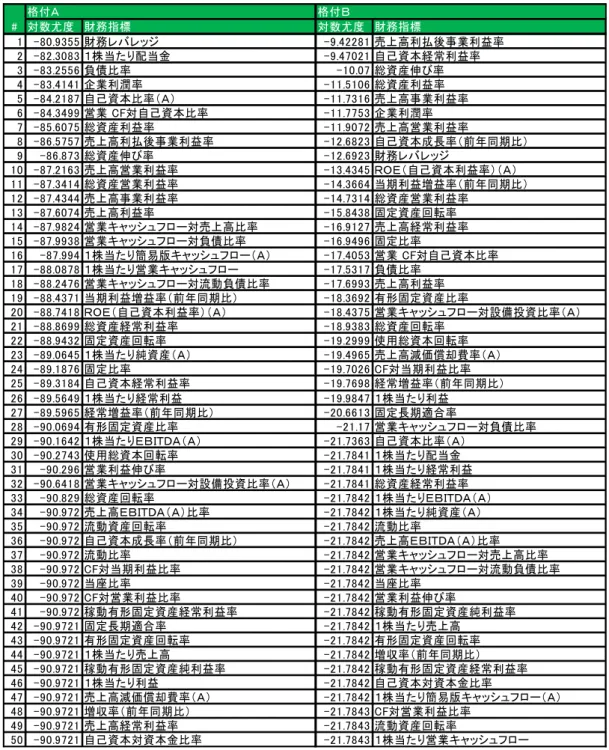
このような、不明確な情報を含むモデルは判別分析やロジスティック回帰分析を適用して構築す ることが考えられる。しかし、モデルを構築するにあたり目的変数と説明変数の間の関係式を仮定 する必要があるが、不明確な情報を含むがゆえ、定式化することが難しい。このような条件下にお いて、ニューラルネットワークやサポートベクターマシン等の学習の仕組みを含むモデルを適用し た研究も行われている。田辺、栗田、西田、鈴木 [1] では、 1,213 社の企業を対象に 11 年間のデー タを用いて、サポートベクターマシンを用いた格付モデルの有効性を検証しており、 86 %の正解 率となることを示した。また、田中、中川 [3] では、説明変数の取り方を定式化し、サポートベク ターマシンの背景にある凸2次計画問題を 1 次形式として表現し、解を近似している。
しかしながら、田中、中川 [3] における説明変数の選択方法には自由度が多く、条件を付与し定 型的なの係数の選択方法を行った。また、田辺、栗田、西田、鈴木 [1] 及び田中、中川 [3] では民事 再生や会社更生法の手続きを実施した企業に関しては分析していないため、この選択方法を用いた 説明変数にて倒産企業に対する予測モデルを構築し有効性の検証を行う。
当稿の構成は以下の通りである。まず、 2 節ではロジスティック回帰分析及びサポートベクター マシンについて説明し、 4 節で数値実験における準備及び結果を説明する。 5 節では数値実験の詳 細と結果を述べ、今後の研究について期待されることを述べる。
∗
首都大学東京社会科学研究科修士
2年
2 格付判別モデル
以下では企業数を H とし、 J 段階の格付けがなされているものとする。信用力は 1 が最も高 く、 J が最も低い。また、各企業は K 種類の財務データ x
i(i = 1, · · · , K ) で特徴付けられて いるものとし、格付け j ∈ { 1, ..., J } に含まれる企業の集合を M
jと表すことにする。つまり、
{ 1, ..., H } = M
1∪ M
2∪ ... ∪ M
Jかつ、 M
k∩ M
l= ∅ (k ̸ = l) とする 。
2.1 ロジットモデルによる格付判別モデル
信用スコアを表現するパラメータである係数ベクトルを a
i= (a
i,1, ..., a
i,K)
T∈ R とし、判別に 用いる閾値を τ = (τ
1, ..., τ
J−1) ∈ R
J−1、 τ
i−1≥ τ
i, i ∈ { 1, ..., J − 1 } 、 h が M
jに属するか否か を判別するための信用スコアを R
i(x
h) =
ta
ix
hとする。このパラメータ a
i, τ を推定するために 最尤推定法を用いる。
まず、企業 h が格付 j 以下に判別する確率 P
jは
P
j≡ p
j(x
h) = 1
1 + exp(−(
ta
ix
h+ τ
i)) , i ∈ { 1, ..., J − 1 } , j ∈ { 1, ...., J } で与えられる。
これを用いて、尤度関数 L(a
i, τ | δ
i,j) は、 p
h,j≡ p
j(x
h) とおくと、
L(a
i, τ | δ
i,j) =
∏
H h=1∏
J j=1p
δh,jh,jのように与えられる。
なお、 δ
h,jはクロネッカーの δ を表し、企業 h が格付け M
jに属する場合は 1 、属さない場合は 0 を表す。上記を用いて、対数尤度関数 logL(a
