Blind Speech Extraction Combining ICA-based Noise Estimation and Less-Musical-Noise Nonlinear Post Processing
5
0
0
全文
(2) beamforming techníque, e.g., null beamformer [6] or adaptive beamforming. Finally, we obtain the sp田ch enhanced signal based on SS. The detailed signal processing is shown below. We consider the following J-channel observ巴d signal in time-f陀quency domain as. (1) x(f, T) = h(f)s(f, T) + n(f, T), where x(f,T) = [x, (f,T), • 目 . , X (f, T)]T is the observed. j. hj(刀]T. signal vector, h(刀 = [h,(f), 目. . , is the transfer function vector, s(λT) is 出e target sp田ch, and n(f,T) = n , (f,T), . • ., nj(f, T))]T is the noise vector. For enhancing th巴 target speech, DS is applied to the observed signal. This can be represent巴d by. [. T. yos(f, T)=gos(f, θu) x(f, T), S gos(f, θ)=[gjD )(fJ),. (2). 品目))(f刈]T,. (3 ). -' gjD勺め= J 叫 -i 2n(f/M)五 dj sín 8/c ,. (. ). (4). where Yos(f, T) is the output of DS, gos(f, 8) ís th巴 coefficient vector of DS a汀ay, and 8u is th巴 loo k direction. Also, !s is th巴 sampling frequency and dj (j = 1, ・・・, J) is the microphon巴 position. B巴sides, M is the DFT size, and c is th巴 sound ve locity. Finally, we obtain the enhanced target speech spec汀al amplitude b也sed on SS. This proc巴dure can be given as. ゆss(f, T)I =. I "'/Iyos(!, T)12 -β. E[lñ(f, T)I2] � (where Iyos(f, T)12 ーβ. E[lñ(f,T)12 ] I y. IYos(f, T)I (otherwis巴),. >. 0), (5 ). wher巴yss(f, T) is the enhanced target speech signal, βis the subtraction coefficient, y is ftooring coefficient, í1(f, T) is the estimated noise signal, and E[.] is an expectation operator íì(f, T) is 0吋inarily estimated by some beamforming tech nique, e.g., fixed or adaptive beamforming. 3. PROPOSED CHSS+BF AND ANALYSIS 3.1. Overview In the proposed chSS+BF, 自rst, channel-wís巴 noise estima tion is conducted. Next, SS is applied to the multi-channel in put signal channel-wisely. Finally, we p巴rform DS to the SS applied multi-channel signal to obtain the sp田ch enhanced signal. In this paper, we prove that this architecture can míti gate the musical noise (details are shown in Sect. 3.3). 3.2. Algorithm of chSS+BF In the proposed method , first, we perforrn SS in each input channel. Consequently, we obtain th巴 multi-channel target sp巴ech enhanced signal by channel-wis巴 SS. This can be des ígnated as. (ゾI Xj(f, T)12 - ß. E[lñj(f, 十)12]. |砂y;?Cぬ叫哨h凶附5お町S. |刊o. (和ot出h巴釘rWIおs 巴め), (6). wh m yjc刷小) is the叫et sp吋巴伽IC巴d叩al by SS at j channel, and ñ j(f,T) is th巴 巴stlmat巴d noi犯signal in j. channel. Finally, we obtain th巴 target speech 巴nhanced signal by applying DS to YchSS(f, T). This proc巴dur巴 can be repr巴sented by. y(f,T) = gbs(f,8u)YchSS(f,T), ss , yy悶(f, T)]T, Yc附U,T)=bid )(f, T),. (7). where y(f, T) is the final output of the proposed method. (8). 