1
カスケードモデルからの少数ルール群選択による
高性能分類器の構築
Building of High-Performance Classifier by Rule Selection from Cascade Model
大村 隆晴 中野 優 岡田 孝
Takaharu Ohmura
Yu Nakano Takashi Okada
関西学院大学 理工学研究科 情報科学専攻
Department of Informatics, Graduate School of Science and Technology, Kwansei Gakuin University
The characteristic rule induction usually produces a large number of rules, and it is difficult for a user to inspect all
rules. This paper describes a method to give a priority index to rules based on their supporting instances, and it guides
a user to inspect the most useful rule successively. The priority index is calculated dynamically at each step of rule set
inspection using the covered instances by the employed rules, and the resulting rule group obtained gives a concise
understanding to the data of the target class.
1. はじめに
近年,様々な分野で大量のデータから有用な知識を発掘するデ ータマイニングが行われている.これまでに,ニューラルネット ワークや SVM(Support Vector Machine),アンサンブル学習やラン ダムフォレストなどの高性能な分類器が考案されてきた.しかし, 精度が向上するにつれて分類器は複雑になり,理解性に欠ける. 一般に,ルールの理解性と分類器の精度は相反するものとして捉 えられているが,本来これらの両立が望ましいことは当然である. データマイニングの代表的な手法として,相関ルール導出[1][2] が挙げられる.その IF-THEN 形式のルールは領域専門家にとっ て可読性が高く,簡潔な表現形式としてその有用性が論じられて いる.相関ルール導出は同時性や関係性が強い事象間の関係を導 出する.この手法の主要な強みは網羅性であり,ユーザが設定し た最小支持度と最小確信度の制約を満たす,すべての相関関係を 導き出す.しかし,この強みは非常に膨大なルールを出力すると いう大きな欠点にもなり,その数は数千から数万件になる場合も ある.この問題点は,特に高い相関性がある属性対を持つデータ セットに対して顕著に現れる.また相関ルールは,支持度,確信 度,Lift 値などの多くのルール評価パラメータが存在し,ルール の評価や整理が一元化できない.
相関ルールを利用した Emerging Pattern(以下 EP)[1][2]は,C5.0 などこれまでに考案された分類器と遜色ない精度を示し,その有 効性が示されてきた.しかし,依然としてそのパターン数は多い. 本研究室ではクラス相関ルールの拡張であるカスケードモデル [3][4]を提案している.これは特徴的ルール導出と呼ばれ,現在デ ータマイニングの主要な技法の1つとなっている.カスケードモ デルはアイテムセットのラティスを構築し,Gini Index を応用し た群間平方和(BSS: Between groups sum of squares)を用いてリンク の識別力を定量化する.それにより,アイテムセットラティスの 識別力が大きいリンクをルールとして提示する.また識別力は単 一パラメータで提示され,これによりルールを最適化するため, 出力されるルール数は相関ルールに比べて 1/10~1/100 と少なく なる.しかし依然として出力ルールは数十個あり,解析の負担と なる.またカスケードモデルは分類器となっていないため,事例 予測が不可能である.そこで本研究では,高精度で現実的に視察 可能な少数ルール群を導出し,高性能な分類器の構築を行う. 連絡先:大村 隆晴,関西学院大学 理工学研究科 情報科学専攻 〒669-1337 兵庫県三田市学園 1-2,Tel:079-565-8149 [email protected]
2. 先行研究
2.1. カスケードモデル
