形式文法を用いたデータ圧縮の効率化に関する研究
著者
北村 紀之
学位授与機関
Tohoku University
形式文法を用いたデータ圧縮の効率化に
関する研究
東北大学 大学院情報科学研究科
システム情報科学専攻 篠原研究室
博士課程前期二年の課程
北村 紀之
2016
年
2
月
15
日
i
目次
第 1 章 序論 1 1.1 研究の背景と目的 . . . . 1 1.2 先行研究 . . . . 2 1.3 本論文の構成 . . . . 4 第 2 章 文法圧縮 5 2.1 構文解析 . . . . 5 2.2 レンジコーダ . . . . 7 第 3 章 有限文脈モデルを用いた圧縮 12 3.1 PPM . . . . 12 第 4 章 実験 18 4.1 実験環境 . . . . 18 4.2 実験 1:枝分かれを持たない文法の圧縮 . . . . 19 4.2.1 実験準備 . . . . 19 4.2.2 実験結果 . . . . 20 4.3 実験 2:四則演算を定義した文法の圧縮 . . . . 21 4.3.1 実験準備 . . . . 22 4.3.2 実験結果 . . . . 23 4.4 実験 3:ノイズを付加したテキストの文法圧縮 . . . . 24 4.4.1 実験準備 . . . . 29 4.4.2 実験結果 . . . . 29 4.5 実験 4:品詞系列の文脈依存性の確認 . . . . 30 4.5.1 実験準備 . . . . 304.5.2 実験結果 . . . . 31
第 5 章 まとめ 33
5.1 まとめ . . . . 33 5.2 今後の課題 . . . . 33
1
第
1
章
序論
1.1
研究の背景と目的
情報科学はトレンドの移り変わりが激しい.マルチメディアやユビキタス社会などが もてはやされた時代は過ぎ,現代はビッグデータの時代と呼ばれている.カメラ,マイク などのセンサの発達により,いたるところでデータを採取することができるようになっ ている. 動画や音声はもちろん,購入情報など様々な現象がデジタルのデータとなり,莫 大な量が集約されているのである.しかしながら,ビッグデータは収集に限った話では ない.日々を振り返ってみると,スマートデバイスの普及により,豊かな情報を容易に 手に入れ,我々は豊かな生活を送っている.その中で,限りある情報インフラの中で爆 発的に増大するビッグデータを活用するためには,ある種の工夫が必要となる.使わな いデータはコンパクトに保存し,利用時のみ展開する,すなわち圧縮技術の活用が不可 欠となる.以上のことから,データの圧縮技術の必要性は明らかである. 本研究は,実データの圧縮率向上を目標として研究を行った.圧縮には 2 種類存在し, 元の情報から欠損無しで圧縮を行う可逆圧縮と,データの切り捨てを伴う非可逆圧縮で ある.本論文では,可逆圧縮をターゲットとし,Prediction by Partial Matching(PPM) に注目する.PPM は事前の系列から入力の出現確率を予測し符号化するアルゴリズムで あり,実データに対して非常によい圧縮率を示す.本研究では文脈依存性を持つ系列と 持たない系列を入力とした時の圧縮率を比較し,文脈を利用する効果を検証する.続い て,ノイズに対してロバストな構文解析アルゴリズムと PPM を組み合わせ,ノイズを含 むデータに対しても文法圧縮が有効であることを確認する.また,自然言語実データにおける品詞系列に文脈依存性が存在するか検証を行った.
1.2
先行研究
数ある圧縮手法の中のでも,文法圧縮は近年バイオインフォマティクス [20] や自然言語 処理 [17] など,多くの分野で注目されている.文法圧縮では,与えられた文字列を一意に導 出する文脈自由文法を作る.文脈自由文法は句構造文法の 1 つであり,(Γ, Σ, P, S) の 4 つ 組で定義れる.ここで,Γ ={a1, a2,· · · , a|Γ|} は非終端記号の集合,Σ = {α1, α2,· · · , α|Σ|} は終端記号の集合,S は開始記号,そして P は Γ から (Γ∪ Σ)∗への関係であり, 生成規 則の集合である.また,Γ と Σ は互いに素な集合である. 例えば,文字列 aabbabab の文脈自由文法を考えると,4 つ組 (Γ, Σ, P, S) は以下のよう になる. Γ = {A, B, C, D, E, F } Σ = {a, b} P = A→ aa B → bb C → ab D→ AB E → CC F → DE 開始記号 は F とする 開始記号 F から文字列を導出する流れを表すと,下記の通りである.3 F ⇒ DE ⇒ ABE ⇒ aaBE ⇒ aabbE ⇒ aabbCC ⇒ aabbabC ⇒ aabbabab 生成規則数が少ないほど圧縮率は高くなるが,生成規則数を最小にする問題は NP 困難 であることが証明されている [10].文法圧縮を適用し,データの圧縮を図る研究は数多く 存在する.Cameron[2] は,ソースコードに文法圧縮を適用した.プログラミング言語の 1 つである Pascal に沿った文法規則を定義し,構文解析の結果を算術符号を用いて圧縮 を行った.その結果,元のサイズから 90%近い圧縮率を達成している.また,Tarhio[15] は,符号化時に算術符号ではなく PPM を用いて文法圧縮の実験を行っている.構文木の 根から葉までを辿る過程を文脈として利用し,PPM を適用した.その結果,gzip や bzip2 に勝る圧縮率を達成している. 先行研究で圧縮の対象としているのは,プログラムのソースコードである.プログラ ミング言語には厳密な文法が存在しているため,文法圧縮の対象としては比較的簡単な 部類と言える.一方自然言語においては,文法は存在するものの例外も多く,文法圧縮 を適用することは難しい.しかしながら,急増する自然言語データに沿った規則を利用 することで,よりコンパクトに圧縮することが望ましいと考える.そこで,本論文では 大規模自然言語データに対して文法圧縮を適用し,従来の圧縮手法よりも高い圧縮率を 達成することを目標とする.
