The 28th Annual Conference of the Japanese Society for Artificial Intelligence, 2014
1D3-1
多目的最適化法によ る 適切な モデル群の探索
Exploring statistical model spaces using multiobjective genetic algorithms techniques
松香敏彦
∗1 Toshihiko Matsuka∗1
千葉大学
Chiba University
1.
はじ めに
統計モデルの多く は学説や理論を 基に 構築さ れ、 データ と の適合度によ っ て、 モデルやその基と なっ た理論の妥当性が検
証さ れて き た。 対象と な る 統計モデルが1つの場合は、 統計
的に有意な結果が得ら れた場合に、 そのモデルの統計的妥当性 ( も し く は、 統計的非妥当性の可能性は低いと いう 結果) が示 さ れたこ と になる 。 例えば、 分散分析や回帰分析などでは、 従 属変数中の分散を 独立変数で説明でき る 割合が有意に高いモデ ル、 loglinear analysisnなどでは、 モデルの予測値と 観測さ れ たデータ が有意に乖離し ないモデルなどが妥当なモデルだと さ
れる 。 複数のモデルを 比較する 際は、 AICな ど のよ う に 単な
る データ と の適合度ではなく 、 モデルの複雑性を 加味し 、 よ り 汎化能力の高いモデルを 採択する こ と が一般的である 。 どち ら
の方法も 、 最終的には1つ、 も し く はごく 少数のモデルを「 適
切」 なモデルと し て採択し 、 その解析結果から 変数間の関係や 構造を 理解・ 考察する こ と が一般的である 。 こ れら の統計モデ ルによ っ て 様々 な 学説や理論が検証さ れ科学は発展し て き た。 一方で、 逆のア プロ ーチと し て データ を 基に 複数の適切な モデルを 探索し 、 新たな仮説を 生成する アプロ ーチも 考えら れ る 。 本研究では進化アルゴリ ズムを 基礎と し た多目的最適化法
[Deb, 01]を 用いて モデルスペースを 探索し 、 複数の適切な モ デル群を 探索・ 識別する 例を 紹介する 。
1.1
多目的最適化法
新たな 仮説の生成を 目的と し たデータ 解析と し て 、 複数 の適切な モデル群を 識別する ために は、 複数の目的関数が必 要と な る 。 こ れら の複数の目的関数を 総合的に 評価する こ と
に よ っ て 、 Pareto-optimalな モデル集合、 つま り 、 各モデル
は他のどのモデルにも 支配さ れない「 適切なモデル群」 を 識別
する こ と が可能と なる 。 図1はPareto-optimalな解集合の例
である 。 こ れは、 20の独立変数を 持つ回帰モデルの
Pareto-optimalな 集合であり 、 目的関数は学習データ への適合度( X
軸: adjusted R2) と 新規テ ス ト データ に おけ る 誤差( Y軸:
Sum of Squared Residual) である 。 つま り 、 図1はモデルの ( 学習データ への) 適合度と 汎化能力を 目的と し た場合の適切
な モデル群を 表し て いる 。
こ の例では、 複雑度と 誤差の2つを 目的関数と し たが、 目的
関数は2つ以上であれば、 ど のよ う な モデルの評価の指標で
あっ て も 、 ま たいく つ用いて も ( 確率的) に Pareto-optimal
な 解集合を 識別する こ と が可能である 。
連絡先:松香敏彦, 千葉大学文学部, 263-8522千葉県千葉市
稲毛区弥生町1.33, 043.290.3578 (Voice), 043.290.2278
(Fax), [email protected]
0.6 0.8 1 1.2 1.4 1.6 1.8 2 x 104 0
0.1 0.2 0.3 0.4 0.5
Adjusted Rsq
Sum of Squared Residual
図1: 実験1Aの結果、 X軸は学習データ におけ る 適合度、 Y
軸はテスト データ におけ る 誤差を 示し て いる 。
2.
