九州大学学術情報リポジトリ
Kyushu University Institutional Repository
実世界シーン認識のためのマルチモーダル視覚に関 する研究
中嶋, 一斗
http://hdl.handle.net/2324/4474891
出版情報:Kyushu University, 2020, 博士(工学), 課程博士 バージョン:
権利関係:
Multimodal Visual Perception for Real-World Scene Parsing
Kazuto Nakashima
A thesis submitted to the Kyushu University
in partial fulfillment of the requirements for the degree of Doctor of Philosophy
Department of Advanced Information Technology,
Graduate School of Information Science and Electrical Engineering, Kyushu University
November 2020
Abstract
Visual perception plays an important role in everyday human activities, which is the ability to process visible lights received on the retina and recognize the struc- ture of the real-world environments. We can thereby avoid dangerous situations or take in-context actions in our daily lives. The functionality of our visual percep- tion is indispensable for real-world applications of autonomous systems, such as safe navigation of self-driving cars and human-robot interaction. Therefore that motivated us to develop a computational visual perception to describe scene im- agery captured by a visual sensor automatically. One of the primary challenges on this topic is to resolve the visual ambiguity of observed data due to its view- point or illuminance. One of the promising approaches to this issue is to exploit the multimodality in scene observation, as human perception relies on not only sight but also multimodal sensory signals from real-world environments.
To this end, this dissertation discusses multimodal methodologies for visual scene understanding and demonstrates novel methods for two tasks: scene clas- sification and caption generation. In particular, proposed methods focus on lever- aging visual multimodality caused in capturing scenes. This dissertation begins by providing a taxonomy of multimodal studies on visual scene understanding in the aspects of data, tasks, and challenges. We discuss how the data can contribute to the tasks and what issues remained on this topic.
The first task is scene classification for outdoor scenes whose illuminance changes dramatically. To capture outdoor scenes stably, LiDAR sensors are widely used in autonomous robots. The core function of LiDAR sensors is to measure omnidirectional distances to be formed as 3D point clouds, while this disserta- tion focuses on the fact that corresponding reflection intensity can be provided for each point and the point clouds can be represented as bijective panoramic maps in 2D. This advantage motivates us to develop the first multimodal method to clas-
i
ii sify outdoor scenes from the panoramic depth and reflectance maps. Experiments compare the multiple architectures and demonstrate the effectiveness of fusing depth and reflectance on the scene classification task.
The second task is to generate a natural language lifelog for human-robot sym- biosis scenes. This dissertation proposes to combine three types of camera views, which involve the first-person point-of-view from the user’s wearable camera, the second-person point-of-view from the service robot, and the third-person point- of-view from the distributed static cameras. This approach assumes that three types of point-of-view have complemental visual modalities to produce accurate and consistent lifelog captions compared to traditional first-person visual lifelog- ging. Experiments demonstrate the effectiveness of this approach, both quantita- tively and qualitatively, using a newly constructed dataset.
Acknowledgements
This dissertation would not have been possible without the guidance and encour- agement of my advisors, collaborators, friends, and family.
First and foremost, I would like to express my sincere gratitude to my doctoral advisor Prof. Ryo Kurazume. Since I joined his lab as an undergraduate, his immense advice and insightful comments helped my activities over the years. I also appreciate the amount of intellectual freedom and opportunities he provided throughout my PhD.
I am deeply grateful to Dr. Yumi Iwashita at Jet Propulsion Laboratory, one of my research advisors. I could not gain wonderful experiences without her con- stant guidance and encouragement. I feel immensely fortunate to be work on many collaborative projects with her.
Besides advisors, I would like to thank my committee members, Prof. Seiichi Uchida and Prof. Atsushi Shimada, for their insightful comments. I am also grate- ful to all collaborators for their valuable discussion and comments. Sincere grat- itude should be addressed to Prof. Ken’ichi Morooka, Assoc. Prof. Tokuo Tsuji, Assistant Prof. Akihiro Kawamura, and Assistant Prof. Shoko Miyauchi, for their guidance and valuable discussion through the lab activities. I am also thankful to Dr. Oscar Martinez Mozos at ¨Orebro University, Prof. Kazunori Umeda at Chuo Univerisity, and Dr. Adrian Stoica at Jet Propulsion Laboratory.
I would also like to thank all of the labmates I met in seven years. I am espe- cially grateful to my colleagues, Akio Shigekane, Daisuke Inada, Yuta Watanabe, Yuta Horikawa, Masato Ushigaki, and Wu Tong, who have been encouraging me with kindness and friendship from past to present. I also thank Naoki Setoguchi, who studied in the same research group, for the countless discussion.
Finally, and most of all, I could not be more grateful to my family for their unconditional supports.
iii
Contents
Abstract i
Acknowledgements iii
Contents iv
List of Figures vii
List of Tables xi
1 Introduction 1
1.1 Background . . . 1
1.1.1 Real-World Scene Parsing . . . 1
1.1.2 Multimodality in Capturing Scenes . . . 4
1.1.3 Learning Tasks from Multimodality . . . 10
1.2 Research Aim . . . 12
1.3 Contributions and Outline . . . 14
2 Scene Classification from Depth and Reflectance Maps 15 2.1 Introduction . . . 15
2.2 Related Work . . . 17
2.3 Approach . . . 19
2.3.1 Data Representation . . . 19
2.3.2 Models . . . 19
2.3.3 Training . . . 25
2.3.4 Data Augmentation . . . 25
2.4 Experiments . . . 25
2.4.1 Dataset . . . 26
2.4.2 Implementation Details . . . 27
iv
Contents v
2.4.3 Quantitative Analysis . . . 27
2.4.4 Qualitative Analysis . . . 32
2.5 Discussions . . . 34
3 Caption Generation from Multi-perspective Images 37 3.1 Introduction . . . 37
3.2 Related Work . . . 41
3.2.1 Visual Lifelogging . . . 41
3.2.2 Image Captioning . . . 42
3.3 Fourth-person Vision . . . 45
3.3.1 First-person Vision . . . 45
3.3.2 Second-person Vision . . . 46
3.3.3 Third-person Vision . . . 46
3.3.4 Fourth-person Vision . . . 46
3.4 Approach . . . 47
3.4.1 Image Encoding . . . 48
3.4.2 Salient Region Clustering . . . 48
3.4.3 Caption Generation . . . 50
3.5 Experiments . . . 52
3.5.1 Dataset . . . 53
3.5.2 Evaluation Metrics . . . 55
3.5.3 Implementation Details . . . 56
3.5.4 Quantitative Analysis . . . 56
3.5.5 Qualitative Analysis . . . 60
3.6 Discussions . . . 65
4 Conclusion and Outlook 66 4.1 Summary . . . 66
4.2 Outlook . . . 68
Appendices 70 A Fourth-Person Captions dataset 71 A.1 Dataset statistics . . . 71
A.2 Annotation Interface . . . 73
A.3 Annotation Examples . . . 73
Contents vi
Bibliography 77
List of Figures
1.1 Levels of scene parsing tasks. The images and caption are from Microsoft COCO dataset [1]. . . 3 1.2 Examples of indoor scene images captured by the first-person cam-
eras. Each image is with object type annotations of the dataset. . . . 5 1.3 An example of a 360◦ depth map from MPO dataset [2] which is
captured by a LiDAR sensor in an outdoor scene. The pixels are colored by a measured distance in grayscale. . . 5 1.4 Examples of multimodal scenarios discussed in this dissertation.