1.3
本論文の構成
本論文の構成は次のとおりである.第 2 章にて,先に触れた文法圧縮について詳しく 説明する.第 3 章にて,実験で用いる PPM について説明する.第 4 章にて,実装した PPM による圧縮結果を比較する.最後に,第 5 章で,本論文のまとめと今後の課題を述 べる.
5
第
2
章
文法圧縮
文法圧縮とは,入力データに繰り返し出現する共通部分を利用し,生成規則として集 約することで,データのサイズを縮小させる手法である.文法圧縮は 2 つのステップで 行われる.1 つは構文解析であり,もう 1 つが符号化である.本章では個々について詳細 を述べる.2.1
構文解析
構文解析とは,入力データに対して,それが生成される生成規則を導出することであ る.解析結果は枝分かれを持つ木構造として表され,構文木と呼ばれる. ここでは,Cameron[2] が用いた例である四則演算を取り上げ,構文解析について説明 する.Cameron の定義した四則演算の生成規則は以下の通りである.⟨expression⟩ → ⟨expression⟩ + ⟨term⟩ | ⟨expression⟩ − ⟨term⟩ | ⟨term⟩ ⟨term⟩ → ⟨term⟩ ∗ ⟨factor⟩ | ⟨term⟩/⟨factor⟩ | ⟨factor⟩
⟨factor⟩ → (⟨expression⟩) | ⟨variable⟩ ⟨variable⟩ → A | B | C | D
非終端記号は式⟨expression⟩,項 ⟨term⟩,因子 ⟨factor⟩,変数 ⟨variable⟩ の 4 つであ り,⟨expression⟩ が開始記号である.また終端記号は {A, B, C, D, +, −, ∗, /, (, )} の 10 種 類である.以上の文法を元に,算術式の構文解析を試みる.
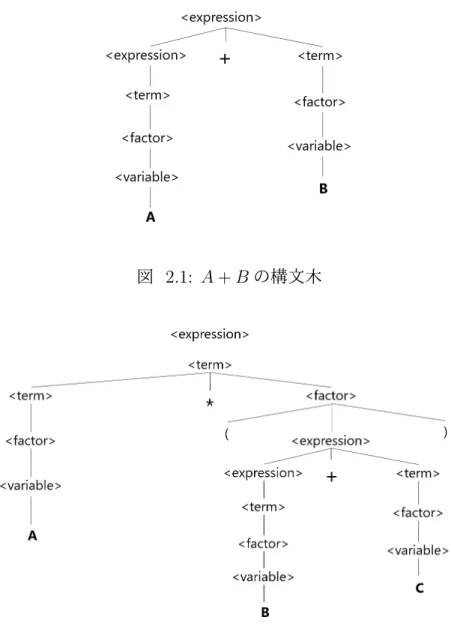
図 2.1: A + B の構文木
図 2.2: A∗ (B + C) の構文木
初めに,単純な例として A + B を考える.開始記号は⟨expression⟩ であるから,その
中から適用できる規則を探すと,第 1 規則⟨expression⟩ → ⟨expression⟩ + ⟨term⟩ が選
ばれる.以降は枝分かれすることなくそれぞれ終端記号 A, B が導出される.構文解析の 結果である構文木を図 2.1 に示す. 続いて,先の例より多少複雑な式として A∗ (B + C) の構文解析を考える.この場合, 括弧は 1 つの因子として見なされるため,開始記号⟨expression⟩ の中からは第 3 規則 ⟨expression⟩ → ⟨term⟩ が選ばれる.以降の流れを構文木として図 2.2 に示す. 以上のように構文解析を行うことで,入力データを復元するために必要な生成規則を 知ることができる.しかし,構文解析しただけではまだ符号化はできない.ここからは,
7 図 2.3: A∗ (B + C) の番号つき構文木 先の式 A∗ (B + C) を用いて,構文解析の結果をいかに利用していくかについて述べる. 初めに準備としてそれぞれの生成規則に順に番号をつける.番号をつけた構文木が図 2.3 である.その構文木を行きがけ順 (pre-order) でなぞり,規則を列挙する.ここから得ら れる番号列は,{31321113322323} となる.この番号列をエントロピー符号で符号化する. 次節では,番号列を符号化する方法について述べる.
2.2
レンジコーダ
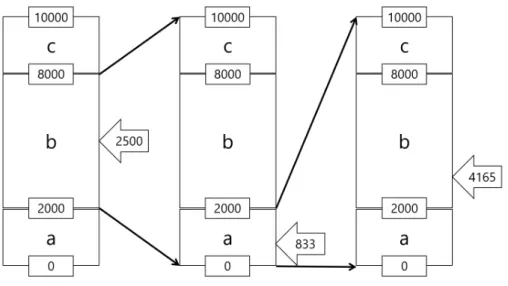
文法圧縮では,構文解析の結果から得られた番号列に対して,符号化を行う.本論文 では符号化にエントロピー符号を用いる.エントロピー符号とは,各記号の出現確率を 利用する手法であり,頻繁に現れる記号には短い符号を,出現頻度の低い記号には長い 符号を与える不等長符号化方法である [21]. エントロピー符号の種類には,ハフマン符号 [5] や算術符号 [8][12][13] などがあり,符 号語の決め方が異なる.ハフマン符号では 1 記号が 1 ビット未満になることはないが,算 術符号では出現確率によっては 1 記号が 1 ビット未満に圧縮できる場合もある.そういっ た点から,算術符号に分がある一方で,特許の問題から算術符号の技術を自由に使うこ とはできなかった.ところが,1979 年に Martin[6] が発表したレンジコーダは,算術符 号から派生したものであるにも関わらず,特許に触れることなく利用ができ,算術符号Algorithm 1 Rangecodere(s) Input: s:文字列 Output: low:区間の下端 1: 区間を初期化 2: 対象言語に含まれる全記号の出現回数を 1 に初期化 3: i← 0 4: repeat 5: 各記号の出現確率に従って区間を分割 6: 記号 s[i] の区間を選択 7: s[i] の出現回数を 1 増やす 8: if 区間幅 < 区間幅の下限 then 9: 区間を拡大 10: end if 11: i← i + 1 12: until i =|s| 13: 区間の下端を出力 と同等の働きが可能である.