特集●ソフトウェア論文
オープンソース組込みシステム向けシミュレータの
マルチプロセッサ拡張
安積 卓也 古川 貴士 相庭 裕史 柴田 誠也 本田 晋也
冨山 宏之 高田 広章
本論文では,オープンソースとして公開している,組込みシステム向けのマルチプロセッサ対応シミュレータについ て述べる.本シミュレータは,マルチプロセッサ向けリアルタイム OS やアプリケーション開発の効率化を目的と し,既存のシングルプロセッサ用 ISS (Instruction Set Simuator:命令セットシミュレータ) を拡張して,プロセッ サ個数分のシミュレータを連携動作させることで,ISS の少ない変更で,マルチプロセッサ対応のシミュレーション 環境を実現可能である.マルチプロセッサ対応のシミュレーション環境を実現するために,ISS 間の (1) 共有メモリ 機構,(2) 排他制御機構,(3) プロセッサ間割込み機構,(4) タイミング同期機構,を新規開発した.さらに,リアル タイム OS のアイドル処理を利用したシミュレーション時間の短縮手法を提案する.本方式は,本研究で対象とした ISS 以外にも適用することが可能である.This paper presents an open source simulator corresponding multiprocessors for embedded systems. The purpose of the simulator is to effectively develop a real-time OS and application for multiprocessors. To realize the multiprocessor simulation environment, an ISS (Instruction Set Simulators) for a single processor is extended with few modifications and cooperate with other ISSes. There are four newly-developed mech-anisms between ISSes as follows: (1) a shared memory mechanism, (2) an exclusion control mechanism, (3) an interrupt mechanism, and (4) a synchronism mechanism. Moreover, the method of reducing simulation time to use the idle time of the real-time OS is proposed. It is possible to adapt this environment to other kinds of ISSes.
Open Source Simuator for Embedded System Ex-tended Multiprocessor.
Takuya Azumi, Hiroyuki Tomiyama, 名古屋大学大学院 情報科学研究科,現在,立命館大学, Graduate School of Information Science, Nagoya University. Presently with Ritsumeikan University.
Takashi Furukawa, 名古屋大学大学院情報科学研究科, 現 在 ,京 セ ラ 株 式 会 社 横 浜 R&D セ ン タ ー, Grad-uate School of Information Science, Nagoya Uni-versity. Presently with Kyocera Corporation Yoko-hama R&D Center.
Seiya Shibata, 日本学術振興会特別研究員/名古屋大学大 学院情報科学研究科, Research fellow of the Japan So-ciety for the Promotion of Science/Graduate School of Information Science, Nagoya University. Hiroshi Aiba, Shinya Honda, Hiroaki Takada, 名古屋
大学大学院情報科学研究科, Graduate School of Infor-mation Science, Nagoya University.
コンピュータソフトウェア, Vol.27, No.4 (2010), pp.24–42. [ソフトウェア論文] 2009 年 11 月 13 日受付.
1 はじめに
近年,組込みシステムにおいても,性能向上・低 消費エネルギーの観点からマルチプロセッサシステ ムの利用が増えてきた.しかし,組込みマルチプロ セッサシステムのソフトウェア開発では,シングルプ ロセッサ用のRTOS(Real-Time Operating System: リアルタイムOS)を利用している場合が多い.効率 的な開発のためには,マルチプロセッサ向けRTOS の利用が必要である.さらに,マルチプロセッサシス テムは実機を使ったデバッグ環境が十分でない.そ のため,マルチプロセッサRTOSに対応したシミュ レータによるデバッグ環境が求められている. 我々はこれまでに,シングルプロセッサ対応RTOS のシミュレーション環境として,RTOSシミュレー タ[4] [10]を用いたコシミュレーション環境を開発してきた.RTOSシミュレータは,RTOSの依存部と 呼ばれるプロセッサの違いを吸収するレイヤーを利 用して,RTOSのタスクにWindowsのスレッドを割 り当てることにより,RTOS及びアプリケーション をWindows上で動作させるプログラムである.その ため,特定のプロセッサに依存しないRTOSの共通 部のコード及びアプリケーション開発に有用であり, これらがホスト計算機上のネイティブプログラムと して動作するため,非常に高速な実行が可能である. また,RTOSシミュレータと他のハードウェアシミュ レータ等との通信を実現するため,デバイスマネー ジャと呼ばれるソフトウェアを開発した.デバイスマ ネージャは,WindowsのCOMを用いてシミュレー タ間通信を仲介する. しかしながら,マルチプロセッサ対応RTOSのシ ミュレーションをRTOSシミュレータと同様の方式 で実現しようとすると,RTOSの共通部のコードを シミュレーション用に書き換える必要があるため, RTOSの開発には向かない. 本 研 究 で は ,マ ル チ プ ロ セッサ 対 応 RTOSの ホ ス ト 計 算 機 上 で の 実 行 を 目 的 と し て ,複 数 の ISS(Instruction Set Simuator:命令セットシミュレー タ)をデバイスマネージャで接続することで, Win-dows上で動作するマルチプロセッサ対応のシミュレー ション環境(TISE:TOPPERS Integrated Simulation Enviroment)†1を実現した. マルチプロセッサRTOSに対応したシミュレータ を実現するためには,複数のプロセッサのシミュレー ションができること,全てのプロセッサから同一のア ドレスでアクセス可能である共有メモリを持つこと, プロセッサの識別機構を持つこと(プロセッサID), 任意のプロセッサへの割込み(プロセッサ間割込み) を発生可能であること,プロセッサ間の排他制御機構 をプロセッサ数の2倍持つこと,すべてのプロセッサ でタイミング同期ができること,のすべての要件を満 たす必要がある. これらの要件を満たすために,既存のISSである SkyEye[14]を拡張(SkyEye-MP)した.具体的には, †1 http://www.toppers.jp/sim.html より,実行ファイ ルおよびソースコードをダウンロードできる. ISS間の(1)共有メモリ機構,(2)排他制御機構,(3) プロセッサ間割込み機構,(4)タイミング同期機構, を新規開発した. SkyEye-MPは,RTOSシミュレータと比較する と,シミュレーション速度は低速であるが,RTOSの 共通部のコードのみならず,ISSがサポートしている プロセッサ用の依存部のコードを変更なしに実行でき るため,RTOSの開発に有効である.さらに,RTOS の実行の命令レベルのトレースログが取得できると いう利点もある. TISEでは,デバイスマネージャにより,ハードウェ ア記述言語(HDL)用のシミュレータや,最近普及が 進んでいるSystemC言語用のシミュレータ[2]など, 様々なシミュレータが接続可能である.さらに,ホ スト計算機もマルチプロセッサである場合は,複数 のISSでマルチプロセッサをシミュレーションする ため,シミュレーション負荷の分散によって高速なシ ミュレーションが可能である.さらに,RTOSのア イドル時間を活用したシミュレーション時間の短縮手 法を提案し実装した. 本論文の構成は次のとおりである.まず2章で,マ ルチプロセッサ対応のシミュレーション環境のベース となった,コシミュレーション環境と,SkyEyeの概 要をそれぞれ解説する.3章でマルチプロセッサ向け RTOSについて述べる.4章で,マルチプロセッサ対 応シミュレータの要件及び,マルチプロセッサ対応シ ミュレータの実現方針について述べ,5章でその実現 について詳述する.6章ではISS間のタイミング同期 について述べる.7章では,RTOSのアイドル時間を 活用したシミュレーション時間の短縮手法について述 べる.8章で関連研究について述べ,9章で開発成果 の活用について報告する.最後に10章で本論文をま とめる.
