人工知能学会研究会資料 SIG-AGI-013-04
省メモリ推論のための深層ニューラルネットワークの圧縮手法
A Compression Method for Memory Saving Inference with
Deep Neural Networks
岩﨑博生
∗伊野文彦
Hiroki Iwasaki
Fumihiko Ino
大阪大学大学院情報科学研究科
Graduate School of Information Science and Technology, Osaka University
Abstract: 本論文では,推論モデルにおけるメモリ使用量の削減を目的として,深層ニューラル ネットワークに対する圧縮手法を提案する.提案手法は,ネットワークを構成するユニットを統合 するために,非構造的枝刈りをもとに,重み行列に対して k 平均クラスタリングを適用し,各行を k 個のクラスタに分類する.さらに,各クラスタに属する行を,クラスタの中心,すなわちクラスタ に属する行の平均値に置換する.置換結果に基づいて,ネットワークのユニットを統合することで, 重み行列の列数および行数をそれぞれ k 個に削減し,メモリ使用量を削減する.k を変えながら提案 手法を AlexNet に適用したところ,適用前の予測精度からの精度低下をたかだか 1%程度に抑えなが ら,全結合層のメモリ使用量を最大で 41.7%削減できた.また,同一メモリ使用量削減率における提 案手法と非構造的枝刈りの予測精度を比較したところ,提案手法の予測精度が非構造的枝刈りの精度 よりも最大で 14.5%高いという結果を得た.同様に,同一予測精度における提案手法と非構造的枝刈 りのメモリ使用量削減率を比較したところ,提案手法のメモリ使用量削減率が非構造的枝刈りの削減 率よりも最大で約 36%大きいという結果を得た.
1
はじめに
画像認識の正確さを競う大会 ImageNet Large Scale Visual Recognition Challenge(ILSVRC)[1] におい て,1000 クラス分類問題で最も高い分類精度を達成し た AlexNet[2] の提案以来,深層ニューラルネットワー ク(DNN)は画像認識や音声認識,自然言語処理などの 様々な応用に用いられている.DNN の特徴は層の深さ にある.その深さが原因で,AlexNet,ResNet-50[3], GoogLeNet[4] などの DNN は,それぞれ約 60M,25M, 13M 個のパラメータを持つ.大量のパラメータは数十 MB から数百 MB の記憶領域を必要とするだけでなく, 推論時の計算量も増大させる. 一方,組み込みシステムやモバイル端末のメモリ容量 は数百 KB から数 MB に留まっていて,メモリの枯渇 が DNN による推論処理を妨げている.そこで,DNN の予測精度を低下させることなく,推論のためのメモ リ使用量や計算量を削減する手法が盛んに研究されて いる. ∗大阪大学大学院情報科学研究科 〒 565-0871 大阪府吹田市山田丘 1-5 E-mail : [email protected] 削減手法の一つとして枝刈りが挙げられる [5, 6].枝 刈り手法は,学習済み DNN の隣接層のユニット間の 結合について,重要度の低い結合が持つ重みの値を 0 とみなす.重みの値が 0 の場合,推論時における積和 計算の一部を省略でき,推論計算量を削減できる.ま た,枝刈り後,重みを保持する重み行列が疎となり,メ モリ使用量を削減できる. 枝刈り後の疎行列の持つ規則性にしたがって,枝刈 り手法は 2 種類に分類できる.不規則にゼロ要素を出 現させるものを非構造的枝刈り [5] と呼び,規則的に出 現させるものを構造的枝刈り [6] と呼ぶ.全結合層を構 造的に枝刈りする場合,枝刈り後の重み行列は列状の ゼロ要素を持つ.つまり,0 を常に出力するユニット が生成される.そのようなユニットは最終的な推論結 果に影響を与えない.したがって,0 を常に出力する ユニットを除去し,疎な重み行列をサイズの小さな密 行列に圧縮できる. 一方,非構造的枝刈りは必ずしも列状のゼロ要素を 出現させない.したがって,密行列による圧縮はできな い.そこで,疎行列を保持するためには,Compressed Sparse Row/Compressed Sparse Column(CSR/CSC)
形式のように,非ゼロ要素に加えてそのインデックス が必要である.m を非ゼロ要素数,n を行数もしくは 列数とすれば,CSR/CSC 形式は 2m+n+1 個のデータ で疎行列を保持できる.これらのうち,およそ半分程 度をインデックスが占めていて [7],メモリ使用量の削 減が求められている. そこで本研究では,非構造的枝刈り適用後の DNN に ついて,疎な重み行列のメモリ使用量を削減する手法 を提案する.提案手法は,DNN の予測精度の低下を抑 えるために,最終的な推論計算の結果を近似する.ま た,疎行列のメモリ使用量を削減するために,記憶する 必要のあるデータの個数が 2m+n+1 であることから, n(疎行列の列数)を小さくする,すなわち DNN の該 当する層のユニット数を削減する. 推論計算におけるある層の出力行列と次の層の重み 行列を掛ける計算において,重み行列に同一行が存在 する場合,積和計算における重みの値が共通であるた めに,出力を足し合わせてから重みを掛けても推論計 算結果は変わらない.すなわち,推論計算結果に影響 を与えずに,出力行列の層のいくつかのユニットを一 つに統合することができる.提案手法では,ユニット 数を削減するためにこの点に着目した.しかし,実際 は重み行列中に同一行が存在する可能性は低いため,同 一行を生成する必要がある.そこで提案手法では,重 み行列に対して k 平均法を適用し,k 個のクラスタに 分類し,各クラスタに属する行をそのクラスタの中央 値で置き換えてを同一行を生成した.置換結果に基づ いてユニット数を削減し,疎行列のメモリ使用量削減 に貢献している.
