Spoken Inquiry Discrimination Using Bag-of-Words for Speech-Oriented Guidance System
4
0
0
全文
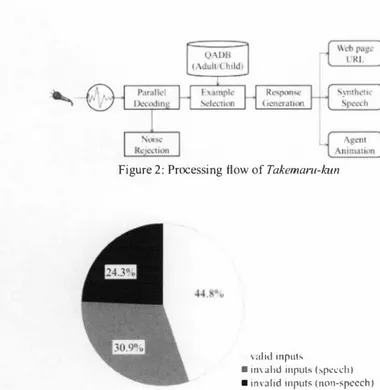
(2) 3.. Discrimination using multiple features. Here we describe the proposed method using multiple features of BOW, Gl\仏11ikelih∞d values, duration and SNR 3.1. Features. The following features are used for invalid input discrirnination A11 features are modeled and calculated using on1y ASR results. Figure 2: Processing flow of. Takernanl-/':un. A BOW vector consists of frequencies of each word in a vocabulary word list which is comprised of the lO-best ASR candidates of training da阻 ηle dimension of BOW veclor is deterrnined by the number of words in the word 1ist. 44.80/0. 、alid inpu臼 • invalid inpul;, (話pccch) • invalid inputs (non-spccch). Figure 3・Delail of inputs to the system (Nov. 2002 to Oct. 2004). Duration is出e duration of an u社町ance, deterrnined by voice activity detection of Julius [6] using amplitude and zero crossmg. Npa一 九 二 円、dP 一 nu 句A. SNR is the s明lal-to-noise ratio of an utterance. We divide an input wave into合ames and then consider lhe lop 10%仕ames having larger power in av町age as signal and the bottom 10% frames having smaller power in av町百ge as noise, conveniently SNR is calculat吋by. σb o nU 4i 一 一 R N pa. 台om a large number of users. When a user u社町s an inquiry, the system responds with synthesized voice, an agent animation, and displays information or Web pages at the monilor in the back, if required. The system structure is illustrated in Figure 2. Speech!Noise discrirnination using lhe likelih∞ds of GMMs is execuled in parallel with ASR. In this process, the system can only rejecl noise inputs, which are part of unintended inputs. However thぽE are many more of them, such as∞nversation between users and utterances of fillers or nonsense words, as we discussed before. We define these unintended inputs as invalid inputs. A11 inputs 10 the system have been collected from the start of operation. The dala of the first two years were manually transcribed with lags ∞ncerning the invalid inpuls mention巴d above and labels about age-group and gender. ηle tags and labels are given by hearing of four trained labelers. These dala W町e used to construcl lhe GMMs and to adapt acoustic models and language m吋els used in the daily operalion. The real users' inpuls to the system contain 55.2% of invalid inputs, as shown inFigure 3. A11 inpuls 10 the system are broadly divided into valid and invalid inputs. Valid inputs include child's and aduIt's valid speech. lnvalid inputs include ∞ugh, laughter and noises, which are non-speech, and olher invalid utteram沼s. The noises made of speech are narrowly divided into six classes, including ∞nversation between users, fuzzy speech, nonsense utterance, mistake in voice activity detection (VAD), overflow and powerless utterances. They are difficult to be discrirninaled as invalid inputs by only using the likelih∞d values of GMMs, which have no inforrnation of lhe meaning of the ulterance. Therefore we employ BO羽/ as a classi fication feature.. GMM Iikelihood is given as the likelihood values of each utterance to six Gl\仏1s ηle GMMs are trained using six kinds of data for adult's valid sp田ch, child's valid speech, laughter, cough, noise and other invalid utterances, respectively. The speech dala is recorded through the system operation in a real environment. When the likelihood values of G孔仏1"s for laughter, cough, noise and olher invalid utterances are high, the i叩ut should be rejectedぉan invalid input. Table 1 lists the training condi tions for Gl\仏1s.. where Ps is the average power of signal and PN is that of noise.. ・aー- - _ . ・ 一 ・ ・ ー 一 ,一 ーーー ー ー. adult utterances child utt町ances laughter ∞ugh Invalid n01se mputs invalid other utter百nces 16 kHz/l6 bit 25 msec / 10 msec Valid. inputs. Amount of training data. SamplingJquantization Width/shift length of window function Feature Mixed number. 1053 6554 287 29 3318 3640. MFCC (12 dimension), Ll MFCC 128. 3.2. Discrimination methods. We used the features described above for the classification, employing SVM and ME as classifiぽS.