本論文では,エントロピー符号化にレンジコーダを用いる. レンジコーダは,ある区間 I を考え,その区間を出現確率で分割していくことによっ て,入力を符号化する. 例として,アルファベット{a,b,c} がそれぞれ {0.2,0.6,0.2} の確率で出現すると仮定 する.区間の初期状態を I[0,10000) とすると,a の区間 Ia が [0,2000),b の区間 Ib は [2000,8000),c の区間 Icは [8000,10000) となる. 例えば b が入力され,区間 Ib が選ばれたとすると,さらにその区間を分割して次の 文字を符号化していく.すなわち,新たな a の区間 Ia′ は [2000,3200),Ib′ が [3200,6800), Ic′[6800,8000) である.b に続いて c が入力されたとしたら,選ばれる区間は Ic′となる.最 終的な符号語は,区間の下端の値となる.以上の流れを図 2.4 に示す. 続いて復号を考える. 先ほどのアルファベットからなるとある文字列を符号化した結果,符号語 2500 が得ら
9 図 2.4: 区間分割(符号化) れたとする.ここでは,符号語がどの区間に含まれるかを調べることで,復号を進めて いく.その様子を図 2.5 に示す. 符号語 2500 は,Ibの間に存在するため,1 文字は b が復号される.続けて復号する時 には,Ibが [0,10000) になるように下式で符号語を拡大する. 新しい符号語 = 区間長の初期値∗ (符号語 − 区間の下限値)/記号の区間幅 式にそれぞれ数値を当てはめると,10000∗ (2500 − 2000)/6000 ∽ 833 となり,新しい 符号語として 833 を得る.区間 I から探すとこれは Iaに含まれるため,a が復号される. また同様に区間を拡張することで,3 つ目の符号語として 10000∗ (833 − 0)/2000 = 4165 を得る.これが含まれる区間を探すと,Ibが該当し,b を得る. 復号の流れは以上の通りである.しかし,ここで問題が 2 つ存在する.それは,記号列 の最後を判定できないことである.すなわち,このままでは無限に記号が復号され続け てしまう.そこで,終わりを表す記号を用意して,その記号を復号したら終了する,ま たは記号の総数をファイルの先頭に書き込んでおく,などの方法で解決することができ る.もう 1 つの問題は,符号化時に区間を分割していった結果 [123,124) といったこれ以 上分割できない状態となった場合の対処である.レンジコーダは整数を対象としている ため,区間が整数で分割できなくなると動作ができなくなる.そこで,区間を例えば 100
Algorithm 2 Rangecoderd(c, n) Input: c:区間の下端,n:復号する記号数 Output: s:記号列 1: 区間を初期化 2: 対象言語に含まれる全記号の出現回数を 1 に初期化 3: i← 0 4: repeat 5: 各記号の出現確率に従って区間を分割 6: c が含まれる区間に該当する記号を出力 7: 出力された記号の出現回数を 1 増やす 8: 区間を拡大 9: i← i + 1 10: until i = n 倍とすることで,区間が [12300,12400) となり,再び分割が可能となる.
11
第
3
章
有限文脈モデルを用いた圧縮
この章では,有限文脈モデルを用いた圧縮手法の 1 つである Prediction by Partial Matching(PPM) について述べる.3.1
PPM
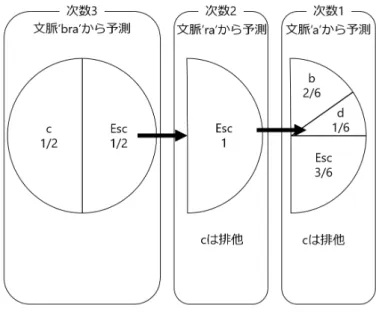
PPM は,1984 年に Cleary と Witten[4] によって発表された.PPM は,確率・統計的テ キスト圧縮手法であり,過去に出現した文字から出現確率の推定を行い,得られる各記 号の生成確率を用いてレンジコーダなどによるエントロピー符号化を行う.PPM を扱っ た研究は多数報告されており,PPM を発展させ無限長の文脈から予測を行うもの [3] や, 自然言語処理 [16][18][19] に応用された例も存在する. PPM による文字の生起確率計算について述べる.文字予測の際に直前の k 文字を用い るモデルを次数 k の有限文脈モデルと呼ぶ.PPM では,長さ k の部分文字列に後続する 文字の出現回数集合 c,および出現回数に基づく予測確率集合 p を得る.単純に次数 k を 伸ばしたとしても性能がよくなるというわけではない.実際,テキスト圧縮分野では,k を 5 程度とした場合が最も PPM モデルの性能がよいと報告されている [1][11]. 以下から,文字列 abracadabra から獲得した確率値を用いて文字列 bra に後続する文 字の確率を k = 3 から推定することを考える.この状況で,予測することのできる各文 脈を表 3.1 に示す.ここで,A は対象言語の文字全てを含む文字集合である. 