(a) Pixel-level modality: objects are observed as different types of quantities. (b) Content-level modality: different views offer com- prementarity and redundancy at semantic level. . . 7 1.5 Examples of sensory modality. . . 8 1.6 Examples from Charades-Ego dataset [3] which comprises
pair of an exocentric/third-person video (left column) and an egocentric/first-person video (right column) with action label an- notations. . . 10 2.1 Samples from MPO dataset [2]. The panoramic depth/reflectance
images are built by a cylindrical projection of the 3D point clouds.
The panoramic images cover 360◦ horizontal directions. . . 20 2.2 Row-wise max pooling proposed by Shi et al. [4]. The maximum
value (blue) is selected for each row. . . 21 2.3 Horizontal circular convolution. The left and right edges are
padded with values of the opposite sides. The convolution output has the receptive field beyond the edges. . . 23 2.4 Architectures of multimodal models. “FCs” and “Conv” denote
fully-connected layers and convolution layers, respectively. . . 23 2.5 Confusion matrix of best models on a depth and reflectance inputs. 29
vii
List of Figures viii 2.6 Classification robustness to horizontal rotation of an input image.
The models with HCC have less performance fluctuation on im- age rotation. Without HCC, the accuracies on both modalities drop when inputs are rotated by about 90◦ and 270◦ where the front or back views are shifted to discontinuous image edges. . . 31 2.7 Grad-CAM [5] visualization for horizontally rotated data. Grad-
CAM highlights regions that contributes to output. . . 33 2.8 Contributing regions which the models activate to predict correct
classes using Grad-CAM [5]. Coast, Forest, InP, OutP, Res, and Urban denote scene classes of coast area, forest area, indoor park- ing, outdoor parking, residential area, and urban area, respectively.
Each class group shows Grad-CAM maps averaged on the test set, which are obtained from the baseline VGG (top row) and the pro- posed VGG with RWMP and HCC (bottom row). The modification works for sharpening of feature selectivity and equilibration of fea- ture extractability between the center and the side area. . . 35 3.1 The fourth-person perspective in the intelligent space. The “fourth-
person” is a concept of the omniscient perspective which comple- mentary combines the first-, second-, and third-person information acquired in the intelligent space. . . 40 3.2 A concept of lifelogging caption generation in a human–robot sym-
biotic environment. The system is composed of the first-person perspective from a human, the second-person perspective from a service robot, and the third-person perspective from an embedded camera. Fragmental visual concepts are adaptively weighted and processed to predicting each word. . . 41 3.3 Baseline model UpDown [6]. R-CNN detects salient regions, where
each region is encoded to a feature vector. Attn is called the at- tention module, which produces vector ˆvt from the set of region features. Decoderproduces word probabilities pt one by one. ht−1 is the previous state ofDecoder. . . 47
List of Figures ix 3.4 Proposed methods. (a)Ensembleis fundamentally equivalent to the
baselineUpDown[6]. All salient regions intact are subject to the atten- tion module Attn. (b) InKMeans, a clustering algorithm is applied to salient region features and the k centroid features are subject to attend. . . 49 3.5 Details of the attention module and the decoder module ofUpDown
model [6]. . . 50 3.6 An experimental room for data collection. (a) Various pieces of fur-
niture are equipped such as tables, chairs, a bed, a tv, and kitchen fa- cilities. (b) The blue sectors denote the positions of the third-person cameras. . . 54 3.7 Setup of a wearable camera. (a) A wearable camera mounted on
the chest (yellow box). (b) The corresponding first-person image acquired from the camera. . . 55 3.8 CIDEr-D and SPICE scores with different methods of clustering.
The number of clusters kis swept among {4, 8, 16, 32, 64} for each.
Both metrics show the best scores atk=32. . . 60 3.9 CIDEr-D and SPICE scores with temporal batch clustering.
The number of frames to be obtained is investigated among {1, 2, 4, 8, 16, 32, 64}. . . 61 3.10 Example of generated captions. Reference: a selected one out
of five annotations. First: UpDown with the first-person image.
Second: UpDown with the second-person image. Third: UpDownwith the third-person image. Proposed: KMeanswith all the images. . . . 62 3.11 Example of generated captions. Reference: a selected one out
of five annotations. First: UpDown with the first-person image.
Second: UpDown with the second-person image. Third: UpDownwith the third-person image. Proposed: KMeanswith all the images. . . . 63 3.12 Top-down attention maps ofKMeansand Ensemble. Strength of the
attention is color-coded; the yellow region have a large weight, while the blue one have a small weight. The group of regions in column conditions the decoder in generating each word. It can be observed that the proposed methodKMeanscorrectly discriminates instances againstEnsemble. Best viewed in color. . . 64
List of Figures x A.1 Three types of top-20 frequent semantic tuples of the proposed
dataset. Same as in SPICE [7] described in Section 3.5.2, the
“object”-, the “attribute”-, and the “relation”-elements are parsed from a set of reference captions, and they form the three types of tuples lined as the bins. . . 72 A.2 Appearance of the web user interface for annotation. The interface
is composed of the video pane (top), the submission form (middle), and the instruction pane (bottom). . . 74 A.3 Example of collected annotations. Each group shows six frames
from a video for each viewpoint and the corresponding annotations. 75 A.4 Example of collected annotations. Each group shows six frames
from a video for each viewpoint and the corresponding annotations. 76
List of Tables
1.1 Types and examples of multimodal imagery. The areas this disserta- tion focuses on are highlighted in bold and with the corresponding section. . . 13 2.1 Baseline architecture to process 32×384 unimodal image. The
numbers (k,s,p) in the setting column denote that incoming ten- sors are padded with ppixels, and the operation withk×kkernels is applied with the stride ofs. . . . 22 2.2 Data distribution of MPO dataset [2]. Each class has 10 subsets,
where each subset was obtained in a different area. . . 26 2.3 Classification accuracy [%] on unimodal inputs.Coast,Forest,InP,
OutP, Res, andUrbandenote scene classes of coast area, forest area, indoor parking, outdoor parking, residential area, and urban area, respectively. The models with RWMP and/or HCC are proposed in this work. . . 28 2.4 Comparison of unimodal and multimodal models [%]. Coast,
Forest,InP,OutP,Res, andUrbandenote scene classes of coast area, forest area, indoor parking, outdoor parking, residential area, and urban area, respectively. . . 32 3.1 Ablation study of image captioning performance. B-n,R,M,C, andS
denote BLEU-n, ROUGE-L, METEOR, CIDEr-D, and SPICE, respec- tively. The proposed methodKMeans(1,2,3) on the bottom shows best scores on all metrics. . . 58 3.2 The relative improvement rate (%) of triple input vs ablated double
input. For example, the “First-Person” scores are computed from KMeans(1,2,3)and KMeans(2,3). B-n, R,M,C, andS denote BLEU- n, ROUGE-L, METEOR, CIDEr-D, and SPICE, respectively. . . . 58
xi
List of Tables xii 3.3 SPICE subcategory scores. The All scores are same as ones in Ta-
ble 3.1. Obj, Rel, Attr, Color, Count, andSize denote object, rela- tion, attribute, color, count, and size, respectively. . . 59 A.1 Summary of Fourth-Person Captions dataset. . . 71
Introduction 1
1.1 Background
1.1.1 Real-World Scene Parsing
Humans perceive a variety of sensory signals from real-world environments so that we can understand the surrounding states and plan to perform complex day- to-day tasks. According to the old-established concept, the perceived signals de- rive from five primary sensations: touch, taste, hearing, smell, and sight. In par- ticular, the sight, or visual perception, provides detailed and structured scene in- formation to recognize the geometric and semantic structures. For example, even with a quick glance at a single picture, we can say much about textures, shapes, categories, and positions of visible objects. Such an ability to describe real-world scenes through visual information is required for a wide range of industrial appli- cations. Therefore, computational visual recognition has been studied throughout the years as a key issue in computer vision.
