招待論文
超伝導単一磁束量子回路による
50 GHz
ビット並列演算マイクロプロ
セッサに向けた要素回路設計
田中
雅光
†a)佐藤
諒
†石田
浩貴
††畑中
湧貴
†松井
裕一
†小野
貴継
††井上
弘士
††藤巻
朗
†Design of Component Circuits for 50-GHz Bit-Parallel Microprocessors
Based on Superconductor Single-Flux-Quantum Logic
Masamitsu TANAKA
†a), Ryo SATO
†, Koki ISHIDA
††, Yuki HATANAKA
†,
Yuichi MATSUI
†, Takatsugu ONO
††, Koji INOUE
††, and Akira FUJIMAKI
†あらまし 超伝導単一磁束量子(SFQ)回路に基づく,100 GHz 級の高性能マイクロプロセッサに向けて進 めている研究について,最近の成果を報告する.超高速で低消費電力なSFQ 回路は,ポストムーア時代の次世 代大規模集積回路技術として注目されている.SFQ 回路に適したアーキテクチャ探索の結果,我々はゲートレ ベルパイプライン処理によるビット並列演算マイクロプロセッサの可能性を見い出し,超高速極低温コンピュー ティングに向けて開発に着手している.本論文では,SFQ 集積回路の高周波設計技術,並びに,ニオブ 9 層構造 の1.0 µm プロセスを用いて試作した,50 GHz ビット並列算術論理演算器などのマイクロプロセッサ要素回路 について紹介する. キーワード 極低温コンピューティング,ゲートレベルパイプライン,単一磁束量子回路,ハイパフォーマン スコンピューティング,ポストムーア
1.
ま え が き
エレクトロニクスは,
20
世紀後半に急激に発達した
大規模集積回路(
LSI
)技術の進展により,大きく社
会を変えた.
1
年半から
2
年ごとにチップに集積でき
るトランジスタは倍増する,といった表現で広く知ら
れるムーアの法則が示すように,半導体デバイスを用
いた
LSI
技術は文字どおり指数関数的な計算機技術の
発達を支えてきた.今日,親指の爪ほどのチップに
10
億個以上のトランジスタが集積され,加工寸法はナノ
メートルに迫っている.しかし残念ながら,継続的な
微細化を望むことは不可能である.
2025
年から
2030
†名古屋大学大学院工学研究科,名古屋市Graduate School of Engineering, Nagoya University, Furo-cho, Chikusa-ku, Nagoya-shi, 464–8603 Japan
††九州大学大学院システム情報学研究院,福岡市
Faculty of Information Science and Electrical Engineering, Kyushu University, 744 Motooka, Nishi-ku, Fukuoka-shi, 819–0395 Japan
a) E-mail: masami [email protected]
年には技術的,あるいは経済的な理由により,ムーア
の法則が終焉を迎えるという予測がある.事実,
2000
年代に入ってからは,電源電圧を下げられないことに
起因し,チップの消費電力の増加が深刻な設計制約と
して顕在化した.計算機の頭脳である,マイクロプロ
セッサの動作クロック周波数は数ギガヘルツで頭打ち
となったままの状況が続いている.ムーアの法則が破
綻すれば,集積度の向上に頼る性能向上も見込むこと
が難しくなるため,情報化社会の持続的な発達を見据
え,新奇デバイスに対する期待も高まっている.
ジョセフソン接合を用いた超伝導回路は,半導体よ
りも高速に動作するポテンシャルをもち,長年研究が
行われてきた.特に,
1990
年代に体系化された単一磁
束量子(
SFQ
)回路
[1]
は高速性と低消費電力性に優
れ,
LSI
技術としても成熟している.近年,
SFQ
回路
を発展させた,よりエネルギー効率の高い回路方式が
次々と提案されており
[2]
∼
[9]
,冷却のハンディキャッ
プを加味しても,
CMOS
集積回路に対して圧倒的な
優位性を保つことができる水準に達している.加えて,
磁性体材料との融合により,従来の課題であったメモ
リなどで新たな進展や機能付加が可能になったことか
ら,米国では大型国家プロジェクト
[10]
が進められて
いるなど,再び活発な研究が進められている.
現在,超伝導量子ビットの研究が活発に進められて
いるが,量子ゲート計算や量子アニーリングが得意と
する組合せ問題や最適化計算は,従来の(古典)計算
とは大きな乖離がある.また,事前計算や,測定型量
子計算のように,膨大な古典計算が要求される場面も
あり,高速な古典計算機の必要性はむしろ高まると考
えられる.同じ極低温環境を利用するという観点から
も,超伝導エレクトロニクスは魅力を増している.
SFQ
回路によるマイクロプロセッサの研究は,米
国の設計試作
[11]
に端を発し,続いて,日本の研究
グループがプロトタイプ
CORE1α
の動作実証に世
界で初めて成功した
[12]
.これを発展させ,これまで
に,パイプライン処理を導入した
CORE1β [14]
や,
小規模なメモリを統合させ,デモプログラムを実行し
た
CORE e2 [18]
を含む,幾つかのマイクロプロセッ
サの動作実証が報告されている
[13]
∼
[18]
.これらの
SFQ
マイクロプロセッサは,ビットシリアル処理を導
入している.そのため,動作クロック周波数は,
15
∼
50 GHz
であるが,マイクロプロセッサとしての実効
的な性能,すなわちプログラム実行時間では,最新の
半導体マイクロプロセッサと同程度のポテンシャルを
示すに留まっていた.ビットシリアル処理を用いてい
た理由は,集積度の制約と,後述するタイミング設計
の難しさによる.
近年,高度な多層構造デバイス作製プロセスが成熟
し
[19], [20]
,また同時に,集積回路設計技術が発達し
たことにより,ビット並列処理のような,より大規模
で複雑な回路が実現可能となった.これを受け,我々
は,
SFQ
回路に適したアーキテクチャの探索を目的と
した研究を開始している.これまでに,
SFQ
回路の特
徴を最大限に引き出すことのできるマイクロプロセッ
サ,及びキャッシュメモリのアーキテクチャに関する
検討
[21], [22]
を進め,これまでとは異なる,ビット並
列演算を軸としたマイクロプロセッサの可能性を見い
出した.実験的にその有効性を検証することを目的と
し,現在,ビット並列演算マイクロプロセッサのプロ
トタイプ実証を目指して研究開発を進めている.
