Improving Rapid Unsupervised Speaker Adaptation Based on HMM Sufficient Statistics
4
0
0
全文
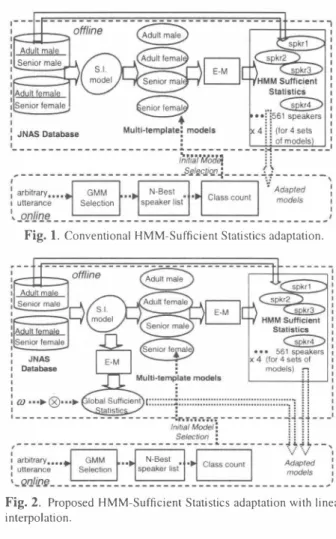
(2) tics.. Figure 2 shows the proposed weighting of the global. Sufficient Statistics. Th巴 proposed method makes it possible to robustly estimate the target speaker's HMMs even with N. best reduced (5く5optimal) since the weighted global Suffi cient Statistics offsets the negative effect of the removed sta. tistical information. The adapted HMM parameters are as fol lows:. u,::, ,oα4, …( 1) ( 乞問=1 乞L I L ωL?と a ) +ω fちds‘ =I L:_ C… 司s F一. C;'α pn e v = …. L. ,"", S. b l. +. ,. alobal. WTni1n μdpneU/ー 一 よ42ー 1 7FEZ771十. (2). ,. T. μ. μ. 成 一 m v d. 'J. ω一 ω 一 + + UL 一. ααdPneu'. 55 5p. E. m. z SJL+ωLf d ー. zε. Fig. 1. Conventional HMM-Sufficient Statistics adaptation.. どJ→yトωL巴:αl ε ;=1 ( �二=1 Li�j +ωL竺ゲ) 1. ". αdpn �ll' αd pnew where C μ- Z ffi ' '--. (4). αα�Pn,w are :E �_�P"円 newlv - ..1 -- - the ---- --' -- t 1 updated mixture weight, means, covariance matrix and up-. ' - 1.1n. dated tran山on probability凶ng linωm印刷lation.. Lrm.. LLJ'm5n,uふare the probability of mixtu児component. occupancy. the accumulated probability of the state occupancy, Fig. 2. Proposed HMM-Suffìcient Statistics adaptation with linear. means and vari ance res p ectively of the selected N-best speak. ers S. L12円L竺アl ?と円 t m. ui bdm山probability. of the mixtぽe occupancy, the accumulated probability of the. interpolation.. state occupancy. Senior female. Consequently, four sets of HMM-Sufficient. Statistics for each speaker are created which are equivalent to. one-iteration of the Expectation Maximization (E-M) training with four multi-template HMMs.. global Sufficient Statistics ωis the weighting factor of the. global HMM-Suf自cient Statistics. In this paper, we used the. following w巴ighting factors :. ω=71ョ. 2.1. Limitations of the Conventional HMM-Sufficient Statistics Adaptation The recognition performance and adaptation spe巴d of this ap proach are dependent on the number of N-best speakers, 5.. • means and variance respectively which are. estimated using all of the training data which constitut巴 the. 乃+ L� :. 72 一一一 ω= 一一 ' 三 α1. (5) (6). where in eqn (5) we used a multiplying constant 71 and in eqn (6), the weighting factorωis normalized by the accumulated. Experiments showed that the optimal N-best is 50ptimal = 40. probabi凶il山l. [8]. If 5 is further reduced such that 5 < 5optimal' adapta. 3.1. Speaker SelectioD. mance. This is attributed to the fact that further decreasing 5. Speaker selection process starts with 1) the denoising of the. which co汀巴sponds to a 10-second adaptation time [7] [ 1 1]. tion time is reduced with a trade-off of the recognition perfor. would result to insufficient data necessary to robustly estimate. the target speaker's HMMs.. ,lobαI. noisy test utterance using Spectral Subtraction (SS), then the parameterization to MFCC. To reduce the effects of the resid. ual noise that is present in the silence or unvoiced region of the speech utterance, the low power parts are r巴moved prior to. 3. PROPOSED HMM-SUFFICIENT STATISTICS. speaker selection. 2) We find the log-likelihood scores given. A D APTATION WITH LINE A R INTERPOLATION To address the problem discussed in section 2.1, we intro. duced linear interpolation using the global Sufficient Statis-. the arbitrary test utterance and the individual-speaker GMMs.. 3) From the log-likelihood scores, only N-best speakerちare selected for adaptation. 4) From the N-best list, a class count. 1 - 1002. A 句Bム 1B・4.
