Model-Integration Rapid Training Based on Maximum Likelihood for Speech Recognition
4
0
0
全文
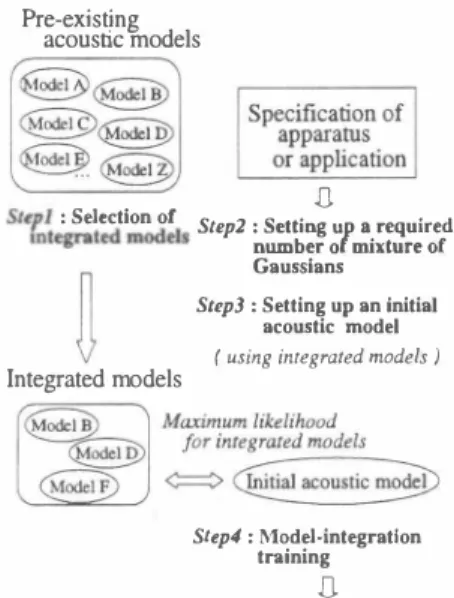
(2) φ. EUROSPEECH 2003 - GENEVA. 2 _E21C(m,zJ)[t] σf(m,j)[t+l] E:;;1A(m,i)[t]. cally close to specific speakers,speaker adaptation c飢also be. _. executed. The integrated models can be selected as in the same way of“By Sufficient Statistics Speaker Adaptation"[l].. 2.2. Setting up a req凶red number of mixture of Gaussians. where t is iteration times and j is index of dimension of x,加d A(m,i)[t], B(m, i, j)[t] ,ωd C(m, i,j)[t] are calculated as fol. C(m,i,j)[t]. =. 乙川)仰_ J.lf(m,j)[t])2. 2.4. Model-integration training. Lg(け. {2二%υ,i)g(Xjμg(l,i),σ;似))}dx. 1n the final step,a new model-integration-type of tr副ning is pro posed. An acoustic model is estimated from the initial acoustic model based on maximum likelihood for the integrated models. A rapid training can be executed by directly using statistics of. (7). where. 出巴 integrated models. This training procedure is the same as. ,.(Xj m)[t]. E恥1 algorithm. 2.4.1.. (5). 、‘,eノ ζU Z .d 、EFJ q,a nuJ σ. 9 μ. describes a method to make an initial model from the integrated models.. z. important to obtain a high-precision acoustic model. This paper. m. 1n白e third step,初initial acoustic model (ωf(m)[O]'μf(m,j)[O], 姐dσf(m,j)[O] in sec.2.4.2) is set up. The initial model is quite. z 吋1. ∞ ∞ p ilι. B(m,i,j)[t] =. 2.3. Setting up an initial acoustic model. z. cult to set up a required number of mixture because the number is restricted to出e one of the integrated models.. d. mod巴Is according to a specification of apparatus or application. While,位aditional model-integration-type of trainings are di飽・. μ. d m. 加re (Mf in sω.2.4.1) independent of the one of the integrated. qa ns σ. mw ∞ ∞ f l I L. is set up. The proposed位創mng c組 decide a number of mix. nud Z OM 。3 U U 同 hL 工同 M 旧 ,a冒t z. = h. lows:. A. 1n the second step, a required number of mixture of Gaussians. (4). Evaluation戸nction. ωf (m ) [ 吋 f(X jμf(m ) [t], σ? (m ) ド ] ). = _�・. 品. 、. ZKJIωf(k)[tJf(Xjμf(k)[t],σÎ (k)[t]). ( 8). Transition probabilities of f酌1M of an acoustic model are. Evaluation function iぬs a likelihood for the integrated models. calculated as follows:. not for training utteranc巴 data. Statistics of an acoustic model. dω吋吋σイ仏?L(何mηn. [i][jJ = where. Tf[i][jJ. z�!1 Tg(k)[i][jJ _� 山山 E;二� E�二1九(k)[iJ[jJ. Tg(k)[i][jJ. and. (9). are回nsition probabilities from. ith state to jth state of HMM of estimated acoustic model and. m. m. n3 o ''唱弘 ∞ ∞ fl← ムL 同. L. 一一 QU O. q,.,Ta, σ ,J HF Z FVJ ,vd ω とL日. (川ω叫f (川m叫)';1,州μ的州fれ(m)川,川卸 )) mated by maximizing t白he evaluation function as follows:. of. kth integrated. model, respectively, and. stat巴S. Lg(・}. L Vg川g(Xjμg川,σ;(IJ))}dz. (l). 2.4.3.. Nst. is a number of. Rapid training technique. The average overlapping of the ne紅白t Gaussians for an acous where. Ng. is a number of integrated models, and f(.)組d. g(.). are Gaussian distributions of 巴stimated acoustic model and of integrated models, respectively.. M, and Lgωare a number. of mixture of Gaussians of estimated acoustic model and of ith. integrated model, respectively. Wf(m)and Vg(l,i) are weights, μf(m)組dμg川町means, 組dσ (m)andσ (l,りare vari. ;. ;. ances,ofm血Gaussian of estimated acoustic mod巴1and of. lth. Gaussian of ith integrated model, respectively,. 2.4.2.. To maximize the evaluation function, statistics of an acoustic. acoustic model are hardly over. 7(z;m )=. {1. 1 UM ( )n悶byω川 f(印刷,af( m ) ). 0. (10). otherwise. ,.