自己符号化器による推薦システムを目的とした
入力値ベクトル補完手法の実験的評価
Experimental Evaluation of Input Vector Complemention for
Autoencoder-based Recommendation Systems
鈴木陽介
尾崎知伸
∗Yosuke Suzuki
Tomonobu Ozaki
日本大学大学院 総合基礎科学研究科
Graduate School of Intergrated Basic Sciences, Nihon University
Abstract: Deep learning attracts much attention in a wide variety of research areas in recent years. In this paper, we consider the application of autencoders, one of the fundamental techniques in deep learning, to recommendation systems. While autoencoders require dense input to learn, only sparse ones can be prepared in recommendation domains in usual. To fill the gap, we propose a series of completion methods of sparse vectors by estimating missing or unrated values. The preliminary experiments by using movielens dataset are conducted to assess the effectiveness of the proposed methods.
1
はじめに
近年,機械学習や人工知能の分野で深層学習への期 待が高まっている.その理由の一つに,元来人間が手 動で設計していた特徴量を深層学習では自動的にうま く抽出できるとされ,データの高次の表現が得られる 点が挙げられる.現在は画像認識や音声認識,自然言 語処理といった分野で盛んに研究されているが,他分 野への応用も広がっている.本研究で取り上げる推薦 システムにおいてもここ数年で深層学習を用いた研究 が増えている. 推薦システムとは大量の情報からユーザの興味や嗜 好に合致した情報を提示するシステムであり,EC サイ ト等で実利用されている.深層学習を用いた推薦シス テムの一つの手法として,自己符号化器の利用が考え られる.自己符号化器とは教師無しの深層学習の一手 法であり,深層学習のプレトレーニングとして利用さ れることが多く,入力データの高次の表現を得ること が経験的に知られている [5].基本的な自己符号化器は 入力層,中間層,出力層と呼ばれる 3 層からなるネッ トワークで構成されており,入力されたデータを一度 圧縮し,圧縮されたデータから元のデータを再現する ように学習を行う.この中間層で得られる圧縮された データが入力データの高次の表現である.また,出力 層では,圧縮されたデータから入力データを再構築す ∗連絡先:日本大学 文理学部 情報科学科 〒 156-8550 東京都世田谷区桜上水 3-25-40 [email protected] るため,元データのノイズや外れ値を除去する効果が 見込める [2]. 自己符号化器を単純に利用した推薦システムとして いくつかの方法が考えられる.例として,ユーザが各 アイテムに対して評価値を付与している嗜好情報を入 力とした自己符号化器を構築した場合を考える.この 自己符号化器は,ユーザの嗜好情報を一度圧縮し,元 に戻すように学習を行うが,複数のユーザに対しても うまく再構築できるように学習を行う.その結果,ある ユーザの嗜好情報を入力すると他のユーザの情報を考 慮した嗜好情報が出力される.この出力自体を推薦す る方法が挙げられる一方,同様の自己符号化器で既存 の推薦アルゴリズムに応用することも可能である.推 薦システムの代表的なアルゴリズムの一つである協調 フィルタリング [7] ではユーザ間 (もしくはアイテム間) の類似度計算が必要であるが,この自己符号化器の中 間層で得られる嗜好情報の高次の表現を用いてユーザ 間 (アイテム間) 類似度を計算することで精度を上げら れる可能性がある. 深層学習を用いた推薦システムの可能性について簡 単に述べたが,画像認識等の分野に比べ,推薦システ ム分野における深層学習の応用は進んでいないのが現 状である.その理由の一つに推薦システムで利用され るデータが極めて疎であることが挙げられる.推薦シ ステムにおいて最も一般的なデータ形式はユーザがど のアイテムを好むかの評価値が付与されているもので あるが,このようなデータから自己符号化器を用いて 人工知能学会研究会資料 SIG-KBS-B504-02ユーザ (もしくはアイテム) の特徴量を抽出をする際に 問題となるのが未評価値である.ユーザは一部のアイ テムにしか評価値をつけておらず,データの大半は未 評価値であることが多いが,基本的な自己符号化器は 欠損値を考慮していないため,何かしらの対処をしな ければならない. 本研究では,深層学習を用いた推薦システムを構築 する際に問題となる未評価値への対応として,未評価 値を他の値で補完する手法を複数提案し,推薦システ ム用データセット MovieLens1M1で評価実験を行った. 本論文では,2 章で未評価値の問題に対処した既存 研究を紹介する.3 章では,自己符号化器の導入と種々 の未評価値補完手法の提案を行う.4 章では,提案手法 の精度評価を行うために MovieLens1M のデータセッ トを用いて,種々の提案手法の比較と既存手法の協調 フィルタリングとの比較を行う.
