システム開発 19-F-12
経済活性化のための
技術用日本語プラットフォームの開発 に関するフィージビリティスタディ
報 告 書
平成20年3月
財団法人 機械システム振興協会 委託先 財団法人 日本特許情報機構
この事業は、競輪の補助金を受けて実施したものです。
http://ringring-keirin.jp/
序
わが国経済の安定成長への推進にあたり、機械情報産業をめぐる経済的、社 会的諸条件は急速な変化を見せており、社会生活における環境、都市、防災、
住宅、福祉、教育等、直面する問題の解決を図るためには技術開発力の強化に 加えて、多様化、高度化する社会的ニーズに適応する機械情報システムの研究 開発が必要であります。
このような社会情勢の変化に対応するため、財団法人機械システム振興協会 では、財団法人日本自転車振興会から機械工業振興資金の交付を受けて、シス テム技術開発調査研究事業、システム開発事業、新機械システム普及促進事業 を実施しております。
このうち、システム技術開発調査研究事業及びシステム開発事業については、
当協会に総合システム調査開発委員会(委員長:東京大学名誉教授 藤正 巖氏)
を設置し、同委員会のご指導のもとに推進しております。
本「経済活性化のための技術用日本語プラットフォームの開発に関するフィ ージビリティスタディ」は、上記事業の一環として、当協会が財団法人日本特 許情報機構に委託し、実施した成果をまとめたもので、関係諸分野の皆様方の お役に立てれば幸いであります。
平成20年3月
財団法人 機械システム振興協会
1990年代、インターネットが成長し、世界中の言語情報が流通するようになった。そし
て、2000年代に入るとWebサービスが爆発的な普及を見せている。こうしたなか世界の情報
は、英語をグローバルスタンダードとして動きつつあり、米国や欧州では、そのような状 況に向けた多くの対応が見られる。例えば、英語圏においては、とりわけ産業用ドキュメ ントの作成に用いられる英語を、そのあるがままに使用するのではなく、国際言語として 多民族(ノンネイティブ)が意思疎通できるように正確でわかり易くするための実践が行わ れてきた。例としては、キャタピラー社、IBM、ゼロックス、ジェネラルモーターズなどの 多国籍企業が、英文マニュアルを多言語に翻訳しやすくするために独自の制限英語を作っ ている。また、欧州と米国の航空業界は、メンテナンスマニュアルのためにSimplified Tech nical English(STE)を制定した。更に、機械翻訳システムに関しては、EU23カ国の言語 間のシステムが実用レベルで利用されている。
他方、わが国において、知的基盤となるのが日本語であることはいうまでもないが、日 本語テクニカルライティングに関しては、実践的な規定集が関連団体や企業で集積されて いるものの、いわば口述伝承のようなスキルに留まり、業界横断的な本格的な規格作りの 動きは見られない。したがって、企業の現場レベルで潜在的に高度なモノ作りの匠を保有 していたとしても、必須の英語によるコミュニケーション不足のために、とりわけ技術情 報の発信において、国際化が進まない状況がある。日本語をこのままの状況で放置してお けば、英語圏との情報ギャップが拡大する一方である。その対応策として、まずは人間の コミュニケーション能力の向上が挙げられる。しかし、併せて機械翻訳の品質と効率を高 めるため、原文に着目し、機械処理に適した産業用日本語をベースとしたドキュメント作 成を、普及促進することが、わが国の将来にとって喫緊の課題である。この点に関し、わ が国における日本語の解析、機械翻訳に関する自然言語処理技術は、世界的に最高の水準 にある。これらを有効に活かし、真に情報発信の国際化を進めることが、わが国の発展の ために欠かせない重要な取り組みである。
本スタディの報告書は、このような現状認識のもと、わが国経済の活性化、国際競争力 の強化に資する、インターネット時代に相応しい仕様の「技術用日本語」の普及促進を推 し進めるための技術用日本語プラットフォーム開発計画を、産業界に初めて示した画期的 なものである。このプラットフォームを通して、日本産業界に、標準となる日本語(技術 用日本語)が根付き、日本企業の国際競争力向上のための知的基盤強化の一助ともなれば 幸いである。
本スタディを実施するにあたり、財団法人機械システム振興協会のご高配に深謝すると ともに、本スタディにご協力いただいた関係各位に心から謝意を表する次第である。
平成20年3月
財団法人 日本特許情報機構
専務理事 兼 特許情報研究所 所長 寺本 義憲
序
はじめに
1 スタディの目的 ... 1
2 スタディの実施体制 ... 2
3 スタディの内容 ... 5
第 1 章 技術動向調査 ... 9
1.1 日本語の規格化の技術動向 ... 9
1.1.1 日本語に関する技術動向 ... 9
(1)日本語ワープロと校正・推敲支援 ... 9