(Xj m) for the inte. grat巴d models are described.. Substiωting equation (10) for the equation (5), (6), (7) , a new estimation formula is obtained as follows:. (2). ωf(m)[t+l] =. (3). μf(m,j)[t+1] =. 22122Jmj)υ州). _M . _N. 口 'L 、. (. 一ε21B(m,M)[t] μf(m,j)[t+l]一 εユA(m,i)[t]. an. lapped each other. On the assumption, ,.(Xj m) in eq.(8) becomes quite simple as follows:. ). �M, �N. assume 出at Gaussians of. -EA --且. model are repeatedly calculated as follows:. ε土'1 A(m, i)[t] = E��1 E;�1 A(k, i)[t]. averag巴 of Mahalanobis' gen巴ralized distance is 3.3. Here, we. ln Fig.2,出e way of deciding of values of. Estimation ofan acoustic model. ωf (m )[t+ 1]. tic model with 16 Gaussians is described abov巴 in Fig.2. The. E ��1 E;;;1乞Jl'HUg(l,z) ε2f1εffJmd}Ug(I,z)μg(l,i,j) _N_ _Q_ ,. ZJ1乞Jlm,HUg(I,z) 、. (12). 円,t 司lム 円〆臼.
(3) 。シ. EUROSPEECH 2003 - GENEVA. Integrated models rーへ Estimated model 16 Gaussians �吋 16 Gaussians. 百e average overlapping of Gaussians 01. Comparison with various methods. 02 。. me出od -5. Propo田d 0. 3.3. I iIDt: male I init: femal e. 5. (for an acoustic model wi山16Gaussians). Estimated acoustic model. ρf史に y(x,m) Y=o. 一一一一 :y=1:y=o. 71.6%. 82.2%. 70.7%. 80.9%. B aum W -蹴 e l ( b U nec )h. . % 824. BySu節目nt S阻nstJcs. 82.. 10民C. (1=1). I day. 2竺よ三 時. ;::γつ柳川. x. I. Figure 2: ,(x; m) for Gaussians of integrated models. 2. tral皿(nt z g 5}. d 門戸両吹ぶ山a1e). x. r (x; m ) for integrated models. Y =〉\よおぶ;\. lnitial (同}. 町祖rung tJme. Word aιcuracy for iteration times. よユ. σf(m,j) [t+1J. word acc町田y. e. 3. Figure 3: }Iゐrd accuracy and training time for an acoustic. model for required speakers. =. L�fIztfJmAU9(IA)(σ;(tJJ)+μ;(tJJ)) ? ε22 1 ε含白J「m V町9 υ 一 μd? ( m 'JJ川3υ川)[μH川川+刊1η1. .2. Iterauon tlm s (t). 3.1. Training foran acoustic model forreq凶red sp eakers. 4吋). (13). where Q9(m,i) is a number of Gaussians Vg(ー)g{.) of ith inte grated model n悶byωf(m)/ { X;μf(m), 加)) of an estimated acoustic model.. 付. A rapid training c釦be executed by directly estimating by a smal1 number of statistics of the integrated models.. 3. Experimental results and discussion Japanese speech corpus collected by Acoustical Society of Japan[31 is used in 0ぽexperirnents. This database consists of 306 speakers and each speaker uttered about 150 sentences Speech data are sampled at 16kHz and 1 6bits. Twelfth-order mel-仕equency cepstrum coefficients (MFCC) are calculated ev ery 10ms. The cepstrum di仔巴rences (delta-MFCC) and d巴Ita power are also used. Cepstrum mean normalization (CMN) is performed based on the whole utter釦ce average.. As integrated models, monophone I品1Ms of 43 phones have 3 states and each state has a mixture of 1 6 or 64 Gaus sians. And as an estimated acoustic model, monophone HMMs of 43 phones have 3 states and each state has a mixture of 16 Gaussians. 46 speakers' data (23 male and 23 female) 訂e used for testing data, which 紅e not inc1uded in町aining of integrated models. Word accuracy for gender-independent acoustic model and 紅白ning time are investigated for various methods. Perfor mance evaluation is carried out using the Japanese dictation sys・ tem Julius[4] with the 20k newspaper artic1e language model. τne baseline tr制ing by Baum-Welch algorithm shows the average word accuracy of 82.4%組d training time of about 1 day using lGHz CPU. It takes a lot of tirne to obtain 釦acoust1c model.. Training for obtaining an acoustic model for required speakers is shown. This experiment is a fundamental one for speaker adaptation. As integrated models, two monophone lTh仏1s with 16 Gaussians for male and for female are selected. These mod els have been trained by Baum-Welch algorithm off-line. An acoustic model for