Oracle Database 10g High Availability
オラクル・ホワイト・ペーパー
Oracle Database 10g High Availability
概要
企業では、その情報技術(IT)インフラストラクチャを使用して競争力を高め、 生産性を向上させ、より多くの情報をユーザーに提供して、迅速な判断を可能に しています。ただし、これらの長所には、そのインフラストラクチャへの依存度 が高まるという短所も伴います。重要なアプリケーション、サーバーまたはデー タが使用できなくなると、企業全体が危機的状態に陥りかねません。そうなると、 収益や顧客を失い、不利益が発生し、悪評による顧客の印象や企業イメージが長 期的にダメージを受けるおそれがあります。現在の変化の激しい経済環境で、企 業が成功し健全な状態を維持するには、可用性の高いIT インフラストラクチャの 構築が不可欠です。 コンピューティング技術における傾向として、グリッド・コンピューティングと 呼ばれる新しいIT アーキテクチャの配置も可能となっています。グリッド・コン ピューティングは、企業のあらゆるコンピューティング・ニーズに応じて、多数 のサーバーとストレージを柔軟なオンデマンド・コンピューティング・リソース に効率よくプーリングする、新しいコンピューティング・アーキテクチャです。 低コストのブレード・サーバー、小型で安価なマルチプロセッサ・サーバー、モ ジュール化されたストレージ技術、およびLinux を始めとするオープン・ソー ス・オペレーティング・システムなどの技術革新が、グリッドの原動力となって います。企業は、これらの技術を組み合せ、Oracle Database 10g で使用可能なグ リッド技術を活用することで、非常に高品質のサービスをユーザーに提供しなが ら、IT コストを大幅に削減できます。Oracle Database 10g により、パフォーマン ス、スケーラビリティ、セキュリティ、管理性、機能性およびシステム可用性を 犠牲にすることなく、グリッド・エンタープライズ・コンピューティングのコス ト・メリットを享受できます。 このホワイト・ペーパーでは、まず、停止の原因を調べます。次に、Oracle Database 10g の新機能を特に重視しながら、Oracle データベースで使用可能な技 術を検証します。この新機能により、コストの高い停止の回避、および予防でき ない障害からの迅速なリカバリが可能になります。停止の原因
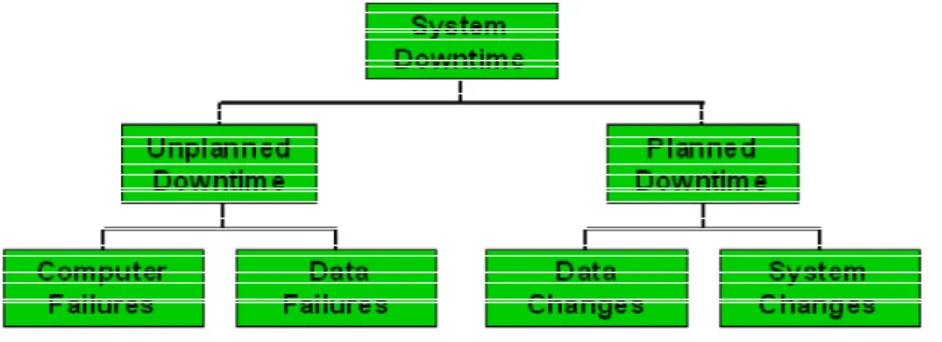
可用性の高いIT グリッド・インフラストラクチャを設計する際の課題のひとつは、 考えられるあらゆる停止原因を調べ解消することです。図1 では、停止を計画外 停止と計画停止の2 つの主なカテゴリに分類しています。フォルト・トレラント でリジリエンスがあるIT インフラストラクチャを設計する際は、計画外停止と計 画停止の両方の要因を考慮する必要があります。図1: 停止の原因 計画外停止は、主にコンピュータ障害またはデータ障害が原因で発生します。計 画停止の理由は、主に本番システムでの実行が必要なデータ変更またはシステム 変更です。次の各項では、これら4 つの停止の理由を調べ、それらの回避に対応 できる技術を検証します。
コンピュータ障害に対する保護
コンピュータ障害は、コンピュータ・システムまたはデータベース・サーバーに 予期しない故障が起こり、サービスが中断される場合に発生します。この原因は 通常、ハードウェアの故障です。この障害に最も有効な対策は、高速データベー ス・クラッシュ・リカバリおよびクラスタ技術です。 図2: コンピュータ障害Real Application Clusters を利用したエンタープライズ・グリッ
ド
企業はReal Application Clusters(RAC)を使用することで、可用性とスケーラビリ ティに優れたデータベース・サーバーを複数のシステム間に構築できます。Real Application Clusters 環境では、Oracle はクラスタ内の複数システム上で動作し、単 一の共有データベースに同時アクセスします。このため、複数のハードウェア・ システムに分散しているにもかかわらず、アプリケーションには単一の統一され たシステムとみなされるデータベース・システムが実現します。このシステムに より、あらゆるアプリケーションの可用性とスケーラビリティが大幅に向上しま す。
• 柔軟かつ低コストの容量計画が可能になり、ニーズに応じて、さらには ビジネス・ニーズの変化に応じて、システムを任意の容量に拡張可能。 • クラスタ内の障害、特にコンピュータ障害に対するフォルト・トレラン
スを実現。
Real Application Clusters により、エンタープライズ・グリッドが可能になります。 エンタープライズ・グリッドは、プロセッサ、サーバー、ネットワーク、ストレ ージなどの標準化された、市販コンポーネントで構成される大規模システムです。 RAC は、これらのコンポーネントを組み合せて、企業に有効な処理システムを構 築できる唯一の技術です。Real Application Clusters およびグリッドは、運用コス トを大幅に削減し、これまでにない柔軟性を実現して、システムに適応性、事前 対応力および高速性を追加します。ノード、ストレージ、CPU、メモリーを動的 に提供することにより、サービス・レベルを単純かつ効率的に維持する一方、使 用率を高めてコストをさらに縮小できます。また、Real Application Clusters は、 RAC データベースにアクセスするアプリケーションには完全に透過的であり、 RAC システム上に配置するための変更が一切不要です。
Real Application Clusters により、ユーザーは容量アップの必要性に応じてノード をクラスタに柔軟に追加できます。また、段階的なシステムの拡張が可能になり、 小規模な単一ノード・システムから大型のシステムに移行が必要ないため、コス ト削減が可能になります。標準低コスト・コンピュータとモジュール式ディス ク・アレイで構成されるグリッド・プールにOracle Database 10g を実装すること により、このソリューションはより強力になります。また、容量の追加も迅速で 容易になります。既存システムをより大型の新しいノードとの交換ではなく、ノ ードをクラスタに追加することでシステムをアップグレードできます。Real Application Clusters に実装されているキャッシュ・フュージョン技術により、ア プリケーションを変更することなく容量をほぼリニアに拡張できます。 このクラスタ・アーキテクチャのもう1 つの重要な特徴は、複数ノードにより実 現するフォルト・トレランスです。物理ノードがそれぞれ独立して実行されるた め、1 つまたは複数のノードで障害が発生しても、クラスタ内の他のノードは影 響を受けません。フェイルオーバーはグリッド上のどのノードでも実行できます。 極端な例をあげると、1 つのノードを除く全ノードが停止しても、Real Application Clusters システムによりデータベース・サービスを提供し続けます。 このアーキテクチャにより、一部のノードを透過的にオンライン化またはメンテ ナンス目的でオフライン化が可能であり、その場合にも、クラスタ内の他のノー ドがデータベース・サービスの提供を継続します。RAC は、Oracle Application Server 10g との統合により、接続プールのフェイルオーバーを実現します。この ため、アプリケーションは障害が発生と同時に通知を受け、TCP タイムアウトが 起こるまで何十分も待つ必要はありません。アプリケーションは、即時に適切な リカバリ処置ができます。そして、グリッド・ロード・バランシングで、ロード が次第に再分散されます。
