放置自転車問題における因果関係を含む
LOD
の
半自動的な構築手法の提案
A Method for Semi-automatic Construction of Illegally Parked
Bicycle LOD with Causal Relations
江上周作
1 ∗川村隆浩
1,2古崎晃司
3大須賀昭彦
1Shusaku Egami
1, Takahiro Kawamura
1, Kouji Kozaki
3, Akihiko Ohsuga
11
電気通信大学大学院情報理工学研究科
1
Graduate School of Informatics and Engineering, The University of Electro-Communications
2
科学技術振興機構 情報分析室
2
Department of Information Planning, Japan Science and Technology Agency
3
大阪大学産業科学研究所
3
The Institute of Scientific and Industrial Research (ISIR), Osaka University
Abstract: Illegally Parked Bicycle (IPB) is an urban problem in Tokyo and other urban areas. To support the problem solving by applying Linked Open Data (LOD), Illegally Parked Bicycle LOD (IPBLOD) has been sustainably built by us. Also, we have estimated and complemented the spatio-temporal missing data to enrich the IPBLOD, which has consisted of intermittent social-sensor data. However, it was necessary to manually extract factors of the IPB from the Web document, when designing the LOD schema. Therefore, it is difficult to extract a wide range of factors. Thus, we propose a method to semi-automatically construct LOD including causal relations of the urban problem. Also, in this paper, we introduce our previous works and the extended results of estimation of spatio-temporal missing data.
1
はじめに
我が国では健康意識の高まりや環境問題への配慮な どにより,自転車保有台数が昭和 45 年から平成 25 年 までに 2.6 倍に増加している1.その一方で,駐輪場の 整備不足や違法性の認識不足などにより,放置自転車 の発生が後を絶たず社会課題・都市課題の一つとなっ ている. 放置自転車のような身近な社会課題をデータ駆動方 式で解決するためには,日々の問題発生状況のデータ 蓄積と構造化,およびオープンデータ化することによ る第三者の利活用促進が重要である.そこで,我々は 放置自転車の原因を調査して Linked Data のスキーマ 設計を行い,ソーシャルセンサにより観測された台数 情報を基に放置自転車 LOD2を構築した [1, 3].さら に放置自転車 LOD の活用により,撤去活動の支援,駐 ∗連絡先:電気通信大学大学院情報理工学研究科 〒 182-8585 東京都調布市調布ケ丘 1-5-1 E-mail: [email protected] 1 http://www.soumu.go.jp/menunews/s-news/94984.html 2http://www.ohsuga.is.uec.ac.jp/bicycle/dataset. html 輪場,自転車シェアリング施設,バス停等の最適な設 置場所の提示,都市設計の際の放置自転車シミュレー ションが可能になると考えている. しかし,ソーシャルセンサによる観測は不定期で行 われるため,収集されるデータには必ず時間的な欠損 が生じる.また,全ての範囲を観測できるわけではな いため,空間的な欠損(放置自転車が存在するが観測 されていない地点)も存在している.そこで,我々は放 置自転車の時間的・空間的な拡充を試み,ベイジアン ネットワークと数値流体力学を用いて放置自転車 LOD の時間的・空間的欠損値を推定し補完する手法を提案 した [2, 3, 4] これまでに提案した放置自転車 LOD の構築手法は, ポイ捨てや落書きなど放置自転車と同様に日常的に発 生する他の社会課題にも適用できる可能性がある.し かしながら,LOD スキーマの設計の際は Web 文書か らの人手による要因抽出を行う必要があったため,設 計に手間がかかり広範囲の要因抽出が困難である.ま た,今後様々な社会課題の LOD 化を視野に入れた時 に,社会課題の因果関係を LOD として構築しておく 10-01ことで,複数の社会課題の因果関係リンクをたどった 横断的な分析が可能になる.そこで,本論文ではこれ までの取り組みの紹介に加えて,放置自転車の因果関 係を含んだ LOD を半自動的に構築する手法を提案す る.具体的には因果抽出のプロセスにおいて,Web 文 書や行政のオープンデータをから自然言語処理を用い た因果単語の抽出を行い,クラウドソーシングによる 因果単語の絞り込みを行う.その後,クラス・インス タンスを設計し因果関係を構築する. 以下,本論文では,まず 2 章で因果関係を含む LOD の半自動的な構築手法について述べる.3 章で放置自 転車 LOD の時間的な欠損値の推定手法について述べ, 4 章で放置自転車 LOD の空間的な欠損値の推定手法に ついて述べる.5 章で関連研究について述べる.最後 に 6 章でむすびとする.