In particular, the ability is indispensable for autonomous robots, where the demand for nursing care robots, rescue robots, and self-driving cars has been
1
1.1. Background 2 increasing in recent years. In this field, many international competitions on real-world tasks have been held, such as DARPA Robotics Challenge1, Ama- zon Picking Challenge2, and RoboCup@Home3. In RoboCup@Home, an inter- national competition on personal service robots, the contestants compete using autonomous robots to perform various service tasks in the home environment, such as carrying daily necessities, following humans, and understanding voice instructions. For the robots to move around in the dynamic real-world environ- ment with obstacles and to perform such context-aware actions, the robots need to have the vision system to understand the surrounding states accurately. The acquired information can be used to condition the next action and to mitigate the gap between real-world dynamics and the simulation. To this end, the typical service robots are equipped with various visual sensors. Furthermore, various levels of scene parsing abilities are required, such as what kind of place the robot is or what kind of obstacle are ahead. Therefore, for autonomous robots to be- come commonplace in our daily environment, developing a vision system with hierarchical scene abstraction and accurate performance is one of the essential challenges.
While the vision task to describe real-world scenes is natural and trivial for us, it is difficult for a computer to simulate the function. Here let us argue the issue in classifying objects in an image as an example. The primary issue is the difficulty of representing semantic concepts for diverse real-world scenes. To clas- sify an image, it is required to design a representation of an image feature that is discriminative for the image content. However, even for a single human face, the imagery appearance varies depending on lighting, his/her hair flow, skin defor- mation, the viewpoint of the camera, and so on. Therefore, it is a nontrivial prob- lem to design the image feature even for human faces, and it becomes increasingly harder for multiple objects due to the vast variation. Traditional approaches for this problem were to design hand-crafted features based on primitive visual pat- terns such as image gradients [8] and to learn mapping function/classifiers to get task-specific outputs. Many subsequent studies have successfully improved this approach with the statistical feature encoding [9, 10] and the availability of large scale datasets such as ImageNet [11], while the performance had been leveled off
1https://www.darpa.mil/program/darpa-robotics-challenge
2http://amazonpickingchallenge.org/
3http://www.robocupathome.org/
1.1. Background 3
(a) Image label
“A woman riding on the back of a brown horse.”
(b) Object labels (C) Relations (d) Captions woman
riding horse Scene: forest horse
woman
Figure 1.1: Levels of scene parsing tasks. The images and caption are from Mi- crosoft COCO dataset [1].
due to the strong priors in feature representation. On the other hand, a new learn- ing paradigm has emerged during the last decade by the tremendous progress of techniques on neural networks, which is specifically referred to asdeep learning.
This approach uses multi-layered neural networks with a large set of parameters, which are trained to directly transform raw data into task-specific outputs. In the case of image classification, the typical network receives a 2D array of RGB values and predicts probabilities over the classes. A key aspect of deep learn- ing is to learn how to represent features in an end-to-end data-driven manner, in which the humans’ bias and hypothesis rarely interfere. As a remarkable achieve- ment, the deep learning-based image classification method called AlexNet [12]
overwhelmed the other hand-engineered methods by 10% in the 2012 ImageNet competition4. More recently, it has become possible not just to classify images but also to solve more high-level tasks for real-world scenes, as mentioned below. In other words, with the advent of deep learning, the first addressed issue is being overcome, and the field of real-world scene parsing is stepping towards a more sophisticated level.
This dissertation classifies the typical image understanding tasks into four principle levels in terms of the target attributes: image labels, object labels, re- lations, and captions. Figure 1.1 shows the taxonomy and the examples for each level. From the picture, we can see the woman and the horse in the lush forest.
The woman wears the black jacket, and she is on the back of the horse. The horse is eating green grass on the road. There are various ways to describe this picture.
(a) The most popular task is predicting image label, so-called image classifica-
4http://image-net.org/challenges/LSVRC/2012/results.html
1.1. Background 4 tion. The label is typically selected from defined categories of salient objects [11]
and places/scenes [13, 14]. (b) This category includes a position and label of an object or pixel-wise labels. Relevant tasks are object detection, semantic segmen- tation, and instance segmentation. Those localized labels can be used for collision avoidance, navigation, and object manipulation of autonomous robots. (c) Rela- tion labels include predicates and positional relationships between objects, which are generally represented by scene graphs [15]. A scene graph is a directed graph format where the object token is on the node, and the relation token is on the edge.
Since the scene graph representation was just proposed in 2015, the number of rel- evant studies and datasets is few in comparison to the other levels. (d) Caption is the linguistic integration of objects, relations, and other attributes. The applica- tion mainly covers human-computer interaction or human-robot interaction. For example, the generated captions can be used for a service robot to communicate with a human.
So far, we discussed the first issue in representing diverse scenes, the break- through by deep learning, and the taxonomy for typical scene parsing tasks. Now let us introduce the next issue this dissertation focuses on, the ambiguity of visual information drawn in the image. Figure 1.2 shows examples from indoor scene datasets [16, 17] captured through the first-person point-of-view with a body- mounted camera. First-person point-of-view can provide high-fidelity images of visual experiences and are popularly used to classify the wearer’s daily activi- ties [16]. However, the observable information is limited, and that leads to some ambiguities, such as where the wearer is and what the posture is. Figure 1.3 shows another example of a LiDAR depth map of the outdoor scene [2]. Suppose that we aim to find pedestrians from the map. It can be expected that false candidates are easily raised due to the lack of textural information. How can we reinforce the ob- servations and suppress the ambiguities to describe the scenes? This dissertation tackles this question by incorporating two types of multimodality in capturing the real-world scenes: pixel-level modality and content-level modality.
1.1.2 Multimodality in Capturing Scenes
Human perception includes multiple channels of sensory information such as touch, taste, hearing, smell, and sight. Each of the channels carries unique infor- mation, and the types are generally calledsensory modalities. In our nervous sys-
1.1. Background 5
(a) ADL dataset [16] (b) GETA dataset [17]
Figure 1.2: Examples of indoor scene images captured by the first-person cameras.
Each image is with object type annotations of the dataset.
