卒業研究報告書
Java による PRAM コンパイラの作成
指 導 教 員
石水 隆 助手
03-1-47-162
神谷 道利
近畿大学理工学部情報学科
平成
19
年2
月5
日提出概要
様々な分野で計算量の大きな問題を短時間で解く事が求められている。計算速度を向 上させる方法としてはプロセッサの性能の向上、アルゴリズムの最適化等が存在するが それぞれには限界が存在するため一定以上の向上が見受けられなくなってきている。そ こで現在ではプロセッサの並列処理による高速化が注目されている。
並列処理とは、ある問題を解く際、その問題をより小さい複数の部分問題に分割し、
その部分問題を複数のプロセッサで解く処理である。並列処理を行うことにより、単一 のプロセッサによる逐次処理よりも高速に問題を解くことができ、またより複雑な問題 を解く事ができる。
しかし、並列計算機は非常に高価であるため、並列アルゴリズムの設計およびその計
算量の解析を実際の並列計算機を用いて実験的に行うことは困難である。そこで、本研
究では並列アルゴリズムの実験的評価を容易化するツールである PRAM シミュレータ
の一部として PRAM コンパイラを作成する。
目次
1 序論 ... 1
1.1 本研究の背景 ... 1
1.2 本研究の目的 ... 3
1.3 本報告書の構成 ... 3
2 研究内容 ... 4
2.1 PRAM 用並列言語 ... 4
2.2 並列アセンブラ ... 4
2.3 PRAM コンパイラ ... 5
3 結果 ... 6
4 考察・今後の課題 ... 7
5 謝辞 ... 8
付録 1 K05
言語の文法... 10付録 2 K05
言語の文法...11付録 3 VSM
アセンブラの文法... 12付録 4 PRAM
コンパイラプログラム... 141 序論
1.1 本研究の背景 1.1.1 並列処理
様々な分野で高速な計算機を用いて計算量の大きな問題を短時間でとくことが求められてい る。計算速度を上昇させるための方法の1つとしてプロセッサの性能の向上が考えられる。だが これには 3.0 × 10
7m/s という光速の限界が存在し現在の1万倍ほどしか速くすることができな い。またアルゴリズムの改良によって劇的な高速化が可能であるが、これには計算量の下界が存 在する。ソーティングを例にとった場合、クイックソートによる計算量の O(n log n) が下界とさ れ、これ以上の改良は不可能とされている。だが、並列処理を用いた場合そのような限界は本質 的に存在しない。
並列処理(Parallel Processing)とは、ある問題を解く際、その問題をより小さい複数の部分問 題に分割し、その部分問題を複数のプロセッサで解く処理である。並列処理を行うことにより、
単一のプロセッサによる逐次処理よりも高速に問題を解くことができ、またより複雑な問題を解 く事ができる。
しかし、並列処理を行うためにはプロセッサ間での通信や同期、メモリへのアクセスなど並列 独特の動きが必要となる。すなわち従来の逐次処理でのアルゴリズムを適応させることができな いため、並列処理専用の並列アルゴリズム (Parallel Algorithm) が必要となる。
1.1.2 並列計算機
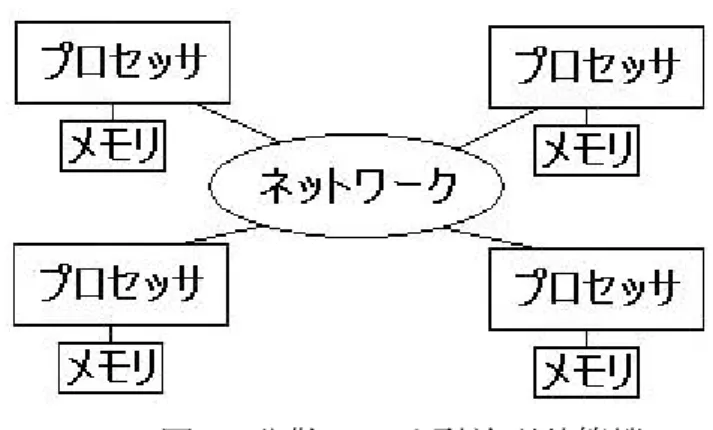
並列計算機(Parallel Computer)とは複数のプロセッサを持ち、並列処理を行える計算機であ る。並列計算機は大きく2つに分類される。図 1 のように全てのプロセッサが共通のメモリを 使用して読み書きを行い、他のプロセッサ間で通信を行う共有メモリ型並列計算機 (Shared Memory Parallel Computer) と、図 2 のように各プロセッサがそれぞれメモリを持ちネットワ ークを通じて通信を行う分散メモリ型並列計算機 (Distributed Memory Parallel Computer) で ある。
図 1 共有メモリ型並列計算機 図 2 分散メモリ型並列計算機
1.1.3 並列計算モデル
並 列 ア ル ゴ リ ズ ム の 設 計 、 解 析 は 、 並 列 計 算 機 を 抽 象 化 し た 並 列 計 算 モ デ ル (Parallel Computing Model) 上で行われる。代表的な並列計算モデルとして PRAM(Parallel Random Access Machine)、Mesh、HyperCube、BSP(Bulk Synchronous Parallel)などがある。
1.1.4 PRAM
並列アルゴリズムの設計およびその計算量の評価は多くの場合 PRAM(Parallel Random Access Machine)[2] 上で行われる。
PRAM は共有メモリ型の並列計算モデルである。 PRAM は演算命令、メモリアクセス命令、