選択された次数の文脈が次の文字を予測できる場合,文字の生起確率として予測確率 p を用いる.もし,予測できない未観測文字であった場合,その文脈におけるエスケープ13 表 3.1: 予測に用いることのできる文脈と各々の確率値 予測 c p 予測 c p 次数 k = 3 次数 k = 0 bra → c 1 1/2 → a 5 5/16 → Esc 1 1/2 → b 2 2/16 → c 1 1/16 次数 k = 2 → d 1 1/16 ra → c 1 1/2 → r 2 2/16 → Esc 1 1/2 → Esc 5 5/16 次数 k = 1 次数 k =−1 a → b 2 2/7 → A 1 1/|A| → c 1 1/7 → d 1 1/7 → Esc 3 3/7 確率(表中の Esc)を用いて,予測に用いる文脈を 1 つ次数の低い文脈に変更する.これ を遷移と呼ぶ.ここで,エスケープ確率とは,各字数の文脈において観測されていない 文字に対して割り当てられる確率であり,1 つ次数の低いモデルへ遷移する確率となる. 次の文字を予測できる文脈となるまで文脈長を順次短くし,予測可能な文脈での確率分 布に基づいて文字の生起確率を求める. しかしこれでは,入力中に初めて現れた文字を処理することができない.そこで,どの ような文字の生起確率を求める場合にも必ず処理が終了するように,対象言語の文字集 合 A 中の全ての文字を等確率 1/|A| で予測する最低次 k = −1 のモデルを用意しておく. 以上の処理によって,PPM では各次数の確率分布を組み合わせて,後続する文字の生 起確率を推定する.したがって,PPM の性能は,各字数の確率分布の混合方法,すなわ ちエスケープ確率の決定方法に依存する.エスケープ確率の推定法としては,いくつか の方法が提案されている.本研究では,その中の方法 C(Method C)と呼ばれる手法を
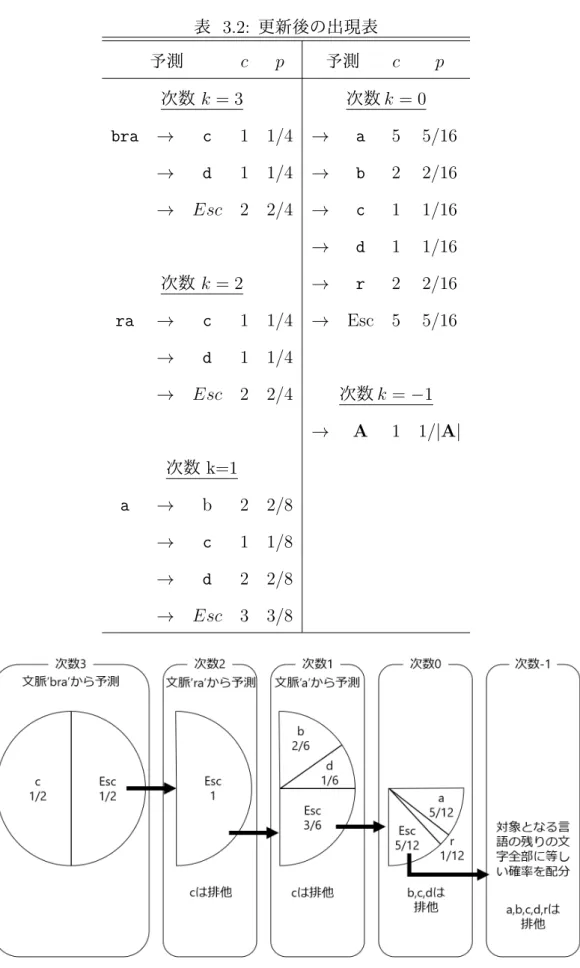
用いた.エスケープ確率 pEscの計算方法は下式の通りである.n がその文脈長で出現し た記号の総数であり,u がそのモデルで出現したエスケープ確率の総数である.文字の出 現回数 c は,エスケープ確率を 1, それ以外の文字は 0 に初期化しておく. M ethodC : pEsc = u n + u それではこれより,文字列’bra’ に続いて文字’d’ が出現する確率を推定する.まず,次 数 k = 3 の文脈’bra’ であるが,ここからは’d’ を予測できないため,1 つ低い次数 k = 2 へ遷移する.この際,エスケープ確率 1/2 が選ばれる.次数 k = 2 の文脈’ra’ において も,’d’ を予測できないため,さらに次数を 1 つ低くする.再び遷移が発生したため,k = 2 におけるエスケープ確率 1/2 が選ばれる.次数 k = 1 の文脈’a’ からは,’d’ を確率 1/7 で 予測できるため,生起確率は今までの確率の積をとると,1/2∗ 1/2 ∗ 1/7 = 1/28 となる. しかしながら,今求めた文字’d’ の生起確率は実は正確なものではない.というのも, PPM には排他(exclusion)と呼ばれる処理があり,遷移の際に予測確率に工夫を加える ことにより,大きい確率を割り振ることができるようになっているのである.表 3.1 の例 を見ると,k = 2, 1 にはそれぞれ文字’c’ に確率が割り当てられているが,もし k = 3 で’c’ が選ばれなかった場合,k = 2, 1 で’c’ が選ばれることはない.そのため,文脈’ra’,’a’ に おける文字’c’ の出現回数を 0 とすることで,k = 2 でのエスケープ確率が 1,k = 1 での 予測確率が 1/6 となり,’d’ の生起確率は 1/2∗ 1 ∗ 1/6 = 1/12 となる.以上のような排他 の処理により,より高い確率を割り当てることに成功している.区間を分割していく様 子を図 3.1 に示す. ここで,文脈’a’ において’d’ を符号化したため,文脈’bra’ における出現表は表 3.2 のよ うに更新される.この時,1 次の文脈で符号化したので,1 次未満の出現表は更新されな い.これを update exclusion と呼ぶ.これにより,低次の出現表の確率を高く保つこと が可能となる. また,別な例を考える.文脈中に登場していない文字’t’ が文字列’bra’ に続いて出現す る確率を推定する場合には,次数 k = 3 から k = −1 まで遷移が繰り返される.k = −1 では,高次ですでに現れた文字の確率を排他し,対象言語で現れる全ての文字を等確率 で予測する.すなわち,文字’t’ は最低次 k =−1 において確率 1/(|A| − 5) で予測される
15
図 3.1: PPM の確率分割 1 (図 3.2 参照).
得られた確率をレンジコーダに与え,エントロピー符号化を行う.復号の際には,初 期化された PPM モデルを用いてレンジコーダを利用し 1 文字ずつ復号を行う.
