The Japanese Psychonomic Society
NII-Electronic Library Service
TheJapanesePsychonomicSociety
77ieimanes'elk)uixato.rtts,ciconomicSciEncg/
1999,Vol,I8,Ne.1,9
-22
Original
Articles
The
Three-dimensional
structure
perception
of
paired-dot
and
unpaired-dot
spherical
surfaces
:
effects
of
the
vantage
point
and
the
object's
rotationpredicted
by
the
generic-view
principle
Michiteru
Ki'rAzAKi"
andShinsuke
SHn{oJo"'
Udeiversity
of
7iokJ,e'
andCtilttb"iia
b2stitute
of
Ttrchnolczg{)'**
.axls
We examjned applicability of thegeneric-view principle to the extraction of structure
frorn
motion.
In
particular we manipulated the angle betweellthelineof sight and therotation nxis of the spherical surface that was definedby moving pairedor unpaired randomdots,
The
image motions of thesphere were categorized using an aspect graph and ussigned values of genericnesslacciclentalness,
The
genericimage
motions elicited clearerlmore depththan theaccidental onesin
the paired-dot stimuli, bejng mostly consistent with the predictions of the generic-viewprinciple.Cf'heeffect of thegenericimage rnetion was
ress
intheunpaired-det stimuli than inthepaired-dotstimuli. Itissuggested thatthe combination of the generic-viewprincipleand the
relative-inotion
hypothesis
could betterexpluin perception of the rotating sphere ingeneral.Thus, both of them seem
to
contribute totheproccssingof structurefrom
motion.Key
words: generic-view principle,three-dimensional motion structurefrom
motion, pairedrandoni
dots,
unpaired.randomdots
'
Introduction
The human observer can perceive
three-climensional
<3-D)
structurefrom
two-dimensional(2
D)
motion without any other cue such as bineculardisparity,shading, textureor occlusion, This
phe-nomenon was firstreported by Miles
(1931),
and is now called the Kinetic DepthEffect
<"J'allach
&
O'Connelr,1953)or
Structure
From
Motion
(UIIman,
1979).
Wallach
andO'Connell
(1953)
founcl
that "simulta・neous change of lengthand orientation of a contour"
was an essentia] condition for the
Kinetic
Depth
Effect
(see
alsoJohansson
&
Jansson,
1968)
by
using* Departinent
of
Psychology,
Graduate
School ofHumanities and Sociology,Universityof Tokyo,
7-3-1Hongo, Bunkyo-ku, Tokyo, ]13-O033
'"
Computation
and
Neural
Systems,
Division of
Biology,
California Instituteof Technology,Pasadena, CA 91125,U.S.A.
thesilhouette of rotating solid objects and wire-frame m6dels. Ullman
(1979)
investigatedstructure frornmotion using the computational approach, and
showed that 3visual frames of 4nonplaner points are
computationallyltheoretically suMcient
for
recover-ing
3-D
structure with the"rigiclity
constraint". This studyhad
so muchimpact
on theresearch fieldthatmany researches
have
fecused on two issueseversince: on the minimal information for recovering
structure computationally and psychophysically
(e.
g.,Longuet-Higgins, 1981;
Hoffman
&
Bennett,
1986;Bennett
&
Hoffman, 1985;Bennett,
Hoffman, Nicola&
Prakash,
1989;
welr reviewbd by Braunstein,Hoffman, Shapiro,Andersen & Bennett,1987)and on
thevalidity of therigiclity constraint as a predictor of
psychophysical
data
(e,
g,,Braunstein&
Andersen,
1984;
Ullman,
1984
a;Ullman,
1984b;
Braunstein
&Andersen,
1986;
Ullman,
1986;11'odd,
1984). Fromthesestudies, itseenis to be obvious that the rigiclity
constraint or the relaxed version of it
(Ullman,
10 The
Japanese
Journal
ofPsych
1984a; Hildreth,Grzywacz & Adelson, 1990)would
contribute tothe process of structure
from
motion.However,
the rigidity constraint isnot enough to explain thevarious aspects of structure from motion.Itwas
founcl
that velocity gradientfrelativemotien(Braunstein,
1962; I.iter,Braunstein
&
Hoffman,
l993),
segmentation boundaries(Ramachandran,
Cobb
&
Rogers-Ramachandran, 1988),and surfaceinterpolation
(Ramachandran,
et al., 1988; Treue,Husain
&
Andersen,
1991
;IIildrcth,Ando, Andersen& Treue, l995;Treue,
Andersen,
Ande&
Hildreth,I995)
could also contribute to the structure-from-motlon process.VLrehave applied the `Generic-view
principle'
(de-scribed
in
detail
in
the next section) to 3-D inotionperception and suggested thatthisprinctple,if
util-izedus a constraint, weuld well predictthe human
perceptionof 3-D mution of a single
bar
anddouble-bar
(Kitazaki
& Shimojo, 1996). The originalrig{d-ity
constraint and the algorithrn(Ullman,
1979)do
not offer the solution for the ambiguity
in
`'deteriorated-infonnation" situations such as the
sin-gle straight
bar
in
Kitazaki and Shimojo study.Urlman also macle a remark that sume additional
assumptions are required to interpretthe
image
inotion of peor
information
such as two pointsor aline,
An
example of such an aclditional assumption wouldbe
the"maximal extension assumption" thathad
been
employedby
Johansson
andJans$on
(1968).
The maximal extensiun assumption states that the
line
with maximum lengthina 2-Dimage
sequence shouldbe
on the frontal-parallelplane und thatit
should app]y to a limitedsequence such as 30 cleg rotation.Johansson
andJansson
(1968)
showed that thismaximal extension assumption,in
addition totherigidity con$traint, could uniquely predictperception
of the 3'D rotation of a
linelbar,
thatis,
theexactslant and tiltof the line.However, the assumption was yalid only
if
thepossibtlityof translation indepthwas excruded a
Pn'on'.
In
fact,
subjects perceivedtranslation indepth when the
image
contajned L-D stretch and 2'D translation(Kitazaki
&
Shimojo,
1996). Thus the rigidity assumption, even with the
additional
L`maximal
extension" assumption, isinsulficient
to predict3-D
motion perceptiun of aonomic
Science
Vol.
18,No. 1single straight bur. This isso mainly
because
itdoes
not solve theambiguity between rotation in
depth
andtranslationin
depth.
On the otherhand,
ourpredic-tions
based
on thegeneric-viewprinciplewereconsts-tentwith theperception of
discriminating
3-D
reta-tion indepthfrom 3"D translation
in
depth
of a singlestraight bar.
We
have
speculated thatthegeneric-viewprincipleisnot incompatible with the rigidity constraint, but
rather cooperates with itingeneral. Inour previous studies, we adopted only a
bar
ordouble-bar
as astimulus so thatwe could cbnsider allcombinations of motion components such as rotation, translation,
and stretching. ConsequentlyL one would argue that
thegeneric-view principlecould be applied only to
3-D motion of such simplest structure. To examine
this issue,we adepted a rotating spherical surface
with multiple dots as a stimulus and tested whether
the generic-viewprinciplecan predict the
3-D
percep-tionof thestimulus.
Generic-view
Principle
We assurne thatthevisual system's selution shoulcl
beprobabilisticallyor statistically appropriate inthe
real world. Inother words, generic views of a
lar
object should befavored over accidental views ofethers. For most object$, there istypicallyat
least
one view that
has
invariant propertiesover largechanges of the vantage point. This isthe `LGeneric
View".
