論文
OCR 作業手順書
国立情報学研究所 阿辺川武
2014 年 1 月 24 日
【目次】 1.はじめに 2.OCR の仕様 2.1 認識領域 2.2 領域の種類と機能 2.3 認識誤りの修正対象 3.基本設定 3.1 ソフトウェアアップデートの確認 3.2 ツールバーの設定 3.3 認識オプションの設定 3.3.1 ドキュメント 3.3.2 スキャン/開く 3.3.3 読み取り 3.3.4 保存/PDF 3.3.5 表示 3.3.6 詳細設定 4.実際の作業手順 4.1 領域の修正 4.1.1 ファイルを開く 4.1.2 ヘッダーとフッター 4.1.3 領域の削除 4.1.4 認識順の変更 4.1.5 領域の機能 4.1.6 図表の削除 4.1.7 図表を残す/領域の種類 4.1.8 文字の向き 4.1.9 修正後の読み込み 4.2 認識誤りの修正 4.2.1 一文字から一文字への修正 4.2.2 一文字から二文字への修正 4.2.3 二文字から一文字への修正 4.2.4 文献リストの番号確認 4.2.5 その他 5.保存 5.1 FineReader ドキュメントの保存 5.2 PDF ファイルの保存
1.はじめに
当手引きでは、スキャン画像から作成された論文PDF ファイルに対して、OCR ソフトウェアにより文字 認識をおこない、透明テキスト付き PDF ファイルに変換する手順を説明する。OCR ソフトウェアには ABBYY USA Software House 社製の ABBYY FineReader 11 Professional Edition を使用する。
実際の作業では、複数の論文PDF ファイルを 200 ページ程に統合して一括して作業をおこなっている。 これは作業を効率的に進めるためである。
2.OCR 作業の仕様
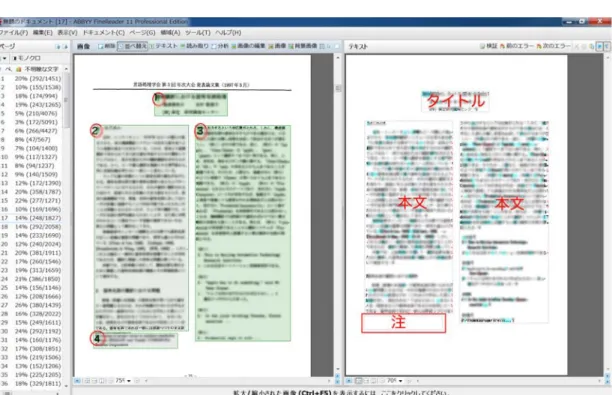
2.1 認識領域 ・対象の領域:標題、著者名、所属、抄録、本文、注、本文中の数式、図表キャプション、謝辞、参考文献 ・対象外の領域:柱、ノンブル、図表(ただし、認識対象となる場合もある) ↓ 【認識対象外の図表】 言葉として意味を持たない英数字、文字として認識できない図形 (※詳しくは4.1.6 図表の削除で説明) 【認識対象の図表】 文書や、言葉として意味をもつ単語 (※詳しくは4.1.7 図表を残す/領域の種類で説明) 2.2 領域の種類と機能 ・領域の種類:テキストもしくは、表 (※詳しくは4.1.7 図表を残す/領域の種類で説明) ・領域の機能:自動、本文、ヘッダーフッター(※詳しくは4.1.5 領域の機能で説明) 2.3 認識誤りの修正対象 ・標題、著者名、所属(著者名直下に記述されている所属情報)、本文見出し、文献リストの番号 一字一句目視で確認し修正する (※詳しくは4.2 認識誤りの修正で説明)3.基本設定
3.1 ソフトウェアアップデートの確認
・定期的にソフトウェアのアップデートを確認し、最新バージョンを保つ (1) ABBYY FineReader 11 を開く
(2) メニューバー/ヘルプ(H)/今すぐ更新を確認(C)
(3) ブラウザが起動し、ABBYY FineReader 11 Professional Edition のアップデートを確認するページが開 くので、新しいバージョンがあればインストールする
図 2 ソフトウェアアップデート 図 1 アプリケーションの起動
3.2 ツールバーの設定 ・作業がスムーズに進むように、ツールバーをカスタマイズする (1) メニューバー/ツール(T)/カスタマイズ(U) (2) カテゴリー(C):/画像から[領域の並べ替え]を選択し、ツールバー(T):/クイックアクセスに移動させる 図 3 ツールバー カスタマイズ 図 4 ツールバー カスタマイズ 領域の並べ替え
3.3 認識オプションの基本設定 ・文字認識は、認識領域に設定されたオプションに沿って行われる。領域のオプションによって認識結果や 認識率に違いが生じるので、必ず読み込む画像に合わせて設定を行う。一度設定を行えば、次回以降は設 定が記憶される。オプションには、[ドキュメント]、[スキャン/開く]、[読み取り]、[保存]、[表示]、[詳細設 定]の6項目がある。 3.3.1 ドキュメント (1) メニューバー/ツール(T)/オプション(O)/ドキュメント (2) ドキュメント言語(D):日本語と英語 (3) ドキュメントタイプ:自動(A) (4) カラーモード:モノクロ(OCR は高速になりますが、色はすべて失われます) 図 5 認識オプション 図 6 認識オプション ドキュメント
