Evaluation of Blind Separation and Deconvolution for Convolutive Speech Mixture using SIMO-Model-based ICA
4
0
0
全文
(2) tm口me delta 仇釦伽mctio叩n民1, where 6 ( 0的) = 1 and 6(rηt) = 0 (n 予#正 0的). ψ( nonlinear vector function. ー) is the. 3. PROPOSED TWO-8TAGE 8SD ALGORITHM. In this section, we propose a new two-stage BSD algSJrithm com bining SIMO-ICA and blind multichannel inverse Ultering. In the propose<!_ method, the separation!deconvolution problems can be solved efUciently using the following reasonable assumptions. (Al) The assumption of the mutual independence among the acous tic sound sources usually holds, and consequently, this can be used in the SIMO-ICA-based separation. (A2) The temporal-co打elation property of the source signals and the nonminimum phase property of the mixing system can be taken into account in the blind multi channel inverse Dltering for the SIMO model. The detailed process using the proposed algorithm is as follows. 3.1. First stage: SIMO-ICA for source separation. �. In this stage, a new blind separation method using SIMO- CA is conducted. SIMO-ICA consists of multiple ICA JJarts and a Udelity controller, and each ICA runs in parallel under Udelity control of the entire separation ザstem. The separated signals of thel-th ICA in SIMO-ICA are deUned by D-l. In this case, (8) yields. YrCAl(t) =. (一一一ー θ ベ11 ')'L ll.lJ\.t'-)' -x(t 伽rCAl(n) \ 白 YrCAl(t -,-. WICAl( Z- I )TWICAI( Z) D-l. 2L. L) are exciusively-selected. LPI /=1. =. [1]り. =. [6im(州)]ki'. D-l (. �. m(州 ) - )J. K+l-l (k+l-l壬L) k+l-l-L (k+l-l>L). n+d)T)t. L. 払い+d. 吋 ル(d). (14). whereαand βare the step-size param�ters;αis for the control of the total update quantity and βis- for Dd巴lity control. In (14), up dating of旬ICAl(n) for alll should be simultaneously performed in parallel in terms of 1 because each iterative equation is asso-. (7). mted with thothers VIaZLuiLl=εL wi4AI(z)z(t) AIso, the initial values of WJCAI(n) for alll should be different. If not, each ICA has the same set of inputs and will produce the same outputs. This results in an undesired solution. However, if we use di仔erent initial values, then the convergence on the appropriate SIMO solution is guaranteed by the simultaneous minimization of (6) and (7).. 体). 3.2. Second stage: 8lind multichannel inverse Dltering for de convolution. permutation. In this stage,日rsl, consider the blind channel identiDcation corre sponding to the Urst sound source SI(t), where we deal with the case of K L 2. Note that this can be easily extended to the gen eral case (K > 2) by picláng up the arbitrary two SIMO compo nents仕om SIMO-ICA's outputs. In this process, the room transfer. (9). = =. 仇釦伽11即I. (10). ) l (. where 6りis Kronecker's delta function, and. (13). + ß( (乞必Al(t)一x(t - D /2)). As for the proof of theorem, we have given in [3] Obviously the solutions given by (8) provide necessary and 印刷cient SIMO components, Akl(Z)SI(t- D/2), for each l-th sourc巴. There, however, is an arbitrariness in a selection of Pl For example, one possible sel巴ction is set permutation matrices, Pl to following equation,. Pl. ( ( 乞YrCAl(t)一x(t -D/2)). -α乞 off-di叫 cp (必Al(t))νiLi(t. where 11 x 11 is the Euciidean norm of vector x. Using (6) and (7), we can obtain the appropriate separated signals and maintain their spatial qualities as follows. Theorem: If the independent sound sources are separated by (6), and simultaneously (7) is minimized to be zero, then the output signals converge on unique solutions, up to the permutation, as. where Pl (1 = 1,…, matrices which satisfy. L. 