Oracle Database 10g の Real Application Clusters は、クラスタを管理するための完全 なクラスタウェア・セットも提供します。Oracle データベース・クラスタウェア は、ノード・メンバーシップ、メッセージ・サービス、ロックなど、クラスタの 実行に必要な全機能を提供します。また、このスタックは一般的なイベントおよ び管理API と完全に統合化されているため、Oracle Enterprise Manager から集中管 理できます。クラスタのサポートに追加のソフトウェアを購入する必要はなく、 製品間の調整も軽減され、エラーを回避できます。さらに、Oracle データベース が使用可能なすべてのプラットフォームで、一貫したインタフェースおよび動作 が保証されます。オラクルは、RAC によるサードパーティ製クラスタウェアのサ ポートも継続します。 RAC は、また、「サービス」と呼ばれる新しい抽象概念もサポートします。サー ビスは、データベース・ユーザーまたはアプリケーションのクラスを表します。 ピーク処理時のノードの割当てやサーバー障害の自動処理といったタスクを実行 するために、ビジネス・ポリシーが定義され、これらのサービスに自動的に適用 されます。その結果、システム・リソースが、ビジネス目標の達成に必要とされ る場所およびタイミングで適切に割り当てられます。廉価な汎用コンポーネント を使用したパラレル・ハードウェア・システムは、データ集中型の意思決定支援 アプリケーションにおいて、従来のメインフレーム・システムよりも優れたコス ト・パフォーマンスを実現する場合もあります。 密結合対称マルチプロセッサ・システム(SMP)は、最も広範に使用されてきた パラレル・ハードウェア・システムです。このシステムは、共通メモリーおよび ディスク・リソースを共有するマルチ・プロセッサを利用するため、「シェアー ドエブリシング型」システムとしても知られています。SMP システムの主な特徴 には、アプリケーション開発の簡単さ、容易な管理などもあげられます。ただし、 このシステムには固有のフォルト・トレランス機能がありません。このため、 CPU などのクリティカル・コンポーネントの 1 つで障害が発生すると、システム 全体がダウンする場合があります。さらに、現在、使用可能なシステム・バスの 帯域幅およびオペレーティング・システム・ソフトウェアのスケーラビリティに 制限があるため、スケーラビリティや拡張の面で多少限定されています。
データベース・クラッシュ・リカバリ時間の特定
計画外停止の最も一般的な原因の1 つは、システム障害またはクラッシュです。 システム障害は、ハードウェア障害、電源障害、およびオペレーティング・シス テムまたはサーバーがクラシュします。このような障害が引き起こす運用中断の 規模は、影響を受けるユーザーの数と、サービスを復旧するまでの時間で決まり ます。高可用性システムは、障害発生時に迅速な自動的リカバリを可能にする設 計がされています。重要なシステムのユーザーが、IT 組織に求めているのは、予 測可能な時間内に迅速に障害からリカバリできる保証です。停止時間が保証され た時間を超えた場合、運用に直接影響を及ぼし、収益と生産性の損失につながる おそれがあります。 Oracle データベースは、システム障害およびクラッシュからの非常に高速なリカ バリを可能にします。さらに、高速性と同様に重要なのが、予測可能性です。 Oracle データベースに含まれるファスト・スタート障害リカバリ・テクノロジは、ースの固有の機能です。この機能により、データベースはチェックポイント処理 を自動調整し、目標とされるリカバリ時間を守ります。このため、リカバリ時間 が高速かつ予測可能になり、サービス・レベル目標の達成が容易になります。 Oracle のファスト・スタート・リカバリ機能は、負荷の高いデータベースのリカ バリ時間を、数十分から10 秒未満に短縮します。
データ障害に対する保護
データ障害は、重要な企業データの損失、損傷または破損を意味します。データ 障害の原因は、コンピュータ障害の原因より複雑で難解であり、ストレージ・ハ ードウェアの障害、人為的エラーまたはサイト障害による場合があります。 図3: データ障害 データ障害に対する保護および障害からのリカバリを可能にするソリューション の設計が重要です。システムまたはネットワーク障害により、データへのアクセ スが不可能になりますが、適切なバックアップまたはリカバリ技術がない場合の データ障害は、リカバリ時間の長期化や、データ損失につながるおそれがありま す。 Oracle Database 10g では、データ保護機能が大幅に拡張されています。このよう な多数の拡張の要因は、データ保護およびリカバリを取り巻く新しい経済環境で す。この20 年間で、ディスク容量は 3 桁増加しました。1980 年代初頭では、 200MB のディスクが最新でしたが、現在の最新ディスクは 200GB であり、この 容量の増加傾向は今後も続きます。500GB または 1TB のディスクも近いうちに入 手可能になるでしょう。この傾向の裏で、ディスク・ストレージの価格は下がり 続けています。ディスク容量の増加に伴い、メガバイト当たりのストレージのコ ストは、現在数円のレベルにまで下落しています。この結果、ディスク・ストレ ージが非常に安くなり、バックアップ・メディアとしてテープよりも安価です。 さらに、ディスクにはオンラインである、すなわち遅延なく常時使用可能である という別の利点もあり、データにランダム・アクセスできます。このような傾向 を受けて、オラクル社はこのような経済的な背景を利用するリカバリ戦略の再考 および再構築を行いました。ディスク・ストレージをOracle で使用可能にするこ とで、バックアップおよびリカバリ時間を数時間から数分へと短縮できます。つ まり、廉価なディスク・ストレージにより、コストの高い停止時間を回避できま す。ストレージ障害に対する保護