2
関連研究
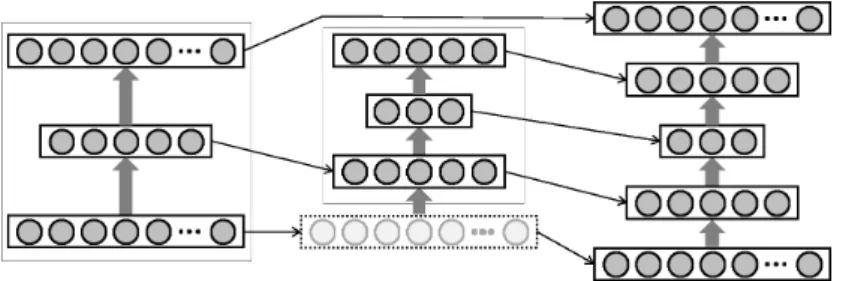
深層学習を用いた推薦システムにおける未評価値の 問題を解決するためにいくつかの手法が提案されてい る.川上ら [8] や田中ら [6] の研究では,欠損値を何か しらの値で補完する手法を提案している.川上らは,未 評価値を 0, 既知の評価値は各アイテムの平均評価値を 引いた値で入力値を更新することで学習を行う.田中 らは評価値の定義域の中央値で補完する方法と各ユー ザの平均値で補完する方法や,さらに,各データのメ タ情報を入力することで精度上昇を図る手法を提案し ている. 一方,未評価値を補完する手法とは別のアプローチ も提案されている.Sedhain ら [3] や Strub ら [4] は, 自己符号化器の学習の際に誤差計算を工夫することで 未評価値に対応している.簡単には,未評価値のアイ テムと対応するユニットの誤差を無視し,評価済みの アイテムと対応するユニットの誤差のみを用いて重み を更新する. データセットの加工法等が異なるため,単純に比較 することはできないが,いずれの研究も MovieLens1M のデータを利用しており,補完を行う手法はどちらも RMSE が約 0.94 であり,誤差計算を工夫する手法のど ちらも約 0.83 であった. 本研究では川上らと田中らの手法を参考に,種々の 補完手法を提案し,それらの推薦精度評価を実験的に 行う. 1http://grouplens.org/datasets/movielens/ 図 1: 提案手法の流れ3
自己符号化器を用いた推薦
3.1
提案手法の概要
本章では,自己符号化器を用いた推薦のための入力 値ベクトルの補完手法を複数提案する. まず,提案手法の簡単な流れを図 1 に示す.未評価値 を含むデータを,提案する各種補完関数 f で補完する. 補完済みデータを正規化した上で,自己符号化器のモ デルを学習する.次に推薦のターゲットとなるユーザ のデータを同様の方法で補完し,正規化した上でモデ ルに入力する.出力された値の中で,評価値の高いア イテムを推薦する.以上が本研究の推薦システムの簡 単な流れである. 次に,本研究で扱うデータ形式を以下に与える.全 ユーザの集合を U ={u1,· · · , um},全アイテムの集合 を I = {i1,· · · , in} と表す.システムにおける評価値 の定義域をR ∈ R ∪ {NA} とする.ここで NA とは未 評価値を表す.評価値を成分とするユーザ-アイテム行 列を R ∈ Rm×nと定義し,このとき,ユーザ u の評 価値ベクトルを ru= (r u,1,· · · , ru,n)∈ Rn,アイテム i の評価値ベクトルを ri = (r 1,i· · · , rm,i)∈ Rmとす る.また,評価値ベクトル ruに対して,レーティング が既知であるアイテムの評価値集合をJ (ru) ={i ∈ I | ru,i ̸= NA} と定義する.さらに,評価値ベクトル ru(ri) に対して,NA を除いた平均を ru(ri) とする.ま た,全てのユーザ U における,評価値ベクトル平均の 平均を rU = 1 |U| ∑ u∈Uru,全てのアイテム I におけ る,評価値ベクトル平均の平均を rI = 1 |I| ∑ i∈Iriと する.3.2
自己符号化器
自己符号化器とは教師無しの深層学習の手法の一つ である.まずは基本となる単層の自己符号化器につい て説明する.あるユーザの評価値ベクトル ruを入力したとき,自己符号化器の出力は h(ru: θ) = f (W· g(V ru+ µ) + b) のように表せる.ここで,f と g は活性化関数と呼ば れる任意の非線形関数であり,V と W は重み,b と µ はバイアス項で,θ ={W , V , b, µ} は重みとバイアス 項をまとめた変数である.自己符号化器の学習は,入 力データ ruに対して誤差関数 E(R, θ) = ∑ u∈U ∥ru− h(ru: θ)∥2 が小さくなるように確率的勾配降下法を用いて θ を更 新していく. 以上の手順を応用すると簡単に多層自己符号化器を 構築できる.図 2 のように,まず単層の自己符号化器 を学習し,その中間層の出力を入力とした単層の自己 符号化器を学習することで多層化することができる. 