マーケティングにおけるストリームデータと文字列解析
矢田勝俊1 要 旨 本研究の目的は、顧客の店内購買行動に関するストリームデータに対して文字 列解析技術を適用することで、正負事例それぞれがもつ販売エリア訪問パターン 文字列から有用な知見を抽出することができる知識発見システムを提案すること である。我々は顧客動線データの中で顧客の販売エリアへの立ち寄りに注目し、 その訪問パターンを文字列で表現することによって、膨大なストリームデータを 効率よく扱うことを提案した。実験の中でより多くのアイテムを購入する顧客の 特徴的なエリア訪問パターンが抽出され、その有用性を示すことができた。また 予測精度や計算時間、インデックス機能などの検討を行い、今後の技術的な課題 を明らかにすることができた。本論文において、マーケティング分野におけるス トリームデータの可能性、文字列解析手法の有用性を示唆することができた。 キーワード: マーケティング,RFID,ストリームデータ,文字列解析, EBONSAI. 1関西大学 商学部:〒564-8680 大阪府吹田市山手3-3-35 SIG-DMSM-A702-09 (10/6)Stream Data and String Analysis in Marketing Katsutoshi Yada
(Faculty of Commerce, Kansai University)
The purpose of this paper is to present a business application for knowledge discovery from stream data using string analysis technique to find useful rules in visiting patterns of sales area. In this paper we have focused on stationary state of customer at a certain sales area in a store. We have applied string analysis technique, EBONSAI, to sales area visiting patterns to effectively deal with huge stream data. In experiments we can extract useful rules and knowledge about charactaristics of sales area visiting patterns and verify effectiveness of our method. And we discuss about prediction accuracy and computing time and clarify technical problems of EBONSAI in future.
1. はじめに RFIDは急速な技術進歩と低価格化が進むことによって、多様なビジネスに用 いられるようになった。近年、その用途はマーケティングなどの小売業にまで拡 大している。経済産業省における電子タグ実証実験においては、『日本版フュー チャーストア・プロジェクト(経済産業省(2005))』として、RFIDのついたカー トを用いて顧客の店内行動を把握し、店頭の販売活動ならびに顧客行動に関する 情報を収集している。このプロジェクトでは、顧客の移動経路に関するデータが 電子的に蓄積されており、従来ではブラックボックスであった店内の顧客の購買 行動に関する詳細な情報を獲得している。こうした動きは日本だけでなく、欧米 各国においても見られ、店内の顧客行動に関するRFIDを用いた詳細な情報収集 が注目を集めている。 従来、小売業における消費者行動の理解のために、POSデータのような顧客の 購買履歴データが用いられてきた。これらを利用すれば、どの顧客がいつ何をど れだけ購入したかが分かり、その購買行動を詳細に分析することが可能になる。 従来からマーケティング分野においては、顧客の購買履歴を用いた多様な消費者 モデル(Guadagni and Little(1983))が提案されている。近年では、こうした膨 大なデータを扱うために、多くの企業ではデータマイニングが導入されている (Hamuro et al.