On
theotherhand,
the'`Accidental View" is
defined
as animage
class thatis
chungeable withslight positionalchanges of the vantage point. The
generic・view principlestates that the visual system
interpretsa 2-D imuge as a genericview of a
3'D
obj ect,
but
not as an accidental view of another objecteven ifit
is
possib]e theorctically.This princip]e
has
alreadybeen
applied to many
different
domains
of vision and cognition, such asmachine vision
(Binford,
1981;"'itkin
&
baum, 1983;
Lowe,
1985;Malik, 19S7),3'D objectrecognition
from
components(Biederman,
1985>,shape from silhouette
(Richards,
Koenderink &Hoffman, 1987), surface perception of untextured
stereograms
(Nakayama
&
Shimejo,
1992),tienof
line
drawings
(Albert
& Hoffman, inpress),The Japanese Psychonomic Society
NII-Electronic Library Service
TheJapanesePsychonomicSociety
M.
KiTAzAici
andS.
SmMoJo
:Generic-view
(Freeman,
199Lt;Freeman, 1994), and color con-stancyCBrainard
&
Freeman,
1994).'T'hus,
thiswouldbe a good candidate
for
a generaltheory of vision.
"Fe
hax,e
attempted to apply thisprincipleto3-Dinotion, or dynamic scene
interpretation.
In
thepresent stucly, we
deal
particulEtrly・with 3-D niotion of aspherical surfacedefined
by
randorn dots,Itisanespecially suitable stirnu]us for our purposc because
thestatic 2-D image of the 3-D sphere isalways a circle
from
a]] possiblevantage pointsso thattheprejected Z
-D
irnagesare al]generic viewsin
termsof n static image. By using thisas a stimurus, we caninvestigatethe
dynarnic
application of thegeneric-view principlewithout contarriination of any static
aspects.
Paired-dots and IJnpaired-dots
Spherical
Surface
and Vantage Points
Inthe presentstudy, we firstemployed u spherical
$urface
definecl
by
paireddots
as motivated byQian,
・Andersen
andAdeLson
(t994
a) study(Experiments
1and 2),
The
relationship of the present study withtheir
finclings
wi1] becliscussed laterinGeneral
Discus-sion. A spherical surface definedby paired random
dots was sirriulated
in
a ,',-D scene(see
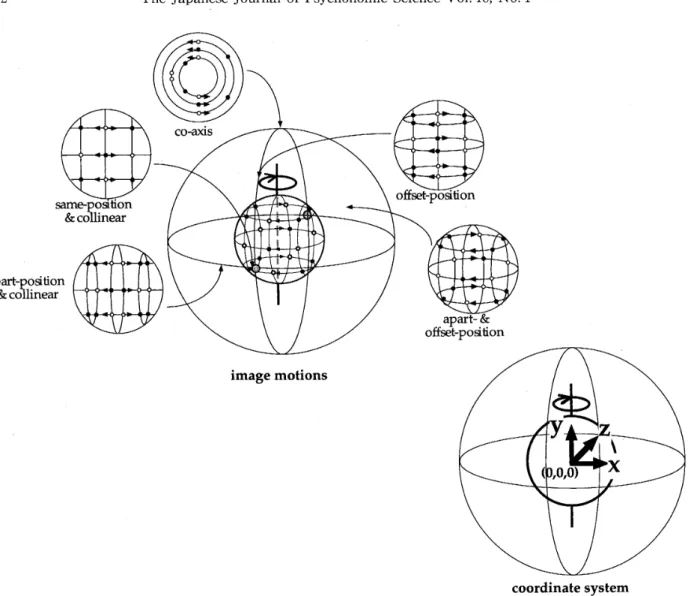
Figure1)i),
that was rotating around the vertical axis. Note that
the coordinate system that we adopted here was
environment-based and was neither dependent on
vantage points ner on object rotation. The v・antage point was as$umed tobe at various positions around
thesphere, but always to
look
through the origin(O,
O,O),which was the center ef thesphere. The
ortho-graphic projectionwas adepted inthispaper.Inother
DWe
used theterms "paireddots"and `'unpaired
dots"
in
avery specitic way to indicatethetypesef spherical surface
defined
by
dots
in
a 3-D scene, as indicatedin
Lhe text."'e
used thephrases,2-D paired dotsand 2'D unpaired
dots,
only to
indicate
thestirnuli employedby
Qian
et a](1994
a). InExperiments1
and 2,all dotswere paired on the surface of a 3'D sphere
model
(see
Figure
1and Method of Experiment1),and theirprojected2--Dimage motions werc
used as stirnuli. Itwas certainly truethut the
offset-position iniagemotion inExperiments ] and 2contained unpaired detson its2-D irnage. Yet,we never employ such usage of theterm in order to avoid confu$ion.
Princip]e
for
Rotating
Spherical
Surface
11words, the
distance
between
the vantage pointandthesphere ",as assumed infinitery]eng thatthe
per-spective didnot appear inany image mot.ion.
All
dots
were simurated on the spherical surface, and pairedsothateach pairhad thesame coordinates on the X'Y
plane but
different
ones en the Z axis at the initialposltion.Thus, when the vantage pointwas at
(U,
O,
]
k)
{`k'
is.
an arbitrary nurnber Iarger than theradius of the sphere), al] paired dots appeared as
paired at the same position on the projectecl 2-D
image plane,thenmoved
in
opposite directions.Thiswas similar tothe2-D paired stimulu$ employed
by
Qian
et al.(1994a).
"rhen
the vantage point "'aslocatedapart from
(O,
O, ±IO, the image motion wasrather similar tothe 2-D unpaired stimulus employed
by
them.Let us now consider all possiblevantage points
nrou"d the sphere and projected retinal image
motions
(Figurel).
The outer spherical surfaceconsisting of vantage pointsissegrnented according
tothequalitative c]ass of the
image
motion, to make an `'aspectgraph"
(Koenderink
&
vanDoorn,
1976;Gigus & Malik, 1990; Kriegnian
&
Ponce,
1990;Ponce & Kriegman,
1992).
At
two singular points ontheaspect graph,theobserver obtains "samc-position
&
collinear"imagc
motions, where thepaireddots
appear at the same positionand move collinearl>,in
opposite directionsto each other. At other twe
singular points,theobserver obtains
L`co-axis"
imagemotion$, where all the
clots
arejust
rotating aroundthe common center.
On
the horizontal arc, theobsen・,er obtains "apart-position & collinear" image motions, where thepaired dotsappear at horizontally apart positionsand move col]inear]y
in
oppositedirections.
On
the vertical arc, the observer obtains"offset-position" image
motions, where the paired
dotsappear at vertically offset po$itions and move in
different
djrections.
From all the other vantagepoints,the
image
mot{ons are a mixture of the"apart-position
&
collinear" and the "offset-position"image
motions, and named "apart- &
offset-position"
image
lnvtions.The genericness of
image
motionsfor
a sphericalstirface
defined
by
paired detsisassumed tobe inthefollowingorder : "apart-
&
12 TheJapanese
Journalof
PsychonomicScienceVol.
18,No.
1<>
saertlowaSeti8n ap.ar,t2-sl/fi',ti.en.co-axls
I offsetJPositionimage
motions apart-& offset-position coordinate systemFigure
1.Schematic
representation of paired randomdots
on a spherical surface andits
orthogonally projectedimage motions. The outer sphere indicatesthe aspect graph
(see
text).The
right-bottornindicates
thecoordinate systern used inthe text; the center of the sphere was the origin
(O,
O,O),and all axes were setenvironmentally so thatthecoerdinate was
invariant
with thevantage-point change.position"="apart-pusition
&
collinear" >"sameposi-tjon
&
collinear"="co-axis". This isdetermined
automatically by thesizes of vantage points'areas inthe aspect graph.