3.2.1 過学習の緩和 自己符号化器に限らず深層学習では過学習を如何に 避けるかが重要である.そこで過学習を緩和するテク ニックがいくつか知られている. ドロップアウト ドロップアウトとは学習を行う際に確率 p でユ ニットが存在しないかのように学習を行う手法で ある.学習時に一部のユニットの情報を消すこと によってモデルの自由度を意図的に下げ,汎化能 力を向上させる. デノイジング自己符号化器 デノイジング自己符号化器とは,入力データに何 かしらのノイズを加えてモデルに入力し,出力層 の値とノイズを加える前の値で誤差計算を行い, 学習を行う方法である.具体的には,評価値ベク トル ruにノイズを加えたものを ˆruとしたとき, 誤差計算を以下のように変更する. E(R, θ) = ∑ u∈U ∥ru− h(ˆru: θ)∥2 正則化項 正則化とは機械学習で一般的に利用される汎化 手法である.以下のように誤差の計算式に重みの L2 ノルムの項を追加し,その式を最小化するこ とで,極端に重みが大きくなることを防ぎ,汎化 能力の向上を図る. E(R, θ) = ∑ u∈U ∥ru−h(ru: θ)∥2+λ 2·(∥W ∥2+∥V ∥2)
3.3
欠損値補完手法
川上らや田中らは未評価値を各アイテムの平均評価 値や各ユーザの平均評価値などで補完する手法を提案 しているが,他にも多くの補完手法が考えられる.そ こで,本研究では関連研究の手法を参考に基本的な補 完手法を複数提案し,それらの評価・考察を行う. 具体的には,以下の補完関数 f (ru,i) で未評価値 ru,i= NA を別の値で補完する.さらに,補完済みのユーザ-アイテム行列の定義域を,元の定義域が−1 から 1 に なるように正規化する.なお,出力される値も−1 か ら 1 に正規化されているため,評価を行う際には出力 値を元の定義域にスケールして評価を行う. • 平均値で補完する手法 各欠損値を,種々の平均値や 0 で補完する基本的 な手法である. 1. 0 値で補完 f1(ru,i) = 0 2. 全てのレーティングの平均で補完 f2(ru,i) = 1 ∑ u∈U |J (ru)| ∑ u∈U ∑ i∈J (ru) ru,i 3. アイテム毎の平均 f3(ru,i) = ri 4. ユーザ毎の平均 f4(ru,i) = ru • ユーザの傾向を考慮する手法 ユーザやアイテムによって評価値が高く (低く) な りやすいことがある.そこで,単純に平均値だけ で補完するのではなく,平均値にアイテムやユー ザの傾向を追加することで精度が上がると予想さ れる. 5. アイテム毎の平均にユーザバイアスを追加 f5(ru,i) = ri+ (ru− rU) 6. ユーザ毎の平均にアイテムバイアスを追加 f6(ru,i) = ru+ (ri− rI) • 確率的に補完する手法 ユーザやアイテムによって,それぞれの評価値の 付けやすさに差異がある.そこでユーザやアイテ ムの評価値の確率分布で補完を行う.図 2: 多層自己符号化器の学習過程
7. 一様分布
f7(ru,i) = U (a, b)
where
a = min(R\{NA}), b = max(R\{NA})
8. 全てのレーティングに関する確率分布 f8(ru,i) = P (R\{NA} | R) 9. ユーザ毎のレーティング確率分布 f9(ru,i) = P (R\{NA} | ru) 10. アイテム毎のレーティング確率分布 f10(ru,i) = P (R\{NA} | ri) • 既存の推薦アルゴリズム 既存の推薦アルゴリズムであれば,尤もらしい補 完ができると予想される. 11. 協調フィルタリング 一般的な推薦アルゴリズムである協調フィ ルタリング [7] で補完を行う. f11(ru,i) = CF (R, ru)
4
評価実験と考察
4.1
データセット