(3) 3.2.1. SVM-based method. 4. Experiments. Support vector machine (SVM) is a useful machine for data. c1assification. It is basically a supervised leaming binary. [4].. 1(1:. c1assifier. When甘aining vectors Xj CRn, i=l , ...,. number of. examples)加d their corresponding classes yjε{I , ーI} are given, the SVM estimates a separating hyper-plane with a maximal margin in a higher dimensional space. The soft margin notation, which permi包the existence of incorrectly classified data, is also In甘oduced using a slack variable. mil} w);;�. �WTW + C+ 2. � j and C parameters as. =. 4.1. Speech database Table 2 illuslrates the speech database used in the experiments. The one-month data of Aug. 2003 were used as training data, and. çj. 4.2. Experimental conditions. yj=ー1. Subject to Yi (wTφ(Xj)+b);:>:lーも. もさO,i. GMM Iikelihood, duration and SNR, evaluation experiments. were ∞nducted using real user's utterances. Oct. 2003 as test da(a. )' も + C_ ムd ). ムd. yj=l. To elucidate the effect of BOW and other features, which are. The experimental conditions on feature ex!raction are illus凶ted. 1,…,1.. in Table 3.ηJe acoustic model (AM) and the language model. C+・∞st parameter for positive examples. (LM) were separately prepared for adults and children. The AMs. C: cost parameter for negative examples.. were trained using The 1apanese Newspaper Article Sentence. In addition, C is divided into parameters C and C, as we. kun. The LMs w町E∞nstructed using the manual transcription of. handle unbalanced data, which have large amount of valid ut低rances but small amount of invalid ( ( 1 ) to (3)). The value of C is set a posteriori. (1). m1mber of examp!es in (Yj=一1) c!. x. Tota! numbeγof exαmples beγof examples in (Yj= 1) c!ass. =. the user's speech to Takemaru-kun. Morphological analyzer Chasen is used to split the transcriptio目白ta into words.. In the following experiments, 10-best ASR candidates were. c = c+十C_ + -. datab蹴(1ト�AS) and adapted by user data spoken to Takemaru. Totalπumber of examples. For this work,. LIBSVM. [4]. ×. C. used for ∞nstructing the wordlist and BOW vectors. The size of the wordlist is also indicated in Table 3. ( 2). (3). C. 4.3. Evaluation meas町es Classification performance of the methods on valid or invalid. is used to apply SVM.. inputs was evalua(ed using the F-measure, as defined by:. Specifically, we are using C support vector c1assification (C. F-meαsure =. SVC), which implements soft margin. 2 . Precision . RecαII Precision + Recall. 3.2.2. ME-based method Maximum entropy (ME) models [5] provide a general purpose machine learning technique for c1assification and prediction,. which. has. been. successfully. appli吋 to. processing, named entity re∞伊ition,. natural. etc. ME. language. models can. integrate features合om many heterogeneous information sources. for classification. Each feature corresponds to a constraint on the. Table 3. model. Given a training set of (C, D), wh町e C is a sel of class. labels and. D. Engine. is a set of feature represented data points, the ME. 10 P(CID,λ)= g. ヤ. Output. or SNR, which will be shown later. λj are the paramelers that. For this work, Stanford Classifier [5] is used to apply ME. 4,488 LIBSVM. Kernel. Radial Basis Function (RBF). parame(er C. 0.01, 0.1 , 1, 10,. likelih∞d, duration. [4]. 1 00, 1000,. 1 0000 ME. need 10 be estimated, which refl民1 the importance of /;(c,d) in the prediction.. Chasen 2.3. 3. Tool function. SVM. where五(c,d) are feature indicator functions. We use ME models. for invalid ut!erance discrirnination. In this context, such features,. GMM. 10-best candidates. Wordlist size. 、 gZ expZ jM(cid) c, (c.d.問。). 4.0.2. Takemaru-model. Morphological analyzer. EXPLiλ.j; (c, d). for instance, could be the utterances'. Julius. AM, LM. ASR. mαlel attempts to ma氾rnize the log likelih∞d. 皇陛豆men凶condit・. Tool. Stanford Classifier [5]. 4.4. Experimental results The. pu巾ose. of. these. expenmen(s. was. (0. ∞mpare. the. classification performance of SVM and ME using combination. of theたatures. The combination pattぽns of features are shown in Tab1e. 4.. The F-measure was calcula(吋individually for SVM.