2
因果関係を含む
LOD
の半自動的
な構築
我々はこれまで放置自転車問題解決に向けてデータ を収集し,継続的に放置自転車 LOD を構築してきた. 放置自転車 LOD を構築するため,まず必要な要件を抽 出した上でスキーマを設計した.この LOD スキーマ 設計の手順を方法論としてまとめ,放置自転車と同様 に日常的に生じる社会課題の LOD スキーマ設計に適 用することを目指している.これまでの LOD スキー マ設計の方法論を次に示す. 1. ドメイン要件抽出 a. 対象とする地域課題をモデル化する既存オ ントロジーを選択 b. 検索エンジンを用いた記事検索 c. 記事からキーワードを抽出 d. キーワードのクラスタリング 2. スキーマ設計 a. 既存オントロジーを軸としてスキーマを設計 b. クラスタリング結果を基にインスタンスと プロパティと値の設計 この方法論では全てのステップが手作業によるもの であり,作業者の負担が大きいという問題がある.ま た,収集する Web 文書の数が少なく作業者一人の知識 に依存するため,対象とする社会課題の因果関係の抽 出に関してはカバー率が低いという問題がある.そこ で,本論文では社会課題の因果関係を含んだ LOD ス キーマを半自動的に設計する手法を提案する.また,本 手法を社会課題の因果関係を含む LOD スキーマ設計 の方法論として以下にまとめる. 1. 因果単語の抽出 a. 検索エンジンを用いた記事検索および収集 (自動) b. 収集した記事から因果単語を抽出(自動) c. 抽出した単語を基にワードクラウドを生成 (自動) d. クラウドソーシングによるキーワードの選 択(半自動) 2. スキーマの設計 a. 対象とする社会課題をモデル化する既存オ ントロジーを選択(手動) b. 既存オントロジーを軸として因果単語を基 にクラスを設計(手動) c. 設計したクラスを基にインスタンスを設計 (手動)2.1
因果単語の抽出
まず,対象とする社会課題名とその同意語を一番目 の検索語とし,“要因” の同意語を二番目の検索語とし て検索エンジンを用いた記事検索を行う.本研究では 放置自転車問題を対象とするため,一番目の検索語は “放置自転車”,“違法駐輪” を使用する.二番目の検索 語は “要因” とその同意語であり,日本語 WordNet の RDF データ [9] から “因子”,“素因”,“要素”,“導因”, “もと”,“原因”,“誘因”,“起こり”,“起り” を取得し て使用する.同意語として取得したが日本語文書にお いて使用頻度の少ないと考えられる,“factor”,“ファ クタ”,“エレメント”,“ファクター” に関しては,これ らの検索語がメインとして検索されてしまったため除 外した.本研究では検索エンジンとして Google を使用 し,Google Custom Search API3に「放置自転車 要因」のようなキーワードパラメータを与えて結果を取得 する.取得するファイルタイプとして HTML と PDF を別々に指定し,一番目の検索語と二番目の検索語の 全ての組み合わせで記事を 20 件ずつ検索する.HTML ページの場合はサイドバーやヘッダー・フッダーなどを 除いたメインコンテンツのみ抽出するために,Mercury Web Parser API4を使用する.このように検索語を複
数設定することで,対象とする社会課題の記事を広く 収集する.HTML と PDF を分けて検索した意図とし ては,社会課題の因果関係について言及している記事 を,行政の調査報告や議事録等と一般人の SNS やブロ グ等から満遍なく収集するためである.また,記事中 3https://developers.google.com/custom-search/?hl=ja 4 https://mercury.postlight.com/web-parser/
における社会課題名の出現回数が低い場合は,この後 の要因単語抽出処理でノイズが多く混ざってしまうた め,社会課題名の出現回数でフィルタリングを行う.こ のような記事は,例えば地域の抱える様々な問題(育 児,教育,医療,交通等)について全て述べた長文記 事が該当する.今回は,“放置自転車” または “違法駐 輪” の出現回数が合計 3 回未満の記事を解析対象外と した. 次に,収集した記事を一文ごとに分割し,文ごとに 形態素解析を行い名詞を抽出する.形態素解析には mecab-ipadic-NEologd5を使用した.この後の処理で あるクラウドソーシングによる要因単語選択の処理に おいて,ある程度意味が通じる名詞となるように,サ 変接続名詞の直前・直後に名詞がある場合はそれらを連 結して一つの名詞とする.例えば “駐輪料金” は通常 “ 駐輪 (名詞-サ変接続)” と “料金 (名詞-一般)” に分割さ れてしまうが,本手法ではサ変接続を結合して “駐輪 料金” とする. 次に TEXT2LOD[7] を用いて各文を RDF トリプル に分解する.TEXT2LOD は自然言語処理,ルール適用, 条件付き確率場により,与えられた文からチャンク(句) を生成し関係抽出を行い,主語,述語,目的語を Linked Data として生成する Web API である.TEXT2LOD から得られた結果に対して,以下の SPARQL を実行す ることで対象とする社会課題の要因を表す句を取得す る.取得した句の中に形態素解析を実行して得られた 名詞が存在する場合,その名詞を要因単語として抽出 する. S E L E C T D I S T I N C T ( str (? o2 ) AS ? v a l u e ) W H E R E { { S E L E C T ? s ? p W H E R E { ? s ? p ? o . f i l t e r (? p != < h t t p :// www . uec . ac . jp / p r o p e r t y / S E N T E N C E >) f i l t e r r e g e x ( str (? o ) , 二番目の検索語) } } O P T I O N A L { ? s ? p2 ? o2 . f i l t e r (? p2 != < h t t p :// www . uec . ac . jp / p r o p e r t y / S E N T E N C E >) } } 最後に抽出した要因単語の出現回数を重みとしてワー ドクラウドを生成する.図 1 に生成したワードクラウ ドを示す.出現回数が多いほど中心に位置し文字サイ ズが大きくなる.文字の色はランダムに決定する.こ のワードクラウドから放置自転車の原因として考えら れるものを 10 個選択するというタスクを設定し,クラ ウドソーシングによる要因単語の選択を行う.今回は 予備実験として 6 人の作業者に依頼した.作業者によ り選択された要因単語を図 2 に示す.今回はこのうち 2 人以上に選択された要因単語を使用した.また,図 2 のように “撤去頻度”,“撤去確率”,“撤去率” などの類 5 https://github.com/neologd/mecab-ipadic-neologd 図 1: 放置自転車の要因単語のワードクラウド 図 2: ワードクラウドから選択された要因単語 似の単語が存在することがある.このような場合は選 択した人数の多い単語に統一する.最終的に抽出され た放置自転車の要因単語は,“撤去頻度”,“同調行動”, “駐輪料金”,“時間的制約”,“施設”,“撤去保管料”,“ 設置方法”,“駐輪施設付近”,“環境要因”,“利己”,“ アクセス利用” である. 同様に因果関係の結果(以下,結果単語)に関して の抽出も行う.日本語 WordNet の RDF から “引き起 こす”,“惹起”,“もたらす”,“来たす”,“招く”,“誘 発”,“生み出す” などの同意語を取得し,これらを二 番目の検索語として要因抽出と同様の処理を行う.図 3 に結果単語に関して生成したワードクラウドを示す. このワードクラウドから放置自転車が引き起こすもの として考えられるものを 10 個選択するというタスクを 設定し,6 人の作業者に選択された結果単語を図 4 に 示す.最終的に抽出された結果単語は “盗難”,“都市 景観”,“交通渋滞”,“快適性”,“走行空間”,“撤去作 戦”,“公共サービス”,“妨げ”,“交通事故”,“犯罪”, “秩序” である.