2
関連研究
Han ら [5] は,結合が持つ重みの絶対値を評価指標と する枝刈り手法を提案している.ネットワークの各層 の重み行列の標準偏差と,層ごとの枝刈りに対する感 度,すなわち,枝刈りによって 0 となる重みの割合を大 きくしたときに予測精度がどのように変化するかの推 移の解析結果に基づいて,層ごとに閾値を設定し,絶対 値が閾値以下の重みの値を 0 にしている.AlexNet や VGG-16[8] といった大規模なネットワークに対して, 予測精度を低下させずに,非ゼロ要素の個数を元のパ ラメータ数の 1/9,1/13 まで削減している.さらに彼 ら [9] は,枝刈りに加えて,重みの値の類似しているも の同士でクラスタリングを行うことで重みを共通化し, 通常 32bit の単精度浮動小数点数で表現される重みを 5bit まで削減することで,AlexNet,VGG-16 の使用ス トレージを 1/35,1/49 まで削減している.また,Sun ら [10] は,2 つのユニットの出力の間の相関係数を評 価指標としている.いくつかの学習データを用いてユ ニットの組ごとに相関係数を求めて,正および負の相 関が強い組の結合を残すという手法で,VGG-16 とほ ぼ構造の似ているネットワークに対して,予測精度を 低下させずに,非ゼロ要素の個数を元のパラメータ数の 12%まで削減している.これらの枝刈り手法は,ネット ワークの結合に不規則なスパース性をもたらす,非構造 的枝刈りに分類される.すなわち,重み行列が 0 配置の 不規則な疎行列となる.したがって,ネットワークが持 つ重みを記憶する際に,非ゼロの重みの値そのものに加 えて,そのインデックスも記憶する必要がある.[9] で は,枝刈りと重み共有を適用後の AlexNet や VGG-16 が使用するストレージの内訳を解析しており,非ゼロ 要素のインデックスがそれぞれ約 51.4%,48.1%を占め ていることが報告されている. また,メモリへのランダムアクセスによって,推論計 算を十分に高速化できないことも報告されている.非 構造的枝刈りでは,重み行列中の非ゼロ要素が不規則に 分散している.これにより,入力行列に対して疎行列 を掛けて次の層の出力行列を求める計算において,非ゼ ロの重みと対応するアクティベーションの積を求めて 出力行列の該当する要素に加算する処理を繰り返す際, 出力行列の要素へのアクセスがランダムとなる.した がって,出力行列の要素へのアクセスにおいて,キャッ シュヒット率が低下しメモリアクセスが増加すること で,推論計算の高速化を妨げている.Wen ら [11] は, 非構造的枝刈り適用後の AlexNet において,畳み込み 層ごとの推論計算時間のオリジナルモデルに対するス ピードアップを評価している.評価結果として,スパー ス率(枝刈りによって 0 となる要素の割合)が 95%以 上であるにもかかわらず,層ごとのスピードアップは 約 0.3∼1.5 倍に留まっていることが報告されている. 非構造的枝刈りにおいて,重み行列中の非ゼロ要素 のインデックスを記憶する必要があることや,メモリ へのランダムアクセスといった問題は,重み行列の 0 配置が不規則であることに起因する.これらの問題を 解決するために,0 配置が規則的になるように枝刈り を行う構造的枝刈り手法も提案されている.構造的枝 刈りでは,0 配置に規則性を生み出すために,重要度の 評価対象の粒度を粗くしている.例えば,全結合層で はユニット,畳み込み層ではフィルタなどが評価対象 である.全結合層の重み行列では一列が一つのユニッ トが持つ重みに該当するため,ユニット単位で枝刈り を行うと,重み行列の要素が列単位で 0 となる.この とき,1 章で述べた理由により重み行列をサイズの小 さな密行列に変換できるため,重み行列中の非ゼロ要 素のインデックスを記憶する必要はなく,密行列の行 列行列積であるためメモリアクセスもシーケンシャル アクセスとなる.また,畳み込み層において,フィル タ単位で枝刈りを行うと,フィルタを構成する全要素 が 0 となりフィルタを削除できる.削除されずに残るフィルタは密行列の状態で保持されるため,疎行列は 生成されず上述の問題を発生させない. He ら [6] は,全結合層のユニットの重要度の評価指 標として,ユニットのアクティベーションの分散,ユ ニットが持つ重みの L1 ノルム,ユニットから出る結合 の重みの L1 ノルムの 3 種類の評価指標を提案してお り,ユニットから出る結合の重みの L1 ノルムに基づく 枝刈りが最も高い予測精度を達成している.Hu ら [12] は,大量のデータセットを用いて,どんな入力データ に対しても 0 に近い値しか出力しないようなユニット を特定し,それらを削除するという手法を提案してお り,VGG-16 に対して,予測精度の低下を発生させずに パラメータ数を約 1/3 に削減している.畳み込み層に おける構造的枝刈り手法も提案されている [13][14].Li ら [13] は,畳み込み層が持つフィルタについて,フィ ルタを構成するカーネルの L1 ノルムをもとにフィル タごとの重要度を評価し,フィルタをまるごと削除し ている.また,Anwar ら [14] は,カーネル単位で枝刈 りを行う際に,非ゼロ要素間で一定の間隔を空けなが ら枝刈りを行う手法を提案している.非構造的枝刈り では,非ゼロ要素間のインデックスの距離は要素間ご とにばらばらであるが,その間隔を一定にすることで インデックスの距離のデータを一つだけ記憶するだけ でよく,メモリ使用量の削減に貢献している. また,枝刈りの粒度と予測精度の関係を調査した研 究も存在する [15].Mao ら [15] は,畳み込み層におけ る枝刈りに関して,枝刈りの単位としてカーネル,ベク トル,チャネル,フィルタの 4 つの粒度を設定し,それ らの予測精度を比較している.結果として,最も粒度 の小さいカーネル単位の枝刈りが最も精度が高く,粒 度の粗いフィルタ単位の枝刈りが精度が低いという結 果が得られており,予測精度の観点では非構造的枝刈 りの方が優れている.