2 シングルプロセッサ向けシミュレーション
環境
マルチプロセッサ対応のシミュレーション環境の ベースとなった,コシミュレーション環境(RTOSシ ミュレータ及びデバイスマネージャ)と,シングルプ ロセッサ向けのISSであるSkyEyeの概要をそれぞ図1 コシミュレーション環境の構成図 れ解説する. 2. 1 コシミュレーション環境 我々は,これまでSoC開発向けに,プロセッサと 専用ハードウェアにより構成されるシステムをホス ト計算機上でシミュレーションするコシミュレーショ ン環境を開発してきた.コシミュレーション環境の構 成を図1に示す. 本コシミュレーション環境は専用ハードウェアや センサ,ディスプレイ等の物理デバイスをシミュレー ションするハードウェアシミュレータ,アプリケー ションソフトウェアとRTOSをシミュレーションす るRTOSシミュレータ及び,ハードウェアシミュレー タ/RTOSシミュレータ間を接続し,通信を実現する デバイスマネージャから構成される. 2. 1. 1 RTOSシミュレータ RTOSシミュレータはユーザプログラムと共にホ スト計算機上のネイティブコードにコンパイルされ, 高速に動作する.RTOSシミュレータは,シングル プロセッサ用RTOSの仕様である,µITRON4.0仕 様[17] [19]に準拠している.また,RTOSシミュレー タは文献[11]で定められたデバイスアクセス用API をサポートしている.このAPIを用いてアドレスを 指定することにより,ユーザプログラムはデバイスマ ネージャを介してハードウェアシミュレータにアクセ スする. 2. 1. 2 デバイスマネージャ デバイスマネージャは,シミュレータ間の通信を仲 介し,ハードウェアシミュレータに対するアクセス (リード/ライト)要求及び,割込み要求を実現する. 各シミュレータは起動後にデバイスマネージャに接続 する.本コシミュレータではメモリマップドI/Oを 前提としており,各ハードウェアシミュレータには固 有のアドレス空間がマッピングされる. RTOSシミュレータは,デバイスアクセス用API で指定されるアドレスを用いてハードウェアシミュ レータにアクセスする.アドレス空間はデバイスマ ネージャが管理し,シミュレータからのアクセス要求 があった時に,操作すべき適切なシミュレータを呼び 出す.各シミュレータはデバイスマネージャへの接続 後に,自分のアドレス空間をデバイスマネージャに知 らせる. デバイスマネージャは,別の機能として共有メモリ もサポートしている.各シミュレータは,ホストOS の共有メモリ機能を利用することでシミュレータ間 の共有メモリを実現する.ホストOS上の共有メモリ は,シミュレータの要求に応じてデバイスマネージャ が作成する. さらに,デバイスマネージャはRTOSシミュレータ 間の排他制御のための排他制御機構もサポートしてい る.RTOSシミュレータは,ホストOSのミューテッ クス機能を利用することで排他制御を実現する.ホス トOS 上のミューテックスは,RTOSシミュレータ からの要求に応じてデバイスマネージャが作成する. シミュレータ/デバイスマネージャ間の通信はCOM で実現しているため,ハードウェア記述言語(HDL) 用のシミュレータや,SystemC言語用のシミュレー タなど,様々なシミュレータが接続可能である. 2. 2 命令セットシミュレータ:SkyEye SkyEyeはGDB/ARMulatorから派生したARM アーキテクチャのISSである.SkyEyeは,ホスト計 算機上で1つのARMアーキテクチャプロセッサを シミュレーションする. シミュレーションは,ARMアーキテクチャ用のオ ブジェクトファイルを1命令毎に読み込み実行する. 命令レベルのシミュレーションを行うため,命令単 位のトレースを取ったり,実行サイクル数を計算でき る.また,SkyEyeは,GDBを用いてデバッグが可 能である. 図2にオリジナルのSkyEyeのコンフィギュレーショ
1 cpu: arm7tdmi 2 mach: at91
3 mem_bank: map=M, type=RW, addr=0x00000000, size=0x01000000
4 mem_bank: map=I, type=RW, addr=0xf0000000, size=0x10000000 図2 SkyEye のコンフィギュレーションファイルの例 ンファイルを示す.図2の1行目では,CPUのアー キテクチャを指定する.この例では,ARM7TDMI を指定している.図2の2行目は,チップや開発ボー ドを指定する. 3,4行目ではメモリの設定を行っている.map=M とした場合にはその領域はRAM またはROMとし て設定され,map=Iとした場合にはI/O空間として 設定される.type=Rとした場合は読み出し専用と なり,type=RWとした場合には読み書きが可能とな る.addrとsizeによってその領域の開始アドレスと サイズを設定する.シミュレーション時には,このメ モリマップの設定に従い,メモリへのアクセスやデバ イスレジスタへのアクセスを行う.
3 マルチプロセッサ向け RTOS
TISEは,マルチプロセッサ対応RTOSのホスト 計算機上での実行を第一目的としている.マルチプロ セッサ対応RTOSとしては,ITRON仕様をマルチ プロセッサ向けに拡張し,TOPPERS/FDMPカー ネル[21](以下,FDMPカーネル)を対象とする. 3. 1 FDMPカーネルの概要 組込みシステムのソフトウェア開発においては, RTOSが用いられることが多い.そのため,マルチ プロセッサを用いて組込みシステムを構築する際に は,マルチプロセッサ上でのシステム開発をサポート するRTOSが必要になる. 拡張仕様は,µITRON4.0仕様のスタンダードプロ ファイルをベースにしており,プロセッサを跨いで通 常のµITRON4.0仕様のシステムコールを実行する ことが可能である.タスクやセマフォなどのカーネル オブジェクトはいずれかのプロセッサに属する.タス ク等の処理単位となるオブジェクトはそれが属するプ 図3 プロセッサをまたぐシステムコールの実行例 ロセッサでのみ実行される.すなわち,あるタスクが どのプロセッサで実行されるかは静的にのみ決定さ れ,システム動作中にタスクが実行されるプロセッサ が変わることはない. FDMPカーネルは,組込みシステム向けに,リア ルタイム性の確保が容易なAMP方式を採用してお り,プロセッサ毎に独立したオブジェクトコードと なっている. 3. 2 プロセッサをまたぐシステムコールの実行例 FDMPカーネルでは,プロセッサ毎にそのプロセッ サに所属するカーネルオブジェクトの管理ブロックを 持つ.そして,それらの管理ブロックを配置するメモ リとアドレスを共有し,お互いのプロセッサの管理ブ ロックを直接操作する(直接操作法). プロセッサをまたぐシステムコールの実行例を図3 に示す.例えば,図3で,プロセッサ1のタスクA がプロセッサ2のタスクBを起動するシステムコー ルを発行すると,タスクAは,タスクBの状態を管 理するデータ構造のポインタを取得して,このポイ ンタを用いて値を書き換え,起動状態とする.タスク Bを起動した結果,プロセッサ2でのタスク切替え が必要になった場合には,プロセッサ1からプロセッ サ2に割込みを発生させ,タスク切替えを依頼する (図中の2). FDMPカーネルはプロセッサ毎に独立したオブジェ クトコードとなっているため,起動時に各プロセッサ の管理ブロックのポインタを他のプロセッサに渡し, システムコール実行時に用いる.4 マルチプロセッサ対応シミュレータの
設計方針
本章では,マルチプロセッサ向けRTOSである FDMPカーネル対応のシミュレータを実現するため の要件と,その実現方法について述べる. 4. 1 マルチプロセッサ対応シミュレータの要件 マルチプロセッサ対応シミュレータを実現するため の要件は下記のとおりである. 要件(1) 複数のプロセッサのシミュレーションが できる 要件(2) 全てのプロセッサから同一のアドレスで アクセス可能である共有メモリを持つ プロセッサをまたぐシステムコールの実現のた めに,プロセッサ間で,ポインタを受け渡して, そのポインタを用いて同一のデータにアクセス することが必要である. 要件(3) プロセッサの識別機構を持つ(プロセッサ ID) マルチプロセッサRTOSが,どのプロセッサで 実行しているかを識別するために必要になる. 要件(4) 任意のプロセッサの割込み(プロセッサ間 割込み)を発生可能である 3. 1節で述べたように,プロセッサをまたぐシス テムコールを実現するために,プロセッサ間割込 みが必要になる. 要件(5) プロセッサ間の排他制御機構をプロセッ サ数の2倍持つ マルチプロセッサRTOSで利用するロックを実 現するために必要になる.タスクロック(タスク 管理に関わるデータを利用する場合に利用),オ ブジェクトロック(同期・通信オブジェクトに関 わるデータを利用)をプロセッサ毎に持つため, プロセッサ間の排他制御機構がプロセッサ数の2 倍必要になる. 要件(6) 任意の精度ですべてのプロセッサの同期 ができる 同期を行うことで,マルチプロセッサRTOS上 で動作するプログラムのデバッグが容易になる. さらに,実行トレースログのサイクルが揃うこと で,プログラムの解析が容易になる. 4. 