Figure 1.3: An example of a 360◦ depth map from MPO dataset [2] which is cap- tured by a LiDAR sensor in an outdoor scene. The pixels are colored by a mea- sured distance in grayscale.
tem, their sensory signals are integrated to resolve the ambiguity in recognizing real-world phenomena. For example, we can feel a presence by sounds even if it is too dark to see clearly. We can experience a variety of foods from the multimodal senses of tongue, smell, and sight. Such nervous processing based on multiple sensory signals is calledmultimodal perception. Analogically, multimodal machine learning has emerged and has traditionally been studied, aiming to exploit or re- late multiple types of data to solve the various machine learning problems. The terms, modality and multimodality, have different definitions and scope depend- ing on literature and research fields. Thus this section first clarifies the definition of multimodality in this dissertation and discusses some related studies.
1.1. Background 6 1.1.2.1 Definition of Multimodality
A modality is a certain form of sensing or data representation about the same phenomenon. In general, it is said that different modalities have heterogeneity in two aspects: input feature space and/or data distribution [18]. An input feature space is a form and structure of data representation. For example, web news can be expressed not only with text but also with images. In this case, the image is represented as a 2D RGB array, but the text is represented as a sequence of words.
On the other hand, differences in data distribution mean that the inter-modality correspondence is not unique. In the above example, the text expression of the article is limited, while there are countless patterns of images that match the article content. These two heterogeneities need to be taken into account when designing a method for solving machine learning problems with multimodal data.
Multimodal machine learning has been greatly progressing along with deep learning techniques in recent years. Some of the reasons are that deep neural networks learn hierarchically abstracted features of data, and the features from heterogeneous sources can be expressed as unified format, tensors. As a result of their seamless fusion, numerous new challenges in multimodal machine learning have emerged. Typical problem settings for multimodal learning will be discussed in the next section, following the taxonomy of Baltruˇsaitiset al.[19].
Most of the early studies on multimodal machine learning focused on cross- ing over visual, audio, and language domain. For instance, early studies include audio-visual speech recognition, cross-modal data retrieval, audio-visual emotion recognition, and so on. However, for the purpose of scene parsing, the contribu- tions of audio and language information are small. Although some studies have applied environmental sounds to image understanding, this is a very challenging problem setup and does not allow for detailed analysis of scene attributes. Since language information is not automatically obtained from the sensor, its applica- tion is limited to web articles with pictures.
This dissertation exclusively focuses on modalities in capturing a scene as im- agery data, called visual multimodality. Unlike the other data domain, this ap- proach consistently uses the imagery format as data representation. Thus it is rel- atively easy to deal with the heterogeneity issues associated with multimodality, which are mentioned above. In the following, we further discuss details with two classified groups: pixel-level and content-level modalities. The concept diagram
1.1. Background 7 Modality B
Modality A (a) Pixel-level modality
Egocentric Exocentric
(b) Content-level modality Figure 1.4: Examples of multimodal scenarios discussed in this dissertation. (a) Pixel-level modality: objects are observed as different types of quantities. (b) Content-level modality: different views offer comprementarity and redundancy at semantic level.
is illustrated in Fig. 1.4.
1.1.2.2 Pixel-level Modality
If the modalities are stored in the pixel-aligned common coordinates, as shown in Fig. 1.4a, this dissertation defines this pixel-level modality. For example, an RGB-D camera produces RGB and depth images that their pixels are aligned; we can represent RGB-D data as a multi-channel image. The advantages are that any processing architectures are sharable for all modalities, and we can exploit low- level correspondence patterns. The following introduces some types of pixel-level modality and related studies.
Multi-spectrum The typical cameras are designed to capture the visible spec- trum, while the appearance can be corrupted in the extreme-illuminance environ- ments,e.g. surveillance applications at night scenes. In such a case, infrared (IR) imaging is commonly used to catch the additional modality, i.e., thermal distri- bution. Figure 1.5a shows the RGB-IR examples [20]. For instance, Xuet al.[22]
used RGB-IR correspondence for pedestrian detection robust to illumination con- ditions. Haet al.[20] fused RGB and IR images for semantic segmentation on road scenes. Iwashitaet al.[23] proposed an IR-based auxiliary task for improving ter- rain segmentation on RGB images. Moreover, the RGB-IR images can be used for
1.1. Background 8
(a) RGB (top) and IR (bottom) [20] (b) RGB (left) and depth (right) [21]
(c) Depth (top) and reflectance (bottom) [2]
Figure 1.5: Examples of sensory modality.
robust face recognition [24].
RGB and Depth With the availability of low-cost RGB-D cameras such as Mi- crosoft Kinect in recent years, we can easily measure 2.5D depth distribution that corresponds to RGB pixels on the image. Figure 1.5b shows the RGB-D exam- ples [21]. Depth information reveals the geometry of the image content so that object boundaries can be clear even if the RGB source is deteriorated or blurred.
For instance, Meeset al. [21] integrated predictions from RGB and depth images for a pedestrian detection task. Eitel et al. [25] fused RGB and depth images to predict object categories accurately. Kimet al.[26] used RGB-D images to produce scene graphs. There are numerous studies in the RGB-D setting to reinforce the image-based scene parsing tasks.
Depth and Reflectance Lastly, this section introduces depth-reflectance corre- spondence from LiDAR sensors, which are commonly used in applications of au- tonomous robots. Figure 1.5c shows the depth-reflectance examples [2]. Unlike the RGB-D cameras, LiDAR sensors are designed to measure a depth map with a wide range of direction and distance, which is used as point clouds on 3D carte- sian coordinates. Typical LiDAR sensors measure the distances by time-of-flight
1.1. Background 9 of emitting pulse lasers, and their receptors can know the reflection intensities from measured objects. This additional modality represents the material property, and the resultant reflectance maps can be used as textural information to support the semantic representation of the depth maps. For instance, Wu et al. [27] and Dewanet al.[28] used aligned depth and reflectance maps to improve the perfor- mance of point-wise instance segmentation.
1.1.2.3 Content-level Modality
A content-level modality focuses on semantic contents such as people and objects in the image. Similar to the pixel-level modality, all modalities are represented in the imagery format; however, there is no requirement for pixel alignment as in the pixel-level modality. Basically, the content heterogeneity is caused by viewpoints.
We further discuss three examples of this category.
Biometrics Biometrics is a technique to identify individuals by their body char- acteristics such as the face, iris, fingerprint, and gait silhouette. If multiple sources are used to characterize the subject person, the approach is called multimodal bio- metrics [29]. Each modality catches the different body parts of a single person so that the complementary information can improve the identification performance.
Street View and Aerial Images This type of image pairs is used in remote sens- ing applications. Street view is an image of an outdoor scene taken from a specific point on the ground, while the corresponding aerial view is taken from the satel- lite. For instance, Hoffmanet al.[30] fuses the set of street view and aerial images to predict the building types. Wegneret al. [31] used the set of images to identify the location of public objects.
Point-of-View In this dissertation, the term point-of-view refers to a type of a camera’s viewpoint in human sensing. Moreover, point-of-view can be classified into two types: egocentric and exocentric. Theegocentric or first-person point-of- view can be recorded from a wearable camera typically attached to the head or the chest of a user. The recorded images approximate how the user sees the world in daily life, which is valuable for understanding the user’s activities, attention, and object manipulation history. Therefore, egocentric images have been widely stud-
1.1. Background 10
Figure 1.6: Examples from Charades-Ego dataset [3] which comprises pair of an exocentric/third-person video (left column) and an egocentric/first-person video (right column) with action label annotations.
ied in various computer vision tasks such as activity recognition, hand interaction recognition, social modeling, and visual lifelogging. Theexocentric point-of-view is a more general case where the subject user is shot from an external camera.