Accerdingly,
the generic-view principle preclictstheclarity of 3-D perception or theamount of perceived depth inthe same order.
We
comparecl theeffects of these image-motion typeson
3-D
perceptionof the sphericul surface definedbypaired random
dots
in
Experirnents
1
and 2to see iftheresults are consistent with thegeneric-view-basecl
predictions. Then, inExperirrient3,we adopted a
spherical surface
defined
by unpairecl!ordinaryran-dom
dots
as thestirnulus, and investigatethe effectsof itsimage-rnotion types on the 3-D perception,
again with regard tothe generic-view-based
predlc-tiOllS.
Experiment
1
We
first
investigated
the qualitativedifferences
indepth
effect among threeimage-motion
types:thesame-position
&
collineurimage
motio'n, theapart-position
&
collinearimage
motion, and theoffset-2) The
"apart-&
offset-position" image metionwas net included inExperiment 1 or 2. We
conducted another experiment which we
do
notreport heretocornpared thatirnagernotion with
theothers, and found thatthe "apart- &
position"image motion
had
a similar effect tothat obtained
in
the "offset-position"image
motlon.The Japanese Psychonomic Society
NII-Electronic Library Service
TheJapanesePsychonomic Society
Dv・I.KiTAzAK]and
S.
SmMoJo:
Generic-viewposition image motion
(see
Figure
1)Z}.
Method
Subjects. Four subjects
(all
males, ages rangedfrom
21
to26)
participatedin
the experiment.Three
subjects were naive to the purpose of the experimentancl one was thefirstauthor. Thcy allhad normal or
cerrected-to-nonnal visual acuity.
Stimuli. The $timulus
displays
consisted ofortho-graphic projections of
dots
on a sphere(radius
5.0deg
in
visual angle). The luminance of detswas 6.93cdlrn2 and that of the buckground was
O.Olcd/m2.
Alr
dotswere pairedso that each pairhad tbesamecoordinates on the X-Y plane
but
different
ones onthe
Z
axis at theinitial
position(We
employcd anenvironment-defined, not viewer-dependent, coordi-nate system todescribe the stimuli :See Figure2).
The
dots
on thevirtual sphere rotated for2s at30.0
degfs
(5.0
rpm) around the Y axis.The
lifetime
ofeach dot pair was limited to 167ms and the
dots
appeared and
disappeared
asynchronously, inorder toexclude the possibleartifact of the dots'long
tra-jactories.
The
number of dots disp]ayedat a timcwas
50
(25
pairs>.Design.
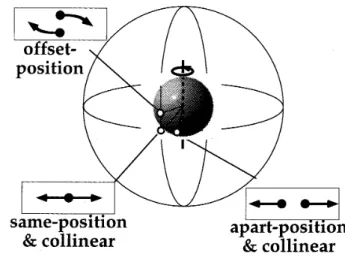
Three different vantage,points
wereadopted for experimental cunditions as shown
in
Figtire2
(See
also Figure1).In
the"same-position
&collinear'' condition, the vantuge peint was at the
coordinate:
(x,u,z)=(O,O,
±fe)
(`k'
was anarbi-fi2ts?n
Figure2. The stimulus conditions of
Experiment
1The coordinate system was environment-based
and never
dependent
on thevantage point.Threeimage motions defined by the vantage points
were used as stimuli.
PrincipleforRotating
Spherical
Surface
13
trary number
lager
than the radius of the sphere), sothatall paireddotsappeared at the same positionon
the 2-D image plane,then moved
in
oppositedirec-tionscollinearly.
In
the "apart-position &collinear"
condition, thevantage point was
horizontally
shifted5.0
deg,
so that all paireddots
appeared at thepositions apart horizontallyon the 2-D image plane, then moved inopposite
directions
collinearly.In
the thirdcondition, '`offset-position"condition, the
van-tage peintwas vertically shifted 5.0 deg,so thatal]
paired
dots
appeared at thepositionswith a verticaloffset on the 2-D image plane,then moved inthe
opposite directions.Three pairsof conditions were repeated 48times inrandom orcler.
Thus,
eachsub-ject
performed 144trials.Apt,aratus. The experiment was
done
inasemi-dark
rooin.Stimuli
were presented on a colorcathode-ray tube
(CRT)
display(HITACHI
CM218MU
O.31 mm pitch21-inchCRT;
1024'
768
pixels;vertical scanning frequency,
60.0
Hz) controlledby
aworkstation
(SiliconGraphics
INDIGO).
The
subject's
head
wasloosely
stabilizedby
a chin-restand theviewing
clistance
was 57cm.
Procedintre.
Each
subject performed30
practicetrials
followed
by
144 experimental trials,Two
ofthree conditions were randomly selected and
present-ed sequentially at each trial
for
paired cemparison.AI] observations were made monocular]y, with the other eye occluded
by
an eye patch. The subject wasinstructed
tochoose thestirnulus thatyieldedclearer3
'D
structure percept or more amount of depth. We employed thisinstructionbecause some subject$re-portedthat they
did
not understand `clarity'of
3-D
perceptionand itturnedout to
be
easierfor
them tojudge
amount ofdepth
than3-D
clarity,Results
All
thesubjects perceiveda significantly clearer3-D
sphere or more depth inthe
apart-posion&
col-Iinearcondition and the offset-position condition than
inthesame-position & collinear condition
(Figure
3
;sign test
P<
.05).
It
is
consistent with thepredictionbased
en thegeneric-viewprinciplebecause theposition
&
collinear and theoffset-position conditionsare more generic than the sarne-position
&
collinear14 The
Japanese
Journalof
PsvchonumicScience VoL 18,No.
I
The
offset-positfon condition w・as preferredfor a clearer 3'D sphere over theapart-position & collineur eunditionby
all thesubjects(statistically
significantfurthreesubjects ;sign test
P<O.5).
This
difference
was not predicted from the generic-view principle
because
both
were equally availablefrem
vantagepoints on an arc in the aspect graph
(Figure1).
These two types of image motion, however, might
contain
different
typesof genericness.W'e
hypothes-izethat there are two types of genericness inthe
paired-dotspherical surface.
One
isthe genericnessrelevant totheinstantaneousmotion of
dot
pairs,andtheother
is
reLevant tethe angle between the]ineof sight and thc rotation axis3). The offset-positionimage motion contains
both
typesof thegenericness,while the apart-position
&
collinear image niotion contains only thegenericnessre]evant tothe instanta-neous motion of dotpairs. That wou]dbe
thereasunwhy theformer elicited clearer clepthimpressionthan
the
later.
In this expcriment, three qualitativelydifferent
vantage points were selected to show the basic or
categorical
differences
among the three types ofimage motion, The next experirnent wus conclucted
in
order toevaluate thediffcrences
morequantitative-ly
among thefollowing
threeimage-motion types:"the
same-position
&
collinear'',"theoffset position", and "the
co-axis"
image
motiens. By shifting thevantage point vertically along
Y
axis, theirnage
motion graduallychanges from
`'the
same-position&
collinear" image motion to "theoffset position"
image
motion, then reaches '`theco-axis"
image
motion")(for
details,
see the method inthe next experiment).The pairedcornparison adopted
in
Experirnent
1isverv sensitive tothe difference
between
two stimuli so'that
it
was suitableto
show thefundamental
effect ofthegenericness. The pairedcomparison
is,
however,
net goodfor
theexperimental designrequiring many3)See also theintroductionof
Experiment
3aboutthesetwo types of genericness.
