位データへの適用―
著者 川端 一光
雑誌名 明治学院大学心理学紀要 = Meiji Gakuin
University bulletin of psychology
巻 25
ページ 1‑19
発行年 2015‑03‑31
その他のタイトル An item response model for estimation of a rater s discrimination power ―An application to three‑mode ranking data―
URL http://hdl.handle.net/10723/2471
『心理学紀要』(明治学院大学)第 25 号 2015 年 1–19 頁
【原著】
評価者の弁別力推定の為の項目反応モデル
―3 相順位データへの適用―
問題と目的
視覚・聴覚・触覚といった人間の感覚を利用 して,評価試料(以降,“試料”と表記)の特 性を把握する方法を官能検査(sensory analy- sis)と呼ぶ(例えば,佐藤,1978)。新製品開 発や製品検査といった実務場面において,一般 消費者で構成される評価者集団(パネル)や少 数の専門家による官能検査は,欠かすことので きない重要な工程となっており,早川(2009)
の解説にもあるように,既に多数の国際標準規 格が ISO(International Organization for Stan- dadization)によって提供されている。
官能検査では試料の特性に対する感覚を,適 当な測定法を利用して数値に変換する。この測 定法には,試料を単独で提示し評価させる採点 法(評定尺度法),試料を一対にして提示し評 価させる一対比較法,試料を複数同時に提示し 評価させる順位法などがある(井上,2012)。
特に順位法は実施の効率性,評価者にとって の分かりやすさという点で,実務場面の官能検 査に限らず,様々な目的の質問紙調査で広く用 いられている。
順位法の使用用途は 2 つある。1 つ目は試料 間の特性の差異に関する評価者の弁別力を測定 することである。この目的の場合,評価者に提 示される試料には客観的な順位(以降,“客観 順位”と表記)が付与されている。例えば,評 価者の重量弁別力を測定するために,5.05 g(1 位),4.95 g(2 位),4.90 g(3 位)のように客 観順位があらかじめ付与されている刺激を提示 し,触覚のみでこの順位を判断させるような状 況である。判断された順位を以降では“判断順 位”と呼ぶ。弁別力の指標として,客観順位と 判断順位間で定義される spearman の順位相関 係数や,kendall の一致性係数などが利用でき る(佐藤,1985)。
弁別力を測定できるという性質上,順位法は 要 約
本研究では,3 相順位データに対応する項目反応モデルが提案された。本モデルは,Mallows-Bradley-Terry モデル
(Mallows, 1957)を拡張したもので,複数評価観点における試料の嗜好度母数と,試料の客観的順序に対する評価者の 弁別力母数で構造化されている。本研究では,モデル中の母数を推定するための Metropolis-Hasting アルゴリズムも同 時に提案された。
標本サイズ=180,評価試料数=4,評価観点数=15 という設定でのシミュレーション研究の結果,考案した推定ア ルゴリズムには,一定の真値復元力があることが確認された。
実データへの適用研究では,183 名の学生から質問紙調査によって順位判断データを得た。スポーツ 4 種目の順位評 価を 15 の観点から評価させたものである。このデータに対して提案モデルを適用した結果,データ分布の実態に沿っ た形で,嗜好度母数と弁別力母数の解釈が可能であった。
キーワード:順位法,項目反応理論,Mallows-Bradley-Terry モデル
川 端 一 光
(明治学院大学心理学部)評価者の選抜に適した方法でもある。また弁別 力を向上させるための評価者訓練の際にも活用 できる。
2 つ目の使用用途は,各試料に対する客観順 位を作成することである。例えば,新規開発し た 4 種の発泡酒 A,B,C,D の“香り”の好 ましさについて,大学生 100 名に順位付けを行 わせ,各商品に割り当てられた順位の度数と比 率によって,客観順位を作成するような状況で ある(Table1 を参照)。
Table 1 度数による客観順位の作成例 (括弧内は比率)
発泡酒 1 位 2 位 3 位 4 位 客観順位
A 5(.05) 13(.13) 68(.68) 14(.14) 3 位 B 10(.10) 6(.06) 16(.16) 68(.68) 4 位 C 48(.48) 20(.20) 17(.17) 15(.15) 1 位 D 22(.22) 48(.48) 13(.13) 17(.17) 2 位
客観順位作成のためのより洗練された方法と して,順位選好過程を確率モデルとして表現す る 様 々 な 統 計 手 法 が 考 案 さ れ て い る。
Critchlow,Flinger & Verducci(1991) や そ れに基づく Alvo & Yu(2014)のレビューでは,
Thurstone(1927)による順序統計量に基づく モデル(order statistics models),一対比較法 に基づく Mallows(1957)の Mallows-Bradley- Terry モデル(以降では,MBTM)といった 嚆矢的手法と,それから派生した様々な確率モ デルが紹介されている。
これらのモデルには,未知母数として各試料 の平均的嗜好度(本稿ではαで統一)が表現 されており,評価者集団の順位回答パタンから この母数が推定されるという特徴がある。得ら れた数値は,間隔尺度上で表現された嗜好度で あるから,試料間の客観順位が把握できるばか りでなく,嗜好度における試料の類似性・非類 似性についても定量的に考察できる。
一方で,1 つ目の使用用途である評価者の弁 別力を捉えるための順位法に対応する確率モデ ルは上述のレビューでは中心的話題ではない。
むしろ関連した研究は,多次元尺度構成法
(Multi-Dimensional Scaling,MDS)の文脈で 報告されている。例えば,順位データに対応し た個人差 MDS(Carroll & Chang,1970)では,