(2)機械翻訳 ... 13
(3)文書検索 ... 17
(4)辞書サーバと言語資源 ... 24
(5)日本語の規範・規格 ... 42
(6)日本語テクニカルライティング ... 48
(7)外国人日本語教育のための日本語 ... 50
(8)法令日本語と数学日本語 ... 56
1.1.2 技術文書を代表する特許文書に関する技術動向 ... 59
(1)特許文書の構造と特性 ... 59
(2)特許文書における機械翻訳 ... 68
(3)特許文書における分類と検索 ... 73
(4)特許工学 ... 76
(5)特許請求項を対象とした言語処理 ... 83
(6)特許日本語ライティング ... 90
1.1.3 文書処理高度化のための CDL(概念記述言語)に関する技術動向 ... 101
(1)セマンティックコンピューティング ...101
(2)CDL ... 102
(3)CDL.core ... 104
(4)CDL.nl ... 104
(5)技術用日本語における CDL の役割 ... 105
1.1.4 文書制作高度化のためのセマンティックオーサリングに関する技術動向 .. 106
(1)セマンティックエディタ ... 106
(3)オーサリングの例題 ... 109
(4)支援機能 ... 111
1.2 海外技術調査 ... 112
1.2.1 総括 ... 112
1.2.2 制限英語 ... 114
(1)全体動向 ... 114
(2)Simplified Technical English ... 119
(3)Plain English ... 120
1.2.3 SEKT (Semantically Enabled Knowledge Technologies) ... 123
(1)概要 ... 123
(2) SEKT の3年間の成果 ... 124
(3)関連研究 ... 125
(4)CLOnE の書き方 ... 125
(5)実装 ... 127
(6)既存オントロジーの、CLOnE 入力解釈への利用 ... 130
(7)評価 ... 130
(8)進行中のプロジェクトと今後の課題 ... 131
1.2.4 ACE(Attempto Controlled English) ... 134
1.2.5 マインドマップ ... 156
(1)概要 ... 156
(2)12のルール ... 156
(3)ソフトウエア ... 156
1.2.6 コンセプトマップ ... 158
(1)概要 ... 158
(2)開発 ... 158
(3)使い方 ... 158
(4)マインドマップとの比較 ... 159
(5)ソフトウエア ... 159
(6)オントロジーとの相互変換 ... 159
(7)関連プロジェクト ... 162
1.2.7 海外の英語政策(アジアと欧州における英語教育の動向) ... 163
(1)アジア ... 163
(2)欧州 ... 164
1.2.8(付録)Nepomuk 論文要約 ... 165
第2章 開発課題の考察 ... 173
2.1 開発課題 ... 173
2.1.1 技術用日本語共通基盤仕様(第 0 版) ... 175
(1) 設計方針 ... 175
(2) 表現機構モデル ... 176
(3) 仕様の記述形式 ... 182
2.1.2 技術用日本語プラットフォームシステム ... 186
(1) 技術用日本語オーサリングシステム ... 186
(2) 技術用日本語言語知識集合知サーバ ... 193
2.1.3 技術用日本語アプリケーションシステム ... 198
(1) 技術用日本語日英機械翻訳システム ... 198
(2) 技術用日本語文書検索システム ... 205
2.2 開発スケジュールと開発体制 ... 211
2.2.1 開発スケジュール ... 211
2.2.2 開発体制 ... 214
第3章 技術用日本語の検証実験 ... 217
3.1 実験と結果 ... 218
3.1.1 技術用日本語暫定仕様の作成 ... 218
(1)CDL規則の策定 ... 218
(2)技術用日本語暫定仕様『暫定規則(23規則)』 ... 221
3.1.2 機械翻訳用規則による言い換えと評価 ... 225
3.1.3 セマンティックオーサリングによる言い換え ... 227
(1)基本仕様 ... 229
(2)セマンティックオーサリング使用における詳細仕様 ... 229
(3)談話関係などの詳細 ... 230
3.2 機械翻訳用規則による技術用日本語文言い換え実験詳細 ... 233
3.2.1 機械翻訳用規則(7規則) ... 233
(1)短文化:文の分割 ... 233
(2)短文化:箇条書きの利用 ... 235
(3)括弧書き(挿入句)の利用による基本構造の簡潔化 ... 236
(4)並列表現に伴って省略された用言、格助詞の補完 ... 237