企業全体に対してはもちろん、シングル・インスタンス・データベースに対して ストレージをプロビジョニングすることも、複雑になる場合があります。通常、 このプロセスに含まれる作業としては、必要とされる領域の容量予測、最適なレ イアウトの計画(問題箇所を排除するデータ・ファイルやアーカイブ・ファイル などの配置)、論理ボリュームの作成、ファイル・システムの作成、データを保 護しミラー化する方法の定義とセットアップ、そのデータに対するバックアップ およびリカバリ計画の定義と実行、Oracle のインストール、そして最後に、デー タベースの作成です。この後で、パフォーマンスに悪影響を与える問題箇所の特 定や、データ・ファイルの移動による競合の削減といった困難な作業が始まりま す。そして、ディスク・クラッシュが発生したり領域が不足して、ディスクの追 加が必要になり、更新したストレージ構成を再調整するために全ファイルの再移 動が必要となる状況に備えることも考えられます。ただし、このような状況は、Oracle データベースの Automatic Storage Management (ASM)という新機能によって改善されます。ASM は、垂直統合されたファイ ル・システムとボリューム・マネージャをOracle カーネルに直接提供するため、 データベース・ストレージのプロビジョニング作業が大幅に軽減されます。そし て、高可用性が実現し、特別なストレージ製品の購入、インストールおよびメン テナンスが不要になり、データベース・アプリケーションに固有の機能が提供さ れます。ASM は ASM ファイルを使用可能な全ストレージに分散してパフォーマ ンスを最適化し、ミラー化も実行できるため、データ損失に対する保護機能とな ります。ASM は、ディスク全体のミラー化が必要なく、データベース・ファイ ル・レベルで行えるという点で、SAME(Stripe And Mirror Everything)概念を拡張 し、柔軟性を高めています。 ただし、より重要なのは、ASM がデータおよびディスク管理の複雑な作業を取 り除き、ミラー化の設定、ディスクの追加および削除というプロセスを大幅に簡 略化することです。ASM を使用するデータベース管理者は、数百、または大規 模データ・ウェアハウスの場合、数千単位のファイルを管理するかわりに、より 大きい単位のオブジェクトであるディスク・グループを作成して管理します。こ のディスク・グループは、1 つの論理単位として管理される一連のディスクを識 別します。基盤となるデータベース・ファイルの命名と配置が自動化されるため、 データベース管理者の作業時間が短縮され、データベース管理者はベスト・プラ クティスの標準に確実に従うことができます。 ASM に固有のミラー化メカニズムは、ストレージ障害に対する保護として使用 されるオプションです。デフォルトでは、ミラー化は使用可能で、トリプル・ミ ラー化も使用できます。ASM のミラー化では、障害グループを使用することで、 データ保護を強化できます。障害グループとは、その障害を許容できる、共通リ ソース(ディスク・コントローラまたはディスク・アレイ全体)を共有する一連 のディスクです。ASM 障害グループを定義すると、このグループはデータの冗 長コピーを別の障害グループにインテリジェントに配置してデータを使用可能に し、ストレージ・サブシステム内のコンポーネントで障害が発生した場合にデー タを透過的に保護します。ASM はさらに、Hardware Assisted Resilient Data 機能 (「データ破損に対する保護」の項で説明)もサポートし、データを強力に保護し ます。
人為的エラーに対する保護
停止時間の原因に対する様々な調査では、停止時間の最大の単一の原因として、 人為的エラーをあげています。不注意による重要データの削除や、UPDATE 文の 不適切なWHERE 句により、意図した以上の行が更新されるなどの人為的エラー を可能なかぎり防止し、それに対する予防措置が取られない場合は、元に戻す必 要があります。Oracle データベースは、このようなエラーに、管理者がそのエラ ーを迅速に診断してリカバリする使いやすく強力なツールを提供します。また、 エンド・ユーザーが管理者の介入なく問題からリカバリする機能も装備している ため、データベース管理者サポート作業が削減され、損失データや損傷データの リカバリが高速化されます。人為的エラーに対するガード
エラーの防止に最も有効な方法は、ユーザーのアクセス権をそのユーザーの仕事 に必要なデータおよびサービスのみに限定することです。Oracle データベースが 提供する幅広いセキュリティ・ツールを使用すれば、ユーザーを認証し、各自の 仕事に必要な権限のみを管理者がユーザーに付与することで、アプリケーショ ン・データへのユーザー・アクセスを制御できます。また、Oracle データベース のセキュリティ・モデルは、Virtual Private Database 機能を使用してデータ・アク セスを行レベルで制限できる機能を提供し、アクセスの必要がないデータからユ ーザーをさらに分離します。Oracle フラッシュバック機能
許可されたユーザーがミスを犯した場合、そのエラーを修復するツールが必要で す。Oracle Database 10g は、人為的エラーを修復するテクノロジ・ファミリを提 供します。これはフラッシュバックと呼ばれ、データ・リカバリの先進的テクノ ロジです。以前は、データベースの破損が数分で発生したにもかかわらず、その リカバリには数時間かかることがありました。フラッシュバックを使用すること で、エラー発生にかかった時間と同等の時間内でエラーを修復できます。また、 フラッシュバックは非常に使いやすく、単一の短いコマンドを使用してデータベ ース全体をリカバリできるため、複雑な手順は必要ありません。フラッシュバッ クは、人為的エラーを迅速に分析および修復できるSQL インタフェースを提供し ます。顧客オーダーを誤って削除した場合などの部分的な障害には、きめ細かい 分析と修復を行います。また、ある月の全顧客オーダーを削除した場合などの、 より広範囲にわたる障害も短時間で修復し、停止時間の長期化を回避します。フ ラッシュバックはOracle データベース固有の機能であり、行、トランザクション、 表、表領域およびデータベース全体といった、あらゆるレベルでのリカバリをサ ポートします。 フラッシュバック問合せOracle フラッシュバック問合せは、Oracle9i Database で導入された機能であり、 管理者やユーザーによる過去のある時点のデータの問合せを可能にします。この 強力な機能を使用することで、誤って削除または変更された可能性のある損失デ ータを参照し再構築できます。例を示します。
Select * from EMPLOYEE as of ‘2:00 P.M.’ where ... この文は、本日午後2 時時点の EMPLOYEE 表の行を表示します。開発者はこの 機能を使用して、セルフサービス・エラー修復機能をアプリケーションに追加で きるため、エンド・ユーザーは自分のエラーを遅延なく元に戻して修復できるよ うになり、管理者がこのタスクを実行する必要がありません。これは、データベ ースが必要な情報を自動的に保持し、過去のある時点のデータを再構築するため、 フラッシュバック問合せの管理は容易です。 フラッシュバック・バージョン問合せ フラッシュバック・バージョン問合せは、データベースの変更を行レベルで参照 できるようにします。これはSQL の拡張機能であり、指定した時間範囲での、特 定行の異なるバージョンをすべて取得できます。例を示します。
Select * from EMPLOYEE versions between ‘2:00 PM’ and ‘3:00 PM’ where … この文は、本日午後2 時から 3 時までの、異なるトランザクションにより変更さ れる対象行の各バージョンを表示します。この機能で、DBA はデータがいつど のように変更されたかを把握でき、それをユーザー、アプリケーションまたはト ランザクションまでさかのぼってトレースできます。このため、DBA はデータ ベース内の論理的な破損の原因を追跡してそれを解決でき、アプリケーション開 発者は自分のコードをデバッグできます。 フラッシュバック・トランザクション問合せ フラッシュバック・トランザクション問合せにより、データベースに行われた変 更をトランザクション・レベルで参照できます。これは、SQL の拡張機能であり、 トランザクションによる全変更の参照を可能にします。例を示します。
