基づく機械学習による自動分類
大山 浩美
†・小町 守
††・松本 裕治
† 近年,様々な種類の言語学習者コーパスが収集され,言語教育の調査研究に利用されて いる.ウェブを利用した言語学習アプリケーションも登場し,膨大な量のコーパスを収 集することも可能になってきている.学習者が生み出した文には正用だけでなく誤用 も含まれており,それらの大規模な誤用文を言語学や教育などの研究に生かしたいと考 えている.日本語教育の現場では,学習者の書いた作文を誤用タイプ別にし,フィード バックに生かしたい需要があるが,大規模な言語学習者コーパスを人手で分類するのは 困難であると考えられる.そのような理由から,本研究は機械学習を用いて日本語学習 者の誤用文を誤用タイプ別に分類するというタスクに取り組む.本研究は,以下の手順 で実験を行った.まず,誤用タイプが付与されていない既存の日本語学習者コーパスに 対し,誤用タイプ分類表を設計し,誤用タイプのタグのアノテーションを行った.次 に,誤用タイプ分類表の階層構造を利用して自動分類を行う階層的分類モデルを実装し た.その結果,誤用タイプの階層構造を利用せず直接多クラス分類を行うベースライン 実験より 13 ポイント高い分類性能を得た.また,誤用タイプ分類のための素性を検討 した.機械学習のための素性は,単語の周辺情報,依存構造を利用した場合をベースラ イン素性として利用した.言語学習者コーパスの特徴として,誤用だけではなく正用も 用いることができるため,拡張素性として正用文と誤用文の編集距離,ウェブ上の大規 模コーパスから算出した正用箇所と誤用箇所の置換確率を用いた.分類精度が向上した 誤用タイプは素性によって異なるが,全ての素性を使用した場合は分類精度がベースラ インより 6 ポイント向上した. キーワード:機械学習,誤用タイプ自動分類,日本語学習者,学習者コーパス,誤用コーパス, 編集距離,置換確率,階層的アノテーションHierarchical Annotation and Automatic Error-Type
Classification of Japanese Language Learners’ Writing
Hiromi Oyama†, Mamoru Komachi†† and Yuji Matsumoto†
Recently, various types of learner corpora have been compiled and utilized for linguis-tic and educational research. As web-based application programs have been developed for language learners, we can now collect a large amount of language learners’ output on the web. These learner corpora include not only correct sentences but also incor-rect ones, and we aim to take advantage of the latter for linguistic and educational research. To this end, this study aims to automatically classify incorrect sentences
†奈良先端科学技術大学院大学, Nara Institute of Science and Technology ††首都大学東京, Tokyo Metropolitan University
written by learners of Japanese according to error types (or classes) by a machine-learning method. First, we annotate a corpus of the learners’ writing with error types defined in a tree-structured class set. Second, we implement a hierarchical error-type classification model using the tree-structured class set. As a result, the proposed method performs better in the error-classification task than in the flat-structured multiclass classification baseline model by 13 points. Third, we explore features for error-type classification tasks. We use contextual information and syntactic infor-mation, such as dependency relations, as the baseline features. In addition, because a corpus of language learners contains not only correct sentences but also incorrect ones, we propose two extended features: the edit distance between correct usages and incorrect ones and the substitution probability at which characters in a sequence change to other characters. Although the performance varies according to error types, the proposed model with all features outperforms the model with the baseline features by six points.
Key Words: Machine Learning, Error Type Classification, Learners of Japanese, Learner
Corpora, Error Corpus, Edit Distance, Substitution Probability, Hierarchical Annotation
1
はじめに
近年,ビッグデータに象徴されるように,世の中のデータ量は飛躍的に増大しているが,教育分 野ではそれらのデータをまだ十分に活用している状態には至っていない.例えば,Lang-8 という SNSを利用した言語学習者のための作文添削システムがある.現在,このウェブサイトは 600,000 人以上の登録者を抱えており,90 の言語をサポートしている.このサイトでは,ユーザーが目標言 語で書いた作文を入力すると,その言語の母語話者がその作文を添削してくれる.このウェブサー ビスにより蓄積されたデータは,言語学習者コーパスとして膨大な数の学習者の作文を有してい る1. それらは言語学習者コーパスとして調査や研究のための貴重な大規模資源となりえるが,それ らを教師や学習者がフィードバックや調査分析などに利用したい場合,誤用タイプの分類などの前 処理が必要となる. しかしながら,日本語教師のための学習者コーパスを対象とした誤用例検索システムを構築する というアプリケーションを考えると,誤用タイプに基づいて得られる上位の事例に所望の誤用タイ プの用例が表示されればよい.つまり,人手で網羅的に誤用タイプのタグ(以後,「誤用タグ」と 呼ぶ)を付与することができなくても,一定水準の適合率が確保できるのであれば,自動推定した 結果を活用することができる. そこで,本稿では実用レベル(例えば,8 割程度)の適合率を保証した日本語学習者コーパスへの 1 http://lang-8.com誤用タグ付与を目指し,誤用タイプの自動分類に向けた実験を試みる.学習者の作文における誤用 についてフィードバックを行ったり,調査分析したりすることは,学習者に同じ誤りを犯させない ようにするために必要であり,学習者に自律的な学習を促すことができる (Holec 1981; 梅田 2005). そのため,学習者の例文を誤用タイプ別に分類し,それぞれの誤用タイプにタグを付与した例文検 索アプリケーションは教師や学習者を支援する有効なツールとなり得る.現在まで,誤用タグ付与 作業は人手に頼らざるを得なかったが,Lang-8のようなウェブ上の学習者コーパスは規模が大き く,かつ日々更新されるため,人手によって網羅的に誤用タグを付与することは困難である.誤用 タイプの自動分類を行うことで,誤用タグ付与作業を行う際,人手に頼らなくてもよくなり,人間 が誤用タグ付与を行う際の判定の不一致や一貫性の欠如などの問題を軽減しうる.これまでは,こ のような誤用タグの自動付与というタスクそのものが認知されてこなかったが,自動化することで 大規模学習者コーパスを利活用する道を拓くことができ,新たな応用や基礎研究が発展する可能性 を秘めている. 今回,誤用タグが付与されていない既存の日本語学習者コーパスに対し,階層構造をもった誤用 タイプ分類表を設計し,国立国語研究所の作文対訳 DBの事例に対してタグ付け作業を行った.次 に,階層的に誤用タイプの分類を行う手法を提案し,自動分類実験を行った.誤用タイプ分類に用 いるベースライン素性として,単語の周辺情報,統語的依存関係を利用した.さらに,言語学習者 コーパスから抽出した拡張素性として 1) 正用文と誤用文の文字列間の編集距離,2) ウェブ上の大 規模コーパスから算出した正用箇所と誤用箇所の置換確率を用い,それらの有効性を比較した.本 研究の主要な貢献は,以下の 3 点である. • 誤用タグが付与されていない国語研の作文対訳 DB に誤用タグを付与し,NAIST 誤用コー パスを作成した.異なるアノテーターによって付与されたタグの一致率が報告された日本語 学習者誤用コーパスは,我々の知る限り他に存在しない. • NAIST 誤用コーパスを対象に機械学習による誤用タイプ自動分類実験を行い,かつアプリ ケーションに充分堪えうる適合率を実現した(8 割程度).英語学習者コーパスの誤用タイ プの自動分類タスクは過去に提案されている (Swanson and Yamangil 2012) が,日本語学 習者コーパスの誤用タイプの自動分類タスクに取り組んだ研究はこれが初めてであり,将来 的には学習者コーパスを対象とした誤用例検索システムを構築するアプリケーションの開発 を目指しているため,その実現化に道筋を付けることができた. • タグの階層構造を利用した階層的分類モデルを提案し,階層構造を利用しない多クラス分類 モデルと比較して大幅な精度向上を得られることを示した.また,英語学習者の誤用タイプ 自動分類で提案されていた素性に加え,大規模言語学習者コーパスから抽出した統計量を用 いた素性を使用し,その有効性を示した.