3.3.2 スキャン/開く (1) メニューバー/ツール(T)/オプション(O)/スキャン/開く (2) 全般:取得したページ画像を自動的に読み取る(R) (3) 画像の前処理:画像の前処理を有効にする(E) 3.3.3 読み取り (1) メニューバー/ツール(T)/オプション(O)/読み取り (2) 読み取りモード:綿密な読み取り(T) (3) 調整:ビルトインパターンのみを使用する(D) 図 7 認識オプション スキャン/開く 図 8 認識オプション 読み取り
3.3.4 保存 PDF (1) メニューバー/ツール(T)/オプション(O)/保存/PDF (2) 既定の用紙サイズ(D):自動 (3) 保存モード(A):ページ画像の下にテキスト (4) 画像設定:カスタム /解像度:元のまま(O) /品質(A):品質低下を許容しない (5) フォント設定:Windows フォントを使用 (6) セキュリティ:PDF のセキュリティ設定(S) セキュリティなし 3.3.5 表示 デフォルト設定から変更なし 3.3.6 詳細設定 デフォルト設定から変更なし 図 9 認識オプション 保存 PDF
4.実際の作業手順
・PDF ファイルを開くと、事前に設定した認識オプションに沿って画像が読み込まれる。読み込まれたファ イルには誤認識があるので、それらを手作業で修正していく。修正には、認識領域の修正と、認識結果の 誤字修正の2 つがある。 4.1 領域の修正 ・認識領域には、領域の種類や機能、向きや順番があり、それらが間違っていると正しく認識する事はでき ない。4.1 では、読み込まれた画像領域の修正方法を示す。 4.1.1 ファイルを開く (1) ファイル(F)/PDF ファイル/画像を開く(O) 任意のフォルダから必要なファイルを開く (2) ファイルを開くと全てのページが自動で読み込まれる ※200 ページ程の読み込みに数分必要 図 10 PDF ファイルを開く4.1.2 ヘッダーとフッター ファイルが読み込まれると、左側に画像画面、右側にテキスト画面が表示される。各論文の最初のページ には「柱」があり、テキスト画面で「ヘッダーまたはフッター」となっているか確認する。領域オプション の設定(3.3.4 保存 PDF)で「ヘッダーとフッターを維持する」のチェックを外しているので、「柱」が「ヘ ッダーまたはフッター」の場合は文字として反映されず問題ない。それ以外の場合は文字認識に反映される ので領域を削除する。最初の読み込みで「柱」が認識領域に入っていなければそのままでよい。ノンブルも 同様の対応。 ※認識領域については2.1 認識領域を参照 (1) テキスト画面から、「柱」と「ノンブル」の領域が「ヘッダーまたはフッター」となっているか確認 図 11 では、「柱」と「ノンブル」の両方がヘッダーまたはフッターになっているので問題ない ※領域を削除する場合の修正手順は、次の4.1.3 領域の削除で説明 図 11 領域修正 ヘッダーとフッター
4.1.3 領域の削除 対象外の部分が認識領域に入っている場合は、領域を削除する。 1 ページ内で修正箇所が多い場合は、一度全ての領域を削除し、最初からやり直したほうが早い。 【一部分の削除】 (1) 図 12 では、認識領域の対象外であるノンブルが文字として認識されているので削除する (2) 画像画面で、削除する領域にマウスを合わせて右クリック (3) [領域の削除(D)]を選択 (4)「並べ替え」から、領域の認識順を確認(※次の 4.1.4 認識順の変更で説明) ※領域の修正は、全て画面左側の「画像画面」から行う 図12 領域修正 削除 図 12 領域修正 削除
【全削除】 図 13 を見ると、読み取った領域の段組みが崩れ、分かれたり繋がったりしている。一つずつ修正するに は時間がかかるため、一度全ての領域を削除し新たに範囲を指定する。 (1) 領域のどれかにマウスを合わせ右クリックし、[領域とテキストをすべて削除(E)]を選択 (2) 領域が全て削除されるので、最初から領域の範囲を指定する (3)「並べ替え」から、領域の認識順を確認(※次の 4.1.4 認識順の変更で説明) 図 14 領域修正 新たに領域を指定 図 13 領域修正 全削除