gender-independ巴nt is estimat巴d from the integrated models for male and for female by the proposed method. The integrated model for male or for female is used as an initial acoustic model In Fig.3, the results for the proposed me出od are de scribed, and the results for “By Sufficient Statistics Speaker Adaptation"[I]訂e also described. The proposed method can obtain an acoustic rnodel in about 10 s巴conds, and 1000 times faster than the廿aining by Baum-Welch algorithm. And the pro. posed method can obtain high word accuracy of 82.2%(using male-based initial model) from 71.6%or 70.7%before training. AIso, the results show that the way of making an initial model is quite irnportant to obtain a high-precision acoustic model. 3_2_ Training foran acou stic model with a req凶red number of mixture of Gaus sian s. Tr出ning for obtaining an acoustic model with a required num ber of rnixture of Gaussians is shown. TIùs experiment is a fun damental one to obtain an acoustic rnodel with a required nurn ber of mixture according to a specification of apparatus or appli cation. Here, an acoustic model wi出 16 Gaussians is obtained 仕orn an integrated rnodel with 64 Gaussians. As佃integrated rnodel, one rnonophone lTh仏1 with 64 Gaussians for gender independent is selected. An acoustic rnodel with 16 Gaussians for gender-independent is estirnated from the integrated rnodel by the p;uposed method. An initial acoustic model is made by picking up 16 Gaussians from白e integrated model. In Fig.4, the results for the proposed rnethod are described The proposed rnethod can obtain a required nurnber of mixtur巴. 。。 句EA つ中.
(4) EUROSPEECH 2003. -. ゆ. GENEVA. Integrated model戸『へEstimated model --y. 64 Gaussians. word acc町acy 山叫 (同). Proposed. |山I凶. 73.7%. Bau皿-Welch. (baseline). 巳e R. 忘. 帽g 詰. ] 診. 田n. 80.2% 82.4%. method. E3e. I .;,�� I init: femaJe inil:. (1=1). day. I. 2. 65.2%. 80.4%. 63.3%. 80.4% 824 . %. 臼me. 20sec. (1=1). 1. day. Eiãìím-WeIC五(baseline) 貯叩凶(皿t: female). /. ;:: I| / /. \. Proposed (init: gid) 0. 官制m n品 { �S). trammg. Word acc山acy for iteration tirnes. A剛r さ削| ;. 7回. imu aIt { sO}. Baun E( e 回- Wenlec)h bu. Baum-Welch (b踊elit官). 回剛o. word accuracy. Propo日d. 10民C 1. 16 Gaussians. Comparison with various methods. 町血 n E U1g. Word accuracy for iteration times. 田. 70.0. trauu (nt孟�S). --y. 64 Gaussians. Comparison with various methods. me出od. r-ーへ Estimated model. Integrated models. 16 Gaussians. 3. 3. IteratioD times (1). 7叩. Propo民d (init: male). 65.0 60.0. 1. 2. 3. 1胞rarion times (1). Figure 4:恥rd accuracy and training lime for an acoustic. Figure 5: Word accuracy and training time for an acoustic. model with a required number of mixture of Gaussians. modelfor requ問d speakers and with a required number of mix ture of Gaussians.. of Gaussians. The results show that the proposed method can obtain an acoustic model in about 10 s巴conds,加d 1000 times faster than 出E仕組ning of Baum-Welch algorithm. And the pro posed method can obtain high word accuracy of 80.2% from the word accuracy of 73.7%before training. While,“By Suffi cient Statistics Speak:er Adaptation"[I] can not ob凶n a required number of mixture's model. To obtain a more high-precision acoustic model, the acoustic model obtained by the proposed method can be re-trained using a small number of sentence ut ter釦ce data. 4. Conclusions A new model-integration-type of training for obtaining a re・ quired number of mixture of Gaussians is proposed. The pro posed町aining can alter a number of mixture of Gaussians into a requ汀ed one according to a specification of apparatus or appli cation. Besides, a