3.3. Kurtosis-based analysis 3.3.1. Analysis strategy It has been reported by出巴 authors that the amount of gen 巴rated musical noise is strongly related with the difference between the before-and-after kurtosis of a signal in nonlin ear signal processing [4]. Thus, in thís section, we analyze the amount of generated musical noíse through the proposed chSS+BF and BF+SS, based on kurtosis. Basically, kurtosís increases through nonlinear signal processing, and larger ín crement of th巴 kurtosis by nonlinear signal processing I巴ads to more amount of musical noise generation. Thus, it can be 巴x pected that th巴 generat巴d musical noise b巴comes smaller with lower- kurtosis-increment signal processing. In the following subsectíons, hence, we analyze the kurtosis of BF+SS and the proposed chSS+BF, and prove which method can reduce the resultant kurtosis. Note that our analysis has no limitation in assumption of nois巴 model, thus any noises including Gaus sian and non-Gaussian can be under consideration. 3.3.2. Kurtosis Kurtosis is one of the popular higher-order statistics for as sessment of non-Gaussianity. Kurtosis is defined as kurtx =. 与. (9). μi. where X is the probability variable, kurtx is the kurtosis of x, and μ11 is the n-th order moment of x. Although kurtx becomes 3 if X ís Gaussían sígnal, note that the kurtosis of Gaussian signal ín power spectral domaín becomes 6. This ís becaus巴 Gaussian sígnal ín time domain obeys chi-squar巴 distribution with two degrees of 合eedom in power spectral domain. In chi叩are dístribution with two d巴grees of freedom, μ4/μ =. i. 6 3.3.3. Resultant kurtosis in spectral subtraction. [4]. In this s巴ction, w巴 analyze the kurtosis after SS. For evaluat ing the resultant kurtosis of SS, we utilize gamma distribution as a model of input signal in power spectral domain The probability density function (p.d.f.) of the gamma distribution for probability variable X is defined as ' P(X)=r ( α) θーα. X αー, e-� ( 10). [7].. where X三0, α> 0 and 8 > O. Here, α denotes the shap巴 P訂ameter and 8 is th巴 scale paramet町田 Besides, r(-) is the gamma function. Gamma distribution with α= 1 corresponds to chi-square distribution with two degr巴巴s of freedom. More over, ít is well- known that the av巴rage of the gamma distribu tion is given by E = αθ. Furthermore, th巴 kurtosis of. - 214-. [P(x)].
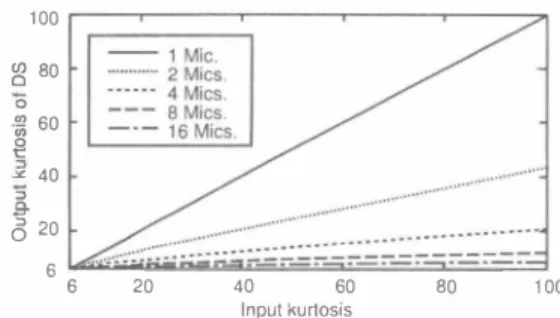
(3) 100. Gamma distribution, kurtGM , can be designat巴d as [4] kurtGM=. (α+• 2") (α+ 3) " -/. (1J) α(α+ 1) 1n SS,the av巴rage of observed power spec汀a is utilizβd as an estimated noisεpower spectrum. So the amount of subtrac tion is β ・α(}. Subtraction of th巴 巴stimated nois巴 power spec trum in each frequency band四n be regarded as deforming of the p.d.f., which is th巴 lateral shift of the p.d.f. to zero pow巴r direction. As a result, the probability of the negative power component arises. To avoid this, such a negative component probability is repl低ed by 日ro (so-called ftooring technique ). The resultant p.d.f. after SS can be written as. (c. (x + β ・α(} )αー l e ー ヰt (X>O) , (12 ) P (X ) = � _ ;ø a8o _. lcr xrlriX dx. (x=0), where C = 1/[ [(α)ea]目 Thus, the resultant kurtosis after ap '_. ,. plying SS, kurtss , can be given as eaß ( 尚子 } kurtss ;::.: 一二一物 + 加+珍+β 1,)+ v-:/唯 α�叫廿 " ' , " " 2 ' 一悌一 l刀 一α(a+ 1)[' J (13). Although we cannot describ巴 details of the derivation of (1 3) due to the limitation of the paper space, reference [4] helps you to understand th巴 derivation of (13).. 