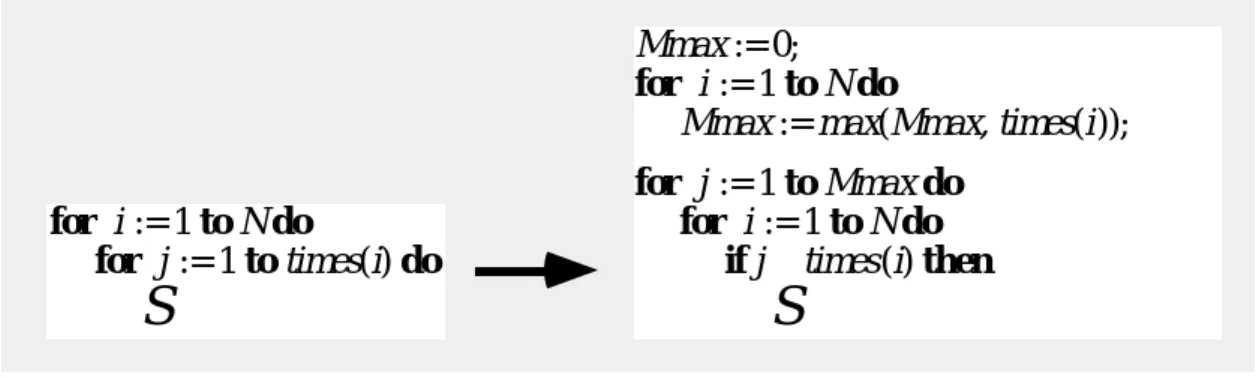
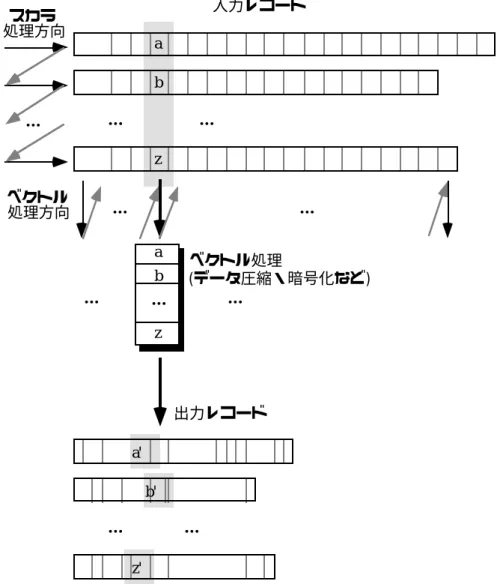
これをプログラムに変換すると図のようになります。 3.2(1.2)。図4.1 構造交換の繰り返しに適したベクトル処理の例:データ変換(変換後のプログラムもスカラー処理の形で示しています)。この方法は2.をベースにしています。
配列線形検索への適用例
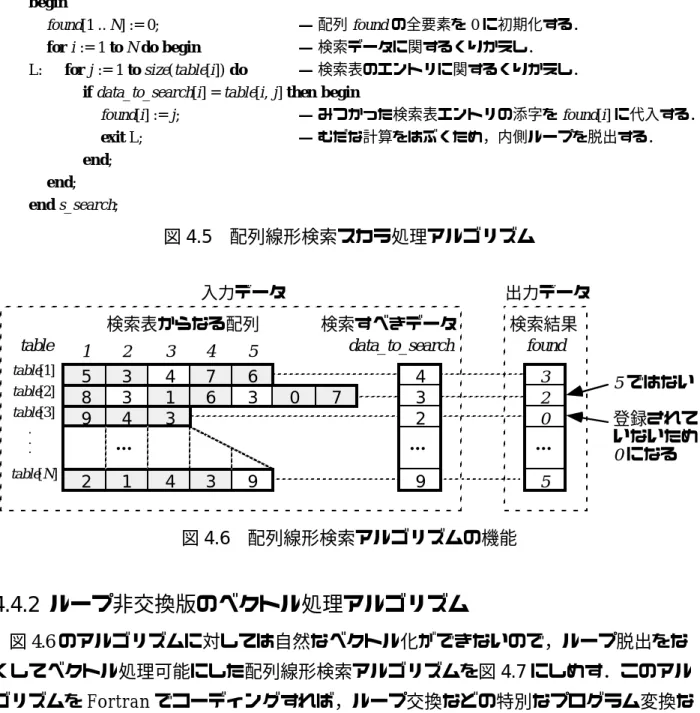
不要な計算を回避するために、このアルゴリズムは、ルックアップ データに対応する値がルックアップ テーブルで見つかったときに内部ループをエスケープします。ベクトル化) は不可能になりました。図4.5 配列線形探索スカラー処理アルゴリズム 検索テーブルから構成される配列 検索結果の検索対象となるデータ。
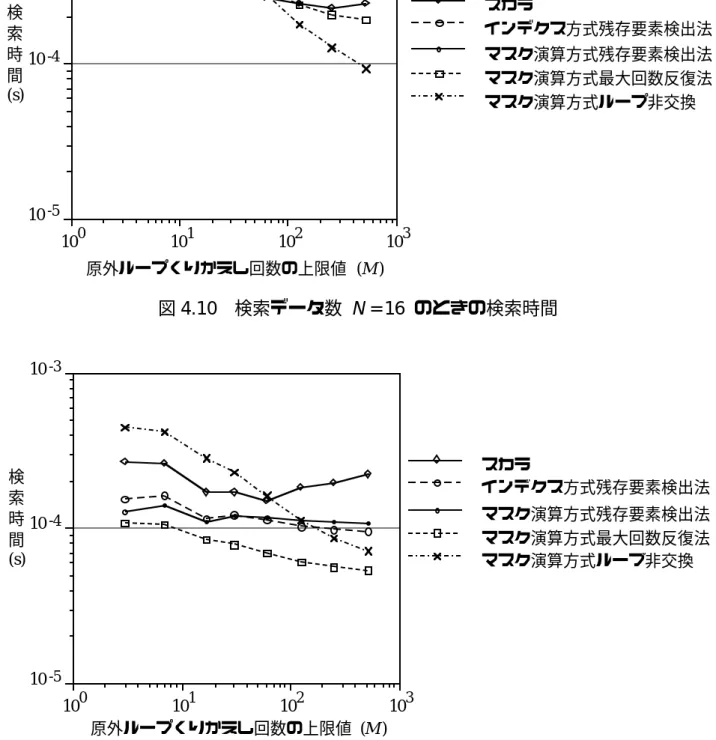
図 4.6 線形場探索アルゴリズムの機能 図 4.7 線形探索ベクトル処理アルゴリズムのループレス バージョン。このアルゴリズムも、特別なプログラム変換を行わずに自然にベクトル化することができます。このアルゴリズムでは、変数 mx を使用して、ループの非可換バージョンの元の内部ループの最大反復数を指定します。外側のループの i 番目の反復における内側の反復の数は、ループが終了しない限り、スカラー処理アルゴリズムの場合と同じです。
