February 21-25, 2013!
!
!
!
!
!
2013 RNA Spring Project!
Basic Theories for Bioinformatics!
Lecture Note I!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
Motomu MATSUI!
!
Institute for Advanced Biosciences!
Keio University, Japan!
GBE
GENOME BIOLOGY AND EVOLUTION www.gbe.oxfordjournals.org!
!
!
!
____________________________________________________
!
Basic Theories for Bioinformatics Lecture Note I!
!
!
by Motomu MATSUI!
!
!
2013/01/20!
ver. 3!
!
2013/02/01!
ver. 3.1!
!
2013/02/08!
ver. 3.14!
!
2013/02/14!
ver. π!
!
!
!
!
!
!
!
!
!
!
Copyright Ⓒ by Motomu MATSUI !
!
____________________________________________________
!!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
目次!
!
L
ECTURE1 -Introduction-!
1.1 A quick introduction 5 1.2 前提となる知識 6 1.3 参考文献 6L
ECTURE2 -Clustering-!
2.1 分類 とClusteringとClassification 8 2.2 クラスタリング手法の 分類 9 2.3 類似度,距離 10 2.4 クラスタリング手法色々 13 2.5 クラスタリング結果の妥当性評価 17L
ECTURE3 -Spectral clustering-!
3.1 スペクトラルクラスタリングの概要 20 3.2 スペクトラルクラスタリングを導出するための下準備 25 3.3 スペクトラルクラスタリングの導出 51L
ECTURE4 -Statistics-!
4.1 統計解析のあらまし 59 4.2 基本的な統計の手順 60 4.3 E値とは何か? BLASTの統計学 68 4.4 最尤法とベイズ法 75L
ECTURE5 -Phylogenetics-!
5.1 分子進化 78 5.2 マルチプルアライメント 785.3 系統樹.進化モデル 79 5.4 系統樹の作成法 83 5.5 進化解析への応用 85
L
ECTURE6 -Spectral Phylogenetic Analysis-!
6.1 進化解析とインフォマティクスをどのように統合するか 87 6.2 Matsui M et al., 2013の概略 87
!
!
!
!
!
!
!
!
1. Data mining
...Graph theory
...Spectral clustering
2. Statistics
...Statistical testing
...Model estimation
3. Phylogenetics
...Molecular evolution
...Comparative genomics
! 1.1 A quick introduction
!
バイオインフォマティクスは本来,広範囲に渡る分野横断的知識が必要とされる難しい 学際分野です.先人達が蓄積してきた多くの有用なツールのおかげで,我々は普段何気な く研究を進める事ができていますが,そこで得られた結果を本当に正しく解釈する為には, 改めて基礎的な概念を「言葉」ではなく「心」で理解しておく必要があるでしょう.そこ で,本勉強会ではその中でも,!!
“Nothing in Biology Makes Sense Except in the Light of Evolution”!
!
- Theodosius Dobzhansky (1900-75)!!
!
ということで,進化解析に関連した以下の三つの分野を取り上げ,それぞれ基礎理論まで 掘り下げた議論をしたいと思います.!!
! クラスタリング! a. クラスタリングとは何か?何の為に行うのか?! b. スペクトラルクラスタリングの詳細な理論的背景と導出!!
! 統計解析! a. 統計解析の理論,具体的な手順! b. 最尤法やベイズ統計について! c. E-valueとは? ...BLASTを正しく理解する!!
! 系統解析! a. 系統解析の理論.分子生物学と進化論.! b. 系統解析の実際! c. 応用的な進化解析の俯瞰!!
特に今回は,データマイニング手法のなかでも最近特に有力視されているスペクトラル クラスタリングについて,その詳細な導出過程を追ってみます.こうした基礎理論に直に 触れる経験は,おざなりな理解のまま進めてしまいがちな普段の解析の意味をしっかりと 理解し直すきっかけになるのではないかと思います.また,上記で取り上げた項目はもち ろん進化解析のみならず,直接的に間接的に全てのバイオインフォマティクスの基礎となBasic theories of Bioinformatics
L
ECTURE
1
!
1.2 前提となる知識 本勉強会への参加に際しては特別な前提知識を求めてはいませんが,以下のキーワード について事前にgoogleって予習しておくとより理解が深まるでしょう.!!
・グラフ理論! ! グラフ...ノード,エッジ,隣接! ! 構造...木,系統樹,重み付きグラフ! ! 隣接行列... 類似度行列!!
・線形代数! ! 固有値,固有ベクトル...行列の基本演算,直行行列,ヒルベルト空間,逆冪乗法! ! 標準化...二次形式,スペクトル分解,レイリー商!!
・ネットワーク理論! ! 中心性...次数中心,距離中心,近接中心,媒介中心! ! ネットワークの特性...ハブ,クラスター係数,コミュニティ構造! ! クラスタリング評価...エントロピー,純度,モジュラリティ!!
・統計学! ! 基本統計量...平均,分散,母数! ! 確率分布...正規分布,t分布,χ二乗分布,中心極限定理! ! ベイズ主義...事前確率,事後確率,尤度,ベイズ情報量基準,ベイズ系統樹!!
1.3 参考文献 本テキストを執筆するにあたって参考にした文献を以下を挙げます.☆をつけた書籍は 初学者にとって非常に読みやすい本ですのでお勧めです.!!
[クラスタリング]! ☆1. 新納浩幸 (2007) Rで学ぶクラスタ解析, オーム社.2. Rui Xu and Donald C. Wunsch II (2009) CLUSTERING, IEEE. 3. 斎藤正彦 (1966) 線形代数入門, 東京大学出版会.!
!
[統計解析]! ☆4. 中澤港 (2003) Rによる統計解析の基礎, ピアソン・エデュケーション. ☆5. Derek A. Roff (2011) 生物学のための計算統計学, 共立出版.!!
[系統解析]! ☆6. 木村資生 (1988) 生物進化を考える, 岩波書店.8. Ziheng Yang (2006) 分子系統学への統計的アプローチ, 共立出版. 9. 三中信宏 (1997) 生物系統学, 東京大学出版会.
10. Ian Korf, Mark Yandell and Joseph Bedell (2003) BLAST, O’REILLY.
11. David W. Mount (2004) Bioinformatics, Cold Spring Harbor Laboratory Press.
!
[原著論文]!
12. Jianbo Shi and Jitendra Malik (2000) Normalized Cuts and Image Segmentation, IEEE
Transactions on Pattern Analysis and Machine Intelligence, 22(8), 888-905
!
13. Chris Ding, Chris H. Q. Ding , Xiaofeng He , Hongyuan Zha , Ming Gu , Horst Simon (2001) A Min-max Cut Algorithm for Graph Partitioning and Data Clustering, In Proceedings of the first IEEE International Conference on Data Mining (pp.107-114). Washington, DC, USA: IEEE Computer Society.
!
14. Motomu Matsui, Masaru Tomita, Akio Kanai (2013) Comprehensive Computational Analysis of Bacterial CRP/FNR Superfamily and its Target Motifs Reveals Stepwise Evolution of Transcriptional Networks, Genome Biol. Evol. 5(2), 267-282.
!