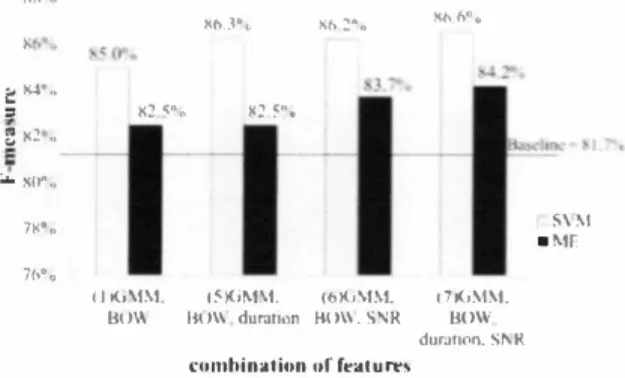
(4) 帥v 色AU A" νR一. and ME using the seven pa口町ns of combination, shown in Figure 4 and 5. The baseline melhod is SVM using only GMM likelih∞d as the feature and the F-measure is 81.7%. The F measures of SVM are always grealer Ihan those of ME. Therefore, it is assumed Ihal SVM is more effeclive in Ihis classificati on匂sk Ihan ME. Figure 4 shows Ihe comparison between feature combination patterns (1) to (4), Ihe combinations of features adding either of BOW, duralion, SNR or both duration and SNR 10 GMM likelih∞d. η1e result shows Ihal using BOW in addition 10 GMM likelihood as features for classification is effective for bolh SVM飢d ME. Especially for SVM, adding only BOW inαeases the F-measure by 3.3 poinls (合om 8 1.7% 10 85 .0%), shown in patlem (1), in comparison 10 Ihe baseline. For SVM, pattems (2) 10 (4), Ihe F・measures are also increased; however, for ME they decrease, in∞mparison to the baseline. Though,∞mparing patlern (1) and (3) for ME shows thal adding BOW increases 5.2 poinls (77.3% 10 82.5%) of F-measure, compared 10 adding SNR. Therefore il is assurr】巴d thal BOW is an effeclive feature for lhis classificalion lask We Ihen conducted an experiment using GI\⑪1 likelihood and BOW, adding eilher or bolh duration and SNR, shown in Figure 5.百】e result shows thal adding more features increases theF-measure for bolh SVM andルæ. The method that presenled the besl performance in c1assificalion was SVM using aU four features (pattern (7)), which are BOW, GMM likelihood, duration and SNR, wilh an F-measure of 86.6%, which represenls a difference of 4.9% in comparison 10 Ihe baseline The問ゐre, using all the four features, especially BOW, is effeclive for invalid inpul discriminalion. ss・0. 持(>1・ω. Só óO;.a. おゐ2・0. と同・" S. お2明。. 群2 �Q.. 穆.. 一 一. 2民2・". 世・・一一一一一 一一 -. E. :"'s伊". -. 7S・.. -. 圃圃・. 760。. s\ �I ・Mf. ・・・. (1正jMM. 伯尚M.\l. 白01'、durallon. 自0\\. (6K.iMM. 且01\. S'1R. t7K.i�1�1. 自O込,. durat1on. S!\ R. ωmhinalion "f featu町S. Fi思Ire 5: F-measures of SVM and ME for combinalion patlerns (1) and (5) to (7). 5.. Conclusions. We investigated discrimination between inva1id and valid spoken inquiries using multiple features as the likelihood values of GMMs, BOWs, utterance durations and SNRs. SVM and ME methods were compared in performance with Ihe F-measure and both methods outp町お口n吋the convenlional melhod, which uses Ihe likelih∞d values of GMMs. Especially SVM p町formed the besl and achieved 86.6% ofF-measure. Our future work includes further investigationゐr effective combination methods of differenl kinds of features.. 6. Acknowledgements This work was partially supporled by CREST (Core Research for Evolutional Science and Technology), Japan Science and Technology Agency (JST).. 7. [1]. M 臥U 船 田園田・ 一 め 同 t 加 一 に 十 ,M M 一川固 川 山 剛 . .. m 曲 出 脳 一 v 削 ・・・・・・・・・・・・・ 目叫 | : 。 船 川 | 榊u | 寸 aコ U6 0 AUい 岡 町叫 同 M M N. Pa仕ern (1) (2) (3) ( 4) (5) (6) (7). - - . - - . -且一白.