2
関連研究
現在,研究・教育目的で利用されている日本語学習者コーパスは,大阪大学の寺村コーパス (寺村 1990)2,名古屋大学の学習者コーパス (大曽,杉浦,市川,奥村,小森,白井,滝沢,外池 1997)3, 東京外国語大学の「オンライン日本語「誤用コーパス」辞典」4,筑波大学の「日本語学習者作文 コーパス」(李,林,宮岡,柴崎 2012)5,大連理工大学の中国人日本語学習者による日本語作文コー パス (清水,宋,孟,杜,壇辻 2004),国立国語研究所(国語研)で収集された「日本語学習者によ る日本語作文と,その母語訳との対訳データベース オンライン版」6(以下,作文対訳 DB)(デー タ総数は 2009 年時点で 1,754 件)がある. 上記の作文対訳 DB は,大規模な日本語学習者コーパスの 1 つであるが,誤用タイプの情報が付 与されていなかった.上記のコーパスのうち,作文対訳 DB 以外のコーパスは誤用タグが付与され ているが,タグが一部にしかついていなかったり,入手ができなかったり,コーパスそれぞれにお いて誤用タグの分類基準が異なっていたりする.また,既存の言語学習者コーパスは言語学や教育 の目的で収集されたもので,自動分類や誤用検出・訂正などの機械処理を考慮した設計にはなって いないため,人手アノテーション以外の分類処理には必ずしも向いていない.具体的には,コーパ スのタグ付けに関するアノテーションの一致率が報告されておらず,機械処理に適した誤用タグ体 系になっているかどうか不明である.そこで,今回機械学習用に誤用タグを付与した NAIST 誤用 コーパスを作成した. また,自動で誤用検出,誤用タイプ分類を行うといった言語学習者コーパス整備作業に関する研 究は,英語教育においても日本語教育においても様々なタスクで進められている.例えば,英語教育 において以下のような研究が行われている.誤用判定として,英語のスペルミス検出研究 (Wilcox-O’Hearn, Hirst, and Budanitsky 2008),英語の名詞の可算性(数えられる名詞),不可算性(数えら れない名詞)の誤用検出研究 (Brockett, Dolan, and Gamon 2006; 永田,若菜,河合,森広,桝井, 井須 2006),前置詞の誤用検出に関する研究 (Chodorow, Tetreault, and Han 2007; De Felice and Pulman 2007, 2008; Tetreault and Chodorow 2008; Gamon, Gao, Brockett, Klementiev, Dolan, Belenko, and Vanderwende 2008),冠詞誤用検出に関する研究 (Han, Chodorow, and Leacock 2006; De Felice and Pulman 2008; Gamon et al. 2008; Yi, Gao, and Dolan 2008;永田,井口,脇寺,河 合,桝井,井須 2005) がある.日本語を対象とする研究では,格助詞を対象とした研究が多い (大 木,大山,北内,末永,松本 2011; Oyama, Matsumoto, Asahara, and Sakata 2008; 今枝,河合,石 川,永田,桝井 2003; 南保,乙武,荒木 2007; Suzuki and Toutanova 2006; 今村,齋藤,貞光,西川2 データ総数 4,601 文中 3,131 文が誤用タグ付け済み 3 756名分の作文
4 誤用タグつき作文 40 名分 http://cblle.tufs.ac.jp/llc/ja wrong/index.php?m=default 5 540名分の作文 http://www34.atwiki.jp/jccorpus/
2012).さらに,誤用タイプに特に着目せずに文を誤用文と正用文とに分類する研究もある (Sun, Liu, Cong, Zhou, Xiong, Lee, and Lin 2007;水本,小町,永田,松本 2013).
これらの誤用検出タスクにおいて,対象となる誤用タイプは限定されている.つまり,誤用タイ プがあらかじめわかっていることが前提である.さらに,誤用タイプを網羅的にタグ付けするよう な研究は以下に示す 1 件を除いて存在しない.実際の言語学習者コーパスでは教師によって添削さ れた正用例があったとしても,誤用タイプまで示すことは稀であり,誤用タイプを網羅的にタグ付 けし,誤用例を検索できるようにすることは困難である.
誤用タイプ分類タスクを行っているのは, Swanson and Yamangil (2012) のみである.彼らは英 語学習者の誤用タグ付きコーパスを用いた教師あり学習による多クラス分類によって,誤用箇所を 与えた上で,誤用タグが付与された文を入力とし 15 クラスの誤用タイプ7に分ける実験を最大エン トロピー法で行っている.しかし,日本語における誤用タイプ分類実験はまだ見られない.また, Swanson and Yamangil (2012)は既存の英語学習者コーパスを用いて自動分類器を学習している が,自動分類に適した誤用タイプのタグ集合を設計しているわけではない.言い換えると,タグの 体系が自動分類の精度に与える影響は考慮されていない.さらに,彼らの自動分類器で用いられて いた素性は誤用・正用の対応に基づく文字列・単語(品詞)情報,そして文脈素性としては直前の 単語のみを用いる非常に単純なものであったが,本研究ではそれらに加えて大規模言語学習者コー パスから計算した置換確率と,正用文と誤用文の編集距離,文脈素性として周辺 3 単語および依存 関係も用いた.
3
機械学習による誤用タイプ分類実験
3.1
データ
誤用タイプ分類実験のために NAIST 誤用コーパスを作成した.NAIST 誤用コーパスは,作文 対訳 DBの中で添削が施された 313 名の作文中の誤用箇所にタグを付与し,様々な情報を補完した コーパスである (大山 2009; 大山,小町,松本 2012).ファイル数は作文者ごとに 313,総文字数 は 191,994 字である.NAIST 誤用コーパスは,作文対訳 DBに対しアノテーションを行っている ため,作文対訳 DB とデータは共通しているが,作文対訳 DBには誤用タグがアノテーションされ ていない. 7 15クラスの誤用タイプは,不足,余剰,置換,動詞のテンス,語順,否定,スペリング,イディオムの誤り(コロケー ションの誤り),活用の誤り,文体の誤り,語の派生,可算不可算名詞の誤り,形式の誤り,主語と動詞の一致の誤り, 項構成の誤りである.3.2
NAIST
誤用コーパスにおける誤用タグのアノテーション