4)
Though
we could quantitativelymanipulate thevantage puintalong any axes or directions,the
v・antage point was manipulated only alung
Y
axis
in
Experiment
2 inerder to compare theresult of thepuired-dot casc
(Experiment
2)
andthat of the unpaired-dot case
<Experiment
3).
The
results inthe ease of the vantage-pointmanipulation along other axes or
direetions
wilrbe inferred
from
the result obtainedin
thisexpenment. Subjects 100ts
90-g'gij:voopt
60a2
soca
ts
40au1:
3ov-UU
20vtu10oaP&arcto'rl:,nSeitat?noffset-position offset-position
v vm v
same-position SaMe-POSItlOn apart-position
&collinear
&collinear
&collinearCompared Image Motion Types
of Experiment 1
The abscissa indicatescombinations of stimuli
The ordinate
indicates
thepercentagejuclgment
of the image motion at theforthe c]earer 3 D percept,ion.The dottedline
indicates
the5%
significance levelFigure3. The results
Subject
MK
was thefirst
author and theothers were naive.presented forpairedcomparison.
upper row ofthe abseissa
The Japanese Psychonomic Society
NII-Electronic Library Service
TheJapanesePsychonomic Society
)vl.
Kri',xz,xK{
andS,
SHm{o.]o:Generic-view・
Principle
for
cenditiuns
because
the number of trialsis easy toexplode.
Therefore,
we employed the subjectiveadjustment method
in
thenext experimentin
order toinvestigaternany quantitatively-rnanipulatecl
stimu-lusconditions,
Experiment
2
The
amount of the vantage-point shift, thatisthe anglebetween
therotation axis and theline
of sight,was systematically manipulated and its effect on
depth was measurcd by thc subjective adjustment
method.
Method
Subjects.
Three
subjects(a
female
ancl two males, ages ranged from 20to26)participated inthe experi-ment. Allthe
subjects were naiveto
thepurpose of the experiment. They all haclnormal orcorrected-to-normal visual acuity.
Stimtfii,
The
$timulu$displays
wereidentical
tothoseinExperiment 1except fortheduration
(1
.5
s)of thestimulus and the positionsof thevantage point as
described
inthefollowing.
Design. The vantage point was quuntitatively
rnanipulated; vertical shift inincrements of O,5,15,
30,
45,
60,
and90
cleg.
One
of thcseconditions wasemployed
in
random orderfor
each tria].Seven
conditions were repeated
24
timesin
random orderfor
each session(168
trials),Apt)a7utzts.The apparatus was identicalto that in
Experiment 1.
Procedttre,Each subject performed
35
practicetrialsfollowed
by
168experimental trials.Allobser-vations were made monocularly, with the other eye
occluded by an eye patch. The subject
judged
theperceivedamount of
depth
relativeto
the
horizontaldiameter on the 2-D image planewith the
`Lbircl's-eye-view adjustment" method: after each stiniulus was presented, a
horizontal
line
whoselength
was thesame as the sphere's diameter and a vertical line whose
length
was adjustab]eby
the subject appeared.The subject was instructedtoconsider theimage of
linesas the bird'sview
(x-z
plane)and the horizontallineas the horizontal
(x-coordinate-axis)
diameter ofthesphere, and toadjust the
length
oftheverticalline
Rotating
Spherical
Surface
15to
be
the same as theperceiveddepth
(z-coordinate-axis diameter) of the sphere by moving the mouse.
Results
The functionof theperceivecldepthamount against
the vantage-point shift was a skewed inverse-U'
shape
(Figure
4). The peak varied ina range of 5-30deg
across thesubjects.At
theO
deg
condition wherethestimulus was thesame-position
&
co]linear image motion, the subject perceivedless
ameunt ofdepth
than at the 5-v60deg conditions where the stimulus
was the offset-position image motion. Itisconsistent
with theresult of
Experiment
1,
The
least
depth
wasperceived ut the
90
deg
condition where thestimuluswas the co-axis
i]nage
motion.We
wouldlike
tointerpretthat thisskewecl inverse-U
function
mayrefiect a compromise between the generic-view
princi-pleand some other principlesuch as thatof relative metien. NVe will
discuss
itfurtherinthe generaldiscussion,
We
used sofar
theimage
motionsderived
from
thepaired dots on a spherical surface as stirnuli
(see
Figure1) and demonstrated the effects predictedby
the generic-view principle. The paired clotson a
spherical surface are, hewever, a very special and
artificial set of stimuli. How about the periectly
unpaired
(spatially
random)dots
on a sphericalsur-face,
thatmight bemore general? To investigatethisImageMotion Types 100 gege S-N p,.tuo 80
:E
7oge
.N
6o'sn
unvd soxg
4o e'.9
ge
30 w"Mi'
2o "10 o sthrneuesltlen [ellinear, /joffset-positionco-axus・Subje[tstHIMtYT-t KM O 10 20 30 40 50 60 70 80 90Vantage-point Shifttdeg
Figure4. The results of Experiment 2
The
abscissaindicates
the amount ofmanipulated vantage-point shift
from
thezontal arc on the aspect graph, The ordinate
indicatestheestimated ratio of
depth
relative to16 The
Japanese
Journalof
Psychonomic
point, we conducted Experiment 3using thespherical surface thatwas
defined
byunpaireddots.
Experiment
3
For the unpaired
dots
(random
dots
without anyregularity) on a spherical surface
in
a3-D
scene, therelationship
between
the
rotation axis and thelineof sight couldbe
described
interms of the anglebetween
them:
it
is
either orthogonal, oblique, or collinear.Unlike
the case of the paired-dot spherical surface(see
also Figure1),thereare nolonger
any effects ofthe
horizontal
shift ofthevantage point(because
thedots
are "apart" tobegin
with).Thus,
we manipulat・ ed onlv the vertical elevation of the vantage point."We
made theaspect graph to
determine
thegeneric-nesslaccidentalness.
Categorically
we have threeimage-motion types forthe spherical surface defined
by
unpaired ranclomdots
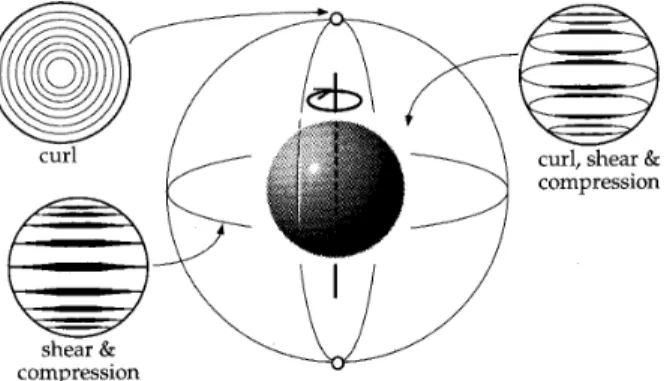
(Figure5).
The
ortho-graphic projectionwas again aclopted
here.
At twosingular points on the aspect graph, the observer
obtains the "curl"
image
motiun that contains onlythe curl component
(arl
dots
rotate around thecom-mon center and the relative positions of dots never change).
On
the horizontalarc theobserver obtainsthe
[`shear
&
compression" image motion that con-tains the shear component(the
speed ofdots
changesin the perpendicular
direction
to the dots'movingdirectien)
and thecempressive component(the
speedof
dots
changes along thedots]
mevingdirection)
without any curl component. On all theother vantage
peints, the
image
motion contains all of thecurl,theshear, and the compressive components, thus was
curl curLshear&
compresslen
shear&compresslo
Figure5. The image-motion typesof the unpaired
random
dots
on a spherical surfaceThe
ihickness
uf trajectoriesin
theimage
motions refiects thespeed of the
dets
(see
text).Science
Vol.