相関ルールの問題点を解決するため,本研究室ではカスケード モデルを提案している.カスケードモデルはアイテムセットのラ ティスを構築し,ラティス内で識別力の高いリンクをルールとし て提示する.例えば,説明変数 A,B,目的変数 Z とする表 1 の サンプルデータを考える.ただし,アイテムは[属性:値]の形式 を考え,本論文では[値]で表す.このとき,長さ 3 のアイテムセ ットラティスは図 1 で与えられ,ノードに目的変数の分布 Z(y/n) を付加する. 表1 サンプルデータ[ ]
5/3[a2 b1 c1]
4/0[b1 c1]
4/1[a2 c1]
4/0[a2 b1]
4/0[c1]
4/3[b1]
4/1[a2]
5/0 図1 アイテムセットラティス このモデルは,水力発電の発電原理と同じように考えることが できる.すなわち,ラティス内の各節点とその間のリンクを池と その間の滝と見なす.ここで各池の高度はポテンシャルを表し, その節点をサポートする事例群でのクラスの純度により定まる. また,滝の流量は滝下側の池のサポート事例数である. 図 2 において強いパワーを有する滝を選択し,Gini による平方 和をもとにルールとして表現する.通常の数値変数における平方 和の定義が,各事例対間の距離の二乗和に等しい.さらに,カテ ゴリ変数値対に対して,それらが同一値を取るか否かにより距離 として 0, 1 を与えるならば,式(1)により平方和が定義できる.こ れから導かれるカテゴリーデータに対する分散は,Gini index と して知られている.全事例をいくつかの群に分けたとき,この c1 c1 c1 c1 c2 c1 c1 c1 C y y n n y n y y Z b1 a2 b1 a2 b2 a1 b1 a1 b2 a2 b2 a1 b1 a2 b1 a2 B A c1 c1 c1 c1 c2 c1 c1 c1 C y y n n y n y y Z b1 a2 b1 a2 b2 a1 b1 a1 b2 a2 b2 a1 b1 a2 b1 a2 B A 117 人工知能学会研究会資料 SIG-DMSM-A803-17 (3/4)2
BSS=0.05
BSS=0.45
(0.5 0.5) → (0.6 0.4)
A (a1, a2):
THEN
(0.5 0.5) → (0.2 0.8)
Y (p, n):
THEN
IF [b2] ADDED ON [ ]
Rule Support Case 8 → 5
BSS=0.05
BSS=0.45
(0.5 0.5) → (0.6 0.4)
A (a1, a2):
THEN
(0.5 0.5) → (0.2 0.8)
Y (p, n):
THEN
IF [b2] ADDED ON [ ]
Rule Support Case 8 → 5
Gini による平方和は式 (2)に示 すよ うに ,群内 平方 和( WSS: Within-group sum of squares)と群間平方和(BSS: Between-groups sum of squares)に分解できる.BSS の定義は式(3)で与えられる.
( )
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − =∑
a i i p a n SS 1 2 2(1)
(
)
∑
+
=
g g i g i iWSS
BSS
TSS
(2)
( )
( )
(
)
22
∑
−
=
a U i L i L g ip
a
p
a
n
BSS
(3)
ただし,pi(a)は属性 i の値が a である確率を示し,g は分割後の 各群を指定する.また,U は分割前の節点,L は分割後の節点を 表す.ここで,カテゴリー変数に対する平方和から導かれる分散 を節点のポテンシャルと考え,リンク毎に定義される BSS をその パワーとすれば,ポテンシャルやパワーを定義することができる. 図 2 カスケードモデルの概念図 ここで,図 1 のノード[ ]と[b2]の間のリンクに注目した場合, 図 3 のルールが得られる.前提条件の ADDED ON 節にラティス の上側節点,主条件の IF 節にリンクに付加されるアイテムを記 す.また THEN 節は目的変数と付加相関の分布変化と BSS が記 される.ただし付加相関は主条件適用後に大きな分布変化を示す 説明変数群とする.実際に BSS 順にルールを適用すると表 1 のデ ータから 14 ルールが導出され,精度 87.5%の分類器が構築された. 図 3 カスケードモデルのルール表現2.2. Emerging Pattern
Eerging Pattern[6][7][11](以下 EP)は itemset のクラス別サポート 数の比を計算し,どちらかのクラスに分布が偏るようなパターン である.パターンの特徴度は,次に示す GrowthRate(GR)を用いる. sup_y(X),sup_n(X)はそれぞれ目的変数値が y/n のデータセットに 対する itemset X のサポート比を示す.
