Voice Conversion Algorithm Based on Gaussian Mixture Model with Dynamic Frequency Warping of STRAIGHT Spectrum
4
0
0
全文
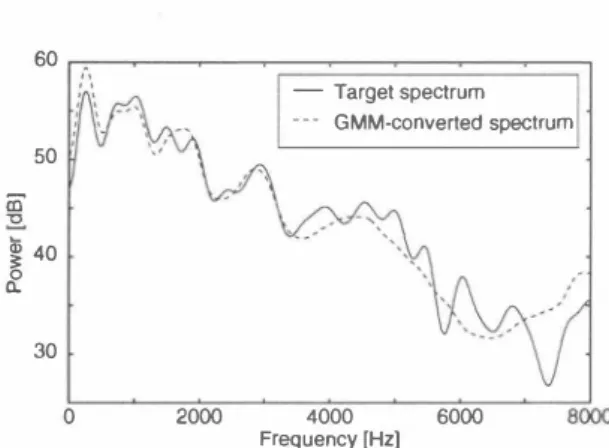
(2) 60 一一Target spectrum 一ー GMM叫converted spectrum. 50. { ∞ てコ. 』. � 0. 40. a. 30 o. 20∞. 4000. Fr<問uency. 60∞ [Hz). Figure 1: Spectrum converted by the GMM・based voice conversion algorithm (“GMM・converted spectrum")加d spectrum of the target speaker (“百rget spectrum") where p�z) 阻dμj官) denote the me阻 vectors of cl蹴i for the source副加get speakers. :E �zz) denotes the covari ance ma位以of class i for the source speak低 利 I/Z) denotes the cross-covaria且ce matrix of class i for the source and tar get speakers. In this paper, we出sume that these matrices are diagonal. In order to estimate 抑制御rs (αhμjz),μj官), 科目), :E �I/Z)), the probability distribution of the joint vectors z = [:1:T , Y T]T for the source and target speakers is represented by the GMM [6]. These parameters are estimated by the EM algorithm. 3.2. Application of GMM-based AIgorithm to STRAIGHT The cepstrum of the smoothed spectrum analyzed by STRA IGHT is used as an acoustic feature. In this paper, the cepstrum order is 40 (the quefrency is 2.5 ms, and the sam pling frequency is 16000 Hz). In order to perform voice conversion, the 1 to 40-th order cepstrum coefficients 紅e converted, and the O-th order cepstrum coe侃cient, which corresponds the signal power, is kept as the value of the source speaker. Figure 2: GMM-based voice conversion algorithm with dy namic f白quency warping. 合equency wむping [7][8]. In this technique, the coπespon dence between the original frequency砿is姐d the converted frequency axis is represented by the warping function. This function is calculated as the path which minimized the nor malized spectrum distance between the STRAIGHT log spectrum of the source speaker and the GMM・based con verted log spectrum. 4.2. Conversion of Spectral Power Conversion-accuracy on speaker individuality with the dy n釦lic合equency warping is worse than that of the GMM based algorithm because the spectral power c担not be con verted. To convert the spectral power, we newly propose the technique to add the weighted residual spectrum which is the djfference between the GMM-based converted log spectrum and the dyn釦lic-frequency-w紅ped log spectrum. By using this technique, we can recover the conversion accuracy on speaker individuality. In the proposed algo回 rithm, the converted spectrum Sc(f) is written部 IScω1 = exp[lnlSd的1+ω(InlSg的I-InISd的1) ], 0壬ω三1,. 3.3. Shortcoming of GMM-based AIgorithm In the GMM-based algorithm applied to STRAIGHT, qual ity of converted speech is degraded because the converted spectrum is exceedingly smoothed by the statistical aver aging operation. Figure 1 shows the example of the GMM based converted spectrum and the spectrum of the target speaker. As shown in this figure, the over-smoothing exists on the GMM-based converted spectrum. 4. GMM-BASED VOICE CONVERSION ALGORITHM WITH DYNAMIC FREQUENCY WARPING OF STRAIGHT SPECTRUM. (4) (5). where Sd(f)阻d 為的denote the dynamic-frequency-warped sp配trum and the GMM・based converted spectrum respec tively. AIso, w denotes the weight for a residual spectrum. The variations of converted spectra which correspond to the different weights for a residual spectrum are shown in Figure 3. In this paper, evaluation experiments are performed to 凶vestigate effects by the weight for a residual spectrum. In the experiments, we used not only the weights of the constant value but also the frequency-variant weights which change on each f民quency槌follows. In this paper, we propose the GMM・based algorithm with dynamic frequency warping to avoid the over-smoothing. An overview of the proposed algorithm is shown in Figure 2.. 叫 (f) ニ. 4.1. Dynamic Frequency Warping Wl (f) =. In order to avoid the over-smoothing of the converted spec trum, spectral conversion is performed with the dynamic. { fs f. 0三f<. l - ï.' + 2. f fl �ï.;.' - l. +1. 2. す 三f<ん 0三f< 2 T 壬f<ム �. ,. (6). �. ,. (7). 凸δ 内ノω 句lム.
