正確な相互情報量を推定する
R
パッケージ
mi.correct
と、株価
予測への応用
鈴木譲
1 ∗1
大阪大学大学院理学研究科
1
Graduate School of Science, Osaka University
Abstract: 相互情報量を推定する R パッケージ mi.correct を公開した。その応用として、今回は、 株式の銘柄間の関連性を見出すことを試みた。
1
はじめに
2 変量の関連性の評価する尺度として、相互情報量 がある。相関係数とちがって、独立でなければ必ず非 ゼロになるので、独立性をはかる尺度にもなる。 相互情報量を正確に推定するメリットはいくつもあ る。最近、著者は相互情報量の R のパッケージ mi.correct を公開したので、まず、それを紹介する。通常、最尤 法といって、相対頻度で得られた確率の推定値を代入 することがよく行われているが、その場合には、過学 習によって、真の相互情報量より大きくなってしまい、 独立性すら判定できない。また、そのような naive な やり方では、連続な 2 変量の場合に拡張ができない。 本稿では、連続な場合の相互情報量の推定方法を用 いて、株式データの関連性を見出すことを試みる。R の quantmod という金融データを扱うパッケージを用 いて、東証や為替のデータを API 経由で獲得し、時系 列のデータフレームを構築し、相互情報量が推定でき、 重要な情報が得られることをデモンストレートする。 銘柄間の関連性がわかると、株式の保有の危険分散 や、個人投資家にとってどの銘柄が得意であるかが把 握できるなど、投資の重要な情報になる。 なお、本稿は、研究の成果というよりは、一つの試 み的な事例を示すことを目的としている。したがって、 何かの議論の引き金になれば、幸いである。2
相互情報量の推定
相互情報量は、X, Y を確率変数として、X, Y が離散 の値をとるとき、その確率が PX, PY, PXY であれば、 I(X, Y ) :=∑ x ∑ y PXYlog PXY(x, y) PX(x)PY(y) ∗連絡先:大阪大学大学院理学研究科 〒 560-0043 豊中市待兼山町 1-1 E-mail: [email protected] また、X, Y に確率密度関数 fX, fY, fXY が存在する とき、 I(X, Y ) := ∫ x ∫ y fXY log fXY(x, y) fX(x)fY(y) dxdy と定義できる。相互情報量には I(X, Y ) = 0⇐⇒ X ⊥⊥ Y (1) (X ⊥⊥ Y と書いて、「X, Y は独立である」と読む) と いう性質がある。この性質は貴重で、相関係数 ρ(X, Y ) の場合には、X ∼ N(0, 1), U ∈ {−1, 1}(等確率), Y = X∗U の場合に、X ̸⊥⊥ Y であって ρ(X, Y ) = 0 となる。 n 個の (X, Y ) の実現値 (最初は離散とする) xn = (x1,· · · , xn), yn = (y1,· · · , yn), (xi, yi)∼ PXY から、 相互情報量を推定するには、以下のような量が計算さ れることが多い (最尤法とよばれる)。 In(xn, yn) := ∑ x ∑ y ˆ Pn(x, y) log ˆ Pn(x, y) ˆ Pn(x) ˆPn(y) (2)ここで、 ˆPn(x, y), ˆPn(x), ˆPn(y) は、(x, y), x, y の n に 対しての相対頻度を表すものとする。この場合に、n を 十分に大きくとると、大数の法則から、n を大きくす ると In(xn, yn)→ I(X, Y ) (3) となることは、確かめることができる。 