15. Hirotsugu Akaike (1973) Information theory and an extention of the maximum likelihood principle, Proceedings of the 2nd International Symposium on Information Theory, Petrov, B. N., and Caski, F. (eds.), Akadimiai Kiado, Budapest, 267-281.
!
16. Newman, MEJ (2006) Modularity and community structure in networks. PNAS 103(23), 8577-8696.
!
17. G Palla, I Derényi, I Farkas, and T Vicsek (2005) Uncovering the overlapping community structure of complex networks in nature and society: Nature 435, 814–818.
!
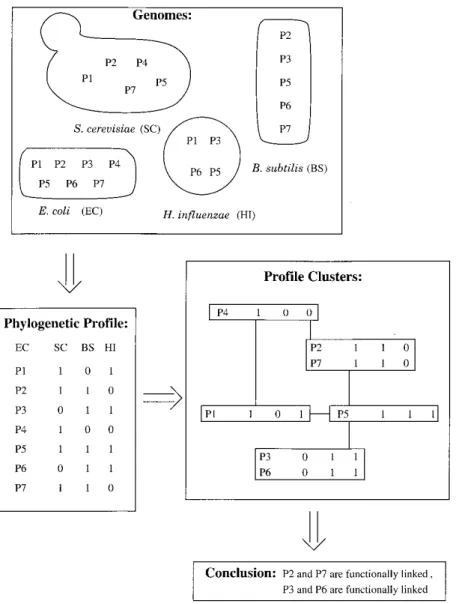
18. Pellegrini M, Marcotte EM, Thompson MJ, Eisenberg D, Yeates TO (1999) Assigning protein functions by comparative genome analysis: protein phylogenetic profiles. PNAS 96, 4285-4288.
!
19. Paul Erdös and Alfred Rényi (1970) On a new low of large numbers. J. Anal. Math 22, 103-111.
!
20. Samuel Karlin and Stephen F. Altschul (1990) Methods for assessing the statistical significance of molecular sequence features by using general scoring schemes. PNAS 87, 2264-2268.
!
21. Richard Arratia, Louis Gardon and Michael Waterman (1986) An extreme value theory for sequence matching. Anal. Stat., 14, 971-993.
! 2.1 分類 とClusteringとClassification 日本語では何となく分類と訳されるようなタイトルの二語ですが,実はクラスタリング (clustering)とクラス分類(classification)は似て非なるものです.その違いを強調して比較す ると以下のようになります.!
!
[Classification]! ・教師付きである.”ルール”によって対象を分類する.! → あらかじめ設定したいずれかの属性に対象物は分類される(はず)と想定している! ・すなわち”学習結果”は次回も適用できる.! → 閾値,分類ルールを決定する事が目的! ・分類パターン自体から得られる新規知見はない.! → 分類された後の個別の要素について考察するだけ! ・属性の設定は主観的,操作は客観的.!!
[Clustering]! ・教師無しである.”類似度”によって対象を分類する.! → 新たな属性を見いだすことが目的.すなわち”学習”は存在しない.! ・分類パターン自体が新規知見.! ・属性の設定は客観的,操作は主観的.!!
! Basic theories of BioinformaticsL
ECTURE
2
Lecturer: Matsui M Fig.1-ClassificationとClusteringの比較.クラス分類においては(観察者からは見える見えな いはともかく),対象物にはあらかじめ設定した属性のどれかが備わっていると考える.分類 の目的は”学習”であり,(あるはずの)属性の境界面に従って超平面を引くという操作であると いえる.一方,クラスタリングにおいては新たな属性を発見する事が目的になる.類似度に 従ってグルーピングを行い,その分類パターンから新たな知見を得る操作であると言える.! 2.2 クラスタリング手法の 分類 クラスタリング手法には様々なものがありますが,大まかには以下のように分類する事 ができます (もちろん複数の分類にまたがるような手法もたくさんあります.例えば Newman法は大域アプローチでしたが,局所アプローチに立った改良もされています.).!
!
① ボトムアップ vs トップダウン! 似ているもの同士を結合してクラスターを形成する作業を再帰的に繰り返すことで,最 終的には一つのクラスターまでまとめあげる事ができます.この方法を”ボトムアップ”ア プローチと言います.逆に全体をまず一つのクラスターと考え,それを複数に分割する事 でサブクラスターをいくつか得る方法を”トップダウン”アプローチと言います.!!
[ボトムアップ]! ・階層クラスタリング!・Markov Cluster Algorithm (MCL)! ・K-クリーク法!
!
[トップダウン]! ・K-meansとその派生! ・スペクトラルクラスタリング! ・混合分布モデル!!
② 大域 vs 局所! 要素の集合全体を対象としてクラスタリングを行うのが”大域”アプローチです.要素数 が限られている場合はこれに属する方法のいずれかを行うべきでしょう.一方で,解析対 象が大きすぎる場合は個別の要素に着目して,その周辺の要素のまとまり方からクラスター を決定する近似的手法が採られます.それを”局所”アプローチと言います.!!
[大域]! ・階層クラスタリング! ・K-meansとその派生! ・スペクトラルクラスタリング!!
[局所]! *以下の二つを始め,ネットワーク理論に基 く多くの方法は局所アプローチに属します.! ・K-クリーク法! ・MCL Fig.3-Local, Globalアプローチの比較. Fig.2-Bottom-up, Top-downアプローチの比較.③ ソフト vs ハード! クラスターを決定したときに,各要素が必ず一つのクラスターに属しているような方法 を”ハード”アプローチ,必ずしも一つではなく,一つの要素が複数のクラスターに属する ことを許す方法を”ソフト”アプローチと言います.!
!
[ソフト]! ・Fuzzy c-means! ・混合分布モデル!!
[ハード]! ・階層クラスタリング! ・スペクトラルクラスタリング! ・K-means!!
!
2.3 類似度,距離 クラスタリングは”似たもの同士”を一つの固まりにする作業でした.そのとき,要素が 似ているか否かの基準となる値が類似度や距離です.!!
*なお,必ずしも全てのクラスタリング手法が類似度に基づくものではない事に留意し ておくといつか役立つかもしれません.例えばネットワーク理論に基づくクラスタリン グ手法のいくつかは,グラフ構造の情報”のみ”を用いますし,混合分布モデルはモデル の推定問題としてクラスタリングを行います.!!
幾何距離! 今,あるユークリッド空間上に以下のように定められるfとgという二点が存在していた とします.! ! このとき,fとgの距離をノルム(norm)と言います. ノルムの定義には様々なものがあるのですが,クラ スタリングでよく使われるのは以下で紹介するマン ハッタン距離とユークリッド距離,そしてそれをそ れぞれの次元の”重み”で正規化したマハラノビス距 離の三つです.f : e
f=
e
f 1e
f 2· · · e
f ng : e
g=
e
g1e
g2· · · e
gn Fig.4-Hard, Softアプローチの比較. Fig.5-マンハッタン距離とユークリッド距離① マンハッタン距離 (L1 norm)! 碁盤目上の空間における距離.! 文字列情報に応用したものはハミング距離と呼ばれます.!
!