出力命令、全てのがその移動に関係なく1単位時間で行われる、1命令ごとに同期が取られる、
通信のコストが一切発生しない、等の仮定が設けられた理想的なモデルであるため、 PRAM 上 ではアルゴリズムの設計および評価を比較的容易に行う事ができる。しかし実際の大規模なプロ セッサでのメモリ共有や、通信、プロセッサ間の同期の高速化は非常に困難であるため、 PRAM アルゴリズムの実験的な評価を行うために PRAM シミュレータが必要となる
1.1.5 PRAM シミュレータ
PRAM アルゴリズムの実行をシミュレートする PRAM シミュレータは以下の4要素から成 る① PRAM 用並列言語②並列アセンブラ③ PRAM コンパイラ④ PVSM ( Parallel Virtual Stack Machine ) 。以下にそれぞれの説明を記す。
① 並列命令に対応した高級言語。
② 並列命令に対応したアセンブリコード。
③ ①の PRAM 用並列言語を②の並列アセンブリコードに変換するコンパイラ。
④ 並列アセンブラを実行するインタプリタ。
図 3 に PRAM シミュレータの実行の流れを示す。
ユーザは PRAM 用並列言語を用いて PRAM 用並列言語アルゴリズムを記述する。次に PRAM 用並列言語プログラムを PRAM コンパイラを用いて並列アセンブラプログラムに変換 し PVSM を用いて並列アセンブラプログラムを実行することにより PRAM アルゴリズムの実 行をシミュレートできる。
図 3 PRAMシミュレータによる実行の流れ
1.2 本研究の目的
本研究では JAVA 言語を用いて PRAM シミュレータの一部である PRAM コンパイラの設計を 行う。本研究で作成した PRAM コンパイラは PRAM 用並列言語に拡張した K05 言語で書かれ たソースプログラムを、スタック上での演算機能を備えた仮想計算機(Virtual Stack Machine)
のアセンブラコードに翻訳することができる。並列アセンブラプログラムを PVSM で実行する ことにより、 PRAM 用並列言語プログラムを PRAM 上で動作させた場合の出力および実行時間 を測定でき、 PRAM アルゴリズムの計算量を実験的に評価することができる。
1.3 本報告書の構成
本報告書の構成を以下に述べる。 2 章では、本研究で作成した PRAM コンパイラについて述
べる。 3 章では、 PRAM コンパイラの検証を行う。またいくつかのプログラムを実行すること
により作成したコンパイラの正当性を検証する。4 章では、3 章の結果を得た上で今後の課題
を示す。
2 研究内容
2.1 PRAM 用並列言語
本研究で使用する PRAM 用並列言語は、 JAVA 風の手続き言語である。この言語は付録 1 に示 す K05 言語を並列処理に対応するように拡張した拡張 K05 言語である。拡張 K05 言語は K05 言語に並列処理を行う parallel 文および特殊記号「 $p 」を追加したものである。 parallel 文の 書式を以下に示す。
parallel (式1 , 式2)文
式1、 式2は int 型の評価値を持つ式であり、 文は parallel を含まない任意の文である。 parallel 文はプロセッサ番号式1から式2までのプロセッサを用いて後ろに続く文を並列に実行する。ま た文中に特殊記号「$p」を記述すると「$p」は実行中のプロセッサ番号の値を持つ変数として 処理される。
拡張 K05 言語プログラムは、0番目のプロセッサのみが命令を実行する逐次状態と parallel 文により指定された複数のプロセッサが命令を実行する並列状態を持つ。プログラム開始時は逐 次状態で開始し、 parallel 命令によって並列状態に移行し、文が終了すればまた逐次状態へ移行 して実行する。付録 2 に拡張 K05 言語の文法を示す。
2.2 並列アセンブラ
本研究で使用する並列アセンブラは付録 3 に示す VSM アセンブラを並列処理に対応させるよ うに拡張した拡張 VSM アセンブラである。拡張 VSM アセンブラは VSM アセンブラの命令セ ットに「 PARA 」 「 SYNC 」 「 PUSHP 」を加えたものである。各命令の働きを以下に示す。
PARA ・・・・並列状態開始命令。逐次状態から並列状態へと移行する。
SYNC ・・・・同期命令。並列状態の時プロセッサ間で同期を取り逐次状態に移行する。
PUSHP・・・プロセッサ番号挿入命令。スタックに命令を実行しているプロセッサのプロセッ
サ番号を入れる。
2.3 PRAM コンパイラ
コンパイラとは高水準言語 (high level programming language) で書かれたプログラムを計算 機が実現可能な形式へ変換する変換機である。本研究では高水準言語である拡張 K05 言語を低 級言語である拡張 VSM アセンブラに変換する。以下に本研究で作成した PRAM コンパイラの 構成を示す。