3
提案手法
本研究では,2 章で述べた非構造的枝刈りの問題点の うち,重み行列中の非ゼロ要素のインデックスを記憶 する必要があるという点に着目した.文献 [9] は,非構 造的枝刈りを適用した AlexNet について,ネットワー ク全体のメモリ使用量の約 51.4%をインデックスデー タが占めていることを報告している.そこで,本研究 では,非構造的枝刈りによって生成される疎行列に関 して,インデックスデータの個数を減らすことで,疎 行列のメモリ使用量,およびネットワーク全体のメモ リ使用量を削減する手法を提案する.3.1
アイデア
疎行列におけるインデックスデータの個数を削減す るためのアイデアとして,疎行列の列数を削減するこ とを考える.疎行列は一般的に CSR/CSC 形式で保持 され,非ゼロ要素数を m,行列の列数を n とすると, 記憶する必要のあるデータの個数は全部で 2m + n + 1 個である.このうち,m 個は非ゼロ要素であるため, 残りの m + n + 1 個がインデックスデータである.し たがって,疎行列の列数 n を削減することができれば, 記憶すべきインデックスデータの個数が減少し,メモ リ使用量の削減につながる.また,列数を削減した結 果,重み行列のサイズが小さくなり,非ゼロ要素の個 数 m の減少も期待できる. また,本論文では,単純化のために,提案手法の適 用対象を全結合層として手法を説明する.実験も同様 に,全結合層に対してのみ提案手法を適用した.畳み 込み層に対する提案手法適用可能性の考察,および実 験は今後の課題とする. 全結合層の重み行列における各列は,一つのユニッ トが持つ重みに相当する.したがって,全結合層の重 み行列の列数を削減することは,ユニット数を削減す ることと等しい.したがって,全結合層のユニット数 を削減することを考える.3.2
ユニット数を削減可能な状況
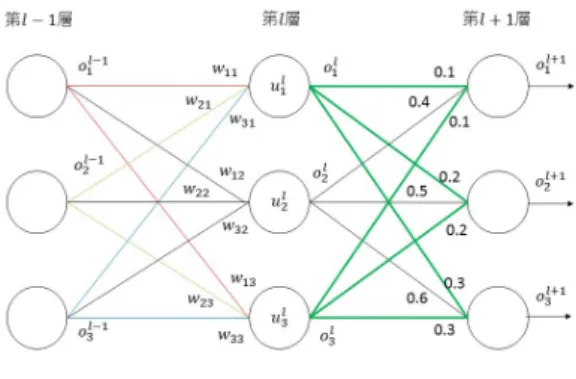
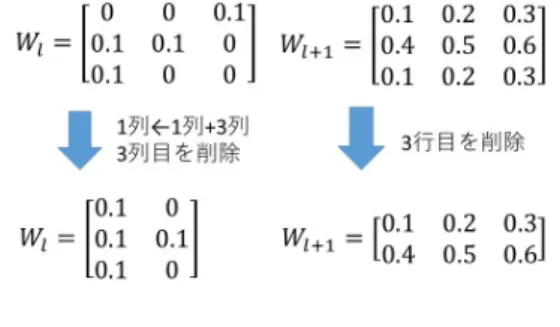
DNN の第 l 層における活性化関数を fl,重み行列を Wlとする.以下の 2 つの前提をおく. 前提 1 flが線形関数である 前提 2 第 l + 1 層の任意のユニットに対する重みが同一 であるような第 l 層のユニットの組が 1 つ以上存 在する(Wl+1において同一行の組が 1 つ以上存 在する) これらの前提を満たすとき,前提 2 における第 l 層 のユニットの組に関して,DNN の推論計算結果(出力 層の各ユニットの出力値)を変えることなく,各組に 属するユニットを 1 つのユニットに統合できる.すな わち,ユニット数を削減できる.本論文では,推論計 算結果を変えずにユニットを統合できることの証明は 割愛する.以降では,上記の前提が成立していると仮 定して,どのようにして DNN の出力値を変えずにユ ニットが統合されるのか,図 1 に示した具体的なネッ トワークの例を用いて説明する.図 1 のネットワーク の第 l 層と第 l + 1 層の重み行列 Wl,Wl+1は図 2 の図 1: ユニット統合可能なネットワークの例 図 2: 図 1 のネットワークにおける重み行列 ようになっている.ここでは,説明の単純化のために, 各ユニットが持つバイアスは推論計算に含めない. 図 1 のネットワークでは,第 l 層のユニット ul 1と ul3 は,第 l + 1 層の任意のユニットに対する重みが等しい. ここで,第 l + 1 層のユニット ul+1 1 の出力値を o l+1 1 , 活性化関数を fl+1とすると,ol+11 は, ol+11 = fl+1(ol1∗ 0.1 + ol2∗ 0.4 + ol3∗ 0.1) = fl+1((ol1+ ol3)∗ 0.1 + ol2∗ 0.4) (1) 上式のように,ol 1,ol2,ol3とユニット u l+1 1 が持つ重 みの内積を活性化関数 fl+1に入力して求めることがで きる.ここで,ol 1と ol3の乗数がどちらも 0.1 であるこ とから,ol 1と o l 3の項を含む 2 つの掛け算は,共通の重 みである 0.1 でくくることで,1 つの掛け算の処理に変 換することができる(式(1)).すなわち,ol 1と ol3を 出力する 2 つのユニット ul 1と ul3の代わりに,ol1+ ol3 を出力するような 1 つのユニットを用いても ol+1 1 の値 は変わらない. ol 1+ ol3を出力するようなユニットを ul13として,ul13 の生成方法を説明する.ol 1と ol3は,第 l−1 層のユニッ トの出力とそれぞれのユニットが持つ重みの内積を fl に入力した結果であるので, ol1+ ol3 = fl(o l−1 1 ∗ w11+ ol2−1∗ w21+ ol3−1∗ w31) + fl(ol1−1∗ w13+ o2l−1∗ w23+ ol3−1∗ w33)(2) ここで,前提 1 より flは線形関数であるため,線形 関数の性質を持つ.つまり,加法性が成立する.加法 性とは,任意の x,y に対して f (x + y) = f (x) + f (y) が成り立つという性質である.したがって,式(2)に おいて,先にそれぞれの関数の入力値を足し合わせて から活性化関数を通しても計算結果は変わらないので, 式(3)のように変形できる. ol1+ ol3 = fl(ol1−1∗ (w11+ w13) + ol2−1∗ (w21+ w23) +ol3−1∗ (w31+ w33)) (3) よって,ユニット ul 13が ol1+ ol3を出力するために は,ul 13が w11+ w13,w21+ w23,w31+ w33の重みを 持つ必要があることがわかる.式(2)から式(3)の 変形において,第 l− 1 層の出力と重みの掛け算につい て,第 l− 1 層の出力の部分が共通の項同士を一つの掛 け算にまとめている.よって,前述の 3 つの重みはそ れぞれ,第 l− 1 層の各ユニットにおける,ul 1と ul3に 対する重みを足し合わせたものと等しい. 第 l− 1 層の i 番目のユニットにおける,第 l 層の j 番目のユニットに対する重みは,Wlの i 行 j 列の要素 に相当する.したがって,ul 13が持つ 3 つの重みは,Wl において,各行の 1 列目と 3 列目の要素を足し合わせ ることで求めることができる.(図 3 参照). また,ul 1と ul3が ul13に統合されることから,ユニッ ト数が減少するため,Wlの列数を調整する必要があ る.図 3 のように,1 列目と 3 列目を足し合わせた結 果(ul 13の重み)を 1 列目に代入した場合,3 列目(ul3 の重み)は不要であるため削除する.さらに,第 l 層の ユニット数が減少するため,Wl+1の行数も調整する必 要がある.ユニット統合によって,ul 3が削除された. したがって,ul 3における,第 l + 1 層の各ユニットに 対する重みを削除すればよい.すなわち,Wl+1の 3 行 目を削除する. このように,上記の前提が成り立つとき,DNN の推 論結果を変えずにユニットを統合できる.ユニット統 合により,重み行列の列数を削減でき,疎行列のイン デックスデータの個数削減につながる.