Select * from DBA_TRANSACTION_QUERY where xid = ‘000200030000002D’; この文は、このトランザクションの全変更を表示します。また、これを差し戻す SQL 文も戻されるため、この文を使用して、このトランザクションで行われたす べての行への変更を元に戻すことができます。DBA やアプリケーション開発者 は、このような精密なツールを使用することで、前述の場合と同様に、データベ ースまたはアプリケーション内の論理的な問題を正確に診断して、それを修復で きます。 フラッシュバック・データベース Oracle データベースを過去のある時点の状態に戻す従来の方法では、 Point-in-Time リカバリを使用していました。Point-in-Time リカバリでは、データ ベース全体をバックアップからリストアし、エラーがデータベースに伝播する直 前の状態を修復するため、数時間または数日もかかる場合があります。データベ ースのサイズ増加に伴い、データベース全体の単純なリストアに数時間または数 日かかります。
フラッシュバック・データベースは、Point-in-Time リカバリを新しい方法で実行 する機能です。この機能は、Oracle データベースを過去のある時点の状態に即時 に巻き戻し、論理的なデータ破損またはユーザー・エラーにより発生した問題が ある場合はそれを修復します。フラッシュバック・ログは、古いバージョンの変 更済ブロックを取得するために使用されます。このログは、継続的なバックアッ プまたはストレージ・スナップショットと考えることができます。リカバリが必 要な場合は、フラッシュバック・ログが即時再実行され、エラー前の時点のデー タベースがリストアされます。この際、変更済ブロックのみがリストアされます。 これは非常に高速で、リカバリ時間は数時間から数分に短縮されます。また、使 いやすさの面でも非常に優れています。たとえば、次の単一コマンドを発行する だけで、データベースを午後2 時 5 分の状態にリストアできます。 FLASHBACK DATABASE to ‘2:05 PM’; テープからのリストア、処理のための長い停止時間、複雑なリカバリ作業は必要 ありません。また、データベースを読取り専用でオープンし、その内容を調べる 場合にもフラッシュバックを使用できます。フラッシュバックの対象範囲が必要 以上に広範でありまたは不十分な場合は、FLASHBACK コマンドを再発行し、デ ータベースの損傷前の適切な時点を検出します。フラッシュバックはData Guard とも統合されているため、本番データベースとスタンバイ・データベースを同時 にフラッシュバックが可能です(「Data Guard」の項を参照)。 フラッシュバック・データベースは、データベースに対する「巻戻し」または「元 に戻す」ボタンのように機能します。 フラッシュバック表 フラッシュバック・トランザクション問合せは、データベースの変更をトランザ クション・レベルで参照できるようにします。これは、SQL の拡張機能であり、 トランザクションによる全変更の参照を可能にします。例を示します。
FLASHBACK TABLE orders, order_items TO TIMESTAMP (JUL-07-2003, 02:33:00); このコマンドは、現在時刻と過去の指定したタイムスタンプ間にorders および order_items 表で行われたすべての更新を巻き戻します。フラッシュバック表はこ の操作をオンラインおよびインプレースで実行し、各表の間に参照整合性制約が ある場合はそれを保持します。 フラッシュバック表は、表または一連の関連表に対する「巻戻し」または「元に 戻す」ボタンのように機能します。 フラッシュバック・ドロップ データベース・オブジェクトを誤ってドロップすること、すなわち削除は、一般 的なミスです。「表を削除したとき、テスト・データベースに接続していると思 っていました」という説明は、オラクル社カスタマ・サポート・センターでよく 聞かれます。ユーザーは自分のミスにすぐ気付きますが、すでに手遅れであり、 削除した表とその索引、制約およびトリガーを簡単にリカバリする方法はありま せん。一度削除したオブジェクトは、永久に削除されます。非常に重要な表やそ
の他のオブジェクト(索引、パーティション、クラスタなど)の場合、従来の方 法では、DBA は Point-in-Time リカバリを実行する必要がありました。これには非 常に時間がかかり、直近のトランザクションが失われる場合もあります。 削除のフラッシュバックは、Oracle データベース 10g のオブジェクトを削除する 場合の安全策です。ユーザーが表を削除すると、Oracle がそれをごみ箱に入れま す。ごみ箱内のオブジェクトは、ユーザーがそれを完全に削除するまで、または その表を含む表領域の容量が上限に達するまで、ごみ箱内に残されます。ごみ箱 は、削除されたすべてのオブジェクトが保持される仮想コンテナです。ユーザー はごみ箱を調べ、削除した表とその依存オブジェクトを元の場所に戻すことがで きます。たとえば、employee 表とその全依存オブジェクトは、次のコマンドで元 の場所に戻すことができます。
FLASHBACK TABLE employee BEFORE DROP;
フラッシュバック・ドロップは、表とその依存オブジェクトに対する「元の場所 に戻す」ボタンのように機能します。
SQL ベースの LogMiner™ログ・アナライザ
Oracle のログ・ファイルには、Oracle データベースのアクティビティと履歴に関 する大量の有益な情報が含まれています。ログ・ファイルは、データベースのリ カバリに必要な全データを保持しています。また、データベース内のデータとメ タデータで行われる各変更を記録します。LogMiner は、SQL による REDO ログ・ ファイルの読込み、分析および解析を可能にする完全にリレーショナルなツール です。LogMiner でログ・ファイルを分析すると、データへの変更の追跡または監 査、調整および容量計画用の補足情報の提供、複雑なアプリケーションのデバッ グに必要な重要情報の取得あるいは削除済データのリカバリが可能です。データ破損に対する保護
破損は、I/O スタック内の障害のあるコンポーネントによって引き起こされます。 たとえば、データベースは更新トランザクションの結果として、IO を発行します。 データベースI/O はオペレーティング・システムに渡され IO コードになり、その 後、ファイル・システムから順にボリューム・マネージャ、デバイス・ドライバ、 ホストバス・アダプタ、ストレージ・コントローラ、ディスク・ドライブへと渡 され、最後に書込みが行われます。I/O スタック内のいずれかのコンポーネント に、不具合またはハードウェア障害があると、データ内の一部のビットが反転さ れ、破損データがデータベースに書き込まれる場合があります。データベース制 御情報やユーザー・データが破損することもあり、その場合は、データベースの 機能性や可用性が深刻な打撃を受ける可能性があります。同様に、ディスク障害 もデータベース・ファイルに損害を与え、データベースのリカバリにバックアッ プが必要となる場合があります。Oracle Hardware Assisted Resilient Data(HARD)