なお,米国でもビット並列演算によるマイクロプロ
セッサの試作が進行中
[23], [24]
であるが,交流駆動
の
SFQ
回路
[8]
を採用しているため設計条件や制約
が若干異なることもあり,半導体マイクロプロセッサ
の設計を踏襲したアーキテクチャが選択されている.
我々は,
SFQ
回路の数十ギガヘルツに及ぶ高周波動作
特性をビット並列演算において引き出すため,ゲート
レベルパイプライン,細粒度マルチスレッディングと
いった手法を導入しており,デバイス
/
回路
/
アーキテ
クチャの階層横断型アプローチを特徴としている.
本論文では,我々が動作実証を目指しているビット
並列演算マイクロプロセッサのプロトタイプの要素回
路となる,演算器やレジスタファイル,キャッシュメ
モリに関して最近の成果を報告する.ここではまず,
SFQ
回路の高周波動作設計技術について紹介し,ビッ
ト並列演算の高周波動作可能性を示すために試作した,
8 bit
ビット並列演算器について述べる.続いて,ビッ
ト並列演算マイクロプロセッサのプロトタイプ実証に
向けた,要素回路の設計と試作について述べる.
2.
単一磁束量子回路の高周波動作設計技術
2. 1
単一磁束量子回路におけるタイミング設計
SFQ
回路は,超伝導体のループ内に入る磁束が磁
束量子
Φ
0≈ 2.07 × 10
−15Wb
の整数倍となること
を利用し,ループ内の磁束量子の有無をバイナリ信号
に割り当てた論理回路である.磁束量子の動きを制御
する能動素子として,超伝導体の間にごく薄いトン
ネル障壁層を挟んだジョセフソン接合を用いる.現在
の集積回路の主流はニオブとアルミ酸化膜を用いた,
Nb/AlO
x/Nb
接合である.ジョセフソン接合に一定
の電流値(臨界電流値)以上の電流を流すと,磁束量
子がジョセフソン接合を横切ることができ,このとき
のみ,ジョセフソン接合の両端にインパルス状の電圧
パルスが発生する.これをスイッチ動作と呼んでいる.
現在の代表的なプロセス(臨界電流密度
10 kA/cm
2,
ジョセフソン接合の最小寸法
1.0
µm
四方)では,パ
ルス幅(スイッチ時間)は約
2 ps
で,この値は接合
寸法によりスケーリングする.
SFQ
回路の特徴であ
る,高速動作性や低消費電力性は,この電圧パルス信
号を用いることの帰結である.信号の伝搬には,マイ
クロストリップやストリップ構造の導波路を集積回路
内に形成した,受動線路(
PTL
)配線
[25]
も利用でき
る.極めて低損失で分散の小さい超伝導送線路を配線
として利用することで,配線容量の充放電過程なしに,
電圧パルスを電磁波として伝搬させることができる.
光信号とは異なり,磁束量子は大きく設計した超伝導
ループ(インダクタンス)を用いて容易に捕捉,保持
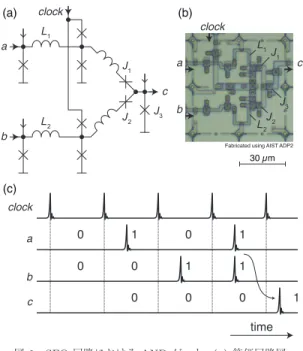
図 1 SFQ回路における AND ゲート: (a) 等価回路図, (b)顕微鏡写真,(c) 論理動作のタイミングチャート Fig. 1 SFQ AND gate: (a) equivalent circuit, (b) mi-crophotograph, and (c) timing chart of logical operation.
することもできる.
図
1
に代表的な
SFQ
回路の論理ゲートとして
AND
ゲートを示す.
(a)
はゲートの主要部分の等価回路図
で,
×
印がジョセフソン接合の回路記号を表す.回路
の駆動のため,直流の一定電流(バイアス電流)を印
加する.同図
(b)
に実際に試作した回路での顕微鏡写
真を示すが,ここで,論理積演算の中心的な役割を担
うのは,
J
1,
J
2,及び
J
3の三つのジョセフソン接合
である.入力
a
,
b
から磁束量子が入力されると,磁束
量子に伴い超伝導ループに流れる周回電流は
J
1,
J
2を通過して
J
3のところで合流する.ここで,
J
3の臨
界電流値を
J
1,
J
2よりも少し大きめに設計しておく
と,片方の入力だけでは
J
1や
J
2がスイッチし,両方
の磁束量子が到着したときにのみ臨界電流値を超えて
J
3がスイッチすることで,論理積の動作を実現するこ
とができる.
ただし,このままでは磁束量子が到着していない状
態と信号の
0
が入力された状態の区別がつかないこ
と,ピコ秒の幅しかもたない電圧パルスを同時刻に
入力することは事実上不可能であること,の
2
点が
問題となる.この解決のため,
SFQ
回路ではクロッ
ク信号
clock
を導入する.同図
(c)
に示したように,
clock
が到着するまでの間に磁束量子が到着すれば
1
,
しなければ
0
と定義する.
a
や
b
に入力された磁束
量子は,
J
1や
J
2に到達する前に,直前の超伝導ルー
プ(
L
1,
L
2)でいったん保持され,
clock
入力による
同期をとってから論理演算が行われる.したがって,
論理ゲートでの演算結果は,
1
クロックサイクルだけ
遅れる,換言すれば,全ての論理ゲートが原則として
ラッチ機能をもつことになる.クロック周期はパルス
幅の
5
∼
10
倍あればよく,現在の作製プロセスでは,
単純なシフトレジスタで
120 GHz
動作
[26]
,複雑な
演算器などでは
50 GHz
程度のビットシリアル信号処
理
[17], [18], [27], [28]
などがこれまでに動作実証され
ている.