図 3: ユニット統合に伴う Wl,Wl+1の変形
3.3
提案手法におけるユニット数削減
3.3.1 活性化関数の変更 推論計算結果を変えずにユニットを統合するために は,前提 1 に示すように,flが線形関数でなければな らない.しかし,既存の DNN は活性化関数として,単 調増加する非線形関数がよく用いられる.具体的には, シグモイド関数や正規化線形関数などである.非線形 関数の場合,必ずしも加法性が成立するとは限らない. 仮に,flが非線形関数の状態で,式(2)から式(3)への 変形をし,式(3)に基づいて u13の重みを決定してし まうと,ネットワークに入力する画像によっては,u13 の出力が o1+ o3とは異なる値となってしまうことが ある.したがって,ユニット統合前後で推論計算結果 が変わるため,ネットワークの予測精度の低下を引き 起こす可能性が高い. したがって提案手法では,第 l 層の活性化関数を線形 関数に変更した後,ユニットを統合する.線形関数と して恒等関数を用いる.すなわち,線形関数を y = ax (a は実数)として,a = 1 を採用する.a ≠ 1 の場合 は,後述する再学習において,順伝播計算時に,前の 層の出力と重みの内積に対して a を掛けるという無駄 な計算が発する.a = 1 の場合は,内積に対して 1 を 掛けても結果は変わらないので,a を掛ける計算を省 略できる. しかし,活性化関数の変更に伴って,ネットワーク の予測精度が低下するという問題が発生する.これは, 関数の変更によって出力層の各ユニットの出力値が変 わるためである.提案手法は,ユニット統合前の推論 計算結果を変えずにユニットを統合するという手法で ある.よって,関数を変更して予測精度が低い状態の ネットワークに対して,推論計算結果を変えずにユニッ ト統合することになり,統合後のネットワークの予測 精度が低くなるという問題が発生する.よって,提案 手法では,非構造的枝刈り適用済みのネットワークに 対して,第 l 層の活性化関数を恒等関数に変更した状 態で,ネットワークの再学習を行う.これにより,活 性化関数として恒等関数を用いている状態で予測精度 の高いネットワークを生成することを図る. 3.3.2 クラスタリングによる重み行列の行置換 前提 2 は,実際の学習済み DNN における重み行列 において成立する可能性は低い.大規模な DNN の一 つである AlexNet は,1 つ目と 2 つ目の全結合層の重 み行列のサイズがそれぞれ,6400*4096,4096*4096 で あるように,重み行列の列数が数千に及ぶ.数千列に わたって各列の成分が等しいような行の組み合わせが 1 つ以上存在することは考えにくい.よって,前提 2 を 満たすために,Wl+1において意図的に同一行を生成す る必要がある.しかし,ランダムに Wl+1のいくつか の行を選択してそれらの行の要素を変更し共通化して も,ユニット統合前後で推論計算結果が全く異なり,予 測精度の大幅な低下が予想される.よって,予測精度 の低下を小さく抑えるための工夫として,重み行列の 各行をサンプルとしてクラスタリングを適用する.ク ラスタリングの結果,各クラスタに属している行同士 を類似行とみなし,それらの行を共通化して同一行を 生成する. 提案手法では,クラスタリングアルゴリズムとして k 平均法を用いる.Wl+1の各行を入力として k 平均法 を適用し,k 個のクラスタに分類する.各クラスタの 中心値はクラスタに属する行の平均を取る.クラスタ リング終了後,各クラスタに属している行を,クラス タの中心値で置換することで,Wl+1において同一行を 生成させる.3.4
提案手法の流れ
提案手法の流れを以下に示す.手法の入力は,非構 造的枝刈り適用済みの DNN である.また,非構造的 枝刈り適用によって,第 l 層の重み行列が疎行列となっ ていることを前提とする. 1. 活性化関数を恒等関数に変更し再学習 2. Wl+1の各行に対して k 平均法を適用し,各行を k 個のクラスタに分類 3. 分類結果に基づき,第 l 層のユニットを統合(統 合後のユニットの重み計算,Wlと Wl+1の変形) 4. ネットワークの再学習4
実験
非構造的枝刈りを適用したネットワークに対して,提 案手法を適用する.具体的には,クラスタリングアル ゴリズムにおけるクラスタの個数 k を変えながら提案 手法を適用する.各 k における,ネットワークのメモ リ使用量や予測精度を評価する.4.1
実験準備
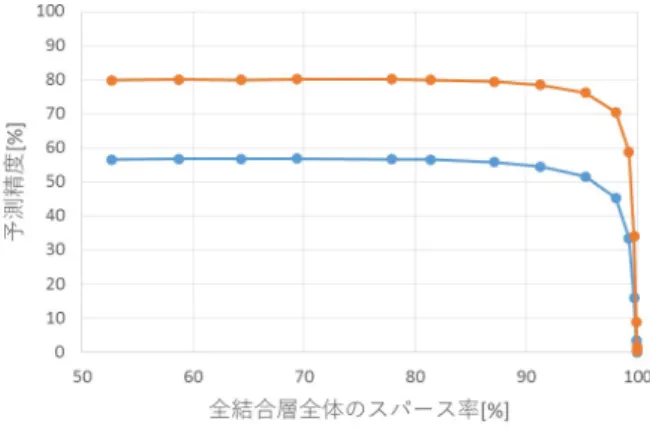
