スライド共有サービスにおける資料作成者を対象とした
専門知識抽出手法の検討
A Method for Representing Knowledge of Presentation Slide Creators
on a Slide Sharing Service
築地 勇人 鷹野 孝典
Hayato Tsukiji, Kosuke Takano
神奈川工科大学 情報学部 情報工学科
Department of Information and Computer Sciences, Faculty of Information Technology,
Kanagawa Institute of Technology
Abstract: In this study, we present a method for extracting and representing knowledge of presentation
slide creators based on the slide contents that are published on a slide sharing service. The proposed method regards the number of views, downloads, and likes from other users as the approval rate for a presentation slide, and extract knowledge of the slide creator in terms of the usefulness and knowledge amount of the slide contents. In the experiment, we evaluate the feasibility of the proposed method by analyzing the presentation slides created by users on SlideShare, which is one of the most popular slide sharing service.
1. はじめに
Web やクラウド技術の急速な発展に伴ない,膨大 な量の情報コンテンツが,HTML ファイルだけでな く,動画,文書,プレゼンテーションスライド,ソ フトウェアといった様々な形態で提供されるように なっている.このような膨大な情報コンテンツから, ユーザが目的の情報コンテンツを獲得するために検 索システムが利用されている.ここで,このような 情報コンテンツを見つけるタイプの検索を,コンテ ンツ検索と呼ぶ. 一方,社会活動の中で生じるある特定の関係の中 で大きな影響を及ぼす,あるいはその関係の中心に 居る人物のことをキーパーソンと呼ぶことがある. 例えば,高度な専門知識を持った専門家や,特定の 技術やスキルを有する人も,その分野におけるキー パーソンと捉えることができる.本研究では,情報 検索において,このようなある特定分野における特 徴的な人物を検索することを,キーパーソン検索と 呼ぶ. コンテンツ検索に対し,キーパーソン検索ではそ の人物がどのような情報コンテンツを発信してきた のかを辿ることができる.このため,最初の検索で 知りたいと思っていた情報コンテンツに加えて,関 連性のあるものを効率よく獲得できる可能性がある. キーパーソン検索では,あらかじめ検索対象となる 人物の特徴を抽出しておく必要があり,対象とする 人物がどのような専門知識を有しているか,あるい は,どのような技術やスキルを持っているかに着目 して人物の特徴を抽出する研究が数多くなされてい る.例えば,文献[3]では対象ユーザのツイート内容 から専門用語などを抽出し,対象ユーザの専門性に ついて機械学習を用いて判別している. 本研究では,スライド共有サービスで公開されて いるスライド資料の内容に基づいた資料作成者の専 門知識抽出手法について検討する.提案方式では, 他ユーザからの閲覧数を支持度と捉えることにより, 専門知識量に有用性を加味して専門知識を抽出する 点に特徴がある.例えば,商品レビューサイトであ る価格.com [12]では,商品レビューについて,他者 からの評価が高い場合,その商品ジャンルにおける 「優良」レビュワーとして評価される.しかし,あ らかじめ決められた商品ジャンルについてのレビュ ワー評価を行うため,ジャンルフリーの状態から, ジャンルを推定した上でのレビュワー評価は行なっ ていない.本研究では,スライド資料を中に出現し ている単語群に基づいて専門性を評価するので,そ の特徴単語の性質に応じて,専門分野を判定するこ とができる. 本 研 究 で は , ス ラ イ ド 共 有 サ ー ビ ス で あ る 人工知能学会研究会資料 SIG-KBS-B505-01SlideShare [13]上のユーザ,および作成されたスライ ド資料を分析対象とした評価実験により提案方式の 実現可能性を検証する.