以上で述べたとおり,
SFQ
回路の設計においては,
電圧パルス信号の到着時間の精密な制御が鍵となって
いる.大規模な
SFQ
集積回路を実現するため,我々は,
セルベース設計法
[29]
を導入し,産業技術総合研究所
が提供するニオブ
9
層構造プロセス(アドバンストプ
ロセス)
[19]
用に開発したセルライブラリ
[30], [31]
を
用いた設計技術を確立している.
SFQ
回路のタイミ
ングは,バイアス電流量のほか,超伝導ループ間の量
子干渉などの影響を受けやすい.任意のセルを自由に
組み合わせたランダムロジックが構築できることを保
証するため,セルライブラリ構築に当たっては,セル
間の相互作用が最小に抑えられるよう入出力端付近の
超伝導ループの回路パラメータが注意深く選択されて
いる.各セルは,バイアス電流量に依存する遅延時間
やセットアップ
/
ホールド時間などのタイミングパラ
メータを,アナログ回路シミュレータ
[32]
を用いて抽
出し,テーブルとして保持している.
実際の設計は,
Cadence
社の
Virtuoso
環境を用い,
SFQ
回路に必要な機能をカスタマイズすることで補っ
ている.タイミング設計に関しては,タイミングパ
ラメータのテーブルに基づき,静的タイミング解析
(
STA
)または論理シミュレーションが可能になって
いる(図
2
,
3
)
.
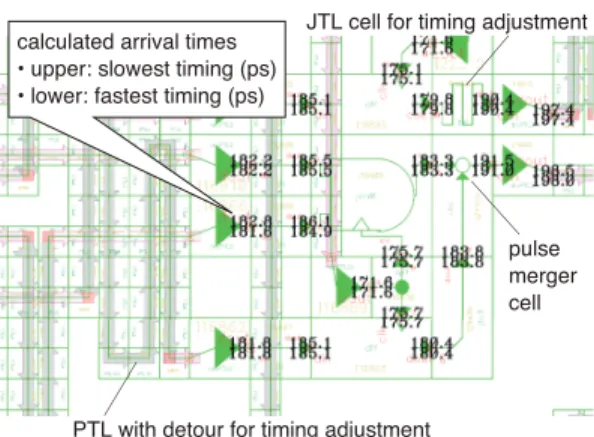
STA
は京都大学のグループにより開
発された.セル間の相互干渉が抑えられていること,
PTL
配線での信号伝搬遅延時間は配線長により決定
されることから,極めて短時間に各セルの入力におけ
るパルスの到着時間を計算できる.図中の数字は,上
段と下段に最も遅く
/
早くパルスが到着する時刻を表
している(経路の途中に,図の右にあるパルス合流回
路などがあると両者に差が生じる).タイミングの調
整は,図の左にあるように
PTL
の配線長を変えるか,
図 2 静的タイミング解析(STA)の実行例 Fig. 2 Example of static timing analysis (STA).
図 3 Verilog-HDLを用いた論理シミュレーションの実 行例
Fig. 3 Example of logic simulation using Verilog-HDL.
右上にあるようにジョセフソン接合を含む能動配線セ
ル(ジョセフソン伝送路,
JTL
)を挿入することで行
う.ただし,両者は遅延時間のバイアス電流に対する
依存が異なるため,
PTL
配線を等長にしながら,配
線上のジョセフソン接合の数も揃える,といった設計
戦略が必要である.現在は手設計に頼っているが,設
計自動化の研究も行われている
[33]
.
STA
はテストパターンを用意する必要がなく高速で
あるが,論理検証は別に行う必要があり,
Verilog-HDL
を用いた論理シミュレーションを併用している.
2. 2
並列算術論理演算器の試作と評価
次節で詳しく述べるように,本研究ではビット並列
演算による高性能
SFQ
マイクロプロセッサの実現を目
指している.これは,これまでに実証されてきたビッ
図 4 8 bitビット並列 ALU の顕微鏡写真 Fig. 4 Microphotograph of 8-bit bit-parallel ALU.トシリアル方式の演算器やマイクロプロセッサに比べ,
多数の配線間で精密なタイミング調整を要することを
意味し,より高度な設計技術が必要となる.我々は,
ビット並列演算器を,ビットシリアル演算器と同程度
の高周波で動作させることを確かめるために,
8 bit
の
ビット並列算術論理演算器(
ALU
)を設計し,評価す
ることにした
[34], [35]
.
設計した
ALU
は,
Brent-Kung
型の並列プリフィ
クス加算器を基本とし,加算,減算,論理積,論理和,
排他的論理和,否定論理和の
6
種類の演算を実装した.
ALU
内部は,論理ゲート
9
段からなる組合せ論理回路
であり,論理演算は加算器の一部の論理ゲートを共有
することで実現している.設計した
ALU
はゲートレ
ベルでのパイプライン処理が可能である.設計クロッ
ク周波数は
50 GHz
で,このとき毎秒
500
億回の演算
を実行できる性能となる.
図
4
に産業技術総合研究所のアドバンストプロセ
スを用いて試作した
ALU
のテスト回路のチップ写真
を示す.テスト回路は,オンチップテストによる高速
テストを可能にするため,テストベクタ及び結果を
格納するシフトレジスタと,
50 GHz
のオンチップク
ロック発生回路を含んでいる.これらを含めた総ジョ
セフソン接合数は
7348
である.
ALU
を構成するジョ
セフソン接合数は
4868
,専有面積は
2.85
×2.01 mm
2である.バイアス電流の設計値における消費電力は
1.35 mW
,演算のレイテンシは
354 ps
となった.な
お.本
ALU
は,ビット並列演算の高速動作の実現可
能性を評価する目的で設計を行ったため,消費電力や
レイテンシについては,まだ改善の余地は残されて
いる.