映画の評価データである MovieLens1M を利用して 種々の補完手法の評価を行った.ユーザ数が 6040 人, アイテム数が約 3400 件,評価値数が約 100 万件である. 評価値は 1 から 5 の 5 段階で付与されており,大きいほ ど高評価である.データの内 80%を学習用データ,残 りの 20%をテストデータとした.学習では学習用デー タの 20%をランダムにフィルタリングし,学習を行う. テストではテストデータの 20%をランダムにフィルタ リングしたデータを入力し,フィルタリングした値と 出力層の値がどれだけ当たるかで評価する.なお,評価 には推薦システムで標準的に利用される RMSE(Root Mean Squared Error) を用いた.作成した自己符号化 器の構成は,中間層の活性化関数は sigmoid 関数,出 力層の活性化関数は恒等写像とした.また,ノイズはガ ウスノイズである.作成した自己符号化器のハイパー パラメタの設定は表 1 の通りである. 表 1: 実験設定 ユニット数 1000, 500, 100 隠れ層数 1, 3, 5 エポック数 5000 バッチサイズ 50 ドロップアウト p = 0.5 ノイズ µ = 0, σ2= 0.001 正則化項 λ = 0.3 学習手法 モメンタム SGD 学習係数 0.2 モメンタム係数 0.34.2
考察
提案した種々の補完手法の評価を行うため,学習済 みの自己符号化器にテストデータを入力し,データ作 成時にフィルタリングした値と出力層の値で RMSE を 算出する. 各補完手法の実験結果を表 2 に示す.なお,表 2 の 最下行は単純に協調フィルタリングで推薦を行った際 の RMSE である.実験結果より,協調フィルタリング で補完する手法が最も精度が良いことが判る.これは, 他の手法に比べ協調フィルタリングが最も尤もらしい 補完ができていると考えられ,ユーザの特徴を学習で きたためと思われる.既存研究においても,協調フィ ルタリングより,未評価値の補完を利用した自己符号 化器による推薦の方が精度が高いことが確認されていたが,本実験においても同様であった.既存研究とは 異なり,既存の推薦アルゴリズムに自己符号化器を適 用することで,既存の推薦アルゴリズムより精度が上 がったことに本研究の意義があると考える.つまり,行 列分解を用いた推薦アルゴリズム [1] のような他の推 薦アルゴリズムに自己符号化器を適用することで精度 が上がる可能性がある. また,ユーザ平均で補完する手法より,アイテム平 均で補完する手法の方が精度が良く,また,ユーザ平 均にアイテムバイアスで補完する手法よりアイテム平 均にユーザバイアスで補完する手法の方が精度が良い. このことから,各ユーザの高評価・低評価の付けやす さよりも各アイテムの人気度の方が重要であることが 判る. 一方,確率的に補完した手法では,各ユーザの評価 値の確率分布で補完した方法が,各アイテムの評価値 の確率分布で補完した手法よりも精度が高い.しかし ながら,確率的に補完をするため,複数回の評価を行 い,統計的に精度を算出する必要性がある. また,多層化による顕著な変化は見られず,5 層にし た場合が最も精度が低くなる手法も多い.多層にした 場合に精度が低下した原因として中間層のユニット数 を 1000-500-100 と段々に少なくしたため再構築が困難 であったことが挙げられる. 表 2: 提案手法毎の RMSE 1 層 3 層 5 層 1000 1000-500 1000-500-100 f1 3.391 3.338 3.315 f2 1.080 1.081 1.081 f3 0.995 0.995 0.995 f4 1.012 1.053 1.078 f5 0.959 0.957 0.973 f6 1.013 1.010 1.033 f7 1.488 1.486 1.486 f8 1.080 1.081 1.081 f9 1.012 1.052 1.078 f10 0.995 0.996 0.996 f11 0.953 0.964 0.986 CF 0.992 次に,推薦システムを実運用する際には,ユーザが好 むアイテムを推薦することが重要である.従って,ユー ザが好むアイテムほど,正しい予測ができることが求 められる.この考え方に従って評価実験を行った.具 体的には,実際のユーザの評価値毎に RMSE を算出し た.実験結果から,総じて低評価値より高評価値での RMSE が低いことが確認できる.また,多くの手法で 評価値 4 の RMSE が最も低いことがわかる.元々の データにおいて,評価値 4 が多く観測されているため 予測が 4 に引っ張られたことが原因と思われる.