② ユークリッド距離 (L2 norm)! ようするにピタゴラスの定理でいう斜辺の長さ.! ③ マハラノビス距離! Σは共分散行列.つまりユークリッド距離を共分散行列で割って正規化したものがマハ ラノビス距離です.! 類似度! いくつか類似度を計る指標も紹介します.類似度と距離は例えばdfg=1-rfgのようにして 変換する事ができます.この変換方法自体はある意味,”個人の自由”にまかされていま す.つまり”妥当そう”であれば何でもありで,例えば|rfg|,rfg2に置き換えるとするとそれぞ れabsolute/squared correlationになります.こういった事からもクラスタリングの”主観性” が分かると思います.!!
④ ピアソン相関係数! !!
ピアソン相関係数のイメージは右図でつかめる のでは無いでしょうか.ちなみにegcをegcのラン クに置き換えるとスピアマン相関係数になりま す.d
f g=
c|e
f ce
gc|
d
f g=
c(e
f ce
gc)
2d
f g=
(e
fe
g)
t 1(e
fe
g)
r
gf=
c(e
f ce
f) (e
gce
g)
c(e
f ce
f)
2 c(e
gce
g)
2⑤ コサイン距離! *余弦定理から導かれた距離.ピアソン相関係数を単純な角度だけの概念にシンプル化 した類似度としても捉える事ができます.!
!
⑥ ジャカード係数! 集合XとYについて! !⑦ 相互情報量 (Mutual information; MI)! 集合XとYについて! ただし,H(X)はXの周辺エントロピーでH(X,Y)はXとYの結合エントロピー.なお,H(X)は X=iとなる確率をPiとすると! と定義される関数です.!
!
結局どの指標を使えば良いか?! 以上様々な指標を列挙しましたが,結論から言いますとどの指標がベストと決定できる ものではなく目的や手元のデータの性質に応じて適当な指標は変わります.また,マイク ロアレイデータを使うならば相関係数,系統プロファイルならジャカード係数,タンパク 質間相互作用なら相互情報量,といったようにある程度”業界内の傾向”はあるのですが, それにとらわれないことも重要です.! ただ,一つポイントを挙げるとすればデータのバラツキがどの程度か?,重み付けをす る必要はあるか?,あるいは0/1にデータを単純化してしまっていいか?などデータの性 質についてよく吟味してから指標を選ぶことですね.各指標のバラツキや大きさが著しく 異なる場合はマハラノビス距離といった正規化項を含む指標を使う方が良いですし,逆に 単純な配列比較などにおいてはマンハッタン距離やハミング距離等,シンプルな指標を使っ た方が良いことが多いです.!cos( ) =
ce
f ce
gc ce
2f c ce
2gcsim(X, Y ) =
X
Y
X
Y
M I(X, Y ) = H(X) + H(Y )
H(X, Y )
H(X) =
iP
ilog P
i2.4 クラスタリング手法色々 2.2で見た通り,クラスタリング手法にも様々なものがあります.ここでは代表的なク ラスタリング手法についてその概要を紹介します.!
!
Tab.1-主要なクラスタリング手法一覧!!
!
選び方のポイント! ・何を知りたいか! e.g.! 近縁種間の関係→階層的クラスタリング! 遠縁種間の関係→ネットワーク解析!!
・事前知識は存在するか! 分割数(K)をあらかじめ決定できる問題か?! 事前にモデルは想定できる問題か?...など!!
・パラメータの種類,個数! 次元の呪い,overfitting! → 次元縮約,赤池情報量基準!!
・安定性(局所解),制約(モデルの大きさ),効率,計算量! 長所 短所 向いている解析 階層クラスタリング 非常に高速 データの解釈が困難 一般 K-means/x-means 高速 超球半径が一定にな りがち 一般 MCL 超大規模なデータ解 析に関して唯一有効 なアプローチ あくまでも近似手法 である 超大規模ネットワ ーク解析 スペクトラルクラスタリング グラフ構造を反映し たクラスタリングが できる グラフ構造によって は適当な分割は得ら れない 類似度行列で表現 できるような群の 解析 Newman/K-クリーク ネットワーク構造の 特徴を抽出できる 全体的に疎な集団に 対しては,有効な手 段ではない ネットワーク解析 混合分布モデル 事前にモデルが想定 できる場合は強力 事前知識が求められ る モデル推定 Fuzzy c-means 曖昧な分類を評価で きる 場合によっては分類 精度が落ちる 緩やかなクラスタ リング階層クラスタリング! 名前の通り段階的に要素を結合し,グループとしてまとめていく手法です.その過程は ちょうどトーナメント表のようなグラフとして表現する事ができ,これをデンドログラム と言います.基本的に似た者同士をくっつけていくシンプルなアルゴリズムなのですが, クラスター間の距離の計算の仕方について以下のように様々なバリエーションがあります. この中ではウォード法が比較的精度が良いとされています.一方で,系統解析においては はほぼ群平均法(UPGMA)一択となっています(実のところUPGMAももはや廃れていて, 階層的な系統解析を行う際は近隣結合法がベターだとされています).!
!
・単連結法 (最近距離法)! 二つのクラスターの中でも最も近い要素同士の距離をクラスターの距離とする! ・完全連結法 (最遠距離法)! 二つのクラスターの中でも最も遠い要素同士の距離をクラスターの距離とする! ・群平均法(UPGMA)! 二つのクラスターの全要素間の距離を計算し,その平均をクラスターの距離とする! ・重心法! 結合したクラスターの重心を新たなクラスターの中心点とする! ・メディアン法! クラスターの重心間の距離の中点を新たなクラスターの中心点とする! ・ウォード法! 二つのクラスターを結合した時に,その分散の増分が小さい順に結合していく! ! !!
!
!
Fig.7-階層クラスタリングの手法色々.星はクラスターの重心. ウォード法の緑の領域は二つのクラスターを結合した場合の増分.K-means! 階層クラスタリング以外の方法を非階層クラスタリングと言いますが,K-meansはその 中でも最も一般的な方法です.手順はFig.8で示す通り非常にシンプルで実装も容易です.! ! !
!
!
!
!
!
また歴史が古い分,色々な派生アルゴリズムがあります.!!
・Kernel K-means! K-meansにはクラスターが超球状になり,またその直径も均等にならす方向への強いバ イアスがかかってしまうという欠点があります.その解決策の一つとして,Kernel法と組 み合わせた Kernel K-meansがあります.平たく言えば,一旦対象の要素を高次元空間へ 写像してからK-meansを行うというもので,そうすると超球や直径の問題を回避する事が できます.さらに要素間の距離は内積から求められますので,Kernelトリックがばっちり 使えます.!!
・x-means! クラスター数を始めからK個に決めうちするのではなく,二分割のK-meansをAIC等の 指標が最適な値になるまで 再帰的に繰り返すものです.!!