今回の試作では,ウェハ全体で臨界電流密度が設計
値よりも
10%
程度高い特性となっており,設計バイア
ス電流値よりも高い領域を中心に正常動作を確認す
ることができた.測定で得られた最高動作周波数は
56 GHz
であった.ビット並列
ALU
については,米国
HYPRES
社のニオブ
4
層,
4.5 kA/cm
2プロセス
[36]
(
1.5
µm
プロセスに相当)を用いて
20 GHz
動作が報
告されている
[37]
.スケーリングファクタを考慮して
も,今回の結果はより高周波での動作を得ることがで
きたといえ,我々の高周波動作設計技術が,ビット並
列演算にも適用可能であることが示された.我々のセ
ルライブラリは,臨界電流密度が設計値から
±10%
の
範囲でばらついても十分な歩留まりが得られるよう設
計している.今回の
ALU
設計で用いたタイミング設
計技術についても,製造ばらつきに対して,一定の余
裕度が確保できていることが示唆される結果となった.
56 GHz
動 作 時 に 計 測 し た
ALU
の 消 費 電 力 は
1.57 mW
であった.得られた電力効率は
35 TOPS/W
(
1
ワット当り毎秒
35
兆演算)を達成している.
3.
マイクロプロセッサ要素回路設計
3. 1
プロセッサアーキテクチャ
CORE1α
をはじめとする,これまでに実証に成功
した
SFQ
マイクロプロセッサは,ビットシリアル処理
の導入により,ハードウェアが最小限に抑えられてお
り,電力効率は高いものの,性能が大幅に限定される
問題があった.加えて,これらのマイクロプロセッサ
のアーキテクチャは半導体マイクロプロセッサに倣っ
たものとなっている.半導体マイクロプロセッサの設
計では,消費電力の問題から深いパイプライン処理に
よる高周波動作化は諦める一方,豊富なトランジスタ
資源を利用したアウトオブオーダ実行などによる高度
なパイプラインハザードの回避策が採用されており,
SFQ
回路とは設計の前提や制約が大きく異なる.我々
は,
SFQ
マイクロプロセッサの性能評価のために,新
たなモデルを作成して解析を進めてきた.その結論と
して,
SFQ
回路の特長を引き出すためには,
a)
ビッ
ト並列演算,
b)
ゲートレベルパイプライン,
c)
細粒
度マルチスレッディングの
3
点が必要なアプローチで
あることを明らかにした
[21]
.以下に要点をまとめる.
a )
ビット並列演算
ワード長に比例して演算時間が増大するビットシリ
アル処理では,たとえ
100 GHz
でのクロック周波数
で動作させても,
32 bit
や
64 bit
のワード長を想定す
ると,命令実行サイクルは数ギガヘルツに落ちてしま
う.この問題の解決には,ビットレベルでの並列性の
導入が必要不可欠である.数ビット単位の演算をまと
めて行う,ビットスライス処理も考えられ,スライス
幅
4 bit
の
ALU
の動作実証例
[38]
などもあるが,ビッ
ト並列演算の導入が優位な点として,ビットレベルの
並列性の積極利用により演算のレイテンシを低減化す
ることが可能なこと,シリアル処理を進めるための反
復計算が不要になることにより,演算時にワード内で
のフィードバックループが生じたり,命令実行のほか
に必要な制御が生じたりしないこと,が挙げられる.
b )
ゲートレベルパイプライン
ゲートレベルパイプラインとは,一つのパイプライ
ンステージに論理ゲートが一つだけしか含まれない,
最も粒度の小さなパイプライン処理である.
SFQ
回
路では,各論理ゲートがラッチ機能を有することから,
パイプライン処理のためのレジスタの追加のコストは
ない.また,
SFQ
回路の論理ゲートが動的に消費す
る電力は,
100 GHz
で動作させたとしても
0.01
µW
程度であり,半導体集積回路のように厳しい電力制約
がないため,徹底的な高周波動作が追求できる.論理
ゲートを駆動するクロック信号が,そのまま命令実行
サイクルを進めるクロックとなることから,マイクロ
プロセッサの設計は簡素化できる.
c )
細粒度マルチスレッディング
一般に,深いパイプライン構造をもつマイクロプロ
セッサでは,データの依存関係や分岐命令,キャッシュ
ミスなどでパイプラインストールが生じると著しく性
能が悪化する.高いスループット性能を維持するには,
これらをできるだけ隠蔽する必要があるが,複雑な制
御機構は
100 GHz
級の高周波動作を狙う
SFQ
マイ
クロプロセッサには向かない.そこで,パイプライン
ステージ数と同数の,多数のスレッドを切り替えて実
行する,細粒度のマルチスレッディングを導入する.
各スレッドは独立しているため,データ依存や制御依
存によるストールの発生を抑止できる.レジスタファ
イルと各スレッドに関するステータスレジスタは,ス
レッドの数だけ用意する必要がある.
現在,これらの手法を導入した,ビット並列演算マ
イクロプロセッサのプロトタイプ実証を目指し,要素
回路となる演算器やレジスタファイル,キャッシュメモ
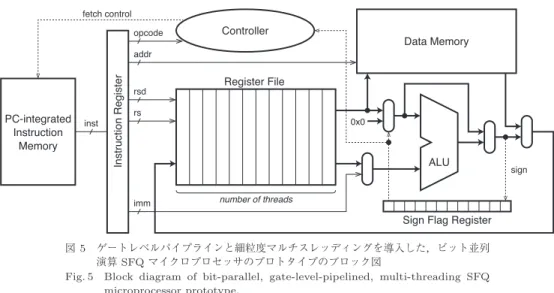
リなどの設計と試作を進めている.図
5
にブロック図
を示す.命令の実行は,
Single Instruction Multiple
Thread
(
SIMT
)方式で,
1
クロックサイクルごとに
図 5 ゲートレベルパイプラインと細粒度マルチスレッディングを導入した,ビット並列 演算 SFQ マイクロプロセッサのプロトタイプのブロック図
Fig. 5 Block diagram of bit-parallel, gate-level-pipelined, multi-threading SFQ microprocessor prototype.
命令を実行する.全体のパイプラインステージ数は
24
であるが,レジスタファイルの回路規模を現在の作製
プロセスで実証可能な水準に抑えるため,スレッド数
は半分の
12
とした.この場合,連続する
2
命令間で依
存関係がないよう,命令実行をスケジューリングをす
る必要がある.命令セットは,レジスタ演算命令(レ
ジスタ
rsd
と
rs
に対して演算を行い,
rsd
に書き戻
す二項演算),データ転送命令,制御命令を含む,最
小限の
12
命令とした.目標クロック周波数(命令サ
イクル)は
50 GHz
である.
