An Enhanced Electrolarynx with Automatic Fundamental Frequency Control based on Statistical Prediction
Kou Tanaka, Tomoki Toda, Graham Neubig, Sakriani Sakti and Satoshi Nakamura
Graduate School of Information Science, Nara Institute of Science and Technology 8916-5Takayama-cho,Ikoma,Nara,Japan
{ko-t, tomoki, neubig, ssakti, s-nakamura}@is.naist.jp
Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full cita
tion on the first page. Copyrights for third-party components of this work must be honored. For all other uses, contact the Owner/Author(s). Copyright is held by the owner/author(s).
ASSETS’15, October 26–28, 2015, Lisbon, Portugal.
ACM 978-1-4503-3400-6/15/10.
DOI: http://dx.doi.org/10.1145/2700648.2811340.
ABSTRACT
An electrolarynx is a type of speaking aid device which is ableto mechanically generateexcitation sounds to help laryngectomeesproduce electrolaryngeal (EL) speech. Al
thoughELspeechisquiteintelligible,itsnaturalnesssuffers frommonotonousfundamentalfrequencypatternsoftheme
chanicalexcitationsounds. Tomakeitpossibletogenerate morenaturalexcitationsounds,wehaveproposedamethod to automatically controlthe fundamental frequencyof the soundsgeneratedbytheelectrolarynxbasedonastatistical predictionmodel,whichpredictsthefundamentalfrequency patternsfromtheproducedELspeechinreal-time. Inthis paper,wedevelopaprototypesystembyimplementingthe proposedcontrolmethodinanactual,physicalelectrolarynx andevaluateitsperformance.
Categories and Subject Descriptors
K.4.2[Computersand Society]: SocialIssues- Assistive technologiesforpersonswithdisabilities
Keywords
electrolaryngeal speech, automatic fundamental frequency control
1. INTRODUCTION
Electrolaryngeal(EL)speechisoneofthemajorspeaking methods used by laryngectomeeswho are peoplewho have hadtheirlarynxusuallyduetolaryngealcancer. ELspeech isproduced usinganelectrolarynx, whichis typicallyheld againstthe neckto mechanically generate artificialexcita
tionsignals. Thegeneratedexcitationsignalsareconducted into the speaker’s oral cavity, and are articulated to pro
duceELspeech. ELspeech isrelativelyintelligiblebutits naturalnessisverylowowingtounnaturalfundamentalfre
quency(F0)patternsofthemechanically generatedexcita
tionsignals. Consequently,qualityoflifeoflaryngectomees issignificantlydegraded.
TogeneratemorenaturalF0 patterns,wehaveproposed a method to control F0 based on the statistical F0 predic
tion[1]. Inourproposedsystembasedonthismethod, F0
patternsarepredictedfromtheproducedELspeechsignals as shown in Fig. 1. Relatively naturalF0 patternscan be predictedusingstatisticsextractedinadvancefromparallel dataconsistingofutterancepairsofELspeechandnatural speech. Therefore,thissystemallowslaryngectomeestodi
rectlyproducemorenaturalELspeechinthesamemanner asinthetraditionalspeakingmethodusingtheconventional electrolarynx. Ourpreliminaryexperimentalresultsthrough simulation[1]havedemonstratedthattheproposedmethod yieldssignificantimprovementsinnaturalnesswhilecausing nodegradation inlistenability and intelligibility compared totheoriginalELspeech.
Inthis paper, we develop aprototype system byimple
mentingourproposed F0 controlmethodinanactual,phys
icalelectrolarynxandevaluateitsperformance. Theexper
imentalresultsdemonstratethattheprototypesystemgen
eratesmorenaturalexcitationsounds,asinthesimulation.
2. METHODOLOGY
DirectControlofExcitationSignalsofElectrolar
ynxbased onStatistical F0 Prediction: Ourproposed system allowsalaryngectomee to produceELspeech with predicted F0 patternsusing twoprocesses: prediction and articulation [1]. Inthe prediction process, the F0 value is predicted framebyframeusingthereal-timevoiceconver
sion algorithm [2]from EL speech producedbythe laryn
gectomee. This process causes a constant processing de
layof50msto makeit possibletopredict relativelynatu
ral F0 patternsvaryingcorrespondingtolinguisticcontents.
Inthearticulationprocess,thelaryngectomeeproducesthe EL speech byarticulatingthe excitation sounds generated
Production of more naturally sounding speech
Mic
System Electrolarynx automatically Expired air (Real time prediction) controlled by predicted
Figure 1: Proposed systemto directlycontrol elec
trolarynx usingreal-time statisticalF0 prediction.
435
A B C D Low-delay conversion
Writing signal into D/A converter
A B C
50ms 50ms 50ms 50ms
EL speech waveform
Predicted pattern …
Excitation signal
… … … A
of electrolarynx
Figure2: Latencycausedby eachprocess
100 200
50
a) Conventional EL speech
100 200
50
Frequency [Hz] b) Proposed EL speech
100 200
50
c) Target normal speech
0 2 4 6 8
Time [s]
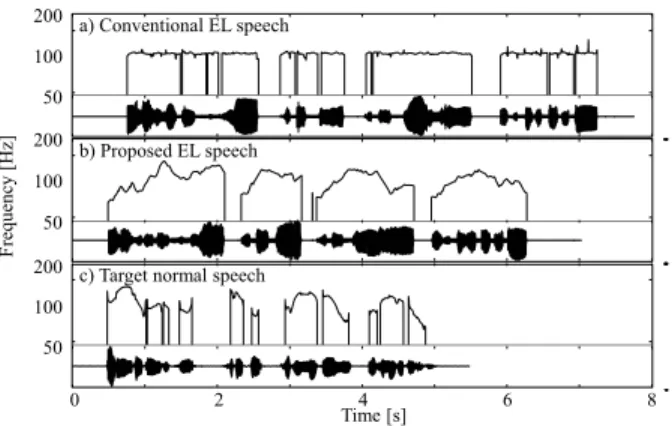
Figure 3: Example of waveforms and F0 patterns ofEL speechsignalsgeneratedbyconventionaland proposedsystemsandthoseoftargetnaturalspeech.
from the electrolarynx based on the predicted F0 values.