ルックアップテーブル[i]のサイズと等しいので、その最大値を求めてmxに置き換えます。
配列線形検索における性能実測結果とその検討
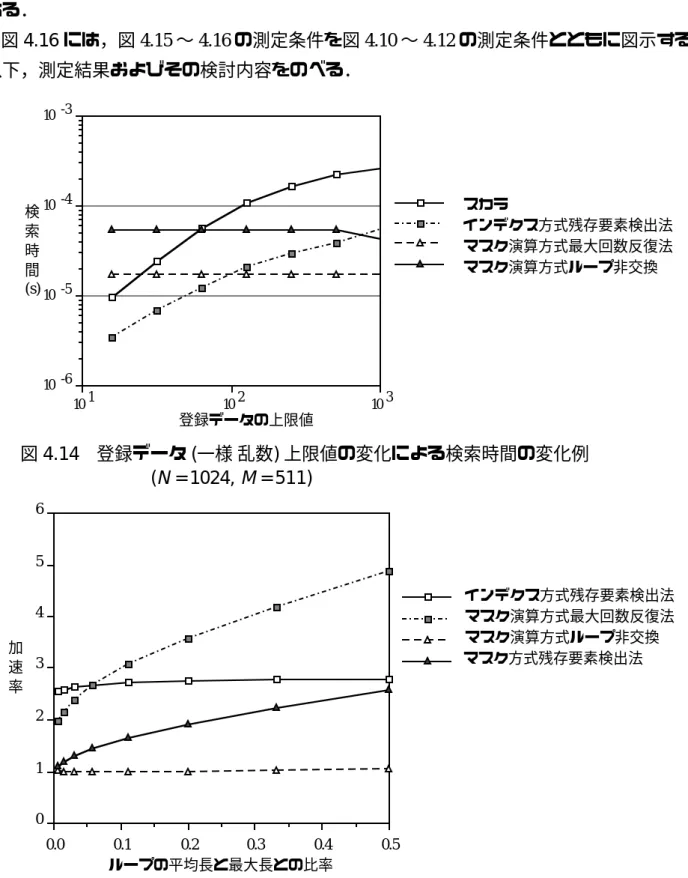
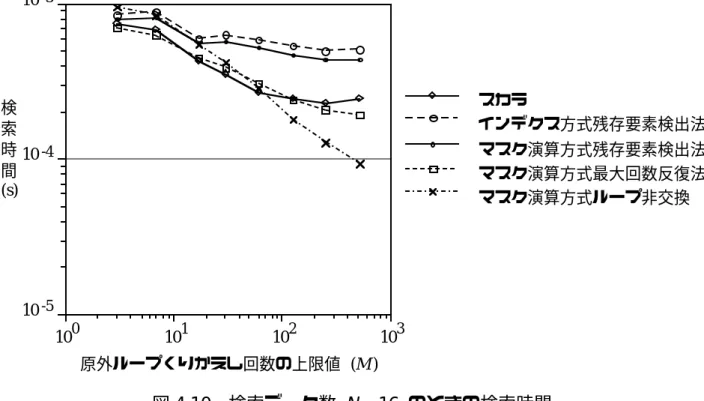
注5 この測定を行う前に、異なる条件で実験測定を行いました。その結果、データを効果的にまとめるには、N 件ごとにグラフを作成するのがよいという結論に達しました。これらの図では表現できない、原内反復回数に対する実行時間の依存性を、図 4.14 以下にさらに示します。 。ループ繰り返し回数の上限(M)
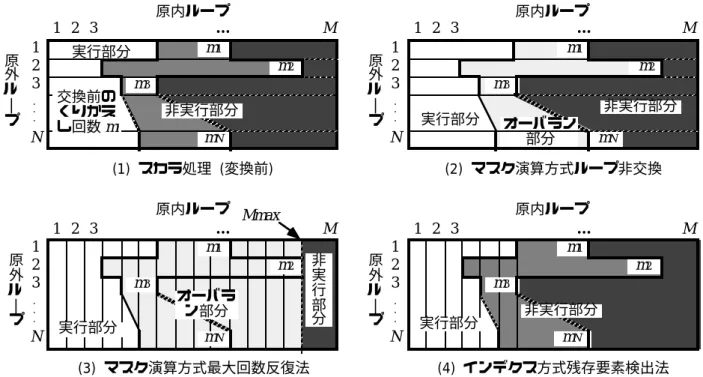
データの生成やルックアップテーブルのサイズ決定には乱数が使用されるため、スカラー処理における内部ループの繰り返し回数は一定ではなく、測定値は変動します。ばらつきを抑えるため、図では乱数を変えて100回測定した平均値を示しています。各測定値の意味を明確にするために、図を示します。乱数の上限 M と各手法の原内反復回数および総反復回数の関係を 4.13 に示します。