多次元の尺度空間における個人差を尺度の単位 の違いとして捉え,その尺度の違いを重み母数 として表現している1。しかし,後述するように,
この重み母数は評価者の弁別力の指標として直 接的に表現されていない。
Coombs(1950,1964)による展開法やその 拡 張 で あ る 多 次 元 展 開 法(Schöneman &
Wang,1972)における個人の理想点(ideal point)と呼ばれる母数は,弁別力の指標とし て有望である。理想点とは,各試料の嗜好度を 一次元尺度上に布置したとき,同一尺度上に表 現された個人の尺度値であり,その理想点と各 試料の嗜好度との距離によって,個人の判断順 位が決まる。例えば,4 つの試料 A,B,C,D の尺度値が[0.2,−0.3,0.5,1.0]であり,評価者 iの理想点が−0.4 であるのなら,評価者iの判 断順位は,[A=2 位,B=1 位,C=3 位,D=4 位]
となる。つまり理想点が明らかとなれば,集団 全体で定義される嗜好度の序列に関する評価者 iの弁別力について言及できる。
しかし上述の 2 方法は,複数の評価者が 1 組 の試料を単一観点から評価した 2 相データ(試 料×評価者)に対応するものであり,実際の官 能検査の状況に対応していない。実務・研究場 面で利用される官能検査では,3 相の実験計画 を立てることが多く,例えば,大藪・木村・三 宅(2008)では食パンの官能検査を,色,きめ,
香り,味(苦み),軟らかさ,等の複数観点か ら行わせている。先述した 4 種の発泡酒の例で いえば,“のどこし”“コク”“キレ”といった 複数観点で順位評価するような 3 相データ(試 料×観点×評価者)に対応した方法ではないと いうことである。
この点で,3 相データに対応した多次元展開 法(Desabro & Carroll,1985)で定義されて いる理想点は,弁別力の指標として最も可能性 がある。ただ,この方法は,任意の多次元空間 に複数観点から評価された試料と個人を布置す
ることを目的としているため,推定する母数が 非常に多いという特徴がある。
多次元展開法では,評価者iが観点jから試 料kを評価した時の嗜好度αijkについて,
αijk=αj+
Σ
d=1D w(xjd id−ykd)2 (1)と い う 加 法 モ デ ル を 仮 定 す る(Desabro &
Carroll,1985)。ここで,d(=1, . . . ,D)は構成 される多次元尺度空間の識別子である。αjは観 点j特有の嗜好度母数であり,xidは評価者iの 第d次元での理想点を,ykdは試料kの第d次 元での嗜好度母数を表現している。
またwjdは,第d次元での観点jにおける知 覚空間の単位の違いを表現する母数である。
wjdが小さいということは,次元dにおいて,
評価者iの理想点と各試料の嗜好度が近接して おり,かつ試料間の嗜好度の差異も小さいとい うことを意味している。
このモデルでは評価者数×観点数×試料数分 の嗜好度αijkについて,これを構造化するαj, wjd,xid,ykdという複数の未知母数を推定する。
高次元空間での現象の記述力は高くなるが,モ デルの倹約度は決して高いとは言えない。弁別 力の推定も含めた発展的モデリングを考える場 合に,3 相データに対応した,より倹約的なモ デルがあれば非常に有用である。
以上を踏まえ,本研究では官能検査の実務に おいて一般的な 3 相データに対応した,平均的 嗜好度と弁別力推定のための倹約的な統計モデ ルと母数推定アルゴリズムを提案する。この方 法を利用することで,
⃝ 最小限の母数で,集団全体での平均的嗜好 度を,評価観点別に推定できる
⃝ 各観点での客観順位を総合的に弁別する能 力を評価者別に推定できる
⃝ 推定された弁別力で条件づけた判断順位の 選択確率を推定できる
⃝ 推定された弁別力が個人毎に異なる知覚空
間の単位の違い(課題の難易度の違い)も 表現する
といった利点を享受できる。
提案手法の妥当性について研究 1 のシミュ レーション,そして研究 2 の実データへの適用 によって試みられる。また,本研究ではモデリ ングの簡潔性に配慮し,比較試料数が 4 の場合 に限定して議論する。
モデル MBTM
本研究では,提案するモデルの核に,Mal- lows-Bradley-Terry モデル(Mallows,1957)
を置く。本モデルは,項目反応理論(Item Re- sponse Theory;IRT)(Lord & Novick, 1968)における項目反応モデル(例えば Mura- ki(1992)の一般化部分採点モデル)と形状が よく似ており,モデル拡張や対応する母数推定 法の考案の際に先行研究の知見を参照できると いう利点がある。そこで,最初に,本稿での記 号の用例の確認も含めて MBTM を解説する。
評価者 i(=1,2, . . . ,I)が試料 k(=1,2, . . . , K)に対して順位法によって評価することを考 える。K 個の試料について,評価者 i が行う可 能性のある判断順位(パタン)の総数は K! で あるが,その中の特定の判断順位を l(=1,2, . . . ,K!)で表現する。
今,試料 A,B,C,D について,“A=3 位”
“B=2 位”“C=1 位”“D=4 位”という順位付 けがなされたとする。K! 個の判断順位の内,[3,
2,1,4]という特定のパタンが得られたという状 況である。ここでω(k)という関数を導入する。l
これは,特定の判断順位lにおいて,k番目の 試料に順位を与える関数である。判断順位lと して,[3,2,1,4]を仮定するならば,k=1 のと き,この関数はω(1)=3 という結果を返すこl
ととなる。したがって,[3,2,1,4]という判断 順位を得るためには,
ωl=[ω(1),l ω(2),l ω(3),l ω(4)]' (2)l
のように,4 つの関数を含んだ関数ベクトルωl
が必要になる。この関数ベクトルは,K個の試 料に対して,より一般的に
ωl=[ω(1),l ω(2),…,l ω(k),…,l ω(K)]' (3)l
と表記される。この関数ベクトルは第 l 番目の 判断順位データとも解釈できる。
評価者 i が特定の判断順位 l を得る確率につ いて,MBTM では次の項目反応モデルを適用 する。
P(il ωl|α)= exp
[ Σ
Kk=1(K−ω(k))l αk]