3.2.1 誤用タグのアノテーション 先に述べた作文対訳 DB へのアノテーションの方法について説明する.基本的に作文対訳 DB の 添削に基づいて誤用タグを付与しており,添削は変更せず,誤用タイプ分類をした後にタグを付与 する.作文対訳 DB の誤用箇所に<goyo>タグを設け,そのタグ内に添削された正用箇所を crr 属 性にて示し,誤用タイプを示す type 属性を付与した.誤用を正用にするために複数の誤りを修正 する必要がある場合,それぞれ typeN(ただし N は自然数で,順不同)という属性を用いて明示 した.また,文章中で複数の添削が相互に依存関係を持っている場合がありうるが,依存関係のア ノテーションは今回のタグの精緻化という独立した別のタスクとして切り出すことが可能なため, 今回のアノテーションでは依存関係は考慮しない.例えば,以下の例文を考える.<s>それで,<goyo type1="sem" type2="not/kj" crr="常に">まいにち</goyo>がいこくの えんじょがいります.</s> 上記の例で,誤用として添削者によって添削された「まいにち」を<goyo>タグで囲み,添削者に よる正用例「常に」を crr 属性で示す.この誤用を正用にするためには,「まいにち→つねに」と 「つねに→常に」を訂正する必要があるため,誤用タイプは,この事例では語彙選択 ("sem") と表 記・漢字 ("not/kj") の 2 種類を付与している. 3.2.2 誤用タイプ表の設計方針 誤用タイプ表の設計方針を立てる際に,英語学習者の話し言葉を集めた SST コーパス,日本語 学習者の作文を集めた名古屋大学の学習者コーパス (大曽 他 1997),大連理工大学の中国人日本語 学習者による日本語作文コーパス (清水 他 2004),さらに市川 (1997, 2000) による「日本語誤用例 文小辞典」を基にした. SSTコーパスは,学習者の誤用が多岐にわたるため,体系的な分類が比較的容易な文法的・語彙 的誤りに対して,独自の誤用タイプ表を構築し,人手でタグ付与を行っている (石田,伊佐原,齋 賀,Thepchai,成田,内元,和泉 2003).SST コーパスの誤用タイプ表は,品詞を第 1 階層に有し, 「名詞,動詞,助動詞,形容詞,副詞,前置詞,冠詞,代名詞,接続詞,関係詞,疑問詞」とに分 かれている.さらに,品詞の第 1 階層の下は第 2 階層に「活用の誤り,格の誤り,単複の誤り,語 彙選択の誤り」など文法的・語彙的ルールとに細分化される.また,ある誤用タイプは各品詞のカ テゴリーにまたがっている場合もある.例えば,「活用の誤り」は「名詞」,「動詞」,「副詞」,「代 名詞」のそれぞれの下位分類に属している.「語彙選択の誤り」も複数のカテゴリーに属している. このように,品詞の階層カテゴリーの下位階層にそれぞれ同様のタイプが存在すると,誤用タグ付 与のアノテーターが意識しなければならないタグが増大するため,人手によるタグ付与作業が煩雑 になる.そこで,我々は多クラスのタグ付けをするのではなく,多ラベルのタグ付けをするように
NAIST誤用コーパスを設計し,複雑な階層カテゴリーを把握しなくてもタグ付けが可能なように した.ただし,SST コーパスでの品詞の分類は,自動分類をする際に素性として取り出しやすく有 効な素性となりうる.そのため,NAIST 誤用コーパスでも品詞による分類を第 1 階層に持つよう にした. 誤用タグを構築する際に誤用タイプ分類の方法として,清水 他 (2004) では,誤用タグの構築方 法を 2 つあげている. (1) 言語学的な特定の文法記述に基づき誤用を分類し誤用タグを構築している場合 (2) 実際の誤用分析で抽出された誤用タイプに基づいてタグを構築する場合 名古屋大学の学習者コーパス (大曽 他 1997) は,上記 (1) の方法に従い,言語学的な特定の文法記 述に基づき誤用を分類し誤用タグを構築しているが,「脱落,付加,混同,誤形成,位置」などの分 類はない. 大連理工大学の中国人学習者による日本語作文コーパス (清水 他 2004) は,上記 (2) の方法に従 い,中国人日本語学習者の作文を添削し,独自の誤用タグを設計,付与している.清水 他 (2004) では,大連工業大学の日本語学習者の作文を誤用分析した結果から抽出した誤用に基づく誤用タイ プを用いているため,大曽 他 (1997) や市川 (1997, 2000) とは異なる「指示詞」,「形式名詞」,「数 量詞」,「漢語」などの誤用タイプが見られる. 市川 (1997, 2000) も,上記 (2) の方法に従い,日本語学習者の作文によく見られる誤用をムー ド,テンス,アスペクトなどの 8 つの主要分類に分け,その次に細分化された 86 の項目に分ける (表 1).市川 (2001) では,さらに,下位項目のそれぞれについてさらに「脱落,付加,混同,誤形 成,位置,その他」の 6 種類に分類している. それらの言語学習者コーパスの誤用タイプ分類を基礎に,NAIST 誤用コーパスでは全 76 種の誤 用タイプ分類を構築した.その全誤用タイプは,付録 B「誤用タイプ 76 項目」(表 7)に示す.表 8 は,「誤用タイプ 76 項目」のタグにおいてさらに細かく説明を加えた表である.清水 他 (2004) の 表1 市川の誤用分類 主要分類 下位項目数 ムード 20 テンス・アスペクト 10 自動詞・他動詞・ヴォイス 5 やりもらい 3 取り立て助詞 3 格助詞・連体助詞・複合助詞 10 連用修飾・連体修飾 2 従属節 33 合計 86
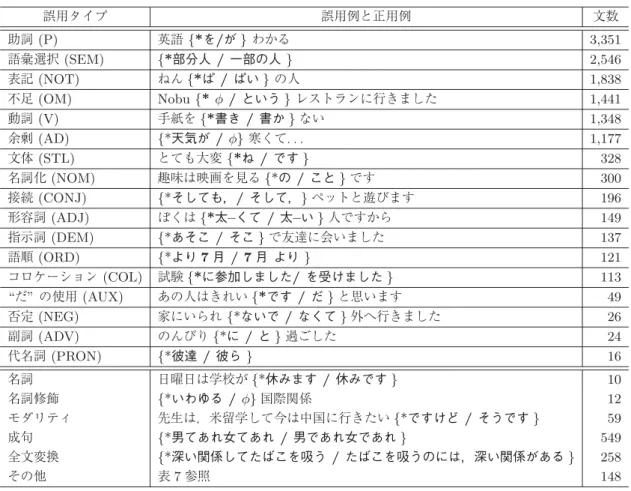
誤用タイプ分類には,市川 (1997, 2000) にはないが,必要だと考えられる誤用タグが見られるた め,それらを含めた.しかし,清水 他 (2004) では,「は/が」の使用誤りの項目と「助詞」を分け ていたりと項目の選出には彼ら独自の理由が見られる.また,中国人日本語学習者を対象にしてい るため,中国人特有の誤用タイプが見られる.NAIST 誤用コーパスの誤用タイプ分類については, そのような点を割愛し,「指示詞」,「形式名詞」,「数量詞」など詳細かつ重要な誤用タグを含めた. 市川 (1997, 2000) の分類も,日本語学習者がよく誤りやすい項目を基に構成されている.表 1 に あるムードは表 7 の 76 の項目中の「モダリティ」に含めている.テンス,アスペクト,自動詞,他 動詞,ヴォイスなどの項目は本稿では「動詞」の下位項目にまとめている.また,取り立て助詞, 格助詞,連体助詞,複合助詞は「助詞」の下位項目にしている.連用修飾,連体修飾は,「名詞修飾 節」の項目に入れている.従属節は,「接続」の項目に含まれている.しかし,市川 (1997, 2000) では「脱落,付加,混同(本稿では,不足,余剰,置換)」などをそれぞれの下位項目のさらに下の 項目に分類しているが,本稿では,「Nobu{* φ / という } レストランに行きました」8 のような, タグを新たに設定しにくい,もしくは修正部分が長く,誤用分類しにくい添削を「脱落,付加」に 入れた.作文対訳 DB にも,市川 (1997, 2000) の分類を採用すると,助詞の下位項目に「不足,余 剰」などの項目を持つ事例がある.しかし,付録 A,「不足」の項目で述べているように,それら は少数である.そのため,本コーパスでは,「不足,余剰」を各分類の下位項目ではなく,独立し た項として新たに設立した.本研究で使用した誤用タグの構築方法について詳しくは 大山 (2009), 大山 他 (2012) を参照されたい. 3.2.3 本稿における実験に使用した誤用タイプ 実験に使用した誤用タイプは,表 2 に示した 17 種である.全誤用タイプ 76 種が階層的に定義さ れ,その第 1 階層の 23 種から 17 種を選択して使用した.全誤用タイプを第 1 階層までまとめ上げ た誤用タイプと研究に必要な誤用タイプとを選択した.誤用タイプのそれぞれの説明は付録 A「誤 用タイプ項目」に詳細に示す. 表 2 において,上位 17 種の誤用タイプを実験に利用した.下位の「名詞」や「名詞修飾」など の誤用タイプは今回事例数が少なかっため,実験対象としなかった.「モダリティ」は,意味や文 の作者の主観に起因する場合が多いので,文脈情報や依存情報よりも意味を扱える素性を考えるべ きであるので,今回は困難であると考え実験対象としなかった.「モダリティ」の場合は,稿を改 めて「モダリティ」を中心に必要な素性を追加した実験を行いたいと考えている.「成句」は,き まったフレーズ(「∼たり∼たり」など)がうまく使えなかった誤りを含む.「全文変換」は,文が すべて書き換えられている誤用事例である.「成句」や「全文変換」も,今回誤用タイプ分類実験 の対象としなかった.「成句」はフレーズの要素が「∼たり∼たり」などのように離れているもの 8 *は誤用例を示す.