提案手法は非構造的枝刈り適用済みの DNN を入力 とする.そのため,提案手法を適用しメモリ使用量や 予測精度を評価する実験の準備として,非構造的枝刈 りを適用したネットワークを用意する必要がある.ま た,非構造的枝刈りを適用するために,枝刈りを適用 していない学習済みのオリジナルネットワークも用意 する必要がある. 4.1.1 オリジナルネットワークの学習 本実験では,ネットワークとして AlexNet を用いる. AlexNet は,Krizhevsky ら [2] によって提案された畳 み込みニューラルネットワークで,画像認識の認識精 度を競う大会である ILSVRC において,2012 年に優勝 したネットワークである.AlexNet は,5 つの畳み込み 層の後に 3 つの全結合層が続く構造となっている.[2] では,AlexNet を ILSVRC2012 データセットを用いて 学習し,1000 クラス分類の分類精度を評価しており, Top-1 accuracy と Top-5 acuuracy でそれぞれ 59.3%と 81.8%を達成している. 本実験では,[2] で述べられている学習方法を一部変更 して AlexNet を学習させた.データセットは,ILSVRC 2012 データセットを用いた.[2] に述べられている学 習方法通りに学習を行うと,前述と同程度の認識精度 を再現できなかったため,精度の向上を目的として 学習方法の一部変更を行った.変更内容は,AlexNet Caffe model[16] の学習方法に基づいた.AlexNet Caffe Model は,深層学習フレームワークである Caffe を用 いて学習された AlexNet であり,学習済みネットワー クや学習プログラム,学習方法などが GitHub で公開 されている.[16] で公開されている学習方法に基づき, [2] で重みの初期値として 1 が設定されている重み行列 について,初期値を 0.1 に変更した.また,入力画像 のバッチサイズを 128 から 256 に変更した.これらの 変更点以外は,Krizhevsky ら [2] の学習方法に準拠し ている.128 万枚の学習データを用いて,ネットワー クを 90 エポック学習させた.学習環境を表 1 に示す. 以降の実験環境は全て表 1 に示す通りである. 表 1: 実験環境 項目 仕様 OS CentOS 7.7.1908GPU NVIDIA GeForce GTX 1080 GPU メモリ 8GB フレームワーク tensorflow-gpu 1.13.1 CUDA 10.0 cuDNN 7.4.2 学習させた AlexNet に対して,5 万枚の評価データ を用いて予測精度を評価した.入力画像を 1000 クラス に分類するタスクにおける,Top-1 と Top-5 の精度を 評価した結果,58.71%と 81.38%を達成した. 4.1.2 非構造的枝刈りの適用 4.1.1 節で学習した AlexNet の全結合層に対して非構 造的枝刈りを適用する.本実験では,非構造的枝刈り 手法として,Han らよって提案されている手法 [5] を 用いる.既存手法 [5] は,学習済みネットワークに対し て,重みの絶対値が閾値以下である結合の重みを 0 に し,再学習を行うという手法である.閾値は a∗ σ と している.ここで,a はネットワークの各層の枝刈り に対する sensitivity,すなわち各層を枝刈りした際に ネットワークの予測精度がどのように変化するかを解 析した結果に基づいて決まるパラメータであり,σ は 各層の重み行列の標準偏差である.既存手法 [5] は,解 析結果に基づいてどのように a を決定するのかについ て言及していないため,計算によって a を求めること ができない.したがって本実験では,a の値を様々に 設定しながら実験を行った.また,a は AlexNet の 3 つの全結合層において全て等しい値を設定した.これ は,既存手法 [5] において,AlexNet の各層に対してス パース率(枝刈りによって 0 となる重みの割合)を変 化させながら枝刈りを適用したときの予測精度の推移 を示すグラフについて,3 つの全結合層のグラフの形 状がほぼ一致していたことに基づく設定である. 本実験では,a の値として,0.7, 0.8, 0.9, 1.0, 1.2, 1.3, 1.5, 1.7, 2.0, 2.4, 2.8, 3.2, 3.6, 4.0, 4.4, 5.0 の 16 種類 の値を設定した.a の間隔が不均等である理由は,様々 なスパース率のモデルを生成するためである.a の値 の大小によって,a の増加に対する全結合層全体のス パース率の増加量が異なる.よって,a の値を 0.1 ず つ増加させながら各 a について全結合層全体のスパー ス率を調査し,満遍なく様々なスパース率のモデルを 生成できるように,実験で用いる a の値を手動で設定 した. 設定した a の値に基づいて層ごとに閾値を求め,学 習済み AlexNet の各全結合層に対して絶対値が閾値以
図 4: 様々なスパース率で非構造的枝刈りを適用した ときの予測精度の変化 下の重みの値を 0 にする.閾値以下の重みを持つ結合 を記憶し,それらを絶対値が小さい方から 3 回に分け て枝刈りした.各回の枝刈りの後に,再学習 10 エポッ クを行った.各 a における実験について,枝刈りと再 学習 10 エポックのセットを 3 回完了したネットワー クに対して,ILSVRC2012 評価データセットを用いて Top-1 accuracy と Top-5 accuracy を評価した.結果を 図 4 に示す.図 4 では,横軸として a の代わりに,各 a における全結合層全体のスパース率を取っている. 結果として,全結合層全体のスパース率が 91%程度 までは,Top-5 accuracy について,非構造的枝刈り適 用前からの予測精度の低下が 3%以内に収まっており, スパース率を増加させても予測精度の推移はほぼ横ば いである.しかし,さらにスパース率を増加させると, 徐々に予測精度が低下し,スパース率が 99%を超える と急激に予測精度が低下するという結果が得られた.