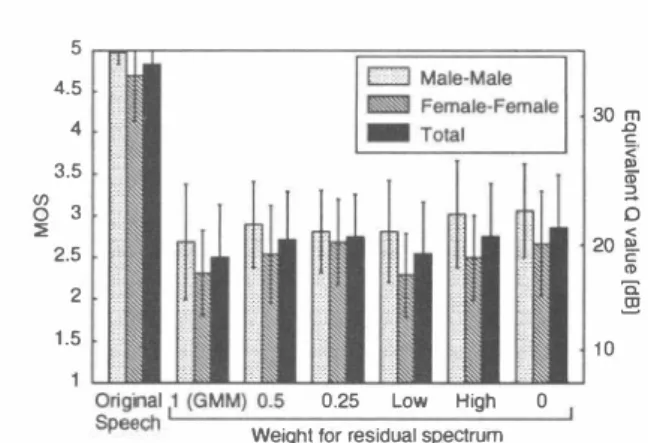
(3) ] 吉田 o c 一 ω 20〈 0 m -〈 c a m nu 巧'』 nu qu. 5 4.5 4. 』 @ ED 仏. 3.5 3 8 2 2.5 2 1.5. 40. 2000. 4000. Frequency [Hz]. 6000. 8000. Figure 3: Variations of converted spectra which correspond to the different weights for a residual spectrum.. 四. o. 副市 h n H げ g@ E明 P F i w po. 30. 10 0.25. Low. High. 0. Weighl for residual spectrum. Figure 5: Relation between the weight for a residual spec trum釘ld speech quality.. 5 4 3 唱2 � 1. 0 0.. 。. -2 2000. 40∞. Frequency. [Hz]. 60∞. 8000. Fi伊re 4: Residual spectra weighted by the f同quency variant weights which increase as the frequency is high (“High-weighted residual spectrum") and the frequency is low (“Low-weighted residual spectrum"). where fs denotes the sampling frequency. The residual sp民tra weighted by those frequency-variant weights are shown in Figure 4. For example, if we use the weight Wh (f) which increase as the frequency is high, the converted spec・ trum is more close to the GMM・based converted spectrum in the high-frequency regions. 5. EVALUATION EXPERIMENTS In order to evaluate the performance of the GMM-based algorithm with dynamic企equency warping, we performed experiments on speech quality and speaker individuality. We also investigated effects by the weight for a residual spectrum. The number of Gaussian mixtures was set to be 64, and the釘nount of training data was set to be 58 sen tences. The male-tcトmale and female-to-female voice con version were performed in each experiment. As for the回urce information, the average of 10含scaled fundamental frequencies of the source speaker was converted to that of the target speaker. The prosodic dynamic char a瓜eristics between two speakers were not considered. 5.1. Evaluation Experiment on Speech Quality In order to evaluate the quality of the conve巾d speech by the proposed algorithm, the subjective evaluation experi ment was performed. Eight listeners participated in the experiment. An opinion s∞re for evaluation was set to be. a 5-point scale (5・ excellent, 4: good, 3: fair, 2: poor, 1: bad). Three sentences which were not included in the training data were used to evaluate. The experimental result is shown in Figure 5. Eπor bars denote standard deviations. The converted speech quality by the proposed algorithm is better than that of the GMM-based algorithm (the weight is 1). About the weight for a residual spectrum, the converted speech qual ity without a residual spectrum (the weight is 0) is best. Also, the converted speech quality with the weight which increase as the合equency is high (“High") is better than that of the weight which increase as the frequency is low (“Loザ' ). When we use the weight “Low", the converted spectrum is smoothed exceedingly in the low-f同quency re gions. As this result, it is considered that the speech quality is degraded by the over-smoothing of the converted spec trum in the low-frequency regions. 5.2. Evaluation Experiments on Speaker Individuality 5.2.1. Objective Evaluation Experiment In order to evaluate the conversion-accur配y on speaker in dividuality of the proposed algorithm, the objective evalua tion experiment was performed by the cepstrum distortion (CD) between the converted speech and the target speech. Ten sentences which were not included in the training data were used to evaluate. The experimental result is shown in Figure 6. CDs by the proposed algorithm is worse than that of the GMM based algorithm (the weight is 1). About the weight for a residual speむtrum, CDs increase as the weight is more close to O. When we use the weight which increase as the 合equency is high (“High-weightedつ, the deterioration of CD is the same as that of using the weight which is 0.5, and the converted speech quality (“High") is better than that of using the weight which is 0.5 as shown in Figure 5. 5.2.2. Subjective Evaluation Experiment In order to ev乱luate the conversion-accuracy on speaker in dividuality of the proposed algorithm, the subjective evalu ation experiment (ABX test) was performed. Eight listen ers participated in the experiment. In the ABX test, A and B were the source and the target speaker's speech, and X was either the converted speech as. nHu n〆“ 司『ム.
