Frequency Domain Semi-Blind Signal Separation: Application to the Rejection of Internal Noises
4
0
0
全文
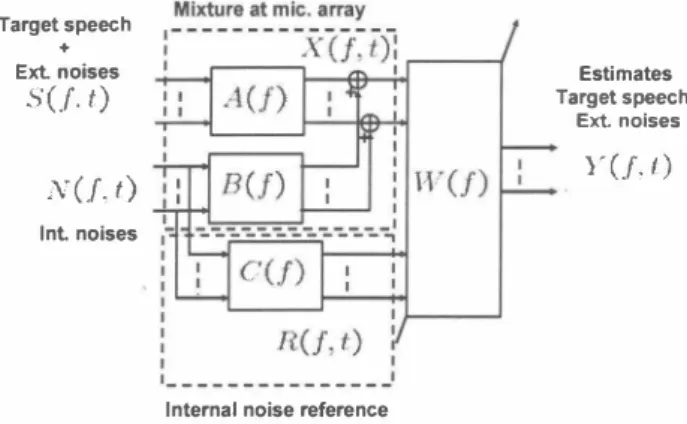
(2) t). The mutual information ofY (k)(f, is minimized by updat ing the matrix B(f) with the following rule (the 企equency and合ame indexes were dropped due to space limitation). Y(f,t) Fig. 2.. Mixture and blind separation at frequency bin f.. B (k l) B(k) +μ(1- <φ(y(k))y(k)H>t)B(k) (4) where < . >t denotes frame averaging andφ(-) denotes the vector of score functions. For Y [y1, .・・,Ypf this vector +. 2. FREQUENCY DOMAIN BLIND SIGNAL SEPARATION. φ(Y). Y(f, t)=B(f)V(f,t) =B(f)A(f"ß(f, t).. t). [�仏t) 1 _ r A(f) R(f, t) II -一 II ;:: --. (2). 0. I. ]. B(f) II I叩) ;')J.,( I II N(f, ;T�J; '!\ t)) I1. C(f). (5). t),. The observed signals and the sources are both partitioned of in two vecto瓜The first part of the observations X(f, size (p x T) with T the number of企ame, is a mixtures of both S(f, (p x T) and N(j, t) (q x T) whereas the second part of the observations R(f, (q x T) is only a function of N(f, t). This strucωre corresponds to the situation described in fig.l, with p external signals and q internal noises. In the following we use the terms references for R(f, and observations for X(f, t). A diagram of the mixing is given in Figふ The proposed demixer has a block structure of compatible dimensions with the matrices A(f), B(f) and C(f).. t). t). t). y(k)(j, t) B(k)(f) V(j, t). 3. PROPOSED METHOD. The goal of the proposed semi-blind approach is also to re cover some unknown signals when only some mixtures of these signals are available. However, contrarγto the fully blind separation case, we are also given an additional infor mation about the observed mixtures. We know that the mix ing process has the following block structure. where P(f) is a n x n p巴rmutation matrix and A(f) is a di・ agonal n x n matrix [2]. O As a consequence, in each frequency bin, it is possiゐble tω recover the c∞omp卯0叩n出E叩n附t岱soぱf S(げf, tの) u叩P tωo sωca此le叩dp戸ermuta司 t巾ion indeterminacy b防y 白命fin叫叫din暗gt批he unrrπ凶I gives s幻ta瓜tis託凶ti比call砂y i加nd巴pe叩ndent component臼s. This problem is often referred to as independent component analysis (ICA). To complete the separation, it is necessary to match the com ponents belonging to the same signal across all the仕equency bins before applying the inverse STFT otherwise th巴 time do main signals are still mixtures of th巴 desired signals. Since our proposed semi-blind method is derived合om the iterative 削FO:rv仏X method [3], we briefly present this method (see review [ 1] for r巴ference to other methods). In the frequency bin f at the kth iteration, the separation equation is. =. [ゆ(Yl)," . ,<þ(YpW. 3.1. Block structure. A usual assumption in BSS is that the∞mponents of S(f, are statistically independent in each frequency bin. Then the components ofY(f, t) are statistically independent if and only if B(f) is such that. P(f)A(f)S(f,. -�O -. l. t. t). t) =. ト三logP θ Yl (Yl)ぃ・ ・ ' 一三log θYP PyP (Yp)lT Yl. where P,仏(Yi) is the probability density function of Y・ i In practic巴 the score functions are unknown and should be esti mated合om the data or prior knowledge on the signal densities is available.. 、‘,ノ 〆, ,‘、. t) = A(f)S(f, t). =. =. where the n x n matrix A(f) represents the mixture, S(f, are the emitted signals at the fth frequency bin and denotes the frame index. Consequently when using a F points叩al ysis企ame for the STFT the convolutive mixture is replaced by F instantaneous mixtures and the goal is to estimate the components of the emitted signals S(f, in each frequency bin. In the fth 合equency bin, the estimates are obtained by applying an unmixing matrix B(f) to the observed signals (see Fig.2). Y(f,. =. is defined by. In acoustic, the observed signals received by a microphone array in a reverberant envitonment are convolutive mixtures of some signals emitted from different locations. The goal of BSS is to recover the emitted signals knowing only the ob served mixtures. In the frequency domain approach to BSS, a short time Fourier transform STFT is applied to the observed signals to get the frequency domain observations. Then the observed signals at the fth企equ巴ncy bin are. V(f,. =. t). t). [お::;ト[wjf)ml liml. Compared to the blind problem of same dimension, the num ber of coefficients to update is reduced Using the results in [2] presented in Sect.2, the compo nents of Y (1, t) and Q (f, are all statistically independent if and only if the matrices W1 (1), W2(f) and W3(f) are such that. t). W2(f) I I A(f) B(f) I W3(f) I I 0 C(f) I 一. _. 0 [川川. (3). 158. �. ]. 九(f)AA22(f) (f ) I. 。。 旬BA.