(1998),矢田(2004))。しかしながら、顧客の購買履歴データはその 顧客の購買結果が記録されているものの、彼女たちがどのように店内を移動しそ れらを購入したのかを知ることはできない。既存研究において、店内における顧 客の移動経路はブラックボックスとして扱われ、主にその結果である購買データ だけが分析対象とされてきた。 上述したように、近年のRFID技術の進展はこうした状況を一変させている。 特にRFID技術のマーケティング応用研究の中で、最も注目されているのは、顧 客または顧客のカートにRFIDを付与し、店内の購買行動、移動経路を解析する 顧客動線分析(Sorensen(2003))である。従来のマーケティング研究のように購 入商品という結果からではなく、顧客の店内での移動経路から新しい店頭販売活 動の知見を得ようとするものである。こうした顧客動線に関する客観的なデータ に基づいた研究は実は極めて少ない。なぜなら従来、そういうデータを収集する ことが極めて困難であったためである。したがってRFIDを用いて得られる顧客
動線データは、マーケティング研究における新しい研究フロンティアの源泉を提 供するものと思われる。
このようなRFIDを用いた顧客動線分析の既存研究として、Larson et al.(2005)
の研究がある。彼らは顧客が利用するカートにRFIDを付与し、店内の顧客の移 動軌跡に関するデータを解析した。彼らはk-meansを改良したクラスタリング手 法を用い、複数の顧客グループを発見し、それらを詳細に検討することで、様々 な仮説を提示している。しかしながら、顧客動線データからの特徴抽出や分類問 題に焦点を置いた研究、適用事例はいまだ存在しない。小売業の現場では、所与 のマーケティング戦略から導き出されたターゲット顧客について、その特徴把握 や購買行動の理解に関するニーズは大きい。したがって、クラスタリング問題だ けでなく、分類問題や特徴抽出に焦点を置いたアプリケーション研究は重要なビ ジネス・インプリケーションがあるものと思われる。 本論文で扱うRFIDデータは通常、ストリームデータ(またはデータストリー ム)と呼ばれる。ストリームデータとは、時間的に変化する対象の変化を電子的 にかつ継続的に記録したデータのことである。流通分野や通信分野ではこうした データから有用な知見を得たいというニーズは高く、またデータマイニングの重 要な応用領域としても、多くの研究者の関心を集めている(有村(2005))。その データ規模は膨大であり、また従来の研究で主に扱われていたような表形式デー タに用いられた手法を直接、適用することは難しい。 そこで我々は本論文において、顧客動線情報を含むストリームデータに対して 文字列の知識表現を導入し、ビジネス分野での文字列解析のアプリケーションで あるEBONSAI(Hamuro et al.(2002), Yada et al.(2007))の適用を提案する。つま りストリームデータから顧客の店内の移動経路に関する情報を抽出し、それらを 文字列として表現することで、既存の文字列解析手法を用いてルール抽出を行お うと考えた。こうした既存技術の新しい領域への適用は、その技術の有用性を示 すだけではなく、新しい技術的課題も明らかにしてくれる。本研究では、実際の ストリームデータへの適用を通して、文字列解析手法のストリームデータへの適 用可能性と技術的課題について議論したい。
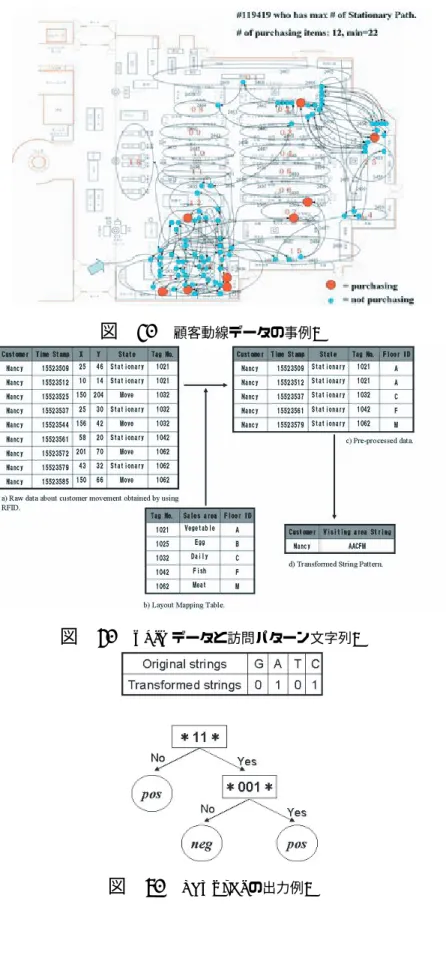
2. 顧客動線分析と文字列解析 2.1 顧客動線分析と文字列解析 顧客動線分析とは、店舗内を顧客が移動した経路を分析することによって、店 舗レイアウトの設計や店内の販売促進計画の効率化を行おうとする店舗マネジメ ント手法の1つである。図1は実際の顧客動線を店舗レイアウト上に表現したも のである。顧客が移動した経路とその方向は矢印付のリンクで表現されている。 また、顧客が立ち止まった場所はノードで表され、赤のノードは何らかの商品購 入を意味する。図から分かるように、顧客は極めて複雑な経路を移動し、買い物 を行っている。 −−−図1−−− 買物行動で特に重要なのが売場への立ち寄り率、つまり顧客がある売場を通っ た際に立ち止まったかどうかである。