同様 の理由で,評価値 1 のデータは元々少ないため,予測 が困難であったと考えられる. 表 3: 実評価値毎の RMSE 1 2 3 4 5 f1 0.725 1.657 2.590 3.590 4.382 f2 2.559 1.560 0.587 0.400 1.361 f3 2.067 1.339 0.670 0.556 1.183 f4 2.564 1.619 0.670 0.303 1.237 f5 1.877 1.220 0.644 0.587 1.142 f6 2.256 1.577 0.908 0.455 0.821 f7 1.563 0.592 0.407 1.350 2.285 f8 2.559 1.569 0.587 0.400 1.361 f9 2.563 1.619 0.670 0.304 1.237 f10 2.068 1.339 0.670 0.557 1.183 f11 2.047 1.367 0.730 0.496 1.024 CF 1.826 1.281 0.788 0.613 0.956
5
まとめと今後の課題
本研究では,自己符号化器による推薦システムを目 的とした基本的な入力値ベクトル補完手法を複数提案 し,MovieLens1M のデータセットを用いて評価を行っ た.本研究は,深層学習を用いた推薦システムの初歩 的な取り組みに留まっており,明らかにすべき問題が 多く存在する.まず.深層学習では多くのハイパーパ ラメタがあるが,それらの推薦精度への影響の調査が ある.他にも,今回は既存の推薦アルゴリズムを用い て補完する手法は協調フィルタリングのみであったが, 近年は行列分解を用いた手法が有名であり,最新の手 法の適用が挙げられる.また,中間層の値を利用した 推薦アルゴリズムの提案も課題の一つである.参考文献
[1] Y. Koren, R. Bell, and C. Volinsky. Matrix Fac-torization Techniques for Recommender Systems.
Computer, Vol. 42, No. 8, pp. 30–37, 2009.
[2] Y. Ma, P. Zhang, Y. Cao, and L. Guo. Paral-lel Auto-encoder for Efficient Outlier Detection. In Big Data, 2013 IEEE International Conference
[3] S. Sedhain, A. K. Menon, S. Sanner, and L. Xie. AutoRec: Autoencoders Meet Collaborative Fil-tering. In Proceedings of the 24th International
Conference on World Wide Web, WWW ’15
Com-panion, pp. 111–112. ACM, 2015.
[4] F. Strub and J. Mary. Collaborative Filtering with Stacked Denoising AutoEncoders and Sparse In-puts. In NIPS Workshop on Machine Learning
for eCommerce, 2015. [5] 麻生英樹. 多層ニューラルネットワークによる深層 表現の学習 (<連載解説> deep learning(深層学習) 〔第 2 回〕). 人工知能学会誌, Vol. 28, No. 4, pp. 649–659, 2013. [6] 田中恒平, 小林亜樹. 深層学習を用いた情報推薦の ための欠損値補完手法. 第 8 回データ工学と情報マ ネジメントに関するフォーラム, 2016. [7] 神嶌敏弘. 推薦システムのアルゴリズム (2). 人工 知能学会誌, Vol. 23, No. 1, pp. 89–103, 2008. [8] 川上和也, 松尾豊. Deep collaborative filtering deep
learning 技術の推薦システムへの応用. 人工知能学 会全国大会論文集, Vol. 28, pp. 1–4, 2014.