2 マルチプロセッサ対応シミュレータの 実現方法 マルチプロセッサ対応シミュレータの実現方法とし て,以下の3つの方法を検討した. (A) RTOSシミュレータを作成する方法 (B) マルチプロセッサ対応ISSを作成する方法 (C) 複数のシングルプロセッサ対応ISSを接続す る方法 上記 の3つの方法 につい て,マルチ プロセッサ RTOSの変更量,シミュレータの実行方法,シミュ レータの開発工数に着目して比較検討した. これらに,着目した理由としては,既存のマルチプ ロセッサRTOSをシミュレータ上で実行する場合や, 新規のマルチプロセッサRTOSをシミュレータ上で の開発を考慮すると,マルチプロセッサRTOSの変 更量をなるべく抑える必要がある.次に,シミュレー ション時間の低減のために,シミュレータ自体の実行 方法を考慮する.さらに,マルチプロセッサRTOS の変更量,シミュレータの実行方法を考慮した上で, シミュレータの開発工数も抑える必要がある. 4. 2. 1 マルチプロセッサRTOSの変更量 2. 1. 1項で述べたように,(A)のRTOSシミュレー タを利用する方法は,ホスト計算機上で直接実行可能 なため非常に高速に動作するという利点がある.こ の方法は,プロセッサ毎にプロセスを割り付け,複数 のプロセスでシミュレーションする方法と,単一プロ セスでシミュレーションする二種類の方法が考えられ る.要件(2)より,プロセッサ間で共有メモリに配置 した管理ブロックに対するポインタを用いたアクセス を実現する必要がある. 複数のプロセスを用いる方法では,プロセス間でホ ストOSが提供する共有メモリを用いて,共有メモリ 上に管理ブロックを配置することは可能であるが,各 プロセスから見える共有メモリのアドレスはホスト OSが動的に設定するため,各プロセスでアドレスが 異なり,ポインタを用いたやりとりができない. 一方,単一プロセスでシミュレーションする場合は,共有メモリは使用する必要がないため,要件(2) は問題とならない.しかしながら,FDMPカーネル はプロセッサ毎に独立したオブジェクトコードである ことを前提として実装されているため,単一のプロセ スとすると,RTOSの共通部の大幅な書き換えは避 けられない. (B),(C)のISS を利用する方法は(A)と異なり, RTOSの共通部の変更は必要ない. 4. 2. 2 シミュレータの実行方法 (B)は,単一プロセスで複数プロセッサをシミュ レーションするため,プロセッサ間でのタイミングの 同期を取りやすいが,プロセッサ数にほぼ比例してシ ミュレーション時間が増大するという問題がある. 一方,(C)は,ホスト計算機がマルチプロセッサで あればシミュレーション負荷の分散によって,(B)と 比較して高速なシミュレーションが可能である.(C) は,個々のISSを別々のプロセスで実行するため,各 ISS間で同期を行う必要がある. 4. 2. 3 シミュレータの開発工数 (B)は既存のシングルプロセッサ用ISSをマルチプ ロセッサ対応するとISSのコードの変更量が多くな ると予想される. (C)は,各シングルプロセッサISS間の通信や同期 機構を追加することで実現できるため,ISSのコード の変更量は少ないことが予想される.同期機構は,既 存のデバイスマネージャを利用することで実現できる ため,工数を抑えられる. 4. 2. 4 TISEの実現方針 TISEの実現方針としては,(C)を採用した.(A) は要件(2)を満たせないことや,RTOSのコードの大 幅な書き換えが必要となるため,実現方針としての採 用を見送った.(B)と(C)を比較した場合,(C)の方 がISSコードの変更量は少ない.さらに,(C)の問題 点である各ISS間の通信や同期機構は,デバイスマ ネージャを利用することで,実現できると判断した.
5 マルチプロセッサシミュレーション環境の
実現
本章では,4章で検討した方針に従った,マルチプ ロセッサシミュレーション環境の実現方法について述 べる.同期機構については,6章で述べる. マルチプロセッサに対応したシミュレーション環境 (TISE)を図4に示す.TISEは,ISS,ハードウェア シミュレータ及び,デバイスマネージャから構成さ れる.マルチプロセッサのシミュレーションのために 複数のISSを起動し,各ISSが1つのプロセッサを シミュレーションする.ISS間,ISS/ハードウェアシ ミュレータ間の通信は,デバイスマネージャを介した 通信及び,ホストOSの提供する共有メモリ,ミュー テックス機能により実現する.シミュレータ間の接 続や,共有メモリオブジェクト,ミューテックスオブ ジェクトは,デバイスマネージャにより管理されて いる.SkyEye-MPは,SkyEyeをベースに拡張され,ISS 本体を実行するメインスレッドとデバイスマネージャ に接続するためのCOMスレッドにより構成されて いる. 4. 1節で述べた,マルチプロセッサ対応シミュレー タの要件を満たすために,SkyEyeに共有メモリ,プ ロセッサIDの設定,プロセッサ間割込み,プロセッ サ間排他機構の拡張を行った.本章では,それぞれの 拡張の詳細について述べる.図5にSkyEye-MPの コンフィギュレーションファイルの例を示す. 5. 1 共有メモリの実現 要件(2)より,共有メモリを実現する.共有メモリ は,ホストOSであるWindowsの提供する共有メモ リオブジェクトにより実現する.共有メモリオブジェ クトを用いることにより,SkyEye-MPは,ローカル メモリと同様に共有メモリにアクセス可能である. 共有メモリの管理はデバイスマネージャが行う方 針とした.SkyEye-MPのいずれかをマスタとして, マスタにより,共有メモリを管理する方法も検討した が,SkyEye-MPの起動や終了の順序に制約が生じ, この順序を守らない場合は,共有メモリが正しく解放 されない等の問題が発生する.さらに,SkyEye-MP により,共有メモリを管理することで,SkyEyeの変 更量が増えることも予想される. 5. 1. 1 デバイスマネージャが提供するAPI デバイスマネージャがISSに提供する共有メモリの
図4 マルチプロセッサに対応したシミュレーション環境 //メモリ構成の設定
1 mem_bank: map=M, type=RW, addr=0x00000000, size=0x00100000
2 mem_bank: map=S, type=RW, addr=0x80001000, size=0x00001000, devm_addr=0x90000000 3 mem_bank: map=I, type=RW, addr=0xf0000000,
size=0x10000000 //排他制御の設定 4 devm_mutex_cont: base=0xffffff00 5 devm_mutex_obj: id=0 6 devm_mutex_obj: id=1 //プロセッサ割込みの設定 7 devm_int_id: 0x01 8 devm_int_out: base=0xffffff40 9 devm_int_in: subid=0x01, IRQ=0 10 devm_int_in: subid=0x00, IRQ=1
//プロセッサ ID の設定
11 prc_id: base=0xffffffa0, id=1 12 cycle_counter: base=0xffffffc0 //実行ホストプロセッサの設定 13 prc_affinity: id=0 //経過時間レジスタの設定 14 perf_time: base=0xffffff80 図5 SkyEye-MP のコンフィギュレーション ファイルの例 COMのAPIを図6に示す.デバイスマネージャは CreateSharedMemory()で要求された共有メモリオ ブジェクトの作成を行う.ReleaseSharedMemory() を呼ばれた結果,どのISSからも参照されなくなっ た共有メモリオブジェクトは,デバイスマネージャが 自動的に削除する. 5. 1. 2 SkyEyeの修正点 SkyEye-MPのメモリ構成は,図5の1,2行目の ようにコンフィギュレーションファイルで指定する.
1 CreateSharedMemory(unsigned long address, unsigned long size, BSTR lpName) 2 ReleaseSharedMemory(BSTR lpName) 図6 共有メモリに関する COM の API map=Mはローカルメモリを表し,map=Sは共有 メモリを表す.この例ではアドレス0x00000000か ら0x00100000バイトをローカルメモリに,アドレス 0x80001000から0x00001000バイトを共有メモリに マッピングしている. 共有メモリは複数作成することが可能であり,シ ミュレーション上の固有のアドレスとサイズにより識 別される.上記の例では,シミュレーション上の固有 のアドレスは,0x80001000である. 各SkyEye-MPは,利用する共有メモリのサイズと シミュレーション上の固有のアドレスを指定して,作 成要求(CreateSharedMemory())をデバイスマネー ジャに送信する.デバイスマネージャは要求されたサ イズの共有メモリオブジェクトを作成して,そのハ ンドルをSkyEye-MPに渡す.SkyEye-MPは,受け 取ったハンドルを元に,共有メモリオブジェクトを 自プロセスにマッピングする.既に他のSkyEye-MP から同じ共有メモリが作成されている場合は,デバイ スマネージャはハンドルのみを返す. デバイスマネージャは共有メモリオブジェクト毎に 参照リストを持っており,参照管理する.SkyEye-MP は,シミュレーション終了時に共有メモリをアンマッ プして,ReleaseSharedMemory()を呼び出し,デバ イスマネージャに通知する.