It can observe the user’s posture and interactions with the environment, which cannot be captured from the first-person point-of-view. It can be said that most studies on human images such as human pose estimation and pedestrian detec- tion are exocentric vision tasks. Therefore, there are many datasets that can be adapted compared to the egocentric case. The pair of views can be used for ac- tion recognition [3], object co-segmentation [32], re-identification of wearers [33].
Figure 1.6 shows examples of simultaneous image pairs of the egocentric and ex- ocentric point-of-view from Charades-Ego dataset [3].
1.1.3 Learning Tasks from Multimodality
Suppose we have a set of multimodal data, then how we can use them to solve a variety of tasks appropriately? Baltruˇsaitiset al.[19] reported a taxonomy of man- ifold problems in multimodal machine learning. Following the formulation of Baltruˇsaitiset al.[19], this section introduces the general challenges in multimodal machine learning. Their proposed taxonomy includes five principal challenges:
representation, translation, alignment, fusion, and co-learning.
1.1. Background 11 Representation The first challengerepresentationaddresses how to learn the uni- fied representation for the multiple modalities with different structures and noise levels. There are two major types of representation: joint and coordinated. In the joint representation, multiple modalities are projected to the common fea- ture space to exploit the complementarity and redundancy; for example, by using neural networks and Boltzmann machines. In coordinated representation, each modality learns separate feature space, while the features are coordinated based on the similarity. The coordinated representation has advantages in supplemen- tary, where it does not requires a full set of modalities in test time.
Translation The second challenge translation addresses how to translate data into the other modalities. For example, the image captioning task aims to describe the visual characteristics of an image in natural language, which is a visual-to- verbal translation. Most translation tasks are challenging due to the open-ended relationships between modalities, as we discussed in Section 1.1.2.1. In the case of image captioning, there is no unique caption for expressing a given image. This challenge includes example-based methods; however, most of the recent methods and tasks take a generative approach with deep neural networks.
Alignment The third challengealignmentaddresses how to identify the relation- ships between elements from the different modalities, which can be divided into explicit and implicit alignment. The explicit alignment includes dynamic time warping, where the similarity metric between modalities is hard to define in many cases. Recent studies on deep neural networks proposed the attention mechanism, which learns partial alignment between the different modalities based on adap- tive weighting. This category can be classified as implicit alignment.
Fusion The fourth challenge fusion addresses how to join multiple modalities to perform predictions. A large number of recent studies tackle this challenge to improve the existing prediction tasks, motivated by the fact that the different distribution in modality can provide a complementary effect. Model-agnostic ap- proaches can be split into early-fusion, late-fusion, and their hybrid. Ealy-fusion simply integrates modalities on the data level, and the single model is trained.
Late-fusion is decision-level integration based on averaging, voting, or weighing the modality-specific decision. Model-based approaches include deep neural net-
1.2. Research Aim 12 works that concatenate the modalities at hidden layers. The challenge is highly related to the representation challenges for neural networks.
Co-learning Finally, the fifth challengeco-learningaddresses methods of transfer learning between modalities or training with imbalanced labels. Baltruˇsaitis et al.[19] addressed two approaches: parallel data and non-parallel data co-learning.
Parallel data co-learning means the modalities are from the same dataset. Non- parallel data co-learning means each modality is from different datasets while the label space is shared for training. Zero-shot learning is a part of the non-parallel co-learning.
1.2 Research Aim
In order for future robots to adapt to our daily environments and perform real- world tasks, it is indispensable to develop a vision system with hierarchical scene abstraction and accurate performance. To this end, exploiting multimodality as humans naturally perform is one of the promising approaches. In Section 1.1, we discussed (1) principal tasks in real-world scene parsing, (2) taxonomy of visual multimodality in capturing scenes and some related studies, and (3) key chal- lenges on multimodal machine learning. Table 1.1 summarizes the existing tasks and some approaches. This dissertation aims to investigate new methodologies on multimodal scene parsing tasks to move forward in this research area. Partic- ularly, the following two objectives will be discussed:
Scene classification from depth and reflectance maps Scene classification task has actively studied in RGB [13, 14] and RGB-D [34], which aims to describe entry- level scene abstraction. However, these imagery data heavily suffer from illumi- nation conditions in outdoor scenes. Therefore, This work aims to build this func- tion based on depth and reflectance maps from a LiDAR sensor, which is robust to illuminance changes. According to my aforementioned taxonomy, LiDAR data is categorized as pixel-level multimodality, and this multimodal task involvesfusion challenges. This work investigates two aspects: effectiveness of the depth and reflectance maps on the scene classification task and comparison in neural archi- tectures from low-level fusion to decision-level fusion. Furthermore, this work
1.2. Research Aim 13 Table 1.1: Types and examples of multimodal imagery. The areas this dissertation focuses on are highlighted in bold and with the corresponding section.
Scene Parsing Level (Fig. 1.1)
Heterogeneity Examples Image label Object label Relation Caption Pixel-level Multi-spectrum [24] [20]
RGB, Depth [25] [21] [26]
LiDAR data Section 2 [27]
Content-level Biometrics [29]
Street view, aerial [30] [31]
Point-of-view [3] [32] [33] Section 3
also covers to design the operations specialized to the circular nature of LiDAR data.
Caption generation from multi-perspective images Image caption generation is also an active topic in computer vision, while most of the relevant researches focus on inference from a single snapshot image [35, 36, 6]. Considering the application such as text-based lifelogging and verbal expression by surveillance robots, an extension to multimodal inputs is an essential challenge to make ro- bust to the view ambiguity. This work focuses on point-of-view, i.e., egocentric and exocentric, in a human-robot symbiosis environment. In such a situation, the first-person point-of-view images can be recorded through a wearable camera at- tached to the human. In addition, two types of exocentric point-of-view can be defined. One is the second-person point-of-view from the camera mounted on the robot, which can observe the user’s state face-to-face, and the robot is mov- able to adjust the viewpoint. The other is the third-person point-of-view from embedded cameras in the room, which has a wide scope to capture the whole scenes of human-robot interaction while the viewpoint is fixed. This work makes a hypothesis that three types of point-of-view have complemental visual modal- ities to produce accurate and consistent lifelogs in comparison to the traditional egocentric-based approaches. According to my taxonomy, this type of data is cat- egorized as content-level multimodality. This task to bridge multiple images and a sequence of words involves many challenges of multimodal tasks; translation, alignment, and fusion. This work tackles the problems by using salient region- based attention mechanism [6].
1.3. Contributions and Outline 14
1.3 Contributions and Outline
This dissertation focuses on the tasks to analyze real-world scenes by exploiting the multimodal imagery data. In particular, novel methods are developed based on deep neural networks, in the aspects of two aforementioned multimodality cases: LiDAR data and point-of-view. The remainder of this dissertation is struc- tured into two main parts.