3. 2
データパス
ここでは,
ALU
とレジスタファイルを結合した,
データパスの設計
[39]
と進捗について報告する.
今回はコンセプトの実証を目的とするため,ワード
長は
4 bit
とし,レジスタ数は
4
としている.我々が
提案しているアプローチでは,レジスタファイルは細
粒度マルチスレッディングを実現するために大容量と
なり,マイクロプロセッサの中では最も大規模な要素
回路となる.ただしスレッドの切り替えは逐次行われ
るので,全体に対してランダムアクセスは不要である.
そこで,
SFQ
回路で実現しやすく,高周波動作に向い
たシフトレジスタ構造を基本とし,循環型シフトレジ
スタによりレジスタファイルを実現することにした.
データパスでは,
ALU
とレジスタファイルの間で
データが往復するため,タイミング設計が特に難しい
箇所となる.
SFQ
回路では,
PTL
配線により光速で
の信号伝送が可能とはいえ,
1 mm
の配線で生じる遅
延は約
10 ps
であり,クロックサイクルの半分に相当
図 6 試作したデータパステスト回路の顕微鏡写真 Fig. 6 Microphotograph of datapath test circuit.する.長距離配線を避けた注意深いフロアプラン作成
が必要である.図
6
にデータパスをテストするため
に試作したチップの顕微鏡写真を示す.図の下部が最
下位ビット側,上部が最上位ビット側になっているが,
ALU
とレジスタファイルを独立に配置するのではな
く,融合したレイアウト設計を行った.クロック信号や
制御信号の分配は,回路全体にわたってオーバーラッ
プするように配置配線されている.回路全体のジョセ
フソン接合数は
9688
,占有面積は
2.85
×1.98 mm
2,
設計バイアス電流での消費電力は
2.5 mW
である.
現在,試作したチップの評価を進めており,部分動
作ではあるが,高周波での動作を確認している.した
がって,フロアプランの設計指針は有効であると考え
ている.論理シミュレーションを用いた解析では,設
計バイアス電流値で
35 GHz
程度の動作を見込んでい
る.目標とする
50 GHz
での動作のため,タイミング
設計の最適化を継続しており,データパスの高周波動
作実証を目指して再試作と評価を進めている.
なお,図
6
の回路の他に,データパスに含まれる加
減算器及びレジスタファイルを評価するため,独立し
たテスト回路の試作を行っており,オンチップテスト
による評価の結果,最高で
40 GHz
程度の高周波動作
を確認している
[39]
.
3. 3
キャッシュメモリ
高いスループット性能を維持するには,高速なオン
チップキャッシュメモリが実現できるかが鍵となる.
マイクロプロセッサプロトタイプの実証と平行して,
SFQ
回路に適したキャッシュメモリの検討を進めてい
る.これまでに,我々は循環型シフトレジスタの構造
をもつキャッシュメモリの提案とその性能評価を行っ
ている
[22], [40]
.
ビット並列処理の導入と,複数の循環型シフトレ
ジスタのサブアレー化により,ビットシリアル処理に
よるキャッシュ
[41]
に比べアクセスレイテンシの高速
化が期待できる.
2 KB
のキャッシュメモリを想定し
た場合,
32
のサブアレー化により,レイテンシは約
740 ps
,消費電力は
240 mW
と見積もっている
[22]
.
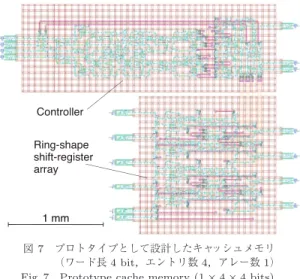
現在,提案したキャッシュメモリの高周波動作を実
験的に検証するため,プロトタイプの試作を行ってい
る.図
7
に試作中のテスト回路のレイアウトを示す.
ワード長,エントリ数,アレー数はぞれぞれ
4
,
4
,
1
としており,コントローラと循環型シフトレジスタア
レーを合わせてジョセフソン接合数は
2523
,消費電力
図 7 プロトタイプとして設計したキャッシュメモリ (ワード長 4 bit,エントリ数 4,アレー数 1) Fig. 7 Prototype cache memory (1× 4 × 4 bits).は
0.78 mW
,回路面積は
1.71
×1.50 mm
2である.
4.
む す び
超伝導単一磁束量子(
SFQ
)回路に基づく,
100 GHz
級の高性能マイクロプロセッサに向け,現在進めてい
る研究の進展を報告した.デバイス
/
回路
/
アーキテク
チャの階層横断型アプローチにより,
SFQ
回路に適
したアーキテクチャを探索した結果,我々はゲートレ
ベルパイプライン処理によるビット並列演算マイク
ロプロセッサの可能性を見い出し,超高速極低温コン
ピューティングに向けて開発に着手している.
ビット並列演算では,これまでのビットシリアル演
算に比べて格段に高度なタイミング設計技術が要求さ
れる.これまでに確立された,
SFQ
回路の高周波設計
技術,並びに,
1.0
µm
プロセスを用いて作製されるニ
オブ
9
層構造デバイスを用い,我々は
8 bit
算術論理
演算器を最高
56 GHz
で動作させることに成功した.
ビット並列演算による高周波動作可能性が実証できた
ことを受け,現在,ビット並列演算マイクロプロセッ
サのプロトタイプ実証を目指し,要素回路となる演算
器やレジスタファイル,キャッシュメモリなどの設計
と試作を進めている.一部の要素回路については正常
動作を確認しており,設計目標となる
50 GHz
の達成
に向け,タイミング設計の最適化など,設計の精緻化
に取り組んでいる.実設計や実証に基づくマイクロプ
ロセッサの定量的な性能評価が次の研究課題である.