表 3.2: 更新後の出現表 予測 c p 予測 c p 次数 k = 3 次数 k = 0 bra → c 1 1/4 → a 5 5/16 → d 1 1/4 → b 2 2/16 → Esc 2 2/4 → c 1 1/16 → d 1 1/16 次数 k = 2 → r 2 2/16 ra → c 1 1/4 → Esc 5 5/16 → d 1 1/4 → Esc 2 2/4 次数 k =−1 → A 1 1/|A| 次数 k=1 a → b 2 2/8 → c 1 1/8 → d 2 2/8 → Esc 3 3/8 図 3.2: PPM の確率分割 2
17 Algorithm 3 P P M (s) Input: s:記号列 Output: low:区間の下端 1: 区間を初期化 2: i← 0 3: repeat 4: k を予測に用いる最大文脈長にセット 5: while s[i] に該当する区間を出力する do 6: 長さ k の文脈における出現頻度表を作成 7: 区間を分割 8: if s[i] を予測できる then 9: s[i] に該当する区間を出力 10: elses[i] を予測できない 11: エスケープ区間を出力 12: k← k − 1 13: end if 14: if 区間幅 < 区間幅の下限 then 15: 区間を拡大 16: end if 17: end while 18: i← i + 1 19: until i =|s|
第
4
章
実験
文法圧縮法を適用した場合の圧縮率が他の手法より勝っていることを確認するため,実 験を行った.構文木が枝分かれを持たないものと枝分かれを持つ文法を用意し,これら 2 つの文法に従って生成したテキストに対して圧縮を行い,構文解析および文脈を利用し た圧縮の効果を示す. また,実データを想定し,ノイズを含むテキストに対しての文法圧縮の有効性を確認 した.入力として,文法に含まれないような記号を含む文字列に対しても圧縮が可能な アルゴリズムを考案し,PPM と圧縮率を比較した. 最後に,自然言語への文法圧縮の適用には,規則間での依存関係に注目が集まる.そ こで,自然言語データから得た品詞系列に対して圧縮を行い,文脈依存性の有無を確認 した.4.1
実験環境
実験に使用した計算機の性能は以下の通りである. • CPU:Intel c⃝CoreTMi7 2.80GHz • OS:Windows 10 Pro • メモリ:8GB 圧縮アルゴリズムは Python2.7.10 を用いて実装した.なお,アルゴリズムの実装に当 たり,広井誠氏の web ページ [7] を参考にした.19
4.2
実験
1
:枝分かれを持たない文法の圧縮
独自に定義した文法 G1 を下に示す.開始記号は A であり,生成されるテキストは,
a,b,c,d,e の系列となる.
G1 = ({A, B, C, D}, {a, b, c, d, e}, P1, A)
P1 = A→ aA|aB|aC B → bB|bC|bA C→ cC|cB|cD D→ dD|dA|de この文法より生成される例として,’abcde’ や,’aabbabcde’ などがある.この文法を 用いてテキストを生成し,圧縮率の違いを比較する. 4.2.1 実験準備
それぞれの生成規則を A1, A2, A3, B1,· · · , D3 のように表すとすると,それぞれの生
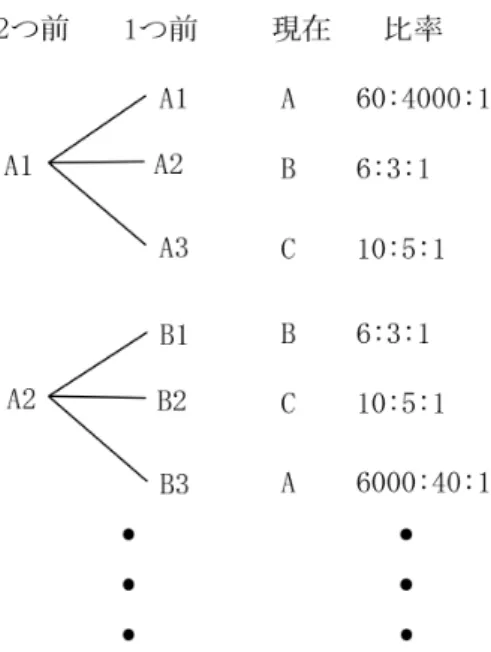
起比率を以下のように定義した. A1 : A2 : A3 = 60 : 40 : 1 B1 : B2 : B3 = 6 : 3 : 1 C1 : C2 : C3 = 10 : 5 : 1 D1 : D2 : D3 = 50 : 50 : 1 上記とは異なる生成比率に従い, もう 1 種類テキストを用意する. と言うのも,文法に 従って生成される実データにおいては, 頻出する規則群が存在すると予測される. そこで, 適用する規則を文脈に依存させたテキストを生成した.図 4.1 のように,過去 2 つ前まで の規則を参照し動的に確率を変更させた. 以上の 2 つのルールに従い,適用する規則が 3000 以上 4000 未満になるように記号列 を 10 種類作成し,圧縮率を比較した.
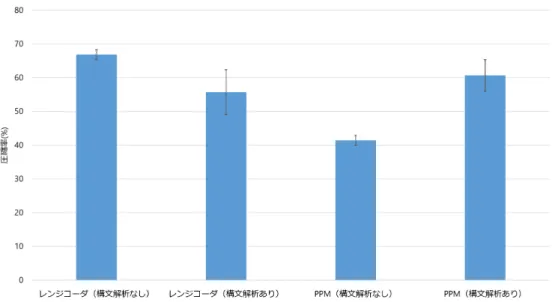
図 4.1: 文脈に依存する生成確率 圧縮するアルゴリズムはレンジコーダと PPM の 2 種類である.PPM の次数は 2 とし た.レンジコーダ,PPM にテキストデータをそのまま入力する場合と,構文解析した結 果を入力する場合の 2 通りをそれぞれ行った. 構文解析した結果を入力する場合について,処理の流れを説明する.例として文字 列’aabbabcde’ を圧縮する場合,まず文法に従って構文木を作成する.(図 4.2) そして各ノードで適用されている規則の番号を列挙する.各規則に対し通し番号を 1 か ら 12 まで振り分ける.例としてテキストが’aabbabcde’ であった場合,[1,2,4,6,2,5,9,12] いうリストが構文解析結果となる. また,レンジコーダに構文解析結果を与える場合には,Cameron[2] の手法に従い規則 ごとに出現回数を管理した.全ての規則を一括で扱う場合,12 区間に分割することとな るが,規則ごとに出現確率を管理することで分割は 3 区間となり,単純に考えて 4 倍の 長さの区間をそれぞれの規則に割り当てることができる.これにより,より短い符号語 を与えることが可能となる. 4.2.2 実験結果 4 つの圧縮手法におけるそれぞれの圧縮率の平均を図 4.3 に示す.エラーバーは標準偏 差を表している.
