Operating a Public Spoken Guidance System in Real Environment
4
0
0
全文
(2) �. INTERSPEECH 2005. 4園主1. 》イル., ..・., .翠"" ・倶ιMω ヲール'" 吋げψ MNhw. 吋ー. Dally �fa川崎tlCS of回同町盲目(門umofutte司町田). L. ト. i陶. J Ir. !. 2∞4ノ07/01 263. 1<8. 14. 26. 75. 2∞4ノ07/03 929. 605. 13. 71. 240. 2∞Il 107 102. 29. 2α)4/07/04 131'. 44. 827. 0 12ち. ill. とこ:tEコ+14玄主+デス+74156/1 b、+. あり+アリ令-47/17/5ます+マス+74158/1 か+カ+70 ? +? +77 1332. 14. 3'5. 101 ;:んにち1;1. (Hello.) 208今は. <hou作時<min>分です. 例。w,it面<hour>:<n叩>.】 + + + 7 30 212パスの時刻表を表示します. 1I 食 1W 堂hOF aワw 0・m showing the泊憎旬ble ョs ク 白 ? ド白 ーFe g明# ; 11 E#4 m 7 +側� 、 ?、 } 、 for the bus.) 、 シ+ 、 9、 5 + +7 +2. 上イレ:tt王k:ill韮 ..フ. +喧5 . +. (Is the開a buffel?). 301t王レi韮.1i.の塁かl韮区たぎ!t= ルの�口l孟�韮互. (The toilet田Ioca除dω� left or n曲r thehalle四回目白J. Response candidates. Questions. =1. Figure 4: Examples of QA database Figure 2: Snapshot of th巴 Takemaru-kun monitoring mecha nism through the Intern巴t.. 2.2. Creating response To make appropriate response choices automatically, we pre par巴d an example question-answer (QA) database beforehand. It consists of actual questions queried to the system, which are morphologically analyzed from transcriptions of user utter. 2. Generation of respon担sentence. 3. R可町t旧n of unnec出田町Inpu包. 4. Estimat回n of user's age group. 白星n m辺叫皇. ances. Each question was attached to a suitable answer. Fig. l.Ext日d同n of recoョnized恒xts. ure 4 shows examples of the QA database, where the answer to“Where is the陀st room?". is detìned as #30 1 .. After rec. ognized text is inputted, the number of matched morphemes of independent parts of speech between a question and recognized text is totaled for all prestored questions. In this proc巴dure, N best output is used as speech recognized result that complement recogmtlOn e打ors. Then each score is determined by dividing the number of matched morpheme by words in the questions. A response candidate attached to the best matched example will be sel巴cted as a response. An advantage of this approach is that it generates a certain response concerned with a guidance task if the QA database is satistìed. The system never produces such meaningless responses as“1 don't know" or “Could you repeat. Figure 3: Takemaru-kun system architecture. that please?," which confuses users and inhibits the operation of the system.. We prepared the QA database that could cover. a wide area related of the topic of users' interests. In addition, after the system was operated, we examined the log and added generated by a Text-To-Speech program that also provides ani. additional the QA database as judged necessary. mated gestures and related Web pages on a screen. 2ふRejection of unnecessary inputs. 2.1. Software configuration. To r句巴ct unnec巴ssary inputs, we investigated speech veri白ca. We designed this archit巴cture based on a blackboard model comprised of four modules: Main, Agent, Web browser, and Talker.. They communicate with each other through a status. server that shares the states of all modules via TCP,江P. Each. module operates independently and can stop and start at any time. This modularity simpli自es the development of each part. The main module recognizes input speech to texts and gen erates responses automatically by choosing a suitable one from the prepared response sentence candidates. In addition, r句ec tion of unnecessary inputs and estimation of user age groups are also performed in the same module. The talker module synthe sizes the response speech according to the generated response. The ag巴nt module displays animation gestures synchronized with response speech created on Macromedia Flash.. Agents. can also indicate the detection of the start of an utterance to a. tion to determine whether th巴 inputted voice was intended by comparison of acoustic likelihoods given by GMMs[8]. GMMs have proven to be powerful tools for text-independent speaker veritìcations[9).. Although conventional speech veritìcation. studies have only focused on the rejection of environmental noise, our proposed method can also consider more utterance like wrong inputs such as laughter, coughing, and wrongly trig gered background speech目In addition to GMM-bas巴d veritìca tion, the removal of short length inputs is incorporated into the 2004 Takemaru-kun system. The improvements of rejection de rived from combining GMM-based veritìcation and short input removal will be evaluated in Section 4. 2.4. Child or adult user discrimination Two parallel speech recognizers were installed to estimate user. user by nodding. Visual information such as Web pages, maps,. age groups while achieving suftìcient speech r巴cogmtlOn accu. and timetables are also displayed by Web browser module. For. racy. Each has an age group-dependent language model (LM). further Web retrieval, manual operation with a mouse is also. and an acoustic model (AM) suitable for adult or child users.. possible.. Outputs are chosen based on comparisons between the two like-. 司lム 凋日τ つω.