(5)語句の関係の明確化 ... 239
(6)動作の結果を表す「もの」の具体化 ... 241
(7)意味の多様な「する」「なる」を含む表現の言い換え ... 242
3.2.2 実験の流れ ... 243
3.2.3 実験データ ... 245
(1)機械翻訳の観点での技術用日本語に対する機械翻訳実験 ... 245
(2)専門家による評価対象 ... 246
3.2.4 技術用日本語変換 ... 247
3.2.5 評価 ... 248
(1)評価者 ... 248
(2)日本語の評価基準 ... 248
(3)英語の評価基準 ... 249
3.3 結果詳細 ... 252
3.3.1 評価シート ... 252
(1)日本語評価シート ... 252
(2)英語評価シート ... 253
3.3.2 評価集計表 ... 254
3.3.3 人にとっての読解容易性 ... 257
3.3.4 コンピュータにとってのわかりやすさ ... 259
3.3.5 課題 ... 261
第4章 市場調査・事業シミュレーション ... 265
4.1 日本の知的生産性の飛躍的向上 ... 265
4.1.1 技術用日本語の適用による効果 ... 265
4.1.2 技術用日本語の適用の対象 ... 268
(1) 創造ステップにおける産業技術文書 ... 268
(2) 保護ステップにおける産業技術文書 ... 268
(3) 活用ステップにおける産業技術文書 ... 269
(4) ステップ間の文書の循環と再利用 ... 270
4.1.3 主な産業技術文書の市場規模と経済的効果 ... 271
(1) 特許文書の市場規模と経済効果 ... 271
(2) その他の産業技術文書の市場規模と経済効果 ... 273
4.2. モデルサービス ... 276
4.2.1 先進的知識マネジメント ... 276
4.2.2 技術用日本語文書の作成支援 -知財サイクルのワンストップサービス ... 278
4 スタディの成果(まとめ) ... 281
4.1 技術動向調査 ... 281
4.1.1 日本語の規格化の技術動向 ... 282
(1)日本語に関する技術動向 ... 282
(2)技術文書を代表する特許文書に関する技術動向 ... 283
(3)文書処理高度化のためのCDL(概念記述言語)に関する技術動向 ... 285
(4)文書制作高度化のためのセマンティックオーサリングに関する技術動向 ... 286
4.1.2 海外技術調査 ... 286
(1)制限英語 ... 286
(2)グラフィック形式 ... 287
(3)英語教育政策 ... 287
4.2 開発課題の考察 ... 288
4.2.1 技術用日本語共通基盤仕様(第 0 版) ... 288
(1)設計目標 ... 289
(2)表現機構モデル ... 289
(3)仕様の記述形式 ... 289
4.2.2 技術用日本語プラットフォームシステム ... 289
(1)技術用日本語オーサリングシステム ... 289
(2)技術用日本語言語知識集合知サーバ ... 290
4.2.3 技術用日本語アプリケーションシステム ... 290
(1)技術用日本語日英機械翻訳システム ... 290
(2)技術用日本語文書検索システム ... 290
4.3 技術用日本語の検証実験 ... 290
4.4 市場調査、事業シミュレーション ... 291
4.4.1 技術用日本語の適用対象と効果 ... 292
4.4.2 市場規模と経済的効果 ... 292
4.4.3 予測されるサービス事業展開 ... 293
4.5 まとめ ... 293
5 スタディの今後の課題及び展開 ... 295
5.1 実験ツールによる技術検証 ... 295
5.2 知識検索及び要約生成への技術用日本語の応用に係る考察 ... 295
5.3 プロジェクト計画の策定調査 ... 296
英語圏においては、1978年カータ米国大統領令によってPlain Englishが奨励され、そ れが法律、金融、公共の場面に広く浸透し、産業、商業用文書の作成に用いられる英語に 関しても正確でわかり易くするための実践が行われてきている。
しかし、わが国において紛れもなく知識基盤となっている日本語については、業界横断 的なそうした取り組みは見られず、技術情報の発信において、国際化が進まず、資源とし ての言語の活用も遅れ、英語圏との情報ギャップが拡大する一方である。
その一方で、わが国における日本語の解析、機械翻訳に関する自然言語処理技術は、世 界最高水準にあり、こうした技術の活用は、英語圏におけるテクニカルライティングの水 準を超える可能性を秘めている。
このような状況下、経済の活性化、国際競争力の強化のために、産業用ドキュメントの 作成に用いる日本語をインターネット時代に適応した仕様の日本語、すなわち「技術用日 本語」に変革することが一つの解決策になると考えている。