18,
No.
1
nained the
`"curl,
shear & compression"irnage
rnotion.The order of genericnesswas assumed to
be
asfol-lo",s:"curl,
shear
&
compression">"shear&
com-pression">`icurl". The generic-view principlepre・
dicts
thattheclarity of 3-D perception or the amountof depth should
be
inthe same order,Inthecase of unpaired dots,we expected thebias
predicted
by
thegeneric-view principle wouldbe
lessobvious than inthecase of paired
dots.
It
wouldbe
so because all theimage motions of the unpaired-dot
spherical surface were similar togeneric views forthe
paired-dotspherical surface interms of 2-D pairedl
unpaired pattern,se that the geometrical
difference
umong generic and accidental image motions wouldbe
lessprorninentintheunpaired stimuli than inthepaired stimuli. In other words, stimulj with the
paired-dot spherlcal surface were relevant
both
to thegenericvantage pointsforthe instantaneousrnotion
of dot pairs and tethat
for
therotation axis,but
the stimuli with theunpaired-dot spherical $urface wererelevant only tothe generic vantage pointsiorthe
latter,
Thus,the generic-vieweffect wouldbe
greaterinthepaired-clotcase than inthe unpaired-dot case.
In
order totestthisexpectation and toextend our analysis to morc general cases, weinvestigated
the effect of anglebetween
therotation axis and thelineof sight for unpaired
dots
on a spherical surface inthisexperiment.
We
must note that this experiment was simllar to that ofLoomis
andEby
(1989)
(see
alseLiter,
et al.,1993)except mainly forthelifetirneof dotsand steps
ofthe vantage-point manipulation, The lifetimewas
limitedto 100ms or
166ms
in
our experiments,but
was not limited in theirs.
We
willdiscuss
thedifferences
later.
Method
Subjects.
Four
subject$(all
males, ages rangedfrom 21to 27)participated
in
theexperiment.All
thesubjects were naive tothe purpose of theexperiment,
Thev
allhad
normal or corrected・to-normal visual acultv.Stijuli. The stimurus
displays
consisted ofortho-graphic projections of random
dots
enthe
sphere(radiu$
5.0deg invisual angle). The luminance ofThe Japanese Psychonomic Society
NII-Electronic Library Service
TheJapanesePsychonomic Society ImageMetlon Types 100 s 9o
'k1so
70 asEE6o
':8
so a.N 4e y. o.8
g
3o 1'-"20 MSU
le o
M.
Ki't'AzAKi
andS.
SHmroJo:
Generic-view
O.Ol
cdlm2. Thedots
on the sphere rotated for2s at60.0degls
(10.erpm)
around the Y axis. Thelife-tirneof each
dot
waslimited
to 1OOms and thedots
appeared and
disappeared
asynchronous]y,in
order to cxclude the possibleartifact of the dots'longtrajec-tories. The number of dots displayedat a time was
50,
Design. The vantage pointswere quantitative]y
manipulated; vertical shift
in
increTnents
ofO,
5,
15,30,45,60,ancl 90
deg.
One
of theseconditions wasemployed inrandom order at each trial.Seven
condi-tionswere repeated 24time$inrandom order foreach
session
(168
triaTs).APParatus. The apparatus was identicaltothat in
Experiment
1.
Procedure. Each subject performed 35 practice
trials
followed by 168experimental trials.AII obser-vations were made monocularly, with the other eye occludecl by an eye patch. The subjectjudged
the perceived amount ofdepth
relatiye tothehorizontaldiameter on a 2-D image planeinthesame way as in
Experiment
2,
Results
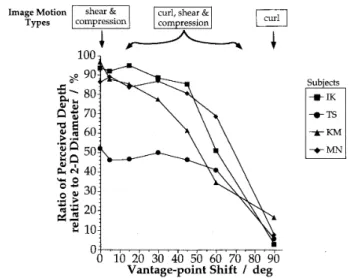
The amount of the perceiveddepth didnot change
much at O'v30deg vantage-point conditions and
de-creasecl monotonically at
30--90
deg
conditionsexcept
for
one subject:KM
(Figure
6).This result is[emwhp[rauTblS:Iil
::/A'S,h.:a,i.g
LNi
n-yAyi
Sub'ectst・]KtTS-tKM-t-MN.
o lo 2e 3o 4o so 6o 7o so go
Vantage-point ShiftIdeg
Figure6. The results of Experiment 3
The abscissa indicates the amount ef
manipulated vantage-point shift
frc)m
the hori-zontal arc on the aspect graph. The ordinateindicatesthe estimated ratio of depthrelative to
the
2・
D
horizontal
diameter,
Princip]eforRotating
Spherical
Surfacc 17differentfrom thatinthepaired-dotexperiment
(see
Experiment 2 and Figure4),
in
that thereis
lloexplicit peak at 5'-30deg conditions.
Loomis
andEbv
(1989)
andLiter
et al.(1993)
showed a monotonically
decreasing
function
in
the entire range of vantage positionsfrorn
O to90
deg,
which isstilldifferentfrom
ours.The
difference
is
atthe OA--30deg conditions ;we have a relutively flat
curve hcre. Loomis ancl Eb},
(1989)
proposed therelative-motion
hypothesis
that thedepth
fromrnotion is
perceived
by thecrude anclheuristic
way ofusing the amount of relative-motion components on
2-D images, Their results were consistent with the
predictienby thishypothesis.
By
considering theresu]ts of E.xperiment 2 and ofLoomis
andEby
(1989),
thepresentresultseems tobe
intermediate
between
thepredictionsby
thegeneric・view principleund that
by
therelative-metionhypoth-esis. Inother words, thepresent result coulcl not be
explained solely by the generic-view principre,but
could well
be
if
thegeneric-viewprincipleiscombinedwith therelative-motion
hypothesis.
We
willdiscuss
this
further
in
theGeneral
Discussion.
General
Discussion
The
effects of the vantage-point mantpulation onhuman il-D motion/structure perception were
inves-tiR.ated with twe typesof stimuli : the paired and the
unpaired random
dots
on spherical surfaces(see
Figure1and Footnote 1inIntroductionfc)rtheexact
definitions>.
The results were predictedby
thegeneric-view principle,InExperiment 1 and 2,the
"apart-position &
collineur" and the
'`offset-position''
image
motions that were genericviews e]icited theclearer 3-D motion perceptionthan theiLco-axis" and
the
"same-position&collillear"
image
motions that were accidental views. In Experiment 3,the `'curl, shear & compression" image motion that was ageneric view elicited clearer or more 3 D motion
perceptionthan the
'Ccurl"
irnagemotion thatwas anaccidental view.
The
differences
between
the "curl, shear&
compression" and the"shear&
cc)rnpression"18 The
Japanese
Journalof
PsychonomicScienceVol.
18,No,
1The
leyel
ofExplanation:relationship
toQian,
Andersen
&
Adelson's
studyv
Recently,
Qian,
Andersen and Adelson(l994a)
found
that thehuman
observer cannot perceive atransparent motion when a display has
finely-balaneed
opposing motion signals inulllocalregions(i.e.,
2"D
paired-dot motiondisplay,
where alldots
are pairedlecallyon 2-D image,and move inopposite
directionsfrom each other)
.