2.2
因果関係を含むスキーマの設計
2.1 節で最終的に抽出した単語を基に因果関係を含む スキーマを設計する.まず,対象とする社会課題をモデ図 3: 放置自転車の結果単語のワードクラウド
図 4: ワードクラウドから選択された結果単語
ル化する既存オントロジーを選択する.本研究では放 置自転車をイベントとみなし,Event Ontology (EO)6
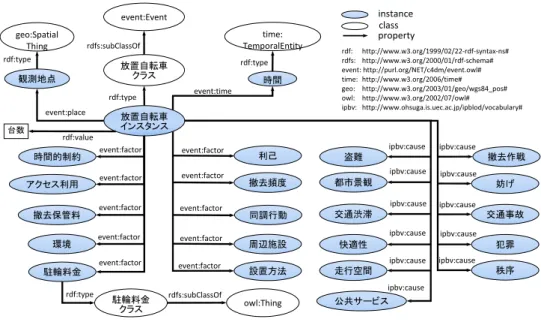
を選択した.次に,対象とする社会課題名のクラスを作 成し,EO における Event クラスのサブクラスとする. 次に,抽出した単語を基にクラスを作成し,因果関係 のプロパティでリンクする.EO には要因として factor プロパティが存在するためこれを再利用する.要因クラ スは factor プロパティの range として設定されている owl:Thing クラスのサブクラスとする.しかし,因果 関係の結果部分に相当するプロパティが EO に存在しな いため,cause プロパティを新たに定義してリンク付け する.また,place,time,agent,product,sub event プロパティを EO から再利用し,EO と同様の構造で設 計する.さらに,対象とする社会課題において重要で あると思われる項目がある場合,新たにプロパティと その値を追加する.放置自転車問題においては台数情 報も重要な項目であるため追加する.放置自転車 LOD のクラス要件を以下に記述論理で示す. 放置自転車⊑ Event 放置自転車⊑ ∃place.SpatialThing 放置自転車⊑ ∃time.TemporalEntity 放置自転車⊑ ∃agent.Agent 6 http://motools.sourceforge.net/event/event.html 放置自転車⊑ ∃product.Thing 放置自転車⊑ ∃sub event.Event 放置自転車 ⊑ ∃factor.(撤去頻度 ⊔ 同調行動 ⊔ 駐輪料金⊔ 時間的制約 ⊔ 施設 ⊔ 撤去保管料 ⊔ 設置方法⊔ 環境 ⊔ 利己 ⊔ アクセス利用) 放置自転車⊑ ∃cause.(盗難 ⊔ 都市景観 ⊔ 交通 渋滞⊔ 快適性 ⊔ 走行空間 ⊔ 公共サービス ⊔ 撤 去作戦⊔ 妨げ ⊔ 交通事故 ⊔ 犯罪 ⊔ 秩序) 放置自転車⊑ ∃number.Integer 次に各クラスのインスタンス部分を設計する.各ク ラスのインスタンスは実データを基に作成されるため, データとして取得することが困難な場合は LOD 化す る際にインスタンスを作成しない.最終的に設計した 放置自転車の LOD スキーマを図 5 に示す.各要因単 語・結果単語のクラス-インスタンス関係は例として駐 輪料金のみ示している.
2.3
LOD の構築
これまでの研究で,Twitter 上で位置情報,写真,ハッ シュタグを付けた放置自転車台数報告のツイートを募 集し,現在までに 1174 件の放置自転車の台数情報を収 集している.さらに,周辺施設の情報を Google Places API7と Foursquare API8から取得し,駐輪場の情報を東京都総務局および市区町村の Web サイトから収集し た [3].そこで,本論文で新たに設計した LOD スキーマ に従い,過去に収集した放置自転車に関するデータを LOD 化した.構築された放置自転車 LOD の一部を図 6 に示す.インスタンスレベルでは実際にデータを取得 可能なリソースのみ追加している.因果関係の結果に ついては事故や犯罪などの容易に取得できない,また は容易に関連付けられない繊細なデータが多く,今回 は追加を見送ることになった.構築したデータ全体は RDF データベースの Virtuoso9に格納し,SPARQL エ ンドポイント10を通して Web 上に公開している.ま た,データセット一式をオープンライセンスで公開し ている11.