i, τ | δ
i,j) を最大化したものをロジットモデルと呼 ぶ。つまり
max log L(a
i, τ | δ
i,j) =
∑
H h=1∑
J j=1δ
h,jlog(p
h,j) (1)
s.t. a
i, τ, i ∈ { 1, ..., J − 1 } (2)
J 個の格付に分類するために逐次ロジットモデルを使用する。逐次ロジットモデルは二項ロジッ
トを繰り返し用いるモデルである。具体的には、まず全企業に対して二項ロジットモデルを用い
R
1(x
h) の係数パラメータ a
1と判別閾値 τ
1を推定し、 M
1に属するか判別する。次に M
1に属さ
ないと判別した企業に対して再び二項ロジットモデルを用いて R
2(x
h) の係数パラメータ a
2と判
別閾値 τ
2を推定し、 M
2に属するか否かを判別する。この手順を一般化したものが以下である。
p
hj=
P
1, if j = 1
(
j
∏
−1 m=1(1 − P
m))P
j, if j = 2, ..., J − 1
j
∏
−1 m=1(1 − P
m), if j = J
2.2 サポートベクターマシンによる格付判別モデル
企業 h の格付 j ∈ { 1, ..., J } に対して、格付けが j 以下か j より大きいかに注目し、集合 M
Uj= ∪
ip=1M
pを以下のように定義する。
{
a
1x
h1+ ・・・ + a
kx
hk+ b ≥ 0 ⇒ h ∈ M
Uja
1x
h1+ ・・・ + a
kx
hk+ b < 0 ⇒ h / ∈ M
Uj( ≡ M
Lj)
この時 a
1x
1+ ・・・ + a
kx
h+ b = 0 を満たす集合を超平面と呼ぶ。次に、企業 h に対する信用ス コア R
j(x
h) を定義する。
R
j(x
h) = a
1x
h1+ ・・・ + a
kx
hk+ b これより、 h ∈ {1, 2, ..., H} に対して
y
h=
1 h ∈ M
Uj1 h ∈ M
Uj− 1 h / ∈ M
Ujとすると、正しくモデルが判断できているかは以下のように表現できる。
{
y
h(a
1x
h1+ ・・・ + a
kx
hk+ b) ≥ 0 ⇒正しい判断 y
h(a
1x
h1+ ・・・ + a
kx
hk+ b) < 0 ⇒誤った判断 正しく判別できているかは y
hの取り方より、以下とできる。
y
h(a
1x
h1+ ・・・ + a
kx
hk+ b) ≥ 1, k = 1, ..., H 全ての点が正しい判断ができるとき、線形分離可能と呼ぶ。
さらに、各企業を表す点 x
hと超平面の距離は以下のように表現できる。ただし、 < · , · > は内 積を表す。
y
h(a
1x
h1+ ・・・ + a
kx
hk+ b)
√ a
21+ ・・・ + a
2k= y
h(< a
Tj, x
h> +b)
| a
j|
2特に、各企業のうち超平面との距離が最小となる点 i に対して、超平面との距離が最大となるよ う a
j, b を求めたものをハードマージンサポートベクターマシンと呼ぶ。
max
aj,b{ min
h
{ y
h(< a
j, x
h> +b)
| a
j|
2} : y
h(< a
j, x
h> +b) ≥ 1, h = 1, ..., H } これは、以下の凸二次計画問題に書き下せる。
min | a
j|
2s.t. a
jx
h+ b ≥ 1, h ∈ M
Uja
jx
h+ b ≤ − 1, h / ∈ M