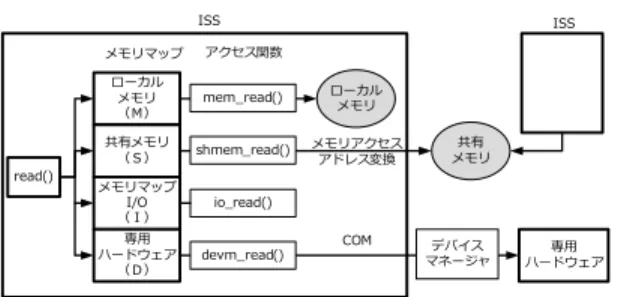
図7 メモリマップとアクセス関数 前述の通り,共有メモリオブジェクトをプロセスに マッピングすると,プロセス毎に異なるアドレスに マッピングされる.しかしながら,要件(2)より,共 有メモリは,どのSkyEye-MP上で動作するプログラ ムからも同じアドレスとして参照できる必要がある. プログラムからのメモリアクセス要求は,シミュ レーション上の固有のアドレスに対して行われる. SkyEye-MPはこのメモリアクセス要求を受け取る と,どの共有メモリに対するアクセスであるか判定 し,対応する共有メモリオブジェクトのアドレスに変 換する. マルチプロセッサ拡張後のメモリアクセスの様子を 図7に示す. ローカルメモリにアクセスする場合に は,SkyEyeのメモリアクセス用関数を使用して,通 常のメモリ(配列に)にアクセスする.共有メモリを アクセスする場合には,SkyEye-MP内でアドレス変 換を行い割り当てた共有メモリオブジェクトにアクセ スする. 5. 2 プロセッサID 要件(3)に示すように,SkyEye-MP上で動作する RTOSでは,自分がどのプロセッサ(SkyEye-MP)で 動作しているか判断する必要がある. 5. 2. 1 デバイスマネージャが提供するAPI デバイスマネージャは,プロセッサ間割込みを実現 するために,各SkyEye-MPのプロセッサIDを管理 している.デバイスマネージャへのプロセッサIDの 登録/削除は,Map()/UnMap() (図8)を介して行う. 5. 2. 2 SkyEyeの修正点 RTOSがどのプロセッサで動作しているか判断する ため,各SkyEye-MPにはプロセッサIDを割り当て
1 Map(unsigned long id) 2 Unmap(unsigned long id)
図8 プロセッサ ID に関する COM の API る.プロセッサIDの指定は,コンフィギュレーション ファイル内で行う.このプロセッサIDをRTOSから 参照可能とするため,プロセッサIDを格納するデバイ スレジスタ(プロセッサIDレジスタ)をSkyEye-MP に追加した. 図5の例では11行目でプロセッサIDレジスタの アドレスを0xffffffa0に,プロセッサIDを1に設定 している. 5. 3 プロセッサ間割込み 要件(4)のプロセッサ間割込みは,デバイスマネー ジャを介した通信により実現する.プロセッサ間割込 みは,プロセッサIDを指定してデバイスマネージャ に割込み要求を出す.前節で述べたように,デバイス マネージャはプロセッサIDを管理しているため,割 込み要求を受け取ると,対応するSkyEye-MPを選 択して,割込み要求を出す.プロセッサ間割込みの流 れを図9に示す. 5. 3. 1 デバイスマネージャが提供するAPI 図10の1行目のRaiseInterrupt()は引数inhnoを 取る.inhnoは32ビットの引数であり,上位16ビッ トで割込み対象のプロセッサIDを,下位16ビット で割込み番号を表す. デバイスマネージャは,図10の2行目の OnInter-ruptRequest()で指定されたプロセッサIDに対応す るSkyEye-MPに割込み要求を出す. 5. 3. 2 SkyEyeの修正点 プロセッサ間割込みをRTOSから使用するため, プロセッサ間割込みレジスタをSkeEyeに追加した. RTOSはプロセッサ間割込みレジスタの上位16ビッ トにプロセッサIDを,下位16ビットに割込み番号を 書き込むことで,SkyEye-MPに対してプロセッサ間 割込みの要求を出す.SkeEye-MPのメインスレッド は,プロセッサ間割込みレジスタへ書込みがあると, COMスレッドに割込み要求を送り,COMスレッド はデバイスマネージャに対して,割込み要求(図10
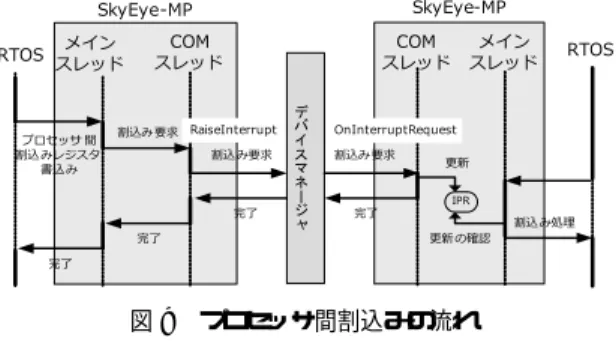
図9 プロセッサ間割込みの流れ
1 RaiseInterrupt(unsigned long inhno) 2 OnInterruptRequest(unsigned long inhno)
図10 プロセッサ間割込みに関する COM の API の1行目のRaiseInterrupt())を行う. デバイスマネージャは,指定されたプロセッサID に対応するSkyEye-MPに割込み要求(図10の2行 目のOnInterruptRequest())を出す. 割込み要求を受け取ったSkyEye-MPのCOMス レッドは,割込み番号に従ってSkyEye-MP上の割込 みペンディングレジスタ(IPR)の該当ビットをセッ トする.IPRはメインスレッドからも変更されるた め,変更時に排他制御を行う.割込み要求を受け取っ たSkyEye-MPのメインスレッドは,現在実行中の命 令を完了した後にIPRをチェックして,割込みが許 可されていれば割込み処理を行う.図5の例では,7 行目でプロセッサIDを1に,8行目で割込み出力レ ジスタのアドレスを0xffffff40に,9,10行目で割込 み番号1,0を外部割込み0,1にそれぞれ設定して いる. 5. 4 プロセッサ間の排他制御機構 要件(5)で述べたプロセッサ間の排他機構を提供 するため,SkyEye-MP間での排他制御機構を実現し RTOS側に提供する.SkyEye-MP間の排他制御機構 は,ホストOSの提供するミューテックス機能により 実現する.排他制御の流れを図11に示す. 5. 4. 1 デバイスマネージャが提供するAPI デバイスマネージャは図12の1行目の Create-Mutex()で 指 定 さ れ た ミュー テック ス オ ブ ジェク ト作成を行う.図12の2行目のCloseMutex()で 図11 排他制御の流れ
1 CreateMutex(unsigned long number, BSTR * lpName) 2 CloseMutex(unsigned long number) 3 AcquireLock(unsigned long address,
unsigned long size) 4 ReleaseLock(unsigned long address,
unsigned long size)
図12 プロセッサ間排他制御に関する COM の API ミューテックスオブジェクトの削除を行う. Acquire-Lock()/ReleaseLock()(図12の3,4行目)を利用す ることで,COMを介した排他制御機構を利用するこ とができる. 5. 4. 2 SkyEyeの修正点 シミュレーション開始時に,SkyEye-MPからデバ イスマネージャにミューテックスオブジェクト作成要 求(図11の1行目のCreateMutex)を出し,デバイス マネージャが作成して,そのハンドルをSkyEye-MP に渡してSkyEye-MPがオープンする. RTOSからミューテックスを取得・解放するイン タフェースとして,排他制御レジスタをSkyEyeに追 加した.RTOSは,排他制御レジスタをリード/ライ トすることで,SkyEye-MPがミューテックスをロッ ク/アンロックする.SkyEye-MPがミューテックス のロックに失敗した時は,SkyEye-MP中で解放待ち にならずに直ちに結果をRTOSに返し,RTOS側で ポーリングによってロックが完了するまで待つか,他 のタスクに切り替える等の処理を行うか選択する. 図5のコンフィギュレーションファイル記述例で は,4行目でロック用のアドレスを0xffffff00に設定 し,5,6行目でIDが0と1のミューテックスを使 用することを指定している