旬以/1 (n) ω見Al(n). where ωrCAI(η) is the sepa則ion日lter matrix in the l-th ICA, ,!nd WrcAI(Z) is the z-transform of wrcAI(n). Regarding the 日delity controller, we introduce the following new cost function to be minimized,. Yr叫t) =叫[A(伊T] PIS(t - D/2),. ). By combining (13) with the nonholonomic TDICA [4], we can obtain a new iterative algorithm in thel-th ICA of SIMO-ICA as. (6). L. 2 /tJ� - D/2) -, - , n11 ). Yr叫t-n+め 切rCAl(d). t. n=û. (11 LYrCAI(t)-x(t-D/2) 112)γ. (12). In order to obtain (8), the gradient of (7) with respect to 切IC占l(n) should be added to the iterative learning rule of the separation Uト ter. The natural gradient [1] of (7) is given as. l νrCAI(t) = [Yk )(t)]klニ乞ωrCAI(η)x(t-n) = WrcAI(z)X(t),. [Akm(k,I)(Z)Sm(州)(t-D/2)]kl'. matching approach [5, 6, 7] in an SIMO framework because we have already resolved the mixing process of the sources into a sim ple SIMO model through SIMO-ICA in the previous stage. The subchannel matching approach can work even for the temporally _ correlated signal. Regarding the blind channel identiUcation cor responding to another sound source S2(t), we can estimate AI2(Z) and An(z) using the same approach. 門 Finally, we can e山nate the m山ichannel 即erse Ulters, Gll(Z). and G21(Z) for Âll(z) and Â21(Z), and Gロ(Z) and G22(Z) for. 円ぺU AUτ 円L.
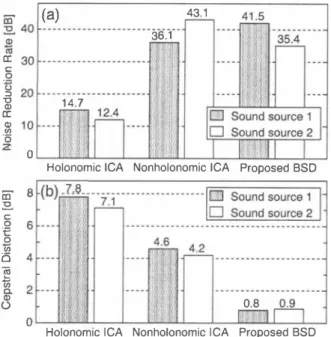
(3) Â12(z) and Â22(Z), based on the m山iple叩put/output inverse theorem (MINT) [8]. In the MINT method, the exact inverse of the room acoustics can be uniquely determined, even when Akl(z). has the nonminimum phase properties, if Akl(z) does not have any common zeros in the z-plane. For example, the recovered signals 8l(t) under (12) are given as. れ(t) = Gll(z)yi円t) + G21(z)品川t), 2 ゐ(t) = G12(Z)yi )(t) + G22(Z )品川(t).. (15) (16). The accurate estimation of the Dlter length N of the room im山叫onses lS仙pensable for i叫r cation pe釘rformance. There are various methods for Uiter-length estimation and we use出e Furuya's method [7] in this work.. 1. 3.3. Discussion on identiDability. In this section, we日rst derive the entire日Iter us�d in the proposed method. Secondly we discuss the channel identiUability of the pro posed BSD. Using (6) and (7), we can express the recovered source signals (15) and (16) as. ) .+ι ( qa -Ameο. |w(iCA円z 81(t) = [G11(z),Gn(z)ll ;;r� i CA2) ) I wit' ''"'(z) x(t), |w(i CA川z) [G12(z),Gn(z)l | (I CA^"' I W:iiV 1)(z) x(t).. W1�CA1)(Z) wACA幻(z). I I. (17). wj;CA幻(z) wACAり(z). I I. (18). Thus, we obtain the entire input-output relation,. [81 (t),82(tW = W(z)x(t),. (19). where. W(z) G12(μωzり)w1日riFC山A幻引(μωz吟) [白ω(μ州z. +. G以z)wJ�C臥A り円(μωz吟),. G仏11(ωz吟)wgc臥A川川1り円)町(μωz吟) 十 G2以1バ(μωz吟)wi�C叫A 幻引(μωz吟) I I G川z)wj;CA幻(z) + G以Z)WJ�CA川z) I. . (20). 玩r ( z ) is the resultant sep訂ation 0 iter matrix, _and is represented as a square (2 x 2) polynomial matrix with a Unite order of less than D + N - L_ Here, N corresponds to the length of the mul tichannel inverse Ulter Gり(z), and is automatically determined in accordance with the length of A(z). On the other hand, D, the. length of the sepa凶ion 日印lt町er Wゲ只zJr( arbitrarily set by the user. Previous studies [9, 10, 11] have indicated that the channel identiDcation cannot be realized in the case of K L without spe cial assumptions. Therefore the proposed BSD cannot obtain the exact source signals in theory because the entire Ulter is a square polynomial matrix. Since the deconvolution in the second stage can be performed exa�tly, it is considered that the separation to the SIMO model in the Urst stage includes a few residuaLs ・ In prac帽 tice, how�ver, we can reduc_e the residuals by setting Ulter length D in the Urst stage to be sufUciently long; this can be shown in the next simulation. Thus, the SIMO-model-based sign�ls are approx imately reproduced in this case. Overall, the identiUability almost �olds under the assumption that we are allowed to use the long FIR Ulters in SIMO-ICA as well as (Al ) and (A2). =. 