3.3.4. Resultant kurtosis after DS 1n this section, we analyze the kurtosis after DS,and we reveal that DS can reduce the kurtosis of input signals.. =. Now let Xj (j 1,. . . , J) be J-channel input signal, and they are i.i.d. signal each other. Moreover, we assume that the p.d.f. of Xj is both side symmetry and its average is zero. Th巴se assumptions make odd order cumulants zero except the first order cumulant. For cumulants , it is well known that the following relation holds; n (14) cumll(aX + bY) = a" cumn(X) + b cumll(y), where cumll(X) expresses the n-th order cumulant of prob ability variable X. Bas巴d on th巴 r芭lation (14), the resultant S cum山nt after DS, K�O ), can be given by, kjDS)=κ,/1"-1, (15 ) where Kn is the n-th order cumulant of Xj ・Using (15 ) and well-known mathematical 閃lation betwe巴n cumulant and mo ment, the power-spec汀aトdomain kurtosis of DS can be ex press芯d by kurtos =. i. i. k8 + 38JK4 + 32JK2K6 + 288J2K K4 + 192J3K ー 2 JK + 16 J2K K4 + 32 J3K. ;. i. i. (16). for this derivation, s田[8 ]. Considering an actual acoustic sig nal and its cumulants, we can iIIustraほth巴 relation between input and output kurtosis via DS as Fig. 3. This relation can be approximated as kurtos. �. � 80. ,-. rl ・(kurtin -6 ) + 6 ,. (1 7). where kurtin is the kurtosis of the input signal power spe氾ー tra. As we can see in Fig目 3, the output kurtosis d巴creases 111. 0. 60 2 0. t. .il. 2. 王子. 40. Ò 20 6 Fig.. DS.. 一 一 一 一ーーーー 60 80. ・ . 一 一 一 ・・ー・・ --ー『・・・・ー司 h孟孟--‘--�ヨr�-=:-:.ニ- - -ニ=ご工」二Z二一ー. 6. 40. 20. Input ku叶0515. 100. 3. Relation between input kurtosis and output kurtosis of. reverse proportion to the number of microphones.. 3.3.5. Resultant kurtosis: chSS+BF. VS.. BF+SS. 1n the previous subsections, we have discussed the resultant kurtosis of SS and DS. 1n this subsection, we formulate th巴 resuItant kurtosis of th巴 proposed chSS+BF and BF+SS. As described in Sect. 3. 3.1, it can be expected that the smaller kurtosis increment leads to the less amount of generated musト cal noise. Thus, we cοmpare the resultant kurtosis increment of both methods. 1n BF+SS, first, DS is applied to multi-channel observed signal. At this point, the resultant kurtosis in power spectral domain, kurtos , is. =. kurtos (18 ) J →. (kurtobs -6 ) + 6, where kurtobs is the kurtosis of the observed signal in power spec汀al domain. Using (11), we can derive a shape parameter of gamma distribution corresponding to kurtos as. =. α. �kurtふ+14 kurtos + 1- kuれos + 5. (19 ) 2 kurtos -2 Next, SS is applied to the DS output; using (1 3), we can obtain the resultant kurtosis of BF+SS, kurtBF+ SS, as e品質 LA _ 'A � �A ωω2 /A �'^ J ku口日科SS三寸寸。 →企-3)�1' ( 1)+一 ''ι ' " ' +司 ' + 2)(â+刃" +β仰 2 ' α(â+ 1)[ J. 玲. (20). 1n the proposed chSS+BF, fìrst, SS is applied to each iJト put channel. Thus, the output kurtosis of channel-wis巴 SS, kurtchSS, can be given by,. 同月{ 町 即 日前2,_ �,_ J -,,- l/) � , +βα (â+ 功。+ 玲 (âー1) (â+司 ku口chSS とて -, +一→&一純一 ,-,,,- - ,-/ 1)['ãã ,, 2 ( + J (2 1). ず寸. where ã is a shape parameter of gamma distribution for the observed signal power spectra. Here, éを加d kurtobs satisfy (11). Finally, DS is performed and its resultant kurtosis can be written as kurtchSS+BF. = J-I・(kurtchSS -6 ) + 6,. (22 ). where kurtchSS+BF is the resultant kurtosis of the proposed chSS+BF Here, we consider the following equation to compare th巴 resultant kurtosis of chSS+BF and BF+SS. D = kurtBF+SS - ku口chSS+BF,. (2 3). ro ワム.