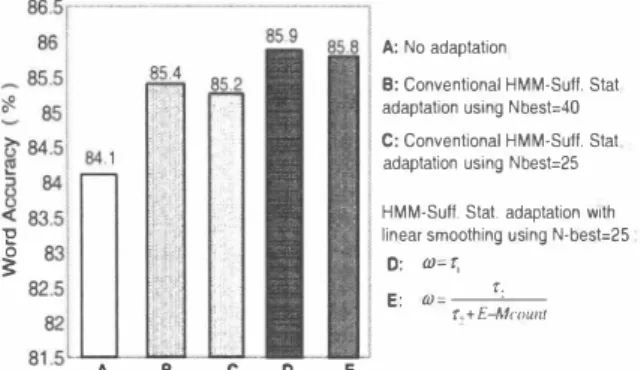
(3) 4.1. General Result A: No adaptation B: Conventional HMM-Suff. Stat adaptation using Nbest=40 C: Conventional HMM-Suff. Stat adaptation using Nbest=25 HMM-Suff. Stat. adaptation 剛th て3. linear smoothing using N-best=25. b �. A. B. C. 0. 0:. 曲二t、. E. τ‘ ω=一一一一二一一一 t,+E-Mc(JWIT. E. Fig. 3. Recognition performance in 25 dB oftìce noise environment. is performed for the 4 different templates. Class counting is carried out using the speaker labels in the form of speaker IDs. Template model is selected based on this count. 5) Tem plate model, N-best HMM-Sufficient Statistics and the global HMM-Sufl白cients Statistics are used for adaptation.. 4. EXPERI恥fENTAL RESULTS. P honetically tied mixture models (PTM) are trained by su p巴rimposing 25 dB office noise to the database [11] in cre ating th巴 multi-template models. In the acoustic modeling part, office noise is superimposed to the cIean speech from the database that r巴sults to 25 dB SNR [11] which is used in training. In the adaptation part, the single arbitrary noisy utterance is denoised with SS which is used for speaker se lection as outlined in section 3.1. Lastly, for the actual recog nition test, the SS-denois巴d test utterances are superimposed with 30 dB office nois巴 prior to recognition to neutralize the r巴sidual noise. [11].. The t巴st set is composed of four classes, namely: adult male, adult female, senior male and senior female. Each class is of 100 utlerances from 23 speakers which are taken out side of the training speakers. This sums up to 400 total test utlerances from 92 test speakers across different g巴nders and age-groups. Recognition experiments are carried out using JULlUS with 20K-word on Japanese newspap巴r dictation task from Jj可AS.The language model is provided by the IPA dic tation toolkit. Weighting factors given in equations (5) and (6) achieved best results when 0 < 71 < 0.2 and 1壬72 :s 2. In particular we used 71 = 0.015 and 72 = 2.. 1. -. In Figur官 3, the word accuracy when using no adaptation is 84.1% (A), while the conventional HMM-Sufficient Statistics adaptation is 85.4% using N-best 5 = 40 (B). It is apparent that when N-best is reduced to 5 25 (C), the word ac curacy drops to 85.2%. This points to the fact that merely reducing the selected N-best in the conventional approach re sults to an insuf白cient statistical data needed to robustly es timate the target speaker's HMMs as mentioned in section 2.1. The proposed HMM-Sufficient Statistics adaptation with Iinear interpolation using the two different weighting factors given in equations (5) and (6) has a recognition performance of 85.9% (D) and 85.8% (E) respectively which is approx imately 0.7% higher than (C) when using the same amount of N-best 5 = 25. It also outperforms the conventional ap proach even when using the optimal N-best 50ptimαI = 40. It cIearly shows that the negative effect in the estimation of the HMMs caus巴d by reducing N-best from 50叩pμt tω0 5= 25 i時s c∞ompensat匂ed by t山he Iinear int臼er叩pola仙tion of the globa討1 Suffi白lCαient Statis幻山ttにcs. As a result, execution time be comes faster owing to fewer N-best. In Table 1, the su町unary of recognition performance in office, crowd, car and booth noise environments with different SNRs are given. In this ta ble the proposed method has an adaptation time of 6 sec. 4.2. Experiments with Clustering. We extended the proposed adaptation method by cIustering the speakers in the database as opposed to using only indi vidual speakers in Figure 2. In this scheme, the individual speaker GMMs and HMM-Sufficient Statistics are changed to cIuster-based. The N-best generates the Iist of cIusters that are cIose to the target speaker. The motivation of this appproach is to further reduce adaptation time by reducing N-best. Aト though, a further reduction of N-best poses a problem due to the insufficient statistical data as dicussed in section 2.1, this problem is minimized by combining 2 speakers statistical in formation in each cIuster and at the same time inco中orate Iinear inte中olation. In order to keep the statistical information uniform in the N-best Iist. we impose that each cIuster be compos巴d of a uniform number of speakers (i.e 2 speakers per cluster) by using Minimax [12]. We also implemented K-Means cIus tering but the former has a better r巴cognition performance. Figur巴 4 is the plot of the word accuracy comparing 1) indi vidual speakers (uncIustered) with interpolation. 2) cIuster巴d speakers with and without Iinear interpolation as a function of N-best. The N-best Iist for the uncIustered speakers are the individual speakers itself while the latters' N-best list is com posed of cIustered speakers. It is very clear that the proposed Iinear interpolation improves the performance of the clustered speakers as opposed to the clustered speakers without Iinear mte中olation. More interestingly, the cIustered speakers with Iinear interpolation using N-best =20 achieved a better recog-. 1003. FhJV -E-.