しかし、X⊥⊥ Y であっても、In(xn, yn) > 0 が無限 回生じるので、In(xn, yn) は (1) を満足する推定量には なっていない、といえる。また、この推定量を連続の 場合に拡張することは難しい。 そこで、たとえば、「私は東京生まれで、私立大学 で博士を取得して、助教を 5 年やってから、大阪にあ る大学のポストを得た」という n 文字のテキストを、 100101· · · 1 というような m ビットの 2 進列に対応さ せることを考える。テキストの各文字を有限集合 A の 要素と考えると、この写像 (符号化とよぶ) は、Anから 人工知能学会研究会資料 SIG-FPAI-B501-06
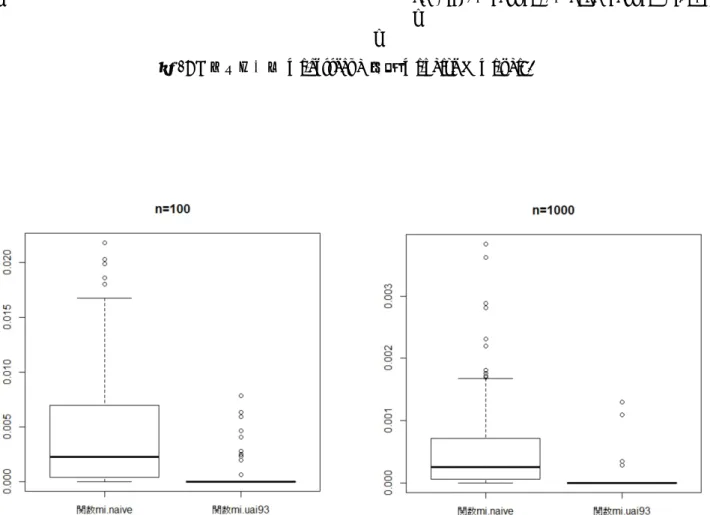
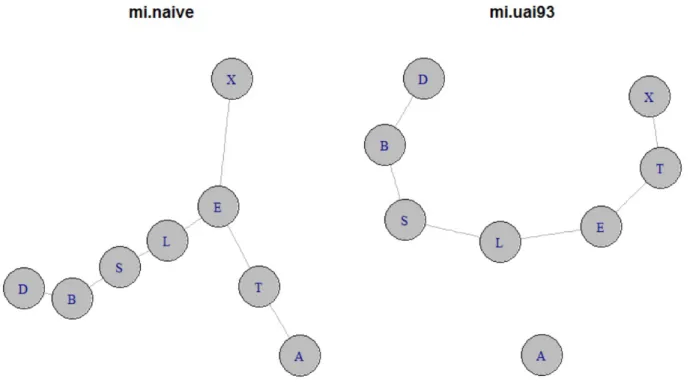
(可変長の)2 進列の集合への対応になっていて、m/n を 圧縮率とよぶ。gzip や uuencode のようなユニバーサル 圧縮の方法を用いると、m/n が確率 1 でエントロピー に近づくことが知られている。そこで、2−mをそのテ キストの確率のようなもの (ユニバーサル確率とよぶ) としてとらえ、各 xn∈ Anに対して、Qn X(xn) := 2−m を割りあてる (m の値は xnごとに異なる)。そして、 yn, (xn, yn) に対しても同様に、Qn Y(y n), Qn XY(x n, yn) を割りあてる。筆者自身、20 年以上前に、下記のよう な相互情報量の推定量を提案した。 Jn(xn, yn) := 1 nlog QnXY(xn, yn) Qn X(xn)QnY(yn) ≈ In(xn, yn)− (α− 1)(β − 1) 2n log n (α, β は、それぞれ X, Y のとりうる場合の数)。これに は、In(xn, yn) と同様、n とともに I(X, Y ) に近づく性 質があるが、それ以外に、 Jn(xn, yn)≤ 0 ⇐⇒ X ⊥⊥ Y (4) が確率 1 で成立する性質があり、また Qn X(x n) などの 評価を連続の場合にまで拡張する (後述) ことによって、 X, Y が連続の場合にも相互情報量が推定できる。 最近、mi.correct という R 言語のパッケージを公 開した。現在は GitHub から誰でもインストールでき、 その中の関数を利用できる。 install_github("mi.correct","prof-joe") #イン ストール時のみ library(mi.correct) # R を立ち上げた時のみ 最尤法による推定量 In(xn, yn) は mi.naive という関 数で、Jn(xn, yn) に基づく方法 (負の値を取るときは、0 の値を与えている) は mi.uai93 という関数であたえて いる。関数 mi.uai93 では、ユニバーサル確率 Qn X(x n) は、 c(xk, xk−1) +12 k− 1 + α2 の積 (k = 1,· · · n) で計算している。ただし、c(xk, xk−1) は、xkの xk−1= (x1,· · · , xk−1) における頻度である。 関数 mi.naive は、xn, ynが独立であっても正の値を 計算するのに対して、関数 mi.uai93 は、xn, ynが独立 である場合、ほとんどの場合 0 を返す。図 2 は、確率 0.5 の独立な 2 進列 xn, ynに対して、mi.uai93 は n = 100 で 100 施行中 10 回程度、n = 1000 では 100 施行中 3-4 回しか、独立性を見落としていない。 この推定量を、Chow-Liu アルゴリズムに適用した 例を図 3 に記す (R パッケージ bn.learn の Asia という に対応する相互情報量が最大となる木を生成する。