図
8
に,これまでに実証に成功した
SFQ
マイクロプ
ロセッサに基づき,
32 bit
の演算を行うシングルコア
プロセッサを想定して性能を見積もった結果をプロッ
トした図を示す.現段階では実プログラムによる性能
の評価は難しいため,性能の指標は
MIPS
(
million
instructions per second
),すなわち
1
秒当り実行可
能な命令数を
100
万命令単位で表したものとする.グ
ラフの縦軸は
MIPS
値,横軸は単位電力当りの
MIPS
値で電力効率を表す.
1.0
µm
プロセスを用いた,ビッ
トシリアル処理によるマイクロプロセッサ
CORE e2
は,パイプライン処理を導入すれば,
50 GHz
のビッ
トシリアル処理により,原理的には約
1500 MIPS
の
性能を
2
× 10
6MIPS/W
の効率で実現できるポテン
シャルをもつ(図中の
×
印).一方,本研究で目指し
ている,ゲートレベルパイプライン処理によるビット
並列演算プロセッサ(
GLP
)を同一プロセスで実現し
た場合,電力効率はやや低下するが,
50 GHz
動作に
より
50,000 MIPS
の圧倒的に高い性能が得られる見
図 8 SFQマイクロプロセッサの性能とエネルギー効率 の比較(32 bit シングルコアマイクロプロセッサ相 当で比較)
Fig. 8 Comparison of performance and energy effi-ciency of SFQ microprocessors (assumed a 32-bit single-core microprocessor).
込みである.図には,シングルコアの性能追求を重視
して設計された時代の代表的な半導体マイクロプロ
セッサについてもプロットを示した.超伝導回路の冷
却に必要な電力は,極低温下で回路が消費する電力の
1000
倍程度であり,
GLP
は計算能力と電力効率の両
面において,半導体集積回路を凌駕できる点に位置す
る.更に将来,
0.3
µm
プロセスが実現されれば,性能
は
200,000 MIPS
,電力効率は
5
× 10
6MIPS/W
に
達すると期待している(図中の☆印).これらは,従
来の
SFQ
回路を用いて設計することを想定している
が,
CORE e2
に対して,低電圧駆動
[7]
や多電圧駆動
技術を導入した
CORE1α LV
や
CORE100
マイクロ
プロセッサ
[16]
のプロットが示すとおり,エネルギー
効率を改善した新しい
SFQ
回路技術の導入で,更な
る性能
/
電力効率の向上も可能である.
謝 辞 本 研 究 は
JSPS
科 研 費
JP16H02796
,
JP16H02340
,
JP26220904
,
JST ALCA
の支援を受
け実施したものである.回路は産業技術総合研究所の
クリーンルーム
CRAVITY
において作製された.研
究の一部は,東京大学大規模集積システム設計教育研
究センター(
VDEC
)を通し,ケイデンス株式会社の
協力で行われたものである.
文
献
[1] K.K. Likharev and V.K. Semenov, “RSFQ logic/ memory family: A new Josephson-junction tech-nology for sub-terahertz-clock-frequency digital
sys-tems,” IEEE Trans. Appl. Supercond., vol.1, no.1, pp.3–28, March 1991.
[2] A.V. Rylyakov, “New design of single-bit all-digital RSFQ autocorrelator,” IEEE Trans. Appl. Super-cond., vol.7, no.2, pp.2709–2712, June 1997. [3] N. Yoshikawa and Y. Kato, “Reduction of power
con-sumption of RSFQ circuits by inductance-load bias-ing,” Supercond. Sci. Technol., vol.12, no.11, pp.918– 920, Nov. 1999.
[4] R. Tsutsumi, K. Sato, Y. Yamanashi, and N. Yoshikawa, “Improvement of operation speed of LR-biased low-power single-flux quantum circuits by in-troduction of dynamic resetting of bias currents,” IEEE Trans. Appl. Supercond., vol.26, no.8, 1301405, Dec. 2016.
[5] D.E. Kirichenko, S. Sarwana, and A.F. Kirichenko, “Zero static power dissipation biasing of RSFQ cir-cuits,” IEEE Trans. Appl. Supercond., vol.21, no.3, pp.776–779, June 2011.
[6] M.H. Volkmann, A. Sahu, C.J. Fourie, and O.A. Mukhanov, “Implementation of energy efficient single flux quantum digital circuits with sub-aJ/bit opera-tion,” Supercond. Sci. Technol., vol.26, no.1, 015002, Jan. 2013.
[7] M. Tanaka, M. Ito, A. Kitayama, T. Kouketsu, and A. Fujimaki, “18-GHz, 4.0-aJ/bit operation of ultra-low-energy rapid single-flux-quantum shift registers,” Jpn. J. Appl. Phys., vol.51, no.5R, 053102, May 2012. [8] Q.P. Herr, A.Y. Herr, O.T. Oberg, and A.G. Ioanni-dis, “Ultra-low-power superconductor logic,” J. Appl. Phys., vol.109, no.10, 103903, May 2011.
[9] N. Takeuchi, D. Ozawa, Y. Yamanashi, and N. Yoshikawa, “An adiabatic quantum flux parametron as an ultra-low-power logic device,” Supercond. Sci. Technol., vol.26, no.3, 35010, Jan. 2013.
[10] Intelligence Advanced Research Projects Activ-ity (IARPA), “Cryogenic Computing ComplexActiv-ity (C3),” https://www.iarpa.gov/index.php/research-programs/c3/, accessed on Nov. 24, 2017.
[11] M. Dorojevets, P. Bunyk, and D. Zinoviev, “FLUX chip: design of a 20-GHz 16-bit ultrapipelined RSFQ processor prototype based on 1.75-µm LTS technol-ogy,” IEEE Trans. Appl. Supercond., vol.11, no.1, pp.326–332, March 2001.
[12] M. Tanaka, F. Matsuzaki, T. Kondo, N. Nakajima, Y. Yamanashi, A. Fujimaki, H. Hayakawa, N. Yoshikawa, H. Terai, and S. Yorozu, “A single-flux-quantum logic prototype microprocessor,” Int. Solid-State Circuit Conf. (ISSCC 2004), pp.298–529, San Francisco, USA, Feb. 2004.