(4)[ Σ
K!m=1exp[ Σ
Kk=1(K−ω(k))m αk]
ここで,
α=[α1, α2,…,αk,…,αK]' (5)
であり,αkは試料 k の平均的嗜好度を表現す る母数であり推定の対象となる。
このモデルでは母数の識別のために,
Σ
Kk=1αk=0 (6)
という制約がおかれる。また,(4)式は確率を 表現しているから,0 <―P(il ωl|α)<―1 であるし,
全 て の 判 断 順 位 で 求 め ら れ た 確 率 の 和 は
Σ
K!l=1P(il ωl|α)=1 となる。(4)式は Mallows(1957)で明示された嗜好 度母数 πについて対数変換を行うことで得られ ることに注意されたい。もちろん,この変換に 対して左辺の確率は不変である。ただし,母数 の単位が Mallows(1957)と異なり,対数変換 された後の尺度で母数を解釈することとなる。
(4)式を利用した上で MBTM の拡張を試み た研究として,Critchlow & Flinger(1993)
が挙げられる。また Croon & Luijkx(1993)
では,K 個の試料の内,上位 n 個までに順位 付けをさせる課題に対応する確率モデルを,
Pendergrass & Bradley(1960)の 3 点比較法
(triple comparison method)のための確率モ デルを拡張する形で提案しているが,このモデ ルは(4)式の和記号の上限が n に設定されるだ けであり,実質的に Mallows(1957)の下位モ デルと捉える事ができる。
(4)式で表現される MBTM は,評価者iが 単一の観点から K 個の試料を順位付けした場 合に,特定の判断順位 l を選択する確率を表現 しており,2 相データに対応するものである。
評価者 i が複数の観点から,K 個の試料を順位 付けする 3 相データには対応していない。また 個人の弁別力に関する直接的な母数も導入され ていない。本研究では MBTM の問題点を補う 形で,弁別力推定のための倹約的な確率モデル を提案する。
提案モデル
評価者 i が観点 j から K 個の試料に順位付け することを考える。このとき,特定の判断順位 l を行う確率を
Pijl(ωjl|θi,αj)= exp
[ Σ
Kk=1(K−ω(k))jl αjkθi]
[ Σ
K!m=1exp[ Σ
Kk=1(K−ωjm(k))αjkθi]
(7)
と表現する。ここで,θiは評価者 i の観点によ らない弁別力母数を表現している。αjkは観点 j で評価した時の,試料 k の嗜好度母数である。
両母数は通常未知であり推定の対象となる。嗜 好度母数αkがさらに観点の違いを表現するよ うになり,かつ,弁別力母数θiが導入がされ た点が,MBTMに対する本モデルの拡張である。
母数の識別のために,
Σ
Kk=1αjk=0 (8)
という制約がおかれる。
評価者 i の観点 j における判断順位 l は,(7)
式で定義される確率を K! 個持つ多項分布から 生成されたものと考える。後のシミュレーショ ン研究ではその前提の下でデータを生成する。
θiの解釈 θiは弁別力の指標であるが,より 正確には,“集団で求められた平均的嗜好度α の序列を正確に見抜けるか”,に関する指標で ある。提案モデルでは,未知である客観順位の 推定を行いつつ,その順位に整合的あるいは非 整合的な評価者を把握することが出来る。
提案モデルでは評価者 i に弁別力が無い場合
(集団全体で決まる客観順位を見抜けない場合)
にはθi=0 となる。(7)式から,θi=0 のとき,
すべての l について Pijl(ωl|θi,αj)=1/K! であ り,各判断順位の選択確率はチャンスレベルと なることを確認されたい。
弁別力が平均的である場合にはθi=1であり,
θiが 1 を大きく超えると,評価者 i の全ての観 点における判断順位は客観順位に完全一致する ようになる。
客観順位と平均的に逆の判断を行う弁別力を もつ評価者についてはθi=−1 となり,θiが
−1 を大きく下回ると,全ての評価観点におけ る判断順位は,客観順位と逆転したものに完全 一致するようになる。
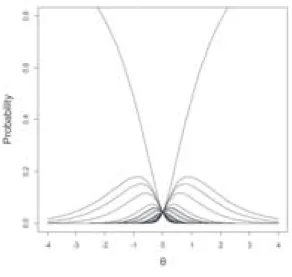
項目特性曲線 Figure 1 にα1=0.875,α2=
−1.025,α3=0.375,α4=−0.225 という条件で,
弁別力θによって 4 つの判断順位の確率が変 化する様子を描画した(Figure 1 を参照)。こ れが提案モデルにおける項目特性曲線(Item Characteristic Curve;ICC)( 例 え ば 豊 田,
2002)となる。
嗜好度母数の序列から客観順位は[1,4,2,3]
であり,θiが高い評価者ほどその判断の選択確 率が高くなる。一方で,2 位と 3 位を誤って評 価した[1,4,3,2]という判断については,θiが 高くなるほど選択確率が低くなる。
θiが 0 の部分では,破線の水平線の高さが対 応する確率になっている。この確率は 1/4!=
0.042 であり,当該評価者がチャンスレベルで しか回答できないことを意味している。
θiが負に大きくなると,[4,1,3,2]の選択確 率が高くなる。この順位づけは嗜好度の序列
([1,4,2,3])と完全に逆である。[4,1,2,3]のよ うに一部が逆の順位付けの場合には,θiが負に 大きくなるほど,選択確率が低くなる。
Figure 1 は 24(=4!)の判断順位の内,4 つ のみを選択表示したものである。Figure 2 に,
Figure 1 と同じαの条件で,24 本の ICC を描 画した(Figure 2 を参照)。特定のθiで条件付 けしたときの 24 個の確率の和は 1 になること を確認されたい。
Figure 1.4 つの ICC
(α=[0.875,−1.025,0.375,−0.225]′)
Figure 2.全ての ICC
(α=[0.875,−1.025,0.375,−0.225]′)
課題の困難度と弁別力の関係 観点 j におい て K 個の試料の嗜好度母数αjが得られる。こ の母数をもとに,試料の客観順位を作成するこ とができるが,αjの標準偏差 SD(αj)が小さい 場合は,大きい場合に比較して,より弁別が難 しい課題であると解釈できる。ここで課題の弁 別困難度(難易度)の指標として SD(αj)を利 用することを考える。この指標は,集団全体で 定義されるものであり,個人に依存していない ことに留意されたい。