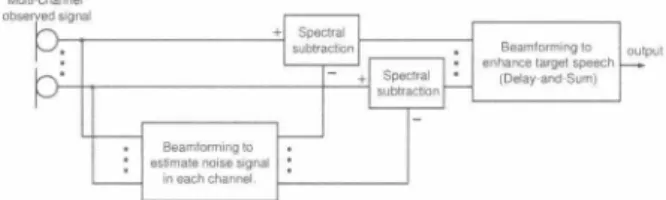
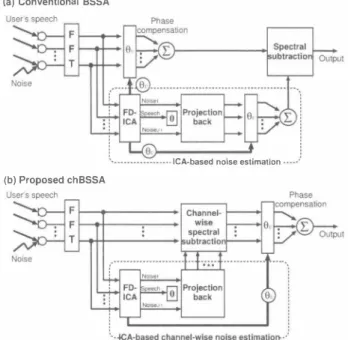
(4) ーーーーー. Mic. Mics. Mics. (a) Conventional BSSA. --- - - 816Mics Mics. O. \. U Z 的 凶 + 由 比 国 C 国司 比 + 的 目 亡 。 ω ミFH @ 且 @ U C @ 』 @ E 百 ω 一的 。 亡 コ uA C 6 H 一 コ 曲 。 匡. 1 2 4. 0. 寸. 。 Input signalls Gauss出n ;,11'. 寸. .1 0. 5. -15. 1....(9, (b) Proposed chBSSA. nu 0 之. 20. 10. 20. 30. 40. 50. 60. Input kurtosis. 70. 80. 90. ICA-based no目eestimation. 100. Fig_ 4. Resultant kurtosis differenc巴 between chSS+BF and BF+SS.. where D expresses the difference of the output kurtosis be tw巴en chSS+BF and BF+SS. The positive D indicates that the proposed chSS+BF reduced the resultant kurtosis com par巴d with BF+SS. The r巴lation about D is depict巴d in Fig. 4. In the figure, oversubtraction parameter β is fixed to 2. From 出is figure, we can confirm that the proposed chSS+BF can r巴duce the resultant kurtosis rather than BF+SS for almost all the i叩ut signals with various kurtosis. When input kurtosis is smaller than 4, the proposed chSS+BF cannot reduce the resultant kurtosis rather than BF+SS. However, such an input kurtosis corresponds to sub-Gaussian signal. 1n a common acoustical environment, such a sub-Gaussian signal cannot be expected to exist. Therefore, the proposed chSS+BF can be considered to r巴duce the resultant kurtosis rather than BF+SS in acoustic signals.. 4. APPLlCATION TO LOW-MUSICAL-NOISE BLlND SPEECH EXTRACTION. 4.1. BSSA and chBSSA Based on the discussion described in the previous section, we propose a new less-musical-noise structure for blind speech extraction method, referred to as chBSSA. Conventional BSSA has been proposed in our previous study, which consists of ICA-based noise巴stimation and the following noise reduction processing based on SS. Figur巴 5(a ) shows the configuration of BSSA. The 1CA-based noise esti mator provides a robust target-speech cancellation, and post SS proc巴ssmg can e伍ciently reduce the noise components However, this method has an inherent drawbac k conceming musical noise generation, just li k巴 the same case of BF+SS. To cope with the musical noise probl巴m in BSSA, in this paper, we propos巴 chBSSA for achieving high-quality speech 巴nhancement. The proposed method consists of three parts, namely, the 1CA-based noise estimator for a robust target cancellation, channel-wise spectral subtraction, and post-beamforming to sum up the chann巴l-wise outputs (see Fig. 5(b ) ); this guarantees less musical noise property similar to the th巴ory of chSS+BF. 1n the following sections, we give. Fig. 5. Configurations of conventional BSSA佃d proposed chBSSA. a performance comparison of th巴 conventional BSSA and the proposed chBSSA目. 4.2. Objective evaluation First, we compared the conventional BSSA and the proposed chBSSA in kurtosis di仔erence and noise r巴duction p巴rfor man田. We used the following 1 6出z sampled signals as test data; the target sp巴ech is the original speech convoluted with the impulse responses which were recorded in a room with 200 ms reverberation, and to which組制ificially generated spatially uncorrelated white Gaussian was add巴d. Besides, we use 6 spea kers (6 sentences ) as sources of the original source. The number of microphone elements in th巴 simula tion is chang巴d from 2 to 1 6. The subtraction coefficient in the SS part, β, is set to 2.0, 組d the flooring par創neter for BSSA, γ, is set to 0.0, 0.1, 0.2, 0. 