関 数 mi.naive では、独立であっても独立であることが認 識できないために、辺として結び、最終的に尤度が最 大となる極大木を生成する。他方、mi.uai93 では、相 互情報量の推定量が非正となる場合 (独立であると認 識している) があり、その場合にはその 2 頂点は結ばれ ない。 連続の場合、相互情報量の推定は、格段に難しくな る。しかし、関数 mi.uai93 を拡張する形で、ベイズ的 な推定量 (スコア) を計算すればよい。この研究会でも 何度か報告しているので、詳細は省略するが、図 4 のよ うに、ヒストグラムを何通りかに分割して、その重み 付け和でスコアを求める。最近では、実際に性能がよく なるように改良を進めている。連続であっても、(3)(4) の 2 性質は証明されている。 X: xn = (x 1,· · · , xn)7→ (a (j) 1 ,· · · , a (j) n ), j = 1, 2,· · · .. . ... .. . ... -Level 1 Level 2 Level j Qn 1(a (1) 1 ,· · · , a (1) n ) λ(a(1)1 )· · · λ(a(1)n ) Qn2(a (2) 1 ,· · · , a (2) n ) λ(a(2)1 )· · · λ(a(2)n ) Qn j(a (j) 1 ,· · · , a (j) n ) λ(a(j)1 )· · · λ(a(j)n ) 図 4: ヒストグラムの重み付け和によるスコアの導出
3
株式の銘柄間の因果関係の推定
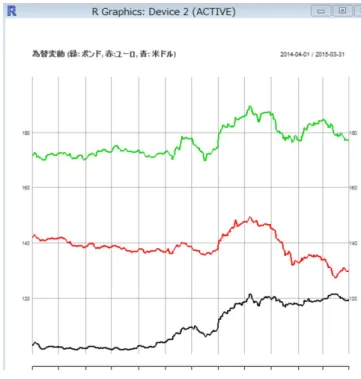
金融データでも、データさえ獲得できれば、そのデー タフレームから、Bayesian ネットワークや Markov ネッ トワークなどの構造を学習できる。近年では、データ を獲得するための API が用意されるようになった。今 回は、比較的使われていると思われる quantomod とい う R のパッケージで、データを獲得することとした。 library(quantmod) sakura<-getSymbols.yahooj("3778.t",from= "2014-04-01",to="2015-03-31",auto.assign=FALSE); 東京証券取引所の銘柄は、2015 年 3 月から新しくパッ ケージに入った関数 getSymbols.yahooj で、株価デー図 6: R パッケージ quantomod の chartSeries 関数に よる表示 5)。また、為替についても、関数 getSymbols.oanda で OANDA 社の API(アカウントの取得は不要) 経由で データを取得できる。 本稿では、どのような銘柄どうしに因果関係が認め られるか調査してみた。ビックデータの新興企業 8 社 (東証コード 2158, 2389, 3622, 3655, 3680, 3905, 3906, 6031) と円ドル、円ユーロの為替の 2014 年 4 月から 2015 年 3 月までの株価データから、相互情報量の推定 量を算出した。
4
まとめ
本稿では、連続な 2 変量の相互情報量を推定する問 題の応用として、株式の銘柄間の関連性を求めてみた。 今回の検討がたたき台となって、新しい問題設定や方 向性がさだまれば、幸いである。参考文献
[1] Joe Suzuki, ”A Construction of Bayesian Net-works from Databases based on an MDL Prin-ciple”. Proc Conf Uncertainty in Artificial
In-telligence (UAI), pp 266-273. Washington D.C.