・Fussy c-means! クラスター同士の重なりを許したクラスタリング手法です.すなわち,要素の所属する クラスターは必ずしも一つだけではなく,複数のクラスターにまたがって所属する要素も 存在するような結果が得られます.ちなみにK-meansとは関係ありませんが,クラスター の重複を許す方法としては混合分布モデルも有力な方法です.これは手元のデータを発生 しうるK個の確率モデルを最尤推定する事で求め,結果としてクラスタリング結果を得る 方法です. Fig.8-K-meansの概要.1.K個のクラスター中心(☆)を適当に設置.2.各要素 について最も近い☆をその要素の所属(クラスター)とする.3.☆を所属する要 素の重心に移動.4-5. 2,3の行程を繰り返す.6.☆が動かなくなったら終了.マルコフクラスターアルゴリズム (MCL)! 階層クラスタリングとK-meansは全要素を対象としたクラスタリング手法でしたので, 例えばWebページのリンクやソーシャルネットワークといった巨大なデータの解析を行う 事は困難です.そういった場合は局所的な要素間の相互関係からクラスタリングを行うア プローチが有効です.MCLはその中でも2000年ごろに提唱された有力な手法の一つです.! ! !
!
!
!
!
!
ネットワーク理論ベースの方法! MCLはネットワーク構造に着目した手法でしたが,ネットワーク理論に基づいた手法は 他にも様々なものが提案されています.その中でも有力な以下の二つを紹介します.!!
・Newman法! あるクラスターの内部とその近傍の要素についてエッジの”密度”を考えます.そのとき 内側の”密度”から外側の”密度”を引いた値が最大限になるようにクラスターを更新してい けば最終的に尤もらしいクラスタリング結果を得る事ができる,というのがNewman法で す.トップダウン,ボトムアップ,局所的手法などいくつかバリエーションがあるのです が,いずれもその評価関数としては2.5で出てくるモジュラリティQが用いられます.!!
・K-クリーク法! K-クリークとはサイズKの完全グラフのことです.これをネットワークから全て抽出 し,次に接しているK-クリークを結合していく事でクラスターを得ます.!!
スペクトラルクラスタリング! グラフ分割問題としてクラスタリングを行う方法で,大域的トップダウン法に属します. 詳細については3.1以降で述べます. Fig.9-MCLの概要.ある要素(☆)を出発点としてある歩数分ランダムウォーク を繰り返す.その試行結果から要素間の遷移確率を求めマルコフモデルを構 築し,クラスタリングを行う.2.5 クラスタリング結果の妥当性評価 ① 正解セットを使用した評価法! 感度,特異度,精度! クラスタリング結果をどのように評価するのか?というのは非常に重要な問題です.様々 な方法が提案されていますが,もし,正解が既知のデータセットが用意できる場合は次の ようなクロス表を作成する事でクラスタリング手法の評価を行う事ができます.!
!
!
ここでC1, C2, ..., CkはK個にクラスタリングした結果,予測された属性,A1, A2, ..., AkはK 通りの実際の属性です.またxp,qはそれぞれのカテゴリーに属する要素の個数です.つま り,p=qはクラスタリング結果が正解のケース,p≠qはクラスタリング結果が不正解のケー スということになります.それをさらに以下の表にまとめると!!
!
のようになります.この表を用いて感度(Sensitivity),特異度(Specificity),精度(Accuracy) 等は以下のように定義されます.また1-Specificityをx軸に,Sensitivityをy軸にとったグラ フをROC曲線と言い,適当な閾値を決定するのに良く利用されます.! !!
!
!
A A ... A C x11 x12 ... x1k C x21 x22 ... x2k ... ... ... ... ... C xk1 xk2 ... xkk TRUE FALSEPredicted True TP FP (α error) PPV
Predicted False FN (β error) TN NPV
Sensitivity Specificity
Sensitivity =
T P
T P + F N
Specif icity =
T N
! エントロピー,純度! 上記はクラスターと要素の対応関係を元に定義した値となっていますが,対応関係では なく,単にクラスター内の”バラツキ”を評価する事もできます.そのように定義される値 としてはエントロピー(entropy)と純度(purity)があります.! ! ここで,EiとPiはそれぞれi番目のクラスターCiにおけるエントロピーと純度です.以下の ように定義されます.つまりこれらの値に重み付けをして,全てのクラスターについて足 し込んだものが上記の値です.! !
!
P ositive predictive value =
T P
T P + F P
N egative predictive value =
T N
T N + F N
Accuracy =
T P + T N
T P + T N + F P + F N
entropy =
K i=1|Ci|
N
E
ipurity =
K i=1|Ci|
N
P
i=
1
N
K i=1max
h|C
iA
h|
E
i=
K h=1P (A
h|C
i) log P (A
h|C
i)
P
i= max
h|C
iA
h|
|C
i|
② 正解セットを使わない指標! モジュラリティ! クラスタリングの結果はネットワークの特徴量によっても評価する事ができます.例え ば,以下のようにクラスター内のエッジが密で,かつクラスター間のエッジが疎であれば, それは良いクラスタリングの結果であると言えます.! ! 後述するスペクトラルクラスタリングも類似の考え方に基づく指標を定義しています が,ここでは先程ちらっと出てきたNewmanのモジュラリティを紹介します.これは全 エッジ数に対するそれぞれのグループ内のエッジの割合から,それをランダムにかく乱し た後に再結合されたエッジの数の期待値を引いた値です.ここでクラスターpとクラス ターqの間のエッジの数を全エッジで割った数をepqとし,それをランダムにかく乱した後 の期待値をai2とすると,モジュラリティQは以下のように定義されます.! 赤池情報量規準! その他に,クラスター数をいくつにするか?というのもまた重要な問題です.つまり要 素の数だけクラスターを作ってしまえば,ある意味それこそが”最適”な分類だからです. しかし我々とってそれは望ましい結果ではありませんので,データの適合度とクラスター 数のバランスをとる必要があります.その場合によく使われるのが赤池情報量規準 (AIC),あるいはその応用であるベイズ情報量規準 (BIC)です.! ここでLは最大尤度,nは対象の大きさ,kは母数の数です.これらの値が最も小さくなれ ばそれが適当なクラスター分割数だという判断ができるわけです. Fig.10-クラスター内/間のエッジ.黒は内部エッジ,赤は外部エッジ.
Q =
i(e
iia
2i)
AIC =
2 ln L + 2k
BIC =
2 ln L + 2k ln(n)
3.1 スペクトラルクラスタリングの概要 これからクラスタリングをグラフ分割問題として解く方法の一つであるスペクトラルク ラスタリングについて,その詳細な導出過程を追っていきます.まず3.1でその概要をつ かみ,3.2でその詳細を理解するための前提知識を学び,そして3.3で導出を試みます.長 くなりますが,必要なのは高校レベルの簡単な計算能力だけです.頑張って付いてきてく ださい.!
!
① グラフ分割問題の定式化!!
! !!
ここではノードaとノードbの類似度を! と表す事にします.例えばFig.11では! Basic theories of BioinformaticsL
ECTURE
3
Lecturer: Matsui M Fig.11-グラフ分割問題のイメージ.(A) 重み付きネットワークグラフGと,その類似度行列 W.(B) 疎なエッジの削除によるクラスターA,Bへの分割sim(a, b)
sim(p, r) = 0.6
です.そしてクラスターAとクラスターBの間の類似度の総和W(A,B)を! と定義します.Fig.11では! となります.なお,クラスターA内部の類似度W(A)は! と定義しておきます.さらに! なるdAを定義します.するとグラフGからクラスターA,Bへの最適な分割は以下で定義さ れるMcutあるいはNcutの最小値問題に帰着することになります.! ! これらの式の意味は実にシンプルです.要するにMcut, Ncutどちらもクラスター内部の ネットワークが最大限”密”になり,かつクラスター外のリンクが最大限”疎”になれば最小 の値を取ります.つまりMcutないしNcutの最小値が求まれば自ずとAとBへの最適な分割 パターンが得られるというわけですね.もちろん,このような式は他にもいくらでも定義 することが可能で,実際色々な人が色々な式を提案していますが,現時点ではMcutあるい はNcutがスタンダードな評価関数とされています.!
