関連したドキュメント
Keywords and phrases: super-Brownian motion, interacting branching particle system, collision local time, competing species, measure-valued diffusion.. AMS Subject
Then it follows immediately from a suitable version of “Hensel’s Lemma” [cf., e.g., the argument of [4], Lemma 2.1] that S may be obtained, as the notation suggests, as the m A
Definition An embeddable tiled surface is a tiled surface which is actually achieved as the graph of singular leaves of some embedded orientable surface with closed braid
Our method of proof can also be used to recover the rational homotopy of L K(2) S 0 as well as the chromatic splitting conjecture at primes p > 3 [16]; we only need to use the
We study the classical invariant theory of the B´ ezoutiant R(A, B) of a pair of binary forms A, B.. We also describe a ‘generic reduc- tion formula’ which recovers B from R(A, B)
While conducting an experiment regarding fetal move- ments as a result of Pulsed Wave Doppler (PWD) ultrasound, [8] we encountered the severe artifacts in the acquired image2.
Based on sequential numerical results [28], Klawonn and Pavarino showed that the number of GMRES [39] iterations for the two-level additive Schwarz methods for symmetric
For X-valued vector functions the Dinculeanu integral with respect to a σ-additive scalar measure on P (see Note 1) is the same as the Bochner integral and hence the Dinculeanu

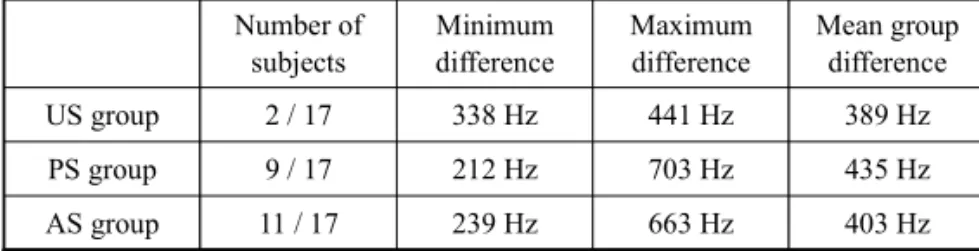
![Table 4. Details of the group differences in F2 of the English [æ] and [ ]](https://thumb-ap.123doks.com/thumbv2/123deta/6289470.2116909/7.892.188.710.607.718/table-details-group-differences-f-english-æ.webp)
![Figure 2. Differences between the English [æ] and [ ] in F2](https://thumb-ap.123doks.com/thumbv2/123deta/6289470.2116909/8.892.219.673.112.498/figure-differences-english-æ-f.webp)
![Figure 3. Differences between the English [æ] and [ ] in F1](https://thumb-ap.123doks.com/thumbv2/123deta/6289470.2116909/9.892.223.672.469.773/figure-differences-english-æ-f.webp)
![Figure 4. Example of formant patterns of the US/PS group’ English [æ]](https://thumb-ap.123doks.com/thumbv2/123deta/6289470.2116909/11.892.158.742.176.599/figure-example-formant-patterns-ps-group-english-æ.webp)


![Figure 6. Differences in F2 among the English [æ] and [ ] and the Japanese [a]](https://thumb-ap.123doks.com/thumbv2/123deta/6289470.2116909/15.892.199.611.174.476/figure-differences-f-english-æ-japanese.webp)