These two processes are simultaneously and continuously performed. Consequently,ELspeechwiththepredicted F0
patternscanbedirectlyproducedbythelaryngectomeebut italwayssuffersfrommisalignmentbetweenthearticulated soundsand F0 patternscausedbytheprocessingdelayof50 ms. Theresultsofourpreviousevaluationthroughsimula
tionhavedemonstratedthattheimpactofthismisalignment onperceptionissmall[1].
DevelopmentofPrototypeSystem: Aprototypesys
tem based onour proposed technique has been developed usingalaptopandadigital/analog(D/A)convertershown inTable1. Asshown inFig.1,EL speechproducedfrom mouthofalaryngectomeeisdetectedwithastandardclose- talk microphone. The EL speech signal is recorded on a laptop and F0 patterns of normal speech are predicted on theflybyusingthereal-timestatisticalF0 prediction. The predicted F0 valuesarelinearlyconvertedtovoltagevalues to controlthe F0 valuesof the excitation signalgenerated byanelectrolarynx. Then, anelectricsignalcorresponding tothedeterminedvoltagevaluesisgeneratedwiththeD/A converter connected from the laptop to the electrolarynx.
The electrolarynx changes the F0 valuesof the excitation signalaccordingtotheinputelectricsignalgeneratedfrom theD/Aconverter. Asshown inFig.2,additionallatency iscausedbytheD/Aconverterintheprototypesystem. It takesaround50ms towritethe digitalsignalontheD/A converter. Moreover,thedigital signaltobewrittenneeds tobedeterminedbeforestartingwriting. Consequently,the D/Apart always causes100 ms latency. In total, 150ms latency is causedin the prototypesystem. Notethat this latencyintheD/Apart maybeaddressedbythedevelop
mentofaspecialdevicefortheelectrolarynx.
3. EVALUATION AND RESULTS
Weconductedanobjectiveevaluationforevaluatingpre
dictionaccuracyofF0 patternsgeneratedbythedeveloped prototypecomparedtothatconfirmedinthesimulationpro
cess[1]. The sourcespeech wasEL speechuttered byone non-disabledmale speaker,andthe targetspeechwas nor
malspeechutteredbyaprofessional femalespeaker. Each speakerutteredabout50sentencesintheATRphonetically
Table1: Electronicdevicesontheprototypesystem
Electrolarynx Yourtone
Microphone CrownCM-311A
CPUofthelaptop Intel(R)Core(TM)i5-4200U D/Aconverter AIO-160802AY-USB
balancedsentenceset[3]. Weconducteda5-foldcrossvali
dationtestinwhich40utterancepairswereusedfortraining ofastatistical F0 predictionmodel,andtheremaining10ut
terancepairswereusedforevaluation. Samplingfrequency wassetto16kHz.
Experimental results: The F0 correlation coefficient between the prototype system and the simulationprocess is 0.91. This result shows that F0 patterns predicted by theprototypesystemstronglycorrelatetothosebythesim
ulation process, which have already been confirmed to be effectiveforimprovingnaturalnessofELspeech[1]. Anex
ampleofELspeechsignalsandtheir F0 patternsareshown inFig.3. We cansee thatthe prototypesystem makes it possibletoproduceELspeechwithmorenaturallyvarying F0 patternscomparedtotheconventionalELspeech.
4. CONCLUSIONS
Inthispaper, wehave developeda prototypesystemby implementing our proposed F0 control methodof an elec
trolarynx based onthe statistical F0 predictiontechnique andevaluateitsperformance. Theexperimentalresultshave demonstrated thattheprototypesystem enablesaspeaker toproducemorenaturallysoundingelectrolaryngealspeech.
5. ACKNOWLEDGMENTS
ThisworkwassupportedinpartofJSPSKAKENHIGrant Numbers: 26280060andtheauthorswouldliketothankMr.
Y. Sugaiof DenseiCommunicationInc., Japan, foradvise tocontrolanelectrolarynx.
6. REFERENCES
[1] K.Tanaka,T.Toda,G.Neubig,S.Sakti,and S.Nakamura,“DirectF0 controlofanelectrolarynx basedonstatisticalexcitationfeaturepredictionand itsevaluationthroughsimulation,”in Proc.
INTERSPEECH,Sep2014.
[2] T.Toda,T.Muramatsu,andH.Banno,
“Implementationofcomputationallyefficientreal-time voiceconversion.”in Proc. INTERSPEECH,Sep2012.
[3] M.Abe,Y.Sagisaka,T.Umeda,andH.Kuwabara,
“Speechdatabase,”ATRTechnicalReport,TR-I-0166, Sep1990.
436