5. 5 その他のSkyEyeの拡張 マルチプロセッサ対応シミュレータの要件を満たす ための拡張以外に,下記の拡張を行った. 5. 5. 1 専用ハードウェアへのアクセス 専用ハードウェアへのアクセスはデバイスマネー ジャを介した通信により実現する. SkyEyeがシミュレーションするARMアーキテク チャでは,デバイスのデバイスレジスタはそれぞれ固 有のメモリアドレスがマッピングされている(メモリ マップドI/O).プログラムはマッピングされたアド レスをリード/ライトすることでデバイスレジスタに アクセスする. デバイスレジスタへのアクセス要求が発生すると, デバイスレジスタ用アクセス関数が呼び出され,アク セス関数の中でアドレス毎に対応するデバイスレジ スタの処理をシミュレーションする.デバイスについ ては,コンフィギュレーションファイルのmem bank オプションでmap=Iと指定されたアドレス空間とデ バイスレジスタ用のアクセス関数が対応付けられて 管理される. TISEでは,デバイスと同様に,専用ハードウェア にもそれぞれ固有のメモリアドレスがマッピングさ れる.プログラムはマッピングされたアドレスをリー ド/ライトすることで専用ハードウェアにアクセスす る.これを実現するために,専用ハードウェア用のア クセス関数を用意し,コンフィギュレーションファイ ルのmem bankオプションでmap=Dを指定したア ドレス空間と対応させる. 専用ハードウェア用アクセス関数からはCOMス レッドに対してリード/ライト要求を渡し,COMス レッドからデバイスマネージャに対してリード/ライ ト呼出し(図13のRead()/Write())を行う.そして, デバイスマネージャは,マッピングされたハードウェ アシミュレータの呼出しを行う. 5. 5. 2 性能評価機能 性能評価機能用に,シミュレータの実行サイクル数 を保持するレジスタ(サイクル数レジスタ)をSkyEye に追加した.実行サイクル数は,ARMマニュアルに 記載されている命令毎のサイクル数の計算式を用い て計算する.プログラムはコンフィギュレーション
1 Read(unsigned long address,
unsigned long size, byte data []) 2 Write(unsigned long address,
unsigned long size, byte data []) 図13 専用ハードウェアアクセスに関する COM の API ファイルで指定したサイクル数レジスタをリードする ことで,実行サイクル数を取得可能である.図5の 例では,12行目でサイクル数レジスタのアドレスを 0xffffffc0に設定している. 5. 5. 3 実時間計測機能 性能評価機能用に,ホスト計算機を起動してから の経過時間を保持するレジスタをSkyEyeに追加し た.経過時間はクロック周波数とホスト計算機が起動 してからのクロック数から計算し,クロック周波数は SkyEye-MP起動時に1秒間のクロック数を計測して 求める. プロセッサID同様,コンフィギュレーションファ イルに指定したアドレスをリードすることで実時間 を取得可能である.図5の例では,13行目でホスト 計算機のプロセッサ0で実行することを,14行目経 過時間レジスタのアドレスを0xffffff80に,それぞれ 設定している. また,ホスト計算機が起動してからのクロック数は, プロセッサ毎に異なる可能性があるため, SkyEye-MP毎に実行するホストプロセッサを固定する機能 を追加した.実行するホストプロセッサの指定はコ ンフィギュレーションファイルにおいて行う(図5の 13行目). 5. 5. 4 メモリ違反に対する警告 SkyEyeは ,コ ン フィギュレ ー ション ファイ ル の mem bankオプションによって定義されていないメ モリアドレスに対してリード/ライトを行っても,警 告を出さずに処理を続行する.しかし,通常このよう なアドレスに対してアクセスするのはプログラムミ スが原因であり,それに起因する重大なバグが存在す る可能性がある. デバッグ効率を上げるために,この違反に対して警 告を出力するように拡張した.まず,未定義のアドレ スに対してリード/ライトを行った場合,その時のプ ログラムカウンタの値と操作対象アドレスを表示し
て警告を出力する. 5. 6 開発規模 SkyeEye-MPは,SkyEyeに対して,24箇所の変 更と9個のファイル追加して実現した.追加したソー スコードは,2650行である.マルチプロセッサ向け RTOSに関しては,共通部は変更していない.依存 部は,SkyEye-MP用に3560行の新規のソースコー ドを開発した.
6 ISS 間タイミング同期
本章では,ISS間のタイミング同期機構について述 べる.SkyEye-MPでは単一のISSではなく,複数のISS を用いることでマルチプロセッサのシミュレーション を実現している. 各ISSはそれぞれ独立したアプリケーションとし て動作するため,各ISSが保持するサイクル数には 大きなずれが生じる.ISS間のサイクル数を同期させ ることにより(タイミング同期)様々なメリットが得 られる. 6. 1 タイミング同期の利点 ISS間で同期をとることには,3つの利点がある. 1つ目の利点は,並列動作する複数ISSからなるシス テム全体の動作に要する実行サイクル数を,ある程度 の精度で計測できることである.ISSは内部で実行サ イクル数を保持しており,その値をシステムの評価指 標として用いることができる.このとき,ISS間で実 行サイクル数の差が小さければ,より正確な値を得る ことができる. 2つ目の利点は,デバッグが容易になることである. 今回ISSとして用いたSkyEyeには,GDBを接続し てデバッグを行うことが可能である.GDBによるデ バッグ時に,1つのISS上のプログラムを停止させた 場合,他のISSは,停止したISSの同期待ちとなる ため,結果として,全ISSの実行を停止させること が可能になる. 3つ目の利点は,実行ログによるISS間の協調動作 解析が容易になることである.これまでは複数のISS の実行ログを解析するとき,ある時点において,それ ぞれどのコードを処理していたのか調べることが困 難であった.たとえば,2つのISSを用いる場合,2 つのISSの起動時刻が異なるだけで,起動時刻の差 分だけ実行ログ中のサイクル数がずれてしまった.し かし,ISSを同期させることで,実行ログ中のサイク ル数のずれが少なくなり,サイクル数をもとに,ある 時刻におけるISSの実行コードを推測することが可 能となる. 6. 2 タイミング同期の実現 本研究では,各ISSの保持する実行サイクル数を 任意の間隔で一致させることでISS間の同期を実現 する.シミュレーション精度の観点からは,1サイク ル毎に同期することが望ましいが,シミュレーション 時間に対するオーバヘッドが膨大となることが予想 される.そこで,シミュレーションの精度と時間のト レードオフをユーザが選択できるように,任意サイ クル数で全てのISSが待ち合わせる,バリア同期手 法を採用した.タイミング同期の実現手法としては, COMを用いた手法と,ホストOSの共有オブジェク トを用いた手法の二種類を実現した. タイミング同期のために,SkyEyeのコンフィギュ レーションファイルを拡張した.具体的には,以下の 記述により,ISSの数と同期を行う周期(サイクル数) を指定する.