顧客はあるものを購入するためにカートを 止め、その商品を手に取り、カートへ入れる動作が必要になる。それが売場への 立ち寄りとしてデータ上、表現される。中には、売場で立ち止まったが、実際に は商品を購入しなかった場合も存在するだろう。そうした購入の有無は動線デー タと販売データを比較すれば容易に判別できる。こうした情報は店頭マーチャ ンダイジングを行う企業にとって、極めて重要な情報となり得る。したがって、 我々は本稿において、顧客動線データ内の売場への立ち寄りに焦点をあて、顧客 の店内移動経路の特徴を抽出する。 RFIDから得られるストリームデータはそのままでは処理が難しいため、何ら かの加工の工夫が必要である。そのため本論文では、顧客動線データを分析する ための知識表現として文字列を用いる。図2を用いて、その変換プロセスを説明 しよう。図2のa)はRFIDから得られる元データである。顧客識別情報や時間、 X、Y方向への加速度、カートの状態、受信したRFIDのタグNoなど様々な項目 が含まれている。この元データを、売場レイアウトとRFIDタグを関連付け、フ ロアIDを付与したレイアウト・マッピングテーブルb)を用いて変換する。RFID の各レコードは、各フロアにユニークな1文字に変換される。その際、顧客がそ の売場に立ち止まっているデータだけに絞り込む。最後に訪問順番を基準にフロ アIDを結合することによって、文字列パターンd)が得られる。例えば、図2の
顧客Nancyの訪問パターンはb)のマッピングテーブルを用いると”AACFM”と表 現される。 −−−図2−−− 2.2 本研究の目的 本研究の目的は、顧客の店内の購買行動に関するストリームデータに対して文 字列解析技術を適用することで、正負事例それぞれがもつ販売エリア訪問パター ン文字列から有用な知見を抽出することができる知識発見システムを提案するこ とである。本システムを構築するにあたり、我々は既存のEBONSAIシステムを
利用する。EBONSAI(Hamuro et al.(1998),矢田(2004))とは、ゲノム解析などに 用いられた文字列解析手法BONSAIシステム(Arikawa et al.(1993),Shimozono et al.(1994),Hirao et al.(2003))をビジネス用に改良した時系列解析システムである。 従来、EBONSAIは販売データやWEBログデータなどの時系列解析に用いられ ていたが、RFIDから発生するようなストリームデータへの適用は行われていな い。本論文では、こうしたストリームデータへの文字列解析手法の適用を試み、 手法の有効性、技術的な課題を明らかにすることで、マーケティング分野におけ るストリームデータの可能性を明らかにしたい。 EBONSAIは分子生物学の分野で開発された文字列解析手法BONSAIシステム を改良したもので、文字列で表現された正負事例が与えられたとき、その部分文 字列または部分シーケンスを用いて高精度に分類する決定木を生成するシステム である。EBONSAIはBONSAIと同様にalphabet indexingというメカニズムを内 包している。これは正負事例を特徴付ける所与の文字集合をより小さいサイズの 文字列に置き換えることで、探索空間を削減すると同時に、より少ない文字列で 解釈可能性の高いルールを抽出することを可能にするものである。 EBONSAIの機能はその出力を見ると理解しやすい。図3は、EBONSAIの出力 例を示している。EBONSAIは上部のマッピングテーブルに基づいて、所与の4 つの文字列を0と1の2つの文字列に置換する。変換された正負事例の文字列に 対して、決定木のrootから抽出された文字列と一致するかどうかが調べられる。 例えば”11”という文字列が含まれる場合、yesの矢印に振り分けられ、含まない 場合、noに分けられる。この作業を末端の葉まで繰り返すことで、与えられた
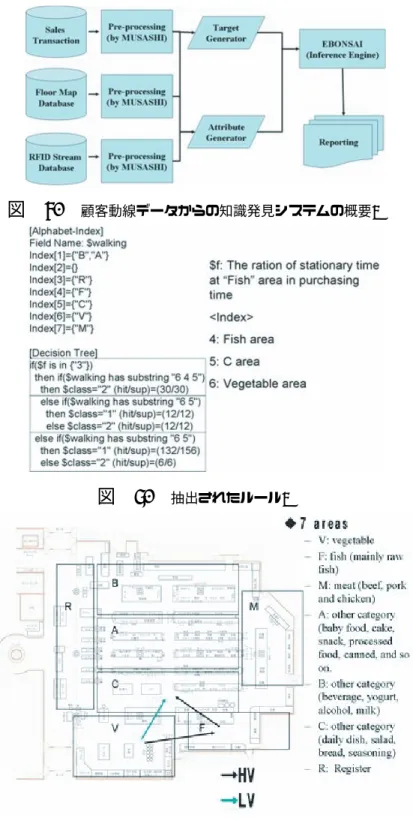