表 2 NAIST誤用コーパスにおける誤用タイプ表(17種+非使用の6種) 誤用タイプ 誤用例と正用例 文数 助詞(P) 英語{*を/が}わかる 3,351 語彙選択(SEM) {*部分人 /一部の人} 2,546 表記(NOT) ねん{*ぱ/ぱい}の人 1,838 不足(OM) Nobu{* φ /という}レストランに行きました 1,441 動詞(V) 手紙を{*書き/書か}ない 1,348 余剰(AD) {*天気が / φ}寒くて... 1,177 文体(STL) とても大変{*ね/です} 328 名詞化(NOM) 趣味は映画を見る{*の/こと}です 300 接続(CONJ) {*そしても,/そして,}ペットと遊びます 196 形容詞(ADJ) ぼくは{*太–くて/太–い}人ですから 149 指示詞(DEM) {*あそこ /そこ}で友達に会いました 137 語順(ORD) {*より7月 / 7月 より} 121 コロケーション(COL) 試験{*に参加しました/を受けました} 113 “だ”の使用(AUX) あの人はきれい{*です/だ}と思います 49 否定(NEG) 家にいられ{*ないで/なくて}外へ行きました 26 副詞(ADV) のんびり{*に/と}過ごした 24 代名詞(PRON) {*彼達 /彼ら} 16 名詞 日曜日は学校が{*休みます/休みです} 10 名詞修飾 {*いわゆる / φ}国際関係 12 モダリティ 先生は,米留学して今は中国に行きたい{*ですけど/そうです} 59 成句 {*男てあれ女てあれ/ 男であれ女であれ} 549 全文変換 {*深い関係してたばこを吸う /たばこを吸うのには,深い関係がある} 258 その他 表7参照 148 表中のφは,要素がないことを示す.*は,誤用例を指す. が多く,アラインメントを取ることが困難であった.また,「全文変換」も同様で,文全体を書き 換えているので誤用箇所の特定が難しかったことが理由である.「その他」についても今回実験に 用いた誤用タイプよりもより詳細で個別的な誤用タイプであり,個々が少数事例のものもあったの で今回対象外とした. 上記以外にも,研究に必要な「“だ” の誤用」,「否定」,「副詞」,「代名詞」,「コロケーション」を 誤用タイプに含めて実験を行った.「“だ” の誤用」,「否定」,「副詞」,「代名詞」の誤用タイプにお いては,作文対訳 DB や KY コーパス (鎌田,山内 1999)9を対象とした研究の中で「“だ” の誤用」 (蔭山ハント 2004; 王 2003),「副詞」(浅田 2007, 2008; 松田,森,金村,後藤 2006),「否定」(峰 2011;吉永 2013),「代名詞」(張 2010) などに関する研究が見られ,言語学習者コーパスを利用した 9 KYコーパスは,英語,韓国語,中国語を母語とする日本語学習者各 30 名位,計 90 名のインタビューが収集された話 し言葉コーパスである.
このような研究がこれから増えてくると思われるからである.「否定」と「コロケーション」に関し ては,Swanson and Yamangil (2012) における誤用タイプ 15 種にも含まれている.「コロケーショ ン」は,コーパスデータを利用する利点があり,重要な誤用タイプだと考えられる (寺嶋 2013).語 彙選択の誤りとコロケーションの誤りとを明確に区別し,語彙選択の誤りでは,単語単位のみを対 象とした.コロケーションの誤りでは,「形容詞+名詞」のようなコロケーションも見られるが「名 詞+格助詞+動詞」の誤りのみを対象とした. 3.2.4 アノテーター間の一致率 誤用タグは 2 人のアノテーターによって付与された.2 人ともアノテーターとして 5 年以上勤 務している.コーパス中の一部のデータ(170 文)を対象に 2 人に同じデータへの誤用タグの付与 を依頼し,κ 値 (Carletta 1996) によりその 2 人のタグ付け一致率を計った.タグ付けの対象とし た 170 文は,誤用タイプ 17 種をそれぞれ 10 文ずつ抽出した(10 文× 17 種).それは,全体の約 1.2%に当たる.アノテーターに 1 位に選ぶ誤用タイプと次に選ぶ誤用タイプまで(2 位まで)を選 択してもらった.表 2 の誤用タイプにおける一致率は,1 位までの場合κ = 0.602 であった.2 位 までの場合,κ = 0.654 であった.κ が 0.81∼1.00 の間にあればほぼ完全な一致,0.61∼0.80 の間 にあれば実質的に一致しているとみなされることから,今回は実質的に一致していると考えられる (Carletta 1996).信頼度の高いコーパスを作成するためには,付与したタグがアノテーター間で異 なる「タグの不一致」の問題をできるだけ解決した方がよい.付与したタグの一致率が高ければ, そのタグは一貫性が高く,信頼性が高いタグセットであることが言える. 3.2.5 階層構造誤用タイプ分類表を使用した階層的誤用タイプ分類
先行研究の Swanson and Yamangil (2012) では,誤用タイプ分類実験にフラットな構造の分類 表を使用していたので,Oyama, Komachi, and Matsumoto (2013) でもフラットなタイプの誤用タ イプ分類表を用いたが,人間はどのように誤用タイプを分類するのか分析するために,誤用タイプ 分類に向けた予備実験を行った. 11人の現役の日本語教師に依頼し,テストデータから無作為に選んだ 20 文について誤用タイプ 分類を行わせた.その後,日本語教師各個人に対して聞き取り調査を行い,ある誤用文に対してあ る誤用タイプに分類する理由を聞いた.この分類実験の結果,次のようなことがわかった. (1) 日本語教師は,多くの誤用文を「語彙選択」 に分類しやすい. (2) 日本語教師は,「動詞」と他の誤用タイプを混同しやすい. (3) 日本語教師は,誤用タイプを判断する際に 1 文すべて与えられていても誤用箇所と正用箇所 で主に判断している. (4) 日本語教師は,誤用箇所と正用箇所の次に参考にする素性は,依存構造である. 日本語教師に行った実験では,「語彙選択」が他の誤用タイプ(助詞,動詞,コロケーションな
どの誤用タイプ)に最も間違われやすかった.これは,「語彙選択」が最も選択を迷う項目である ということを示している.聞き取り調査の結果,日本語教師は誤用タイプを判断する際に 1 文すべ て与えられていても誤用箇所と正用箇所などで主に判断していることがわかった.さらに,日本語 教師は,最小の素性で判断しきれない場合,前後 2 単語,前後 3 単語先をみるより,依存している 単語は何かに焦点を当てていた.「助詞」の誤りかどうか判断に迷った時は,それが依存している 動詞を見ている.「副詞」の誤りかどうかの分類も同様である.この結果を受け,「語彙選択」は, どの誤用タイプにも入りやすく,この点が分類を妨げている要因と考えたため,17 種の誤用タイプ 図1 階層構造誤用タイプ分類表
をさらに 3 階層に分類し直し,図 1 に示す構造に変更した. 上記のような流れを受けて,本実験において 3 段階の階層構造に基づく分類を行った.細川 (1993) では,寺村 (1972) の誤用の領域を基にし誤用を分類しており,1) 語彙レベルの誤用,2) 文構成レ ベルの誤用,3) 談話レベルの誤用の 3 レベルを立てている.談話レベルまで扱うのは今回の実験の 範疇にないので,細川 (1993) の分類に従い,第 2 段階を語彙レベルか文構成レベルかに分類した. 図 1 で見られるように,第 1 段階で「不足」,「余剰」,「置換」とに分類する.第 2 段階では,「置 換」内部において「文法的誤用」であるか「語彙的誤用」であるかの 2 値分類を行った.第 3 段階 では,前段階で成功した事例において「文法的誤用」と「語彙的誤用」のそれぞれのグループ内に おいて,多クラス分類を行った.
3.3
実験方法
誤用タイプ自動分類実験は,先行研究の Swanson and Yamangil (2012) にならい,機械学習法 を用いた分類実験を行った.3.2 節で説明したように誤用タイプ分類実験のデータとして言語学習 者が書いた誤用文と正用文に文単位の対応をつけ,誤用タイプを付与した NAIST 誤用コーパスを 用意した.実験には,そのコーパスから誤用箇所,正用箇所や誤用タイプラベルを取り出し,さら に素性を抽出し使用した.また,誤用タイプ表(表 2)を階層構造化し実験を行った(図 1). NAIST誤用コーパスから,13,152 事例を取り出し,10 分割交差検定を行った.1 つの文に別々 の誤用が 2 つ以上ある場合は,1 誤用につき 1 事例として取り出した. 3.3.1 実験の流れ 実験の概要を図 2 に示す.まず,NAIST 誤用コーパスから正用文と誤用文のペアを取り出す. それらの 2 種類の文から,対応する誤用箇所 (x) と,正用箇所 (y),誤用タイプ (t) の 3 つ組のラベ ル (x, y, t) を取り出す.その後,その事例ごとに素性を付与する.ベースラインの素性として,誤 用箇所,正用箇所の表層の語彙素と,誤用箇所,正用箇所の形態素解析結果,周辺単語情報(前後 1 から 3 単語),依存関係情報を付与した.テストデータにおいても同様の素性を取り出し,分類判 定実験に使用した.分類実験には,最大エントロピー法10を利用し,多クラス分類を試みた11.最 大エントロピー法は確率値を出力することができるため,閾値を用いて予測結果を調整しやすく, 英語・日本語の誤用検出・訂正で広く用いられている (Suzuki and Toutanova 2006; Swanson and Yamangil 2012).