しかし、そうした技術用日本語の必要性を提唱するだけでは、状況の改善がなされない。
そこで、技術用日本語導入を実践的かつ具体的に進めるため、実際に技術用日本語プラ ットフォームを開発し、そのプラットフォームを浸透させる活動を通じて、日本産業界に 技術用日本語を根付かせ、わが国の知識基盤の強化を図ることを最終目標とする。
「技術用日本語プラットフォーム」とは、技術用日本語を扱うための基盤システムであ り、①技術用日本語プラットフォームシステム及び②技術用日本語アプリケーションシス テムからなる。まず、①技術用日本語プラットフォームシステムとしては、技術用日本語 の辞書データベースからなる「技術用日本語文書作成集合知サーバ」を基本モジュールと して、その上に、技術用日本語を作成支援するためのワードプロセッサ的役割を果たす「技 術用日本語オーサリングシステム」が載る。そして、②技術用日本語アプリケーションシ ステムとして、「技術用日本語日英機械翻訳システム」と、概念表現レベルでの構造検索を 可能にする「技術用日本語文書検索システム」が加わる。
こうした「技術用日本語プラットフォーム」をベースとして、将来的には、中小ベンチ ャー企業用海外ビジネスドキュメント作成支援システム、TLO用外国出願作成支援システム などの個別の技術用日本語アプリケーション/サービスの開発・提供も想定される。
本スタディは、上記①及び②の両システムの最も基本となる「技術用日本語共通基盤」
を含む、これらのシステム自体を対象とする基本的な「開発計画」を立案することを目的 とする。
また、インターネット時代の技術用日本語の必要性を確認しつつ、技術用日本語を用い た文書処理の高度化、高精度化、高能率化によりもたらされる経済活動の活性化の形態を、
その波及効果及び事業展開の具体的イメージを示すことで明らかにし、更に、技術用日本 語導入による効果を、実験を通じて検証することも目的としている。
本スタディの実施体制として、図1に示すとおり、(財)機械システム振興協会内に総合 システム調査開発委員会を、また(財)日本特許情報機構内に、技術用日本語プラットフ ォーム委員会を設置した。そして各作業は、技術用日本語プラットフォーム委員会での審 議を経て着手し、その結果を委員会で審議した。業務分担として、開発課題の考察につい ては、技術用日本語プラットフォーム委員会の主導で実施し、一部のサブシステム(概念 構造検索系、辞書サーバ、技術用日本語共通基盤仕様、日本語処理系)の検討は再委託し た。
図1:委託事業実施体制 再委託先:
・東京大学大学院情報理工学系研究科・石塚研究室 ・慶應義塾大学環境情報学部・石崎研究室
・特定非営利活動法人セマンティック・コンピューティング研究開発機構 (ISeC) ・東芝ソリューション株式会社
財団法人 日本特許情報機構 特許情報研究所
[技術用日本語プラットフォーム委員会]
委員長:橋田 浩一 (独)産業技術総合研究所 情報技術研究部門 部門長
委 員:大学研究者、企業研究者、有識者
(16名)
再 委 託
財団法人 機械システム振興協会 総合システム調査開発委員会
委 託
(順不同・敬称略)
委員長 東京大学 藤 正 巖 名誉教授
委 員 埼玉大学 総合研究機構 太 田 公 廣 地域共同研究センター
教授
委 員 独立行政法人産業技術総合研究所 金 丸 正 剛 エレクトロニクス研究部門
副研究部門長
委 員 独立行政法人産業技術総合研究所 志 村 洋 文 産学官連携推進部門
産学官連携コーディネータ
委 員 東北大学大学院 中 島 一 郎 工学研究科 教授
(未来科学技術共同研究センター長)
委 員 東京工業大学大学院 廣 田 薫 総合理工学研究科
教授
委 員 東京大学大学院 藤 岡 健 彦 工学系研究科
准教授
委 員 東京大学大学院 大 和 裕 幸 新領域創成科学研究科
教授(副研究科長)
(順不同・敬称略)
委員長 独立行政法人産業技術総合研究所
情報技術研究部門 部門長 橋 田 浩 一 副委員長 東京工科大学
メディア学部 教授 横 井 俊 夫
委 員 東京大学大学院
情報理工学系研究科 教授 石 塚 満 委 員 慶應義塾大学
環境情報学部 教授 石 崎 俊
委 員 名古屋大学大学院文学研究科
研究科長 町 田 健
委 員 独立行政法人国立国語研究所
研究開発部門言語資源グループ グループ長 山 崎 誠 委 員 IRD国際特許事務所
所長・弁理士 谷 川 英 和
委 員 トヨタ自動車株式会社
知的財産部 企画統括室 主幹 弁理士 佐 野 夏 茂 委 員 キヤノン株式会社
知的財産法務本部 副本部長 大 野 茂 委 員 (株)富士通研究所
ソフトウェア&ソリューション研究所 主管研究員 潮 田 明 委 員 (株)日立製作所
システム開発研究所uValueイノベーションセンタ 主任研究員 間 瀬 久 雄 委 員 (株)三菱総合研究所
情報技術研究センター 主席研究員 白 井 康 之 委 員 (株)ジャストシステム