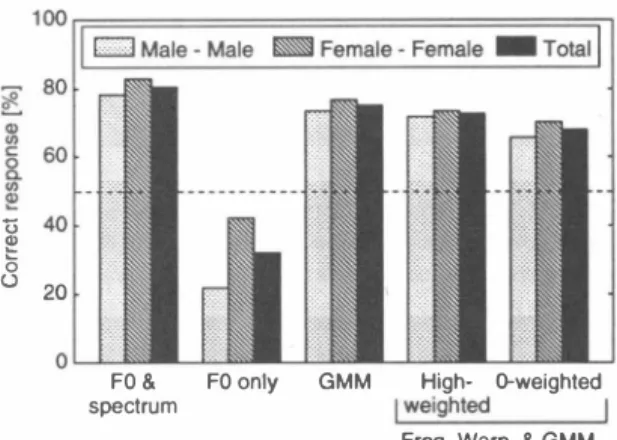
(4) 3.8 3.6. éiì 3.2. 司. 8. 3. -由-. l. 2. 6. F一一一一一一一一一一. 2.4. -、島�. 0. 0.2. �ミ--. ・- 一一一一一一一一 でQ: 腎寸ごー)C二 J支で ご 長 二. 《U 内ζ. 2.8. u o ヒ00. Original speech 01 sou陀e (Male) -)(- Converted speech (Male-Male) 一一H句作weighted (Male-Male) ー Original speech 01 source (Female) 〈トConverted speech (Female-Female) - High-weighted (Female-Female). 3.4. 二 見: 二 ー 。. 0.6 0.8 0.4 Weight lor residual spectrum. FO & s�ctrum. FO only. GMM. Figure 6: Relation between the weight for a residual spec・. O-weighted. Fr,伺. Warp. & GMM. trum and CD: Cepstrum Distortion.. I. Fi尽ue 7: Correct response for speaker individuality.. follow,. results, it is clarified that the converted speech quality is. ・converted speech by the GMM-based algorithm. better th担 that of the GMM-based algorithm, and the. .“GMM" . ,. conversion-accuracy on speaker individuality is the same as that of the GMM-based algorithm in the proposed method. • converted speech by the proposed algorithm without. with the properly-weighted residual spectrum. . a residual spectrum. .“O-weighted'九. • converted speech by the proposed algorithm with the. weight which increases as the frequency is high. . . "High weighted" ,. 7. ACKNO W LEDGEMENT This work wぉpartly supported by CREST ( Core Research for Evolutional Science担d Technology) in Jap加.. • synthesized speech by converting of the average log. 8. REFERENCES. scaled FO・・-“FO only" ,. [1] H. Kuwabara, and. • synthesized speech by converting of the average log. on speaker individuality when conversion of spectra was Listeners were asked to select either A or B. X.. as. Y.. Stylianou, O. Cappé, and E. Moulines,“Statistical. ROSPEECH, Madrid, Spain, pp. 447-450, Sept. 1995. [3]. cluded in the training data were used to evaluate.. Y.. Styli組ou, and O. Cappé, “A system voice con・. version based on probabilistic classification 阻d a. The. harmonic plus noise model," Proc. ICASSP, Seattle,. conversion-accuracy on speaker individuality of the pro. U.S.A., pp. 281-284, May 1998.. posed algorithm without a residual spectrum (“0・weighted"). [4] H. Kawahara, “Speech representation阻d transfor. is worse th担 that of the GMM・based algorithm (“GMMつ. mation using adaptive interpolation of weighted spec・. However,明白n recover the conversion-accuracy on speaker. trum: vocoder revisited," Proc. ICASSP, Munich, Ger m加ly, pp. 1303-1306, Apr. 1997.. individuality by using the weight which increases as the frequency is high “ ( High-weightedη). In order to compare. [5] H.. Kaw油訂a, 1. Masuda-Katsuse, 担d A. de Cheveigné,“R忠structuring speech representations uト. these two algorithms “ ( GMM" and“High-weightedつ, we also performed another subjective experiment ( preference. ing a pitch-adaptive time-frequency smoothing担d 組. test) on speaker individuality. The result clarifies that the. insta且taneous・frequency-based FO extraction: possible. conversion-accuracy on speaker individuality of the prcト. role of a repetitive structure in sounds," Speech Com. pωed algorithm with the weight which increases as