2.4
LOD スキーマ設計の考察
因果関係抽出処理において,最終的に収集された要 因の記事数はリンク切れや画像 PDF を除いて 330 記事 となり,“放置自転車”,“違法駐輪” を合計 3 個以上含 7https://developers.google.com/places/?hl=ja 8https://developer.foursquare.com/ 9http://virtuoso.openlinksw.com/ 10http://www.ohsuga.is.uec.ac.jp/sparql 11http://www.ohsuga.is.uec.ac.jp/bicycle/dataset. html図 5: 放置自転車の LOD スキーマの一部 図 6: 実際に構築される放置自転車 LOD の一部 む文は 83 記事であった.また,要因単語を抽出した文 の数は全 64,676 文のうち 103 文であった.因果関係の 結果に関する記事数は 323 記事となり,“放置自転車”, “違法駐輪” を合計 3 個以上含む文は 57 記事であった. 結果単語を抽出した文の数は全 164,238 文のうち 94 文 であった.記事数が減った原因としては,Google 検索 において二番目の検索語を重視してマッチした記事が 取得されてしまう場合があるためである.特に因果関 係記述を多く含む医療関係の記事がノイズとして多く 取得された.今後は「“放置自転車の原因”」など,検 索語をスペースで区切らずにフレーズとして検索する ことで,この問題を解決できると考える. また,クラウドソーシングによる要因単語・結果単語 選択の一致度を算出するためにカッパ係数 [6] を計算し た.要因単語はワードクラウドの表示単語数 238 語に 対してカッパ係数は 0.464,結果単語は表示単語数 204 語に対してカッパ係数は 0.433 となり,どちらも中程 度の一致度が得られた.この結果から,要因単語・結 果単語の抽出結果およびワードクラウドの表示はある 程度妥当であったと考えられる. しかし,放置自転車の要因として考えられる盗難,駅, 駐輪場の設備(照明,ロック方式)などの単語は取得で きなかった.これは形態素解析と TEXT2LOD を用い た因果単語抽出処理と,クラウドソーシングによる因 果単語選択処理のどちらかで抽出漏れしていることが 原因である.前者の場合,TEXT2LOD で SVO に分割 する時に,要因について言及している部分が欠落する ことがわかった.これは,行政の発行する記事に冗長 的な言い回しが多く,一つの文が複雑な複文で構成さ れていることが多いからである.後者の場合,今回は 作業人数が少なかったことも原因の一つであるが,因 果単語抽出処理の段階で放置自転車以外の要因単語も 多く抽出されたことも原因であると考えられる.その 結果,放置自転車の真の要因単語の抽出回数が相対的 に減ることとなり,ワードクラウド上で目立たなくなっ た.これにより,真の要因単語が作業者に選択されづ らくなったと考えられる.今後は対象とする社会課題 の因果単語をより高精度に抽出するために,因果単語 の抽出ルールを新たに設定する必要があると考える. また,結果単語に関しては放置自転車により引き起 こされる問題と,放置自転車が与える影響が混在する という結果になった.今後は結果単語の分類を行い,適 切なプロパティでリンクする必要がある.
本論文で構築したスキーマとこれまでに構築してい た放置自転車 LOD[3] のスキーマを比較すると,スキー マ設計の段階では要因リソースと結果リソースの数が 大幅に増加している.しかし,これらのリソースは実 データとして取得できるものが少なく,LOD 構築の段 階ではこれまでの放置自転車 LOD と比べて要因リソー スの数が減少するという結果になった.そのため,ク ラスレベルでの因果関係分析に使用できる可能性があ るが,インスタンスレベルでの因果関係分析を目的と して使用することは難しい.今後は,現在データとし て取得することができないものについて,新たにオー プンデータ化するように行政に働きかける必要がある と考える.また,要因単語クラスと結果単語クラスの 粒度を,実データを取得できる範囲で統一化・階層化 する必要があると考える.