2. 関連研究
情報検索分野において,コンテンツ検索[7][8]やキ ーパーソン検索[3][4]に関する研究が盛んに行われ ている.文献[7]では,タグ組み合わせに基づく web コンテンツ検索方式を提案しており,コンテンツの 提供者,および閲覧者が付与した複数タグの組み合 わせでコンテンツ検索を実現している.また,文献 [8]では,映像コンテンツを対象としたコンテンツ検 索・推薦を効果的に行うことを目的として,利用者 が視聴中に付与したメタデータ,選択した映像,描 いたスケッチに基づいた類似検索・推薦システムを 構築している. また,キーパーソンの発見に関する研究として, 文書検索と固有表現抽出を組み合わせることにより, 適応例として与えられたトピックに関するWeb 上の キーパーソンを発見する手法[4]や,Twitter における ツイート内容の専門用語や実世界の出来事と共起情 報,抽象的な単語の使用頻度を機械学習で学習させ ることにより,対象人物が専門家であるかを判別す る手法が提案されている. 人物検索においては,キーワード検索が主流であ るが,キーワード検索だけでは目的の人物にたどり 着けない,または,検索された人物の識別や理解が しにくいことがあり,人物を特徴付けるラベル付け が必要であると考えられる[5].このため,コンテン ツ分析等に基づいた人物の特徴抽出手法についても 多くの提案がなされており,Twitter のリスト機能を 用いたユーザの特徴抽出[1],レビュー内容に基づく ユーザ評価の根拠分析[2],日本十進分類法(Nippon Decimal Classification, NDC)を用いた人物ディレク トリの開発[5],Web 上の同姓同名人物判別のための 職業関連情報の抽出[6]に関する手法等が提案され ている. さらに,スライドからの情報抽出について,内容 のみでなく,デザインや構造に着目した手法が提案 されている.文献[9]では,プレゼンテーションスラ イドのデザイン的構成評価による個別のスライドの 修正支援に関する手法を提案している.また,文献 [10]では,スライド情報を機能的なまとまりに組織 化することにより,計算機が構造情報を扱えるよう にすることを目的としたプレゼンテーションスライ ド情報の構造化手法を提案している.文献[11]では, スライド情報検索の効率性を高めるために,スライ ドページから関連する情報を適切に抽出する要求関 連情報抽出の開発を行っている. 本研究では,キーパーソン検索を目的とした人物 からの特徴抽出に焦点を当てており,提案手法は, 生成されたスライド資料から抽出される専門知識量 のみではなく,他ユーザからの評価に基づいた有用 性を考慮して,対象人物の専門知識の抽出および提 示を行う点に特徴がある.3. 提案方式
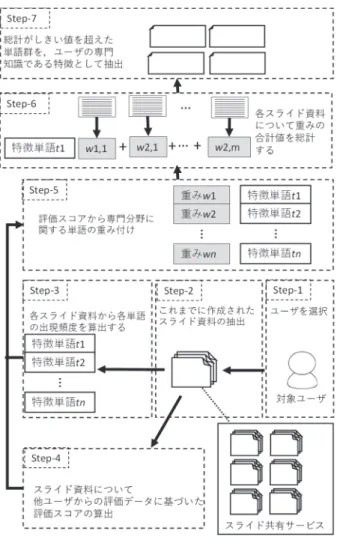
図 1:提案方式の概要図 提案方式の概要図を図1 に示す.本方式では,ス ライド共有サービス上に公開されたスライド資料を 対象として,スライド資料に出現する単語群の分析, およびスライド資料に対する閲覧数やお気に入り数 といった他ユーザからの評価情報に基づいて,スラ イド作成者の専門知識に関する特徴単語,および専 門分野の抽出・提示を行う. また,本方式により抽出した専門知識に関する特 徴単語や専門分野は,人物データベース上に格納し ておくことで,ユーザの探したいコンテンツ情報を 持つ人物の発見を目的としたキーパーソン検索へ適 用できると考えられる.図 2:専門知識を示す特徴単語群の抽出手順 提案方式では,ユーザuiの専門知識を示す特徴単 語を,下記の手順で抽出する(図2).ここで,k 個 の専門分野Fxについて,その専門分野の内容を表す 専門単語集合 Txをあらかじめ定義しておく.また, T1, T2, T3,…, Tkの和集合をT={t1, t2, t3, …, t m}とする. Step-1: スライド共有サービスから,分析対象とする ユーザuiを選択する. Step-2: Step-1 で選択したユーザ uiがこれまでに作成 したn 個のスライド資料 s1, s2, s3, …, snを抽出する. Step-3: T の各単語について,Step-2 で抽出したスラ イド資料sx内の出現頻度fx,1, fx,2, fx,3, …, f x,mを算出す る. Step-4: スライド資料 sxについて,他ユーザからの評 価データに基づいた評価スコア scorexを,各評価デ ータIiの合計を評価データ数p で割ることで算出す る. ∑ 例えば,表5 に示す 4 つの評価データを用いる場 合,scorexは下記のように計算される. 4 表 1:評価データの項目例 項目 変数名 I1 閲覧数 view I2 共有された回数 share I3 ダウンロード回数 download I4 お気に入り数 like Step-5: スライド資料 sxについて,T の各単語の重み 係数wx(tk)を下記のように計算する.ここで,重み係 数は,スライド資料sxのスライド枚数sheetxで正規 化されている. 1 , Step-6: ユーザ uiの作成した全てのスライド資料 s1, s2, s3, …, sn について,tkの重みの合計値w (tk)を下記 のように計算する.ここで, = 1⁄ , Step-7: w (tk)の値がしきい値θ1を超えたものを,ユ ーザuiの専門知識を示す重み付き特徴単語として抽 出する. また,抽出した重み付き特徴単語から,ユーザ ui の専門分野について下記の手順で抽出する. Step-1: 抽出した重み付き特徴単語集合の各単語を 専門単語集合T1, T2, T3,…, Tkに分類する. Step-2: 専門単語集合ごとに,特徴単語の重み合計値 w (ti)の総計 Vkを計算する. ∈ Step-3: Step-2 で計算した総計 Vkがしきい値θ2を超 えた場合,Tk に該当する専門分野 KNkに関する知識 をユーザuiが持っているとみなし,uiの専門分野と して割り当てる.