!
!
W (A, B) =
a A,b Bsim(a, b)
W (A, B) =
a A,b Bsim(a, b)
= sim(p, s) + sim(r, t)
= 0.3
W (A) = W (A, A)
d
A= W (A) + W (A, B)
M cut =
W (A, B)
W (A)
+
W (A, B)
W (B)
N cut =
W (A, B)
d
A+
W (A, B)
d
B② Ncutの最小値問題を解ける形に変える! さてグラフ分割問題の定式化は出来ましたが,これらの式をそのまま解くのは容易では ありません.そこで,これから頑張って色々と式変形をして解ける形まで持っていきます. そのためにはいくつか下準備が必要なのですが,しかしそれは3.2で述べるとして,この セクションの後半部分では問題解決までの概略をNcutを使って示すことにします.Mcutに ついてはほとんどNcutと同じ式変形なのでここでは省略します. ! ! 最初にまず以下のような 行列W,Dと ベクトルqを定義します.それぞれの詳細は3.3 で述べるので,まずはそんなものかと思って受け入れてください.! この中では類似度行列Wは既に出てきていますね.行列Dとベクトルqについては今は の ままでOKです.ただし,ベクトルqは以下に述べる重要な性質を持っているのでここで指 摘しておきます;ベクトルqの中でaは対応するグラフGの要素がクラスターAに,-bは対応 するグラフGの要素がクラスターBに振り分けられている事を意味する.つまり! ! というイメージです.ともかくこうすると! となるのです!そしてさらに! なる ベクトルzと 行列Xを定義すると,最終的に!
W...
D = diag(W e)
q...
q = (a, a, a, b, b, b)
N cut =
W (A, B)
d
A+
W (A, B)
d
B= ...
= ...
= ...
=
q
t(D
W )q
q
tDq
z = D
12q
X = E
D
12W D
12 グラフGの類似度行列 (N×N次元) aか-bのどちらかの値を取るN次元ベクトル なんやかんや p q r s t uという素晴しく美しい式に変形されます!ここに至って初めてNcutが解ける形になりまし た.!
!
③ なぜ“解ける形になった”と言えるのか! 大事なことなので2回言いますが! は非常に美しい式です.なぜかというと,この式はレイリー商と呼ばれる特殊な式の形を しているからです.やはり詳細は3.2で述べますが,レイリー商は以下に述べる都合のい い性質を持っています.! なるレイリー商RX(z)について,行列Xの固有値を! 対応する固有ベクトルを! とすると,! という関係式が成り立ちます.!!
あれ,もしかして問題解けてる?!!
!
N cut =
z
tXz
z
tz
N cut =
z
tXz
z
tz
R
X(z) =
z
tXz
z
tz
1 2...
nz
1, z
2, ..., z
n 1= R
X(z
1)
R
X(z
2)
...
R
X(z
n) =
n④ まとめ! ということで概略をまとめると,!
!
1. グラフGを与えられたらまず類似度行列Wを求めます.!!
2. 次に以下で定義される 行列Xを求めます.! 3. そして行列Xの固有値(の集合, すなわちスペクトル)を求め,その中で二番目に小さな固 有値λ2 (Fielder値)とそれに対応するべクトルz2 (Fielderベクトル)を求めます.さらっと二 番目とか言ってますがその理由は後で説明します.とにかく何かしらの支障の無い範囲で なるべく小さな固有値(と固有ベクトル)を求めている事に変わりはありません.!!
4. 最後に以下の関係式からベクトルqを求めます.! すると先ほど述べた通り,ベクトルqの要素のうち正の値(≒a)に対応するグラフGの要素は クラスターAに,負の値(≒-b)に対応するグラフGの要素はクラスターBに振り分けられた 事を意味しています.まるで魔法のようですが,ともかく,これでクラスタリング結果を 得る事が出来ました.!!
とりあえず分かった事は,!!
・スペクトラルクラスタリングの”スペクトル”とは行列の固有値の集合の事! ・グラフ分割問題を単なる固有値(と固有ベクトル)の求値問題として解く事ができる!!
の二点ですね.これで得られる利点は沢山ありますが,例えば!!
・解を一意に求める事ができる(K-meansやMCLと違ってランダム試行が入らない)! ・非常に高速に解く事ができる(固有値問題は計算機の得意分野です)! ・そもそもグラフの分割問題として問題を解いているので,結果が人間の直感になじむ!!
を挙げる事が出来ると思います(三つ目には多少の個人的主観が入っていますが).!!
!
X = E
D
12W D
12q = D
12z
3.2 スペクトラルクラスタリングを導出するための下準備
!
さて,これでクラスタリングがグラフ分割問題として扱えて,さらにそのグラフ分割問 題は行列の固有値問題として解けるということが示されましたが,その詳細を理解する為 には以下に挙げるようなグラフ理論と線形代数に関する少々の前提知識が必要です.!!
① 内積と直交,行列と固有値&固有ベクトル! ② グラフと類似度行列! ③ 二次形式とレイリー商!!
一つ一つ確認していきましょう.!!
① 内積と直交,行列と固有値&固有ベクトル! 線形代数の入門編ということで,ここではベクトルと行列の基礎を確認します.!!
! ベクトルの内積! Fig.12には二つのベクトルa,bが描かれています.それぞれ! と表現します.またθはベクトルa,bのなす角度を表します.この図を使って考えれば以下 の関係は自明でしょう.! Fig.12-二次平面(直交座標).a =
a
1a
2b =
b
1b
2またベクトルaの長さ(ノルム)を||a||と表現しますが,その定義である以下の式の意味も直 観的で分かりやすいと思います.ピタゴラスは偉大ですね.! さて,ここまでは問題はないのですが,ベクトルのかけ算はどのように定義するのでしょ うか?答えから言うと,実はかけ算の定義の仕方は”自由”です.一定のルールを満たせば 好きなように定義してかまわないのです.しかしそれでは話が進まないので,とりあえず 以下のように定義する事にします.! ポッチ(・)はベクトルのかけ算の記号です.また,この操作は(a,b)とも書く流儀もありま す.そして答えがベクトルではなくスカラー(つまりただの数)になっている事にも注意で す.繰り返しますが,かけ算の定義は自由なのでこのような定義をしてみたに過ぎず,そ れ以上の意味はありません.ただこうすると色々と都合がいいのでこのような定義の仕方 をしたかけ算をみんなが使っているのです.例えば,これはa,bの角度θとうまく関連づけ ることができます.!
!