rapid 紅白ning can be executed by using pre existing acoustic models. In future works, the way of making an initial acoustic model will be investigated,加d佃evaluation for speak:er adaptation will be done. 5. References 3.3. Thaining for an acoustic model for required speakers. [1]. Shinichi Yoshizawa, Akira Baba, Kanako Matsunami, Yuichiro Mera, Miichi Yamada, K.iyohiro Shikano,“Un supervised Speak:er Adaptation Based on Sufficient HMM Statistics of Selected SpeakersヘProceedings of th巴 ICASSP, 2001.. [2]. M.J.F. Gales, Recognitionぜl'ヘProce巴dings of t白h巴 ICSLp, pp.1783-1786, 1998.. (3). Katunobu Itou, Mikio Yamamoto, Kazuya Takeda, Toshiyuki Takezawa, Tatsuo Matsuoka, T,巴tsunon Kobayashi, K.iyohiro Shikano and Shuichi Itahashi, "JNAS: Japanese speech corpus for large vocabulary continuous speech recognition researchヘ The Joumal of 由e Acoustical Sωiety of Japan (E), Vo1.20, pp.199・206, 1999.. [4]. Akinobu Lee, Tatsuya Kawahara, Kazuya Tak:eda and K.iyohiro Shikano, "A new phonetic tied-mixture model for e節cient decoding", Proceedings of血e TCASSP, pp.1269-1272,2000.. and with a req凶red number of mixture of Gaussians. Training for obtaining 飢acoustic model for required speak:ers and with a required number of mixture of Gaussians is shown Here, an acoustic model with 16 Gaussians is obtained from in tegrated models with 64 Gaussians. As integrated models,two monophone HMMs with 64 Gaussians for male and for female is selected. An acoustic model with 16 Gaussians for gender independent is estimated from the integrated models by the pro posed method. The initial acoustic model is made by selecting 16 Gaussians from the male-based integrated model or female based one. fn Fig.5,the results for the proposed method are described. The proposed method can obtain a required number of mixture of Gaussians. The results show 白紙 出e proposed method can obtain an acoustic model in about 20 seconds, and 1000 times faster白組曲e training of Baum-Welch algorithm. And 出e pro posed method can obtain high word accuracy of 80.4%台om 65.2%or 63.3%before training. While,“By Sufficient Statis tics Speak:er Adaptation"[I] can not obtain a required number of mixture's model.. nHd 旬EA 円ノU.
(5)
図


関連したドキュメント
This paper deals with the a design of an LPV controller with one scheduling parameter based on a simple nonlinear MR damper model, b design of a free-model controller based on
In this realization, the indecomposable objects of the cluster category correspond to certain homotopy classes of paths between two vertices.. Keywords Cluster category ·
In this paper, for the first time an economic production quantity model for deteriorating items has been considered under inflation and time discounting over a stochastic time
To overcome the drawbacks associated with current MSVM in credit rating prediction, a novel model based on support vector domain combined with kernel-based fuzzy clustering is
This, together with the observations on action calculi and acyclic sharing theories, immediately implies that the models of a reflexive action calculus are given by models of
Then the strongly mixed variational-hemivariational inequality SMVHVI is strongly (resp., weakly) well posed in the generalized sense if and only if the corresponding inclusion
L´evy V´ehel, Large deviation spectrum of a class of additive processes with correlated non-stationary increments.. L´evy V´ehel, Multifractality of
More precisely, the category of bicategories and weak functors is equivalent to the category whose objects are weak 2-categories and whose morphisms are those maps of opetopic