sup_y(X) / sup_n(X)
GR(X) = 0
if sup_n(X)=0 and sup_y(X)=0
∞
if sup_n(X)=0 and sup_y(X)≠0
表 1 のサンプルデータで GR を求めると以下の様になる.(1) { (A=a2) }
sup_y(X2)=5/5,sup_n(X2)=0/3
∴ GR(X2) = (5/5)/(0/3) = ∞
(2) { (B=b2) }
sup_y(X3)=1/5,sup_n(X3)=2/3
∴ GR(X3) = (2/3)/(1/5) = 3.33
この例で,itemset{(A=a2)}は GR が∞で Z=y に特徴的であり, itemset{(B=b2)}は GR が 3.33 で Z=n に特徴的な EP である.一般 には,閾値(default:1.0)を上回る EP を抽出し,分類ルールの候補 として採用する.実際に GR 順にルールを適用すると,表 1 のデ ータから 21 ルールが導出され,精度 75.0%の分類器が構築された.3. ルール群最適化
本研究では,2 種のルール群最適化手法を提案する.一つはル ールの新規性に注目した優先度によるルール選択,他方は広範囲 に探索お行う Genetic Algorithm(以下 GA)によるルール選択である. これに第 2 節で述べた 2 種のルール導出法(カスケードモデル, EP)を組み合わせ,表 2 に示す 4 種の分類器を構築し比較を行う. 表2 ルール導出手法とルール群最適化手法の組み合わせ カスケードモデル EP ルール優先度 CM:priority EP:priority GA CM:GA EP:GA3.1. ルール優先度による選択
図 4 の四角形は,あるデータセットの事例全体を現している. 目的変数は T と F の値を取り,その分布に対応して四角形が左右 に区切られている.図 4(a)は,既得ルール Rule1 がサポートする 事例を示す.候補ルールとして,図 4 (b)の Rule2,図 4 (c)の Rule3 が挙げられるとする.このとき,次に Rule2,Rule3 のいずれを採 用するべきであろうか. (a) Rule1 (b) Rule1+Rule2 (c) Rule1+Rule3 図 4 ルールによる事例サポートの様子 ルールに優先順位を決定する際,重要な要因として,精度が挙 げられる.精度の低いルールは,信頼性が低いため,それ自身で は有用ではないからである.また,データ全体を効率よく視察す る目的で,ルールにある一定以上の精度が得られるとき,候補ル ールが満たす新規事例数も重要な要因である.なぜなら,新しい 情報をより多く含むルールの優先度は高くなるべきであると考 えられるからである. ここで,精度と新規事例数の点で,R2 と R3 を比較する.図 4 の(b)より, R2 は R3 より高い精度を持つが,R1 と重複する事例 を多く満たすことが分かる.すなわち,R2 は R1 とほとんど同じ 事例に対する特徴を示しており,新たな情報が少ないと考えられ る.一方,図 4 の(c)より,R3 は R2 より精度は低いが,R1 と重 複しない事例をより多く満たすことが分かる.すなわち R1 で表 現されていない事例の特徴を,R2 より多く表現していると言え る.この問題を解決するため,ルールの新規性と分類識別力を取 り入れたルール優先度を明確に設定する必要がある.3.1.1. 定義
特徴的ルール導出により得られたルールの総数を L,既得ルー ルを R:{R1,R2,…Ri,…Rk}(1≦i≦k),候補ルールを Rj(k<j≦L)とす る.候補ルールが満たす事例 m に対して, 既得ルール群が満た す事例と重なる事例(Overlap),重ならない事例(¬Overlap)に分け, さらにそれらを学習に用いられた目的変数のカテゴリ別に分け る.同様に,候補ルールが満たさない事例 n に対しても同じ処理 を行い,得られた度数を表 3 に示す.また,度数表の変数と既得 T F T F T F Rule1 が満たす事例 候補ルール Rule2, Rule3 が満たす事例 1183
ルール図,候補ルール図との関係をそれぞれ図 5,図 6 に示す 表3 事例度数表 R={R1,R2…Rk} T F Sum ¬Overlap mNT/nNT mNF/nNF mN/nN Overlap mOT/nOT mOF/nOF mO/nO Rj /¬Rj (k<j≦L) Sum mT/nT mF/nF m/n nNT nNF mT+nOT mF+nOF T F 図 5 既得ルール図と変数の関係 nNT nNF mNT mNF mOT mOF nOT nOF T F 図 6 候補ルール図と変数の関係3.1.2. 新規度