まず余弦定理を思い出しましょう.どういうものだったかというと,! ! こういう三角形があったときにaとbとθからcが求まるよ,という定理でしたね.証明は 図を見れば一発だと思います.!ka =
ka
1ka
2a
± b =
a
1± b
1a
2± b
2a =
a
21+ a
22a
· b = a
1b
1+ a
2b
2 Fig.13-余弦定理.さて,ここでa,b,cをベクトルに置き換えてみます.まずa, bは以下のように表すことにし ます.! するとそれぞれのノルムは以下のように表す事ができます.! ! これを余弦定理の式に代入してcosθについて整理すると! ここで右辺の分子に着目すると,先ほど定義したベクトルのかけ算の形が現れています ね.一方,分母に着目するとこれはちょうどaとbのノルムのかけ算の形になっています. つまり,! !
!
c
2= (b sin )
2+ (a
b cos )
2= b
2sin
2+ a
22ab cos + b
2cos
2= b
2(sin
2+ b
2cos
2) + a
22ab cos
= a
2+ b
22ab cos
a =
a
1a
2b =
b
1b
2a =
a
21+ a
22b =
b
21+ b
22c = b
a =
(b
1a
1)
2+ (b
2a
2)
2c
2= a
2+ b
22 a b cos
cos =
a
1b
1+ a
2b
2a
21+ a
22b
21+ b
22cos =
a
· b
a
b
ベクトルを中心にまとめると,! 見事θとかけ算がつながりました.こうしてみるとこのかけ算の定義を幾何学的に理解す る事ができます.! ! つまり違う方向を向いたベクトルを一方のベクトルへ”影を落としてから”その長さ同士を かけているということです.こうして見ると二つのベクトルが”直交”している状況という のも理解しやすいですね.つまり直角に交わっているときはcosθ=0ですから,かけ算の 結果も0になるのです.逆に言えばかけ算した結果が0になったときはその二つのベクトル は直交している,と言う事もできます.これは重要な性質なので覚えておいてください.!
!
さて,これまでずっと”ベクトルのかけ算”と言っていましたが,高校の数学を勉強した 人はこの操作が”内積”と呼ばれていることを知っていると思います.先ほど”かけ算”の定義 の仕方は”自由”だと言いましたが,他の様々な”かけ算の流儀”と混じって混乱しないため に,これから我々もこのかけ算の仕方を内積と呼ぶことにします (その他の有名な”かけ算 の流儀”の内の一つは外積でしょう.ここでは詳しく述べませんが,雑な説明をしておき ますと,内積のcosをsinに変えてから,とある単位ベクトルを掛けると外積になります).!!
しかし,厳密には内積というのはもっと抽象的な概念です.ある一定のルールを満たし た操作は何でも内積になり得ます.たまたま,このかけ算の定義が内積の定義も満たして いたので内積と呼んでも間違ってはいなかったということだけです.ここではこれ以上深 入りしませんが,内積の正確な知識は将来,例えばカーネル法といった応用技術の理解を 助けてくれるでしょう.簡単にでも押さえておく事をお勧めします.a
· b = a
1b
1+ a
2b
2= a b cos
Fig.14-ベクトルのかけ算の幾何的理解.行列の定義! まず,以下のような連立方程式を考えます.! これはもちろん簡単に解く事ができて! ですね(ただしad - bc ≠ 0とします).さて,この連立方程式をより見やすく表現するため に,今以下のような感じで表現する規約を作りました.! ルールは簡単.! のようにかけるだけです.左側が横(行),右側が縦(列)というわけですね(漢字中の二本線 がそのまま掛ける方向になっています!).実際計算してみるとちゃんと最初の連立方程 式になっていることが分かると思います.この表記法はとても便利なので左側の4つの数 字の並びをこれから行列と言う事にします.そして,この表記法は実は見やすいという他 にもう一つの大きな利益を生み出しています.それは連立方程式の解を以下のように表記 できるということです.! ここで行列について! という表記法法を導入すると,!
ax + by = X
cx + dy = Y
x =
ad bc1(dX
bY )
y =
ad bc1(aY
cX)
a
b
c
d
x
y
=
X
Y
x
y
=
1
ad
bc
d
b
c
a
X
Y
A =
a
b
c
d
ときれいな形で書く事ができます.さらに! という表記方法を導入すると! と書く事ができます.こうして見るとちょうど! のような関係になっているのが分かるでしょうか?実際AとA-1を掛けてみると! 何やらきれいな形になりました.ここで出てきた行列を! とすると,Eは面白い性質を持っている事がわかります.たとえばAとEのかけ算を考えま す.すると!
A
x
y
=
X
Y
A
1=
1
ad
bc
d
b
c
a
x
y
= A
1X
Y
p = q
p =
1q
AA
1=
a
b
c
d
1
ad
bc
d
b
c
a
=
1
ad
bc
ad
bc
ab
ab
cd
cd
ad
bc
=
1 0
0 1
E =
1 0
0 1
となります.任意の行列にEを掛けても答えは元の行列になるというわけですね.つま り,行列Eは行列の世界における単位元(普通のかけ算での”1”のようなもの)であると言え ます.そのためEは単位行列と呼ぶことにします.またAに対してかけ算するとEになるA-1 のような行列をAの逆行列と言います.以上のように取り決めると,A-1さえ求める事がで きてしまえば結局冒頭の連立方程式は! のような式変形で解くことができてしまう,ということが分かります.逆にこのようにう まく連立方程式が解けるように定義した計算ルールや表記方法が行列である,とも言える でしょう.!
!
行列の基本! ここでいったん行列の基本用語についてまとめておきます.!!
1. 単位行列E! 行列計算における単位元.特にN次元の単位行列であることを強調するときは右下にn をつける事もあります.また人によってI(あい)や1(いち)で表記しています.!!
AE =
a
b
c
d
1 0
0 1
=
a
b
c
d
A
x
y
=
X
Y
A
1A
x
y
= A
1X
Y
E
x
y
= A
1X
Y
x
y
= A
1X
Y
E
n=
1
O
1
· · ·
O
1
N次元2. 逆行列 A-1!
行列Aに対して!
を満たすような行列XをAの逆行列と言いA-1と表記します.なおこのようなA-1はAに対し てただ一つ定まる事が知られています (ただし次の行列式の所で確認する通り|A|=0の時は 逆行列は存在しません).!
!
3. 行列式 |A|! 以下のような正方行列Aについて! 行列式|A| (det(A)とも書く)は以下のように定義されます.! この表記法を使うと,逆行列A-1は以下のように表す事ができます.! つまりA-1は|A|≠0の時のみ定義可能です.!!
4. 転置行列 At! 例えば以下のように定めた行列Aについて! 次の行列をAの転置行列と言いAtで表します.tは右上に付いたり,左上に付いたり,ある いは大文字になったりしますが,すべて意味は同じです.! !AX = XA = E
A =
a
b
c
d
|A| = ad
bc
A
1=
1
|A|
d
b
c
a
A =
a
b
c
d
e
f
g
h
i
A
t=
a
d
g
b
e
h
c
f
i
5. 対角行列! 以下のように対角線上(左上→右下)にのみ数字が並んだ行列を対角行列といいます.! 後ほど出てきますが,この行列は非常に扱いやすい行列です.そのため,色々手を尽くし てこの形まで変形しようとする訳ですが,残念ながら大抵の行列はこの形にはなりません. しかし,なるべくこの対角行列に近い形まで持っていこうとがんばると少なくともジョル ダン標準形までは持っていけることが知られています.!