4. SI恥侃JLATIONS 4.1. Conditions for experiment. A(x) is taken to be All(z) = 10.7z-1 - 0.3z-2, A21(Z) = Z-1 + 0.7z-2 + 0.4z-3, A12(Z)二 Z-1 + 0.7z-2 + 0.4z-3 , and A22(z) = 1 - 0.7z-1 - 0.3z-2.. The mixi時日lter matrix. Two sentences spoken by two male speakers are used as the origト nal speech samples s(t). The sampling frequency is 8凶z and the length of speech is limited to 7 seconds. The number of iterations in ICA is 15000. We carry out the following two experiments (Experimel1t 1) We evaluate SIMO-ICA while the length of the separation Ulter, D, is varied from 4 to 128 taps. We change the step-Slze parameter_α , among 1 X 10-6 2 X 10-6, and setβto be 6 x 10-'" and we Und optima which give the best performances (Experiment 2) We compare three methods as follows: (a) con ventional holonomic ICA (ICA-based BSD) [1] given by (5), (b) conventional nonholonomic ICA [4] given by (14) with setting ß=O, and (c) proposed two-古tage BSD. In SIMO-ICA, the step size parameterαis 2 X 10-6 andβis 6 X 10-4. AIso,ηis 1 X 10 -6 in the holonomic ICA, andαis 1 x 10-0 in the nonholonomic ICA; th巴se are optima �hich provide the best performances. The length of the separation Ulter is set to be 64 taps. In these experiments, thr官e objective evaluation scores are de 。 n巴d as described as follows. First, SIMO・model accぽacy(SA) is ddndas 2. "-'. l 1 f (Ilrefkl(t)11 )t J, (21) SAl = ;, F 2...'". 10 1暗1 0{/(i) 2 r efkl(t)11 )t) τ � .v l (1Iy1"(t) 一 where re!kl(t) = Akl(Z)Sl(t). The SA is used as to indicate a degree of similarity between the SIMO-ICA's outputs yi')(t) and SIMO叩odel七ased_signals refkl(t). Secondly, noise reduction. rate (NRR) [12], deUned as th氾 output signaHo・世oise ratio (SNR) in dB minus the input SNR in dB, is used as出e objective indica tion of separation performance, where we do not take into ac∞unt the distortion of the separated signal. The SNRs are calculated un dぽthe assumption that the speech signal of the undesired speaker is問garded as noise. Thirdly, mel cepstral distortion (meICD) is used a� the indication of deconvolution performan心e. In this study, we deUned the melCD as the distance between the spectral enve lope of the original so叫rce signal 5l (t - D /2) and that of the sep arated output. The 40th-order Mel-包caled ceps汀um based 0岨the smoothed FFT spωtrum is used. The melCD will be decreased to zero if the separation-deconvolution processing is performed per fectly.. 4.2. Results and discussion. Figur巴1 shows the results of SA, where th直SA increases as the length of the separation Ulter, D, is increased to more than the length of th� mixing system. In partic凶ar, the SA of about 30 dB, which is sufUciently accura�e for the following deconvolution pro cess, is achieved when the Ulter length is set to 64 taps. Thus, the SIMO-!CA can reprqduce the SIMO叩odel-based signals using the sufDcLently long Dlter. This r官sult supports the discussion on the identiUability of the propo喧ed method as described in Sect. 3.3. When the �hannel -ide�tiDcation was performed in the sec ond stage, the proposed method could blindly estimate the length ofα(n) at four taps successfully by using an existing Furuya's method [7] for SIMO model. Figur官 2 shows the results of NRR and melCD f,ωdifferent methods. From the results of NRR, it is evident that the sep岨rahon perf,ωmance of the holonomic ICA is too poor, but tho臼of the. A吐 A斗ゐ 円〆U】.