4 and 0.8. Note that flooring is not performed in chBSSA. Here, we utilize th巴 kurtosis difference as the measure for the amount of generated musical noise. This is given by Kurtosis difference = kut1(nproc(f, T)) - ku口(norgげ, T)), (24). where I1proc( f, T) is the power spectrum of the residual noise signal after processing, and l1org(f, T) is the power spectrum of the noise signal before processing. This kurtosis di仔erence indicates how kurtosis is inc問ased with processing. Thus, it is d巴sired that the kurtosis di仔巴rence becom巴s smaller. More over noise reduction performance is measured based on the power of the residual noise; this is given by. IL= r.T Inproc(f, T)I2 ì. 叶 ふ |んμ T ) 12 J. Pow吋residual no 叫B ]= 川o. (25 ). nhu つ白.
(5) ー-. --- BSSA (flooring�0.2) Proposed chBSSA BSSA (flooring�O.O) 一一BSSA (flooring�O.4) - - - BSSA (flooring�0.1)…… BSSA (flooring�0.8). 4. 6. 8. 韮-25 10 12 14 16 Õ. The number 01 microphones. 1一、 、、- _. ι. ‘ー. 2 4 6 8 10 12 14 The number 01 microphones. 口. 町SA. H. 95 % confidential interval. Hτ. 0 2. . 日ド ー,.....t. 2. 2. ー ち 20. c時制. 0 4. \ - - - - - ーーーー ・ーーーーーーー- - 1... .-0 , ・~ ニー10 、;ぷ、、、 雪 一、、主、、 、ー 豆、‘三ー 一之、-._ 15 ‘ -‘司、 -. (b). 囚. 0 6. :;'" "民. |. 0 8. ・r. lD 0. { JF] 28問。U E E22t. へー…………γaf�. 100. 16. Fig. 6. Results of (a) kurtosis difference, and (b) power of. residual noise,with various ftooring parameters in BSSA and chBSSA. Figure 6 shows the simulation results. From Fig. 6 (a),we can see that the kurtosis di仔erence of chBSSA is monotoni cally decreasing with increasing the number of microphones On the other hand,the kurtosis difference of BSSA is constant r巴gardl巴ss of the number of microphones. Indeed BSSA with the specifìc ftooring paramet巴r can achieve the same kurtosis diff,巴rence as chBSSA, e.g.,出e case of flooring parameter of 0.4 in 10 microphon巴s. However, BSSA with the large ftoor ing parameter degrades th巴 nOls巴 reduction performance itself (see Fig. 6 (b)). On the other hand, the proposed chBSSA can reduce the kurtosis di仔'erence,i.e., musical noise generation, without degradation of noise reduction performance.. White Gaussian. Station noise from 3610udspeakers. Speech from 36 loudspeakers. Fig.7. Subjective evaluation results.. perimental subjective evaluation. These analytic and exper卜 mental results imply great potential of higher-order-statistics based optimization for musical noise [9]. 6. REFERENCES. [1] C. Ma打0,et a1.,“Analysis of noise reduction and dere verberation techniques based on microphone a汀ay with postfìlt巴ring," IEEE Trans. Speech and Audio Process., vol.6,pp. 240-259, 1998目. [2] Y. Ta kahashi, 巴t al., “Blind spatial subtraction array for speech enhancement in noisy environment, " IEEE Trans. Audio, Speech and Lang. Process., vol.l 7, no.4, pp. 650- 664,2009. '‘ [3] Y. Ohashi,et a1., Noise robust speech recognition based on spatial subtraction array, " Proc. ofNSIP, pp.324-327, 2005.. 4.3. Subjective evaluation Next, w巴 conducted a su切ective eva1uation to confìrm that the proposed chBSSA can mitigate the musical noise. In the eval uatlOn, we gave two proc巴ssed signals by the proposed chB SSA and conventional BSSA respectively to examinees with random order, and let 7 examinees (7 mal巴s) forcedly select which signal is less amount of musical noise. In this exper im巴nt, 3 types of noises, i.e., (a) artificial spatia11y unco町。 