!
固有値,固有ベクトル! さて固有値,固有ベクトルです.その定義を考える前に,行列とベクトルを掛ける事の 意味をもう一度考えてみましょう.今,具体的に! という行列Aを考えます.それにベクトルx = (2, 0)tを掛けてみます.! この操作を座標上で眺めてみます! !A =
a 0 0
0 b 0
0 0 c
A =
6 3
1 8
Ax =
6 3
1 8
2
0
=
12
2
Fig.15-行列の”可視化”まず,普通の座標系(つまり単位ベクトルが(1,0)と(0,1))の座標上に(2,0)と(12,0)の点を それぞれプロットしてみますと,これはベクトルx(2,0)に行列Aを掛けた結果,新たなベク トルx’(12,2)に移動したと解釈する事ができます.一方でまた別の見方もできます.それは 以下のように定義されるpとqを考えたときに (x-y=0とx+3y=0に由来,なぜこれを考えた のか?というのは後で分かります)! これらを単位ベクトルとする座標系で,ベクトルxをそれぞれp方向に5倍,q方向に9倍拡 大したとする解釈です.一見めんどくさそうな解釈ですが,こうすると面白い事が分かり ます.例えばx+3y=0上の点(3,-1)に行列Aを掛けたらどうなるでしょう?! 見事にまたx+3y=0上に乗ってきました.しかもq方向に5倍されています.同様にいくつか 確かめていただければ分かりますが,x+3y=0とx-y=0上の点ならばいつでも同じ結果を得 る事ができます.これを式の形で書くと以下のようになるでしょう.! ここでxはx+3y=0上あるいはx-y=0上のベクトル,λはベクトル方向に応じた倍率(5もしく は9)を意味する定数です.すなわち適切に選んだ定数λとベクトルxのセットに関しては, 行列Aを掛けるという操作は単なるベクトルの定数倍になるのです.この面白い性質はあ らかじめ与えられていたpとqという新たな座標系を元に導きだしたものでしたが,逆に考 える事もできます.すなわちpとqが分からない状態からでも,上記の式を満たすような定 数λとベクトルxの組を見つけることができれば,それはpとqを自力で求めたという事にな るのです!実際に計算してみましょう.まず,右辺を左辺へ移行して! を得ます.当然,ベクトルの答えとしてx=0が浮上してくるのですが,我々にとってそれ は意味のある答えではありません.そこでx≠0となる条件を考えます.! 例えば今,X=(A-λE)に対する逆行列X-1が存在していたとします.そうすると先程の式は!
p =
1
2
(1, 1)
q =
1
10
(3, 1)
A
3
1
=
6 3
1 8
3
1
=
15
5
Ax = x
(A
E)x = 0
となってしまいました.つまりx≠0であるためにはX-1は存在してはいけない事になりま す.従ってその条件は行列式を使って以下のように表す事ができます.! 計算してλを求めてみますと,! ! 求められたλを使って,それぞれに対応するxを求める事もできます.x=(x1,x2)として,ま ずλ=5の場合,! ! 同様にλ=9の場合,!
Xx = 0
X
1Xx = 0
x = 0
|A
E
| = 0
6 3
1 8
1 0
0 1
= 0
6
3
1
8
= 0
(6
)(8
)
3 = 0
(
5)(
9) = 0
= 5, 9
6
5
3
1
8
5
x = 0
1 3
1 3
x = 0
x
1+ 3x
2= 0
! これらはまさに行列Aによって与えられる新たな座標系と倍率に他なりません.そしてこ れはまたFig.15で確認した通り,一般のベクトルに対する行列Aによる影響をうまく説明 できる定数とベクトルだということでもありました.そこで今回求めたようなλには行列 Aの固有値,それに対応するxには行列Aの固有ベクトルという名前がつけられ,様々な場 面で重用されています.!
!
一例として,Fig.15の操作を3ステップに分けて考えてみます.すると!!
1. 単位ベクトルp,qの座標系に移動する! 2. それぞれの単位ベクトルの方向へ定数倍する! 3.(1,0),(0,1)が単位ベクトルの元の座標系に戻る!!
になりますが,それは固有値と固有ベクトルを用いる事で以下のような分かりやすい式で 表す事ができます.! !!
この意味するところは単純です.!!
1. 固有ベクトルを使ってp,qの座標系に移動して,! 2. 固有値を使ってそれぞれの単位ベクトルの方向へ定数倍して! 3. 1の逆行列(今回はたまたま1と同じ)を使って元の座標系に戻る!!
これだけです.実際に右辺と左辺の行列も一致していますね.行列をベクトルに掛けると いう操作はここまで分解して考える事ができるのです.“固有値と固有ベクトルは行列の特 徴を抜き取ったものであり,それらを使えば行列による作用をより分かりやすく扱いやす い形で表記する事ができる”,ということを今一度確認してください. 3.元に戻る 2.定数倍 1.新座標へ移動6
9
3
1
8
9
x = 0
3
3
1
1
x = 0
x
1x
2= 0
Ax =
1
4
1
3
1
1
9 0
0 5
1
1
3
1
x
② グラフと類似度行列! 繰り返しになりますが,スペクトラルクラスタリングの本質はグラフの分割問題です. そこでグラフ理論の初歩をここでマスターしておきましょう.特に類似度グラフを理解す る事がメインの目標となります.!
!
グラフ理論入門! 最初に教科書の文言を引用しながら,あえて小難しくグラフを定義しておきます.しか し,言っている事は簡単ですので安心してください.! ! 1.グラフ! 空でない集合Vとその二点集合からなる集合E,つまり! を組にしたG=(V,E)をグラフと言います.またVの元をノード(note, 頂点),Eの元をエッジ (edge, 辺)と呼ぶ事にします.Fig.16はグラフの例ですが,これを見れば上の式の意味は容 易に理解できると思います.つまりVは頂点(○)の集合,Eは頂点と頂点を結ぶ辺(-)の集合 で,それを組み合わせたものをグラフと呼ぶ,と言っているだけです.!!
2.隣接! Vの二点x,yが{x,y}∈Eを満たすときxとyは隣接していると言いx~yと表記します.ようす るに,xとyが一本の線で繋がっていることをグラフ理論の業界では隣接すると言う,とい うだけの話です.!!
3.次数! グラフG=(V,E)の頂点x∈Eについて,! を頂点xの次数と呼びます.一つの頂点からでている辺の数をdegという関数で表す,とい うことです.例えばFig.16のグラフは全部の頂点についてその次数が3となっています.! Fig.16-ピータースングラフ(3-正則グラフ).E
{{x, y} ; x, y
V, x = y
}
deg
G(x) = |{y V ; y
x
}|
二つのグラフG=(V,E)とG’=(V’,E’)について,全単射f: V→V’で! を満たすものが存在するとき,二つのグラフG=(V,E)とG’=(V’,E’)は同形であると言い,! と表します.またfを同形写像といいます.Fig.16はまさに同形なグラフの例でピータース ングラフという名前がついています.見た目は大きく違いますが,各頂点についてつなが り方が同一なのが確認できると思います.ちなみにピータースングラフは先にも述べた通 り全ての頂点で次数が3になっている事から,3-正則グラフでもあります.!