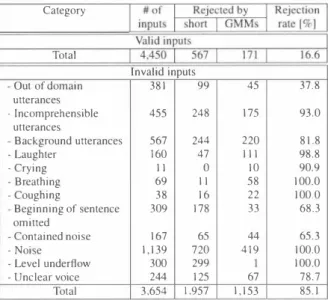
(3) 《ジ. INTERSPEECH 2005. Au 9白' -・・・・ ---FO E-ドトド -一i 「IlA AU 3B ・ ,.、a 勾,‘ ・・・・・・・圃・園周 凶 : i jiJdi〓 i-J , r 4 斗園風可 14斗111 ・・E 11 11汁l l叶lJ圃 l e 劃 C hベ 1 圃』 h l k F ド l l 別Fi 一川 J U H 引 --E t---illi ri--ef lI L 1 l ili esJ 1 Illi-Ill11 1; 』FEll 20 --・ nu il l n 1 1 il i l 由--・ 8 3 0 日 H U H H H UU U U U U M G P 園 什 H H 什 園 風 引 印 刷 出 l l i i l i L l i l l i 同 4吟 ・・圃 圃 e-5・・ i ヤBel I 1 内d -1Lih 除 il--、iil! 7 1一 寸 γ叫 1 l|E1i1 ! i ll LUU. 副 u f d nu nu nu 必値守 内,‘. 25000. 80%. 15000. 60%. 20000. 汁. h. 』 e UM、 J. c. Ln - C E I F ・4 ---i 11 4 e 1 ゅ i l i l U ・ ・ ・ ・ ・ ・ ・ ・ ・ rIL E E ・ E ・1 : o a l n l 2 f 崎 lill1E. E与. 圃 引 圃 ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ h ド ドド l 1 1 1 1 1 1. 1T 幽 1 11 1 1 1 1 1 1 1 1 1 11 1 1 11 1 Ill. 4 ag 圃 ・・ ・ 田 園 l 卜 h lドkl E BE. 1S our. EL ロ・. lihood scores from each decoder. The speech r巴cogmzer. -EE『 圃 ・・・ LH. Figure 5: Number of data collected per month.. y v川 Il 7 -l i 「 l j B I EI -li s i l a 「l l3 oe. 5000. 1m・ド. 同 川川刈 川 川 l l l1 川: U; 一! 川: !い: i; lN \ 園 川 2叫比 l J川 1 】 川 州 戸引 2hi H--圃 I l F 岨・D 、 弘 首. 10000. �,'氏. 3、. . . 圃 ‘日 巾. 100%. 30000. 1・ l 11 t t I 1 1 1 1 1 1 I l l it J 川 “ 地n 叶1 -画 -「 14 t ・口 圃・・・ 晶4. 35000. open source speech recognition engine Julius[ 10]. For the lan Figure 6: Populations by age group per month. guage model, task-dependent word 3-grams are train巴d by Web texts related to guidance tasks and transcriptions of questions collected through the operation of the system. The vocabulary. Table 1: Number of valid/invalid inputs.. size was set to 40,000 words. Speaker independent phonetic tied-mixtur巴 (PTM) triphone models were adopted as acoustic models and trained by collected utterances and reading style speech extracted from th巴JNAS newspaper database. See. [1 1]. for details.. Validity rate. Valid. Invalid. Undetermined. Infant. 13,535. 5,534. 743. 68%. LowerGrade. 53,422. 9,605. 2,003. 82%. 1 5,605. 2,548. 358. 84%. 1 9.193. 2,024. 455. 89%. 244. 67. 3. 78%. 2,2 1 4. 50,034. Age group. Child. 3. Data collection and analysis. Higher Grade. The operation of Takemaru-kun system started on November 6, 2002, and operat巴d every business day at the entrance hall of the Ikoma Community Center. 328,288 inputs wer巴 recorded in 28 months by February 200 5; voice segmentation from inputs using a raw level threshold and zero cross counts method wer巴. Child Adult Elderly Person. 回堅旦旦. 2∞ �竺」. performed by Julius. This means an average of about 490 inputs were recorded per day. The amount of data reached about 17目9 gigabytes and 1 58 hours. Figure 5 shows the numb巴r of data collected per month. The system regularly obtained actual utilization by general citizens for a long period without special promotions or human assis tance. After implementing the new functions in April 2004, the number of access from users were increased because the system acquired improvements of reliability. The system attained twice growth of access in comparison with the previous yea仁. 4. Experiments of unnecessary rejection The r句ection of unnecessary inputs was ca汀1巴d out experimen tally. Test set samples included the 8,248 data extracted from the collected inputs and excluded from theGMMs training. Table 2 shows the experimental results and the number of inputs by category. Because of category duplication, the sum of. All collected data were manually transcribed, classi自ed,. the inputs and the number of test sets do not agree. “Rejected by sho口" indicates the number of inputs removed. and tagged for smooth detailed analysis by operators who sub. due to their short length. In these experiments, a short input. jectively listened to it.. We have completed 177,789 data from. the beginning to恥1ay 2004.. Age group classi自cations of the. was defined as under 0.8 seconds, and they were discarded as unnecessary. data are illustrated in Figure 6, showing that 58.1 % was uttered. Next, GMM-based veri日cation was applied to the remnants. by children. Thus, we should accept the