sync: num=[ISS数], cycles=[同期サイクル数]
6. 2. 1 COM を用いた同期手法 COMを用いて同期を実現することにより,様々な 言語で記述されたシミュレータとの同期が実現できる. 各ISSは起動時に,ISS数と同期サイクル数(コン フィギュレーションファイルに記述される)をデバイ スマネージャに通知する.ISS上のプログラムが動作 を開始し,設定したサイクル数分のコードを実行した ときに,デバイスマネージャにそのことを通知し,待 ち状態に入る.デバイスマネージャは待ち状態のISS 数と起動時に設定されたISS数を比較し,同じであ れば全てのISSの待ち状態を解除する.そして,再 び次の同期地点までシミュレーションを開始する.デ
図14 COM を用いた同期の流れ バイスマネージャとISS間の通信にはCOM通信を 用いる. 図14にCOMを用いた2つのISSの同期の流れを 示す. ISS1は先に同期地点に到着し,待ち状態にな る.ISS2が同期地点に到着し,デバイスマネージャ にそのことを通知すると,デバイスマネージャが内部 で持つカウンタの値から,全てのISSが同期地点に 到着したと判断し,待ち状態を解除している. 6. 2. 2 共有オブジェクトを用いた同期手法 COMを用いた同期手法は,通信に大きなオーバ ヘッドがかかる.そこで,オーバヘッドの小さいホス トOSの共有オブジェクトを用いる同期手法を実装 した. この手法では,同期用の共有変数やこの変数の排他 制御用のミューテックス等の生成は,デバイスマネー ジャに依頼することで作成するが,同期処理は,デバ イスマネージャを介さずにISSで直接行う. ISSは起動時に,デバイスマネージャに対して,待 ち状態のISS数をカウントするための共有変数と ミューテックスの生成を依頼して,そのハンドルを取 得する.共有メモリの作成と同様に,他のISSが既 に同期用の共有変数を作成している場合は,ISSに対 してハンドルのみを返す.各ISSは同期地点到着時 に共有変数の値を更新し,待ち状態になる.このと き,ISSは共有変数の値から,全ISSが同期地点に到 着したかどうかを判断する.全ISSが到着したと判 断したISSは,自分以外のISSの待ち状態を解除す る.その後,各ISSは次の同期地点までシミュレー ションを実行する. 図15に,共有オブジェクトを用いた2つのISSの 同期の流れを示す. 同期地点に先に到着したISS1は 図15 共有オブジェクトを用いた同期の流れ 待ち状態になる.その後同期地点に到着したISS2は 共有変数の値から,全ISS が同期地点に到着したこ とを確認し,他のISSの待ち状態を解除している. 6. 3 タイミング同期の評価 6. 3. 1 タイミング同期手法の比較 二種類の手法の実行オーバヘッドを比較するため, 100,000回の空のforループ処理にかかるシミュレー ション時間を計測した.図16は,ホストコア数を2 とし,2つのISSを同期させた場合の結果である.for ループに要したサイクル数は1,302,228サイクルで あった. 図16から,COMを用いた同期手法(手法1)では, 共有オブジェクトを用いた同期手法(手法2)と比べ て,非常に長いシミュレーション時間がかかること がわかる.同期サイクル数100の条件で比較すると, 手法1は非同期時の約40倍の時間を要したのに対 し,手法2では約1.5倍の時間に抑えることができ た.ISS間のみで同期を行う場合は手法2を適用す べきである.しかしCOMには柔軟で汎用性が高く, 記述言語に依存しないという利点があり,ハードウェ アシミュレータと同期させる場合には手法1を利用 するとよい. 6. 3. 2 タイミング同期の有用性の確認 FDMPカーネルに付属するトレース機能を用いて 非同期時と同期時のトレース結果を比較し,同期の有 用性を確かめた.図17(非同期時)と図18(同期時)に, オープンソフトの波形表示ツールであるGTKWave [7]を用いてトレース結果を波形表示した結果を示す. FDMPカーネルのトレース機能にはフェイズとい う概念があり,フェイズごとに異なるコード上の位置
図16 提案同期手法のシミュレーション時間の比較 (ホストコア数 2,ISS 数 2) を示す.トレース結果(図17,18)中では,1つのフェ イズを1つの行(波形)に対応させて表示している. 図では,タスク内の機能ごとにフェイズを対応させて トレースを取得した例を示しており,タスク名(例: PE1.MAIN TASK[1])の最後の数字([1])は,機能に 割り当てられたフェイズ名を表している.波形の立ち 上がりはフェイズの起動を意味し,横軸はサイクル数 をもとにして計算された実行時間を示す.使用したテ ストプログラムでは,点線で囲まれたフェイズ3に おいて,MAIN TASKが,別ISS上のPE2.TASK2 に対して起動要求を発行している. 図17 は非同期時のトレース結果である.起動要 求発行のタイミングと起動のタイミングがずれて表 示されている.これは,それぞれのISSが保持する サイクル数が異なるためであり,この情報からプロ セッサ間通信に要する時間を考えることなどはできな い.実際には,FDMPカーネルの性質から,フェイ ズ3(PE1.MAIN TASK[3])の実行中に,別プロセッ サ上のPE2.TASK2が起動することが想定される. それに対し,同期を行った場合の図18では,想定 通り,MAIN TASKのフェイズ3の間にTASK2が 起動されていることが確認できた.システム開発時に もこのように,実行ログを用いて検証やデバッグを行 うことが考えられる.ISS間のタイミングのずれを解 消することで,ISS間の協調動作の流れがわかりやす くなり,検証が行いやすくなる. 6. 3. 3 タイミング同期によるシミュレーションの 高速化 シミュレーションするプロセッサに対して,ホスト 図17 非同期時のトレース結果 図18 同期時のトレース結果 計算機のプロセッサ数が少ない場合,タイミング同期 をすることにより,シミュレーションが高速化するこ とが分かった. 図19に,タイミング同期の有無によるシミュレー ション時間の変化を示す.図19では,タイミング同 期をしない場合(非同期)は,一万サイクルごとに同 期する場合(10000)の10倍近いシミュレーション時 間を要したことを示している.これは,同期機構の実 装前には想定しなかった事象であるため,以下にその 原因について考察する. Windowsのプロセススケジューリングポリシーは, ラウンドロビンであるが,ISSのように,待ち状態と ならないプロセスが複数ある場合,特定のプロセスに 優先的にプロセッサ時間を割り当てる傾向があると考 えられる.つまり待ち状態とならない複数プロセスに 均等にプロセス時間が配分されない. ISSが待ち状態とならない理由は,ISS上で動作す るRTOSがアイドル状態になったとしても,ISSそ のものは内部でサイクル数経過をシミュレーションし ているためである. そのため,ホストPCの持つプロセッサ数を超える 数のISSを並行して実行しようとすると,特定のISS のみが実行され,全体のシミュレーションが進まない 現象が発生すると考えられる.図19の非同期の場合 は,この事態に陥ったと推測される.
図19 同期サイクル数によるシミュレーション時間の変化 タイミング同期は,ISSそのものを,同期タイミ ングごとにホスト計算機上で待ち状態に遷移させる. ISSが待ち状態になった場合,Windowsは自動的に 他のプロセス,つまり他のISSを起動する.結果と して,ホスト計算機のプロセッサ数を超える数のISS を動作させても,それらすべてが均等に実行される.