① 字句解析部
原始プログラムを読み、空白や記号等で区切り単語を生成する。
② 構文解析部
字句解析で得た単語の文法的な関係をまとめ、分類する。
③ 制約検索部
プログラムから型情報を抽出し、使用時に矛盾がないかを調べる。
④ コード生成部
上記の情報を元にアセンブラコードを生成する。
付録 4 に本研究で作成した PRAM コンパイラプログラムを示す。以下に本研究で作成した PRAM コンパイラの使用方法を示す。
foo.k を PRAM 用並列アルゴリズム言語によって記述された PRAM 用アルゴリズムとする。
以下のコマンドを実行すると、 foo.k が並列アセンブラに変換され、 outputfile に出力される。
Outputfile を省略した場合は OpCode.asm に出力される。
> java Pram foo.k [outputfile]
PRAM コンパイラにより生成された並列アセンブラは PVSM インタプリタにより実行される。
以下に PVSM インタプリタの使用方法を示す。
foo.asm を拡張 VSM アセンブラとする。以下のコマンドにより foo.asm が PVSM により実 行される
> java Pvsm [-c] [foo.asm]
ファイル名 foo.asm を省略したときは OpCode.asm が実行される。
また、実行時にオプション-c を指定することにより、拡張 K05 言語で書かれた PRAM プログ
ラムを PRAM 上で実行したときの PRAM で実行したときの実行時間を計測できる。
3 結果
本研究は、 作成したコンパイラの正当性を検証するため、 簡単な PRAM プログラムを作成し、
それが正しくコンパイルされているか検証を行う。図 4 に拡張 K05 言語によるプログラム例を 示す。
図 4 拡張 K05 言語プログラム
図 4 のプログラム例はプロセッサ番号 0 番から 15 番までのプロセッサが実行中のプロセッサ 番号の値を持つ変数として処理され、並列に実行するというプログラムである。本研究で作成さ れたコンパイラにより図 4 のプログラムは図 5 に示す拡張 VSM アセンブラに変換される。
図 5 拡張 VSM アセンブラプログラム
図 5 の拡張 VSM アセンブラを PVSM で実行することにより図 6 に示す実行結果が得られる。
図 6 PVSM インタプリタの実行結果
以上の結果から、本研究で作成した PRAM コンパイラは正しくコンパイルされ、並列処理さ
れた結果が出力される事を確認した。また PVSM インタプリタの出力により、図 4 のプログラ
ムを PRAM 上に実行させたときの実行時間を測定できる。
4 考察・今後の課題
本研究では並列アルゴリズムの設計、正当性の証明、およびその計算量の評価を実験的に行う ためのツールである PRAM シミュレータの一部として PRAM コンパイラを作成した。また PRAM アルゴリズムを記述できる拡張 K05 言語および拡張 VSM アセンブラを作成した。本研 究で作成した PRAM コンパイラを用いることにより PRAM アルゴリズムの設計、正当性の証 明、およびその計算量の評価を実験的に行うことが出来る。
しかし今回作成したシミュレータには対応していない JAVA 言語の命令が多数存在する。また
parallel 文中で parallel を使用できない構造になっている。よってこれらに対応させてさらに多
様なアルゴリズムに対応させることが今後の課題である。
5 謝辞
本研究を行うにあたり、並列処理の基礎から自分たちの研究内容まで様々なご指導ご鞭撻をい
ただき、石水隆助手には誠に感謝しております。また同じ研究を目的とした共同研究者の板東俊
助君、池田直樹君には様々な相談にものって頂き、深い感謝、敬愛の気持ちを表します
。参考文献
[1]
平成17年度第5セメスター 情報・コンピュータシステムプロジェクトⅠ指導書[2] Joseph JáJá:”An Introduction to Parallel Algorithms”, Addison-Wesley(1992)
付録1 K05
言語の文法<Program>::=<Main_fanction>
<Main_fanction>::= ”main” “(” “)”<Block>
<Block>::= “{” { <Var_decl> } { <Statement> } “}”
<Var_decl>::= (“int” | “boolean”) NAME [ “[” INT”]” ] {“,” NAME [ “[“ INT “]” ] } “;”
<Statement>::= <If_statement> | <While_statement> | <Assignment>