実験
多目的最適化法によ る モデル探索の有用性を 検証する ため、
2つの実験を おこ なっ た。 実験1では生成さ れたデータ を 基に
回帰モデルを 探索し 、 実験2では実データ を 基に 、 共分散構
造分析モデルの探索を おこ な っ た。
2.1
実験
1
実験1では、 生成さ れたデータ から 、 進化アルゴリ ズムを 用
いた多目的最適化法(MOGA)を 用いて、 適切な回帰モデル群
を 探索する 。 データ は20の一様分布(a=0,b=1)に 従う 説明
変数から な り 、 そ の内10変数を 用いて 目的変数を 生成し た。
目的変数と 従属の関係に ある 説明変数の回帰係数も 一様分布
(a=10,b=15)に従う も のを 用いた。 説明変数と 関係のない目的
変数の独自の要素は正規分布に従う も のと し た(µ= 0,σ= 10)。
実験1Aでは、 目的関数を 学習データ における 適合度(Adjusted
R2)と テスト データ における 誤差(SSR)と し 、 実験1Bでは、
目的関数を ベースモデル(目的変数と 従属関係にある10の説明
変数の内5 変数を 含むモデル) と の距離とSSRと し た。 実験
1A、 1B共に、 学習データ は120、 テスト データ は80と し た。
2.1.1 結果
図1は実験1Aの結果であり 、 学習データ における 適合度と
テスト データ におけ る 誤差を 目的関数と し たpareto-optimial
な回帰モデル群である こ と を 示し ている 。 図2は、 こ れら のモ
デル群がどのよ う に定義さ れている かを 表し ている 。 図3は実
験1Bの結果であり 、 ベースモデルと は異な る ( 距離のある )
汎化能力のある モデル群を 模索する のに有益な情報と なっ てい る こ と が分かる 。
The 28th Annual Conference of the Japanese Society for Artificial Intelligence, 2014
0 10 20 30 40 50 60 70 80 90 100 0
5 10 15 20
Model Numbers
Variables
図2: 実験1Aの結果:モデル定義。 X軸はSSRの低い順序で
並べたモデルを 表し て いて 、 Y軸はモデルに おけ る 各変数の
有無を 表し ている 。 SSR値の低いモデルでは変数1 10の含有
率が高く 、 SSR値の高いモデルでは、 変数12と 16の含有率
が高い。
0 1 2 3 4 5 6
7000 8000 9000 10000 11000
Distance
Sum of Squared Residual
図3: 実験1Bの結果。 X軸はベースモデルから の距離
(city-block distance)、 Y軸はテス ト データ に おけ る 誤差を 示し て
いる 。 ベースモデルに4 6変数を 変更する こ と によ っ て、 大幅
にモデルの汎化能力を 強化でき る こ と が分かる 。
表1: 実験2の結果: モデルの定義
Model F V1 V2 V3 V4 V5 V6 F2 Model1 F1 X X X X X
F2 X X X X −
Model2 F1 X X X X X
F2 X X X −
Model3 F1 X X X X
F2 X X X −
Model4 F1 X X X X
F2 X X X −
Model5 F1 X X X X X X
F2 X X X X −
Model6 F1 X X X X X X
F2 X X X −
Model7 F1 X X X X X
F2 X X X −
Model8 F1 X X X X X
F2 X X −
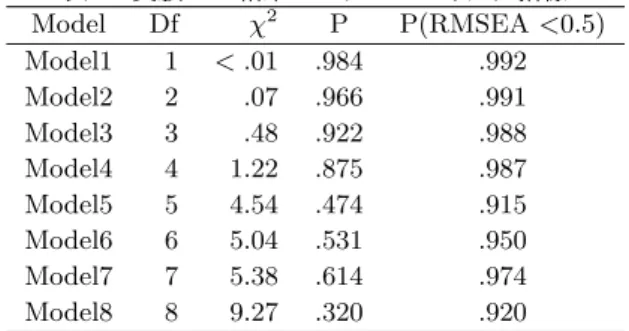
表2: 実験2の結果: モデルのフ ィッ ト 指標
Model Df χ2 P P(RMSEA<0.5)
Model1 1 < .01 .984 .992 Model2 2 .07 .966 .991 Model3 3 .48 .922 .988 Model4 4 1.22 .875 .987 Model5 5 4.54 .474 .915 Model6 6 5.04 .531 .950 Model7 7 5.38 .614 .974 Model8 8 9.27 .320 .920
2.2
実験
2
実験2では、 実データ を 基に共分散構造分析を 探索的におこ
な っ た。 共分散構造分析の入門書[Kenny,98]にある 、 中学生
556名の教育に関する 6 つ顕在変数から な る データ を 用いた。
変数の詳細は本研究の目的と の関連性が低いため省略する 。 実
験1と 同様に、 MOGAを 用いて 適切な モデル群を 探索し た。
目的関数は複雑度( Df:自由度) と データ と の適合性( χ2値)
を 用いた。 一世代の人口を30と し 、1000世代の進化アルゴリ
ズムによ る 探索を おこ なっ た。 顕在変数の数が6 つと いう こ と から 、 パラ メ タ ーの同定問題な ど を 踏ま え 、 因子の数は最大
2つま でと し た。
2.2.1 結果
表1と 2は、 30モデルの内、 モデルで再現さ れた共分散行
列と データ から 得ら れた共分散行列の乖離が統計的に 有意で な いも の、 つま り 、 統計的に 有意な モデルを 示し て いる 。 表
1はモデルの定義を 表し て おり ( Fは因子、 Vは顕在変数) 、
Xの有無が因子と 顕在変数、 因子間の関係の有無を 示し て い
る 。 表2はそ れぞれのモデルのデータ と の適合性を 表す指標
を 示し ている 。 なお、 こ のデータ を 解析し たオリ ジナルの研究
[Kenny,98]では、 表に ある Model8が採用さ れて いた。 自由 度の値の近いモデル間では比較的似たモデルも ある が、 全体と し て多様な統計的に有意なモデルを 探索する こ と 可能である こ と が示さ れた。 つま り 、 学説や理論から モデルを 定義する ので はなく 、 データ から モデル探索を 介し 、 仮説や学説を 導く 可能 性が示唆さ れた。
因子分析やパス解析など、 共分散構造分析では同一のモデル を 複数の異な っ た定義で表現する こ と が可能である 。 例え ば、
Model8 の場合、 因子間の相関を 排除し て も 、F1と V5およ
びF1と V6 に 従属関係がある と し た場合も Model8と 全く
同じ 説明力を も つ同意義モデルと なる 。 実験2においても 、 あ
る 複雑度において、 複数の同意義モデルが得ら れた。 こ のよ う な一見異なっ てみえる が、 実は同一のモデルである など、 モデ ル定義によ る モデル間の距離だけで多様性を 扱う には注意が必 要である 。
参考文献
[Deb 01] Deb K.Multi-objective optimisation using evolu-tionary algorithmsWiley, Chichester. (201).
[Kenny 98] Kenny, R. B.,Principles and Practice of struc-tural equation modelling. Guilford, NY. (1991).