necessities of service. of short input removal to extirpate invalid inputs. Table 3 shows. for children when a spoken interface is located in a public place. the conditions of GMM training and the number of data set.. The collected data included such invalid inputs as unin. We prepared 5-class GMMs with 128 Gaussian mixtures from. tend巴d or unclear speech, fragmentary utterances, noises, and. the training data classified: chi1d, adult, 1aughter, coughing, and. background speech.. We classi白ed all inputs as valid or in. other. These classes wer巴 de自ned according to the amount of. valid by hand, and categorized them by age groups in Table. each categorized data existing in the training sets. That is, in. Valid inputs were about 80%, except for the infants. The. va1id inputs which had the few amount of data were treated as ‘‘Other". 1.. system succeed巴d in being utilized with obvious intention of talking to agents by many users, particularly adults.. 96% of. This combined procedure r句ect巴d 85.1 % of the inva1id in. the inputs whose age group was deemed unce口ain by operators. puts as experimenta1 results.. were classed as invalid. T hey consisted of unnecessary inputs. short input remova1. GMMs assisted r吋ection of utterance. The majority were r句ected by. that should have been r句ected. 37% of the invalid inputs were. like wrong inputs such as 1aughter, coughing, and background. caused by mis-triggered r巴cordings that only contained noise. speech. Mis-rejection of va1id inputs was only 1 6.6%, which of-. 円〆白 A性 つ臼.
(4) 《ジ. INTERSPEECH 2005. using more huge amounts of data will be actualized.. Table 2: Results of rejection experiments.. Further. developments to have flexibility for unanticipated e汀ors are re quired. It is important to improve acquiring paralanguage in. Category. formation on the basis of statistical methods exploiting large amounts of collected data. We will also perform detailed anal. IS a m勾or bottleneck. ysis of the data that resolve diffìculty of data collection, which. Total Invalid inputs Out of domain. 381. 99. 45. 37.8. 455. 248. 175. 93.0. 6. Acknowledgment. utterances ーIncomprehensible utterances 567. 244. 220. 81.8. 160. 47. 111. 98.8. ーCrying. 11. 。. 10. 90.9. - Breathing. 69. 11. 58. 100.0. 38. 16. 22. 100.0. 309. 178. 33. 68.3. Background utterances ーLaughter. - Coughing Beginning of sentence. A part of Takemaru-kun project is supported by the e-Society project provided by MEXT (Ministry of Education, Culture, Sports, Science and Technology), Japan. The authors greatly appreciate supports when 日l巴d testing the system by the Ikoma City office and th巴Jkoma North Community Center. 7. References. omitted 167. 65. 44. 65.3. 1,139. 720. 419. 100.0. 300. 299. Contained noise - Noise ーLevel under日ow. 100.0. - Unclear voice. 244. 125. 67. 78.7. Total. 3,654. 1,957. 1,153. 85.1. in developing dialog systems[ 12].. [ 1] E. Hurley et al., “Telephone Data Collection Using Th巴 World Wide W,巴b," in Proc. ICSLP96, vo1.3, pp. 1 8981 90 1 , 1 996. [2] V. Zue 巴t al., “JUPITER: A Telephone-based Conversa tional Interface for Weather Jnformation, " in IEEE Trans.. on Speech and Audio Processing, vol.8, no. l , pp. 100-1 12, 2000. Table 3: Training conditions of GMMs Amount of. Valid. Child. 20,016. Training data. mputs. Adul t. 4,065. I nval id. Laughter. mputs. Coughing Other. Win dow wid th/sh ift Parameter. 98 6,413. 25/19 msec MFCC. Error Resolution in a Publicly Available Spoken Dialogue System,". in Proc. EUROSPEECH2003, pp.6 1 3-pp.6 16,. 2003. [4] N. Kawaguchi et al., “Multimedia Corpus of In-Car Spe巴ch Communication, ". 16 kHz, 16 bit. Sampling ra telbi t. ". 