新規度を,既得ルール群で満たされていない事例をより多く満 たす尺度と定義する.ルール新規度を以下の式(4)のように設定す る.カスケードモデルと EP 両手法とも同様に適用する.m
m
m
Novelty
=
TF+
NF(4)
3.1.3. 分布変化度
特徴的ルール導出に使用されたデータセットのクラスに偏り がある場合,ルールの精度だけでは,候補ルールが満たす事例の クラス分布と元データセットのクラス分布の変化を評価できな い.例えば,目的クラス T,F の分布が T:F=1:9 であるデータセ ットを仮定する.このとき,データセットはクラス F である事例 数が多く,クラス F に対する精度が高いルールが多く導出される と考えられる.しかし,そのようなルールが満たす事例は,デー タセットのクラス分布に非常に大きな影響を受けており,既知で ある内容を表現するルールである場合が多い. 以上の点を考慮に入れ,分布変化度をルールの精度が高く,元 のデータセットに対する目的クラス分布と,支持する事例に対す る目的クラス分布の変化が大きいという尺度と定義する.分布変 化度を設定するにあたり,カスケードモデルでは群間平方和 (BSS)を参考にし,EP では GR を用いる.カスケードモデルでの 分布変化度を式(5)に示す. 2 2 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + − + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + − = n m n m m m n m n m m m Strength T T T F F F(5)
式(5)は,候補ルールが満たす事例のクラス分布の割合と,全て の事例のクラス分布の割合から,クラス分布の変化を評価してい る.以上がカスケードモデルからの分布変化度の設定である. 次に EP での分布変化度を説明する.EP で導出されるパターン の特徴度である GR は,目的クラスそれぞれにおける事例支持の 割合の比であるため,例えば,目的クラス T,F の分布が T:F=1:9 であるデータセットを仮定しても,クラス T に対する精度が高い ルールも十分に導出され得る.また,EP はカスケードモデルと は違い,データセットの大局的な相関をルールとして導出してい るので,EP での分布変化度を式(6)と定義する.1
Rate
Growth
Rate
Growth
+
=
Strength
(6)
3.1.4. ルール優先度の設定
ルール優先度を新規度と分布変化度,支持事例数の積で表現し, 式(7)に示す.最も優先度が高いルールを選択し,ルール群へ付加 する.新規度はルール視察が進むにつれて必然的に小さな値にな る.すなわち,既得ルール群と同じような事例を満たすルールの 優先度は低くなり,類似ルールの重複視察を防ぐことができる.Priority = Novelty・Strength・Support
(7)
ルール群への付加が行われる毎に新規度の更新を行い,候補ル ールの新規度が最小閾値(default:0.1)を下回らない限りルール選 択を繰り返す.分類予測の際にテスト事例がルール群のどのルー ルにも支持されない場合,データセットの majority で予測する.3.2. Genetic Algorithm による選択
GA は解の候補を遺伝子で表現した個体を複数用意し,適応度 の高い個体を優先的に選択して遺伝的操作を繰り返しながら解 を探索する手法である.遺伝的操作は二点交叉と突然変異を用い る.候補ルール群から最適なルール選択状況を導出し,分類器に 適用する.評価関数は精度を,パラメータには表 4 の値を用いる. 表4 GA パラメータ 世代数 20 個体数 50 交叉率 0.9 突然変異率 0.14. 計算実験
以上の提案手法をプログラミング言語 Python により実装した. 本節では,テストデータを用いた計算実験の結果を提示する.た だし,計算機環境は CPU3.33GHz,メモリ 2.0GB の PC であり, OS は Windows Server 2003 R2 とする. テストデータを用いて 4 種の分類器の計算結果を比較し,カス ケードモデルからのルール群最適化が良いパフォーマンスを得 ているか検証する.データセットによって最適なパラメータが異 なるため,最小支持度,threshold は default 値を中心にパラメータ を変化させながら計算し,最適な結果を採用する.その他のパラ メータは default 値を使用する.4 種の分類器の他に,決定木(C5.0) の結果を付記した.なお,GA は表上部 6 データセットについて のみ記述し.精度は 10-fold Cross Varidation で算出した.また, 全てのデータセットに対する平均(Average(all))と,高精度を記録 した上位 4 データセットに対する平均(Average(top 4))も求めた.4.1. 精度比較