Oracle Hardware Assisted Resilient Data(HARD)は、データ破損を未然に防ぐため の包括的なプログラムです。データ破損は、頻繁には発生しないまでも、発生し た場合には、データベースに対し、また結果的には企業の事業全体に壊滅的な被 害をもたらすことがあります。ストレージ・デバイス内にOracle のデータ妥当性 チェック・アルゴリズムを実装することで、Oracle では破損データが永続ストレ ージ上のデータベース・ファイルに書き込まれることを防止します。上位のソフ トウェアから下位のハードウェアまでの、このようなエンド・トゥ・エンドの妥 当性チェックは、オラクル社とストレージ・パートナー各社が提供する独自の機 能です。Oracle が保護情報の妥当性をチェックしてデータベース・ブロックに追 加し、この保護情報の妥当性がストレージ・デバイスによりチェックされます。 HARD はデータベースとストレージ間の I/O パスに破損データが入るのを防止し、 データベース業界でこれまで防止が不可能だった大規模障害を除去します。 RAID は物理的にデータを確実に保護することで、ストレージ業界から幅広い支 持を得ていますが、HARD は物理ビットの保護からビジネス・データの保護へと 進化することで、データ保護を1 つ上のレベルに高めています。
HARD は、Oracle9i Database で初めて導入されましたが、Oracle Database 10g では さらに拡張されています。妥当性チェックの範囲が広がり、データベース・ファ イル、オンライン・ログ、アーカイブ・ログ、バックアップなどのあらゆるファ イル・タイプとブロックが、HARD により保護されます。また、ASM により、 RAW ディスク・デバイスを使用せずに HARD が実現します。HARD は、多数の 主要なストレージ・ベンダーとの協力でサポートされています。
フラッシュ・バックアップおよびリカバリ
企業データのバックアップの代わりは存在しません。複数の障害により、ストレ ージ・サブシステム内でミラー化されているデータまでもが使用不可能になりま す。Oracle では、全データを適切にバックアップし、以前のバックアップからデ ータをリストアし、障害発生直前までにそのデータに対し実行された変更をリカ バリする、オンライン・ツールを提供しています。 大規模なデータベース・システムのバックアップは困難です。大規模なデータベ ースは、多数の異なるディスクに分散された数百のファイルで構成されている場 合があります。重要なファイルのバックアップを怠ると、データベース・バック アップ全体が使用不可能になります。通常、破損したこのようなファイルは、そ れが必要になり初めて検出されます。Recovery Manager(RMAN)は、Oracle デー タベースのバックアップ、リストアおよびリカバリ・プロセスの管理ツールです。 このツールは、バックアップ・ポリシーを作成して保持し、すべてのバックアッ プおよびリカバリ・アクティビティを分類します。バックアップおよびリストア 中に、すべてのデータ・ブロックで破損を分析することで、破損データがバック アップに伝播するのを防止します。さらに重要な点は、Recovery Manager により、 必要な全データ・ファイルがバックアップされるため、データベースを確実にリ カバリできることです。 Recovery Manager は、ユーザーが指定した期間において、データベースのリスト アに必要なファイルを自動的に追跡し続けます。中断された操作の再起動、破損したログ・ファイルの処理、および個々のデータ・ブロックのリストアを自動的 に行う一方で、データベースの残りの部分はオンライン状態で維持されます。 Oracle Database 10g の RMAN は、データベースのバックアップおよびリカバリを 大幅に強化しています。RMAN は、フラッシュ・リカバリ領域への全データのバ ックアップおよびリカバリを自動管理できます。フラッシュ・リカバリ領域は、 統一されたディスク・ベースのストレージであり、Oracle データベース内のすべ てのリカバリ関連ファイルとアクティビティを格納します。前述のとおり、スト レージを取り巻く環境が大きく変わり、テープではなくディスクを使用すると、 より高速のバックアップが可能になります。ただし、データベースのメディア・ リカバリが必要な場合、最も重要な点は、データベースのリカバリ時間を大幅に 短縮するデータ・ファイルのバックアップが存在することです。 Recovery Manager は、フラッシュ・リカバリ領域でリカバリ・ファイルを管理し ます。RMAN はフラッシュ・リカバリ領域で全バックアップを自動的に作成し、 この領域を管理します。アーカイバは、アーカイブ・ログをフラッシュ・リカバ リ領域に書き込み、RMAN は、不要となったバックアップおよびアーカイブ・ロ グを自動的に削除、またはテープに移動します。保存ポリシー(RETENTION POLICY)のリカバリ期間を 7 日に設定している場合、RMAN はデータベースの リカバリに必要な全バックアップを過去7 日分保存します。7 日以上さかのぼっ てリカバリが必要な場合、RMAN はデータをテープからリストアします。 Enterprise Manager は、フラッシュ・バックアップおよびリカバリする完全なイン タフェースを提供し、これにはベスト・プラクティスの実装も含まれます。 増分バックアップは、Oracle8 Database で最初にリリースされて以来、RMAN の 一部となっています。増分バックアップ機能は、前回のバックアップ以降に変更 されたブロックのみをバックアップします。Oracle Database 10g は、ブロック変 更トラッキングの実装により、高速な増分バックアップを可能にします。そして、 データベースの全変更の物理的な場所を追跡します。RMAN は、この変更追跡情 報を自動的に使用して、増分バックアップ中にどのブロックの読込みが必要かを 判断し、そのブロックに直接アクセスしてバックアップします。増分バックアッ プを以前に作成したイメージ・バックアップとマージすると、リカバリ時間を最 小化できます。増分更新バックアップに基づくバックアップ戦略で、メディア・ リカバリに必要な時間を最小限に抑えることが可能です。変更トラッキングを使 用した増分バックアップを、バックアップ戦略の一部として取り入れることで、 日々のバックアップに必要な時間の短縮、ネットワークを経由したバックアップ 時のネットワーク帯域幅の節約、ログに記録されていない変更のデータベースへ のリカバリ、バックアップ・ファイル・ストレージの削減、およびデータベー ス・リカバリ時間の短縮が可能です。 Oracle Database 10g のバックアップおよびリカバリには、次のような画期的な機 能も多数含まれています。 • バックアップの圧縮 • リストアでバックアップの欠落または破損が検出された場合の以前のバ ックアップへの自動フェイルオーバー • 以前のPoint-in-Time リカバリによる自動リカバリ(resetlogs によるリカバ リ)
• リカバリ中の新規ファイルの自動作成 • バックアップまたはリストア時の自動チャネル・フェイルオーバー • 表領域の自動Point-in-Time リカバリ • ミラーの分割を高速化するフルDB「begin backup」コマンド • リカバリ並列性の改善(2~4 倍) • 表領域の名称変更。 • アーカイブ・ログ用のプロキシ(サードパーティ)バックアップ • バックアップの時間枠ベースのスロットリング • クロス・プラットフォームのトランスポータブル表領域