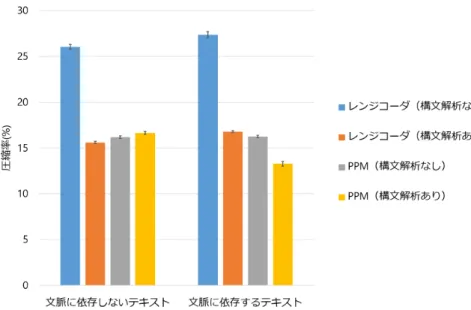
21 図 4.2: ’aabbabcde’ の構文木 両方のテキストにおいてレンジコーダ(構文解析なし)の結果が一番悪かった. 文脈に 依存しないテキストにおいてはレンジコーダ(構文解析あり)の結果が最も優れていた のに対し, 文脈に依存するテキストでは PPM(構文解析あり)の結果が最も優れていた. 生データでは圧縮率の低いレンジコーダであるが,構文解析結果を入力とすることで, 文脈依存性の有無によらず飛躍的に圧縮率が向上した.規則ごとに出現回数を管理する ことで,非常に短い符号語を与える効果はとても大きいと確認できた. 実データを模した文脈に依存するテキストにおいて PPM(構文解析あり)が優れた圧 縮率を示したことから,実データにおいても文脈を利用した文法圧縮の有効性が確認で きたと言える.
4.3
実験
2
:四則演算を定義した文法の圧縮
第 2 章にて定義した文法を使用する.生成規則を再掲する.図 4.3: 枝分かれを持たない文法の圧縮結果
⟨expression⟩ → ⟨expression⟩ + ⟨term⟩ | ⟨expression⟩ − ⟨term⟩ | ⟨term⟩ ⟨term⟩ → ⟨term⟩ ∗ ⟨factor⟩ | ⟨term⟩/⟨factor⟩ | ⟨factor⟩
⟨factor⟩ → (⟨expression⟩) | ⟨variable⟩ ⟨variable⟩ → A | B | C | D
文法から導出された数式を圧縮し,手法による圧縮率の違いを検討する.
4.3.1 実験準備
それぞれの生成規則を,⟨expression1⟩⟨expression2⟩⟨expression3⟩⟨term1⟩ · · · ⟨variable4⟩ のように表すとすると,それぞれの生起確率を以下のように定義した.
⟨expression1⟩ : ⟨expression2⟩ : ⟨expression3⟩ = 3 : 2 : 5 ⟨term1⟩ : ⟨term2⟩ : ⟨term3⟩ = 4 : 2 : 4
⟨factor1⟩ : ⟨factor2⟩ = 1 : 9 ⟨variable1⟩ : ⟨variable2⟩ : ⟨variable3⟩ : ⟨variable4⟩ = 1 : 1 : 1 : 1
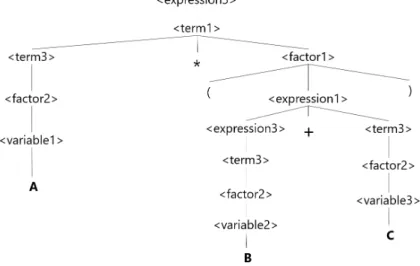
23 図 4.4: 文脈に依存する生成確率 上記の一定の確率で生成したテキストの他に,適用する規則を文脈に依存させたテキ ストを用意した.図 4.4 のように,過去 2 つの規則を参照し,動的に生成確率を変更した. 構文解析結果を用いる場合,入力は第 2 章で示したように数字列となる.枝分かれが 存在する文法においては,数字列を順次処理するのでは不適切であると考える.常に構 文木の親を文脈とする必要があるため,枝分かれ時に文脈を保存し,葉にたどり着いた 際に文脈を復元する処理を加えた.例としては,図 4.5 の⟨term1⟩ において枝分かれが発 生するが,この時文脈を保存し,⟨variable1⟩ の処理を終えた後 ⟨factor1⟩ へ移る際に文 脈を復元することで,木構造に沿った文脈を参照するようにした. 先に示した規則に沿って,適用する規則数が 300 以上 500 未満になるように数式を 10 個生成し,圧縮率を比較した.圧縮するアルゴリズムは実験 1 と同様にレンジコーダと PPM の 2 種類について, 構文解析のするかしないかの 2 通りで行った. 4.3.2 実験結果 実験 2 の結果を図 4.6 に示す.エラーバーは標準偏差である.両方のテキストにおいて レンジコーダ(構文解析なし)の結果が一番悪かった. 文脈に依存しないテキストにお いてはレンジコーダ(構文解析あり)の結果が最も優れていたのに対し, 文脈に依存する テキストでは PPM(構文解析あり)の結果が最も優れていた. 実験 1 とは異なり,枝分 かれを持つ文法においても,文脈を参照することで圧縮率を高く文法圧縮を行うことに
図 4.5: A∗ (B + C) の構文木(再掲) 成功した.