(4) 十干 内,』 唱1 ee . FU 内lu r r u U R o oed cu Au AU. order to eva1uate its effectiveness, a separation-deconvo1ution ex periment was carried out assuming 2 microphones and 2 speech sources. The simu1ation resu1ts revea1ed that the conventiona1 ICA based method inc1udes adverse spec汀a1 distortion due to the inher ent whitening e仔ect, and the spectra1 distortion can be consider ab1y reduced by using the proposed two-古tage BSD a1gorithm. 00 ・ nonb. nn 町 uu. 40 35 � 30 25 520 -g 15 �2 10 5 cn 00 [ö て3 国. <( 由. 6. REFERENCES. [ 1 ] S. Amari, S. Doug1as, A. Cichocki, and H. H. Yang, .‘Multi channe1 blind deconvo1ution and equa1ization using the nat ura1 gradienC', Proc. IEEE Int. 防'orkshop on Wireless Com munication, pp.lOl -1 04, Apri1 1997.. 20 40 60 80 100 120 140. [2] S. Haykin (ed.), Unsupervised Adaptive Filtering, John Wi1ey & Sons, Ltd., New York, 2∞o目. Length 01 Separation Filter [taps]. Fig. l. SIMO-model accuracy of SIMO-lCA with different Dlter length.. 市 40 Iト (a). 由 咽 a: C 0. g ã::. 匡. :1l. 。 Z. I. 30トー 20�I 14.7 10トー 。. 36.1. [3] H目Saruwatari, T. Takatani, H. Yam句0, T. Nishikawa, K. Shikano,“Blind separation and deconvo1ution for rea1 con vo1utive mixture of temporal1y corre1ated acoustic signa1s us ing SIMO-mode1-based ICA", Proc. 4th Int. conf on ICA and BSS σCA2003), pp.549-554, Apr. 2003.. 43.1. [4] S. Choi, S. Amari, A. Cichocki, and R. Liu, "Natura1 gradient 1earning with a nonho10nomic constraint for b1ind deconvo1ution of mu1tip1e channe1s," Proc. Int防'orkshop on ICA and BSS σCA'99), pp.371 -376, 1999 [5] H. Xu and L. Tong,“'A deterministic approach to b1ind iden tiUcation of multh:hannel FIR systems, Proc. ICASSP94, pp.58 1 -584, 1994. '・. { 由主 F』O一 亡O窃 δ 一個』 窃 門戸 由。. S お 一 一 一 図口一. Holonomic ICA Nonholonomic ICA Proposed BSD. ゆ州市 I. I. [6] Z. Ding and Y. Li, Blind Equalization and IdentiDcation,. Marcel Dekker, Inc., New York, 200 1 .. [7] K . Furuya and Y. Kaneda,“Two-channel blind deconvolu tion of nonminimum phase FIR system," IEICE Trans. Fun damentals, vo1.E80-A, no.5, pp.804-808, 199ï. [8] M. Miyoshi and Y. Kaneda,“Inverse Dltering of room acous tics," IEEE Trans. Acoustics, Speech and Signal Processing,. 0.8. vol.36, no.2, pp. 1 45-1 52, Feb. 1988. 師事1. Holonomic ICA Nonholonomic ICA Proposed BSD Fig. 2 . Simulation Results for different methods with regard t o (a) noise reduction rate, and (b) cepstral distortion.. proposed method and the nonholonomic ICA are high and compa rable as far as the only separation performance is concerned. As for the distortion of出e separated speech, which is an impoロant issue from the practical viewpoint, there is a considerable di釘er ence between these methods, and this wil1 be discussed in the next From the results of melCD,日rst, it is evident that the melCD of the holonomic ICA is obviously high, i.e., the resultant sp巴ech is whitened by the decorrelation