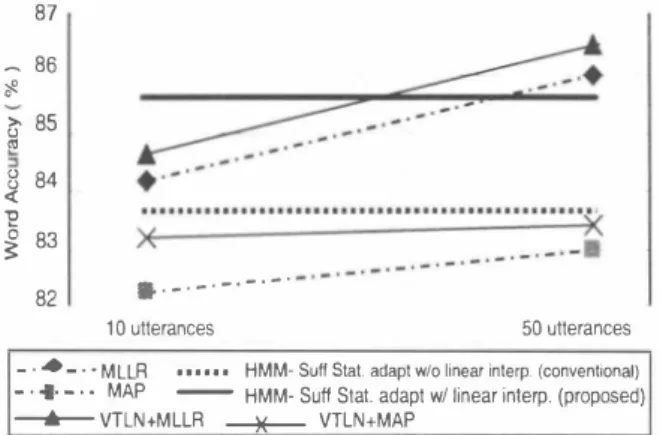
(4) Table 2. Execution time of the proposed method using Intel XEON 2.4 GHz processor with 1GB of memory. HMM-Su任Stat. adaptation. Linear inte叩w/ clustered speakers. _ ポ. /イゴ .....-.... . .. .. ピヲ三三. 86. '" 85 284 �. 10町. Conventional Lmear mte中・w/ i叫vidual恥akers. 78 �77 i76 :75 � 74. I Execution time I I I. 87. コ. 6sec. 5 sec. 2. �. \ノ ,、. ハ. 83. _._. _._._. _.. 82. . _._._._.-. 50 utterances. 10 utterances -'''-''MLLR ・・... MAP. >o. HMM苧SuH Stat. adapt w/o line町interp. (conventional) -- HMM. Suff Slat. adapt w/linear inlerp. (proposed) 一一色一一- VTLN+MLLR 一一弾一一_ VTLN+MAP. _. .. 0 。. す-Glustered spkrs. w/linear Inter附ation. Fig. 5.. 寸陪Clustered spkrs. w/o linear Inter仰lation. 0. 2. 4. 8. - O. Individual spkrs. wl. 13. 18. 20. Recognition performance with various adaptation tech. ruques.. linear Inlerpolation. Number 01 N.best (SpeakerslClusters). ・・・・・・. 25 30. Fig. 4. Clustered speakers' HMM-Sufficient Statistics adaptation with linear interpolation (Averaged in all noisy environment cond卜. word accuracy. Furthermore, the system works well under office, crowd, booth and car noise and in different SNRs. This work is supported by the Japanese MEXT e-Society proJect.. tions and SNRs). 6. REFERENCES. nition performance with that of using the individual speakers (unclustered) with N-best = 25, thus a reduction in adapta tion time is further achieved. Table 2 is the sumrnary of the adaptation time. 4.3. Supervised MLLR, MAP, and VTLN Results. Figure 5 compares the proposed method against MLLR and MAP. We also combined VTLN with MLLR (VTLN+MLLR) and VTLN with MAP (VTLN+MAP ) by warping both the training and the testing data before performing MLLR using 128 c1asses and MAP respectively. In the abscissa, the labels 10 and 50 utteranαs co打巴spond to the adaptation data for the MLLR and MAP variants. The proposed method works better than that of the super vised MLLR, MAP, VTLN+MLLR and VTLN+MAP when using 1O-utterance adaptation data. W hen using 50 utterances, MLLR and VTLN+MLLR has a better performance than the proposed method while MAP together and VTLN+MAP are still outperformed by the proposed method. It should be noted that when using 50-utterances of adaptation data, MLLR and MAP are performed offline while the proposed method can execute the adaptation process in 5 sec using only a single arbitrary adaptation utterance without transcriptions.. [1]. [2]. A. Baba,“Elderly Acoustic Model for Large Vocabulary Continuous Speech Recognition" In Proceedil1gs of EU ROSPEECH, pp. 1657-1660,2001. C. Huang, et al.,“Analysis of Speaker Variability", In Pro ιeedings of EUROSPEECH,Vol. 2, pp 1377-1380 September. [3]. 