表 5 より,GA は全6件中 4 件について最も高い精度であった. 少数ルール群選択による分類器がほとんど C5.0 などと遜色のな い精度であることがわかる.また,C5.0 よりも高精度であったの は,全 16 件中 8 件であり,およそ半数のデータセットに関して は,高精度なルール群最適化を行うことができている.さらに, 全 16 件中 7 件に関して全ての分類器中最も精度が高かった.ま た Nursery データに関しては C5.0 より精度が悪く,ルール群最適 化がうまく行えていない可能性がある.GA 分類器に関して初期 収束などの理由で探索が十分に行われなかったため,よい結果が 得られなかった場合も考えられる.これは今後の課題とする. T F T F 1194
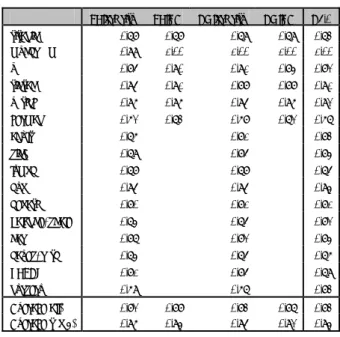
表 5 精度比較結果
EP:priority EP:GA CM:priority CM:GA C5.0
titanic 0.78 0.78 0.79 0.79 0.73 muchroom 0.99 1.00 1.00 1.00 1.00 zoo 0.85 0.90 0.91 0.84 0.82 tictac 0.95 0.91 0.88 0.88 0.91 voting 0.96 0.96 0.95 0.96 0.92 german 0.62 0.73 0.68 0.72 0.67 adult 0.76 0.81 0.83 sick 0.79 0.85 0.84 lymph 0.78 0.78 0.75 hypo 0.95 0.95 0.94 hepati 0.80 0.81 0.81 balance-scale 0.74 0.75 0.82 car 0.87 0.82 0.84 hayes-roth 0.74 0.75 0.76 SPECT 0.81 0.85 0.79 nursery 0.69 0.67 0.83 Average(all) 0.82 0.88 0.83 0.87 0.83 Average(top 4) 0.96 0.94 0.95 0.92 0.94
4.2. ルール数比較
ルール数の比較結果を表 6 に示す.表 5 と同様,GA 分類器は 表上部 6 データセットについてのみ記載する.表 6 より, CM:priority が半数以上のデータセットに対して最も少数なルー ル群選択を行えていることがわかる.C5.0 を用いた sick, hypo, hepati の分類では,ルールが生成されなかった.これはデータセ ットのクラス値の分布にもともと偏りがあるため,ルールを生成 せずに偏りがあるクラス値を予測値とした方が,精度が高い場合 であると思われる.しかし,解析者の立場からこれは有用ではな いと言える.その点本システムの分類器では少数ルール群が選択 されており,表 5 を参照してもある程度の精度が保たれている. GA に関しては,候補ルールが多数の場合は,視察可能な水準ま でルール選択が行き届かなかった.一方で CM:priority は安定して 少数ルール群選択が行えていた. 表 6 ルール数比較結果5. 結論
本研究では,少数ルール群選択による高性能分類器の構築を行 った.少数ルール群選択手法として,2 種のルール群最適化手法 を提案した.一方は新規度によるルール優先度の設定によるルー ル選択,他方は GA による広範囲探索による選択である.第 4 節 より,特にルール優先度によるルール群最適化が,ある程度精度 を保ったままの少数ルール群選択に成功した.またルール導出法 はカスケードモデルが,高精度を記録した.実際に分類器のルー ル群に注目しても,十分に視察可能な内容であり,本研究によっ てルール解析の負担を和らげることができると思われる.本研究 の課題として以下の点があげられる. z 目的変数,説明変数が数値属性の場合に対応していない. z GA の最適化戦略に改善を要する. z ルール最適化手法の計算時間がボトルネックとなっている. 本研究は,カテゴリーデータを対象としているため,数値属性 のデータを扱うことはできない.今回 GA の評価関数として精度 を用いたが,ルール数が少ない時により高い評価が得られる評価 関数の設定が必要である.また初期収束に対応し,ルール数が必 然的に少なくなるようなパラメータの設定と改良が必要である. ルール群最適化による計算時間短縮も今後の課題である.参考文献
[1] R. Agrawal; T. Imielinski; A. Swami, “Mining Association
Rules Between Sets of Items in Large Databases”,