事例は正例(pos)か負例(neg)に分類することができる。このようにEBONSAIは 少数の変換された文字列を用いることで、よりシンプルで予測力のある決定木を 生成する。またEBONSAIは主に購買パターン文字列に対して利用されていたた め、100以上の文字で構成された文字列データに対応することが可能である。 −−−図3−−− 2.3 システムの概要 図4は今回開発したRFIDデータを用いた知識発見システムの概念図である。 元データとして3つのデータベースを利用し、それぞれに前処理システムが付随 している。前処理システムは、XMLデータとしてそれらを処理、蓄積し、次の ターゲット属性生成、説明属性の生成のためのシステムに引き渡される。そし て、それらのデータを融合し、マイニングエンジンによって、分類モデルが構築さ れる。これらはデータマイニングのオープンソースプラットフォームMUSASHI (羽室 他(2005))をベースに構築されている。 −−−図4−−− 次にこれらの主要なサブシステムについて、詳細を説明しよう。本システムで は3つのデータベースを利用している。第一は顧客の購買履歴データベースであ り、顧客ID、価格・商品情報などが含まれている。第二に、店舗のレイアウト データベースである。これには商品データベース、ならびRFIDのセンサー位置 情報が含まれており、店内の商品の販売位置、ならびに顧客の位置情報を追跡す ることが可能である。第三にRFIDのセンサーログデータベースである。これら をすべて統合すれば、ある顧客がどのように店内を移動し、そしてどの位置にあ る商品を購入したのかが把握できる。 次にターゲット属性の生成である。ここで開発するのは、様々なデータベース を統合し、最終的に顧客の分類モデルを構築するシステムである。したがって、 分類すべき対象となるターゲット属性を上記のデータベースから生成する必要が ある。このコンポーネントは購買履歴データベース、RFIDのセンサーログデー タベースを用い、ユーザーが任意のターゲット属性を生成する。例えば、特定商 品の購入者や店舗の優良顧客などが考えられる。
同様に、上述のデータベースから分類モデルで利用する説明属性を生成するコ ンポーネントが用意されている。ここから特定商品またはカテゴリの購入情報、 店内の移動情報などに関する説明属性が生成される。例えば、店内の移動情報か ら顧客ごとに立ち寄った売場の順序情報がシーケンスの説明属性として生成さ れる。 最後に、マイニングエンジンはこれらのターゲット属性、説明属性から分類モ デルを構築する。本システムのマイニングエンジンはEBONSAIをベースに構築 されている。したがって、上述したデータベースから生成される数値、カテゴ リ、文字列属性を用いた決定木が出力される。 3. 実験結果 3.1 データの説明 ここでは、実際の顧客動線データに対して本システムを適用し、ルール抽出の 実験を行う。データは、日本の九州地方に立地する中規模スーパーで収集された 顧客動線データを用いた。このプロジェクトでは、顧客が用いるカートにRFID レシーバーを装着し、各売場にRFIDタグを設置することで顧客の店内の購買行 動を詳細に追跡した。実験は2006年9月に実施され、顧客動線データのほかに、 フロアレイアウト、販売履歴データなども収集された。サンプル数は216、平均 購買時間は24分、平均購入数量は約12アイテムだった。店内のフロアレイアウ トは7つのエリアに別れ、それぞれのエリアはサブエリアを持ち、サブエリアの 合計は17であった。 本実験における分析目的は、この論文で提案したシステムを用いて、より多く のアイテムを購入する顧客がどのような店内移動経路の特徴を持っているのかを 明らかにすることである。今回はデータの制約もあり、来店時の購入アイテム数 を用いており、それぞれの顧客の購買間隔日数や金額デシル(1ヶ月あたりの購 買金額合計)などは考慮できなかった。クラスタリング手法はk-meansを利用し、 より多くのアイテムを購入したHighVolume顧客(HV)、それ以外のLowVolume 本研究で利用したデータは、(株)ボンラパス、(株)博報堂、(株)富士通研究所からご提供いただいた データをもとに作成した。記して謝意を表したい。
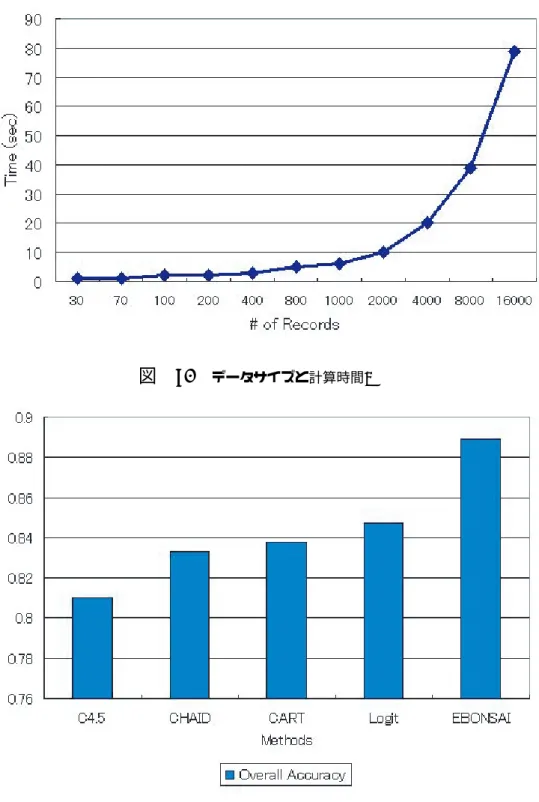