10http://homepages.inf.ed.ac.uk/lzhang10/maxent toolkit.html
11事例は,複数の誤用タイプに分類される事もあり,その場合,複数の誤用タグを付与しているが,今回それらの事例数 は全体の 3%にすぎなかったため,本研究の分類においては多ラベル分類ではなく多クラス分類と見なした.
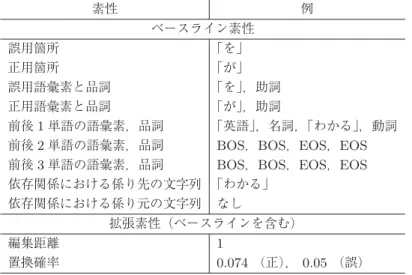
図2 機械学習による誤用タイプ分類実験の流れ 3.3.2 素性 この節では,実験で使用した事例と素性について説明する.表 3 は,今回使用した全ての素性を まとめたものである.例として,誤用を含む文「英語 を(誤)→ が(正)わかる.」をあげる.誤 用箇所「を」が x,正用箇所「が」が y,「助詞」の誤用が t という 3 つ組みのラベルが 1 事例とし て抽出される. • (誤)英語 を わかる • (正)英語 が わかる • 誤用タイプ:「助詞 (P)」使用の誤用 依存関係情報は,誤用箇所の単語にかかる文節内の単語の bag-of-words および誤用箇所の単語 からかかる文節内の単語の bag-of-words を用いた.誤用箇所内が複数の文節にまたがる場合,そ の全ての文節内の全ての単語の bag-of-words を用いた.さらに,係り元・係り先の文節内にある全 形態素の語彙素を用いた.例えば,「∗ 私はりんごを 食べった」という文において「食べった」が 誤用箇所の場合,誤用箇所に係っている文節内の係り元の「私」,「は」,「りんご」,「を」を素性と して利用している.
表3 誤用タイプ分類実験に用いた素性と具体例:「英語 を(誤)→が(正)わかる.」の例文における素性 素性 例 ベースライン素性 誤用箇所 「を」 正用箇所 「が」 誤用語彙素と品詞 「を」,助詞 正用語彙素と品詞 「が」,助詞 前後1単語の語彙素,品詞 「英語」,名詞,「わかる」,動詞 前後2単語の語彙素,品詞 BOS,BOS,EOS,EOS
前後3単語の語彙素,品詞 BOS,BOS,EOS,EOS
依存関係における係り先の文字列 「わかる」 依存関係における係り元の文字列 なし
拡張素性(ベースラインを含む)
編集距離 1
置換確率 0.074(正),0.05(誤)
形態素解析には,UniDic–2.1.2 辞書12と MeCab–0.99413を利用し,依存構造解析器 CaboCha– 0.6814で形態素情報と依存関係を抽出した. 言語学習者コーパスには,ひらがな文字が多く含まれたり,辞書に存在しないような単語が出現 したりする.そのためにアライメントに失敗し,分類精度に影響する.そこで,言語学習者コーパ スにおける誤用による影響を軽減するために次の 2 つの拡張素性を用いた実験も行った. 編集距離素性 2つの文字列がどの程度異なっているかを示す距離である編集距離を用いた.正用文と誤用文に おいて動的計画法によるマッチングを用いて置換対の抽出を行い (藤野,水本,小町,永田,松本 2012),誤用文には存在するが正用文には存在しない文字列を余剰箇所とみなした.同様に,正用 文には存在するが誤用文には存在しない文字列を不足箇所とみなした.ある文字列がある文字列に 置き換えられている場合,置換箇所とした.その際に,置換,不足,余剰の誤りの編集距離をいず れも 1 と定義し,編集距離は実数値素性として用いた. 置換確率 拡張素性として,Lang-8 から抽出した正用箇所と誤用箇所のペアの置換確率を利用した.Lang-8 には,言語学習者の書いた誤用文と添削された正用文とが大量に含まれている.この置換確率は, 12http://osdn.jp/projects/unidic/ 13http://taku910.github.io/mecab/ 14http://taku910.github.io/cabocha/
Lang-8のような大規模な言語学習者コーパスを利用したことから得られる一つの新しい知見であ る.Lang-8 から抽出した正用箇所と誤用箇所のペアから,誤用はどのように訂正されているか(誤 用置換確率)と正用文はどのような誤用から訂正されているか(正用置換確率)を計算し,利用し た.Lang-8 において取り出されたペアは 796,403 ペアである. 例えば,「を」が誤用で「が」が正用である場合の誤用置換確率の式は以下のようになる. P(正用 = が | 誤用 = を)= P(正用 = が,誤用 = を) P(誤用 = を) (1) 「が」が誤用で「は」が正用である場合の正用置換確率の式は以下のようになる. P(誤用 = が | 正用 = は)= P(誤用 = が,正用 = は) P(正用 = は) (2) 3.3.3 評価尺度 評価尺度として F 値を利用した.再現率は対象とする各誤用タイプの中で正しく分類された誤 用タイプを指し,適合率は,システムがある誤用タイプだと分類したもののうち正解を当てた率で ある.F 値はそれらの調和平均を表している. 再現率 = 正しく分類された事例数 各誤用タイプの全事例数× 100 (3) 適合率 = 正しく分類された事例数 システムがある誤用タイプだと分類した事例数× 100 (4) F 値 = 2× 適合率 × 再現率 適合率 + 再現率 (5)
4
実験結果
4.1
階層構造を使用した場合の実験結果
NAIST誤用コーパスにおける誤用タイプ分類実験の 10 分割交差検定による結果について述べ る.表 4 は,階層構造を使用した場合と使用しなかった場合とを比較した表である.簡単のため 前後 1 単語の素性を用いた場合を W1,前後 2 単語までの素性を用いた場合を W2,前後 3 単語ま での素性を用いた場合を W3 とする.最後の行は,全体のマクロ平均を示す.この表で分かるよう に,階層構造を利用したことで分類性能(F 値)が全体的に 49.6 から 62.4 へと向上した.また,F 値で 80 以上を達成した誤用タイプは「助詞」,「不足」,「余剰」の 3 つのみであったが,階層構造 を利用することにより,「語彙選択」,「表記」,「動詞」,「指示詞」も新たに F 値が 80 を超え,実用 的な精度で自動推定が行えることが分かった. 「不足」と「余剰」の値は,階層構造を使用した場合において階層構造を使用しなかった場合よ表4 階層構造を使用した場合と使用しなかった場合の実験結果(10分割交差検定)(F値) 階層構造なし 階層構造あり 事例数 W1 W2 W3 W1 W2 W3 P 96.4 96.3 96.0 98.6 98.3 98.5 3,351 SEM 67.8 65.8 65.3 84.1 83.9 83.2 2,546 NOT 75.5 74.1 72.8 79.4 78.5 77.7 1,830 OM 95.9 95.4 95.5 89.1 89.2 89.1 1,441 V 67.0 66.7 65.4 87.8 87.5 87.1 1,348 AD 89.2 89.7 89.2 83.0 82.0 80.6 1,177 STL 56.9 55.7 53.1 60.1 63.1 61.9 328 NOM 61.6 57.0 58.0 71.5 70.9 71.4 300 CONJ 45.7 42.3 42.7 64.6 63.2 61.1 196 ADJ 44.2 40.4 35.3 75.1 73.0 68.5 149 DEM 61.7 56.1 55.6 83.8 83.6 82.2 137 ORD 17.7 25.6 25.0 42.6 48.7 49.3 121 COL 12.4 11.9 11.1 18.2 16.0 17.4 113 AUX 19.8 31.7 30.4 38.7 42.4 30.6 49 NEG 6.1 11.1 11.1 30.0 29.6 25.6 26 ADV 20.0 16.2 22.4 38.3 36.9 13.3 24 PRON 5.4 7.1 10.0 8.3 14.6 0.0 16 マクロ平均 49.6 49.6 49.3 62.0 62.4 58.7 13,152 り精度が下がっている.「不足」と「余剰」の誤用タイプは第 1 階層において「不足」か「余剰」か 「置換」の 3 値分類をする.その際,「不足」は 1,441 事例,「余剰」は 1,177 事例,「置換」は 10,534 事例となり,「置換」の事例数は,「不足」と「余剰」の事例数よりもはるかに多くなる,これが, 「不足」と「余剰」の階層構造を使用した場合での精度を下げる原因となったと考えられる.