4.2
提案手法適用
4.1.2 節で生成した,16 種類のスパース率の非構造 的枝刈り適用済みモデルに対して提案手法を適用する. 本論文では,紙面の都合上,16 種類の中からスパース 率の異なる 3 種類のモデルを選択し,それらのモデル に対して提案手法を適用した.3 種類のモデルとして, a = 1.7, 2.4, 2.8 のモデルを選択した.各 a のモデルに おける,全結合層全体のスパース率,Top-1 accuracy, Top-5 accuracy を表 2 に示す. 4.2.1 恒等関数を用いて再学習 提案手法は,活性化関数として線形関数を用いるこ とを前提としている.したがって,重み行列に対して 表 2: 各 a のモデルにおける全結合層全体のスパース 率と予測精度 a スパース率(%) Top-1(%) Top-5(%) 1.7 91.25 54.47 78.53 2.4 98.05 45.38 70.50 2.8 99.21 33.47 58.90 表 3: 各 a のモデルにおける再学習前後の予測精度 a Top-1(%) Top-5(%) 前 後 前 後 1.7 54.47 53.88 78.53 77.98 2.4 45.38 46.61 70.50 71.57 2.8 33.47 36.60 58.90 61.83 クラスタリングを適用する前に,活性化関数を恒等関 数に変更した.さらに,予測精度の回復を目的として 変更後のネットワークに対して再学習を行った. 具体的には,表 2 に示す 3 種類の a のモデルに対し て,fc1 層の活性化関数を ReLU 関数から恒等関数に変 更した.その後,ILSVRC2012 学習データセットを用 いて,ネットワークを 20 エポック学習させた.再学習 の前後の Top-1 accuracy と Top-5 accuracy を表 3 に 示す. 表 3 から,a = 1.7 のモデルは,再学習後の予測精 度が関数変更前の予測精度から 1%以内の低下に収ま る結果となった.また,a = 2.4, 2.8 のモデルについて は,活性化関数変更と再学習によって,約 1∼3%予測 精度が向上する結果となった.この精度向上の原因は, 更新される重みの個数の違いによるものと考えている. a = 2.4, 2.8 のモデルは表 2 に示すように,スパース率 がかなり大きい.全結合層の重みの 98,9%が 0 である ために,多くのユニットの出力値が 0 となる可能性が 高い.それに加えて,活性化関数として ReLU 関数を 用いているモデルは,負の数を出力するユニットの出 力値も 0 に変える.しかし,恒等関数を用いるモデル はそのまま負の数が出力される.したがって,ReLU 関 数を用いたモデルの方が,0 を出力するユニットの個 数が多くなる可能性が高い.a = 2.4, 2.8 のモデルは, 高いスパース率がゆえに,ReLU 関数を用いる場合に 0 出力のユニットが過多となり,それによって,更新さ れる重みの個数が過少となる.よって,比較的更新さ れる重みの個数が多い恒等関数を用いたモデルの方が 予測精度が高くなったと考える. 4.2.2 クラスタリングの適用 4.2.1 節において,活性化関数を変更し再学習を行っ た各 a のモデルに対して,クラスタリングを適用した.具体的には,fc1 層の重み行列の列数を削減するために, fc2 層の重み行列の各行を,値の類似度の高いもの同士 で複数のクラスタに分類した.クラスタリングアルゴ リズムとして k 平均法を用いた.k 平均法は最初のク ラスタの中央値を,fc2 層の重み行列の行の中からラン ダムに選択する.これにより,初期値(最初のクラス タの中央値)によっては,各行と中央値との距離が大 きいクラスタリング結果が得られる場合がある.各ク ラスタに属する行はそのクラスタの中央値で置換され るため,各行と中央値との距離が大きい場合は,推論 計算結果が置換前後で大きく異なってしまい,クラス タリング後の予測精度の低下に影響する可能性がある. したがって,5 回クラスタリングを適用し,各行とその 行が属するクラスタの中央値との距離の和が最小とな るクラスタリング結果を用いた.クラスタリング結果 に基づき,fc2 層の重み行列において,各クラスタに属 する行を中央値で置換した.置換結果に基づいて,fc1 層の重み行列の列数および fc2 層の重み行列の行数を 削減した.その後,ネットワークを 50 エポック再学習 した. 本実験では,k 平均法におけるクラスタの個数 k に 様々な値を設定した.AlexNet における fc1 層,fc2 層 の重み行列のサイズはそれぞれ 6400*4096,4096*4096 である.fc2 層の重み行列の 4096 個の行に対してク ラスタリングを適用するため,クラスタの個数 k は, 1≦ k ≦ 4096 を満たす整数である.本実験では,k の 値として,4000, 3500, 3000, 2500, 2000, 1500, 1000, 750, 500, 250, 100 を設定した.ただし,実験に要する 時間の都合上,一部の a のモデルでは実験していない k が存在する. 3 種類の a のモデルに対して,上記の各 k の値でク ラスタリングを適用した.クラスタリング後再学習し たモデルに対して,ILSVRC2012 評価データセットを 用いて,Top-1 accuracy と Top-5 accuracy を評価し た.また,全結合層全体のメモリ使用量を評価した. a = 1.7, 2.4, 2.8 のモデルの評価結果をそれぞれ図 5, 図 6,図 7 に示す.グラフの横軸は,クラスタの個数 k の代わりに,各 k における fc1 層の重み行列の列数削 減率 [%] を表す.すなわち,((4096− k)/4096) ∗ 100 に よって求めた数値である.列数削減率 0%におけるデー タが,各 a のモデルにおける提案手法適用前の予測精 度と全結合層のメモリ使用量を表す. 図 5 より,a = 1.7 のモデルに関して,k = 1500(列 数削減率 63.4%)において,提案手法適用前と比較し て Top-5 accuracy の低下を 2%以内に抑えた.このと き,全結合層のメモリ使用量を 53.1%削減した.また, k = 100(列数削減率 97.6%)においてメモリ使用量が 最小となり,84.7%の削減率を達成した.しかし,Top-5 accuracy が提案手法適用前から 10.4%低下した. 図 6 より,a = 2.4 のモデルに関して,k = 2000(列 図 5: fc1 層の重み行列の列数削減率を変更したときの 予測精度と全結合層のメモリ使用量の変化(a = 1.7) 図 6: fc1 層の重み行列の列数削減率を変更したときの 予測精度と全結合層のメモリ使用量の変化(a = 2.4) 数削減率 51.2%)において,提案手法適用前から Top-5 accuracy を低下させることなく,全結合層のメモリ使 用量を 34.2%削減した.また,k = 250(列数削減率 93.9%)においてメモリ使用量が最小となり,80.1%の 削減率を達成した.しかし,Top-5 accuracy は 13.9%低 下した. 図 7 より,a = 2.8 のモデルに関して,k = 1000 (列数削減率 75.6%)において,Top-5 accuracy の低下 を 0.3%程度に抑えながら,全結合層のメモリ使用量を 38.3%削減した.また,k = 500(列数削減率 87.8%)に おいて,メモリ使用量が最小となり,53.7%の削減率を 達成した.このときの Top-5 accuracy の低下は 5%程 度であった. これらの結果をまとめると,a の値によらず,すなわ ち,提案手法適用前のモデルのスパース率の大小によら
図 7: fc1 層の重み行列の列数削減率を変更したときの 予測精度と全結合層のメモリ使用量の変化(a = 2.8) ず,k = 2000 程度までは,Top-5 accuracy の低下をた かだか 1%程度に抑えることができることがわかった. このとき,全結合層のメモリ使用量を 34.2%∼41.7%削 減した.また,最大メモリ使用量削減率は,a の値が小 さいほど大きいことがわかった.この原因は,スパー ス率の大小によって,非ゼロ要素数の削減率が異なる ためだと考える.a の値が小さいことは,提案手法適用 前のモデルにおいてスパース率が小さいことを意味す る.クラスタリング結果に基づく,fc1 層の重み行列の 該当列の統合において,スパース率が小さい場合,足 し合わせる成分中に含まれる非ゼロ要素の個数が多い ため,列統合による非ゼロ要素数削減率が大きくなる 可能性が高い.非ゼロ要素数削減率が大きいとメモリ 使用量削減率も大きくなる.