イノベーションテクノロジー研究開発部 荒 川 直 哉 委 員 (株)日本システムアプリケーション
顧問 荻 野 孝 野
委 員 (株)東芝
研究開発センター知識メディアラボラトリー 主任研究員 熊 野 明 事務局 (財)日本特許情報機構
専務理事 兼 特許情報研究所 所長 寺 本 義 憲 事務局 (財)日本特許情報機構
特許情報研究所 調査研究部長 奥 直 也 事務局 (財)日本特許情報機構
特許情報研究所 企画調査課長 大 塩 只 明
本スタディの内容は、以下のとおりであり、グローバルな経済活動を行う企業にとって 技術用日本語プラットフォームが有効であることを検証している。そして、全体として、
技術用日本語プラットフォーム開発のための基本的な計画を提案するものとなっている。
(1)技術動向調査
技術用日本語プラットフォームの開発に資する、わが国における日本語への取り組みや 有用技術を把握するために行った、関係者へのヒアリングや文献調査の結果をまとめた。
(2)開発課題の考察
開発課題として、技術用日本語共通基盤仕様、技術用日本語プラットフォームシステム 及び技術用日本語アプリケーションシステムに関する検討を行い、基本的な開発スケジュ ールをまとめた。
(3)技術用日本語の検証実験
技術用日本語文の作成と評価分析に不可欠な3つの実験を行った。一つは技術用日本語 暫定仕様を作成すること、二つ目は既存の文章を、技術用日本語暫定仕様に基づき手作業 で変換して技術用日本語を作成し、原文と比べて、正確性、読解容易性、そして機械にと っても理解しやすい日本語であるかの観点で評価すること、3つ目は技術用日本語文とグ ラフィカル表示を結びつけるセマンティックオーサリングによる言い換え実験である。
(4)市場調査、事業シミュレーション
知的生産性の向上及び経済活性化の観点から、国内グローバル企業などへのヒアリング 結果などに基づき、経済効果及び事業展開のイメージをまとめた。
第 1 章 技術動向調査
第 1 章 技術動向調査
1.1 日本語の規格化の技術動向 1.1.1 日本語に関する技術動向
(1)日本語ワープロと校正・推敲支援
主にパソコン上で動作する日本語ワードプロセッサープログラム(以下日本語ワープロ)
の機能としての校正・推敲支援機能について検討を行った。校正・推敲支援機能は、文章 を自動的にチェックする校正支援機能と、共同作業としての推敲を支援する機能に大別さ れる。以下では、市販の日本語ワープロ([JS 07], [MS 03]など)に実装されている機能を 中心に検討結果を説明する。
① 校正支援機能
ここでは主に、日本語の文章を自動的にチェックし、誤りなどを指摘する機能について 述べる。機能分類としては、誤りの指摘、避けた方がよいと思われる表現の指摘、表現の 統制、読みやすさの評価を挙げることができる。チェック項目は、ユーザ設定あるいは文 体の設定により取捨選択することができる。
• 誤り(候補)の指摘 o 誤字脱字の指摘
助詞の欠落(例:「会議終わった」)、未登録語(解析用の辞書にない文字列を指 摘~必ずしも誤りではない)、よくある誤りの指摘(例:「斡施→斡旋」)など o 同音語誤りの指摘(例:「人口知能」)
o 仮名遣いの誤り、旧仮名遣いの指摘(例:「通常どうり→通常どおり」)
o 慣用表現のよくある誤りの指摘(例:「的を得る→当を得る/的を射る」)
o 不適切な呼応の指摘(例:「ちっともおもしろい」、「決して遅刻する」)
o ら抜き表現の指摘(例:「食べれる」)
o さ入れ表現の指摘(例:「終わらさせていただく」)
o 二重敬語の指摘(例:「おっしゃられる」)
o 送り仮名のチェック
「文部省公用文送り仮名用例集」や昭和 56 年内閣告示の「送り仮名の付け方」のよ うな規則に準拠しているかどうかをチェックする。
o 助詞関連の指摘
助詞の連続(例:「のの」、「とを」)や「たり」の欠落などを指摘する。
• 避けた方がよいと思われる表現の指摘
o 重ね言葉の指摘(例:「およそ1時間ほど」)
o 曖昧な表現の指摘
構文的な曖昧さをもたらすような修飾関係(例:「白いカゴの中の小鳥」)あるい は並列関係(例:「太郎及び花子または次郎」)を指摘する。
o 当て字の言い換え(例:「倶楽部 → クラブ」)
o 難しい語の言い換え(例:「橋梁→橋」)
o 差別語の言い換え(例:「ジプシー→ロマ」)
o これらの他:「が、」の多用、連用中止形の多用、二重否定、文語調、受動態など の指摘を行う。また、商標・商品名を指摘する機能も用いられている。
• 表現の統制 o 文体の統制
「です/ます」体対「だ/である」体の統制を行うほか、通常の文、公用文、くだ けた文などの文体ごとに異なるチェックを行う機能を持つ。
o 文字の統制
常用漢字以外の漢字、当用漢字以外の漢字、旧字体、機種依存文字などの使用を指 摘する。
o 読みの統制
常用漢字表などに準拠していない読みを指摘する。
o 公用文表記統制