観点 j で評価された試料 k に対して,評価者 i の弁別力θiを乗じた値を
βijk=αjkθi (9)
と定義する。ここで評価者 i の観点 j における 評価試料の嗜好度の標準偏差 SD(βij)を求めた ならば,以下の比を評価者 i における弁別の困 難度の指標として利用できる。
困難度比=SD(βij)/SD(αj)=θi (10)
これは評価者 i の弁別力に他ならない。
つまり,θi=1.5 の評価者における知覚空間 では,平均的な弁別力(θi=1)の評価者よりも,
嗜好度の散布状況が 1.5 倍拡大されていること になり,より容易に弁別できると解釈すること ができる。
αjが基準集団で推定されており既知である という前提で,新たな評価者 i についてθiを 推定する場合,評価者 i がどのような集団に属 していようが,θiは基準集団内で相対評価され る。また,課題の困難度 SD(αj)と個人の弁別 力とを独立に評価できていることにも大変意義 がある。
Figure 3 は,Figure 1,Figure 2 の嗜好度 を 2 倍しα1=1.75,α2=−2.05,α3=0.75,α4=
−0.45 と い う 条 件 で 描 画 さ れ た ICC で あ る
(Figure 3 を参照)。嗜好度が 2 倍されている ので,試料間の弁別がつき易い状況である。
Figure 2 と ICC の形状を比較すると,Figure
3 において,確率の変化が急峻であり,平均的 な弁別力(θi=1)の持ち主でも,0.4 以上の確率 で客観順位と整合的な判断を行えることが明ら か で あ る。Figure 3 は,Figure 1,Figure 2 の試料をθi=2 の評価者が把握する場合の知覚 空間における ICC とも解釈できる。
提案モデルのθiとは,弁別力の指標である と同時に,個人毎に異なる知覚空間の単位の違 いを表現する母数である。先述した個人差 MDS や多次元展開法で定義される重み母数 w は,知覚空間の単位の違いのみを表現するため に導入された母数であり,積極的に弁別力の指 標として利用できない。その点,提案モデルで は,単一の母数で弁別力と知覚空間の単位の違 いを表現するから,倹約性は高い。
母数推定法
モデルに対応する母数推定法として,本研究 ではマルコフ連鎖モンテカルロ法(Markov Chain Monte Carlo;MCMC)(例えば,小西・
越智・大森,2008)を併用したベイズ推定を利 用する。MCMC 法のアルゴリズムの枠組みと しては,Metropolis-Hasting 法(Hasting,1970)
Figure 3.全ての ICC
(α=[1.75,−2.05,0.75,−0.45]′)
(以降では M-H 法と略記)を採用する。アルゴ リズムの構成にあたって,Patz & Junker(1991),
宇佐美(2010),室橋(2008)による,項目反 応モデルに対する実装例を参考にした。
M-H 法では,モデルの尤度と母数の事前分 布が必要となる。以下にその設定について述べ る。
嗜好度に関する尤度 評価観点 j におけるαj
の尤度は次式で与えられる。
L(j αj|θ,Ωj)=
Π
i=1IΠ
l=1K!Pijl(ωjl|θi,αj)Zijl(11)ここでΩjは観点jにおいて I 人の評価者が,
K 個の試料を順位付けした結果が収められた サイズ I×K の順位データ行列を表現している。
またθはサイズ I×1 の弁別力母数ベクトルで ある。Zijlは評価者 i の観点 j における判断順 位を指示する関数で,判断順位 l を選択する場 合には Zijl=1,選択しない場合には Zijl=0 と なる。
弁別力に関する尤度 評価者 i の弁別力の尤 度は次式で与えられる。
L(jθj|A,Ωi)=
Π
j=1JΠ
l=1K!Pijl(ωjl|θi,αj)Zijl(12)ここでΩiは,評価者 i が全ての観点において,
K個の試料を順位付けした結果が収められたサ イズ J×K の順位データ行列である。Aはサイ ズ J×K の嗜好度母数行列である。
事前分布 嗜好度母数αjkの事前分布として は標準正規分布を仮定する。
αjk〜Normal(μα=0,σα=2) (13)
ここで Normal(μα,σα)は,母平均μα,標準偏 差σαの正規分布を表現している。またσαの数 値は,項目反応理論の 2 母数ロジスティックモ デルに含まれる困難度母数を推定するための Patz et al(1999)の設定を参考にした。
弁別力母数θiの事前分布としては,μθ=1 の 正規分布を設定する。
θi〜Normal(μθ=1,σθ=1) (14)
IRT の項目反応モデル同様に,提案モデル の母数は尺度不定であるから,この事前分布の 設定によって,θの原点と単位が決定され,そ の尺度上で嗜好度母数αが表現される。
条件付き事後分布 M-H 法では当該母数に 関する条件付き事後分布が必要となる。この事 後分布は上述した尤度と事前分布の積に比例す るから容易に導出できる。観点 j の嗜好度αj
の条件付き事後分布は,
P(j αj|θ,Ωj)∝ L(j αj|θ,Ωj)
Π
k=1K P(αjk) (15)となる。ただし P(αjk)はαjkに対応する事前分 布の確率密度である。また,評価者 i の弁別力 θiの条件付き事後分布は,
P(jθi|Ωi,A)∝ L(iθi|A,Ωi)P(θi) (16)
となる。ただし P(θi)はθiに対応する事前分布 での確率密度である。
提案分布 MCMC 法を利用することで,母 数の事後分布の形状が一般的に知られていない 確率分布であっても,そこから無数に標本
(MCMC 標本)を抽出することで,事後分布を 経験的に構成することができる。M-H 法では,
その標本が興味のある事後分布から抽出される ことを確保するために,提案分布を設定し,そ の 分 布 か ら 候 補 と し て 挙 げ ら れ た 母 数 を MCMC 標本として採用するか,あるいは棄却 するかの判断を繰り返していく。提案分布の選 択法には様々な方法があるが(例えば,Patz et al,1991),本研究では宇佐美(2010)を参考 に,αjkとθiの提案分布に標準偏差が 0.05 で,
