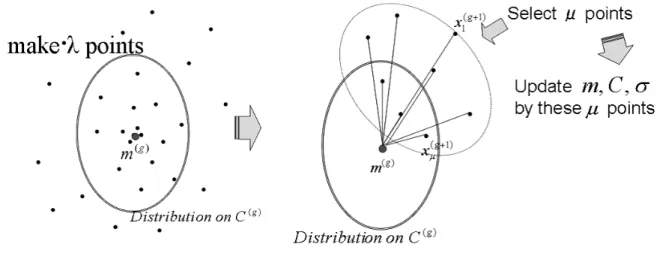
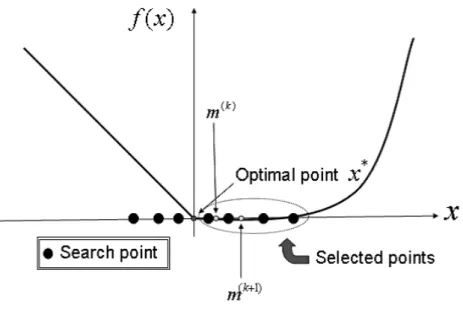
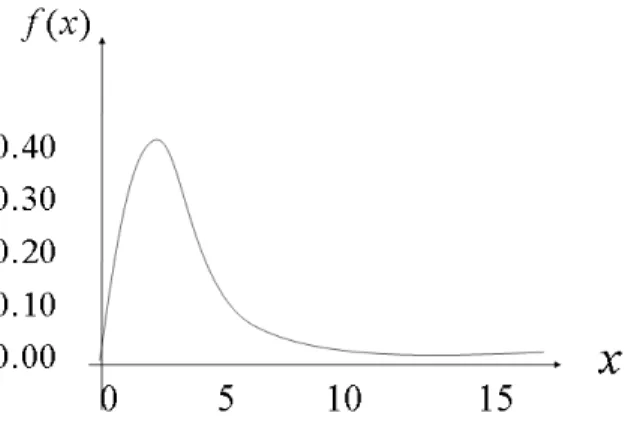
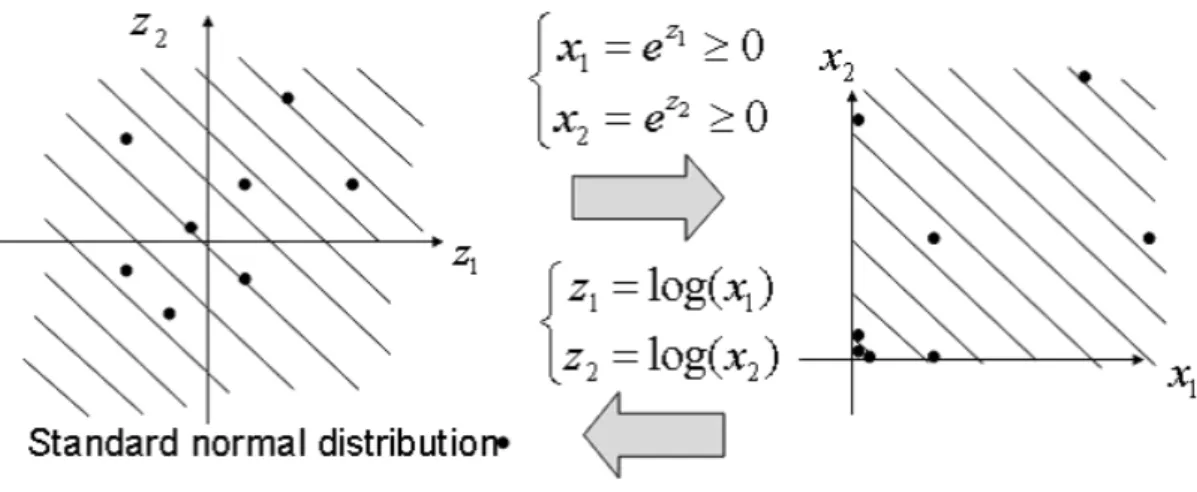
関連したドキュメント
10 This value corresponds to 19.385 which is the average number of daily trades over the period November 2006 through May 2008 (Bannouh et al.. estimated covariance matrix is not
The fusion method proposed in this paper comprises a fusion transformation called alge- braic fusion and a strategy called improvement which is useful for refining and reasoning
It is a new contribution to the Mathematical Theory of Contact Mechanics, MTCM, which has seen considerable progress, especially since the beginning of this century, in
In particular separability criteria based on the Bloch representation, covariance matrix, normal form and entanglement witness, lower bounds, subadditivity property of concurrence
Table 5 presents comparison of power loss, annual cost of UPQC, number of under voltage buses, and number of over current lines before and after installation using DE algorithm in
13 proposed a hybrid multiobjective evolutionary algorithm HMOEA that incorporates various heuristics for local exploitation in the evolutionary search and the concept of
By incorporating the chemotherapy into a previous model describing the interaction of the im- mune system with the human immunodeficiency virus HIV, this paper proposes a novel
5 used an improved version of particle swarm optimization algorithm in order to solve the economic emissions load dispatch problem for a test system of 6 power generators, for