昭和 56 年 12 月「文部省用字用語例」(昭和 56 年 10 月内閣告示の「公用文におけ る漢字使用などについて」に基づくチェックを行う。
o 半角/半角の統制
一律に半角を用いる、あるいは全角を用いるという統制(指摘)を行う。
o 表記揺れ(カタカナ、送り仮名、漢字/仮名、数字、全角/半角)の統制 o 句読点の統制
例えば句点に「。」を用いるか「.」を用いるかなどの統制を行う。
o 変更された名称の指摘(例:「田無市→西東京市」)
• 読みやすさの評価
使用されている表現の難しさのレベルや、文の長さなどについて指摘したり、統計を 提示したりする。表現の難しさとしては、漢字の難しさや単語の難しさ(例えば義務 教育での各学年で教える漢字、単語などを参考にして判別する)を用いる。統計とし ては、文字数、語数、文の数、段落数の合計や、1 段落中の平均文数、平均文長、句点 の間平均文字数などを指摘する。また、使用される文字種(漢字、ひらがな、カタカ ナ、アルファベットなど)ごとの割合を提示する。
• 多言語校正
日本語ワープロにも、日本語以外の言語の校正支援機能(英語の場合、スペルチェッ ク、ハイフネーション機能など)を持つものがある。ここでは詳細は割愛する。
• その他の便利な機能
各種辞書を検索する機能などを持つものがある。
② 推敲支援機能
専用の添削(赤入れ)機能や、コメント(付箋)機能、変更履歴の記録機能を用いて 複数作業者による共同推敲作業を支援することができる。
③ 日本語ワープロ以外の校正支援システム
パソコン上の日本語ワープロ以外に、独立的に動作するパソコン用校正支援プログラム
([JS2005][GKK1989])や作文小論文の自動採点ソフト([森リン 08][石岡 07][石岡 08])、新聞社などの社内で使用される専用の校正支援システム([脇田 92][松井 96][池 原 93])などが存在している。校正支援機能は、日本語を原文とする機械翻訳システム で、原文を機械翻訳にかかりやすくするためにも用いられている([祖 07])。
④ 校正・推敲支援機能と技術用日本語作成支援
明晰化が曖昧性の除去にあるとすれば、明晰化のために特に役立つと考えられる機能は、
曖昧な表現を指摘する機能(上記)であろう。例えば[祖 07]のシステムでは、「上記の 通り」という表現を「3ページの2行目にある通り」などと書くように指示を行う(日 経産業新聞の記事による)。また、明晰化支援システムの機能として、構文的な曖昧性 を(市販の校正支援システムより)適確に指摘できるような機能を実装することも考え られる。
⑤ 日本語ワープロの現状と今後
既存の市販(日本語)ワープロの機能は(細かい改善を除くと)ほぼ完成形に近いもの となっており、ここ数年大きな変化は起きていない。今後については、以下のような革 新を期待することができる。
• 構造化文書の編集
(現行のアウトライン編集機能に加え)文章の要素や要素間の関係が明確に意味づけ されているような構造化文書を編集する機能の実現が期待される。こうした文書は、
構造的に「明晰」であり、機械処理や可視化が容易になるためである。セマンティッ クオーサリング(第 4 章参照)は、こうした構造化文書編集機能の一つの実現形であ る。(構造化文書は、CDL(第 3 章参照)や XML、RDF などの構造化文書形式により保 存・交換される。)
• 構文解析の利用
多くの日本語ワープロは、校正支援において、単語レベルの解析とパターンマッチン グのみを用いている。一方、文内の論理構造の明晰化を支援するためには、構文的な 構造を処理できることが望ましい。一般のテキストから構文的な構造を自動的に誤り なく解析することは困難であるが、ユーザと対話的に解析を行うことにより、誤りを なくすことが考えられる。こうした対話的な解析は、テキスト入力時に行うことで作 業効率を高めることができる。対話的に多義性を除去した構文解析結果は、次のよう な目的で使用することができる。
o 文法的な誤りの指摘
「てにをは」の間違いなどをより適確に指摘する。
o 矛盾の指摘
構文構造から論理的な構造を抽出することにより、矛盾を指摘する。
o 明晰化支援
構文的な多義性を対話的に除去した解析結果を、より明晰な文章に自動的または対 話的に変換する。
o 翻訳支援
多義性の除去された構文解析結果からの翻訳は品質の高いものになる。
• 修辞支援
英語圏では、適切な修辞によりテキストを書くことを支援するソフトウェアが製品化 されている(キーワード「software for writers」などで Web 検索、[奥出 89])。日 本語を明晰化するために、日本語ワープロにも修辞支援機能の導入が望まれる。なお、
文書の意味的な構造化及び構文的な解析(上記)から得られる情報は、修辞支援にも 利用することができる。
[ 参考資料 ]
[JS 07] 一太郎2007(製品名), 株)ジャストシステム (2007).