4.4
実験
3
:ノイズを付加したテキストの文法圧縮
文法圧縮を実データに適応するにあたり,文法で表現できない部分の存在は避けられ ない.そこで,先に用いた四則演算の文法で導出されたテキストに対して,ノイズを付 加したものを用意し,文法圧縮を試みる. ノイズに対応するために,圧縮の処理手順を改めた.以下に概要を示す. • ノイズ部分を切り分け,テキストを文法圧縮が可能となるよう整形する • 整形したテキストを構文解析し,PPM で圧縮する • 切り分けたノイズ部を PPM で圧縮する ノイズ部分の切り分けであるが,考えうる全てのノイズを除去できるよう,4 つのアル ゴリズムを考案した. • 文法の終端記号に含まれない記号の除去 • 空の括弧や算術記号の連なりの除去 • 右括弧と左括弧の一致25
図 4.6: 枝分かれを持つ文法の圧縮結果
• 先頭や末端に存在する算術記号の除去
Algorithm 4 文法の終端記号に含まれない記号を除去するアルゴリズム Input: s:文字列 Output: s:整形した文字列,list:除去した記号 1: for i :=|s| to 0 do 2: if s[i] が終端記号でない then 3: 記号 s[i] と位置 i を list に追加 4: s から s[i] を除去 5: end if 6: end for Algorithm 5 空の括弧や算術記号の連なりを除去するアルゴリズム Input: s:文字列 Output: s:整形した文字列,list:除去した記号 1: repeat 2: [+− ∗/(][+ − ∗/)] に一致する箇所を探索 3: if 一致箇所がある then 4: 一致箇所の内 2 つ目を削除 5: 削除した記号と記号の位置を list に追加 6: end if 7: until 一致箇所が存在しない
27 Algorithm 6 右括弧と左括弧の数を一致させるアルゴリズム Input: s:文字列 Output: s:整形した文字列,list:除去した記号 1: count← 0 2: for i :=|s| to 0 do 3: if s[i] = ”)” then 4: count を 1 つ増やす 5: end if 6: if s[i] = ”(” then 7: if count≥ 1 then 8: count を 1 つ減らす 9: else 10: s から s[i] を除去 11: list に [(, i] を追加 12: end if 13: end if 14: end for 15: if count≥ 1 then 16: count の数だけ s から ”)” を削除 17: 削除した位置を list に追加 18: end if
Algorithm 7 先頭や末尾に存在する算術記号を除去するアルゴリズム Input: s:文字列 Output: s:整形した文字列,list:除去した記号 1: repeat 2: if s の先頭が [+− ∗/] に一致 then 3: s の先頭を削除 4: 削除した記号を list に追加 5: end if 6: if s の末尾が [+− ∗/] に一致 then 7: s の末尾を削除 8: 削除した記号を list に追加 9: end if 10: until どちらも一致しない 以上のアルゴリズムによりノイズを除去することで,構文解析が可能な形に整形する. 除去したノイズは全文における位置情報と共にリスト化し,圧縮結果に添付する.しか し,このままでは A + BC のような,終端記号のみで構成されているにも関わらず文法 から外れた入力に対応できない.そこで,文法を以下のように拡張を行った, ⟨sentence⟩ → ⟨sentence⟩⟨expression⟩|⟨expression⟩
⟨expression⟩ → ⟨expression⟩ + ⟨term⟩|⟨expression⟩ − ⟨term⟩|⟨term⟩ ⟨term⟩ → ⟨term⟩ ∗ ⟨factor⟩|⟨term⟩/⟨factor⟩|⟨factor⟩
⟨factor⟩ → (⟨sentence⟩)|⟨variable⟩ ⟨variable⟩ → A|B|C|D
⟨sentence⟩ という規則を導入し,開始記号と括弧の中身を ⟨sentence⟩ に変更した.こ
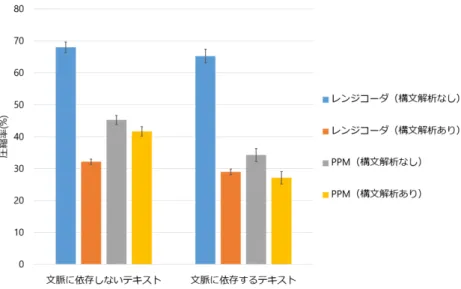
29 4.4.1 実験準備 実験 2 で用いた,文脈によって確率を変更させる手法を使いテキストを生成した.そし てテキストに対して一定の確率でノイズを付加した.全文に対して,2% の確率で A ∼ Z, a∼ z のいずれかの記号を挿入した. 10 のテキストデータにおける圧縮率を比較した.圧縮するアルゴリズムは先と同様レ ンジコーダと PPM で構文解析の有無を含む計 4 種類である. 4.4.2 実験結果 結果を図 4.7 に示す.エラーバーは標準偏差を表す.PPM(構文解析なし)が最も優 れた圧縮率を示した.文法圧縮の結果はレンジコーダ,PPM ともに振るわなかった. 理由の 1 つとして,構文解析結果の符号化とは別にノイズ情報も符号化しファイルに 保持する必要があるため,圧縮後のサイズが増大したことが考えられる.ノイズ情報の 効率的な処理を改善する必要がある. もう 1 つの理由は,文脈の依存関係が崩れたことが考えられる.文法を拡張したため, 生成時とは異なる文法で構文解析を行うことになる.それにより,生成時に頻出してい た規則の連なりが解析時に出現せず,圧縮率が向上しなかったと推察される.文脈を利 用できなければ PPM のメリットは失われるため,文法の拡張法を見直し,メリットを活 かせるよう改善が望まれる.