3
時間的欠損値の推定
放置自転車問題において,自転車の放置台数はソー シャルセンサにより観測されるため,各観測地点にお ける全ての時間帯の放置台数を観測することはできな い.すなわち,構築した放置自転車 LOD には時間的 な欠損が生じる.この欠損データを推定・補完するこ とで時系列的に密な LOD となり,データとしての有用 性が高まる.そこで放置自転車 LOD では,未観測日 時の放置自転車の台数をベイジアンネットワークによ り推定する.推定結果をもとに RDF グラフを構築し, 放置自転車 LOD に追加する.ベイジアンネットワー クとはグラフィカルモデルの一種であり,因果関係を 確率的に表現することで様々な推論を行う技術である. まず,放置自転車 LOD から放置自転車の要因を取得 する.放置自転車の要因は event:factor プロパティを辿 ることで取得できるリソースまたは値と仮定し,これ らをベイジアンネットワークにおける属性とする.2.4 節で述べた通り,本論文で新たに構築した LOD は要 因の種類がこれまでの放置自転車 LOD より減少して いる.そのため,時間的欠損値の推定に関してはこれ までに構築した放置自転車 LOD のデータを使用する. 使用する属性は,実際にデータとして取得することが できた観測地点,曜日,時間帯,降水量,気温,駐輪場 の日極料金,駐輪場の月極料金,可住地面積 1km2当 たり人口密度,自宅外通勤・通学者数(鉄道・電車), 周辺施設のタイプとした.ここで,周辺施設のタイプ は全部で 68 種類得られたが,これを全て属性として追 加すると属性過多となる.そこで,LinkedGeoData[14] オントロジーにおける上位クラスを取得し,これを属 性とすることで周辺施設の属性数を 46 種類にまで削減 している.各属性の集合は 観測地点名 Loc,曜日 Day, 時間帯 Hour = {1, . . . , 24},降水量 P recipitation = {0, 1, ...}, 気温 T emperature = {..., −1, 0, 1, ...},駐 輪場の日極料金 DailyF ee ={0, 1, . . .},駐輪場の月極 料金 M onthlyF ee ={0, 1, . . .},人口密度 Density = {0, 1, ...},自宅外通勤・通学者数 Commuters={0,1,...}, 周辺施設のタイプ 46 種 = {0, 1}, 放置台数 Num = {1, 2, 3, 4} である.放置自転車の台数 Num は自然分類(Jenks Natural Breaks)[15] を用いて 4 つに分類し, 台数の範囲は,0∼6,7∼17,18∼35,36∼100 となっ ている.この 56 次元のベクトル集合 O を入力データと して,時間的な欠損における放置自転車の台数をベイ ジアンネットワークにより推定する.ベイジアンネット ワークのライブラリとして Weka12を使用する.データ 数は 1174 件である.すなわち,1174 件のデータを学習 データとして,既知の観測地点の未観測日時における 放置自転車の台数を推定する.ベイジアンネットワーク におけるパラメータとして,探索アルゴリズム,確率計 算アルゴリズム,マルコフブランケット分類器の有無, 最大親ノード数,評価指標の項目を変更しながら実験を 行い,最も推定精度の高くなるパラメータを採用する. 最終的に,探索アルゴリズムとして LAGDHillClimber を使用,確率計算アルゴリズムとして SimpleEstimator を使用,マルコフブランケット分類器を使用,最大親 ノード数を 7,評価指標を BAYES とした時に,10 分 割交差検証の精度が 70.9%と最も高くなった. ベイジアンネットワークによる放置台数推定後に,推 定結果とその確率を用いて RDF グラフを生成し,放 置自転車 LOD に追加する.本研究では,各観測地点に おいて初観測日から最終観測日までの間で,午前 9 時 または午後 9 時に観測がされていない場合に,前述の パラメータ設定で放置自転車の台数を推定する.推定 値とその確率を基に次のような RDF を生成し,放置 自転車 LOD に追加する. @ p r e f i x ipb : < h t t p :// www . o h s u g a . is . uec . ac . jp / i p b l o d / v o c a b u l a r y # > @ p r e f i x b i c y c l e : < h t t p :// www . o h s u g a . is . uec . ac . jp / b i c y c l e / r e s o u r c e / > b i c y c l e : i p b _ { o b s e r v a t i o n p o i n t } _ { d a t e t i m e } ipb : e s t i m a t e d V a l u e [ rdf : v a l u e "0 -7" ; ipb : p r o b a b i l i t y " 0 . 7 7 2 " ^ ^ xsd : d o u b l e ] .
4
空間的欠損値の推定
放置自転車 LOD には時間的な欠損値だけでなく,空 間的な欠損値(放置自転車があるが未観測の地点)も 存在している.我々はこの空間的な欠損値を補完する ことにより,放置自転車 LOD を地理空間的に拡充する 手法を提案した [4].本論文ではこの手法について,実 験データを増加しノイズの除去を行った結果とともに 報告する. 人の避難行動のシミュレーション研究においては物 理モデル手法,セルオートマトン法,エージェントシ 12 http://www.cs.waikato.ac.nz/ml/weka/図 7: 調布駅周辺の格子生成図 ミュレーションが存在する [5].我々はこれらの手法か ら着想を得て,人の流れをシミュレーションすること で自転車の放置地点を推定できないかと考えた.セル オートマトン法とエージェントシミュレーションは行 動ルールを設定する必要があり,放置者個人の目的が 不明瞭な放置自転車問題においては,これらの手法を 直接取り入れることは難しい.そこで,本研究では流 体の保存則に従う物理モデルを用いて放置自転車のシ ミュレーションを行う.具体的には,駅付近の 3D 地 図を基に気流のシミュレーション行うことでよどみ点 を検出し,放置自転車の観測地点との相関性を調べた. さらに DBpedia Japanese[16] を用いてよどみ点をフィ ルタリングし,この結果を放置自転車が存在する可能 性の高い地点として,空間的な欠損値を推定した.