サイト障害に対する保護
データ保護機能は、サイトの処理を不可能にする壊滅的なイベントからサイトを 長期的に保護します。例としては、ファイルの破損、自然災害、停電、通信障害、 さらにはテロなどがあります。Oracle データベースは、本番データベースのロー カルまたはリモート・コピーを作成し保持する、様々なデータ保護ソリューショ ンを提供します。破損または災害の場合、データのユーザーはリモート・データ ベースにアクセスすることで自分のタスクを続行できます。 データ保護の最もシンプルな形式は、データベース・バックアップのオフサイ ト・ストレージです。データ・センターが適正な時間内にサービスを再開できな い場合、バックアップを別のサイトのシステムでリストアでき、ユーザーはこの バックアップ・システムに接続できます。ただし、別のシステムでバックアップ をリストアするには時間がかかり、全部が最新ではない可能性があります。より 迅速なリカバリを可能にし、災害時でさえも継続的なデータベース・サービスを 可能にする機能として、Oracle は Data Guard を提供します。Data Guard
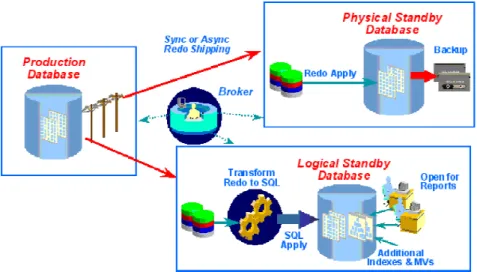
Data Guard は、あらゆる Oracle データベース障害時リカバリ計画の基盤となるも のです。Data Guard により、本番データベースのスタンバイ・コピーをセットア ップおよび保持できます。このスタンバイ・データベースは、本番データベース から見て地球の裏側、または同じデータ・センターに配置することも可能です。 Data Guard には、複雑なタスクを自動化する拡張機能があり、優れた監視、警告 および制御メカニズムを提供します。このため、データベースはデータ・センタ ーの障害に耐えることができます。また、フェイルオーバーが必要な場合にはサ ーバーをスタンバイ・データベースに動的に追加できるため、Data Guard はグリ ッド・クラスタ間で透過的に動作します。
図4: Data Guard のアーキテクチャ
Data Guard Redo Apply
Redo Apply モードの Data Guard は、フィジカル・スタンバイ・データベースと呼 ばれる本番データベースのコピーを保持し、それを本番データベースと常に同期 させます。プライマリ・データベースのREDO データはスタンバイ・データベー スに移され、メディア・リカバリを通じて物理的に適用されます。スタンバイ・ データベースは、プライマリ・データベースと物理的に同一です(ただし、プラ イマリより遅れる場合があります)。また、スタンバイ・データベースは読取り 専用で開くことができるため、報告作業を本番データベースからオフロードする ためにも使用できます。バックアップ処理も本番データベースからオフロードで きます。これは、スタンバイ・データベースで作成されたバックアップを使用し て、本番データベースのリカバリができるためです。 フィジカル・スタンバイ・データベースは、障害やデータ・エラーからの保護機 能として有効です。エラーまたは障害の発生時に、フィジカル・スタンバイ・デ ータベースをオープンして使用することで、データ・サービスをアプリケーショ ンおよびエンド・ユーザーに提供できます。スタンバイ・データベースへの変更 の適用には優れたメディア・リカバリ・メカニズムが使用されているため、スタ ンバイ・データベースは各アプリケーションでサポートされ、最大のトランザク ション・ワークロードにも簡単に効率よく対処できます。
Data Guard SQL Apply
SQL Apply モードの Data Guard は、Oracle のアーカイブ・ログを取得して SQL ト ランザクションに変換し、それをオープン状態のスタンバイ・データベースに適 用します。このスタンバイ・データベースは、ロジカル・スタンバイ・データベ ースと呼ばれ、物理的にはプライマリ・データベースと異なる場合もありますが、 論理的にはプライマリと同一で、プライマリ・データベースが破壊された場合に は、処理を引き継ぐことができます。トランザクションは、SQL を使用してオー プン状態のデータベースに適用されるため、スタンバイ・データベースは他の複 数のタスクに同時に使用でき、本番データベースとは異なる物理構造を持つこと ができます。たとえば、ロジカル・スタンバイ・データベースを意思決定支援に
使用することや、プライマリ・データベースに存在しない追加的な索引およびマ テリアライズド・ビューを使用することで、報告用に最適化が可能です。 Data Guard SQL Apply では、データ保護が最も重要な機能です。SQL Apply モー ドのData Guard は、ログ・ファイル内の変更前の値をロジカル・スタンバイ・デ ータベース内の変更後の値と比較し、論理的な破損に対する確認を行います。こ のようにロジカル・スタンバイ・データベースは、非常に幅広い破損に対する保 護機能を提供します。 ロジカル・スタンバイ・データベースは、リカバリ中に読取り/書込みが可能な ため、REDO ログへの変更が適用されている間も、スタンバイ・データベースの 問合せができます。
データ損失ゼロのログ転送
フィジカルとロジカルの両方のスタンバイ・データベース・コンポーネントで、 同じログ転送サービスを使用します。従来の方法では、アーカイブ・ログは、作 成と同時にプライマリからスタンバイに移されます。Data Guard は、プライマリ からスタンバイ・データベースに直接、REDO ログ更新を同期書込みができます。 このため、データ損失ゼロの包括的な障害時リカバリ・ソリューションが実現し ます。プライマリ・サイトに障害が発生した場合でも、スタンバイ・サイトのア プリケーションは、全トランザクションの保持に必要なすべてのREDO データを 使用できます。 管理者は、REDO データをスタンバイ・サイトに非同期に移すこともできます。 この方法は、データ損失の可能性を最小化しながら、長距離にわたる最適なパフ ォーマンスを提供し、ネットワーク障害からの保護を実現します。リアルタイム適用およびフラッシュバック・データベース
Oracle Database 10g の Data Guard の新機能には、リアルタイム適用機能、および フラッシュバック・データベースとの統合があります。リアルタイム適用機能に より、ログ適用サービスは、REDO データをプライマリ・データベースから受信 すると同時にスタンバイ・データベースに適用できます。現在のログ・ファイル がスタンバイ・データベースでアーカイブされるまで待機する必要はありません。 このため、スタンバイ・データベースをプライマリ・データベースと密接に同期 でき、最新かつリアルタイムの報告が可能です。また、スイッチオーバーやフェ イルオーバーの所要時間も短縮されるため、事業の計画停止や計画外停止を軽減 できます。DBA は、Oracle Database 10g のフラッシュバック・データベース機能 を、プライマリとスタンバイの両方のデータベースで使用する選択をすれば、デ ータベースを過去のある時点の状態に短時間でリストアし、ユーザー・エラーも 排除できます。さらに、スタンバイ・データベースへのフェイルオーバーを選択 した場合に、ユーザー・エラーがスタンバイ・データベースにすでに適用されて いても(リアルタイム適用が有効になっていたため)、管理者はスタンバイ・デ ータベースを過去のある安全な時点に、簡単にフラッシュバックできます。これ ら2 つの機能を使用すると、スタンバイ・データベースを最新の状態に保つか、 本番データベースでの人為的エラーがスタンバイ・データベースに伝播すること を防ぐためにRedo Apply を遅延させるかの選択が必要ありません。