SIGMOD Conference 1993, 207-216
[2] R. Agrawal and R. Srikant, “Fast Algorithms for Mining
Association Rules”, In Proceedings of the International
Conference on Very Large Data Bases, pp.487-499, 1994
[3] Takashi Okada, "Rule Induction in Cascade Model based
on Sum of Squares Decomposition", Principles of Data
Mining and Knowledge Discovery, PKDD pp.468-474,
1999.
[4] 岡田孝: "カスケードモデルとルール導出システム
DISCAS", 関 西 学 院 大 学 情 報 科 学 研 究 , Vol.15,
pp.31-44, (2000).
[5] 中野優, 岡田孝: “ルール群視察ガイドシステム”, The
20th Annual Conference of the Japanese Society for
Artificial Intelligence, 2006
[6] H.FAN: ”Effient Mining of Interesting Emerging Patterns
and Their Effective Use in Classification”, U.Melbourne,
May 2004
[7] Guozhu Dong, Jinyan Li, “Efficient Mining of Emerging
Patterns:Discovering Trends and Differences”, In
Proceedings of the fifth ACM SIGKDD international
conference on Knowledge discovery and data mining,
pp.43-52, 1999.
[8] Jiawei Han, Jian Pei, Yiwen Yin, “Mining Frequent
Patterns without Candidate Generation”, ACM SIGMOD
Record , Proceedings of the 2000 ACM SIGMOD
international conference on Management of data SIGMOD
'00, Volume 29 Issue 2
[9] G. Grahne, J. Zhu, “Efficiently Using Prefix-trees in
Mining Frequent Itemsets”, Proceeding of the First IEEE
ICMD Workshop on Frequent Itemset Mining
Implementations, 2003A
[10] Wonjae Lee, Hak-Young Kim, “Genetic Algorithm
Implementation in Python”, Proceedings of the Fourth
Annual ACIS International Conference on Computer and
Information Science (ICIS’05)
[11] Guozhu Dong, Xiuzhen Zhang, Limsson Wong, Jinyan Li,
“CAEP:Classification by Aggregating Emerging Patterns”,
In Discovery Science 99, LNAI 1721, Tokyo, Japan,
pp.30-42, 1999.
EP:priority EP:GA CM:priority CM:GA C5.0
titanic 2 12 4 17 7 muchroom 7 2856 4 3066 13 zoo 5 4372 2 66605 14 tictac 26 464 7 78 122 voting 2 2956 6 3183 2 german 4 1538 4 365 91 adult 3 7 128 sick 5 3 0 lymph 9 3 16 hypo 2 2 0 hepati 4 3 0 balance-scale 3 8 84 car 5 4 115 hayes-roth 9 5 16 SPECT 4 3 12 nursery 4 3 332 Average(all) 6 2033 4 12219 60 Average(top 4) 9 2662 4 18233 34 120