4.2
編集距離,置換確率を加えた実験結果
編集距離,置換確率を加えた誤用タイプ分類実験の結果を表 5 に示す.ベースライン (BL.) は, 誤用タイプの構造が階層構造であり周辺素性および依存関係情報を付加した素性とし,表 4 におけ る「階層構造あり」の結果を用いた.さらに,拡張素性として,1) ベースライン + 編集距離 (edit), 2)ベースライン + 置換確率 (sub.)(F 値)を示した.ALL は,それら全ての拡張素性を付加した ものである.表 5 の最下行はマクロ平均値を表し,表 5 より編集距離を加えることで 4.1 ポイント の分類性能の上昇,置換確率を加えることで 3.4 ポイントの上昇が見られる.それら拡張素性を合 わせた素性 (ALL) においては 6 ポイントの上昇が見られる. 表 6 は,階層ごとの分類の難しさを示している.まず 1 行目は「不足」か「余剰」か「置換」か の多値分類での平均値である.2 行目は「文法的誤用」における多値分類,3 行目は,「語彙的誤用」 における多値分類での平均値である.表5 NAIST誤用コーパスにおける誤用タイプごとの分類実験結果(10分割交差検定)(F値)
BL. BL. + edit BL. + sub. ALL
事例数 W1 W2 W3 W1 W2 W3 W1 W2 W3 W1 W2 W3 P 98.6 98.3 98.5 98.7 98.5 98.4 98.8 98.6 98.6 98.7 98.6 98.6 3,351 SEM 84.1 83.9 83.2 89.9 89.7 89.5 84.4 84.0 83.1 90.2 89.9 89.5 2,546 NOT 79.4 78.5 77.7 88.1 88.0 87.6 79.7 79.1 78.5 88.5 88.0 87.8 1,830 OM 89.1 89.2 89.1 90.6 90.2 89.6 91.1 90.4 89.7 91.2 90.6 90.5 1,441 V 87.8 87.5 87.1 88.4 88.0 88.3 88.9 88.6 88.3 88.8 89.6 89.0 1,348 AD 83.0 82.0 80.6 86.4 86.9 86.1 87.4 86.3 86.4 87.6 87.3 87.4 1,177 STL 60.1 63.1 61.9 67.8 65.5 65.7 67.7 68.7 65.7 68.0 70.8 67.2 328 NOM 71.5 70.9 71.4 74.3 73.0 72.8 73.9 73.5 73.0 72.5 75.3 72.5 300 CONJ 64.6 63.2 61.1 63.5 60.6 63.3 67.1 61.7 62.6 66.2 60.2 61.6 196 ADJ 75.1 73.0 68.5 79.8 76.4 74.8 82.5 76.8 73.5 79.4 78.5 77.8 149 DEM 83.8 83.6 82.2 83.7 85.8 79.5 85.8 81.7 85.2 87.3 85.5 82.3 137 ORD 42.6 48.7 49.3 53.5 54.0 57.1 53.2 40.7 45.0 53.5 46.3 46.1 121 COL 18.2 16.0 17.4 15.5 20.2 18.9 27.6 23.9 18.7 21.8 20.9 18.4 113 AUX 38.7 42.4 30.6 44.9 48.9 32.5 41.2 53.7 38.4 55.6 46.1 42.7 49 NEG 30.0 29.6 25.6 31.8 23.7 15.0 25.0 15.0 0.0 45.8 26.0 16.7 26 ADV 38.3 36.9 13.3 12.5 56.7 48.0 38.9 55.6 29.2 56.7 44.4 73.3 24 PRON 8.3 14.6 0.0 11.2 23.8 6.3 25.0 18.8 25.7 11.1 16.7 0.0 16 マクロ平均 62.0 62.4 58.7 63.6 66.5 63.1 65.8 64.5 61.3 68.4 65.6 64.8 13,152 表 6 各階層における分類実験結果(10分割交差検定)(F値)
マクロ平均値 BL. BL. + edit BL. + sub. ALL
W1 W2 W3 W1 W2 W3 W1 W2 W3 W1 W2 W3 不足/余剰/置換 89.62 89.29 88.76 91.44 91.48 90.98 92.05 91.33 91.11 92.12 91.78 91.77 文法タイプ 59.95 59.32 54.12 59.18 62.90 58.47 62.32 61.11 57.09 65.30 61.51 60.63 語彙的タイプ 60.56 62.80 59.45 64.52 65.97 65.35 63.93 62.34 60.09 66.82 66.26 65.23 表 6 のマクロ平均値において,第 1 段階(余剰,不足,置換)実験において編集距離を加えるこ とで 1.8 ポイントの上昇,置換確率を加えることで 2.4 ポイントの上昇が見られる.ALL では,2.5 ポイントの上昇が見られる.文法タイプ内実験において編集距離を加えることで 0.8 ポイントの下 がっているが,置換確率を加えることで 2.4 ポイントの上昇が見られる.ALL では,1.2 ポイント の上昇が見られる語彙タイプ内実験において編集距離を加えることで 4.0 ポイントの上昇,置換確 率を加えることで 3.4 ポイントの上昇が見られる.ALL では,6.3 ポイントの上昇が見られる.