4.3
非構造的枝刈りモデルとの性能比較
4.3.1 同一メモリ使用量における予測精度の比較 4.2.2 節の実験結果から,各 a のモデルについて,k 平均法におけるクラスタ数 k を減らす,すなわち fc1 層 の重み行列の列数削減率を増加させると,全結合層の メモリ使用量を削減できることがわかった.このメモ リ使用量削減は,提案手法適用前の非構造的枝刈り適 用済みモデルにおいて,スパース率をさらに増加させ ることでも実現できる.したがって,各 k の値でクラ スタリングを適用し実現したメモリ使用量と同一のメ モリ使用量となるように非構造的枝刈りを適用し,メ モリ使用量が等しい状況における提案手法と非構造的 枝刈り手法の予測精度を比較した. 非構造的枝刈り手法は,4.1.2 節と同様に,Han らの 手法 [5] を用いた.提案手法において,各 k の値でクラ 図 8: 同一メモリ使用量における提案手法と非構造的 枝刈り手法の予測精度の比較(a = 1.7) スタリングを適用し実現したメモリ使用量と同一のメ モリ使用量となるようなスパース率を求めた.本実験 では,3 つの全結合層に対して等しいスパース率を設 定した.求めたスパース率を満たすように,各全結合 層に対して,絶対値が小さい重みの値を 0 にする.枝 刈りの対象となる重みを持つ結合を記憶し,それらを 絶対値が小さい方から 3 回に分けて枝刈りした.各回 の枝刈り後に再学習 10 エポックを行った.枝刈りと再 学習 10 エポックのセットを 3 回完了したネットワー クに対して,ILSVRC2012 評価データセットを用いて Top-1 accuracy と Top-5 accuracy を評価した.同一メモリ使用量における提案手法と非構造的枝刈 り手法の予測精度を比較した.a = 1.7, 2.4, 2.8 のモデ ルの比較結果をそれぞれ図 8,図 9,図 10 に示す.グ ラフの横軸は,メモリ使用量の変わりに,全結合層の メモリ使用量削減率を用いている.また,メモリ使用 量削減率 0%におけるデータは,提案手法適用前の予測 精度である. 図 8 より,a = 1.7 のモデルに関しては,メモリ使用 量削減率が 81.3%のときに Top-5 accuracy の差が最大 となり,提案手法が非構造的枝刈りより約 3%精度が高 い結果となった.メモリ使用量削減率の大小にかかわ らず,同一メモリ使用量における提案手法と非構造的 枝刈りの予測精度はほぼ同じであった. 図 9 より,a = 2.4 のモデルに関しては,全てのメモ リ使用量削減率において,提案手法の予測精度が非構造 的枝刈りの精度を上回った.おおむね,メモリ使用量削 減率が大きくなるにつれて提案手法と非構造的枝刈り の予測精度の差が大きくなった.メモリ使用量削減率 が 80.1%において,提案手法と非構造的枝刈りの Top-5 accuracy は適用前からそれぞれ 13.9%,28.3%低下し た.このとき,Top-5 accuracy の差は最大となり,提
図 9: 同一メモリ使用量における提案手法と非構造的 枝刈り手法の予測精度の比較(a = 2.4) 図 10: 同一メモリ使用量における提案手法と非構造的 枝刈り手法の予測精度の比較(a = 2.8) 案手法が非構造的枝刈りよりも 14.5%高い精度を得た. 図 10 より,a = 2.8 のモデルに関しても同様に,全 てのメモリ使用量削減率において,提案手法の予測精 度が非構造的枝刈りの精度を上回り,おおむね,メモリ 使用量削減率が大きくなるにつれて,予測精度の差が 大きくなった.メモリ使用量削減率が 53.7%において, 提案手法と非構造的枝刈りの Top-5 accuracy は適用前 からそれぞれ 5.3%,18.3%低下した.このとき,Top-5 accuarcy の差が最大となり,提案手法が非構造的枝刈 りよりも 13.1%高い精度を得た. 実験結果から,a = 1.7 のモデルのように,提案手法 適用前のスパース率が比較的小さい場合はメモリ使用 量削減率が大きい場合でも提案手法と非構造的枝刈り の間で予測精度の差はほぼない.しかし,a = 2.4, 2.8 のように,提案手法適用前のスパース率が比較的大き い場合は,メモリ使用量削減率が大きくなるにつれて, 提案手法と比較して非構造的枝刈りの精度低下が大き く,予測精度に大きな差を生じることがわかった. 4.3.2 同一予測精度におけるメモリ使用量削減率の 比較 同一メモリ使用量における精度比較に加えて,予測 精度が同じ場合における,提案手法と非構造的枝刈り のメモリ使用量削減率の比較も行った.k の値を変え ながらクラスタリングを適用し得られた各モデルの予 測精度に関して,それらの予測精度と同程度の予測精度 を非構造的枝刈りで実現する場合,メモリ使用量削減率 がどれくらいになるのかを,図 8,9,10 のグラフを用 いて求めた.具体的には,提案手法の Top-5 accuracy を示す折れ線中の各点を通る水平な直線を引き,その 直線と非構造的枝刈りの Top-5 accuracy を示す折れ線 との交点の x 座標を求めた. a = 1.7 のモデルに対して,同一精度における提案手 法と非構造的枝刈りのメモリ使用量削減率を比較したと ころ,提案手法の Top-5 accuracy が 73.9%(k = 500) のとき,メモリ使用量削減率の差が最大となった.提 案手法のメモリ使用量削減率が 76.4%であるのに対し て,非構造的枝刈りのメモリ使用量削減率は約 62%に とどまり,提案手法が非構造的枝刈りよりも約 14%メ モリ使用量削減率が大きくなった. a = 2.4 のモデルに対しては,Top-5 accuracy が 65.5%(k = 750)のとき,メモリ使用量削減率の差が最 大となった.提案手法のメモリ使用量削減率が 66.6%で あるのに対して,非構造的枝刈りのメモリ使用量削減 率は約 39%にとどまり,提案手法が非構造的枝刈りよ りも約 28%メモリ使用量削減率が大きくなった. a = 2.8 のモデルに対しては,Top-5 accuracy が 58.6%(k = 1000)のとき,メモリ使用量削減率の差が最 大となった.提案手法のメモリ使用量削減率が 38.3%で あるのに対して,非構造的枝刈りのメモリ使用量削減 率は約 2%にとどまり,提案手法が非構造的枝刈りより も約 36%メモリ使用量削減率が大きくなった.
