Rendaku as a stochastic phonological alternation: Multiple OCP constraints and MaxEnt
INTRODUCTION: Phonotactic judgment patterns have long been known to be stochastic; i.e. it is not either a matter of yes-grammatical or not-grammatical (Greenberg & Jenkins 1960 et seq.). One well-known case is the pattern of similarity avoidance, found in many Semitic languages, in which pairs of similar adjacent consonants are disfavored, and the more similar the pairs are, the more disfavored they are (Frisch et al. 2004). Less well-established whether phonological alternations can show patterned, systematic variations. Recent work shows that some vowel harmony patterns show such patterned systematic variations (Hayes & Londe 2006 for Hungarian; McPherson & Hayes 2016 for Tommo So).
This talk explores the systematic stochastic nature of rendaku, a well-studied Japanese morphophonological pattern observed in compounding, in which the initial segments of the second member of a compound get voiced (e.g. /nise+tako/ → /nise+dako/ “big octopus”). In this talk we build upon Kawahara & Sano’s (2016) recent work which shows that Identitiy Avoidance constraints apply stochastically to the application of rendaku in nonce words. Our experiment shows that the more similar pairs of segments rendaku creates in nonce words, the less likely rendaku is to apply; that is, gradient similarity avoidance (Frisch et al. 2004) is at work in shaping the patterning of rendaku. We show that these stochastic patterns naturally follow from a MaxEnt grammar (Hayes & Wilson 2006), if we posit multiple OCP constraints (Coetzee & Pater 2008). Overall, we show that knowledge of phonological alternation can be stochastic and systematic, and that a MaxEnt grammar is a usable tool to model it.
METHOD: The current experiment builds upon Kawahara & Sano (2016). They show that Japanese speakers avoid creating identical consonants in adjacent moras (e.g., schematically, */iga+gomoke/ from /iga/+/komoke/). Furthermore, they show that the applicability of rendaku is even more reduced when rendaku results in adjacent identical CV moras (e.g., schematically, */iga+ganiro/ from /iga/+/kaniro/). These results exemplify a case in which the more similar strings of segments rendaku creates, the more likely it is avoided.
The current experiment tests this thesis from a slightly different angle. Rendaku turns /h/ into /b/. Kawahara et al. (2006) argue that rendaku is inhibited in /h…m…/ words, because it would result in the output configuration /b…m…/, which involves two adjacent labial consonants; i.e. the effects of OCP(lab). This experiment tested whether this constraint is psychologically real, and also whether /h…ɸ…/ and /h…w…/ words avoid rendaku, because their outcomes also involve two adjacent labial consonants. For the sake of simplicity, we report only a subset of the data (Anonymous 2016 for a full report).
The experiment thus had four conditions. The first consonant was always /h/. The second consonants were either /m/, /ɸ/, /w/, or /r/, the last of which is a control (e.g., /hamara/ vs. /haΦura/ vs. /hawara/ vs. /haraha/). There were three items for each condition by varying the first vowel. Participants were 61 naive native speakers of Japanese. In the test, they were told that the words were used in Old Japanese, and were given two forms (yes-rendaku or no-rendaku) for each nonce word. They were then asked to choose which of the forms is more natural than the other if tested words are attached to /nise/ “fake” (e.g., given /nise/ + /hamara/, would you say /nisehamara/ or /nisebamara/?).
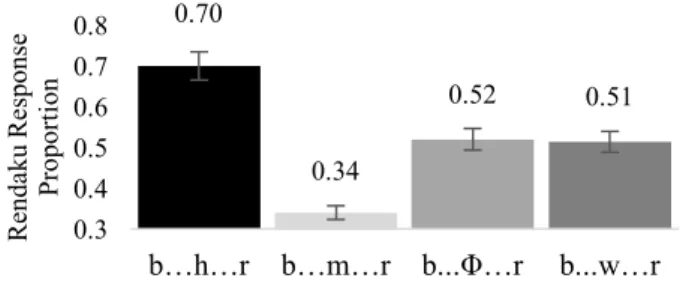
RESULTS: Figure 1 shows rendaku responses for each condition. The control condition, which violates no OCP(lab), shows 70% of rendaku responses. All the other conditions that violate OCP(lab) show lower rendaku responses (/b…h/ vs. /b…m/: χ2(1)= 47.7, p < .001; /b…h/ vs. /b…Φ/: χ2(1)= 12.5, p < .001; /b…h/ vs. /b…w/: χ2(1)= 13.2, p < .001, all statistically significant at p<.001 level). Among those, /b…m…/ is avoided most often, which is different from the /b…ɸ.../ condition and the /b…w…/ condition ([b…m] vs. [b…Φ]: χ2(1)= 12.147, p < .001; [b…m] vs. [b…w]: χ2(1)= 11.44, p < .001).
Figure 1: Rendaku response percentages for each condition.