5
分類実験に関する考察
この節では,どの素性がどのように自動分類に役立つかについて考察する.「不足」,「余剰」,「語 彙選択」,「表記」,「助詞」,「動詞」は事例数が多く,全体の事例の 91%を占めている.そのため, それらについて説明する15. 全体的に編集距離素性と置換確率素性を入れた実験 (ALL) において精度の向上が見られる.個 別に見ると「語彙選択」,「表記」と「余剰」において,編集距離素性を用いた実験で精度の向上が 見られる. 「語彙選択」において漢字同士の誤用は数多く見られる.置換確率を入れるとさらに半数程度改 善している(成功事例中 44.8%).語彙の選択誤りは多種多様であるため,Lang-8 のような巨大な コーパスから置換確率を計算したとしても出現しない可能性もある.そのような場合においても編 集距離素性が効果があったと考えられる.下に例を示す. 《語彙選択 (SEM)》このたばこという物はどうして人々の 必用(誤)→ 必需品(正)になっ ているのがわからない. 「語彙選択」の場合,ひらがなやカタカナを漢字に変換する(またはその逆)事例の精度も上がっ ていた(成功事例中 41.8%).日本語学習者の作文ではひらがな,カタカナ,漢字の混合もよく見 られる.ひらがなやカタカナと漢字では,表記が長くなるか短くなるかで編集距離が異なるため, その差が素性の効果に影響したと考えられる. 《語彙選択 (SEM)》いろいろな飾りが大好きだからたばこを買う代わりにほしがっている 飾り物(誤)→ アクセサリー(正)を買った方がいい. 「表記」の事例において編集距離素性で精度の向上が見られる事例を分析する.最も向上した事 例のパターンは,以下のようなひらがなが漢字に変更された事例である .そのような事例が編集 距離素性を入れたことで分類に成功しており,成功事例の半分を占めていた(55.9%). 《表記 (NOT)》家の外と中を そうじ(誤)→ 掃除(正)しました. 次に,「余剰」の事例を見る.比較的文字列数が長い物が成功するようになっている.これは,編 集距離の素性の効果だと考える. 《余剰 (AD)》私はその中で いろいろな食べもの(誤)→ φ(正)一番好きなものはレマンです. 次に,置換確率素性を用いた実験で精度の向上が見られた場合を検証する.全ての素性を組み合 15「助詞」は事例数が最も多く,素性を付加しなくても精度も高いため,対象から除いた.わせた実験 (ALL) において,分類に成功した事例と失敗した事例においての置換確率が利用可能 である場合を比較した.分類に成功した事例においては,置換確率が出現した場合が 69.9%である のに対し,分類に失敗した事例中では,57.8%となっており,置換確率値があった方が分類に成功 していることが分かる. 以下では置換確率素性を用いた実験で精度の向上が見られた「不足」,「動詞」の事例を見る.ま ず,「動詞」において置換確率を付加したことで分類に成功した事例を見る. 《動詞 (V)》個人的には,軽い生活磁器よりも韓国のたましいが感じ る(誤)→ られる(正) 非生活磁器が気に入りました. 誤用置換確率 = 0.046, 正用置換確率 = 0.475 上記の例は,「ベースライン+編集距離」の実験では,「文体」に分類されていた.「動詞」と「文 体」が共に文末の誤りであることから,お互い間違われる事例が多いが,誤用箇所「る」正用箇所 「られる」の誤用正用パターンが Lang-8 中に出現し,置換確率が得られたことで分類が成功したと 考えられる.「文体」は,付録 A にあるように,通常「です・ます体」か「だ・である体」で統一 されているかどうかの誤用である.この添削文は作文対訳 DBの添削に基づいており,日本語教師 が添削を施している16.その際,日本語教師によって誤用箇所の「る」が「ます」に修正されてい る.誤用タグを付与するときに,その添削にそってタグをつけている.よって,誤用箇所が「る」 であり,正用箇所が「ます」である事例(またはその反対)が多く出現しており,「文体」に特徴的 なパターンとして認識されている. 「不足」,「余剰」の場合の性能についての考察をする.「不足」と「余剰」は一見誤用文字列・正 用文字列の長さで簡単に判別できるように思われるが,もし不足しているものあるいは余剰に書か れているものが助詞とはっきりわかるものであれば,助詞へ分類されており(付録参照),誤用文 字列・正用文字列の長さを見ただけでは必ずしも判断できない.そして,助詞はタグ全体の 1/4 を 占める誤用タイプ(「不足」と「余剰」はそれぞれ全体の 11%と 9%)であるため,「不足」「余剰」 の分類性能に影響を及ぼしたのではないかと思われる. また,「不足」より「余剰」の分類精度が低いことに関して,「不足」と「余剰」の事例が分類に 失敗する場合を比べてみると,「余剰」の方に 10 ポイントほど多く,他の誤用タイプ(助詞や “だ” の誤用など)に含まれる可能性のある事例が含まれていた.前の段落で書いたように,これが「不 足」と「余剰」の分類精度に影響したと考えられる.「不足」と「余剰」の分類精度において差が 見られたが,全ての素性を入れた実験においては 3.6%の差であり,ベースラインと比較すると差 が減っている.これは,拡張素性によって正用例と誤用例の文字列を考慮することができるように 16正用に添削する際には日本語教師が文章全体を見て添削しておりその結果を用いているので,本研究での誤用タイプ分 類問題においては文章全体を見なくてもよい.
なり,より助詞の誤用等と区別しやすくなったからではないかと考えられる.
さらに,全体に共通する傾向として,文脈長を長くすることが必ずしも分類性能の向上につな がっていない,ということが確認できる.Swanson and Yamangil (2012) も文脈に関する素性は直 前の 1 単語しか使っていないが,これは英語学習者の誤用タイプ分類タスクにおいても文脈の情報 が寄与していない可能性がある.誤用の発生している箇所の周辺は形態素解析が失敗しやすいこと に加え,そもそも言語学習者の作文自身の形態素解析が困難であることが背景にあると考えられる. 言語学習者のテキストに頑健な形態素解析器の作成は今後の課題である.
6
おわりに
本稿では,大規模コーパスを言語資源として活用するために,コーパス整備タスクの 1 つとして 日本語学習者コーパスへの誤用タグ付与のための半自動的な処理を目指し,誤用タイプの自動分類 に向けた実験を試みた. まず,日本語学習者の誤用タグつきコーパスを設計し,誤用タグ付与作業を行った.作成した コーパスのアノテーター間のκ 値は 0.602 であり,高い一致率であった.また,作成したコーパス を用い,最大エントロピー法によって誤用タグの自動分類タスクに取り組んだ.素性にはベースラ インとして単語の周辺情報と依存関係を利用した.さらに,誤用タイプ分類表を階層構造にし,分 類性能の向上を計った.誤用文の性質を考慮し,拡張素性として「ベースライン+編集距離」,「ベー スライン+置換確率」を付加した結果,分類性能を向上させることができた.その結果,F 値のマ クロ平均は 49.6 から 68.4 に向上した.事例数が少なく十分な精度が得られていない誤用タイプも 存在するが,初の誤用タイプ自動分類器において実用的な精度と考えられる.F 値 80 を達成して いた誤りタイプはベースライン法では「助詞」,「脱落」,「余剰」の 3 種類のみであったのに対し, 階層構造を利用することによって新たに「語彙選択」,「表記」,「動詞」,「指示詞」が,置換確率を 用いることで新たに「形容詞」が,それぞれ F 値 80 を達成することができ,自動化に向けて大き く前進することができた.事例数の少ない誤用タイプは精度も低いので,その問題を解決するため にセルフトレーニングを用いて,事例を増やし,精度向上を図ることも現在検討中である. 今回,Lang-8 のように正用文と誤用文の両方が大量に存在するが誤用タイプが不明な場合を想 定し,誤用文を考慮に入れた素性を試したが,誤用箇所および正用例が示されていない言語学習者 コーパスも多数存在する.そのような場合,誤用タイプ分類の前に誤用検出・訂正をする必要があ る.本研究により,正用例が誤用タイプ分類に貢献することが示されたが,誤用タイプが誤用検出・ 訂正に影響を与えている可能性も考えられる.そこで,誤用タグに関しては,誤用タイプ分類と誤 用検出・訂正を同時に行う手法を今後検討していきたい.さらに,言語教育現場でどのように使用 されるかを考慮に入れたタグの使いやすさの評価のためには,他の誤用タグと比較してどのように 自動分類性能が異なるかなども考慮に入れるべきであるが,自動分類に対応できる誤用タイプの構築を目指しているため本稿では対象とせず,今後の課題とした. 現在,様々な言語学習者コーパスが存在するが,学習者コーパスをそのまま用いるには情報が 足りないため,誤用検出をしたり,誤用タイプに分類し誤用タグを付与したりと前処理をしなけれ ばならない.機械学習による誤用タイプ分類の精度が高くなれば,研究のために利用できる学習者 コーパスの量が増え,大規模なコーパスでさらに普遍的な現象なども見ることが可能になると考え られる.
謝 辞
Lang-8という貴重な資料を提供して頂いた株式会社 Lang-8社長喜洋洋氏に感謝申し上げます. 論文に対して貴重なご意見を頂いた査読者の方と編集委員の方にも感謝申し上げます.参考文献
浅田和泉 (2007). 日本語学習者作文コーパスにみる多義的副詞の習得について. 熊本大学社会文化 科学研究科 2007 年度プロジェクト研究報告,7, pp. 79–96. 浅田和泉 (2008). 中国人日本語学習者の副詞の語順. 熊本大学社会文化科学研究科 2008 年度プロ ジェクト研究報告,8, pp. 37–58.Brockett, C., Dolan, W., and Gamon, M. (2006). “Correcting ESL Errors Using Phrasal SMT Techniques.” In Proceedings of the 21st International Conference on Computational Lin-guistics and 44th Annual Meeting of the Association for Computational LinLin-guistics (ACL), pp. 249–256, Sydney, Australia.
Carletta, J. (1996). “Assessing Agreement on Classification Tasks: The Kappa Statistic.” Com-putational Linguistics,22 (2), pp. 249–254.
張希朱 (2010). 話者を表す「私は」の用法について:日本語母語話者と日本語学習者の意見文を比 較して. 学校教育学研究論集,22, pp. 23–35.
Chodorow, M., Tetreault, J., and Han, N.-R. (2007). “Detection of Grammatical Errors Involving Prepositions.” In Proceedings of the 4th ACL–SIGSEM Workshop on Prepositions, pp. 45–50, Prague, Czech Public.