Data Guard Broker
Data Guard には、Data Guard Manager という使いやすい GUI が提供されています。 このGUI は Oracle Enterprise Manager Grid Control の一部です。Data Guard コンポ ーネントの監視、自動化および管理を行うコマンドライン・インタフェースも使 用できます。マウスのシングル・クリックにより、Data Guard Manager は、プラ イマリから2 つのタイプのスタンバイ・データベースのいずれかに処理をフェイ ルオーバーできます。Data Guard Manager を使用すると、DBA はスタンバイ・デ ータベースを簡単に管理および運用できます。フェイルオーバーやスイッチオー バーなどのアクティビティが容易になることで、エラーの可能性が大幅に削減し ます。
計画停止の回避
計画停止であっても、業務が中断されることにかわりません。これは、異なるタ イムゾーンに属するユーザーをサポートするグローバル企業では特に問題となり ます。このような場合、計画的な中断を最小化するシステムの設計が重要です。 計画停止には、日常の操作、定期メンテナンス、新規配置などが含まれます。 日常の操作とは、バックアップ、パフォーマンス管理、ユーザーおよびセキュリ ティ管理、バッチ操作などの日常的なメンテナンス作業を指します。また、パッ チのインストールやシステムの再構成などの定期メンテナンスは、データベース、 アプリケーション、オペレーティング・システム、ミドルウェアまたはネットワ ークの更新に必要です。新規配置としては、ハードウェア、オペレーティング・ システム、データベース、アプリケーション、ミドルウェアまたはネットワーク へのメジャー・アップグレードがあります。アップグレードを実行するタイミン グだけでなく、その変更によるアプリケーション全体への影響も考慮する必要が あります。 インターネットは、データのグローバル共有を容易にしましたが、データ可用性 についての新しい問題と要件も提起しました。世界中のユーザーが1 日 24 時間デ ータにアクセスするため、メンテナンスの時間帯がなくなりました。計画停止に よる業務の中断は、計画外停止による中断と同様に深刻な問題となっています。 ユーザーが影響を受けない時間枠は存在しません。データベースに格納されるデ ータ量が膨大になると、メンテナンス作業に非常に時間がかかります。このよう な作業を、データのユーザーに影響を与えずに行うことが重要です。データ変更の停止時間の回避
図5: データ変更オンライン・スキーマおよびデータ再編成
Oracle データベースでは、データベース運用、またはユーザーによるデータ更新 やデータ・アクセスを中断せずに、多数のメンテナンス作業を実行できます。デ ータベースがオンライン状態で、エンド・ユーザーがデータの読取りまたは更新 を行っている場合でも、索引の追加、再作成または断片化解消が可能です。同様 に、オンライン状態での表の再配置や断片化解消も可能です。表の再定義、表タ イプの変更、列の追加、削除または名前変更、およびストレージ・パラメータの 変更は、基盤となるデータの表示または更新を行っているエンド・ユーザーの操 作を中断せずに実行できます。Oracle Database 10g では、この機能が拡張され、 次の操作が可能です。 • 表の索引、権限付与、制約およびその他の特性の簡単なクローニング • long データ型から LOB データ型へのオンライン変換 • 主キーを必要としない一意索引の使用 Java™および PL/SQL™のストアド・プロシージャの動的更新が可能であり、 Oracle データベースがすべての依存関係を管理するため、新しいプロシージャが データベースに適切に統合され、エンド・ユーザーの操作への影響はありません。 Oracle Database 10g では、この機能が拡張され、様々なタイプの表の変更をその 表と関連付けられているストアド・プロシージャの再コンパイルなしに行うこと ができます。表および索引のパーティション化
データベースが大きくなると、その管理作業が極端に膨大になることがあります。 管理者は、データベース表および索引をパーティション化する機能で、大きい表 を管理の容易な小さい表に分割できます。パーティション化によって、ほとんど の操作やスキーマ変更をオンライン状態に維持しながら、メンテナンス作業を一 度に1 パーティションずつ行うことができます。このため、メンテナンス中に影 響を受けるデータは、最小限ですみます。またパーティションは、パラレル実行 を可能にするため、大半の操作の実行時間が大幅に短縮されます。 パーティションの他の利点としては、障害の伝播防止があります。メディア障害 や破損などの障害は、障害が発生したディスク上のパーティション以外には伝播 されません。影響を受け、リカバリを必要とするのは、そのパーティションのみです。これはリカバリ時間の短縮にはなりませんが、障害が発生したパーティシ ョンのリカバリ中に、他の影響を受けていないパーティションをオンライン状態 に維持できます。 一般に、大きい表の中の全データが、同じアクセス特性を持つわけではありませ ん。通常、保留中のオーダーはクローズされたオーダーよりも頻繁にアクセスさ れ、前四半期の販売実績は3 年前の四半期の販売実績よりも頻繁に分析されます。 パーティション化により、データのインテリジェントなストレージ管理が可能に なります。頻繁にアクセスされるデータは、最速のディスクに格納し、アクセス の集中するデータは、多数のドライブにストライピングできます。
リソースの動的プロビジョニング
Oracle データベースは、動的再構成に対するサポートの拡張を継続しているため、 必要に応じて、サービスを中断せずにハードウェア内の変更に対応できます。 Oracle データベースは、次のようなハードウェア構成への変更を動的にサポート します。 • SMP サーバーとの間のプロセッサの追加/削除 • RAC クラスタ内のノードの追加/削除 • 共有メモリー割当ての動的拡大/縮小、およびメモリーの自動オンライン 調整 • データベース・アクティビティを中断しない、データベース・ディスク のオンライン追加/削除 • データベース・ストレージ全体でのIO ロードの自動再調整 • データ・ファイルのオンライン移動 このような機能により、コスト・ゼロのシステム変更とニーズに応じたプロビジ ョニングが、真に可能になります。これは、エンタープライズ・グリッド・コン ピューティングに対する基本要件です。システム変更の停止時間の回避
図6: システム変更ローリング・パッチ更新