(1993).
[2] Joe Suzuki, ”The Bayesian Chow-Liu Algo-rithm”, The European Workshop on Probabilistic
Graphical Models(PGM), Granada, Spain (2012).
図 7: 為替データの獲得
表 1: ビックデータ関連上場会社 8 社と為替の毎日の終値: 3 社は 2014 年 4 月に上場していない。 2158.t 2389.t 3622.t 3655.t 3680.t 3905.t 3906.t 6031.t USD EUR 2014-04-01 332 790 1710 1702 1685 NA NA NA 103.03 141.85 2014-04-02 336 808 1850 1662 1937 NA NA NA 103.38 142.53 2014-04-03 334 809 1837 1579 1851 NA NA NA 103.76 143.06 2014-04-04 377 829 1787 1587 1798 NA NA NA 103.93 142.88 2014-04-05 NA NA NA NA NA NA NA NA 103.74 142.20 2014-04-06 NA NA NA NA NA NA NA NA 103.29 141.56 2014-04-07 457 809 1748 1545 1658 NA NA NA 103.29 141.56 2014-04-08 418 787 1718 1456 1580 NA NA NA 103.19 141.57 2014-04-09 498 773 1698 1424 1498 NA NA NA 102.52 141.15 2014-04-10 532 775 1600 1451 1386 NA NA NA 101.96 140.74 .. . ... ... ... ... ... ... ... ... ... ... 表 2: ビックデータ関連上場会社 8 社と為替の間の相互情報量 2158.t 2389.t 3622.t 3655.t 3680.t 3905.t 3906.t 6031.t USD EUR 2158.t NA 0.1903 0.2052 0.1783 0.2067 0.0512 0.1000 0.0722 0.1856 0.3865 2389.t NA NA 0.3390 0.1757 0.3095 0.1119 0.0165 0.1152 0.1734 0.3016 3622.t NA NA NA 0.4475 0.5176 0.0075 0.4292 0.000 0.4111 0.3436 3655.t NA NA NA NA 0.3573 0.1658 0.0588 0.2883 0.3788 0.3345 3680.t NA NA NA NA NA 0.4028 0.0000 0.1194 0.5137 0.3224 3905.t NA NA NA NA NA NA 0.2567 0.2957 0.0000 0.2962 3906.t NA NA NA NA NA NA NA 0.0757 0.0000 0.3038 6031.t NA NA NA NA NA NA NA NA 0.0000 0.1499 USD NA NA NA NA NA NA NA NA NA 0.4524 EUR NA NA NA NA NA NA NA NA NA NA
mi.naive<-function (x,y) { m=length(x);n=length(y); if(m!=n)
stop("x and y must have equal length.") else {
z=table(x,y);
u<-apply(z,1,sum); v<-apply(z,2,sum); I<-length(u); J<-length(v);
S<-0;
for(i in 1:I) for(j in 1:J)if(z[i,j]>0){ S<-S+z[i,j]*log(z[i,j]*n/(u[i]*v[j])) }; return(S/n); } } mi.uai93<-function (x,y) { m=length(x);n=length(y); if(m!=n)
stop("x and y must have equal length.") else {
z=table(x,y);
u<-apply(z,1,sum); v<-apply(z,2,sum); I<-length(u); J<-length(v); K=I*J; S<-0;
k<-0; for(i in 1:I)for(h in 1:u[i])
{k<-k+1;S<-S+log((k-1+I*0.5)/(h-0.5));} k<-0; for(j in 1:J)for(h in 1:v[j]) {k<-k+1;S<-S+log((k-1+J*0.5)/(h-0.5));} k<-0; for(i in 1:I)for(j in 1:J) for(h in 1:z[i,j])if(z[I,j]>0) {k<-k+1;S<-S-log((k-1+K*0.5)/(h-0.5));} if (S<=0) return(0) else return (S/n); }
}
図 1: R パッケージ mi.correct の関数 mi.naive と mi.uai93
図 3: mi.uai93 は事後確率最大の森を生成するが、mi.naive は常に極大木を生成する