They also foundthattheVl cells of behaving monkeys do not generally
dis-criminate
between
theba]anced
motio'n pattern(nontransparent
motion) and theunbalanced motionpattern
(transparent
rnotion),but
Dv{T
cellsdo
<Qian
& Andersen, 1994). Accordingly, they proposed a
two-stage computational model of motion processing
fortransparentmoti,en perceptjon
(Qian,
Andersen
&
Adelson, 1994b). They successfully demonstrated
correlation among psychophysical effects, physiologi・ cal mechanisms, and themodel's predictionson
trans-parentmotion,
We
would Iiketoexplain thcirresurtsat another level. Their investigationsare at the mechanism level,whereas we offer a
fitnctional
and compulationat account."rhy
does
thevisual systeminterpretthe 2-D paired-dot motion pattern as the
nontransparent niotion,while the 2-D unpaired-dot
motion pattern as the transparent motion?
What
guarantees itsvaliclity or itsadvantage over other
interpretations?The generic-view principleseems to
offer an account
fer
thesequestions.It
isattheveryaccidental vantage point where we seethe 2-D
irnage
of paired-dotsthatare moving inopposite
directions
and sharing the trajectory though on differentdepth
planes!surfacesinthe 3-D scene. On the other hand,
at thegeneric vantage potntsthe
dots
on thedifferent
depthplanesfsurfacesin3-D scene move
in
unpairedstyle and
do
not share the trajector},in
2-D
image
motion. This may bethebiological
reason why the visua] system would liketointerpretimage motion astwo surfaces
in
depth,
on]yin
the]atterimage motion.This
principleoffers afunctional
accountfor
both
thelearningprocess and the competence of transparent
motion perception. This explanatien isnot at all
incompatible with studies by
Qian
et al.(1994a;
1994b) and
Qian
and Andersen<1994).
Rather,theirelectrophysiological
findingshnodel
offer afeasible
way ferthevisual $ystem toimplement the principle.
The
present study w・asinspired
by
theirstudy.We
employed the similar stimuli
(paired
and unpaireddots)to investigatethe $tructure from motion, and
showed the psychophysical
data
and thecomputatjonal account by the generic-view principle.
If
physiological studyis
conducted using the samestimuli as ours,
it
would inturnoffer themechanical-levelexplanation and contribute thetotal
understand-ingof thestructure-from-motion perception.
Relationship to Relative-motion Hypothesis
Some aspeets of our results, however, were not
explained
fully
by
the generic-view principle,andbetter explained
by
the relative-motion hypothesis,which states thatthe
human
visual svstemdetermines
.
depth
using the amount oi relative moion!shearcom-ponentsina crude and heuristicway. Yet,theresults
inthepresentstudy were not fullyexplained bythe
relative-motion hypothesis,either. For instance,the
function
that related3-D
perceptionwithvantage-peint shift was u skewed
inverse-U
shapein
Experi-ment 2 and a horizontal-to-deelineshape
in
Experi-ment
3,
The previousstudies showed anionotonicallydecreasing
linearprofilewith the rotation-axismanip-ulation that was equivalent toeur vantage-point shift
(Loomis
&
Eby,
1989;
Liter,
et al,,1993).
Their
resu]ts were consistent with thepredictionbased
onthe relative-motion hypothesisalone.
To furthcrcompare the predictionbased on the
relative-motion
hypothesis
with thatbased
on the generic-view principle, we conducted the simulatienby
applying the shear componellt efLoomis
andEby
<1989)
(see
Appendix fermore details)te our stimu]i.We also show the results of thesimulation with the
generic-view・predictionand the psychophysica]
data,
for
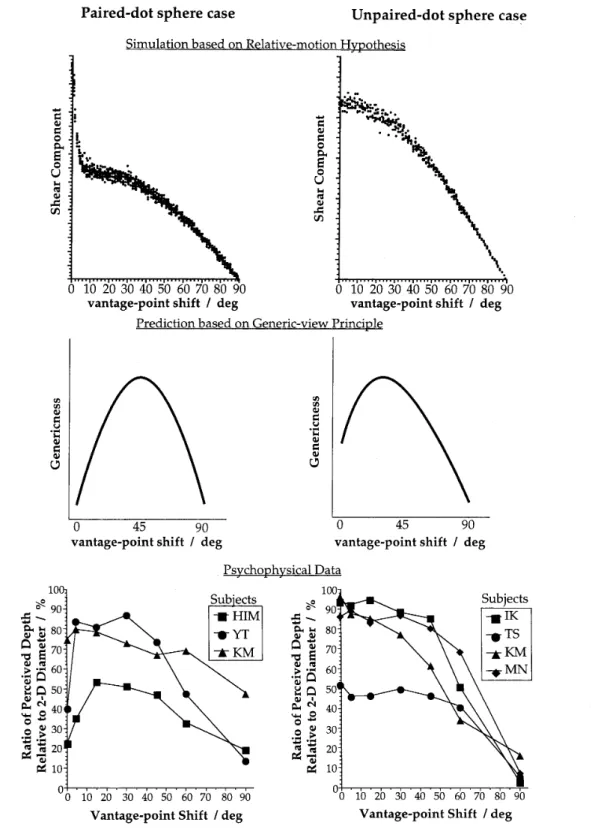
the paired and the unpaired cases, side by side(Figure
7).The
psychophysicaldata
obtainedby
thepresent stucly were intennediate between thesetwo
different
predietions,so that the data wouldbe
wellexplained
by
a combinationfsum of both predictions.The practicar
differences
of the presentresults ofours with the
data
ofLoomis
andEby
(1989)
rnightbe
causcd by themethodological differencesinuur study
such as the short-lifetime clisplayand the adopted
The Japanese Psychonomic Society
NII-Electronic Library Service
TheJapanesePsychonomicSociety
M. KiTAzA- and S.SHiMeJo:Generic-xriew
Paired-dot
sphere casePrincipleforRotating
Spherical
Surface
Unpaired-dot
sphere case19
SSiuudqtiQ!Lbase[LQ!L
rmulat b d RIt t H th-#egeptEeU-esosm O 10 20304050 6070 vantage-point shift l Prditinba 8090deg dnnn-1
1:gaoU-tuesm
O 1020304050 607080 90vantage-point shift / deg
Prini 1 thmo".u-o:dio utcoecu--utuapto O 45 go O 45 90 vantage-pointshift1deg vantage-pointshift/deg
p
thhIDtt
1eg
tu aeg
tu es・b
b'
-i
'n"
un
un
dii
di
rvi o-.e.
.!
.-o.
,! esX
M-e ntes
i'
pt atVantage-point Shift ldeg Vantage-point Shift 1deg
Figure 7. [['op:The results of sirnulation
based
on the relative-motionhypothesis
for
the paired・dot(I.eft
column) and theunpaired-dot
(Right
culumn) cases.We
calculated`shear'
according to Loomis ancl Eby
(1989)
for
every one degree of vantage-point shift from O deg to 90 deg. )vliddle:The predictionsofgenericness from the aspect graph. Bottom: The psychophysical
data
from
Experiment
2
(Lcft)
andExperiment 3
(Right).
'
were employed enly
in
our experiments.inthefigure,we interpolateamong threecategorical
We
must note thatthegenericnesswas tentatively views and those values. Though Freeman(1994)
defined
as continuously(quantitatively)
changing showecl the way of quantifyingthe genericncssinthe20
The
Japanese
Journalof
PsychonomicScience
Vor.
18,
No,
1
foundthe way of quantifying thegenericness
in
the3'
D motion perception.
W'e
could intheoryquantifythegenericness,but thisneeds furtherinvestigations.
Integrated Framework & Bayesian Inference
theory
A combination of the relative-motien
hypothesis
and the generie-view principleseems towell explain
our data inthe presentstudy, The relative-motion
hypothesiscould beunderstood by assuming the
rigid-ityconstraint ina broad sense. The relative motion or shear component
in
the2D
image
would leadto3-D structurefdepth perception
if
the visual systemprefersthe more rigid structure over the non-rigid
relutive rnotion inthe 3TD scene.