以上のステップで抽出したユーザが持つ専門知識 を示す重み付き特徴単語,および専門分野について, 可視化して表示する例を図3 に示す. 図 3:結果出力の例
4. 実験
スライド共有サービスである SlideShare [13]上の ユーザ,および作成されたスライド資料を分析対象 とした評価実験により提案方式の実現可能性を検証 する.4.1 実験環境
SlideShare [13]上のスライド作成者 4 名を特徴抽出 の対象とした.対象とした人物のユーザID,および 作成スライドの種類と数について表2~表 5 に示す. 例えば,表2 では,ユーザ ID が hakoika-itwg である 個人ユーザは,「バージョン管理」,「オブジェクト指 向」,「データベース」などの分野に関するスライド 資料を SlideShare 上で公開していることを示してい る.なお今回の実験では,作成スライドの種類とし て情報処理分野のもの作成している人物を分析対象 として選んでいる. 表 2:対象人物のデータ (1) ユーザID スライドの種類 数 hakoika-itwg (個人) バージョン管理 2 オブジェクト指向 7 データベース 1 セキュリティ 1 ネットワーク 1 合計 12 表 3:対象人物のデータ (2) ユーザID スライドの種類 数 Hayasitd (個人) データベース 3 ソフトウェア開発 1 オブジェクト指向 1 合計 5 表 4:対象人物のデータ (3) ユーザID スライドの種類 数 matsuzawafumiaki (個人) クラウド 1 データベース 1 通信技術 1 プレゼンテーション 1 セキュリティ 1 合計 5 表 5:対象人物のデータ (4) ユーザID スライドの種類 数 Ssuser70f2c8 (企業) ネットワーク 4 アプリケーション開発 5 仮想化 3 合計 124.2 実験方法
表2~表 5 の人物を対象として,3 章で示した提案 方式に従って抽出した場合の重み付き特徴単語の抽 出結果と,重み付けなしの場合の特徴単語の抽出結 果を比較・考察する.特徴単語はそれぞれ場合にお いて,スコアの高い上位10 件について比較する.重 み付けなしの場合は,重み係数を1 として,特徴単 語のスコアを算出している.なお,本実験で用いた 評価データは,閲覧数,共有された回数,ダウンロ ード回数,お気に入り数の4 項目である.4.3 実験結果と考察
特徴単語の抽出結果を表6~表 9 に示す. 例えば,表9 では,ユーザ ID が Ssuser70f2c8 であ るユーザを対象とした場合の結果を示している.表 10 において,重み付きなしの場合の結果では,「ネッ トワーク」や「config」などネットワーク関する特徴 単語が上位に表れている.これに対して,提案方式 のように重み付けをしてスコア算出した場合では, 「API」や「Android」などアプリケーション開発に ついての特徴単語が上位に表れている.これは,ユ ーザ Ssuser70f2c8 が作成したスライド資料のうち, アプリケーション開発について書かれたスライド資 t1 t2 t3 … tn 特徴単語t1:8 特徴単語t2 :7 特徴単語t3 :6.5 特徴単語tn:5.8 ユーザID 特徴単語から抽出 された専⾨分野 ・専⾨分野A (Score 20) ・専⾨分野B (Score 16) …料に対する他ユーザからの評価が高かったためと考 えられる.これらの結果は,提案手法では,作成さ れたスライド資料の内容,および他ユーザからの評 価に基づいたスライド資料の有用性を考慮して,対 象人物の専門知識を表す特徴単語群が抽出できるこ とを示している. 表 6:特徴単語の抽出結果 (ユーザ ID: hakoika-itwg) 重み付けなし 提案方式 (重み付けあり) 特徴単語 スコア 特徴単語 スコア テスト 92 クラス 214.60 オ ブ ジ ェ ク ト 指向 80 原則 209.95 管理 64 作業 156.09 クラス 59 依存 140.71 作業 59 タスク 140.66 ファイル 58 仕事 140.21 svn 57 細分 126.15 html 55 型 118.23 変更 55 Principle 117.34 実行 49 モジュール 116.84 表 7:特徴単語の抽出結果 (ユーザ ID: Hayasitd) 重み付けなし 提案方式 (重み付けあり) 特徴単語 スコア 特徴単語 スコア データ 104 データ 385.29 データベース 92 データベース 298.44 言語 56 ト ラ ン ザ ク シ ョン 219.11 テスト 55 SQL 167.98 ト ラ ン ザ ク シ ョン 50 口座 126.37 SQL 46 状態 91.12 型 44 保存 