図 4.13 では、内側のループが横方向に、外側のループが縦方向に繰り返されており、バラン部分、つまり無効な処理が行われる部分を薄い灰色で示しています。 Mmax の意味は図 4.13 (3) にも示されています。データの生成とルックアップ テーブルのサイズの決定には乱数が使用されるため、原内ループの反復回数は一定ではなく、結果として測定値にばらつきが生じます。ばらつきを抑えるために、図では乱数を変えて100回の測定を行い、その平均値をプロットしました。 4) インデックス法 残存要素 M を検出する方法。置換前の繰り返し回数 mi。
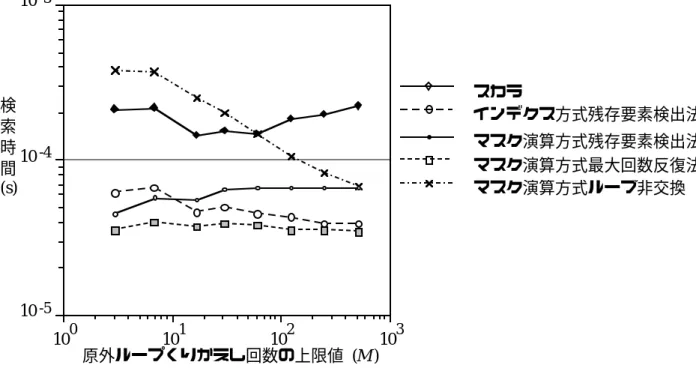
上記の測定結果を完成させるために、2 つの異なる条件で測定が行われ、図に示されています。図 4.14 に、上記の測定条件注 6 とは異なり、記録データおよび検索データ生成用の乱数の上限を変更した場合の、各方式の検索時間の変化を示します。ルックアップ テーブルのサイズを決定する乱数は固定です。その他の測定条件は図と同じです。データ生成用の乱数の上限が増加すると、Hara 内の平均反復回数が増加し、総反復回数もそれに応じて増加します。

10 〜 4.12 におけるのとひとしい.データ発生に関する乱数の上限を 増加させると原内くりかえし回数の平均値が増加し,それにつれて総くりかえし回数も