Thus,
the relative-motion hypothesiscan be considered a natural con-straintbased
en theprior probability ofa3-D
scene7s property: rigidity.On
theotherhand,
thegeneric-ness lsconsidered a conditional probabilityof a 2 D
image given a 3'D scene
(Nakayuma
&
Shiinojo,
199Z; Freeman, 1994). Taken together, itis
suggest-ed thut the
human
vision oi structure-from-motioncan
be
explainedby
comb{ning thepriorprobabilityof a 3-D scene
(relative
motionlrigidity) and theconditional probability of a
2
D
view given a3'D
scene
(genericness>.
Itisconsistent with the idea that the Bayesian
inference
theoryis
a general framework forvision(Nakayama
&
Shimejo,
1992 ;Freeman, 1994;Knill& Richards, 1996;
Knill,
Kersten
&
Yujl]e,1996).The visual processing ean
be
formulated
asfollow-illg:
p(sll)
-・
P(IIi7I.pl
.(s)
where
S
means a scenein
the realworld and Imeansan image as visual
input,
"Je
can treatP(l)
as anormaHzation constant, so thatwe have
p(sll)ocp(IIS)p(S)
Here,
P(S)
is
aPrior
of agiven scene. Thedistribu-tion
P(S)
isthe prior probabilit}, ofdifferent
collec-tionsof scene propertiesthatare actuall.y occurn'ng in
our enviromnent.
On
the otherhand,
p(llS)
is
aprebab{litydistril]utionspecifying therelutive
proba-bility
of obtainingdifferent
images frum the scene, i,e., the
gdeelihood
.fltnction
for
S. The naturalcon-straints such as rigidity or smoothness are considered
priorprobabilitiesofspecificscene propertiesthat are
actually occurring and not negligible inour ecologi-cal environrnent, while the
genericnessfaccidental-ness of images isconsidered conditional probability
(likelihood)
forimages duringtheobserver'slocomo-tion.Thus,these are incorporated
into
thefollowing
equatlon:
p(SiJ)-p(IIS)p(S)
=(genericness
of I)
'(natural
constraintfor
S)
Moreover, we argue that
it
depends
on thesituationhow the generic-vie-,principleinteractswith other
natural constraints. We specu]ated that the
generic-view principle works with other constraint$
depend-ingon thesituation, and
has
an advantage especiallywhen the available
information
is
impoverishedl
deteriorated
and ambiguous,lt
wouldbe
reasonableto assume that the visual system isvery sensitive to
thequalitativechange ef
2-D
images with the slightvantage-point change when the
informatien
islim-itecl,Inthe previousstudies, thegeneric-view
princi-ple was successfully applied to such situationsl scenes:e.g., a single straight bar
(Kitazak{
&
Shimojo,
1996),
untextured stereogram$(Nakayama
&
Shimojo,
1992),and subjective contour by sparseinducers
(Albert,
1993).
The
difference
of rcsultsbetween ours inExperiment 3and
Loomis
andEby's
cou]d be interprctedbythis aspect. Since the
short-Iifetimemotion empleyed in our study is more
impoverished
than thelong-Iifetime
motion employedintheirs,the generic・view effect should be greuterin
our stimulus conclitions.
The
findingthattheview-point
dependency
was strongerfor
the recognition ofwire-forms than forthat of surfaces and volumes also would support the idea
<Rock,
Wheeler,
&
Tuder,
1989
:Farah,
Rochlin,&
Klein,1994).
Appendix
NNie
app]ied the simulation of shear componentby
Lommis and Eby
(1989)
forour stirnuli inExperiment
2
(I'aired-dot
spherical surface) andExperiment
3
(Unpaired-dot
spherical surface). Three arbitrarydots
were randomly selected from a frame and their`shear'
was calcLilated
froin
theirpositions on the2
'D
image and those at the next frame
(Figure
8)."re
The Japanese Psychonomic Society
NII-Electronic Library Service
TheJapanesePsyc)onomic Society
)v'T.
KiTAzAici
andS.
SHi"・ioJo
:Generic-view
Frame1
dabl
b adcal c Frame 2 dab2 a dca2 dbcl b dbc2 cshear= log(ddbbC,2illdd".bb2i
)
+
log(ddC,a,2i
lldd."bbi2
)
'
Figure8,
The
definition
of the shear componentadopted
by
Looinis
and Eby(1989)
and used inFigure7
We
can calculate theshear componentby
usingthisformulatien when two
frames
(Frame
1and2)of threedots
(Dot
a, b,and c) are available.two successive framcs. Inother words,
if
even one ofthe three dots disappeared inthe next
frame,
a newset of three
dots
was selected randomry again.One-hundred
sets of three dots were randomlyselected and used
for
the shear calculation foreuchtrial, Ten trials were conducted foreach
vantage-pointcondition. We adopted 91steps of thevantage
pointevery one
clegree
frorn
O
deg
condition to90-deg
cendition(see
also the Methods of Experiments 2 and 3).
All
thecalculated shear components(relative
value) were plottedagainst the vantage-point shiftinthe top row of Figure7.
Acknowledgments.
A part of thisresearch was presented at the
Associ-ation
for
Research
in
Vision
andOphtha]mology
(ARVO),
Fort
Lauderdale,
FL, 1996(Kitazaki,
1996).NX・'e
wouldlike
to thank Dr.Johanna
MJ'eberforthecareful Ehglishcorrection, Preparation of thisarticle was supported
by
aGrant-in-Aid
from
MESSC,
Japan
to MK, and by a grant from the
Human
FrontierScience
Program toSS,
References
Albert,M. K. I993Parallelismand theperceptionof
illusoryconteurs, fftrrcoption,22,589'595.
Albert,
M.K., & IIoffman, D.D, Generic visions.ScientijicAmen'can, in
press.
Bennett,B,
M,,
&
Hoffman,
D.
D.
1985 Thetionof structure from fixed-axismotion :nonrigid
structure, Biogagical
Cvbemetics,51,
293
300.
Principlefor
Rotating
Sphericar
Surface
21
Bennett,B.M., IIoffman,D.D.,Nicola,
J.
E,,&
kash,
C.
1989Str'ucture
from
two orthographicviews of rigid motion.
fournat
tij'theQPticag
Sociedy'
oj'
A,nen'caA, 6,1052-1069.Biederman, I.1985 IIuman image understanding:
recent research and a theory.
Computer
Vision,
Cmphfcs.
and iniageProcessing,32,29-73.Binford,T.O. 1981 Inferringsurfaces from images,
ArtCiicialh7telligence,17,205'244.
Brainard,
D.H.,
&
Freeman,
W.T.
IY94 Bayesiantnethod ferrecovering surface and
illuminant
erties from photesensor responses. Hittman
IGsion,
wrsital
P,vcessing
a]id DigitalDisplccl,V,2179,364 376.Braunstein, M.L. I962 Depth perception
in
rotuting
clot
patterns:effects of numerosity andtive.
.fotfnv.at
(ijiElPEn'pizentalRsy'cholclg]y,,64,415'420,
・
Braunstein,M. L.,
&
Andersen,G.
J.
1984A
example to therigidity assumption in the visual
perceptionof structure from motion.
ftrcePtion,
13,
213-217.Braunstein,
M.
L.,
&
Andersen,
G.
J.
1986Testing
therigidity assumption :a reply toUllman. Rercoption,
15,641-646.