Uj一方、財務情報による格付が常に線型分離可能であるとは限らない。正しく判別できない企業 が含まれるデータを取り扱う前提でのモデル上の工夫が必要となる。そのため、スラック変数 ξ
h∈ R , h ∈ { 1, ..., H } を導入し、 C(> 0) をペナルティパラメータとおく。以下をソフトマージン サポートベクターマシンと呼ぶ。
min 1
2 | a
j|
2+ C
∑
H h=1ξ
hs.t. a
jx
h+ b + ξ
h≥ 1, h ∈ M
Uja
jx
h+ b − ξ
h≤ − 1, h / ∈ M
Ujξ
h≥ 0, h ∈ { 1, ..., H }
このような二次計画問題に対しては双対問題を考えることが自然である。 α, β ∈ R
Hを双対変 数とし α
h∈ α, β
h∈ β とおくと、ラグランジュ関数 L(a, b, α, β) は
L(a, b, α, β) = 1
2 |a
j|
2+ C
∑
H h=1ξ
1h−
∑
H h=1α
h(y
h(< a
j, x
h> +b) − 1 + ξ
h) −
∑
H h=1β
hξ
h(3)
となる。そのKKT条件( Karush-Kuhn-Tucker 条件)は以下のように書き下せる。
∇
αL(a, b, α, β) = α − 1 2
∑
H h=1α
hy
hx
h= 0 (4)
∇
bL(a, b, α, β) =
∑
H h=1α
hy
h= 0 (5)
∇
ξhL(a, b, α, β) = C − α
h− β
h= 0 (6) y
h(< a
j, x
h> +b) − 1 + ξ
h) ≥ 0 (7) α
h(y
h(< a
j, x
h> +b) − 1 + ξ
h) = 0 (8)
β
hξ
h= 0 (9)
α
h≥ 0, a
h≥ 0, ξ
h≥ 0 (10)
ただし、式 (6) から各式 (10) は h ∈ { 1, · · · , H } に対して成立する。これにより、双対問題は
max − 1 2
∑
H h∑
H iα
hα
iy
hy
i< x
h, x
i> +
∑
H h=1α
h(11)
s.t. 0 ≤ α
h≤ C, h = 1, · · · , H (12) となる。
式 (11) の内積表現に着目しカーネル法を適用することで、説明変数を高次元に写像し超平面に より線形分離できることが知られている [6] 。これをカーネルトリックと呼ぶ。以下は、 2 つの説明 変数 x
1, x
2によって表される信用スコアを格付 A 、 B によって分類されている場合に 3 次元に埋 め込むことで線形分離を可能とする例である。
カーネル法の適用により、式 (11) は写像 ϕ と内積表記 K( · , · ) (カーネル関数と呼ぶ)を用いて 以下のように書き下せる。
max − 1 2
∑
H h∑
H iα
hα
iy
hy
iK(ϕ(x
h), ϕ(x
i)) +
∑
H h=1α
hs.t. 0 ≤ α
h≤ C, h = 1, · · · , H ただし、カーネル関数は以下の定理を満たす必要がある [7] 。
定理 2.1 ( Mercer の定理) X を R
Nのコンパクトな部分集合、 K : X × X → R を連続かつ対称 (K(x, y) = K(y, x) な関数とする。この時、 L
2を二乗可積分な集合とし
∀f ∈ L
2(X) に対して、
積分差要素 T
K: L
2→ L
2(T
Kf ))(˙) =
∫
X
K(˙ ,xf (x)dx が正であると仮定する。すなわち、
∫
X×X