!
なお,全単射については簡単なイメージを以下に載せておきます.!!
! あるグラフが全単射で他のグラフへ写像した時にその二つが同形であればそれ以後の計 算結果は同値である,ということは当たり前のようですが重要な事実です.なぜなら複雑 でそのままでは解析困難な研究対象も,同形関係を保ちつつうまく抽象化する事でその情 報をグラフに落とし込む事ができれば,あとは数学の問題として淡々と解く事ができるか らです.そうすることで例えば,交通工学,SNS,生態系,遺伝子相互作用といった現実 社会の問題を数学の問題として扱うことができるのです.!!
!
x
y
f (x)
f (y)
g
= g
Fig.17-写像の種類.5.隣接行列! グラフG=(V,E)について! で定義される行列A=(axy)をグラフG=(V,E)の隣接行列といいます.これは具体的に考えた 方が分かりやすいので,例えば以下のようなグラフG1=(V1,E1)を考えましょう.ただし V1={1,2,3,4,5,6},E2={{1,2},{1,3},{1,4},{2,3},{3,5},{4,5},{4,6},{5,6}}です.! ! このとき,グラフG1の隣接行列A1は! となります(自分自身とは隣接はしていないので対角成分は0).このように隣接の有無を 行列で表現する事でグラフの特徴がよく見えてきます.例えばここで6次元のワンズベク トルe6とA1を掛け合わせるとどうなるでしょうか?!
a
xy=
1 if x
0 if x
y
y
Fig.18-グラフG1.A
1=
0 1 1 1 0 0
1 0 1 0 0 0
1 1 0 0 1 0
1 0 0 0 1 1
0 0 1 1 0 1
0 0 0 1 1 0
A
1e
6=
0 1 1 1 0 0
1 0 1 0 0 0
1 1 0 0 1 0
1 0 0 0 1 1
0 0 1 1 0 1
0 0 0 1 1 0
1
1
1
1
1
1
=
3
2
3
3
3
2
これは,それぞれの頂点からでている辺の数を意味するベクトルと解釈する事ができます ね.ではA1の二乗はどうなるでしょうか?! これはすなわち,ある二つの頂点について”二歩”で到達できるような道順パターンの数を 意味する行列になっています.例えば二歩で到達できないところはちゃんと0になってい ます.同様にA1の3乗, 4乗...はそれぞれ3歩, 4歩...で到達できる道順パターンということに なりそうです.このようにして具体的に演算をしてみるとA1の意味がよく理解できるので はないでしょうか.!
!
6.有向グラフ! さて,ここまでの話で前提としてきたグラフは全て無向グラフと呼ばれるものでした. つまり辺に関して重み(あるいは長さ)や方向といったものはなく,単に頂点の隣接関係の みを意味していたという事です.しかし当然,辺に方向や重みを与えたグラフも定義する 事ができ,そうしてできたグラフをそれぞれ有向グラフ,重み付きグラフと言います.こ こでは有向グラフについて述べ,続くセクションで重み付きグラフについて述べます.!!
まず先程と同じような感じで有向グラフG2=(V2,E2)を定義します.V2={1,2,3,4,5,6}, E2={{1,3}, {2,1}, {3,2}, {4,1}, {4,5}, {4,6}, {5,3}, {5,6}}です.ただし,G1と違って今度はE2の 中カッコの中の順番には意味があります.例えば{1,3}は1から3へはたどれる一方で,3か ら1へはたどれない事を意味しています.これを図で表現すると以下のようになるでしょ う.!A
21=
0 1 1 1 0 0
1 0 1 0 0 0
1 1 0 0 1 0
1 0 0 0 1 1
0 0 1 1 0 1
0 0 0 1 1 0
0 1 1 1 0 0
1 0 1 0 0 0
1 1 0 0 1 0
1 0 0 0 1 1
0 0 1 1 0 1
0 0 0 1 1 0
=
3 1 1 0 2 1
1 2 1 1 1 0
1 1 3 2 0 1
0 1 2 3 1 1
2 1 0 1 3 1
1 0 1 1 1 2
! このようなG2の隣接行列A2は! とアシンメトリーな行列で表す事ができます.ここで先程と同様にまずワンズベクトルを 掛けてみると! これは頂点から出て行く辺の数ですね.また転置行列に掛けてみると! Fig.19-有向グラフG2.
A
2=
0 0 1 0 0 0
1 0 0 0 0 0
0 1 0 0 0 0
1 0 0 0 1 1
0 0 1 0 0 1
0 0 0 0 0 0
A
2e
6=
0 0 1 0 0 0
1 0 0 0 0 0
0 1 0 0 0 0
1 0 0 0 1 1
0 0 1 0 0 1
0 0 0 0 0 0
1
1
1
1
1
1
=
1
1
1
3
2
0
A
t2e
6=
0 1 0 1 0 0
0 0 1 0 0 0
1 0 0 0 1 0
0 0 0 0 0 0
0 0 0 1 0 0
0 0 0 1 1 0
1
1
1
1
1
1
=
2
1
2
0
1
2
G1の時と同じように二歩で到達できる道順パターンが出てきましたが,有向グラフを考え ている分,なにやら先程よりさらに”実用性”がupした気がしませんか?もしこの結果に運 命を感じてしまったなら代謝解析などに進まれると良いかもしれません :-)!
!
7. 重み付きグラフ,類似度行列! 最後に重み付きグラフG3=(V3,E3)について考えます.V3={1,2,3,4,5,6}, E3={{1,2},{1,3},{1,4},{2,3},{3,5},{4,5},{4,6},{5,6}}です.ただし,以下の図のように辺にはそ れぞれ重みが与えられているとします.! ! 数学的にはこの数字は単に数字でしかないのですが,例えば交通工学と組み合わせればそ れは距離や乗り換え時間を意味するでしょうし,SNSでは例えば友好度など,遺伝子解析 では発現相関や系統プロファイルといった指標とリンクさせることができます.ここで先 程の”同形”という考え方が生きてくるわけですね.!!
A
22=
0 0 1 0 0 0
1 0 0 0 0 0
0 1 0 0 0 0
1 0 0 0 1 1
0 0 1 0 0 1
0 0 0 0 0 0
0 0 1 0 0 0
1 0 0 0 0 0
0 1 0 0 0 0
1 0 0 0 1 1
0 0 1 0 0 1
0 0 0 0 0 0
=
0 1 0 0 0 0
0 0 1 0 0 0
0 0 0 0 0 0
1 0 2 0 0 1
0 1 0 0 0 0
0 0 0 0 0 0
Fig.20-重み付きグラフG3.さて,このグラフG3の隣接行列はA1を同じになることは自明ですが,そこに重みを付 加したA3という行列を作ってみるとどうなるでしょうか.ただし,ここでは自分自身への 重みは1.0とします.すると! となります.これはまさにクラスタリングの世界で類似度行列と呼ばれるものです.今は 無向グラフについて重み付けをしてみましたが,有向グラフについても同じように類似度 行列を作る事ができます.!