De Felice, R. and Pulman, S. (2007). “Automatically Acquiring Models of Prepositional Use.” In Proceedings of the 4th ACL–SIGSEM Workshop on Prepositions, pp. 45–50, Prague, Czech Public.
De Felice, R. and Pulman, S. (2008). “A Classifier-based Approach to Preposition and Deter-miner Error Correction in L2.” In Proceedings of the 22nd International Conference on
Computational Linguistics (COLING 2008), pp. 169–176, Manchester, U.K.
藤野拓也,水本智也,小町守,永田昌明,松本裕治 (2012). 日本語学習者の作文の誤り訂正に向け た単語分割. 言語処理学会第 18 回年次大会, pp. 26–29.
Gamon, M., Gao, J., Brockett, C., Klementiev, A., Dolan, W., Belenko, D., and Vanderwende, L. (2008). “Using Contextual Speller Techniques and Language Modelling for ESL Error Correction.” In Proceedings of the 3rd International Joint Conference on Computational Linguistics (IJCNLP 2008), pp. 449–456, Hyderabad, India.
Han, N. R., Chodorow, M., and Leacock, C. (2006). “Detecting Errors in English Article Usage by Non-Native Speakers.” Natural Language Engineering,12 (2), pp. 115–129.
Holec, H. (1981). Autonomy and foreign language learning. Pergamon Press, Oxford.
細川英雄 (1993). 留学生日本語作文における格関係表示の誤用について. 早稲田大学日本語研究教 育センター紀要,5, pp. 70–89. 市川保子 (1997). 日本語誤用例文小辞典. 凡人社. 市川保子 (2000). 続・日本語誤用例文小辞典 接続詞・副詞. 凡人社. 市川保子 (2001). 日本語の誤用研究. 国際交流基金日本語グループ(編), 日本語教育通信 (40 版)., pp. 14–15.国際交流基金. 今枝恒治,河合敦夫,石川裕司,永田亮,桝井文人 (2003). 日本語学習者の作文における格助詞の 誤り検出と訂正. 情報処理学会研究報告 コンピュータと教育研究会報告, pp. 39–46. 情報処理 学会. 今村賢治,齋藤邦子,貞光九月,西川仁 (2012). 識別的系列変換を用いた日本語助詞誤りの訂正. 言語処理学会第 18 回年次大会, pp. 18–21. 石田亨,伊佐原均,齋賀豊美,S. Thepchai,成田真澄,内元清貴,和泉恵美 (2003). 適合型コミュ ニケーションの研究開発. 平成 15 年度通信・放送機構研究発表会, pp. 572–581. 蔭山ハント悠子 (2004). 新・はじめての日本語教育 1 日本語教育の基礎知識. アスク, 東京. 鎌田修,山内博之 (1999). KY コーパス Ver 1.1. テクニカル・レポート, 第二言語としての日本語 の習得に関する総合研究グループ. http://www.opi.jp/shiryo/ky corp.html. 李在鎬,林炫情,宮岡弥生,柴崎秀子 (2012). 言語処理の技術を利用したタグ付き日本語学習者 コーパスの構築. 2012 年度日本語教育学会春季大会予稿集. 松田真希子,森篤嗣,金村久美,後藤寛樹 (2006). 日本語学習者の名詞句の誤用と言語転移. 留学 生教育,11, pp. 45–53. 峰布由紀 (2011). 言語処理の発達の観点からみたナイデとナクテの習得過程. In 7th International Conference on Practical Linguistics of Japanese (ICPLJ7), pp. 92–93, San Francisco, U.S.A. 水本智也,小町守,永田昌明,松本裕治 (2013). 日本語学習者の作文自動誤り訂正のための語学学
永田亮,井口達也,脇寺健太,河合敦夫,桝井文人,井須尚紀 (2005). 前置詞情報を利用した冠詞 誤り検出. 電子情報通信学会論文誌,J88-D-I (4), pp. 873–881. 永田亮,若菜崇宏,河合敦夫,森広浩一郎,桝井文人,井須尚紀 (2006). 可算/不可算名詞の判定 に基づいた英文の誤り検出. 電子情報通信学会論文誌,J89-D-8, pp. 1777–1790. 南保亮太,乙武北斗,荒木健治 (2007). 文節内の特徴を用いた日本語助詞誤りの自動検出・校正. 情報処理学会研究報告 自然言語処理研究報告, pp. 107–112. 情報処理学会. 大木環美,大山浩美,北内啓,末永高志,松本裕治 (2011). 非日本語母国話者の作成するシステム 開発文書を対象とした助詞の誤用判定. 言語処理学会第 17 回年次大会, pp. 1047–1050. 大曽美恵子,杉浦正利,市川保子,奥村学,小森早江子,白井英俊,滝沢直宏,外池俊幸 (1997). 日本語学習者の作文コーパス:電子化による共有資源化. 言語処理学会第 3 回年次大会論文集, pp. 131–145. 大山浩美 (2009). 日本語学習者コーパスのための誤用タグの構築について. 国文研究, 54, pp. 102–114. 大山浩美,小町守,松本裕治 (2012). 日本語学習者の作文における誤用タグつきコーパスの構築に ついて―NAIST 誤用コーパスの開発―. 第一回テキストアノテーションワークショップ. Oyama, H., Komachi, M., and Matsumoto, Y. (2013). “Towards Automatic Error Type
Classi-fication of Japanese Language Learners’ Writings.” In Proceedings of the 27th Pacific Asia Conference on Language, Information, and Computation (PACLIC 27), pp. 163–172, Taipei, Taiwan.
Oyama, H., Matsumoto, Y., Asahara, M., and Sakata, K. (2008). “Construction of an Error Information Tagged Corpus of Japanese Language Learners and Automatic Error Detection.” In Proceedings of the Computer Assisted Language Instruction Consortium, San Francisco, U.S.A. CALICO.
清水政明,宋哲,孟慶栄,杜鳳剛,壇辻正剛 (2004). 中国人日本語学習者対訳作文コーパスの構築 における誤りタグの構築について. 日本語言文化教学与研究国際学術研討会.
Sun, G., Liu, X., Cong, G., Zhou, M., Xiong, Z., Lee, J., and Lin, C. (2007). “Detecting Erroneous Sentences using Automatically Mined Sequential Patterns.” In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics (ACL), pp. 81–88, Prague, Czech Public.
Suzuki, H. and Toutanova, K. (2006). “Learning to Predict Case Makers in Japanese.” In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics (ACL), pp. 1049–1056, Sydney, Australia.
ESL Educational Aid.” In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pp. 357–361, Montreal, Canada. 寺嶋弘道 (2013). 日本語教育におけるコーパスの応用―データ駆動型学習とその実践方法の考察―.
ポリグロシア, pp. 91–103.
寺村秀夫 (1972). 日本語の文法 上・下. 国立国語研究所.
寺村秀夫 (1990). 外国人学習者の日本語誤用例集接続詞・副詞. テクニカル・レポート, 大阪大学・ 国立国語研究所.
Tetreault, J. and Chodorow, M. (2008). “The Ups and Downs of Preposition Error Detection in ESL Writing.” In Proceedings of the 22nd International Conference on Computational Linguistics (COLING 2008), pp. 865–872, Manchester, U.K.
梅田康子 (2005). 学習者の自律性を重視した日本語教育コースにおける教師の役割. 愛知大学 言 語と文化,12, pp. 59–77.
王国華 (2003). 中国人日本語学習者が間違えやすい表現について. 北陸大学紀要,27, pp. 115–122. Wilcox-O’Hearn, A., Hirst, G., and Budanitsky, A. (2008). “Real-word Spelling Correction with Trigrams: A Reconsideration of the Mays, Damerau, and Mercer Model.” In Gelbukh, A. (Ed.), Proceedings of 9th International Conference on Intelligent Text Processing and Computational Linguistics (CICLing-2008)(Lecture Notes in Computer Science Vol. 4919), pp. 605–616, Berlin. Springer.
Yi, X., Gao, J., and Dolan, W. (2008). “A Web Based English Proofing System for ESL Users.” In Proceedings of the 3rd International Joint Conference on Computational Linguistics (IJC-NLP 2008), pp. 619–624, Hyderabad, India. 吉永尚 (2013). 「ナイデ」と「ナクテ」の相違について. 園田学園女子大学論文集,47, pp. 133–140.