- 結果のまとめ
- 関連研究
- 付録 1 : Fortran による配列線形検索の ベクトル処理プログラム
- スカラ処理版
- 付録 2 : 配列線形検索の実測データ
- 付録 3 : 最大回数反復法におけるくりかえし回数 Mmax の推定
注6 ただし、マスク計算方式を用いた残留要素検出方式の探索時間は測定されていません。インデックス方式による残存要素検出方式 マスク編集方式 最大反復方式 マスク編集方式 ループ非交換
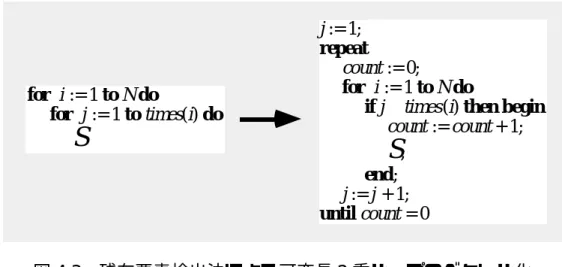
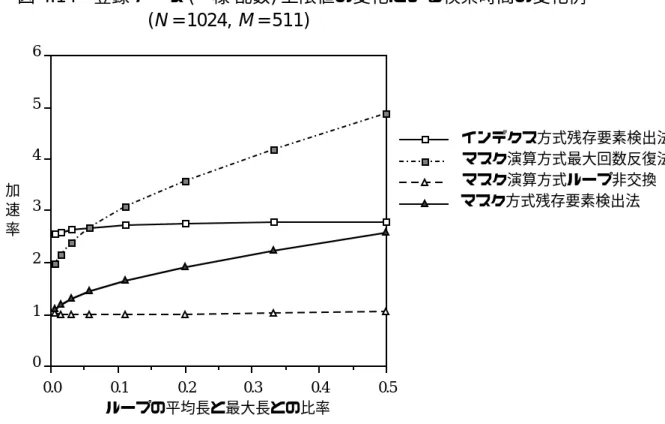
プログラムのバージョンは比較的良く、ループ交換を伴う方法はかなり不利です。ただし、図では最大反復法が残差要素検出法よりも有利ですが、置き換えられたプログラムの方が常に高速です。 3) 最大反復法と残差要素検出法の比較。
例:配列線形探索の場合、N=1024、M=61、平均ループ長・最大反復法(マスク演算)の場合、インデックスによる残存要素検出法はマスク演算による最大反復法より高速です。 ) 方法) 時間 (s) 加速率。残留要素検出方式(マスク演算方式) 時間(秒) 加速度。
残余元素提取方法(指数法) 时间(t) 加速度。