互いに独立なK次元の多変量正規分布を利用 する。
M-H アルゴリズム 本研究では,上述した 尤度と事前分布に基づき,提案したモデルに対 応した M-H アルゴリズムを構成する。
本アルゴリズムでは最初に観点 j の嗜好度母 数αjの標本抽出から行う。先ず,αjに含まれ る K 個の要素に対応した標準正規乱数を K 個 生成する。生成された乱数は偏差化することで,
(8)式の制約を満たす。この偏差化された K 個 の標準正規乱数をαjの初期値として設定し,
αtjとする。t はアルゴリズムの反復回数を表現 する。
次に,αtjを平均ベクトルとして持つ K 次元 の多変量正規分布から,次の反復の候補値αj*
を抽出する。この多変量正規分布の共分散行 列の非対角要素は 0 であるため,実質,K 個 の独立な正規分布から,1 つずつ正規乱数を発 生させたことになる。この多変量正規分布が αjに関する提案分布である。(8)式の制約を意 図して,提案分布から抽出された母数について も偏差化しα*jに収める。
この候補値を MCMC 標本として採択し,
t+1 回目の反復に利用するかについて,次の採 択確率に基づいて判断する。
P(αj*|αtj)=min
{
LL((jj αα*jjt||θθtt,,ΩΩjj))ΠΠKk=1Kk=1P(P(αα*jjtkk)),1}
(17)
勿論,この採択確率はモデルに依存しているの で,別のモデルであれば構成要素も変化する。
M-H 法ではこの採択確率と,区間[0,1]から 発生させた一様乱数 urを比較することで,候 補値の採択の可否を決定する。本研究では P(α*j|αtj)>urならば,αjt+1=α*j そうでなければ αjt+1=αjtとする。
以上で観点 j におけるαjtの更新が終了した ので,別観点のαjtの更新を行う。この判断を J 個の観点全てで行う。最終的に,全ての観点に おいてαjt+1
となっている。
弁別力母数θiについては,最初に平均=1,
標準偏差=1 の正規乱数を初期値として与え,
θitを作成した上で,個人毎に採択確率,
P(θ*i|θti)=min
{
LL((ii θθ*iit||AAt+1t+1,,ΩΩii)P()P(θθ*iit)),1}
(18)を求め,上述の方法によってθi*=θit+1かθit+1=θit
かの 2 者択一の判断を行う。この作業を,全評 価者について順に行っていく。ここで,At+1で あり,嗜好度母数行列が全て更新後の値になっ ていることに注意されたい。
全評価者のθitがθit+1に更新されたら,θit+1と して嗜好度母数のアルゴリズムに戻る。
この一連の過程を任意の収束基準が満たされ るまで繰り返すことによって,経験的に事後分 布を生成することができる。その平均値を母数 の推定値として採用する。
研究 1:シミュレーション研究 目的
提案モデルに対応する母数推定アルゴリズム が適切に機能するかについて,シミュレーショ ン研究によって明らかにする。ここでは,後述 する実データへの適用に配慮し N=180,J=15 という設定で母数推定アルゴリズムの真値復元 力を検証する。
方法
シミュレーションデータ行列 推定対象とな る母数の真値として,αjkには標準正規乱数を,
θiについては平均=1,標準偏差=1 の正規乱 数を与えた。これらの真値と(7)式の項目反応 モデルをもとに評価者 i が観点jで判断順位 l を選択する確率 Pijl(ωjl|θi,αj)を全ての l(=1, . . . ,K!)について求め,それを母数として持つ K! 次元の多項分布から,評価者 i の観点 j にお ける判断順位を無作為抽出した。この作業を全 ての観点,全ての評価者について行うことで,
シミュレーションデータ行列を生成した。また データセット毎に母数の真値も異なるように設 定した。
真値復元精度の指標 本研究では提案した母 数推定法の精度を真値復元状況によって評価す る。具体的には平均平方誤差(Root Mean Square Error,RMSE)を利用する。試料 k の嗜好度母 数αkについては,シミュレーションデータセッ ト数を S とするとき,
RMSEαk=
√ ΣSs=1Σ
Jj=1J×S(^αsjk−αsjk)2 (19)
とする。ここで,αsjkは,第 s 番目のシミュレー ションデータにおける観点 j の試料 k の嗜好度 母数の真値を,^αsjkは推定値をそれぞれ表現し ている。また s=1,2,. . . ,S である。弁別力 母数θiについては,
RMSEθi=
√ ΣSs=1Σ
Jj=1I×S(^θsi−θsi)2 (20)
とする。ここで,θsiは第 s 番目のシミュレーショ ンデータにおける評価者 i の弁別力母数の真値 を,^θsiは推定をそれぞれ表現している。
本研究では,母数推定に要する計算時間に配 慮して,生成するデータセット数 S を 20 に設 定した。
分析プログラム M-H アルゴリズムの実行 やシミュレーションデータ生成に当たっては,
計算機言語 R(R core team,2014)にて分析 プログラムを作成し,利用した。ただし,R で の M-H アルゴリズムの実装にあたっては,宇 佐美(2010)が項目反応モデルの母数推定に利 用したプログラムを参考にした。
結果・考察
本研究では,Geweke の指標(1992)にもと づき,全母数のマルコフ連鎖が大局的に事後分 布に収束するアルゴリズムの反復回数(これを burn-in 期間と呼ぶ)として 100,000 回を設定 した。また,弁別力母数θについては記憶媒 体の容量の制限に配慮して,180 個中,20 個の みについて,マルコフ連鎖の記録を行った。
burn-in 期間以降の 800,000 回の反復で得られ た MCMC 標本の算術平均を用いて,各母数の 推定値とした。
20 のデータセットの内,Geweke の指標の 観点から全マルコフ連鎖の収束状況が 90% 未 満のデータセットにおける推定値は RMSE の 評価の際に区別した。該当するデータセット数 は 10 となった。
Table 2 に, 各 母 数 の RMSE を 掲 載 し た