849. [3]し8ell et al., "Child and Adult Speaker Adaptation during. (12 dim.),ムMFCC,ムPower. Other" includes background speech and miscellaneous noise s.. in Journal of VLSI Signal Processing-Systems for Signal, b叩ge, and Video Technol ogy, vo1.36, pp. 153-159, 2004. [5] T. Giorgino et al., “Automated spoken dialog system for hypertensive patient home management," in Intemational. ten occurred when dealing with rapid utterances such as greet ings and slanders.. Joumal of Medical Inforl11atics, vo1.74, no.2-4, pp.15916 7,2005 [6] V. Goffìn et al., “The AT&T WATSON Spe巴ch Recog nizer, " in Proc.ICASSP2005, vol. l , pp.1033-1036, 2005.. s. Conclusions. [7] R. Nisimura et al., ,‘Takemaru-kun: Speech-Oriented In. T his paper summarized the architecture of the Takemaru-kun. formation System for Real World Res巴arch Platform," in. system. Jt has a practical spoken dialog interface to realiz巴 a. Proc. Firstlntemational Workshop on Language Under standing and Agents for Real World Interaction, pp.7078,2003.. public guidance in the Ikoma Community Center. Two-years actual operation described in Sectio日 3 showed that the system is regularly used whil巴 obtaining 490 inputs per day.. We also. describ巴d the following advances introduced to the 2004 sys tem: (1 ) Rejection of unintend巴d speech based on GMMs; (2) Remo val of short, unnecessary inputs of impulsive noise; (3) Child or adult user discrimination; (4) Web-based monitoring. mechanisms. These advances contributed improvem巴nts of r巴ー liability, which conduced acquiring positive rise of the number of access from users. As a result, the system realized twice. [8] A. Lee et al., “Noise Robust Real World Spoken Dialogu巴 System using GMM 8ased Rejection of Unintended In puts," in Proc.INTERSPEECH2004-ICSLP, 2004. [9] D.A. Reynolds, “Speaker Identifìcation and Veri自cattOn using Gaussian Mixture Speaker Models," in Speech COI1l. l11unication, vo1. 17, pp.91-108, 1 995. [ 10] A. Lee et el., “Julills - An Open Source Real-Time. growth of access in comparison with the previous year. It sug. Large Vocabulary Recognition Engine," in Proc. EU. gests the necessity of large-scale data collection to investigate. ROSPEECH2001, pp. 169 1-1694, 2001. the actualities of how users employ a spoken interface In experiments, we evaluated the rejection of unnecessary inputs included in actual human-machine utterances. Th巴 com bination of GMM-based veri自cation and short input removal produced a c巴rtain advantage for this scheme and achieved a 85. 1 % r吋ecttOn rat巴 for invalid inputs. In future work, we plan to continue the operation and data. [ 1 1] R. Nisimura et al., “Public Speech-Oriented Guidance System with Adlllt and Child Discrimination Capability," in Proc.ICASSP2004,vol. l , pp.43 3-436, 2004 [ 1 2] Y. Gao et el., ,‘Portability Challenges in Developing In teractive Dialogue Systems," in Proc. ICASSP2005, vol.5, pp.10 17-1020, 2005.. collection in various situations. Evaluations and developments. 円べU A生 内〆“.
(5)
図



関連したドキュメント
W ang , Global bifurcation and exact multiplicity of positive solu- tions for a positone problem with cubic nonlinearity and their applications Trans.. H uang , Classification
Let X be a smooth projective variety defined over an algebraically closed field k of positive characteristic.. By our assumption the image of f contains
The main problem upon which most of the geometric topology is based is that of classifying and comparing the various supplementary structures that can be imposed on a
Then it follows immediately from a suitable version of “Hensel’s Lemma” [cf., e.g., the argument of [4], Lemma 2.1] that S may be obtained, as the notation suggests, as the m A
Definition An embeddable tiled surface is a tiled surface which is actually achieved as the graph of singular leaves of some embedded orientable surface with closed braid
In order to be able to apply the Cartan–K¨ ahler theorem to prove existence of solutions in the real-analytic category, one needs a stronger result than Proposition 2.3; one needs
Section 3 is first devoted to the study of a-priori bounds for positive solutions to problem (D) and then to prove our main theorem by using Leray Schauder degree arguments.. To show
In this diagram, there are the following objects: myFrame of the Frame class, myVal of the Validator class, factory of the VerifierFactory class, out of the PrintStream class,