顧客(LV)と定義した。HVの1回来店あたりの平均購入アイテム数は19、LVは 7.86で、統計的に有意な差(p=0.05)があった。 今回の実験では、説明属性を生成するコンポーネントから出力された文字列属 性と数値属性の2種類を利用した。文字列属性としては、顧客の販売エリアの訪 問パターン文字列(walking)を用意した。エリアもしくはサブエリアで構成さ れた2つの文字列属性を用意した。 また、数値属性としては各エリアx(x=1,...,7)の滞在合計時間の構成比を利用 した。顧客iがエリアxにtix 秒滞在したとき、顧客iのエリアxの滞在時間構成 比 rix は、次のように表せる。 rix = tix ∑ tix (3.1) 各エリアの構成比として、7属性をモデル構築に利用した。 3.2 ルール抽出とその解釈 EBONSAIによって分類モデルの構築を行ったところ、図5のような非常にシ ンプルな結果を得た。図中のclass1がLV、class2がHVである。属性fは魚売場 の滞在時間の構成比であり、売場訪問パターン文字列の4が魚売場、5は定番棚、 6が野菜売場である。 −−−図5−−− 得られたルールは3つである。第一のルールでは、魚売場の滞在時間構成比が 10%を超え、かつ野菜売場から魚売場、その後定番棚へ向かう訪問パターンを 持っているとHV顧客になるというものである。第二のルールでは、魚売場の構 成比が10%を超えていても、訪問パターンに野菜売場から定番棚に向かう文字 列が含まれているものはLV顧客になるというルールである。そして第三のルー ルは、魚売場の構成比が10%以下で、かつ野菜売場から定番棚への文字列が含 まれているものはLV顧客になるというものである。 −−−図6−−− 得られたルールで特徴的なのは、野菜売場からどの売場(定番棚もしくは魚売 場)へ移動するのかが購入アイテム数、つまりHV顧客とLV顧客の分岐点になっ
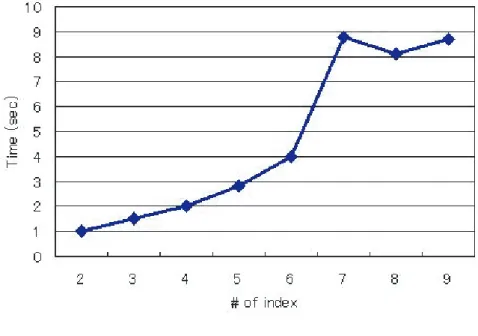
ていることを示している点である。専門家によると、スーパーにおける魚売場は その店舗の顧客忠誠度を惹きつける最も重要な売場の1つである。従来、店舗の 担当者らは魚売場での滞在時間が長い顧客ほど多くのアイテムを購入してくれる という単純な仮説を持っていた。しかしながら、この実験ではむしろ、販売エリ ア移動のパターンに重要な特徴が見られたのである。 そもそもターゲット属性はその顧客の当日のアイテム数を基礎に分類している ため、HV顧客は多くの売場を訪れているはずである。一方、購入アイテム数の 少ないLV顧客は当初の購買目的アイテムの売場のみを訪れている可能性がある。 購入アイテム数の少ないLV顧客が魚売場に行っていることもあるが、彼女たち は野菜売場から魚売場には向かわず、定番棚を訪れる。HV顧客は野菜売場から 魚売場への移動が見られるが、これは野菜売場で購入商品(魚)を決定している からかもしれない。その場合、野菜売場で顧客の購買意欲を刺激し、需要を喚起 できるかが重要と考えることもできるだろう。 3.3 文字列解析手法の有用性と技術的な課題 文字列解析手法による販売エリアの訪問パターン分析は従来の手法と比較し重 要な知見をもたらすと考えられる。文字列という知識表現は、典型的な表構造の データよりも訪問パターンに関するリッチな情報を表現することが可能である。 実際に実験から得られたパターンも顧客の店内移動パターンの特徴を抽出するこ とができている。このように、文字列解析手法は販売履歴データだけではなく、 マーケティングにおけるストリームデータに対しても、その有用性が高いと考え られる。 −−−図7−−− 図7はEBONSAIを用いたルール抽出のための計算時間とデータサイズの関係 を示している。データサイズと計算時間はほぼ比例しており、将来的にレコード 数の増大は大きな障害にはならないものと推測される。 そこでEBONSAIと他の手法を予測精度の観点から比較してみよう。評価指標 は、正しく分類された正負事例が全事例に占める割合として、Overall Accuracy
(Witten and Frank(2000))を用いた。図8は各手法を適用した交差検証(10 fold)
め、各エリアの滞在時間構成比の7属性のみを利用している。図8から分かるよう に、EBONSAIは他の手法と比べ約4%以上、精度が高かった。これは、EBONSAI
が利用した訪問パターンの文字列属性に分類に有用な情報が含まれているからで あると考えられる。
−−−図8−−−