4.1.4 認識順の変更 1 ページで領域が複数に分かれている場合、認識順が通常論文を読み進める場合に即しているか確認する。 【領域の順番】 ・各論文最初のページ:柱→標題→著者名→著者名直下の所属情報→本文→注→ノンブル ・各論文最後のページ:本文→注→謝辞→参考文献→ノンブル ・それ以外のページ:本文→注→ノンブル 【段組み】 ・一段:上から下 ・二段:左カラム上から下→右カラム上から下 ※図表の位置によってはこの通りでなく、できるだけ自然な流れになるような順番にする。 (1) 図 15 を見ると、左カラムで本文と「注」が同じ領域に入っている。このままでは、柱→タイトル→著者 →本文→注→本文となり、誤った文章の繋がり方をしているので領域と順番を修正する。 (2) 左カラムの領域を本文と注で分ける(一般的な範囲選択方法と同じ手順) (3) クイックアクセスに追加した「並べ替え」を選択し、認識したい順番に領域をクリックしていく (4) 図 16 のテキスト画面を見ると、新たに指定した領域が読み取られず空欄になっている。修正した領域の 読み取りは、最後にまとめて行うので今はこのままでよい ※各ページで、必ず最後に認識順の確認を行うこと
図15 領域修正 順番修正前
4.1.5 領域の機能 文字認識に必要な領域が「ヘッダーもしくはフッター」になっている場合は削除ではなく、領域の機能を 「本文」に変更する。領域の機能は通常「自動」になっており、文字が認識されていればそのままでよい。 (1) 図 17 のテキスト画面を見ると、表のキャプションが「ヘッダーとフッター」になっている (2) 修正する領域にマウスを合わせ右クリック、[テキスト機能(F)]を選択 (3) 機能を[本文(A)]に変更 (4)「並べ替え」から、領域の認識順を確認 図17 領域修正 機能
4.1.6 図表の削除 図表に入っている英数字や記号は、言葉として意味を持たない場合が多く、それらは文字として認識して も検索対象とならないので削除する。図形も同様に削除する。 (1) 図 18 では数値メインの表が 1 つと、図形が 1 つ入っている (2) 削除する図表にマウスを合わせて右クリックし、領域の削除を選択、この時キャプションは残す (3)「並べ替え」から、領域の認識順を確認 図18 領域修正 図表の削除
4.1.7 図表を残す/領域の種類 図表であっても、文章や単語など言葉として意味を持つ文字列がメインの場合は認識領域として残す。最 初の読み込みで領域の種類が[表(A)](紫色)や[画像(P)](赤色)となっている場合も多い。表は文字として認識さ れているので、画像とテキストを見比べて認識率が悪くなければそのままでよい。画像は文字として認識さ れていないので、領域の種類をテキストに変更する。 【図を残す】 (1) 図 19 では、文章がメインの図が画像領域となっており、文字として認識されていない (2) 変更する領域にマウスを合わせて右クリックし、[領域の種類変更(A)]からテキスト(T)に変更 (3)「並べ替え」から、領域の認識順を確認 【表を残す】 (1) 図 20 の 2 つの表は単語一覧なので認識領域として残す (2) 領域の種類が表(A)で、テキスト画面から文字として正しく認識されている事を確認 (3) 誤認識が多い場合は種類をテキスト(T)に変更し、どちらがよいか比べる 図19 領域修正 図を残す 図20 領域修正 表を残す
4.1.8 文字の向き 画像画面の文字の向きと、テキスト画面の文字の向きが一致しない時は修正する (1) 図 21 のテキスト画面を見ると、右カラムで誤って縦書きになっている領域がある (2) 変更領域にマウスを合わせて右クリックし、[判別できないテキストの向き(H)]から[横書き(H)]を選択 (3)「並べ替え」から、領域の認識順を確認 図21 領域修正 文字の向き
4.1.9 修正後の読み込み 全ページの領域修正が終わったら、再度読み込み、修正をテキストに反映させる。 (1) 画面左側のページ一覧を全て選択する (2) ツールバーの「読み取り」から再度読み込みを行う 領域毎に読み取りを行いたい場合は、画像画面で該当の領域にマウスを合わせて右クリックし[領域の読み取 り(R)]を選択する。次の「4.2 認識誤りの修正」では、画像画面から修正を行ったら必ず領域毎に読み取り を行い、修正が反映されているか確認する。 図22 領域修正 読み取り 図23 領域修正 読み取り(2)