Braunstein,
M.L,,
Hoffman,
D.D,,
Shapiro,
L.R.,
Andersen, G.J.,& Bennett, B.M. 1987 Minirnum points and views for the recovery of
dimensional
structure.Jourvtag
of
Etpen'mental
Itlly'choltav
: Hunta7z Percoption and Peijbi7nance, 13,335-343.Farah,M.
J.,
Rochlin,R.,
&
Klein,
K,L.1994tioninvarianceand geometric primitivesinshape
recognition. CagnitiveScience,IS
(2),
325-344.Freeman, W.T. 1992 Expleiting the generic view
assumption to estimate scene parameters. Mfl'
Media
labo7uto7:v,
ViSionand Adi)deling7bchnicalRapo,t,196,1-29.
Freeman,
W.
T.
1994
The
genericviewpointtion
in
aframework
for
visual perception. Miture,368,542-545.
Gigus,
Z,:rvlalik,J,
1990Computing
theaspect graph
for
line drawings of polyhedrul objects. EEE
7bez]2saction
onR7ttern
Avaab'sis
and il4dclzineligence,12,113--122.
IIildreth,E.
C.,
Ando.
H.,
Andersen.
R.A.,&
Treue,S.
1995
Recovering
three-dimensionalstructurefrom
motion with surface reconstruction. Visicn
Researt,h,35,117 1:S7.
.
Hildreth,
E.C.,
Gryzwacz,
N.M.,&
Adelson, E,H.1990 The perceptual buildup of three-dimensional
structure
from
metion,krcoption
e
Aiychopiz.vsics,
48,
19-36.Hoffrrian,D.D.,& Bennett,B.M. I986The
22
TheJapane$e
Journal
ofPsychonomicScienceVoL
18,No.
1structure, Biolagic/at
Qvbenretics,
54,71'83.Johansson,
G.,&Jansson,
G. 1968 Perceived rotarymotion
from
changein
a straightline,
l]?rcoptione
Asp,choph.vsics,4,165
'170.
Kitazaki, M. 1996 Generic view principlefor ttD
motion perception: an upp]ication to volumetric
object.
ARVO,
Fbrt
Laudeidele,
Florid?i,
CLSA,
hivest4gative
Ciphthahnolag}'
e
Wsual Sctlences,37,s17'
9.Kitazaki,
M.,
&
Shimojo, S.1996`Generic-view
ple' fer
three-dirnensional-motion
perception:optics and jnverseoptics of a single straight bar.
PercePtion,
25.797'S14.Knill,D.C.,Kcrsten, D,,
&
Yuille,
A.
1996tion:A Bayesian formulationof visual perception.
InKnM, D.
C.
&
Richards,W.(Ed.>,
PerceptionasBayesian inference
(pp.I21),
bridge
University
Press.Knill,
D.C.,
&
Richards,
W',
l996,
Perception
as
Bayesian
inference.Cambridge:
Cambridge
versity Press,
Koenderink,
J.
J.,
&
vun Doorn, A.J.
1976The
larities
of the N,isual mappjng. BiolagicaJnetics, 24,51-59.
Kriegman, D.J.,
&
I'ence,J.
I990Computing
exactaspect graphs of curved objects: selids of
tioii.Inte7viationag
fournal
qfComPttter
VZsion,5,119-135,
I.iter,
J.
C,,
Braunstein,M. L.,&
IIoffman,D.D. 1993Inferringstructure
from
motion ifltwo-view andmultiview displays,Percention,22,I441-1465.
Longuet-IIiggins,II.C.198r A computcr algorithm
for
reconstructing a scenefrom
two projections.IVhttt,e,293,443--444.
Loomis,
J.M.,
& Eby, D.VLJ.1989 Relative motionparallax and the perception of structure
from
niotic]n. 717.eVM)ideshoPo'n
VJisual
illotion,fo'z,ine,
en.,
204
Lll,Lo",e,
D.
G,
1985
I)ercEPtual
otga"ieatioit and vist{alrec/ag"itian. Norwerl, Mass: Kluwer Academic
Publishers.
Malik,
J.
1987 Interpretinglinedrawings
of curvedobjects. Intemationag
.ibw'nal
of
Co"iputer
Vision,1,73-103.
]v'Ii]es.
IV.R.
1931 "tlovement interpretationsof thesilhouette of a revolving
fan.
AmericanJournat
of
k.v/cholag],,43,392'・I05.
Nakayama, K.,
&
Shimojo,
S.
1992Experiencing anclperceiving visual surfaces,
Scian'ce,
257,
1357-1363.
Ponce,
J.,
&
Kriegman, D.J.
1992Toward 3D curvedobject recognition from image contours. InMundy,
J.
&
Zisserman,
A.
(Ed.),
Ceomeim/c
invariance
in
tromPuter t.,ision(pp.408-439>.
Cambridge,
MA:
MIT Press.
Qian,
N,,& Andersen, R.A.1994Transparent motionperceptionas detectionof unbalanced motio'n
nals, 2, Physiology.
Jbfts7tag
of
AJIittrt)scn'exce,14,7367-7380.
Qian,
N., Andersen, R.A., & Ade]son, E.H. 1994a
Transparent
inotion perception asdetection
efunbalanced motion signals. 1.
Psychophysics.
nal
of
A'euroscience.14,7357'7366.Qian,
N.,
Andersen,
R.
A.,
&
Adelson,
E.H. 1994b
Transparent
motion perception asdetection
ofunbalanced motion signals. 3.Modeling.
Ibztnial
of
fVreuTvscie,ice,
14,7381-7392,
Ramachandran.
V.S.,
Cobb,
S,,
&
Ramachandran, D.19S8
Perception
of 3-D structurefrom metion:the role of velocity gradientsand
segmcntation
boundaries.
lkiToption
e
Ph),sics,44,390-393,
Richards,W. A.,Kocnderink,
J.
J.,
& Hoffman, D.D.
1987
Inferring
three-dimensionalshapes fromdirnensionalsilhouettes.
fottmaag
of
the ([ipticalSociety
of
Amenlca
A,
4,1168'l175.Rock, I.,Wheeler, D.,& Tudor, L.I989Can we
inc how objects Iook
from
other viewpoints?
C,'og-nitive
Ps.vchology.
21 185 210.Toclcl,
J.
T.
1984
The
perceptionof three-dimensionalstructure
from
rigid und nonrigid motion.ti.onasA.vch(iplp'sics,36,97-103.
Treue,S.,Andersen,R.A.,Ando, H.,
&
Hi]dreth,E.
C.
1995
Structure-from-metion:
PercepLual
evidenceforsurface interpolation.Visionfteseaivh,35,]39'
148.Treue,
S.,
Husain,
M.,
&
Andersen,
R,A. 1991Humanperception of structure from motion. Vision
Research,31,59'75.
Ullman,
S,
]979
The
interpretationof structure frommotien.
Proceedings
clftheRayal
Societ.y
of
Londbve
B,203,405-426.
U]]man,
S.
1984a Maximizing rigidity: thecremental recovery of 3-D structure
from
rigid ofnonrigid motien.
Pe7z,option,
13,
255
274.
Ullman,
S.1984b Rigidityand misperceived inotion.
fertroption,
13, 2]9-220.Ullinan,
S.
I986Competence,
performance, and therigidity assumptiun. Percoption,15,644-646.
W'allach,H.,
&
O'Connelr,D,N. 1953 The kineticdeptheffect. .lournal
of
IlrPe?i7nentag
R!1'cholqgy',
45,2e5-2I7・
.
Witkin,
A.
P.,
&
Tannenbauni,
J,
M.
1983,On
the
roleof structure
in
visiun. In Beck,J.,
Hope, B. &Rosenfeld,A.
(Ed.),
Httmaii and MachineVision