(Table 2 を参照)。全母数の事後分布への収束 が良好なS=10 条件では,^αjkは真値付近±約 0.13 の範囲で平均的に分布していることが明ら かとなった。小数点第 1 位での変動であり,無 視できない大きさなので,推定値が近接した試 料間の順位づけについては注意が必要であろ う。また,^θiは真値付近±0.329 の範囲で平均 的に分布していることが明らかとなった。αの 3 倍の誤差であるから,解釈にはより注意が必 要である。
Table 2 各母数の RMSE
収束条件 α1 α2 α3 α4 θ
S=10 .120 .108 .137 .140 .329
S=20 .146 .150 .150 .155 .342
収束が良好でないデータセットの結果を含め
たS=20 条件では,全母数で相対的に RMSE
が大きくなっているが,その増分は極端なもの ではなく,アルゴリズムが発散しているとは考 え難い。
Table 3 に,推定値と真値間の相関係数を求 め,データセット数分の平均を求めた結果を掲 載した(Table 3 を参照)。母数やデータセッ ト数の条件に依らず,相関係数は 0.99 以上で あり,非常に高い。真値の分布の形状はかなり 精度高く復元されていることが分かる。収束が 良好でないデータセットを含めても高い相関係 数が得られていることから,提案した M-H ア ルゴリズムには一定の母数復元力があると考え られる。
Table 3 推定値と真値の相関係数の平均値
収束条件 α1 α2 α3 α4 θ
S=10 .994 .993 .994 .994 .945
S=20 .994 .994 .994 .994 .944
研究 2:適用例 目的
シミュレーション研究により,N=180,J=
15 という条件において,提案アルゴリズムに 一定の母数復元力が確認されたので,次に実 データに適用し,結果の解釈可能性の観点から,
モデルや母数推定アルゴリズムの妥当性につい て検証する。
方法
調査参加者 都内の私立大学生 189 名に対し て,後述する順位判断課題が含まれた質問紙調 査を実施した。回答に先だって,同意書への署 名を求めていたが,2 名の参加者について署名 に不備があったので,分析から除外した。また,
1 つでも欠損のあった回答についても分析から 除外した。結果として,分析に用いた標本サイ ズは 183 となった。性別の内訳は,女性 129 名
(平均年齢=20.093,SD=1.228),男性 54 名(平 均年齢=20.462,SD=1.969)であった。
課題 評価対象となる試料を知らないことに よるデータの欠損を回避するため,全評価者に とって身近なスポーツの競技種目を試料とし た。平田(2000)では大学生にとって関心をも たれやすい種目として,野球,テニス,サッカー,
バスケットボールが挙げられている。そこで,
本研究では,この 4 種目を評価対象試料とした。
課題では,この 4 試料について 15 の観点か ら順位付けさせた。そのうちの 13 の観点は,
平田(2000)に掲載されているスポーツのイメー ジに関する形容語のリストの中から選出した。
具体的には,“さわやか”“汗”“楽しい”“走る”
“疲れる”“健康”“体力”“精神力”“苦しい”“努 力”“熱い”“感動”“青春”である。また,平 田(2000)が述べるように,スポーツのイメー
ジは特定の競技種目と強く結び付いているた め,評価観点として“スポーツ”を導入した。
さらに,4 種目に対する個人毎の嗜好度を評価 するために,“やってみたい”という観点も付 け加えた。
種目の経験の有無が弁別力に影響を及ぼすか を検討するため,質問紙の最後で,上述 4 試料 について,経験したことのない種目の記述回答 を求めた。ソフトボール経験者については野球 経験者として処理した。
結果・考察
各母数の事前分布や提案分布の設定,初期値 の設定等については,シミュレーション研究の 設定を採用した。また,マルコフ連鎖について も,シミュレーション研究の設定同様に burn- in 期間を 100,000 回とし,その後の 800,000 回 の反復で得られた MCMC 標本を用いて,母数 推定値を得た。Geweke の指標の観点からは全 母数のマルコフ連鎖の収束率は92.5%であった。
^αjの分布と推定精度 Table 4 に^αjとそれ に基づく客観順位を掲載した(Table 4 を参 照)。観点別に各試料の嗜好度(そして客観順 位)が変動していることが伺える。
Figure 4 は^αjの分布を観点別に描画したも のである(Figure 4 を参照)。同一試料の嗜好 度の観点による推移を表現している。折れ線が 交差している部分では,観点によって試料の順 位が変動している。
各 母 数 の 推 定 精 度 を 表 現 す る 標 準 誤 差
(MCMC 標本の標準偏差)を,Table 5 に掲載 した(Table 5 を参照)。殆どの母数において,
標準誤差は小数点以下第 2 位での変動であり,
推定精度が高いことが伺える。この結果は,本 モデルと母数推定法が実データに対して適切に 機能していたことの証左として考えることがで きる。
^αjの解釈 推定された嗜好度母数が解釈可 能であるか,そして,提案したモデルが実デー タに対して妥当に機能しているかについて検証 するために,Table 4 に掲載された嗜好度母数
Table 4 観点別の^αjとSD(^αj)(括弧内は客観順位)
観点 野球 テニス サッカー バスケット SD(^αj)
スポーツ 0.144(2 位) −0.500(4 位) 0.618(1 位) −0.263(3 位) .425
さわやか −0.834(4 位) 0.588(1 位) 0.321(2 位) −0.074(3 位) .536
汗 0.513(1 位) −0.825(4 位) 0.052(3 位) 0.260(2 位) .503
楽しい −0.220(4 位) 0.068(2 位) 0.045(3 位) 0.108(1 位) .129
走る −0.676(3 位) −0.913(4 位) 1.237(1 位) 0.352(2 位) .858
疲れる −0.797(4 位) −0.408(3 位) 0.593(2 位) 0.612(1 位) .618
健康 −0.161(3 位) 0.465(1 位) −0.013(2 位) −0.290(4 位) .286
体力 −0.552(3 位) −0.603(4 位) 0.617(1 位) 0.538(2 位) .578