[MS 03] Microsoft Office Word 2003(製品名), Microsoft Corporation (2003).
[JS 05] Just Right! (製品名), 株)ジャストシステム (2005).
[GKK 89] 校閲/推敲支援システム, 株)言語工学研究所(1989):
http://www.gengokk.co.jp/kouetsu.htm
[森リン 08] 作文小論文の自動採点ソフト(Web上のサービス),森リン(2008):
http://www.mori7.info/moririn/moririn1200.php
[石岡 07] コンピューターによる小論文の自動採点について, 石岡恒憲, 教育テスト研究センター第3回研究報告書(2007):
http://www.cret.or.jp/j/report/070720_Ishioka_report.pdf [石岡 08] 小論文及びエッセイの自動評価採点における研究動向,
石岡恒憲, 人工知能学会誌, Vol. 23 No.1, pp. 17-24(2008).
[脇田 92] 日本語校正支援システムFleCS, 脇田早紀子 et al., 第45回情報処理学会全国 大会, No.3, pp. 149-150, (1992)
[松井 96] 日本語校正支援システム(Joyner)の研究について(3), 松井 et al., 第52回情報 処理学会全国大会, No. 3, 2J-4 (pp.283-284), (1996).
[池原 93] 文書校正支援システムにおける自然言語処理, 池原 et al., 情報処理 Vol. 34 No. 10, pp. 1249-1258 (1993).
[祖 07] 中国でのオフショア仕様書チェックシステム, 祖国威, 東芝レビュー Vol. 62 No. 1, pp. 70-71 (2007):
http://www.toshiba.co.jp/tech/review/2007/01/62_01pdf/rd02.pdf
(cf. 「文脈解析する校正システム」日経産業新聞 2007年10月12日)
[奥出 89] コンピュータ上のソクラテス―Thoughtlineを使う, 奥出直人, 現代思想, Vol. 17 No. 7 (6月号) (1989).
(2)機械翻訳
機械翻訳の方式や現状、翻訳精度向上に向けての課題等の観点から検討を行った。
① 機械翻訳精度向上の必要性
今日、世界中の言語で書かれた情報がインターネットで参照可能となり、業務上の目的 や個人的な興味のため日本語以外の言語で書かれた情報に接する機会が多くなってきた。
例えば、有力な検索エンジン Google 、Yahoo は英語・中国語・韓国語などから→日本 語及び日本語から英語などへの機械翻訳をサービスしており、全く知らない言語からの情 報取得に有用である。
このように実用的に利用され始めた機械翻訳であるが機械翻訳結果のレベルはどうだろ うか。アジア太平洋機械翻訳協会(AAMT)の調査によると英語のテストを行うときに機械 翻訳結果を見せた場合と見せない場合、英語能力が中位レベル以下の人は成績が上がり、
上位レベルの人は変化が少ないという相関関係を得た。これは機械翻訳の恩恵を受けるの はその言語に詳しくない人に限られるという機械翻訳の現状を示している。
機械翻訳は1980年代に本格的な技術開発が始まり、多大な投資が行われてきたが残 念ながら未だ完成の閾には達していない。これは自然言語の柔軟性に機械翻訳技術が追い ついていないためである。技術用日本語という機械に理解しやすい日本語を使うことで、
入力文の解析が正確になり飛躍的に機械翻訳精度が高まることが期待できる。これは機械 翻訳の恩恵を受ける人の範囲の拡大につながる。
② 機械翻訳の方式
機械翻訳は入力した言語を翻訳して出力する。機械翻訳の方式は規則ベース・統計ベー ス・用例ベースがある。これら3つの方式について簡単に説明する。
a.規則ベース機械翻訳
規則ベースの機械翻訳は下記の工程で行う。各工程は人手によりあらかじめ定義された 複数の規則を持っており、前の工程から引き継いだ情報を規則と照らし合わせて、最も適 合した規則にしたがって変換した結果を次の工程へ渡し、最終的に出力言語に変換する。