| <Write_statement> | <Writechar_statement>
| “{” { <Statement> } “}” | “;”
<If_statement>::= “(” <Expression> “)” <Statement>
<While_statement> :: = “while” “(” <Expression> “)” <Statement>
<Assignment>::= <Lefthand_side> “=” <Expression> “;”
<Writeint_statement>::= “writeint” “(” <Expression> “)” “;”
<Writechar_statement>::= “writechar””(” <Expression> “)” “;”
<Lefthand_side>::= NAME | NAME “[” <Expression> “]”
<Expression> ::= <Logical_term> { “||“ <Logical_term> }
<Logical_term> ::= <Logical_factor> { “&&“ <Logical_factor> }
<Logical_factor> ::= <Arithmetic_expression>
| <Arithmetic_expression> “==“ <Arithmetic_expression>
| <Arithmetic_expression> “!=“ <Arithmetic_expression>
| <Arithmetic_expression> “<“ <Arithmetic_expression>
| <Arithmetic_expression> “<=“ <Arithmetic_expression>
| <Arithmetic_expression> “>“ <Arithmetic_expression>
| <Arithmetic_expression> “>=“ <Arithmetic_expression>
<Arithmetic_expression> ::= <Arithmetic_term> { ( “+“ | “-“) <Arithmetic_term> }
<Arithmetic_term> ::= <Arithmetic_factor> { ( “*“ | “/“ | “%“) <Arithmetic_factor> }
<Arithmetic_factor> ::= <Unsigned_factor> | “!“ <Arithmetic_factor>
| “-“ <Arithmetic_factor>
<Unsigned_factor> ::= NAME | NAME “[” <Expression> “]“ | INT | CHAR
| “(“ <Expression> “)“ | “readint“ | “readchar“ | “true“ | “false“
付録2
拡張K05
言語の文法<Program>::=<Main_fanction>
<Main_fanction>::= ”main” “(” “)”<Block>
<Block>::= “{” { <Var_decl> } { <Statement> } “}”
<Var_decl>::= (“int” | “boolean”) NAME [ “[” INT”]” ] {“,” NAME [ “[“ INT “]” ] } “;”
<Statement>::= <If_statement> | <While_statement> | <Para_statement>
|<Assignment>| <Write_statement>
| <Writechar_statement>| “{” { <Statement> } “}” | “;”
<If_statement>::= “(” <Expression> “)” <Statement>
<While_statement> :: = “while” “(” <Expression> “)” <Statement>
<Para_statement>::= “parallel” “(” <Expression> “,” <Expression> “)” <Statement>
<Assignment>::= <Lefthand_side> “=” <Expression> “;”
<Writeint_statement>::= “writeint” “(” <Expression> “)” “;”
<Writechar_statement>::= “writechar””(” <Expression> “)” “;”
<Lefthand_side>::= NAME | NAME “[” <Expressi