[13] M. Tanaka, T. Kondo, T. Kawamoto, Y. Kamiya, A. Fujimaki, H. Hayakawa, N. Nakajima, Y. Yamanashi, A. Akimoto, N. Yoshikawa, H. Terai, Y. Hashimoto, and S. Yorozu, “Demonstration of a single-flux-quantum microprocessor using passive transition
lines,” IEEE Trans. Appl. Supercond., vol.15, no.2, pp.400–404, June 2005.
[14] Y. Yamanashi, M. Tanaka, A. Akimoto, H. Park, Y. Kamiya, N. Irie, N. Yoshikawa, A. Fujimaki, H. Terai, and Y. Hashimoto, “Design and implementation of a pipelined bit-serial SFQ microprocessor, CORE1β,”
IEEE Trans. Appl. Supercond., vol.17, no.2, pp.474– 477, June 2007.
[15] A. Fujimaki, M. Tanaka, T. Yamada, Y. Yamanashi, H. Park, and N. Yoshikawa, “Bit-serial single flux quantum microprocessor CORE,” IEICE Trans. Elec-tron., vol.E91-C, no.3, pp.342–349, March 2008. [16] M. Tanaka, Y. Hayakawa, K. Takata, and A.
Fujimaki, “35-GHz demonstration of energy-efficient microprocessor based on low-voltage RSFQ circuit,” Appl. Supercond. Conf. (ASC 2014), 2EOr2C-01, Charlotte, NC, USA, Aug. 2014.
[17] Y. Ando, R. Sato, M. Tanaka, K. Takagi, N. Takagi, and A. Fujimaki, “Design and demonstration of an 8-bit bit-serial RSFQ microprocessor: CORE e4,” IEEE Trans. Appl. Supercond., vol.26, no.5, 1301205, Aug. 2016.
[18] R. Sato, Y. Hatanaka, Y. Ando, M. Tanaka, A. Fujimaki, K. Takagi, and N. Takagi, “High-speed operation of random-access-memory-embedded mi-croprocessor with minimal instruction set architec-ture based on rapid single-flux-quantum logic,” IEEE Trans. Appl. Supercond., vol.27, no.4, 1300505, June 2017.
[19] S. Nagasawa, K. Hinode, T. Satoh, M. Hidaka, H. Akaike, A. Fujimaki, N. Yoshikawa, K. Takagi, and N. Takagi, “Nb 9-layer fabrication process for super-conducting large-scale SFQ circuits and its process evaluation,” IEICE Trans. Electron., vol.E97-C, no.3, pp.132–140, March 2014.
[20] S.K. Tolpygo, V. Bolkhovsky, T.J. Weir, A. Wynn, D.E. Oates, L.M. Johnson, and M.A. Gouker, “Ad-vanced fabrication processes for superconducting very large scale integrated circuits,” IEEE Trans. Appl. Supercond., vol.26, no.3, 1100110, April 2016. [21] 石田浩貴,田中雅光,小野貴継,井上弘士,“単一磁束量 子回路向けマイクロプロセッサのアーキテクチャ探索,”情 処学論,vol.58, no.3, pp.629–643, March 2017. [22] K. Ishida, M. Tanaka, T. Ono, and K. Inoue,
“Single-flux-quantum cache memory architecture,” 13th In-ternational SoC Design Conference (ISOCC 2016), pp.105–106, Jeju, South Korea, Oct. 2016.
[23] Q.P. Herr, “RQL for large scale, energy-efficient com-puting,” Appl. Supercond. Conf. (ASC 2016), Den-ver, CO, USA, Sept. 2016.
[24] A. Herr, B. Konigsberg, R. Clarke, M. Vesely Jr., P. Farrell, P. Tschirhart, J. Egan, J. Strong, M. Al-varado, B. Song, K. Ogg, and Q. Herr, “Reciprocal quantum logic CPUs for energy efficient high perfor-mance computing,” 16th Int. Supercond. Electron.
Conf. (ISEC 2017), Fr-I-DIG-02, Sorrento, Italy, June 2017.
[25] S.V. Polonsky, V.K. Semenov, and D.F. Schneider, “Transmission of single-flux-quantum pulses along superconducting microstrip lines,” IEEE Trans. Appl. Supercond., vol.3, no.1, pp.2598–2600, March 1993.
[26] H. Akaike, T. Yamada, A. Fujimaki, S. Nagasawa, K. Hinode, T. Satoh, Y. Kitagawa, and M. Hidaka, “Demonstration of 120 GHz single flux quantum cir-cuits based on a 10 kA/cm2Nb process,” Supercond. Sci. Technol., vol.19, no.5, pp.S320–S324, May 2006. [27] X. Peng, Q. Xu, T. Kato, Y. Yamanashi, N. Yoshikawa, A. Fujimaki, N. Takagi, K. Takagi, and M. Hidaka, “High-speed demonstration of bit-serial floating-point adders and multipliers using single-flux-quantum circuits,” IEEE Trans. Appl. Super-cond., vol.25, no.3, 1301106, June 2015.
[28] T. Ono, H. Suzuki, Y. Yamanashi, and N. Yoshikawa, “Design and implementation of an SFQ-based single-chip FFT processor,” IEEE Trans. Appl. Supercond., vol.27, no.4, 1301505, June 2017.
[29] S. Yorozu, Y. Kameda, H. Terai, A. Fujimaki, T. Yamada, and S. Tahara, “A single flux quantum stan-dard logic cell library,” Physica C, vol.378–381, no.2, pp.1471–1474, Nov. 2002.
[30] H. Akaike, M. Tanaka, K. Takagi, I. Kataeva, R. Kasagi, A. Fujimaki, K. Takagi, M. Igarashi, H. Park, Y. Yamanashi, N. Yoshikawa, K. Fujiwara, S. Nagasawa, M. Hidaka, and N. Takagi, “Design of single flux quantum cells for a 10-Nb-layer pro-cess,” Physica C, vol.469, no.15–20, pp.1670–1673, Oct. 2009.
[31] Y. Yamanashi, T. Kainuma, N. Yoshikawa, I. Kataeva, H. Akaike, A. Fujimaki, M. Tanaka, N. Takagi, S. Nagasawa, and M. Hidaka, “100 GHz demonstrations based on the single-flux-quantum cell library for the 10 kA/cm2 Nb multi-layer process,” IEICE Trans. Electron., vol.E93-C, no.4, pp.440–444, April 2010.