In Chapter 2, this dissertation proposes a method of scene classification that utilizes panoramic depth and reflectance data from LiDAR sensors. As discussed in the previous section, 3D data from LiDAR sensors are widely used in robotics applications. Scene classification is among the essential tasks for autonomous robots/cars, where the task aims to classify the LiDAR data into scene categories such as parking, urban, residential area, and so on. The contributions include an empirical study on multimodal architectures to fuse depth and reflectance im- ages and the proposal of a novel model designed for processing a panoramic data structure. The proposed method is evaluated on the large-scale LiDAR dataset.
The results on feature visualization of trained models are also provided.
In Chapter 3, this dissertation formulates the task of generating a natural lan- guage description from multiple lifelogging images captured through three types of point-of-view cameras. First, I introduce the envisioned situation, a human- robot symbiosis scenario where a user and a service robot coexist in the sensor distributed room, generally called intelligent space [37, 38]. Then I address the viewpoint taxonomy in intelligent space and introduce a novel concept of fourth- person vision. This work proposes a novel method that complementarily fuses object-centric visual features from the images to produce consistent captions. The other contribution includes the construction of a novel dataset, which comprises three types of synchronous videos annotated with five captions for each. This dissertation demonstrates the effectiveness of this approach through quantitative and qualitative evaluations.
Finally, Chapter 4 concludes this dissertation and discusses the future direc- tions.
Scene Classification from Depth and 2
Reflectance Maps
2.1 Introduction
Recognizing place categories is one of the essential tasks for autonomous robots and vehicles. Information about place types enables them to make actions adap- tive to places. However, the task is non-trivial due to the dynamic changes and complexity of the real-world scenes. The autonomous systems are required to have a high-level interpretation for observed sensor data to reason about various environments.
This work addresses the problem of place recognition in which an agent needs to determine where it is. In particular, this work focuses on the scene classifi- cation task, which predicts a semantic category of a place. Information about the place improves communication between robots and humans [39]. It also al- lows autonomous robots to make context-based decisions to complete high-level tasks [40, 41]. Moreover, information about place categories can be used to build semantic maps of environments [42] and high-level conceptual representations
15
2.1. Introduction 16 of a space [43]. Finally, an autonomous vehicle that can determine the type of its location can make better context-based decisions [44]. For example, vehicles can automatically lower the speed when driving through residential areas where pedestrian possibly rush out in front of the vehicles.
As the most straightforward approach to determine the place category, geo- graphic information measured using a global navigation satellite system (GNSS) is available. Although robots can have a self-localization function if they install dedicated sensors, a labeled environmental map is required as a retrieval source.
The environmental map should be huge and updated frequently and may cause a temporal and spatial gap between the retrieved information and the real world.
Therefore, the online approach in which the robots autonomously perceive their surroundings by using onboard visual sensors has received a great deal of atten- tion.
In particular, RGB images, visible spectrum data from typical cameras, are commonly used. In the field of scene classification, Zhouet al.proposed a dataset named Places [13] in 2014 and Places2 [14] in 2017 for benchmark evaluation. Both datasets are composed of color scenery images annotated with hundreds of indoor and outdoor place types. Since the amount of the annotated images are large, the datasets are popularly used to train convolutional neural networks (CNNs), a ma- chine learning model with huge parameters. Although the images involve rich textures of the scenes, the appearance depends on the illuminance of the place.
For example, if with ill-lit sunlight during nighttime or rainy weather, it can fail to catch the scene-specific visual attributes. The vast diversity of appearances can also affect the efficiency of learning the classification networks. Therefore, it is essential challenges to exploit the other visual attributes robust to illumination changes.
One approach to overcome the above issues is to fuse with other modalities.
Some researchers [34, 45, 46] have provided sequences of point clouds with col- ors as RGB-D images. The RGB-D image comprises aligned RGB and depth im- ages and can be acquired by low-cost sensors such as Microsoft Kinect and ASUS Xtion. The depth modality can offer supplemental information about the scene geometry. However, the previous studies with the RGB-D sensors have been lim- ited to indoor applications since the depth measurement is affected by sunlight.
For outdoor applications such as self-driving cars, a LiDAR sensor is commonly used today, to measure 3D data with a wide range of distance and to ensure the
2.2. Related Work 17 robustness to illumination changes. As introduced in Section 1.1.2.2, the mea- surement is based on the time-of-flight of emitting pulse lasers, which is less af- fected by ambient lights. Moreover, the scanned data is represented by a bijective map in 2D, not limited to point clouds in 3D, as shown in Fig. 2.1. Most studies and datasets [47, 48] on LiDAR data focused on localization and mapping prob- lems motivated by navigation tasks but not scene classification. Although the KITTI [49] dataset includes four place categories: city, residential, road, and cam- pus, this dataset is commonly used as a benchmark for other purposes: optical flow estimation, visual odometry, 3D object detection, and 3D tracking.
This work introduces a novel method of LiDAR-based scene classification. In particular, this work also uses the reflectance intensity of the pulse lasers, which provides the material property of scanned objects. The main contributions of this work include an empirical study on two topics: multimodal architecture to fuse depth and reflectance data and learnable custom operations for processing LiDAR data. The proposed approaches are demonstrated on the large-scale dataset of outdoor LiDAR scans.
2.2 Related Work
Understanding scenes/places attributes have been studied in computer vision and robotics, and it is now highly motivated because of its application to au- tonomous robots and vehicles.
A visual place recognition task has traditionally been cast as two problems:
instance-level recognition to identify the location where an image is captured or category-level recognition to identify the semantic attribute of a place. The category-level recognition is generally called as scene classification. For in- stance of instance-level recognition, Toriiet al.[50] densely extracted SIFT [8] fea- tures from the query image and retrieves the most similar image from a view- synthesized database. Conversely, our aim is the category-level recognition that targets unknown places and predicts their semantic categories. Related to this viewpoint, Xiaoet al.[51] applied several local and global feature techniques for place images. Fazl-Ersi et al. [52] applied histograms of oriented uniform pat- terns of images in outdoor environments. Alternatively, depth information can be used to categorize places. The work in [53] extracted geometrical features from
2.2. Related Work 18 2D laser scans to categorize indoor places. In addition, 3D depth information has been used to categorize indoor places by using RGB-D sensors [54] and 3D laser scans [55].
A common problem in traditional techniques was how to extract efficient vi- sual features. Recently, convolutional neural networks (CNNs) have gained a great deal of attention as a powerful method to automatically extract the fea- tures in visual recognition tasks. For instance-level recognition using color im- ages, Arandjelovi´cet al.[56] proposed a CNN architecture to recognize place in- stances by treating the problem as an image retrieval task. Gomez-Ojedaet al.[57]
trained a CNN based on the triplet loss calculated from three instances to recog- nize revisited places under significant appearance changes. S ¨underhaufet al.[58]
investigated the performance of a CNN as an image descriptor and its robustness to appearance and viewpoint changes. For category-level recognition, Zhou et al.[13] used a CNN for scene recognition in the Places 205 dataset. Ur˘si˘cet al.[59]
proposed a part-based model of household space categories based on CNNs.