精神力 0.261(1 位) 0.100(2 位) −0.176(3 位) −0.185(4 位) .189
苦しい −0.141(3 位) −0.384(4 位) 0.235(2 位) 0.290(1 位) .277
努力 0.428(1 位) −0.183(3 位) −0.013(2 位) −0.232(4 位) .260
熱い 0.596(1 位) −0.498(4 位) 0.069(2 位) −0.167(3 位) .399
感動 0.808(1 位) −0.624(4 位) 0.275(2 位) −0.459(3 位) .577
青春 1.030(1 位) −0.993(4 位) 0.357(2 位) −0.393(3 位) .763
やってみたい −0.148(4 位) 0.172(1 位) −0.042(3 位) 0.018(2 位) .116
Figure 4.^αの観点による推移
を利用して,評価者集団が各種目に対して抱い ているイメージを検証した。具体的には,4 つ の嗜好度母数を利用して(4 変数を利用して)
15 観点のクラスタリングを行い,各クラスタ―
内で種目別に嗜好度の平均値を求め比較した。
Table 4 の嗜好度母数行列について階層的ク ラスター分析(ward 法)を利用したところ,
3 クラスターが抽出された。
第 1 クラスタには,“汗”“努力”“精神力”,
そして“苦しい”というように,心身の鍛練に 関与しうる 4 観点が含まれていた。また,“ス ポーツ”“熱い”“感動”“青春”という 4 観点 も含まれていたが,これらの観点は,中学・高 校の青春時代を通じて評価者が直接的もしくは 間接的に経験した部活動での取り組みを連想さ せるものと解釈できる。以上の 8 観点を踏まえ,
本クラスタを“部活イメージクラスタ”と命名 した。
第 2 クラスタは,種目に関する身体的なイ メージに関連した 3 観点(“走る”“疲れる”“体 力”)で構成されているから,“身体イメージク ラスタ”と命名した。
第 3 クラスタには,“楽しい”“やってみたい”
という種目への取り組みに対する興味関心を表
現する 2 観点が含まれていた。また,第 1 クラ スタで定義される,部活動での真剣な種目への 取り組みではなく,“さわやか”“健康”のよう な,もっと関与の浅い取り組みを印象付ける 2 観点が含まれていた。以上,4 観点を踏まえて 本クラスタを“趣味・健康イメージクラスタ”
と命名した。
Table 6 に各試料の嗜好度の平均値をクラス タ別に掲載した(Table 6 を参照)。部活イメー ジクラスタでは,嗜好度の序列は 1 位 : 野球,
2 位 : サッカー,3 位 : バスケットボール,4 位 : テニスの順であった。特に,野球とサッカーが 他の種目に対して相対的に嗜好される結果と なった。両種目は中学・高校時代に生徒が部活 動で取り組むスポーツとして代表的であり,高 い能力をもった生徒達はプロ選手の予備軍とし て各種マスコミでも取り上げられることも多い ため,評価者集団において,“中学・高校時代 の部活の代表”というイメージが形成されてい た可能性がある。本クラスタに含まれる観点“ス ポーツ”における嗜好度の順位は,Figure 4 から,1 位:サッカー,2 位:野球である。野 球とサッカーの強い印象のため,バスケット ボール,テニスの部活動のイメージは相対的に Table 5 ^αjの標準誤差(MCMC 標本の SD)
観点 野球 テニス サッカー バスケット
スポーツ .048 .061 .070 .050
さわやか .092 .068 .056 .050
汗 .063 .090 .048 .051
楽しい .043 .038 .037 .039
走る .084 .094 .124 .074
疲れる .087 .065 .073 .074
健康 .044 .059 .040 .047
体力 .072 .073 .074 .070
精神力 .045 .040 .041 .042
苦しい .043 .053 .045 .048
努力 .056 .044 .040 .044
熱い .069 .062 .045 .047
感動 .088 .073 .057 .063
青春 .106 .102 .067 .068
やってみたい .040 .040 .037 .037
低く評価されてしまったものと解釈することが できる。
身体イメージクラスタでの嗜好度の序列は,
1 位 : サッカー,2 位 : バスケットボール,3 位 : テニス,4 位 : 野球の順であった。サッカーと バスケットボールが相対的に嗜好される結果と なったが,両種目は,他の 2 種目に比較して フィールドを長時間にわたり走り続ける必要が あるから,疲れやすい種目であり,より体力が 必要であるとイメージされた可能性が高い。
趣味・健康イメージクラスタでの嗜好度の序 列は,1 位:テニス,2 位:サッカー,3 位:
バスケットボール,4 位 : 野球の順であった。2 位のサッカーと 3 位のバスケットボールの嗜好 度の差はわずかであるから,第 1 位のテニスが 非常に強く嗜好されていることが明らかとなっ た。テニスは年齢や性別を問わず取り組める種 目である。大学生の趣味としてのサークル活動 や,高齢者の健康維持活動に盛んに利用されて いることからも,この結果は納得がいくもので ある。運動量の多いサッカーや,バスケット ボールは,趣味・健康目的の評価者にとっては 選択し難い種目であると考えられる。
一方,野球は運動量という点ではそれほど高 くなく,競技する者を選ばないはずであるが嗜 好度が最も低い。この点については,種目に参 加するための装備面での準備事項が他種目と比 較して多く,軽い気持ちで始められないという ことが影響したのかもしれない。
以上,15 の観点を 3 つのクラスタに次元縮 約することで,4 つの種目に対する評価者集団 のイメージについて一定の解釈が可能であっ た。提案モデル中に表現された嗜好度母数の推 定値が,ノイズでもアーティファクトでもなく,
実データの分布を代表している可能性は非常に
高いと考えられる。
観点の困難度 ここでは弁別の困難度の観点 から,Figure 4において特徴的な点を考察する。