4.1
CFD を用いたよどみ点の検出
本研究では国土地理院基盤地図情報サービス13から 建物の平面データを取得し,地理情報サービスの Ar-cGIS14を用いて建物の 3D データを作成した.建物の高 さデータは取得することができなかったため一律 30m として作成した.次に,ArcGIS 上で動作する気流のシ ミュレーションソフトである Airflow Analyst15を使用 して,駅付近の気流シミュレーションを行った.図 7 は 調布駅を中心として解析範囲を設定して格子を生成し た図である.解析範囲は放置自転車の観測地点が全て 含まれるように設定した.図 7 では調布駅を中心とし て 700m 四方を解析範囲とし,格子点間の距離を 5m, 合計格子点数を 10,000 としている.また,風源は駅に 伸びる道路と平行になるように設定し,調布駅の場合 は道路に沿って 4 方向から人が駅に向かうことを想定 し 11 度,109 度,190 度,288 度と風向を変えてシミュ レーションを行う. 13http://www.gsi.go.jp/kiban/ 14http://www.esrij.com/products/arcgis/ 15 http://www.airflowanalyst.com/ 図 8: 調布駅周辺の平均風速 図 9: 本研究で定義したよどみ点のパターン 図 8 は風向を 11 度として,風速 5m/s の風を発生さ せた時のシミュレーション結果を基に,全格子点にお ける平均風速の値を OpenStreetMap16上にプロットし た結果である.青い点が格子点であり,この点の大小 が平均風速を表している.この数値データを基に気流 のよどみ点を検出する.よどみ点とは流れ場の中で流 体の速度が 0 になる点である.我々は図 9 のパターン を全格子点に適用してよどみ点の検出を試みた.黒色 部分は平均風速が 0 以上の点,白色部分が平均風速が 0 の点,灰色部分が平均風速が 0 より大きく 0.1 以下 の点である.実際には平均風速が 0 の格子点は建物が ある点となるため,本研究では隣接する格子点より平 均風速が低く,かつ平均風速が 0.1 以下の点をよどみ 点として定義した.結果として,パターン (a) と (j) が 最も放置自転車の観測地点の分布と近い結果となった ため,本研究においてはよどみ点の検出にパターン (a) と (j) を使用する.図 10 は調布駅において 4 方向のシ ミュレーション結果に図 9 のパターン (a) と (j) でよど み点を検出し,4 方向の検出結果をマージして地図上 にプロットしたものである.青いマーカはよどみ点で あり,赤いマーカは放置自転車の観測地点である. 16 https://openstreetmap.jp/図 10: 調布駅周辺にけるよどみ点の検出結果
4.2
DBpedia Japanese を用いたよどみ点
のフィルタリング
前節で述べた手法によりよどみ点を検出したが,図 10 を見て分かる通り多くのノイズが含まれている.我々 は,気流のよどみ点付近であり,かつ注目度の高い POI が周囲に存在する点に放置自転車が発生しやすいと考え た.そこで,よどみ点周囲の POI の注目度を DBpedia Japanse を用いて算出し,注目度の総和でフィルタリ ングした. まず,前節で得られたよどみ点の緯度経度を基に, Google Places API で半径 20m 以内の POI を検索す る.取得した POI の type に関するリソースについ て,DBpedia Japanse 上での被リンク数を計算する. Google Places API のタイプは DBpedia Japanse の リソースに予めマッピングしている.我々は,人物に 関するリソースからの被リンク数を注目度とし,POI の type に関するリソースが foaf:Person のインスタ ンスから受けているリンクの数を取得した.例えば (http://ja.dbpedia.org/resource/居酒屋) の場合この値 は 47 となる.その後,周辺 POI の注目度の総和を計 算し,注目度の合計が 200 未満であるよどみ点を除外 する.この閾値は 100 から 1000 まで変動させて,最も 結果が良くなったものを使用している. 次に,自転車が入ることができない建物敷地内の空 間も推定値の対象となっているため,これらの範囲内 で得られた推定値をノイズとして除去する.建物デー タと同様に国土地理院基盤地図情報サービスから道路 データを取得し,最寄りの道路から 10m 以上離れて存 在している点をノイズデータとして削除する.図 10 の フィルタリング後の結果,すなわち最終的な空間的欠 損の推定値を示す.緑色の点は建物敷地内と判定され 削除された点である. さらに,この空間的欠損の推定値を以下の RDF 表現 で放置自転車 LOD に追加した.追加したデータを放置 図 11: 調布駅周辺にけるフィルタリング後のよどみ点 (最終的な推定値) 自転車マップ17で図 12 のように可視化しており,こ れにより新規観測地点における放置自転車の台数デー タの収集が期待できる. @ p r e f i x ipb : < h t t p :// www . o h s u g a . is . uec . ac . jp / i p b l o d / v o c a b u l a r y # > @ p r e f i x b i c y c l e : < h t t p :// www . o h s u g a . is . uec . ac . jp / b i c y c l e / r e s o u r c e / >@ p r e f i x geo : < h t t p :// www . w3 . org / 2 0 0 3 / 0 1 / geo / w g s 8 4 _ p o s # > . @ p r e f i x o g c g s : < h t t p :// www . o p e n g i s . net / ont / g e o s p a r q l # > . @ p r e f i x n g e o : < h t t p :// g e o v o c a b . org / g e o m e t r y # > . @ p r e f i x d c t e r m s : < h t t p :// p u r l . org / dc / t e r m s / > . @ p r e f i x gn : < h t t p :// www . g e o n a m e s . org / o n t o l o g y # > . @ p r e f i x g n j p : < h t t p :// g e o n a m e s . jp / r e s o u r c e / > . @ p r e f i x xsd : < h t t p :// www . w3 . org / 2 0 0 1 / X M L S c h e m a # > . b i c y c l e : e s t i m a t e d _ o b s _ { t i m e s t a m p } rdf : t y p e ipb : E s t i m a t e d O b s e r v a t i o n P o i n t ; geo : lat " l a t i t u d e "^^ xsd : d o u b l e ; geo : l o n g " l o n g i t u d e "^^ xsd : d o u b l e ; gn : p a r e n t A D M g n j p :{ P r e f e c t u r e } gn : p a r e n t A D M 2 g n j p :{ City , P r e f e c t u r e } ; gn : p a r e n t A D M 3 g n j p :{ Town , City , P r e f e c t u r e } ;
gn : p a r e n t A D M 4 g n j p :{ L a n d lot , Town , City , P r e f e c t u r e } ; n g e o : g e o m e t r y [ a n g e o : G e o m e t r y ; o g c g s : a s W K T " P O I N T ( l a t i t u d e , l o n g i t u d e ) "^^ < h t t p :// www . o p e n l i n k s w . com / s c h e m a s / v i r t r d f # G e o m e t r y > . ] ; gn : n e a r b y b i c y c l e :{ POI n a m e } ; d c t e r m s : c r e a t e d " d a t e t i m e "^^ xsd : d a t e T i m e .