図 4.7: 文脈を考慮した数式の圧縮結果 図 4.8: 自然言語における構文木
4.5
実験
4
:品詞系列の文脈依存性の確認
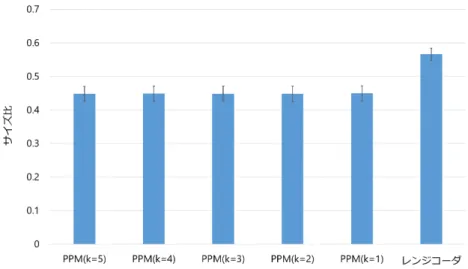
自然言語に文法圧縮を適用する場合,図 4.8 のように品詞が規則になる.文脈を利用し て文法圧縮を行うに当たっては,自然言語実データにおいて前後の品詞間で依存性があ るかどうか調べることが第一に必要である.そこで,英語· 日本語の2か国語において品 詞の文脈依存性の有無を検討した. 4.5.1 実験準備 英語の実データとして,ニューヨーク・タイムズのホームページより,閲覧数ランキ ング上位 10 個の記事を選択した.英文のテキストから品詞を得るため,形態素解析ツー31 図 4.9: 英語の品詞系列の圧縮結果 ルとして TreeTagger を利用した [14].また,日本語の場合には,NHK のホームページ より,アクセスランキング上位 10 個の記事を選択した.そして形態素解析ツールには, MeCab を用いた [9].MeCab の出力のうち,品詞情報と細分類情報を利用した. 解析結果から得られる品詞系列をレンジコーダ,PPM に入力し符号化を行う.ここで, どれだけの長さの文脈が寄与するかを見るために,PPM の最大文脈長 k は 1 から 5 とし た.圧縮結果の比較は,以下の指標を用いる. サイズ比 = 圧縮結果のファイルサイズ/品詞数 これは,テキストを構成する全単語の個数を圧縮後のファイルサイズで割ったもので ある. 4.5.2 実験結果 英語の結果を図 4.9 に,日本語の結果を図 4.10 に示す.エラーバーは標準偏差を示す. 英語· 日本語両方において,最大文脈長に関係なくレンジコーダより PPM が優れてい た.このことから,品詞の前後関係を利用して文法圧縮を行う利点はあると推測される.
33
第
5
章
まとめ
5.1
まとめ
本論文では,PPM に構文解析を導入し,圧縮率の解析を行った.2 種類の文法で実 験を行い,文脈によって発生確率を操作することで圧縮率を向上できることを示した.ま た,実データを形態素解析した品詞系列に対して圧縮を行い,日本語· 英語において品詞 が文脈に依存していることを確認した.5.2
今後の課題
今後は,実データに対する圧縮を行い検証を進めていくことが必要となる.自然言語処 理や,DNA の塩基配列に文法圧縮を適用し,有効性を示したい.自然言語などの実デー タでは,文法では記述されていない例外にも対処していくことが必要となる.そのため にも,例外処理を効率よく行うアルゴリズムの考案をが望まれる. 自然言語の前後の品詞に依存関係が見られたため,文脈を利用した文法圧縮の適用を 目指すことになる.ある言語を網羅する構文規則の構築がなされれば,文法を利用した 文脈圧縮により従来手法より高い圧縮率を達成することができるようになるだろう.参考文献
[1] Timothy C. Bell, John G. Cleary, and Ian H. Witten. Text Compression. Prentice-Hall, Inc., Upper Saddle River, NJ, USA, 1990.
[2] R.D. Cameron. Source encoding using syntactic information source models.
Infor-mation Theory, IEEE Transactions on, Vol. 34, No. 4, pp. 843–850, July 1988.
[3] John G. Cleary, W.J. Teahan, and Ian H. Witten. Unbounded length contexts for ppm. In Data Compression Conference, 1995. DCC ’95. Proceedings, pp. 52–61, Mar 1995.
[4] John G. Cleary and I.H Witten. Data compression using adaptive coding and partial string matching. Communications, IEEE Transactions on, Vol. 32, No. 4, pp. 396– 402, Apr 1984.
[5] R.G. Gallager. Variations on a theme by huffman. Information Theory, IEEE Transactions on, Vol. 24, No. 6, pp. 668–674, Nov 1978.
[6] G.N.N.Martin, editor. Range encoding: an algorithm for removing redundancy from
a digitised message. Video & Data Recording Conference, July 1979.
[7] Makoto Hiroi. Lightweight language. http:\\www.geocities.jp\m_hiroi\light\ index.html.
[8] Randford M.Neala & John G.Cleary I.H.Witten. Arithmetic coding for data com-pression. Communication of the ACM, Vol. 30, pp. 520–540, 1987.
[9] T. KUDO. Mecab : Yet another part-of-speech and morphological analyzer.
35 [10] Eric Lehman and Abhi Shelat. Approximation algorithms for grammar-based com-pression. In In Proceedings of the 13th ACM-SIAM Symposium on Discrete
Algo-rithms, pp. 205–212. ACM/SIAM, 2002.
[11] A. Moffat. Implementing the ppm data compression scheme. Communications,
IEEE Transactions on, Vol. 38, No. 11, pp. 1917–1921, Nov 1990.
[12] Richard Clark Pasco. Source Coding Algorithms for Fast Data Compression. PhD thesis, Stanford University, Stanford, CA, USA, 1976.
[13] J. Rissanen and G. G. Langdon. Arithmetic coding. IBM J. Res. Dev., Vol. 23, No. 2, pp. 149–162, March 1979.
[14] Helmut Schmid. Probabilistic part-of-speech tagging using decision trees, 1994. [15] J. Tarhio. On compression of parse trees. In String Processing and Information
Retrieval, 2001. SPIRE 2001. Proceedings.Eighth International Symposium on, pp.
205–211, Nov 2001.
[16] 卓久丸山, 久美子田中(石井), 正人武市. Ppm 法を用いたかな漢字変換の学習モデ ル. 情報処理学会研究報告自然言語処理(NL), Vol. 2001, No. 112, pp. 9–14, nov 2001.
[17] 亮洋宮木, 比呂志坂本. 頻出文字列の近似数え上げに基づく省スペース文法圧縮の改 良 (特集知識情報処理技術の最新動向および一般). 人工知能基本問題研究会, Vol. 95, pp. 33–37, oct 2014.
[18] 裕之穴瀬, 和宏芥子, 崇石田, 茂一平澤. 文脈混合を考慮した ppm アルゴリズム (フ レッシュマン, 一般). 電子情報通信学会技術研究報告. IT, 情報理論, Vol. 105, No. 191, pp. 35–40, jul 2005.
[19] 北 研二小田 裕樹. Ppm*言語モデルを用いた日本語単語分割. 情報処理学会論文誌, Vol. 41, No. 3, pp. 689–700, mar 2000.
[20] 幸司前田, 嘉将高畠, 靖生田部井. 文法圧縮を応用したハミング距離の短い文字列 列挙アルゴリズム (特集機械学習/知識発見の最新動向). 人工知能基本問題研究会, Vol. 94, pp. 21–25, jul 2014.
37