78.93 場合 38 テーブル 76.42 処理 35 表 75.82 プログラム 34 場合 73.84 表 8:特徴単語の抽出結果 (ユーザ ID: matsuzawafumiaki) 重み付けなし 提案方式 (重み付けあり) 特徴単語 スコア 特徴単語 スコア 利用 57 対策 103.15 プ レ ゼ ン テ ー ション 53 token 91.57 クラウド 48 設定 80.28 図 44 ファイル 68.68 スライド 36 無効 57.24 ストーリー 30 session 57.23 目的 30 セッション 57.23 データ 29 トークン 45.82 聞き手 28 PHP 45.79 無線 26 SESSION 45.79 表 9:特徴単語の抽出結果 (ユーザ ID: Ssuser70f2c8) 重み付けなし 提案方式 (重み付けあり) 特徴単語 スコア 特徴単語 スコア ネットワーク 268 テスト 462.02 設定 262 OpenStack 321.20 構築 233 API 290.00 テスト 232 Android 280.99 config 213 WebRTC 261.52 VLAN 207 サーバ 209.77 スイッチ 195 アプリ 184.33 Android 179 コード 158.68 アプリ 152 ブラウザ 152.60 OpenStack 147 メソッド 152.50
5. むすび
本研究では,スライド共有サービスで公開されて いるスライド資料の内容に基づいた資料作成者の専 門知識抽出手法について検討した.また,スライド 共有サービスである SlideShare 上のユーザ,および 作成されたスライド資料を分析対象とした評価実験 により提案方式の実現可能性を検証した. 今後の予定として,既存の人物からの特徴抽出手 法との比較実験を行うことにより,提案方式の有効 性をしていく予定である.さらに,提案方式の拡張 として,抽出した専門知識に関する特徴単語や専門 分野を人物データベースのインデックスとして適用 することで,ユーザの探したいコンテンツ情報を持つ人物の発見を目的としたキーパーソン検索を考案, および実現していくことを検討している.
参考文献
[1] 奥川巧, 倉門浩二, 大石哲也, 越村三幸, 藤田博, 長 谷川隆三: Twitter のリスト機能を用いたユーザの特 徴抽出, 情報処理学会 第 73 回全国大会講演論文集 2011(1), pp. 687-688, (2011) [2] 松尾哉太, 新妻弘崇, 太田学: レビュー解析に基づく ユーザ評価の根拠提示の一手法, 情報処理学会研究 報告. [システムソフトウェアとオペレーティング・シ ステム], pp.1-6, (2014) [3] 鎌田健史, 長谷川大, 佐久田博司: Twitter における専 門家判別手法の性能評価, 情報処理学会 第 75 回全 国大会講演論文集2013(1), pp. 105-106 (2013) [4] 原田昌紀, 佐藤進也, 風間一洋: Web 上のキーパーソ ンの発見と関係の可視化, 情報処理学会研究報告情 報学基礎, pp. 17-24, (2003) [5] 浦芳伸, 村上晴美: NDC を用いた人物ディレクトリ の開発, 情報処理学会 第 73 回全国大会講演論文集 2011(1), pp. 651-652, (2011) [6] 上田洋, 村上晴美, 辰巳昭治: web 上の同姓同名人物 判別のための職業関連情報の抽出, 人工知能学会全 国大会論文集, pp. 174-174, (2008) [7] 福盛秀雄, 村岡洋一: タグ組み合わせに基づく web コンテンツ検索, 情報科学技術フォーラム講演論文 集, pp. 143-144, (2009) [8] 住吉英樹, 望月貴裕, 後藤淳, 藤井真人: 関連コンテ ンツ検索・推薦システム, 映像情報メディア学会年次 大会講演予稿集, pp. 3-1-“1-3-1-2”, (2010) [9] 前田圭太, 花植康一, 渡辺豊英: プレゼンテーション スライドのデザイン的構成評価, pp. 861-863, (2012) [10] 羽山徹彩, 難波英嗣, 國籐進: プレゼンテーシ ョンスライド情報の構造化, 情報処理学会研究報告 デジタルドキュメント(DD), pp. 45-50, (2008) [11] 羽山徹彩, 國籐進: プレゼンテーションスライ ド情報検索のためのスライドページからの要求関連 情報抽出, 研究報告デジタルドキュメント(DD), pp. 1-7, (2010) [12] 価格.com, http://kakaku.com, (2016.10.1 訪問)[13] Share and Discover Knowledge on LinkedIn