7 RTOS のアイドル時間を活用した
シミュレーション時間の短縮手法
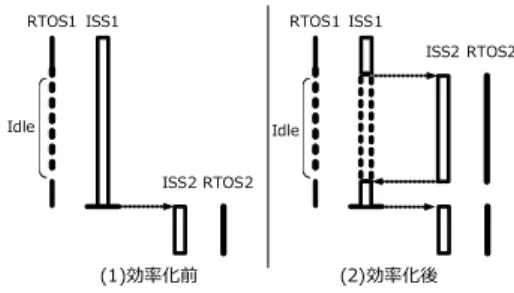
本章ではRTOSのアイドル処理を活用したシミュ レーション時間の短縮手法について述べる.RTOS上 で実行すべきタスクが無い状態をアイドル状態とい う.ホスト計算機のホストプロセッサ数が実行中のシ ミュレータ数よりも少ない場合には,アイドル状態中 は図20のように,他のISSのシミュレーション実行 を行うことで,シミュレーション時間の短縮が可能で ある. 6章で述べた,タイミング同期の有無に応じて,二 種類の実現方法を開発した. 7. 1 非同期時の効率化 ISS非同期時はRTOSがアイドル状態に遷移する たびにホストOSの時間待ちAPIを用いて一定時間 待ち状態にし,起床時に割込みの有無を調べる. ただし,SkyEye-MPは一定数の命令を処理するご とにタイマ割込みを発生させる仕様となっているた め,ISSが待ち状態の間は命令が処理されずタイマ割 込みが発生しなくなってしまう.そこで今回は,ISS 起床時に,タイマカウンタの値にかかわらずタイマ割 込みを発生させることとした. 図20 効率化の概要 7. 2 同期時の効率化 タイミング同期機構を適用している場合は,7. 1節 の手法ではシミュレーション実行効率が悪くなる可能 性がある.これは,ISSが時間待ちAPIを発行する と,ISS内部のサイクル数が進まなくなるため,結果 として同期地点への到着が遅れ,すでに同期地点に到 着していた他のISSの起床が遅れてしまうためであ る.そこで,ISS同期時には時間待ちAPIを用いず, 同期地点への到着を早めることで効率化を行う. ただし本手法でも非同期時と同様に,タイマ割込み への対応が問題となる.アイドル状態遷移時に次同期 地点までサイクル数を進めてしまうと,ISS内部のタ イマカウンタが更新されず,タイマ割込みが発生しな くなってしまう.そこで,アイドル状態遷移時にタイ マ割込み発生までのサイクル数を計算し,同期地点 までの残りサイクル数よりも少ない場合,すなわち, 同期地点到達よりもタイマ割込み発生のほうが早い 場合には,タイマ割込み発生までサイクル数を進め, タイマカウンタをリセットし,タイマ割込みを発生さ せる.そうでない場合には次同期地点までサイクル数 を進め,そのサイクル数に相当する分だけタイマカウ ンタの値を更新する. 図21はRTOS1のアイドル時にタイマ割込みが発 生し,割り込み処理中にISS1が同期地点に到着した 様子を表している. 図21の左側では,ISS1がアイドル状態とタイマ割 込み処理をシミュレーションした後,同期地点に到着 して待ち状態になり,ISS2が起床する. 図21の右側では,ISS1上のRTOSがアイドル状 態に遷移した際,タイマ割込みの発生まで,シミュ レーション実行を省略している.そのため同期地点図21 タイミング同期時の効率化 への到着が早まり,結果としてISS2の起床を早めら れる. 7. 3 RTOSからISSへのアイドル状態通知方法 本章の提案する効率化を実現するには,どのように してRTOSからISSへアイドル状態となったことを 知らせるか,また,待ち状態のISSをどのようにし て復帰させるかが課題となる. 7. 3. 1 アイドル状態遷移の通知,検出方法 RTOSのアイドル状態への遷移を検出するにはい くつかの方法が考えられる. まず,現在実行中のタスクを管理している変数を ISSが調べるという方法がある.FDMPカーネルで はruntskという変数が現在実行中のタスクコント ロールブロック(実行再開番地やスタックポインタな どタスクに関する情報を保持する構造体)をさしてお り,実行すべきタスクが無い場合はNULLをさして いる.そこでISSがその変数のさすアドレスに格納さ れた値からRTOSの状態を調べ,アイドル状態か否 かを判断するということが考えられる.この方法は, アイドル状態の検出を全てISSが行うため,RTOS を書き換える必要が無いという利点がある.しかし, どの変数が現在実行中のタスクを管理している変数 なのか,また,その内容がどうなっているときがア イドル状態なのかをISSが事前に知っている必要が ある.今回研究対象としたISSであるSkyEyeには skyeye.confという設定ファイルがあり,そこに事前 に知っているべき内容を記述しておくなどの対処法が 考えられるが,それ以前に利用者がRTOSの内部を 詳細に知っていなければならない. つぎに,RTOSの依存部でアイドル状態に遷移し
1 mem bank: map=I, type=RW, addr=0xf0000000, size=0x10000000
2 idle base: base=0xffffff88
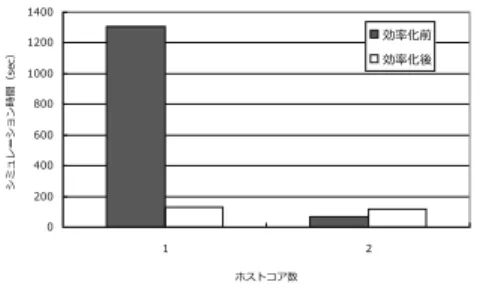
図22 RTOS アイドル状態を通知するための設定 たことをISSに通知する方法が考えられる.この方 法では,RTOSの共通部に修正を加える必要はなく, ISSからも比較的容易にアイドル状態への遷移を検出 しやすいという利点がある.また,所定の通知方法を 取ることで様々なRTOSにも柔軟に対応が可能であ る.以上より,今回は後述した方法を採用した. 本研究で対象としたマルチプロセッサシミュレー ション環境を構成するISSは,ISS間の割込みやホス トOSのミューテックスへのアクセスなどの拡張機能 の使用要求をISSへ伝えるのに,特定の番地へアク セスするという方法をとっている.そこでアイドル状 態遷移の通知方法も同様に,RTOSがアイドル状態 となった場合には特定の番地にアクセスするように 変更を加えておき,ISS側ではその番地にアクセスさ れた場合には,RTOSがアイドル状態であると判断 し,それに対応した処理を行うようにした.アイドル 状態通知用アドレスは idle_base: base=[ベースアドレス] のようにコンフィギュレーションファイルにて設定す るものとした.ただし,このベースアドレスはコン フィギュレーションファイル内でデバイスアドレスと して設定しておかなければならない(図22). 7. 4 効率化の評価 提案効率化手法の有効性を確かめるために,タイミ ング同期時と非同期時の効率化それぞれ実験を行った. 7. 4. 1 非同期時の効率化 非同期時の効率化の効果を調べるため,デュアルプ ロセッサ用MPEG4デコードシステムのシミュレー ション時間を計測した. 図23は,非同期時の効率化手法適用前後のシミュ レーション時間を比較したものである. アイドル時のISS 起床周期は1msecとしている. ホストプロセッサ数が1の場合,効率化手法の適用 により,シミュレーション時間が従来の約90%減少
図23 非同期時のシミュレーション時間の結果 図24 効率化による MPEG4 デコーダの シミュレーション時間の変化 した.ホストプロセッサ数が1の場合,提案する手法 により,大幅にシミュレーション時間を短縮すること ができた. しかし,ホストプロセッサ数が2の場合,シミュ レーション時間は,効率化前より長くなった.これ は,ホストプロセッサ数とISS数が同じでありホス トプロセッサを譲る必要がないため,シミュレーショ ン時間が短縮されることはなく,時間待ちAPIによ るオーバヘッドが追加されたためだと推測される. 実験の結果から,ISS非同期時の効率的利用手法 は,ホストプロセッサ数がISSのコア数より少ない 場合に有効である. 7. 4. 2 同期時の効率化 タイミング同期時の効率化手法の効果を調べるた め,デュアルプロセッサ用MPEG4デコードシステ ムの1フレーム処理にかかるシミュレーション時間 を計測した.ホストプロセッサ数は1とした.図24 は効率化前後のシミュレーション時間を比較したもの である. 同期サイクル数によらず,シミュレーション時間の 削減ができている.特に,同期サイクル数が大きくな るほどシミュレーション時間の削減量が多くなってい る.これは,同期サイクル数が大きいほど,一度に短 縮できるサイクル数が多いためと考えられる.