4.3
評価と考察
本節では,4.1 節で述べたよどみ点検出手法と 4.2 節 で述べた手法それぞれとベースライン手法を比較する ことで,本研究の提案手法の優位性について検証した 結果を示す. 本研究では,事前に放置自転車の観測地点を複数取 得できている調布駅,府中駅,新宿駅を対象に実験を 行った.4.2 節で述べた提案手法とベースライン手法の 再現率,適合率を比較する.全よどみ点の内,放置自 17 http://www.ohsuga.is.uec.ac.jp/bicycle/図 12: 空間的欠損値推定結果の可視化 転車の観測地点から半径 20m 以内に含まれるよどみ 点の割合を適合率と定義した.また,全観測地点の内, 半径 20m 以内によどみ点を含む観測地点の割合を再現 率とした.ベースライン手法では一様性を保つために, 提案手法により推定された地点数とほぼ同数となるよ うに格子の幅と格子点数を設定し,この格子点をベー スライン手法における推定地点としている.図 13 に 本研究のベースライン手法を示す.表 1 にベースライ ン手法と提案手法の再現率,適合率,F 値を示す.結果 として,提案手法は再現率,適合率,F 値の全てにお いてベースライン手法を上回った.また,ベースライ ン手法と提案手法 1 結果に差がないとの帰無仮説のも と,χ 二乗検定を適用した結果,5%水準で優位であっ た (χ2 = 22.3725, df = 1, p < 0.05).従ってベースラ イン手法と提案手法に優位な差が見られ,提案手法は 放置自転車の新規観測地点検出の手法として一定の優 位性があると考える. 提案手法の精度が落ちた原因として,観測地点数の 不足が考えられる.本研究で正解データとして使用し た観測値点数は調布駅付近と府中駅付近と新宿駅付近 の合計で 56 地点である.実際には提案手法により推定 された地点の付近にも放置自転車が存在している可能 性はあり,正確な精度を計算するためには推定地点の 実地調査による確認が必要である.
5
関連研究
Lopez ら [11] は静的データとセンサデータを Linked Data で管理・提供するプラットフォーム「QuerioCity」 図 13: ベースライン手法 表 1: ベースラインと提案手法 2 の推定精度 ベースライン 提案手法 2 調布駅 適合率 0.0469 0.247 再現率 0.115 0.462 F 値 0.0667 0.322 府中駅 適合率 0.125 0.250 再現率 0.222 0.333 F 値 0.160 0.286 新宿駅 適合率 0.0493 0.211 再現率 0.190 0.571 F 値 0.0784 0.308 Total 適合率 0.0559 0.228 再現率 0.161 0.482 F 値 0.0829 0.310 を提案している.この研究では,実センサからストリー ムデータを取得し,IBM InfoSphere Streams18とC-SPARQL[12] を使用することでリアルタイムに RDF を提供している.実際にアイルランドのダブリン市の データポータル「Dublinked19」で運用されており,バ スの路線,位置,遅延,混雑などの情報を 20 秒毎に更 新して提供している.しかし,この手法では実センサ を使用しておりコストがかかるため,本研究のように 草の根運動的に収集が必要なデータに関しては,同様 の取り組みを行うことは難しい. また,本研究と同様にデータを補完・推定し Linked Data 化する取り組みとしては,Bischof らの研究 [10] が挙げられる.Bischof らは DBpedia[13],Eurostat20,
United Nations Statistics Division (UNSD)21などの
18http://www-03.ibm.com/software/products/ja/ ibm-streams 19http://www.dublinked.ie/ 20http://ec.europa.eu/eurostat 21 http://unstats.un.org/unsd/default.htm
複数のデータソースから市のオープンデータを収集し, 形式の異なるこれらのデータをオントロジーに基いて Linked Data 化している. その際に生じる欠損値を統計 的回帰法と主成分分析を組み合わせた手法により推定 している.さらに,異なるデータソースから欠損値を 推定する Cross Data Set Prediction を提案している. しかし,本研究のように,同種のデータセットが他に存 在せず,時空間的な欠損が生じる場合においては適用 が難しい.そこで,本研究では時間的な欠損値をベイ ジアンネットワークを用いて,空間的な欠損値を CFD を用いて推定・補完することを試みた. 文書から因果関係を抽出する手法としては,手がか り表現を使用する研究が存在する [8].坂地らの研究で は,因果関係を表現する “を背景に”,“により” などの 21 種類の手がかり表現を使用して,新聞記事から因果 関係を抽出している.本研究でもこれらの手がかり表 現を使用して因果関係の抽出を試みたが,放置自転車 以外の因果関係が多く抽出される結果となったため,日 本語 WordNet から取得した “要因”,“引き起こす” の 同意語を使用した.