次にEBONSAIの中のIndexingの機能について検討を加えたい。EBONSAIに おいてIndexingは、単に探索空間の削減だけではなく、ルールの意味解釈を容易 にするという効果を持つ。例えば、ブランドスウィッチパターンへEBONSAIを 適用した場合、同じメーカーから発売されているブランドや同じ味、類似のター ゲットを持つブランド(低価格帯の商品など)がIndexingによって、1つの文字 に置き換えられることが多い。これによって、出力されるルールが単純化され、 ルールの解釈可能性が非常に高くなるという効果を持つ。しかし、顧客動線分析 においては、ルールの解釈可能性という点でIndexingが十分に機能しない。なぜ なら複数の売場が1つの文字に置き換えられ、そのグルーピングに特定の意味を 見つけ出すことが困難なためである。実際に専門家との議論において、Indexing はむしろ混乱を招いた。顧客動線分析では、特定の経路を見つけることに多くの 専門家が興味を持っているため、これらの分析ではIndexingを利用しない、もし くはインデックスのサイズをなるべく大きくとる方法を検討すべきである。 −−−図9−−− しかし、インデックスのサイズを大きくすることは通常、計算時間の増大を招 く。図8はEBONSAIのパラメーターであるインデックスのサイズと計算時間の 関係を示したものである。この実験では、販売エリアはより詳細なサブエリアを 採用したため、店内が17のエリアに分割されている。EBONSAIのインデックス のサイズはパラメーターで設定する仕様になっており、デフォルトは2である。 予測精度という観点からみれば、多くの場合、インデックスサイズが2もしくは 3のときに高い精度が得られることが多い。またインデックスサイズが小さいほ ど計算時間は短縮される傾向を持つ。図8のグラフにおいて、インデックスのサ イズ7から計算時間が長くなるが、それ以降の極端な伸びはなかった。その理由 としては、極端に訪問頻度の低いサブエリアが多く含まれていたためと考えられ
る。計算時間という観点から見れば、インデックスのサイズを大きくしても十 分に対応が可能と思われる。しかしながら、現在のEBONSAIの最大のインデッ クス数は9であるため、今後、さらに大きなサイズのインデックスが扱えるよう 改良する必要がある。また、顧客が様々な売場を訪れるような店舗の場合、イン デックスのサイズの増大が計算時間の極端な増大を招く可能性もある。したがっ てIndexing以外の新しいアプローチによる探索空間の削減方法について、検討す る必要があるだろう。 4. むすび 本研究ではRFIDを用いて得られた顧客動線に関するストリームデータに対し て、既存の文字列解析手法を適用し、顧客の購買行動に関する知識発見を試み た。我々は顧客動線データの中で顧客の売場への立ち寄りに注目し、販売エリア の訪問パターンを文字列で表現することによって、膨大なストリームデータを効 率よく扱うことを提案した。より多くのアイテムを購入するHV顧客には野菜売 場から魚売場へと移動する特徴的な訪問パターンが見られた。こうして得られ た仮説は新規性が高く、示唆に富むものであったが、サンプル数の問題などもあ り、今後の検証が不可欠である。またこの実験を通して、既存の文字列解析手法 の課題を理解することができた。 しかしながら、本研究で利用した文字列解析手法の適用には本質的な問題が存 在する。それは訪問パターンに関する時系列情報が大幅に消失していることで ある。例えば、売場間の移動時間やある売場への滞在時間といった重要な情報が 文字列の知識表現の中に反映されていないのである。こうした問題の解決には、 グラフ構造データの導入といった新たな知識表現の導入が考えられる。グラフ構 造データであれば、販売エリアの訪問パターンだけでなく、売場間移動時間や滞 在時間などの時系列情報を含めることが可能である。今後の課題として取り組み たい。 参 考 文 献
Arikawa, S., Miyano, S., Shinohara, A., Kuhara, S., Mukouchi, Y. and Shinohara, T. (1993). A machine discovery from amino acid sequences by decision trees over regular patterns, New Generation Computing, 11, 361–375.