(3) where (dropping the frequency and frame indexes for Y(f,t) and Q(f,t)). Target speech +. Ext. noises. S(.f. t). Estimates. 官 ;江主h γ(J,t;). T. N(.f,t). 一. Inl noises. ムW叫吋JrPk刈k)(fげωf刀) = (I- <φ(がりが)H>付1k)(f). It(fj)i. The合equency domain signals are approximately circular be cause they were obtained by a STFT. For a circular random variable ν= Iyleiargy we have. Internal noise reference Fig. 3.. ゆ(ν) = φ(Iyl)ei argy. 810ck structure of the mixture.. Thus the unknown score functions can be estimated合om the data using a kernel based estimate of the score function of their modulus. After the semi-blind separation is performed in all the合e quency bins, the permutation resolution is also simplified be cause of the block structure.. where P1(f)(P x p)加d P2(f) (q x q) are permutation matri ces and A1(f)(P x p) and A2(J) (q x q) are diagonal ma trices. Consequently it is possible to estimate the compo nents of S(f, t) and N(f,t) by updating W (1), W2(f) and I W3(f) until the components ofY(f,t)叩d Q(f,t) are all sta tistically independent (Note that an echo canceler [4] cancels the contribution of N(f,t) in X(f, t) but does not recover. 4. EXPERIMENTAL RESULTS. S(f,t)).. To demonstrate the importance of the intemal noise reference we performed some experiments mixing the noise recorded in a train station as external noise and a synthetic non stationary noise as internal noise. The impulse response of the train sta tion hall was also measured for a speaker at 50cm in front of a four microphone array (inter mic. spacing is 2.15cm). 200 Japanese sentences of different 1巴ngth were used as speech signals (2s to 14s at 16kHz from the介�AS database [6]). The observed signals are obtained in two steps. First a speech signal convoluted by the impulse response is mixed with the recorded noise. The SNR in this mixture is called SNR ext. Then the mixed speech and external noise is mixed wi出the internal noise that is filtered by a low pass filter. The SNR for this second mixture is SNR int. We also filter the internal noise to obtain the reference. In all experiments we compared the iterative INFOMAX approach (blind) to the proposed approach (semi-blind). The STFT is performed with a 512 points hanning window with 256 points ove巾p. Th巴mat巾e岱s B(げ1)訂巴inωi t討ity in all f合k尚equ巴 叩ncy bins then 20∞o iterations are pe釘rfiおormed W山it出h叩 adaptation s坑te叩pμ= 0.1. The s叩pe白ech signal is s印e lected out of the separated c∞ompon巴nt臼s in all the fì仕r巴quency bins using th巴 same method for both approach. The INFO MAX method considers the reference signal as a fifth ob servation. Then both algorithms have the same amount of statistical information. The only difference is that the semi blind approach knows that the mixture has the block structure showed in Fig.3. The estimation quality is measured in term of noise re duction rate (NRR) defined as the difference of the SNR for. 3.2. Proposed algorithm. The proposed semi-blind separation method uses the mutual information of Y(f,t) and Q(f,t) to measure the statisti・ cal independence of their components. The criterion is opti・ mized by an iterative gradient descent on the matrices W1(f), W2(f) and W3(J). At iteration k, we have the following unmlxmg system. ドQ伏)(k)(f,t) 卜. I. (f,t) 一 1. |l. wl�ω り )ω X(fj) 0 WJk)(f) 1 l R(J,t). l. To obtain the update rules for these matrices we rewrite the update rule in the blind case eq.(4) with the proposed demixer structure. 叫吋叶r附糾叩川川+1刊1り川 川)( O WJrk糾k+1刊1川f) 1-一| [. WJrk+I円f) ,φ(Y( め (f,t)) l,Y (刈(f,t) 1 H \ 一μハ(� lp+ Q-<""' 1 φ(Q(k)(f,t))J l Q(k)(f,t)J /t J 叩川 糾 +附w 川刊叫 lk+1り町 )(川 f 昨 吋 O WJrk糾叩+1川1) Then the update rules for the matrices W1(f), W2(f) and W3(f) are extracted (A semi-blind method for instantaneous r. ム吋)(f) = (Iー<φ(Y伏))が附>t) wlk)(f) ムWJk)(f) = (I- <<Þ(刊))y(k)H>村'Jk)(f) (<φ<Þ (YσμY戸刊刊(伏刷切k刈). O. �. �. x[. mixtures in the time domain uses the s創ne approach to get the update rules in [5]). The update rules for the matrices have the following form. W}k+1)(f) = W?)(f) +μムwjk)(f). 159. nwd tEム 唱aA.