<Expression> ::= <Logical_term> { “||“ <Logical_term> }
<Logical_term> ::= <Logical_factor> { “&&“ <Logical_factor> }
<Logical_factor> ::= <Arithmetic_expression>
| <Arithmetic_expression> “==“ <Arithmetic_expression>
| <Arithmetic_expression> “!=“ <Arithmetic_expression>
| <Arithmetic_expression> “<“ <Arithmetic_expression>
| <Arithmetic_expression> “<=“ <Arithmetic_expression>
| <Arithmetic_expression> “>“ <Arithmetic_expression>
| <Arithmetic_expression> “>=“ <Arithmetic_expression>
<Arithmetic_expression> ::= <Arithmetic_term> { ( “+“ | “-“) <Arithmetic_term> }
<Arithmetic_term> ::= <Arithmetic_factor> { ( “*“ | “/“ | “%“) <Arithmetic_factor> }
<Arithmetic_factor> ::= <Unsigned_factor> | “!“ <Arithmetic_factor>
| “-“ <Arithmetic_factor>
<Unsigned_factor> ::= NAME | NAME “[” <Expression> “]“ | INT | CHAR
|”$p”| “(“ <Expression> “)“ | “readint“ | “readchar“ | “true“ | “false“
付録3 VSM アセンブラの文法
ASSGN:
addr = Stack [--SP];
Dseg[addr] = Stack[SP] = Stack [SP+1];
ADD: BINOP(+);
SUM: BINOP(-);
MUL: BINOP(*);
DIV:
If (Stack[SP] == 0) {
printf(“Zero divider detected¥n”);
return -2;
}
BINOP(¥);
MOD:
If (Stack[SP] == 0) {
printf(“Zero divider detected¥n”);
return -2;
}
BINOP(%);
CSIGN: Stack [SP] = -Stack[SP];
AND: BINOP(&&);
OR: BINOP(||);
NOT: Stack [SP] = !Stack [SP];
COPY: ++SP; Stack [SP] = Stack [SP-1];
PUSH: Stack [++SP] = Dseg[addr];
PUSHI: Stack [++SP] = addr;
REMOVE: --SP;
POP: Dseg[addr] = Stack[SP--];
INC: Stack [SP] = ++ Stack [SP];
DEC: Stack [SP] = -- Stack [SP];
COMP:
Stack [SP-1] = Stack [SP-1] > Stack [SP] ? 1:
Stack [SP-1] < Stack [SP] ? -1 0;
SP--;
BLT: if (Stack [SP--] < 0) Pctr = addr;
BLE: if (Stack [SP--] <= 0) Pctr = addr;
BEQ: if (Stack [SP--] == 0) Pctr = addr;
BNE: if (Stack [SP--] != 0) Pctr = addr;
BGE: if (Stack [SP--] >= 0) Pctr = addr;
BGT: if (Stack [SP--] > 0) Pctr = addr;
JUMP: Pctr = addr;
HALT: return 0;
INPUT: scanf(“%d%*c”, &Stack[++SP]);
INPUTC:scanf(“%c%*c”, &Stack[++SP]);
OUTPUT:printf(“%15d¥n”, Stack [SP--]
OUTPUTC:printf(“%15c¥n”, Stack [SP--]
LOAD: Stack [SP] = Dseg[Stack [SP]];
付録4 PRAM コンパイラプログラム
本研究用いた