Figure 4 を参照すると,観点“走る”におい て試料間の嗜好度の差が相対的に大きい。両観 点における困難度は,Table 4 からSD(^α走る)
=.858 である。他の困難度の数値を参照すると,
この観点は,15 の評価観点の内,弁別が最も 容易であることが伺える。
“走る”という評価観点は,一試合中に走る 距離と解釈すれば,全評価観点中,最も客観的 な評価観点となりうる。多くの評価者にとって その判断は容易であり,1 位:サッカー,2 位:
バスケットボール,3 位:野球,4 位:テニス という序列が一様に報告されていた可能性があ る。ただし,野球とテニスの試料間の差(0.237)
はサッカーとバスケットボールの差(0.885)
よりも相対的に小さく,この部分での弁別はそ れほど容易ではないことも伺える。
“走る”に次いで“青春”も困難度の低い観 点であった(SD(^α青春)=.763)。野球とサッカー が非常に高く嗜好されているが,先述したよう に,両種目は中学・高校時代に生徒が取り組む 種目の代表として認知されている可能性があ り,弁別が容易であったと考えられる。
Figure 4 から,“やってみたい”において試 料間の嗜好度の差が相対的に小さい。両観点に おける困難度は,Table 4 からSD(^αやってみたい)
=.116 である。他の困難度の数値を参照すると,
この観点は,15 の評価観点の内,弁別するの が最も難しいことが伺える。
“やってみたい”という観点は,“楽しい”と 同様に,個人の嗜好を聞いている評価観点であ る。各評価者がやってみたい種目については,
嗜好の個人差が強く反映され,特定の種目に集 Table 6 クラスタ別の嗜好度の平均
クラスタ名 野球 テニス サッカー バスケット
部活イメージ .455 −.488 .177 −.144
身体イメージ −.675 −.641 .816 .501
趣味・健康イメージ −.341 .323 .078 −.060
中する可能性は低くなるので,各試料の嗜好度 は互いに接近し,弁別が難しくなったと予想さ れる。“楽しい”という観点の困難度も SD(^α走 る)=.129 と“やってみたい”に次いで高い。こ ちらも,嗜好の個人差を反映した結果と解釈で きる。
^θiの分布 Figure 5 は^θiのヒストグラムで ある(Figure 5 を参照)。平均は 1.271,SDは 0.529 であった。また,最大値は2.868,最小値は−0.133 であった。また,Figure 6 は^θiとその標準誤 差(MCMC 標本の標準偏差)の散布図である
(Figure 6 を参照)。^θiの値が大きくなるほど
標準誤差は大きくなっていき,最大で 0.618 と なった。
標準誤差の平均値は 0.369,SD は 0.008 であっ た。平均的には全ての評価者の標準誤差は 0.369 近傍の狭い区間に集中して分布していることが 伺える。標準誤差の 0.369 は無視できるほど小 さい値ではない。^θiの解釈の際にはある程度の 幅を持たせる工夫が必要だろう。特に,高弁別 力と推定された評価者ほど,^θiに含まれる誤差 も多くなることに注意が必要である。
ヒストグラムの形状は正規分布に近く,弁別 力について,個人差が存在していることが強く 示唆される結果となった。弁別力は理論的には 負値をとりうるのだが,この評価者集団では,
該当する評価者は最小値(−0.133)を獲得し た 1 名のみであった。
^θiと他指標との関連 上述の 2 名の評価者
(最大値,最小値)の判断順位と客観順位(推 定された嗜好度による順位)との整合性を確認 するために,基準との不一致度も考慮した重み づけκ係数(−1<κ<1)を求めたところ,最 大の弁別力を持つ評価者で 0.760,最小の弁別 力者で−0.013 となった。^θiとκの間には対応 関係があるように見受けられた。
そこで,全評価者について重み付きκ係数を
Figure 7.θˆͱॏΈ͖κͱͷࢄਤ
48 Figure 5.θ^のヒストグラム
Figure 6.θ^と標準誤差(MCMC 標本の SD)
の散布図 Figure 7.θ^と重み付きκ係数との散布図
求め,^θiとの散布図を描画した。この散布図が Figure 7 である(Figure 7 を参照)。散布図に おける積率相関係数は r=0.884 であり,両指 標には高い整合性があることが明らかとなっ た。提案したθiは,客観的順位に対する弁別 力の指標として,一定の妥当性を保持している と考えられる。
SD(^βj)の比較 先述した弁別力が高い評価 者(^θ=2.868)と弁別力が低い評価者(^θ=−
0.133)では,試料間の知覚空間の単位が異なる。
このことは,両者において課題の困難度が異な るとも解釈できるのであった。Table 4 で示し た SD(^αj)を基準(θ=1)として,両評価者の 観点別の課題の困難度 SD(^βj)を縦軸に配置 した棒グラフを Figure 8 として描画した(Fig- ure 8 を参照)。弁別力が低い評価者の知覚空 間の単位は基準の 0.133 倍であり,弁別力が高 い評価者の単位は 2.868 倍となっている。弁別 力が低い評価者の単位を基準とするならば,弁 別力が高い評価者の単位は 21.515 倍である。
弁別力が低い評価者よりも,21.515 倍広い空間
に 4 試料を位置づければ良い後者において,客 観順位の弁別が容易であることは想像に難くな い。
弁別力と種目経験の関係 種目の経験の有無 が弁別力に対して影響を及ぼしているかについ て,経験が無かった種目の合計点(1 から 4 点 の範囲に収まる)と^θの間で相関係数を求め たところ,r=0.105 であり 5% 水準で有意でな か っ た(t(181)=1.427,p=0.155)。 経 験 の 有 無によって,種目に対するイメージは変化する 可能性があるが,個人が経験している種目がそ れぞれ異なるので,全員が経験している種目に 対して偏った回答をしたとしても,集団全体と してみたときその偏りは相殺されてしまったの かもしれない。θとκには高い相関が確認され ているので,上述の結果をもってθの妥当性 の低さを主張するには根拠が足りないと考えら れる。
以上の結果・考察を総合すると,嗜好度母数,
弁別力母数は,様々な観点から解釈可能性が高 く,実データの分布とその背後に存在する評価 Figure 8.SD(^β)の比較