in the conventional method. Next, the result of the nonholonomic ICA shows that there are still some distortions in the separated signa1s. Finally, regarding the results of 出e proposed method, there is a considerable reduction of me1CD. T hese results indicates that the proposed 8SD algorith can suc cessful1y achieve th separation and deconvolution for a 叩nvolu tive mixture of t �mporal1y correlated signa1s using the sut1Jciently long separation Ulter in SIMO-ICA. [9] K. Diamantaras, P. Petropulu, and )3. Chen, “Blind two input-two-output FIR channel identiUcation based on fre quency domain second-order statistics," IEEE Trans. Signal Processing, vol.48, no.2, pp.534-542, Feb. 2000 [ 1 0] Y. Inouye and K. Hirano,“Cumulant七ased blind identiDca tion of linear multi寸nput-multi-output systems driven by coト ored inputs," IEEE Trans. Signal Processing, vol.45, no.6, pp. l 543-1552, June 2000.. [1 1 ] Y. Hua and J. Tugnait,“8lind identiDability of FIR-MIMO systems with colored input using second order statistics," IEEE Signal Processing Letters, vol.7, no. 1 2, pp.348-350, Dec. 20oo. [12] S. Araki, S. Makino, R. Mukai, T. Nishikawa, and H. Saruwatari, “Fundamental limitation of frequency domain blind source separation for convolved mixture of speech," Proc. 3rd Int. conf. on ICA and BSS (ICA2001), pp.132- 1 37, Dec. 200 1 .. 5. CONCLUSION. We proposed a new BSD framework in ',Vhich SIMO-lCA and blind m-ultichannel inverse Dltering are et1Jciently combined. In. - 245-.
(5)
図
関連したドキュメント
In order to estimate the noise spectrum quickly and accurately, a detection method for a speech-absent frame and a speech-present frame by using a voice activity detector (VAD)
Two grid diagrams of the same link can be obtained from each other by a finite sequence of the following elementary moves.. • stabilization
Standard domino tableaux have already been considered by many authors [33], [6], [34], [8], [1], but, to the best of our knowledge, the expression of the
H ernández , Positive and free boundary solutions to singular nonlinear elliptic problems with absorption; An overview and open problems, in: Proceedings of the Variational
Keywords: Convex order ; Fréchet distribution ; Median ; Mittag-Leffler distribution ; Mittag- Leffler function ; Stable distribution ; Stochastic order.. AMS MSC 2010: Primary 60E05
It is suggested by our method that most of the quadratic algebras for all St¨ ackel equivalence classes of 3D second order quantum superintegrable systems on conformally flat
In particular, we consider a reverse Lee decomposition for the deformation gra- dient and we choose an appropriate state space in which one of the variables, characterizing the
Massoudi and Phuoc 44 proposed that for granular materials the slip velocity is proportional to the stress vector at the wall, that is, u s gT s n x , T s n y , where T s is the