lated white Gaussian, (b) real-recorded railway-station noise emitted from 36 loudspea kers, and (c) real-recorded human speech 巴mitted from 3 6 loudspea kers, were used. 10 pairs of signal per one kind of noise, totally 30 pairs of processed signal were displayed to each examinee. Figure 7 shows the subjective evaluation results, and we can confìrm that the output of the proposed chBSSA is prefe町ed by more than 90% examin巴es compared with that of BSSA even for the real acoustic noises including non Gaussianity and inter-channel correlation properties.. [4] Y. Uemura, et a1.,“Automatic optimization scheme of spectral subtraction based on musical noise assessment via higher-order statistics," Proc. of IWAENC 2008, 2008.. [5] S. F. BolI, “Suppression of acoustic noise in speech using spectral subtraction," IEEE Trans. Acoustics, Speech, Signal Proc., voI.ASSP-27, no.2, pp.113-120, 1979. [ 6] H. Saruwatari, et al., “Blind source separation com bining independent component analysis and beamform ing," EURASIP J. Applied Signal Proc., vo1. 2003,no.l l , pp.1135-1146,2003.. [7] 1. W. Shin,巴t al.,“Statistical modeling of speech signal based on generalized gamma distribution," IEEE Signal Processing Letters, vol.l2, nO.3, pp.258-261, 2005. 5. CONCLUSION. [8] Y. Takahashi, et al., '‘Musicalnoise analysis in methods of integrating microphone array and spectral subtraction based on higher-order statistics," EU凡4SlP J. Adναces in Signal Proc., vo1.2010, Article ID 431347, 25 pages, 20 10. (doi: 10. 1 155/2010/43 1347). In this pap巴r, first, w巴ana1yzed musical noise generation in two mt巴grated methods of microphone a汀ay signal process ing and SS,i.e.,chSS+BF and BF+SS,based on higher-order statistics. We revealed that the proposed chSS+BF can reduc巴 the kurtosis compared with BF+SS. Next,based on the above m巴ntioned analysis, we proposed a new less-musical-nois巴 structure for a combination method of ICA-based noise esti mator and channel-wis巴 nonlinear signal processing. Finally, the superiority of the proposed method was assessed in the ex-. [9] H. Saruwatari, et al., “Musical noise controllable algo rithm of channelwis巴 sp巴ctral subtraction and adaptive beamforming based on higher-ord巴r statistics," IEEE Trans. Audio, Speech and Lang. Process., 2011 (in print ing). 弓i qL.
(6)
図

関連したドキュメント
In order to estimate the noise spectrum quickly and accurately, a detection method for a speech-absent frame and a speech-present frame by using a voice activity detector (VAD)
Bae, “Blind grasp and manipulation of a rigid object by a pair of robot fingers with soft tips,” in Proceedings of the IEEE International Conference on Robotics and Automation
T. In this paper we consider one-dimensional two-phase Stefan problems for a class of parabolic equations with nonlinear heat source terms and with nonlinear flux conditions on the
In order to prove Theorem 1.10 it is sufficient to construct a noise, extending the white noise, such that for every λ ∈ R \ { 0 } the extension obtained by the drift λ is
In this paper, we extend the results of [14, 20] to general minimization-based noise level- free parameter choice rules and general spectral filter-based regularization operators..
At the same time, a new multiplicative noise removal algorithm based on fourth-order PDE model is proposed for the restoration of noisy image.. To apply the proposed model for
The procedure consists of applying the stochastic averaging method for weakly controlled strongly nonlinear systems under combined harmonic and wide-band noise excitations,
Based on this, we propose our opinion like this; using Dt to represent the small scaling of traffic on a point-by-point basis and EHt to characterize the large scaling of traffic in