[32] E.S. Fang and T. Van Duzer, “A Josephson inte-grated circuit simulator (JSIM) for superconductive electronics application,” 2nd Int. Supercond. Elec-tron. Conf. (ISEC ’89), pp.407–410, Tokyo, Japan, June 1989.
[33] N. Kito, K. Takagi, and N. Takagi, “Automatic routing of SFQ digital circuits considering wire-length matching,” IEEE Trans. Appl. Supercond., vol.26, no.3, 1300305, April 2016.
[34] 佐藤 諒,畑中湧貴,松井祐一,田中雅光,赤池宏之,藤 巻 朗,井上弘士,“50 GHz 動作を目指した単一磁束量 子並列算術論理演算回路,” 2017信学総大,C-8-2, March 2017.
[35] M. Tanaka, R. Sato, Y. Hatanaka, Y. Matsui, H. Akaike, A. Fujimaki, K. Ishida, T. Ono, and K. Inoue,
“High-throughput bit-parallel arithmetic logic unit using rapid single-flux-quantum logic,” 16th Int. Su-percond. Electron. Conf. (ISEC 2017), Tu-C-DIG-02, Sorrento, Italy, June 2017.
[36] HYPRES, Inc., “Niobium IC Fabrication Design Rules,” http://www.hypres.com/, accessed on Nov. 24, 2017.
[37] T.V. Filippov, A. Sahu, A.F. Kirichenko, I.V. Vernik, M. Dorojevets, C.L. Ayala, and O.A. Mukhanov, “20 GHz operation of an asynchronous wave-pipelined RSFQ arithmetic-logic unit,” Physics Procedia, vol.36, pp.59–65, June 2012.
[38] G. Tang, K. Takata, M. Tanaka, A. Fujimaki, K. Takagi, and N. Takagi, “4-bit bit-slice arithmetic logic unit for 32-bit RSFQ microprocessors,” IEEE Trans. Appl. Supercond., vol.26, no.1, 1300106, Jan. 2016.
[39] 畑中湧貴,松井裕一,田中雅光,佐野京佑,藤巻 朗,石 田浩貴,小野貴継,井上弘士,“単一磁束量子ゲートレベ ルパイプラインマイクロプロセッサに向けた要素回路設 計,”信学技報,SCE2017-17, Aug. 2017.
[40] K. Ishida, M. Tanaka, T. Ono, and K. Inoue, “To-wards ultra high-speed cryogenic single-flux-quantum computing,” IEICE Trans. Electron., vol.E101-C, no.5, pp.359–369, May 2018.
[41] M. Tanaka, Y. Yamanashi, N. Irie, H. Park, S. Iwasaki, K. Takagi, K. Taketomi, A. Fujimaki, N. Yoshikawa, H. Terai, and S. Yorozu, “Design and im-plementation of a pipelined 8 bit-serial single-flux-quantum microprocessor with cache memories,” Su-percond. Sci. Technol., vol.20, no.11, pp.S305–S309, Nov. 2007. (平成 29 年 11 月 29 日受付,30 年 4 月 27 日再受付, 9月 11 日公開)
田中 雅光 (正員)
2006年名古屋大学大学院工学研究科電 子情報学専攻博士課程(後期課程)修了. 博士(工学).2009 年より同大学院情報科 学研究科特任助教.2016 年より同大学院工 学研究科助教,現在に至る.単一磁束量子 集積回路による超高速信号処理応用,集積 回路設計技術に関する研究などに従事.電子情報通信学会,低 温工学・超電導学会,電気学会,応用物理学会,IEEE 各会員.佐藤
諒
2015年名古屋大学工学部電気電子・情 報工学科卒業.同年,同大学大学院工学研 究科量子工学専攻博士課程(前期課程)に 入学し,超伝導集積回路に関する研究に従 事.2017 年修了.修士(工学).石田 浩貴 (学生員)
2016年九州大学工学部電気情報工学科 卒業.同年同大学大学院修士課程入学,現 在に至る.単一磁束量子マイクロプロセッ サ・アーキテクチャに関する研究に従事. 電子情報通信学会,IEEE 各会員.畑中 湧貴 (学生員)
2016年名古屋大学工学部電気電子・情報 工学科卒業.現在,名古屋大学大学院工学 研究科量子工学専攻博士課程(前期課程) にて超伝導集積回路に関する研究に従事. 電子情報通信学会会員.松井 裕一 (学生員)
2017年名古屋大学工学部電気電子・情報 工学科卒業.現在,名古屋大学大学院工学 研究科電子工学専攻博士課程(前期課程) にて超伝導集積回路に関する研究に従事. 電子情報通信学会会員.小野 貴継 (正員)
2009年九州大学大学院システム情報科 学府情報理学専攻博士課程修了.博士(工 学).同年より日本学術振興会特別研究員 (PD).2010 年株式会社富士通研究所入 社.データセンタ向けサーバの研究開発に 従事.2015 年より九州大学大学院システ ム情報科学研究院助教,現在に至る.メモリ・アーキテクチャ, スーパーコンピューティング等に関する研究に従事.電子情報 通信学会,IEEE 各会員.井上 弘士 (正員)
1996年九州工業大学大学院情報工学研 究科修士課程修了.同年横河電機(株)入 社.1997 年より(財)九州システム情報技 術研究所研究助手.1999 年の 1 年間 Halo LSI Design & Device Technology, Inc. において訪問研究員としてフラッシュ・メ モリの開発に従事.博士(工学).2001 年より福岡大学工学部 電子情報工学科助手.2004 年より九州大学大学院システム情 報科学研究院助教授.2007 年より同大学准教授.2014 年より 同大学教授,現在に至る.高性能/低消費電力プロセッサ/メモ リ・アーキテクチャ,セキュア・アーキテクチャ,スーパーコ ンピューティング,ポストムーア・コンピューティング等に関 する研究に従事.電子情報通信学会,ACM,IEEE 各会員.