6
むすび
本論文では,放置自転車の因果関係を含んだ LOD を 半自動的に構築する手法を提案した.これにより,こ れまで手動で行っていた LOD スキーマの設計段階か ら,因果関係を含んだ社会課題の LOD を半自動的に 構築することが可能となった.今後は因果関係抽出及 び構築精度を高めるために,2.4 節で述べた解決策を試 行する. 本手法により放置自転車以外の様々な社会課題が LOD 化されることで,社会課題同士の因果関係を記述した 大規模な LOD クラウドの形成が期待できる.これに より,LOD の因果関係リンクを辿って自治体の抱える 課題の解決策の提示などが可能になると考える.また, 本論文では放置自転車 LOD の時空間的な欠損値を推 定し補完する手法を紹介し,新たにデータを追加して 実験を行った結果を可視化した.今後はより多くの地 域で推定実験を行い,実地調査により提案手法の精度 を算出する.参考文献
[1] 江上周作,川村隆浩,大須賀昭彦.: 放置自転車問題解 決に向けた循環型LOD構築システムの提案.人工知能 学会研究会資料,SIG-SWO-038-08 (2016) [2] 江上周作,川村隆浩,大須賀昭彦.: 放置自転車LODの 拡充に向けた空間的欠損値推定手法の提案.人工知能学 会研究会資料,SIG-SWO-039-06 (2016)[3] Egami, S., Kawamura, T., Ohsuga, A.: Building Urban LOD for Solving Illegally Parked Bicycle in Tokyo. In: Proc. The 15th International Semantic Web Conference, pp.291-307 (2016)
[4] Egami, S., Kawamura, T., Ohsuga, A.: Estimation of Spatio-temporal Missing Data for Expanding Urban LOD. In: Proc. The 6th Joint International Semantic Technology Conference, pp.152-167 (2016)
[5] 堀宗明,宮嶋宙,犬飼洋平,小国健二.: 地震時避難行
動予測のためのエージェントシミュレーション,土木学 会論文集A, vol.64, no.4, pp.1017-1036 (2008) [6] Landis, J Richard and Koch, Gary G.: The
mea-surement of observer agreement for categorical data. Biometrics, pp.159-174 (1977)
[7] 川村隆浩,大須賀昭彦.: TEXT2LOD∼テキスト情報
のLOD化に向けたWeb APIの開発∼.人工知能学会
論文誌(to appear) [8] 坂地泰紀,増山繁.: 新聞記事からの因果関係を含む文の 抽出手法.電子情報通信学会論文誌,Vol.J94-D, No.8, pp.1496-1506 (2011) [9] 小出誠二,他.:日本語WordNetとIPAdic辞書のRDF 化とDBpediaリンク.人工知能学会全国大会論文集, Vol.27, 1N4-OS-10b-4 (2013)
[10] Bischof, S., Martin, C., Polleres, A., Schneider, P.: Collecting, Integrating, Enriching and Republishing Open City Data as Linked Data. In: Proceedings of the 14th International Semantic Web Conference (ISWC), pp.57-75 (2015)
[11] Lopez, V., Kotoulas, S., Sbodio, M. L., Stephenson, M., Gkoulalas-Divanis, A., Aonghusa, P. M.: Queri-oCity: A Linked Data Platform for Urban Informa-tion Management. In: Proceedings of the 11th Inter-national Semantic Web Conference (ISWC), pp.148-163 (2012)
[12] Barbieri, D. F., Ceri, S.: C-SPARQL: SPARQL for continuous querying. In: Proc. The 18th Interna-tional Conference on World Wide Web, pp.1061-1062 (2012)
[13] Auer, S., Bizer, C., Kobilarov, G., Lehmann, J., Cy-ganiak, R., Ives, Z.: DBpedia: A Nucleus for a Web of Open Data. In: Proc. The 6th International Se-mantic Web Conference, 2nd Asian SeSe-mantic Web Conference (ISWC 2007 + ASWC 2007), pp.722-735 (2007)
[14] Stadler, C., Lehmann, J., H¨offner, K., Auer, S.: LinkedGeoData: A Core for a Web of SpatialOpen Data. Semantic Web Journal, vol.3, no.4, pp.333-354 (2012)
[15] Jenks, G. F.: The data model concept in statisti-cal mapping. International yearbook of cartography, vol.7, no.1, pp.186-190 (1967)
[16] Kato, F., Takeda, H., Koide, S., Ohmukai, I.: Build-ing DBpedia Japanese and Linked Data Cloud in Japanese. In: Proceedings of the Joint International Workshop: 2013 Linked Data in Practice Workshop (LDPW2013) and the First Workshop on Practical Application of Ontology for Semantic Data Engi-neering (PAOS2013). CEUR Workshop Proceedings (2013)

![図 7: 調布駅周辺の格子生成図 ミュレーションが存在する [5] .我々はこれらの手法か ら着想を得て,人の流れをシミュレーションすること で自転車の放置地点を推定できないかと考えた.セル オートマトン法とエージェントシミュレーションは行 動ルールを設定する必要があり,放置者個人の目的が 不明瞭な放置自転車問題においては,これらの手法を 直接取り入れることは難しい.そこで,本研究では流 体の保存則に従う物理モデルを用いて放置自転車のシ ミュレーションを行う.具体的には,駅付近の 3D 地 図を基に気流のシ](https://thumb-ap.123doks.com/thumbv2/123deta/8250509.1284598/7.892.463.808.148.391/ミュレーションシミュレーションエージェントシミュレーション.webp)