5
まとめと今後の課題
本論文では,推論モデルにおけるメモリ使用量の削 減を目的として,深層ニューラルネットワークに対す る圧縮手法を提案した.既存の圧縮手法の一つである 非構造的枝刈りは,適用後に疎な重み行列を生成する ため,非ゼロの重みに加えてインデックスデータも記 憶する必要がある.記憶すべきインデックスデータの 個数を削減するために,ネットワークのユニット数を 削減することを考えた.提案手法は,ユニット数を削減するために,重み行列に対して k 平均クラスタリン グを適用し,各行を k 個のクラスタに分類した.さら に,各クラスタに属する行を,クラスタの中心,すなわ ちクラスタに属する行の平均値に置換した.置換結果 に基づき,ユニットを統合し,ユニット数を削減した. ユニット数の削減は重み行列において列数が削減され ることと等しいため,インデックスデータの個数削減 につながり,疎行列のメモリ使用量削減に貢献する. スパース率の異なる 3 種類の非構造的枝刈り適用済 み AlexNet を用意し,3 種類のモデルに対して k を変 えながら提案手法を適用したところ,適用前の予測精 度からの精度低下をたかだか 1%程度に抑えながら,全 結合層のメモリ使用量を最大で 41.7%削減できた.ま た,同一メモリ使用量削減率における提案手法と非構 造的枝刈りの予測精度を比較したところ,提案手法の予 測精度が非構造的枝刈りの精度よりも最大で 14.5%高 いという結果を得た.この比較結果より,提案手法適 用前のモデルのスパース率が大きいほど,同一メモリ 使用量における提案手法と非構造的枝刈りの予測精度 に大きな差が生じる傾向があることがわかった.同様 に,同一予測精度における提案手法と非構造的枝刈り のメモリ使用量削減率を比較したところ,提案手法の メモリ使用量削減率が非構造的枝刈りの削減率よりも 最大で約 36%大きいという結果を得た. 今後の課題として,提案手法クラスタリングにおい て k 平均法以外のクラスタリングアルゴリズムを用い たときの,メモリ使用量削減率および予測精度の評価 を予定している.また,構造的枝刈りといった,非構 造的枝刈り以外の既存の圧縮手法との性能比較も予定 している.
謝辞
本研究の一部は,JSPS 科研費 JP15H01687 および JP16H02801 の補助による.参考文献
[1] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A.C. Berg, and L. Fei-Fei,“Imagenet large scale visual recognition chal-lenge,” International Journal of Computer Vi-sion, vol.115, no.3, pp.211252, 2015.
[2] Krizhevsky, A., Sutskever, I., and Hinton, G. E. ImageNet classification with deep convolutional neural networks. In NIPS, pp. 11061114, 2012.
[3] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” Com-puting Research Repository, vol.abs/1512.03385, 2015.
[4] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” Proceedings of CVPR, pp.19, 2015.
[5] S. Han, J. Pool, J. Tran, and W. Dally,“Learning both weights and connections for efficient neural network,” Advances in Neural Information Pro-cessing Systems, pp.1135 1143, 2015.
[6] T. He, Y. Fan, Y. Qian, T. Tan, and K. Yu,“Re-shaping deep neural network for fast decoding by node-pruning,”2014 IEEE International Confer-ence on Acoustics, Speech and Signal Processing (ICASSP), pp.245249, 2014.
[7] Song Han, Huizi Mao, and William J. Dally. A deep neural network compression pipeline: Pruning, quantization, huffman encoding. Arxiv Preprint Arxiv:1510.00149 (2015).
[8] K. Simonyan, and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” Computing Research Repository, vol.abs/1409.1556, 2014.
[9] S. Han, H. Mao, and W.J. Dally, “Deep com-pression: Compressing deep neural network with pruning, trained quantization and huffman cod-ing,”International Conference on Learning Rep-resentations (ICLR), 2016.
[10] Yi Sun, Xiaogang Wang, and Xiaoou Tang. Spar-sifying neural network connections for face recog-nition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 48564864, 2016.
[11] W. Wen, C. Wu, Y. Wang, Y. Chen, and H. Li. Learning structured sparsity in deep neural net-works. In Advances in Neural Information Pro-cessing Systems, pages 20742082, 2016.
[12] Hengyuan Hu, Rui Peng, Yu-Wing Tai, and Chi-Keung Tang. Network trimming: A data-driven neuron pruning approach towards efficient deep architectures. arXiv preprint arXiv:1607.03250, 2016.
[13] H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf. Pruning filters for efficient ConvNets. In ICLR, pages 113, 2017.
[14] Sajid Anwar, Kyuyeon Hwang, and Wony-ong Sung. Structured Pruning of Deep Con-volutional Neural Networks. arXiv preprint arXiv:1512.08571, 2015.
[15] H. Mao, S. Han, J. Pool, W. Li, X. Liu, Y. Wang, and W. J. Dally, “Exploring the Regularity of Sparse Structure in Convolutional Neural Net-works,”CoRR, 2017.
[16] caffe/models/bvlc alexnet at master BVLC/caffe GitHub.
https://github.com/BVLC/caffe/tree/master/ models/bvlc alexnet, (2019-10-11)