Oracle データベースは、Real Application Clusters(RAC)システムのノードへのパ ッチ適用をローリング(循環)方式でサポートします。この方式を次の図に示し ます。 図7: ローリング・パッチ更新 RAC システムの実行中は、データベース・クライアントにかわって全ノードが、 トランザクションをアクティブに処理します(図7 の左上の RAC システム)。パ ッチ適用の手順1 では、パッチが適用される最初のインスタンスを静止させます (この例ではインスタンス1)。手順 2 では、Oracle パッチ・ツール(opatch)を 使用して、静止中のインスタンスにパッチを適用します(インスタンス1 の Oracle ホームが更新されます)。手順3 では、パッチが適用されたインスタンスが再度 アクティブ化され、クラスタに再結合します。これで、RAC システムは、1 つの インスタンスがクラスタ内の他のノードよりも高いメンテナンス・レベルで実行 されるようになりました。 RAC システムは、このパッチが元の問題を解決し、別の問題を引き起こしていな いことを確認するために、任意の期間にわたってこの複合モードで実行が可能で す。次に、この手順がクラスタ内の残りのノードに対して繰り返されます。クラ スタ内の全ノードにパッチが適用されると、ローリング・パッチ更新が完了し、 全ノードが同じバージョンのOracle データベース・ソフトウェアを実行するよう になります。さらに、opatch にはパッチの適用をロールバックする機能もありま す。この機能では、更新されたインスタンスで異常な動作が見られた場合、クラ スタ全体を停止することなく、問題のパッチをアンインストール、すなわちロー
ルバックできます。ロールバック手順はパッチ適用手順と同じですが、この場合 のopatch は適用されたパッチを削除できます。
ローリング・アップグレード
Oracle Database 10g はデータベース・ソフトウェア・アップグレードのインスト ールおよびパッチセットの適用を、ローリング方式でサポートします。この際、 Data Guard SQL Apply が使用され、データベースの停止はほとんどなくなります。 この方式を次の図に示します。 図8: スタンバイ・データベースの確立 スタンバイ・データベースをインスタンス化し、本番データベースでの変更をス タンバイ・データベースにレプリケートするようData Guard を構成すると、スタ ンバイ・データベースがアップグレードされます。 図9: スタンバイ・データベースのアップグレード この構成は、本番環境のアップグレードの妥当性をチェックするために、任意の 期間にわたってこの複合モードで実行が可能です。チェックが完了すると、アッ プグレードされたソフトウェアは正しく動作し、データベースのロール・リバー サルおよびスイッチオーバーを実行できます。
図10: ロール・リバーサル ロール・リバーサルは、複数の手順で構成されます。たとえば、元のスタンバ イ・データベースを本番データベースに切り替えるData Guard スイッチオーバー、 新しい本番データベースへのデータベース・クライアントの再指定、スタンバ イ・データベースのアップグレード、両方のデータベースの互換性レベルの向上 などです。このプロセス中に数回、アップグレードの妥当性をチェックするため に、構成が複合モードで実行されます。そのタイミングでは、データを損失する ことなくアップグレードを中断し、ソフトウェアをダウングレードできます。ロ ーリング・アップグレード中は、スタンバイ・データベースを障害時リカバリに 使用できます。この手順の間のデータ保護を強化するため、Data Guard 構成で第 2 のスタンバイ・データベースを使用できます。 Oracle ではローリング・アップグレードおよびローリング・パッチ更新をサポー トしているため、DBA が管理タスク用に確保しているメンテナンス時間枠の大 半が不要となり、企業は1 年 365 日にわたり継続的な業務ができます。
Maximum Availability Architecture(MAA)のベスト・プラクテ
ィス
IT インフラストラクチャの実装を成功させる鍵は、運用のベスト・プラクティス です。技術のみでは不十分です。Oracle の Maximum Availability Architecture (MAA)は、可用性の高いシステムを構築する完全に統合された実証済青写真で す。MAA に基づいたシステム・アーキテクチャを持つ企業は、事業のシステム 可用性に対する要件を満たすアプリケーションを、迅速かつ効率的に設計し配置 できます。MAA は、最適なシステム可用性と信頼性を保証するように広範囲に 検討され、テストされた特別な設計と構成の推奨事項を含んでいます。MAA 構 想は、高可用性を実現するためのOracle データベースの主な機能である Real Application Clusters、Data Guard、Recovery Manager、Enterprise Manager などを組 み合せた使用方法を検証して詳述しています。また、サーバー、ストレージ、ネ ットワーキング、アプリケーション・サーバーなど、可用性の高いシステムのそ の他の重要なコンポーネントの構成と統合にも対処しています。このような各機 能がそれぞれ、オラクル社のソリューションの可用性を高めます。これらを完全 に統合し、Maximum Availability Architecture に従い正しく組み合せることにより、 最大可用性を持つシステムが実現し、Unbreakable なソリューションとなりま す。
MAA のベスト・プラクティス・ガイドは現在改訂中であり、Oracle Database 10g ドキュメント・セットの標準ガイドとなる予定です。MAA の詳細は、 http://otn.oracle.com/deploy/availability/htdocs/maa.htm を参照してください。
まとめ
IT インフラストラクチャの主要コンポーネントとなる Oracle データベースは、基 幹業務アプリケーションのデータ・アクセスと可用性を保証する機能およびツー ルを提供します。Oracle Database 10g の重要で画期的な可用性機能により、デー タとデータベースを必要に応じた時と場所で、確実に使用できます。さらに、グ リッド機能により、データベース環境を配置し、変化するビジネス・ニーズに対 応するためのコストを最小限に抑えることができます。Oracle Database 10g High Availability 2004 年 4 月 著書: Ron Weiss Oracle Corporation World Headquarters 500 Oracle Parkway Redwood Shores, CA 94065 U.S.A. 海外からのお問合せ窓口: 電話: +1.650.506.7000 ファックス: +1.650.506.7200 www.oracle.com
Copyright © 2004, Oracle. All rights reserved.
この文書はあくまで参考資料であり、掲載されている情報は予告なしに変更されることがあります。 オラクル社は、本ドキュメントの無謬性を保証しません。また、本ドキュメントは、法律で明示的または暗黙的に記 載されているかどうかに関係なく、商品性または特定の目的に対する適合性に関する暗黙の保証や条件を含む一切の 保証または条件に制約されません。オラクル社は、本書の内容に関していかなる保証もいたしません。また、本書に より、契約上の直接的および間接的義務も発生しません。本書は、事前の書面による承諾を得ることなく、電子的ま たは物理的に、いかなる形式や方法によっても再生または伝送することはできません。