While several methods have used depth images to recognize object cate- gories [60], to estimate object shapes [61], or to detect vehicles for autonomous driving [62], not many works have focused on depth images to solve the scene classification task by using CNNs. Sizikova et al. [63] used generated synthetic 3D data to train a CNN for indoor place recognition; however, they presented this task as an image matching problem at the instance level. For works related to ours, Goeddelet al.[64] transformed 2D laser reading into an image and train CNNs to classify household places such as a room, a corridor, or a doorway. Song et al.[34] proposed the SUN RGB-D indoor scene database and performed scene classification by concatenating color-based and depth-based CNN features. Still, these works have been demonstrated in indoor places due to the sensor charac- teristics.
In contrast, this work aims to predict the scene category from LiDAR data, assuming the outdoor applications. In particular, CNN is used to learn the feature representation of LiDAR data that involves aligned depth and reflectance maps.
2.3. Approach 19
2.3 Approach
A task of this work is to predict the scene class from LiDAR data. In particular, the LiDAR data is represented by a set of depth and reflectance panoramic images.
In general, the classification model is designed to produce a likelihood for each class from a given input, where the model parameters are trained to maximize the likelihood of the correct class. This section introduces the data representation of LiDAR data, unimodal/multimodal models to produce the class probabilities, formulation to train the models, and data augmentation.
2.3.1 Data Representation
In this work, LiDAR data is represented by a set of two aligned panoramic images:
depth and reflectance. Suppose that we have point clouds where each point has the reflectance value. Then all the points are mapped into a 2D plane by cylindri- cal projection around the vertical axis. Samples of generated images are shown in Fig. 2.1. On both depth and reflectance modalities, the obtained 2D maps are scaled by the max limit value of the LiDAR. Note that the LiDAR data has miss- ing points in the areas of the sky and mirrored surfaces where the emitted laser defuses. In this work, the missing points are set to 0.
2.3.2 Models
This section introduces unimodal models to verify the modality-specific perfor- mance and four types of multimodal models that fuse the modalities.
2.3.2.1 Unimodal
The unimodal model is based on one of the popular architecture of convolutional neural networks, VGG proposed by Simonyanet al.[65]. In particular, this work uses VGG-11 described in the paper [65]. The VGG-11 architecture has a stack of 3×3 convolution layers where the numbers of convolution filters from input to output are{64, 128, 256, 256, 512, 512, 512, 512}. All the convolution operations do not change the spatial resolution. When the number of channels is doubled or convoluted twice, the resolution of the outputted feature map is halved with 2×2 max pooling. Outputted feature maps from the convolutions are followed
2.3. Approach 20
(a) Panoramic color image
(b) Panoramicdepthimage
(c) Panoramicreflectanceimage
(d) 3D point clouds
Figure 2.1: Samples from MPO dataset [2]. The panoramic depth/reflectance im- ages are built by a cylindrical projection of the 3D point clouds. The panoramic images cover 360◦ horizontal directions.
2.3. Approach 21
Feature map Output
Width
Height
Max pooling
Figure 2.2: Row-wise max pooling proposed by Shiet al.[4]. The maximum value (blue) is selected for each row.
by three fully-connected layers and a softmax function. All the outputs from the convolution and the fully-connected layers are activated by a rectified linear unit (ReLU) function, except for the final layer. The final output is a categorical dis- tribution p ∈ RK, whereKis the number of defined classes, and each dimension represents a probability of the specific class.
This work prepares a baseline model based on VGG-11 to verify the effective- ness of the proposed architecture. First, the last stack of fully-connected layers is shrunk to be fewer layers and units. The shrinking reduced a large number of training parameters and resulted in fast convergence and higher performance.
Second, batch normalization [66] is applied to the pre-activated outputs from all convolution layers and all fully-connected layers except for the final layer. Ac- cordingly, bias parameters of the normalized layers are removed because the bi- ases are canceled by the subsequent batch normalization. The final architecture of the baseline is shown in Table 2.1. This work empirically verified that the per- formance was not improved even when using the deeper VGG models [65] or skip-connections [67]. Moreover, this work introduces the custom operations that consider the circular nature of panoramic images.
Horizontally-Invariant Pooling The visual concepts on the panoramic images tend to move largely in the horizontal direction due to the yawing motion of the measurement vehicle and the installation angle of LiDAR. To cope with the varia- tion, this work applies a row-wise max pooling (RWMP) layer proposed by Shiet al.[4] to feature maps before the first fully-connected layer (fc1in Table 2.1). As depicted in Fig. 2.2, the RWMP outputs the maximum value for each row of the input feature map, which makes the CNNs invariant to horizontal translation.
2.3. Approach 22 Table 2.1: Baseline architecture to process 32×384 unimodal image. The numbers (k,s,p) in the setting column denote that incoming tensors are padded with p pixels, and the operation withk×kkernels is applied with the stride ofs.
Name Layer type Setting Parameters Output shape
conv1 Convolution (3, 1, 1) 64 kernels 64×32×384
pool1 Max pooling (2, 2, 0) 64×16×192
conv2 Convolution (3, 1, 1) 128 kernels 128×16×192
pool2 Max pooling (2, 2, 0) 128×8×96
conv3 1 Convolution (3, 1, 1) 256 kernels 256×8×96 conv3 2 Convolution (3, 1, 1) 256 kernels 256×8×96
pool3 Max pooling (2, 2, 0) 256×4×48
conv4 1 Convolution (3, 1, 1) 512 kernels 512×4×48 conv4 2 Convolution (3, 1, 1) 512 kernels 512×4×48
pool4 Max pooling (2, 2, 0) 512×2×24
conv5 1 Convolution (3, 1, 1) 512 kernels 512×2×24 conv5 2 Convolution (3, 1, 1) 512 kernels 512×2×24
pool5 Max pooling (2, 2, 0) 512×1×12
fc1 Fully-connected 128 units 128
fc2 Fully-connected 6 units 6
Softmax 6
Circular Convolution on the 2D Plane The depth and reflectance panoramic images have continuity between the left and right edges, while standard convo- lution only extracts features from local regions limited by image boundaries. To extract the features while retaining the circular structure, this work introduces the operation to circulate the convolution kernels horizontally, called horizontal circular convolution (HCC). In a standard convolution layer, a zero-padding op- eration is commonly used to keep the resolution of feature maps, which fills the periphery of an incoming tensor with zero. In contrast, the HCC layer pads the left and right edges with values of the opposite sides and follows by the normal convolution without padding, as shown in Fig. 2.3. This operation is equivalent to circulate the kernels over the edges. All convolution layers of the baseline model are replaced with the HCC layer.
2.3. Approach 23
Feature map
Width
Height
Padding
Output
0 0 0 0 0
0 0
0 0 0 0 0
0 0
Conv3×3
Figure 2.3: Horizontal circular convolution. The left and right edges are padded with values of the opposite sides. The convolution output has the receptive field beyond the edges.
Conv FCs Softmax
Conv FCs Softmax
x0.5 x0.5
Softmax Average Reflectance Depth
Adaptive Fusion
Reflectance Depth
Gating Network
Conv FCs Softmax
Conv
Late Fusion Reflectance Depth
Conv FCs Softmax
Early Fusion Conv
FCs Softmax
Conv FCs Softmax
Figure 2.4: Architectures of multimodal models. “FCs” and “Conv” denote fully- connected layers and convolution layers, respectively.