4.2 認識誤りの修正 領域の修正と再読み込みが完了したら、一部については目視で一字一句確認する。対象は、標題、著者名、 所属(著者名直下に記述されている所属先)、本文見出し、参考文献リストの番号であり、画像とテキストを 見比べてながら修正を行う。 4.2.1 一文字から一文字への修正 (1) 図 24 を見ると、標題の「日」が「曰」に誤認識されているので、テキスト画面から該当文字の左側にカ ーソルを合わせ右クリック (3) 修正候補の文字が表示されるので、図 25 のように該当文字があれば選択 (4) 該当文字がない場合は、テキスト画面から文字を削除し、直接正しい文字を入力する (5) 1 つの領域内で修正が終わったら、その都度読み込み確認する 図24 誤認識修正 一文字修正前 図25 誤認識修正 一文字修正後
4.2.2 一文字から二文字への修正
(1) 図 26 のテキスト画面を見ると、章見出しが「2. 日英_の…」となっており、「翻訳」が「_」に誤認識さ れている
(2)「_」の左側にカーソルを合わせ右クリックすると、認識した画像として「翻訳」の二文字が表示され、 修正候補には一文字の漢字がいくつか表示される
(3) ABBYY FineReader 11 Professional Edition では、複数の文字が一文字として誤認識された場合、分割 する機能がない
(4) そのため、本来別々の文字が 1 文字として誤認識された場合は、テキスト画面から該当文字を削除し、 直接正しい文字を入力する
(5) 1 つの領域内で修正が終わったら、その都度読み込み確認する
4.2.3 二文字から一文字への修正 (1) 図 27 では、「観」という文字を二文字に分割し、「!」「!」と誤認識している (2) 誤認識している「!」「!」の両方を選択し、右クリック (3) 修正候補の文字が表示されるので、該当文字があれば選択 (4) 該当文字がない場合は、テキスト画面から文字を削除し、直接正しい文字を入力する (5) 1 つの領域内で修正が終わったら、その都度読み込み確認する 図27 誤認識修正 二文字から一文字
4.2.4 文献リストの番号確認 各論文の最後のページには参考文献がついているので、リスト番号がついている場合はその番号のみ確認 し、誤認識があれば修正する。 (1) 図 28 の参考文献リストを見ると[6]が誤認識されている (2) この場合[6]の三文字が一文字として誤認識されているので、誤った文字を削除し直接正しい文字を入力 (3) 1 つの領域内で修正が終わったら、その都度読み込み確認する 図28 誤認識修正 文献リスト番号
4.2.5 その他 誤認識の修正で、画像と対応する文字の特定が難しい場合や、拡大して確認したい時は「検証画面」を利 用する。 (1) テキスト画面の確認したい箇所にカーソルを合わせ左クリック (2) テキスト画面右上の「検証」選択 (3) 画像とテキストを見比べながら修正を行う 図29 誤認識修正 検証
画像画面で領域に入っている文字がテキスト画面で認識されない場合、その領域を再度読み込むか、領域 を分けて読み込む (1) 図 30 では、領域内に入っている著者の所属がテキスト画面では認識されていない (2) 再度読み込むも、認識されないので著者と所属の領域を分割 (3) 領域の数が増えたので順番を修正し、再読み込み (4) 修正後の図 31 では、著者所属が認識されている 図30 認識されていない領域 図31 修正で認識された領域
5.保存
5.1FineReader ドキュメントの保存 作業の中断や、修正が一段落した時には FineReader ドキュメント(作業ファイル)を保存する。次に作業 を再開する時は、FineReader ドキュメントを開けば前回の続きから作業を行える。 (1) ファイル(F)/FineReader ドキュメントを保存(U)、任意のフォルダに保存 図 32 FineReader ドキュメントの保存5.2 PDF ファイルの保存
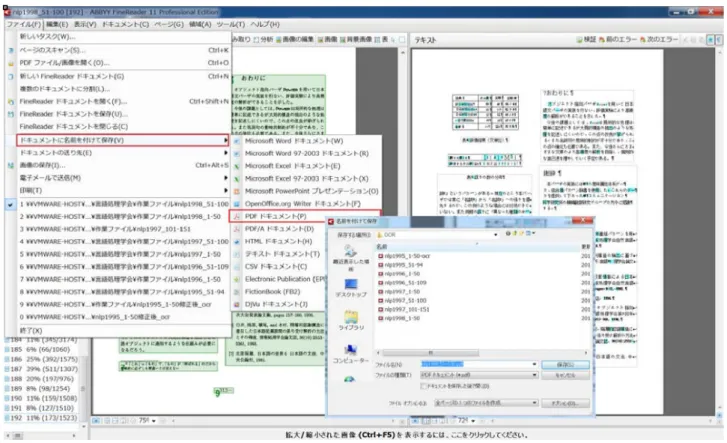
1 つのファイルの認識が終了したら、PDF ファルを保存する。
(1) ファイル(F)/ドキュメントに名前を付けて保存(V)/PDF ドキュメント(P)、任意のフォルダに保存