有村博紀 (2005). 大規模データストリームのためのマイニング技術の動向, 電子情報 通信学会論文誌 D-1, J88-D-1, 563–575.
Guadagni, P. M. and Little, J. D. C. (1983). A logit model of brand choice,calibrated on scanner data, Marketing Science, 2, 203–238.
Hamuro, Y., Katoh, N., Matsuda, Y. and Yada, K. (1998). Mining Pharmacy Data Helps to Make Profits, Data Mining and Knowledge Discovery, 2, 391–398.
羽室行信・加藤直樹・矢田勝俊・鷲尾隆 (2005). 大規模ビジネスデータからの知識発 見システム:MUSASHI, 人工知能学会誌, 20, 59–66.
Hamuro, Y., Kawata, H., Katoh, N. and Yada, K. (2002). A Machine Learning Algorithm for Analyzing String Patterns Helps to Discover Simple and Interpretable Business Rules from Purchase History, Progress in Discovery Science, LNAI 2281, 565–575. Hirao, M., Hoshino, H., Shinohara, A., Takeda, M. and Arikawa, S. (2003). A practical algorithm to find the best subsequences patterns, Theoretical Computer Science,
292, 465–479.
経済産業省 (2005). 『日本版フューチャーストア・プロジェクト』について, News
Release, 1–10. (http://www.meti.go.jp/press/20051108001/20051108001.html)
Larson, J.S., Bradlow, E.T. and Fader, P.S. (2005). An exploratory look at supermarket shopping paths, Int. J. Research in Marketing, 22, 395–414.
Sorensen, H. (2003). The Science of Shopping, Marketing Research, 15, 30–35.
Shimozono, S., Shinohara, A., Shinohara, T., Miyano, S., Kuhara, S. and Arikawa, S. (1994). Knowledge acquisition from amino acid sequences by machine learning sys-tem BONSAI, Trans. Information Processing Society of Japan, 35, 2009–2018. Witten, I.H. and Frank, E. (2000). Data Mining: Practical Machine Learning Tools and
Techniques with JAVA Implementation, Morgan Kaufmann.
矢田勝俊 (2004). マーケティングにおけるデータマイニングの利用, 人工知能学会誌,
19, 376–377.
tree-based decision analysis of new product sustainability, Decision Support Systems,
図 1. 顧客動線データの事例.
図 2. RFIDデータと訪問パターン文字列.
図 4. 顧客動線データからの知識発見システムの概要.
図 5. 抽出されたルール.
図 7. データサイズと計算時間.