8 関連研究
組込みシステム開発において重要なコシミュレー ションに関して,これまで多くの研究がなされてき た.ソフトウェアのシミュレーション手法に着目す ると,(1)ソフトウェアをホスト計算機上でネイティ ブに実行する方法と,(2)プロセッサのシミュレータ (ISS)を用いてターゲット用のオブジェクトファイル を読み込みながらシミュレーションする方法に大別で きる. (1)の手法は,ネイティブ実行であるために非常に 高速なシミュレーションが可能である.この場合,一 般的にターゲット上のタスクをホスト上のスレッドに 対応させてシミュレーションを行うが,ターゲット上 の(RTOSの)タスクスケジューリングとホスト上の タスクスケジューリングとの違いがあり,ターゲット 上での実行順序とシミュレーション時の実行順序が大 きく異なってしまう.これを解消するために,RTOS のシミュレーションモデルを導入することが提案され た[8] [18] [15]. 文献[8] [18]では,特定のRTOSに依存しない一般 的なRTOSモデルを利用したシミュレーションが提 案されている.これは一般的な組込みシステム開発で 利用可能であるが,RTOSのシミュレーションモデ ルは,ターゲット上で動作する実際のRTOSと比較 すると,提供する機能やサービスコールが異なるた め,シミュレーション用にソフトウェアを書き換える 必要がある. 文献[15]では,設計者がシステム記述言語である SystemC[16]により仕様を記述し,そこからソフト ウェアを自動生成する手法が提案されている. Sys-temCに関してはオープンソースのSystemCシミュ レータが公開されており,誰でも利用することができ る.SystemCシミュレータを単純なRTOSモデルと みなし,タスク間通信等はSystemCの構文によって 記述する.ソフトウェア自動生成ツールはSystemC の構文をRTOSのサービスコールに置き換える.本ツールを用いることで,より一般的に使用されてい るSystemCでの記述によりシミュレーションが可能 であるが,自動生成されたソフトウェアは一般的な RTOSを利用していて,文献[8] [18]と同様にソフト ウェアの書き換えが必要となる.この問題を解消す るために,我々の研究室では実際のRTOSのシミュ レーションモデルを作成し,シミュレーションと実 装に同一のソフトウェアが使えるようにした[10] [2]. 本シミュレータはµITRONと呼ばれるRTOS仕様 に完全に準拠している.µITRONは仕様定義であり µITRONに準拠したRTOSは多数存在するが,それ らのRTOSを利用したソフトウェアは全て本シミュ レータでシミュレーション可能である. (2)の手法はターゲット用のオブジェクトファイル を解析しながら実行するため,(1)の手法と比べて 100∼1000倍程度遅い[1]とされているが,命令単位 のトレースを取ることができる.この手法を用いると RTOSのシミュレーションモデルは必要なく,ター ゲット上で実際に実行されるRTOSを利用できる. そのため,ISSのサポートするプロセッサで動作する システムは全てシミュレーション可能である.ISSで マルチプロセッサをシミュレーションする場合,単一 スレッドでシミュレーションする方法と,複数スレッ ド(あるいは複数プロセス)でシミュレーションする 方法がある.単一スレッドでシミュレーションする場 合,プロセッサ間での同期を取りやすいという利点が あるが,プロセッサ数にほぼ比例してシミュレーショ ン速度が低下する. 一方,複数スレッド/複数プロセスでシミュレーショ ンを行う場合,ホスト計算機もマルチプロセッサであ る場合に負荷分散が可能であるため,ターゲットプ ロセッサ数が増えた時のシミュレーション速度は,ス レッド間/プロセス間通信のオーバヘッドによりわず かに低下する程度である.文献[6]では柔軟なシミュ レーション環境を紹介している.本環境はSystemC を中心としたシミュレーション環境であり,SystemC で記述された接続ツールに複数のISSやRTOSシ ミュレーションモデル,ハードウェアシミュレータを 接続可能である.本環境を用いることで様々な抽象 度のシミュレーションを行うことが可能になる.文献 [5] [3]では,RTOSとそのシミュレーションモデルの 自動生成手法を提案している.自動生成されるRTOS シミュレーションモデルは本環境により使用可能で ある. 我々がマルチプロセッサ対応シミュレータを検討し 始めた頃には,QEMU[13]はマルチプロセッサ対応 のシミュレータは対応していなかったが,最新版の QEMUではマルチプロセッサ対応のシミュレータを 提供している.しかし,QEMUは,バイナリトラン スレーションをベースとしているため,詳細なトレー スログを取得することができない.さらに,ハード ウェアシミュレータとの接続もできない
9 開発成果
TISEを2009年5月より一般に公開した†2.TISE はすでに,マルチプロセッサ対応RTOSやアプリ ケーションの実装や教育で利用されている.本章で は,TISEの活用事例を紹介する. 9. 1 TOPPERS/FMPカーネルの開発での活用 TOPPERSプロ ジェクトに おいて ,マルチ プロ セッサ向けRTOSであるTOPPERS/FMPカーネ ル[22](以下,FMPカーネル)を開発している.FMP カーネルは,プロセッサ間での通信や,プロセッサを またいだタスク移動(タスクマイグレーション)をサ ポートする.FMPカーネルの開発は,TISEをメイ ンターゲットとして進めた. プロセッサ間通信やタスクマイグレーションのため のAPI開発においては,複数のプロセッサ上でのプ ログラム状態を同期して観測することが可能であった ため,TISEのタイミング同期機構とトレース取得機 能が活用された. 9. 2 コンポーネントシステムでの活用 組込みシステムに適したコンポーネントシステ ムであるTECS(TOPPERS Embedded Component System)[23]を提案している.TECSはコンポーネン トを静的にインスタンス化・結合する静的なコンポー†2 http://www.toppers.jp/sim.html より,実行ファイ
ネントモデルを採用しており,結合を最適化すること により,オーバヘッドを削減している. TISEは,TECSのソフトウェア開発にも利用され ている.例えば,共有メモリを考慮したRPCチャネ ル[24]のプロトタイプの開発では,実機では困難なプ ロセッサをまたいだタスクの通信や同期の確認が,タ イミング同期を用いることで容易になる. 9. 3 システムレベル設計ツールでの活用 SystemBuilder[20] [9]は,ソフトウェア・ハードウェ ア混在の並列システムの設計を効率化するツールで ある.TISEは,SystemBuilderが提供するシステム 設計フローの一部として,並列システムの機能検証用 シミュレータとして活用されている. SystemBuilderは,システムレベル設計と呼ばれる 設計手法を支援する.SystemBuilderを用いた設計で は,設計者はシステムの機能を表現する記述(機能記 述)を,最終的な実装がソフトウェアかハードウェア かを意識することなくC言語レベルで作成する.こ こで機能記述は,SystemBuilderが提供するメッセー ジパッシング通信用APIを用いて記述する.機能記 述を元にして,SystemBuilderは,プロセッサ数など が異なる様々なターゲット向けに実装記述を合成する ことができる. 複数のプロセッサやハードウェア上に分散して実 装されたモジュール間通信の詳細実装は, System-Builderにより自動生成される.ただし,その通信 APIの使用(同期やメモリリード/ライト)の正しさ については保証されないため,実際に動作させて検証 及びデバッグを行う必要がある. システムを高速に動作させるために,プログラマブ ルハードウェアであるFPGA上にシステムを利用す ることができる.しかしFPGAはハードウェアの内 部動作を観測することができない,ログ取得に手間が かかる,などデバッグ性に乏しい. TISEを用いてシステムをシミュレーションするこ とにより,効率的な検証及びデバッグを行うことがで きる. 9. 4 組込みシステムの人材教育
NEP (NCES Education Program) は,名古屋大 学の組込みシステム研究センターが主催する人材教 育プログラムである[12].本教育プログラムの中で, TISEを利用して組込みソフトウェア開発の教育を 行っている.従来,無料で利用できるマルチプロセッ サ対応シミュレータがなかったために,教育のために は評価用ボードを受講者数分だけ購入し用意する必 要があった.TISEを利用することで,コストを削減 し,ホストPCを用意するだけで教育を行うことがで きている. また,NEPの一部として,複数の企業が共同して 研究・開発を行いながら教育を行う,共同研究型教育 を実施している.共同研究型教育では,9. 1節で述べ たマルチプロセッサ向けRTOSであるFMPを対象 として,ソフトウェアテストの効率化に関する研究を 行っている.マルチプロセッサのテストにおいては, 並列に動作する2つ以上のタスクがシステムコール を行うタイミングが複数考えられる.このようなタイ ミングパターンを網羅的にテストするためのテスト スイートを開発している.ここでテストパターン数は 数百,数千にのぼるため,これらを逐次,評価ボード にロードして実行することは困難である.ホスト計算 機上で動作するTISEを利用し,全テストパターンを バッチ実行することによりテストを効率化している. さらに本プロジェクトの中で,コードカバレッジ解 析・出力機能gcovをサポートするようにSkyEye-MP を拡張した.これによりテストパターン実行時に所望 の実行パスを通過したかどうかを確認することがで きている.



![図 16 提案同期手法のシミュレーション時間の比較 (ホストコア数 2,ISS 数 2) を示す.トレース結果 ( 図 17 , 18) 中では, 1 つのフェ イズを 1 つの行 ( 波形 ) に対応させて表示している. 図では,タスク内の機能ごとにフェイズを対応させて トレースを取得した例を示しており,タスク名 ( 例: PE1.MAIN TASK[1]) の最後の数字 ([1]) は,機能に 割り当てられたフェイズ名を表している.波形の立ち 上がりはフェイズの起動を意味し,横軸はサイクル数 をもとにし](https://thumb-ap.123doks.com/thumbv2/123deta/5690182.514277/13.774.412.695.107.212/シミュレーションホストコアフェイズトレース割り当てサイクル.webp)