the. munication, vol. 27, no. 3-4, pp. 187-207, 1999.. frequency is high is the same as that of the GMM・based. [6] A. Kain, and M. W. Macon,“Spectral voice conversion. algorithm.. for text-to-speech synthesis," Proc. ICASSP, Seattle,. As shown in Figure 7, the conversion-accuracy on speaker. U.S.A., pp. 285-288, May 1998.. individuality of only FO conversion (“FO only") is insuffi. [7] H. Valbret, E. Moulines, and J.P. Tubach,. cient, and it can be improved by conve凶ing spectra.. transformation. using. PSOLA. technique,". 吋oice Proc.. ICASSP, S加 Francisco, U.S.A., pp. 145-148, Mar.. 6. CONCLUSION. 1992. In this paper, we propose the voice conversion algorithm. [8] N. M脱出, H. B阻no, S. K勾ita, K. Takeda, 担d F.. based on the Gaussian Mixture Model ( GMM) with dy. Itakura,“Speaker conversion through non-linear f時. namic企equency warping of STRAIGHT spectrum, and evaluate this conversion algorithm.. 1995. [2]. methods for voice quality transformation," Proc. EU. Two sentences which were not in. The experimental result is shown in Figure 7.. Sagisaka, "Acoustic characteris. Speech Communication, vol. 16, no. 2, pp. 165-173,. “FO & spectrum" was used to evaluate the conversion-accura勾F. being most similar to. Y.. tics of speaker individuality: control and conversion,". scaled FO and replacing the source speaker's spectra . & spectrum". with those of the target speaker. . “FO. perfect.. 州gh・. I W副ghted. quency warping of STRAIGHT spectrum," Proc. EU. We performed evalu. ROSPEECH, B udapest, Hungary, pp. 827-830, Sept.. ation experiments on speech quality and speaker individ. 1999.. uality, compared with the GMM・based algorithm. As the. ハu n〈U 句tム.
(5)
図
関連したドキュメント
We present a Sobolev gradient type preconditioning for iterative methods used in solving second order semilinear elliptic systems; the n-tuple of independent Laplacians acts as
Using right instead of left singular vectors for these examples leads to the same number of blocks in the first example, although of different size and, hence, with a different
В данной работе приводится алгоритм решения обратной динамической задачи сейсмики в частотной области для горизонтально-слоистой среды
At the same time, a new multiplicative noise removal algorithm based on fourth-order PDE model is proposed for the restoration of noisy image.. To apply the proposed model for
Debreu’s Theorem ([1]) says that every n-component additive conjoint structure can be embedded into (( R ) n i=1 ,. In the introdution, the differences between the analytical and
Then it follows immediately from a suitable version of “Hensel’s Lemma” [cf., e.g., the argument of [4], Lemma 2.1] that S may be obtained, as the notation suggests, as the m A
We study the classical invariant theory of the B´ ezoutiant R(A, B) of a pair of binary forms A, B.. We also describe a ‘generic reduc- tion formula’ which recovers B from R(A, B)
(1999) “A novel, quantitative model for study of endothelial cell migration and sprout formation within three-dimensional collagen matrices”, Microvasc. 57, 118 – 133) carried out