2.3.2.2 Multimodal
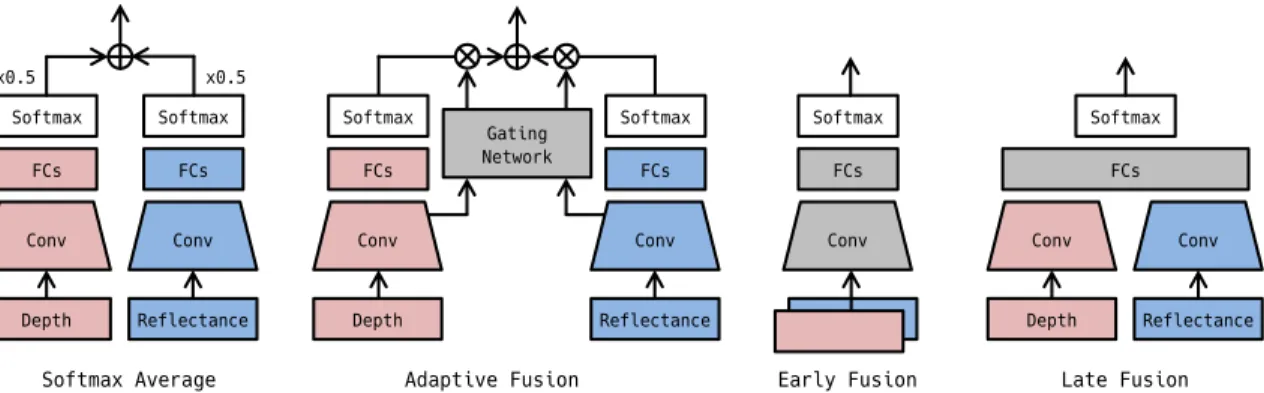
Multimodal models receive both a depth image and the corresponding reflectance image as input. This section herein introduces four types of multimodal architec- tures for fusing both modalities as depicted in Fig. 2.4.
Softmax Average This model is a type of decision-level fusion. The visual fea- tures of the depth map and the reflectance map are learned separately on the different models. In this work, each model is selected in terms of performance for the unimodal case. At inference time, each of the unimodal models predicts probabilities of K classes. Let pd and pr be the probabilities from the depth and the reflectance models, respectively. The final result p ∈ RK is determined by a category-wise averaged score p= (pd+pr)/2.
Adaptive Fusion The Adaptive Fusion model adaptively weighs the modality- specific predictions by adopting an additionalgating network g(·), which estimates
2.3. Approach 24 the certainties from intermediate activations of both modalities. This approach was originally proposed by Meeset al.[21] for a pedestrian detection task. Let the intermediate activation maps of the depth and the reflectance models berdandrr, respectively. In this work, thepool5feature map in Table 2.1 is used as the input to the gating network. Each model is selected in the same fashion as Softmax Average. At the training phase, each unimodal model is pre-trained separately and fixed, and then only the gating network is trained. The final result p ∈ RKis determined by weighted averaging as follows:
(wd,wr) = g(rd,rr) (2.1) p=w| {z }dpd
Depth
+ w|{z}rpr
Re f lectance
, (2.2)
wherewd andwr are the certainties estimated from the gating network g(·), and pdand prare probabilities from the depth and the reflectance models. The gating network is composed of two stacked fully-connected layers and softmax. Similar to the main part, the first fully-connected layer is followed by batch normalization, ReLU activation.
Early Fusion The Early Fusion model takes two-channel input that is a sim- ple stack of the modalities. Local co-occurrence features can be learned on the pixel level since the information of both modalities is merged at the first convo- lution layer of the unified network. Except for the number of input channels, the layer structure is the same as the unimodal baseline. All parameters of the input through the output are trained end-to-end.
Late Fusion The Late Fusion model has separate convolutional streams for each modality and shared fully-connected layers to output a final categorical distribu- tion. For both modalities, spatial features are learned separately while the global co-occurrence is learned in the shared part. Up to the last convolution layers, the architectures are the same as in the unimodal cases. At the training, to avoid the vanishing gradient problem, the model first copies the parameters of convolu- tion layers from the pre-trained unimodal models and then fine-tunes the entire model, including randomly initialized fully-connected layers.
2.4. Experiments 25
2.3.3 Training
Let p = (p1, . . . ,pK) be a categorical distribution of K classes that any model predicts from a given input. The elementpirepresents a probability of classi. To train the model, we have the corresponding labely = (y1, . . . ,yK), which is a K- dimensional one-hot vector where the element of the correct class is 1, otherwise 0. To solve theK-class classification problem, the model is trained to minimize the following cross-entropy loss:
L=−
∑
Ki=1
yilogpi. (2.3)
To update the model parameters, this work employs stochastic gradient de- scent (SGD). In SGD, we first accumulate the loss in Equation 2.3 for a mini-batch of N images. Then, the gradient of the total loss is computed with respect to all the parameters by backpropagation.
2.3.4 Data Augmentation
This work augments the training data by applying two types of random transfor- mations to the original image set. First, the input image is horizontally flipped with a probability of 50%. Second, a random circular shift in the horizontal direc- tion is performed on the image; this is equivalent to rotating panoramic images in the yawing direction. The number of shifted pixels is randomly selected from zero to the image width.
2.4 Experiments
The experiments are composed of two parts,unimodalandmultimodal. In the uni- modal experiment, either the depth map or the reflectance map is given to the proposed models described in Section 2.3.2.1. Subsequently, this work conducts the multimodal experiment with the models described in Section 2.3.2.2 by using the unimodal results.
![Figure 1.1: Levels of scene parsing tasks. The images and caption are from Mi- Mi-crosoft COCO dataset [1].](https://thumb-ap.123doks.com/thumbv2/123deta/9785973.1869213/17.918.143.780.137.345/figure-levels-scene-parsing-images-caption-crosoft-dataset.webp)


![Figure 1.6: Examples from Charades-Ego dataset [3] which comprises pair of an exocentric/third-person video (left column) and an egocentric/first-person video (right column) with action label annotations.](https://thumb-ap.123doks.com/thumbv2/123deta/9785973.1869213/24.918.148.780.149.395/figure-examples-charades-dataset-comprises-exocentric-egocentric-annotations.webp)
![Figure 2.1: Samples from MPO dataset [2]. The panoramic depth/reflectance im- im-ages are built by a cylindrical projection of the 3D point clouds](https://thumb-ap.123doks.com/thumbv2/123deta/9785973.1869213/34.918.133.788.113.929/figure-samples-dataset-panoramic-reflectance-cylindrical-projection-clouds.webp)
![Figure 2.2: Row-wise max pooling proposed by Shi et al. [4]. The maximum value (blue) is selected for each row.](https://thumb-ap.123doks.com/thumbv2/123deta/9785973.1869213/35.918.315.611.146.266/figure-row-wise-pooling-proposed-maximum-value-selected.webp)


![Figure 2.7: Grad-CAM [5] visualization for horizontally rotated data. Grad-CAM highlights regions that contributes to output.](https://thumb-ap.123doks.com/thumbv2/123deta/9785973.1869213/47.918.136.785.248.901/figure-visualization-horizontally-rotated-highlights-regions-contributes-output.webp)