(4) 12. ,。. ,。. 百. 8. e. i:. Unproc.. 口. 。暗. 81ind. 口. �n..[te]. .... (c) SNR ext. 20dB. (b) SNR ext. 15dB. (a) SNR ext. 10dB. B. lind 是E. .0. o �・ LJ ,..,. •••. S同性roll'. ...,. &測B. (d) SNR ext. 10dB. SNR皿[OIl'. 以到B. .... "". S明rt.(,咽. (f) SNR ext. 20dB. (e) SNR ext. 15dB. Fig. 4. Noise r蹴reduction。恨R) and word accuracy for different SNRs.. 6. REFERENCES. the speech estimates (after processing) and the SNR for the observations (before processing). Consequently, a positive. [1] M.S. P edersen et aI.,. NRR means that the speech estimate quality is improved. Fig. “'A survey of convolutive bJind. ures 4(a), (b) and (c) show the NRR for mixtures at different. source separation methods,". SNRs (averaged on the 200 test signals). The second measure. Speech Communication, 2007.. of performance is the word accuracy for a continuous speech. [2] P. Comon,“Independent component analysis,a new con. recognition task.η1巴 speech recognition conditions are given in table 1 and the results in Figs. 4(d),(e) and. Springer Handbook on. cept 7," Signal Processing, vol. 36, pp. 287-314,1994.. (η.. The blind method is able to improve the speech signal but. [3] A. 1. Bell and T. 1. Sejnowski,“'An information maxim. using the block structure gives the advantage to the s巴mi-blind. imization approach to blind separation and blind decon. method when the number of iterations is limited. The perfor. volution," Neural Computation, vol. 7, no. 6, pp. 1129-. mance of the blind method would increase if the number of. 1159,1995.. iterations is larger but in a real situation computation time. [4] 1. Benesty et al.,“'A better understanding and an improved. is limited. The performance difference is also larger for the. solution to the specifìc problems of stereophonic acoustic. shorter sentences.. " IEEE Trans. Speech Audio Process echo cancell:杭on,、 ing, vol. 6, pp. 156-165,1998.. Table 1. Conditions for speech recognition Acoustic model. I I. Acoustic model training. I 260 speakers. Task. Decoder. I. [5] M. Joho et al.,“Combined blind/nonblind source separa. 20k wo吋newspaper dictation. tion based on the naturaJ gradient," IEEE Signal Process. phonetic tied mixture,. ing Letters, vol. 8, no. 8, pp. 236ー238,2001.. clean model [7]. (150. [6] K. Ito et al., “Jnas: Japanese speech corpus for large. sentences/speaker). vocabulalγcontinuous speech recognition research," The. n江IUS ver 3.2 [7]. Journal 01Acoustical Society 01Japanパ01. 20, pp. 19ι 206,1999. [7] A. Lee et al., “Julius - an open source real-time large vocabulary recognition engine,". 5. CONCLUSION. 1691-1694,2001.. In this paper we proposed a semi-blind separation approach that operates in the合巴quency domain. The method easily incorporates the information given by additional sensors to the BSS based approach. Experiments showed that this can be very benefìciaJ in a hands-free speech recognition scenario.. 160. EUROSPEECH" pp.. ハU つ臼.
(5)
図

関連したドキュメント
Keywords: continuous time random walk, Brownian motion, collision time, skew Young tableaux, tandem queue.. AMS 2000 Subject Classification: Primary:
The damped eigen- functions are either whispering modes (see Figure 6(a)) or they are oriented towards the damping region as in Figure 6(c), whereas the undamped eigenfunctions
In Section 13, we discuss flagged Schur polynomials, vexillary and dominant permutations, and give a simple formula for the polynomials D w , for 312-avoiding permutations.. In
“Breuil-M´ezard conjecture and modularity lifting for potentially semistable deformations after
Then it follows immediately from a suitable version of “Hensel’s Lemma” [cf., e.g., the argument of [4], Lemma 2.1] that S may be obtained, as the notation suggests, as the m A
This paper presents an investigation into the mechanics of this specific problem and develops an analytical approach that accounts for the effects of geometrical and material data on
The aim of this article is to establish new behaviors for the asymptotic of eigenvalues for the magnetic Laplacian in that case, and also to prove that the form-domain of
While conducting an experiment regarding fetal move- ments as a result of Pulsed Wave Doppler (PWD) ultrasound, [8] we encountered the severe artifacts in the acquired image2.