2001 P.c. Woodland et al. "Experiments in Speaker Normalisation. [4]. ceedil1gs of ICASSP,VoI.2,No.1,pp.1047-1 051 ,Apr1997 C.J.Leggeter and Woodland “Maximum Likelihood Linear. and Adaptation for Large Vocabulary Adaptation", In Pro. Regression for Speaker Adaptation of Continuous Density Hidden Markov Models" In Proceedil1gs oI Computer Speech. [5] [6]. and ù/I1guage, voI.9,pp.171-185, 1995 "' S. Young, et al., The H TK Book" C. Huang, et al., ''Transformation and Combination of Hidden. [7]. ing.1 ofICSLP,2004. S. Yoshizawa, et al., "Unsupervised Speaker Adaptation Based. Markov Models for Speaker Selection Training" In Proceed. [8]. on Suf白cent H恥4恥1 Statistics of Selected Speakers" ceedil1g.l' (}f ICASS P, 200 I. 111 Pro. R. Gomez. et al.,“Rapid Unsupervised Speaker Adaptation. Based on Multi-template HMM Sufficient Statistics in Noisy Environments" In Proceedings (!lEUROSPEECH,pp 296-301,. [9 ]. 2005 G. Vatbhava,. V Karthik, G. Ramesh,“Rapid Adaptation with 111 Proceedil1gs. Linear Combinations of Rank-one Matrices",. [10]. ofICASSP,2001 R. Kuhn, F. Perronnin, P. Nguyen, J. Junqua, L. Rigazio,'‘Very Fast Adaptation with a Compact Context-Dependent Eigen. 5. CONCLUSION. We have succesfully reduced the adaptation time from 10 sec to 6 sec with Iinear interpolation of the global HMM-Suf自ctent Statistics. A further reduction to 5 sec is obtained by c1uster , ing the speaker百 HMM-Sufficient Statistics together with lin ear interpolation. Most interestingly, the reduction in N-best which reduces adaptation time is achieved without degrading the recognition performance. In fact, it slightly improved the. 1. -. [11]. voice Model", 111 Proceedil1gs ofICASSP,2002 S. Yamade, et al., “Spectral Subtraction In Noisy Environ ments Applied To Speaker Adaptation Based on HMM Suf 自cient Statistics". [ 12]. 111 Proceedings of ICSLP , ppト1045司1048. 2000 R. Gomez, et al., “Speaker-Class Reduction for HMM Sufficient Statistics Adaptation Using Multiple Acoustic Mod els". 1004. 111 p,口印edings ofAcoustica/ Socieη。fJap日n,2005.. 6.
(5)
図
関連したドキュメント
In this paper, we assume parametric regression models for dependent survival data in the presence of censored observations considering the special Weibull dis- tribution, a
Keywords: determinantal processes; Feller processes; Thoma simplex; Thoma cone; Markov intertwiners; Meixner polynomials; Laguerre polynomials.. AMS MSC 2010: Primary 60J25;
Furuta, Log majorization via an order preserving operator inequality, Linear Algebra Appl.. Furuta, Operator functions on chaotic order involving order preserving operator
In the study of dynamic equations on time scales we deal with certain dynamic inequalities which provide explicit bounds on the unknown functions and their derivatives.. Most of
By employing the theory of topological degree, M -matrix and Lypunov functional, We have obtained some sufficient con- ditions ensuring the existence, uniqueness and global
In this paper, based on a new general ans¨atz and B¨acklund transformation of the fractional Riccati equation with known solutions, we propose a new method called extended
Thus, we use the results both to prove existence and uniqueness of exponentially asymptotically stable periodic orbits and to determine a part of their basin of attraction.. Let
In this paper we show how to obtain a result closely analogous to the McAlister theorem for a certain class of inverse semigroups with zero, based on the idea of a Brandt