MAXENT ANALYSIS:The results show that OCP(lab) is active on the patterning of rendaku. Moreover, the fact that /b…m…/ is more disfavored than /b… ɸ…/ and /b…w…/ can be accounted for if we posit OCP(lab,
0.70
0.34
0.52 0.51
0.3 0.4 0.5 0.6 0.7 0.8
b…h…r b…m…r b...Φ…r b...w…r Rendaku Response Proportion
Rendaku as a stochastic phonological alternation: Multiple OCP constraints and MaxEnt
-cont), which targets only /b…m…/ (Coetzee & Pater 2008). To model the stochastic nature of the results, we fitted a MaxEnt grammar (Hayes & Wilson 2006). MaxEnt is like Optimality Theory, in which there are various candidates, and they are evaluated by a set of constraints; unlike OT, however, the constraints are weighted (rather than ranked). For each candidate, weighted constraint violations are summed, which is its H(armonic)-score. H-score is mapped to probabilities in such a way that P(candi)=exp(H(candi)), relativized to the other candidates so that all probabilities sum to 1. We used a MaxEnt grammar tool (Hayes 2009) to implement the analysis, which yielded optimal weights for each constraint.
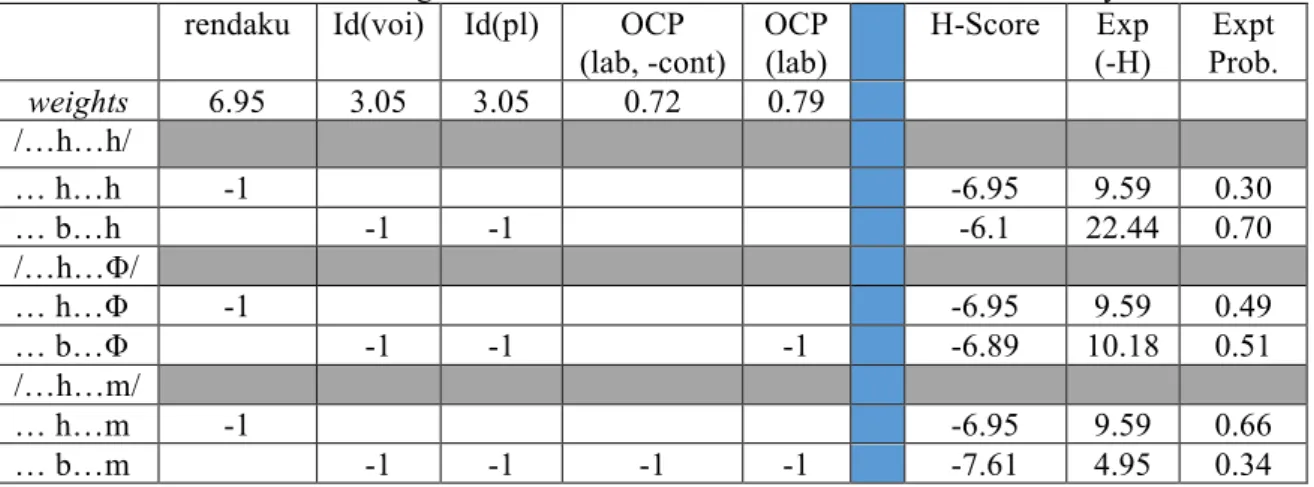
Table 1 shows constraint violation profiles on the left. The second raw shows the constraint weights which were obtained based on the MaxEnt analysis. The right three columns show the results, including the expected probabilities in the rightmost column.
Table 1: Constraint violation profiles on the left. The calculated constraint weights are shown on the second raw. The right three columns show the results of the MaxEnt analysis.
rendaku Id(voi) Id(pl) OCP (lab, -cont)
OCP (lab)
H-Score Exp (-H)
Expt Prob.
weights 6.95 3.05 3.05 0.72 0.79
/…h…h/
… h…h -1 -6.95 9.59 0.30
… b…h -1 -1 -6.1 22.44 0.70
/…h…Φ/
… h…Φ -1 -6.95 9.59 0.49
… b…Φ -1 -1 -1 -6.89 10.18 0.51
/…h…m/
… h…m -1 -6.95 9.59 0.66
… b…m -1 -1 -1 -1 -7.61 4.95 0.34
We observe a very good fit between the observed probabilities and expected probabilities (Figure 1 and the rightmost column in Table 1). Although the weights for the OCP constraints are rather low, they nevertheless account for the lower probabilities of rendaku which would violate these constraints.
As an addendum, we also modelled the effects of Identity Avoidance effects reported by Kawahara & Sano (2016). In their results, rendaku applies 26% of the time when it violates OCP(CV) (e.g. /igaganiro/), 39% of the time when it violates OCP(C) (/igagomoke/), 45% of the time when it does not violate any OCP constraints. The MaxEnt learner could learn these patterns with success, once we posit multiple OCP constraints; the predicted probabilities are almost identical to the observed probabilities.
Table 2: A MaxEnt analysis of Kawahara & Sano (2016) rendaku Id(voi) OCP
(CV)
OCP (C)
H-Score Exp (-H)
Expt Prob.
weights 4.89 5.1 0.60 0.24
/…pa+ta…/
…pata… -1 -4.89 1.58 0.55
… pada… -1 -5.1 1.63 0.45
/…ga+ko…/
…gako… -1 -4.89 1.58 0.61
…gago… -1 -1 -5.34 1.68 0.39
/…ga+ka…/
… gaka -1 -4.89 1.58 0.74
… gaga… -1 -1 -1 -5.69 1.74 0.26
CONCLUSION: In summary, we show that (i) rendaku shows systematic probabilistic variation, (ii) in such a way that both OCP(lab) and OCP(lab, -cont) affects the applicability of rendaku, and that (iii) a MaxEnt grammar is a useful to model such stochastic patterns. Overall, it adds to the growing body of the literature showing that phonological knowledge can be stochastic (Hayes & Londe 2006).