司 -一 一. -・. -. Table 4: F mb Combination of features GMM likelihood, BOW GMM Iikelihood, duration GMM Iikelihood, SNR GMM Iikeliho吋, duration, SNR GMM Iikelihood, BOW, duration GMM likelihood, BOW, SNR G恥仏1likelihood, BOW, duration, SNR. [2]. 自H・。. 島4.�.o. お45・@. R, l・。. [3]. M. :. [4]. [5]. Figure 4目F-measures of SVM and ME for combination patt町ns ( l ) 10 (4). R. Nisimurn,. A.. Speech-Oriented. References Saruwotori. Lee, H.. Guidance. System. ond. K.. with. Shikono, “Public. Adult. and. Child. Oiscrimination Capability", In Proc. ICASSP2004, vol. 1, pp.433436,2004 H. Saka� T. Cincarek,H. Kawanami, H.Saruwatari, K. Shikano, A Lee,. “Voice. Activity. Oetection. applied to. hands-free. spoken. dialogue robot based on decωing using acoustic and language model", Proceedings of the 1 st international conference on Robot commu町田tion and coordination (ROBOCOMM2007),Article No 16,8 page邑2007 A.. Lee,. Shikano. K. Nakamura, R. Nishimura, H. Saruwatari, and. K.. ‘'Noise R obust R田1 World Spoken Oialogue System. using GMM Based R句ection of Unintended Inputs", In Proc. Int町田tional Conference on Spoken Language Processing, pp. 847-850,2004 C. Chang and C. Lin,“LIBSVM: a Library for Support Vector Machines",. 2001.. Software. available. at. http://www.csie.n刷edu.tw,ム-cj linIlibsvm C. Manning and O. Klein,“Optimization, Max朗t Models, and Conditio回1 Estimation without Magic", Tutorial at HLT-NAACL 2003. and. ACL. 2003.. Software. available. at. http://nJp.stanford.edu/softwar巴/classifi町shtml [6]. A.. Lee, T. Kawahara. Realtime. Large. and. K.. Shikano,. Vocabulary. ,‘JuIius. Recognition. Eurospeech2001,pp. 1691-1694,2001. - an Open Source Engine",. Proc.
(5)
図

関連したドキュメント
Such conditions are usually written in the form of the Stieltjes integral containing an atomic measure at the ends of an interval.. Using methods of the theory of nonlocal
Based on Table 16, the top 5 key criteria of the Homestay B customer group are safety e.g., lodger insurance and room safety, service attitude e.g., reception service, to treat
Moreover, to obtain the time-decay rate in L q norm of solutions in Theorem 1.1, we first find the Green’s matrix for the linear system using the Fourier transform and then obtain
In the previous section, we revisited the problem of the American put close to expiry and used an asymptotic expansion of the Black-Scholes-Merton PDE to find expressions for
This means that finding the feasible arrays for distance-regular graphs of valency 4 was reduced to a finite amount of work, but the diameter bounds obtained were not small enough
In summary, based on the performance of the APBBi methods and Lin’s method on the four types of randomly generated NMF problems using the aforementioned stopping criteria, we
As explained above, the main step is to reduce the problem of estimating the prob- ability of δ − layers to estimating the probability of wasted δ − excursions. It is easy to see
Applications of msets in Logic Programming languages is found to over- come “computational inefficiency” inherent in otherwise situation, especially in solving a sweep of