a. 入力文を形態素(単語など)に分割する b. 入力文の構文を解析する
c. 入力文の意味を解析する
d. 入力文の各形態素を出力の言語に変換する e. 出力言語の構文構造に変換する
f. 出力言語の形態素構造を生成する
多くの商用機械翻訳システムは規則ベースを基本としている。
b.統計ベース機械翻訳
統計ベース機械翻訳は入力言語と出力言語の大量の対訳文を必要とする。統計ベース機 械翻訳は翻訳の準備として大量の入力言語と出力言語の対訳文を統計的に処理して翻訳モ
デルを作成する。この翻訳モデルは統計的に最も尤もらしい単語・フレーズ・文などの単 位で対訳を格納した一種のデータベースである。
翻訳時、入力文で翻訳モデルを検索して、最も尤もらしい組み合わせで結果を返す。結 果的に入力言語に対応する出力言語が得られる。
大量の対訳があれば、人手をかけて規則を作成する必要が無く、短時間でそれなりの機 械翻訳システムを作成することが可能である。単語とフレーズ単位で良い翻訳を行うため、
近縁の言語間では比較的良い翻訳結果が得られる。しかし、日本語と英語の様な語順が異 なる言語間の翻訳では適切な文にならないことが多い。
c.用例ベース機械翻訳
あらかじめ対訳を蓄積して用例とする。入力文の単語や構文解析結果をもとに最も類似 した用例を選択し、変化部分を翻訳する。機械翻訳ユーザにとって規則の追加は難しいが 用例の追加は可能なため、規則ベース機械翻訳と組み合わせて使われることがある。
③ 機械翻訳の現状
日本の特許庁が日本の特許情報を外国の審査官にオンラインで英語に機械翻訳して提供 していることを例に機械翻訳の現状を説明する。このサービスは「高度産業財産ネットワ ーク(AIPN: Advanced Industrial Property Network)」というサービスで、海外の特許 庁の審査官が、日本の特許明細書や手続き書類を機械翻訳による英訳で参照できる。これ により、既に日本で出願された技術と同じ技術が外国で第三者によって取得されることを 防止することや我が国の出願人の海外への特許出願についての権利取得の迅速化が期待さ れる。なお、この機械翻訳機能は規則ベースの商用機械翻訳エンジンをカスタマイズした ものが利用されている。 審査官が翻訳対象を指定した後は全自動で機械翻訳される。
このAIPNを利用した感想を欧州特許庁(EPO: European Patent Office) の審査官に ヒアリングした結果が機械翻訳結果利用の現状を良く示しているので引用する。
質問:どの様な場面で機械翻訳を利用するのか。
EPO:日本で技術開発が進んでいる分野の特許審査で利用する。例えばDVD関連など。
質問:機械翻訳を利用するまでの流れを教えて欲しい。
EPO:検索した特許の人手で英訳された発明の名称と要約で概要を理解する。
その中から該当しそうな文献を見つけた、明細書全文を機械翻訳する。
機械翻訳中のキーワードを見て人手翻訳を依頼するかどうかを判断する。
質問:機械翻訳で改善すべきことは何か。
EPO:辞書のさらなる充実。
このことは、AIPN の機械翻訳結果は単語レベルでは良く訳されていることを示すと同 時に機械翻訳結果を読んで内容を理解することが難しいことを示している。
④ 機械翻訳精度の向上
市販の規則ベースの機械翻訳システムで翻訳精度を向上させる方法を整理する。規則ベ ースの機械翻訳システムではユーザが辞書に対訳を追加することで単語レベルの翻訳精度 向上が可能である。
・ 辞書の優先順位設定
機械翻訳システムが利用する辞書の順番が指定できるので、適切な分野の辞書を優 先的に使うように設定する。
・ 訳語の選択
対話的に機械翻訳を実行する場合に利用する。複数の意味を持つ用語から今回の文 章で利用する訳語を選択すると学習機能が働き、次回の翻訳からその用語が最初に選 択される機能。規則ベース機械翻訳のステップ 「d. 入力文の各形態素を出力の言語 に変換」を制御する。
・ 辞書の追加
辞書にない用語や適切な訳のない用語を辞書に登録する。次回の翻訳からその用語 が使われる。規則ベース機械翻訳のステップ 「b. 入力文の構文を解析」~「d. 入力 文の各形態素を出力の言語に変換」に関係する。
・ パターン辞書の追加
「文献3の 5 行目」の表現が多く現れる場合は、「文献<変数 1>の<変数2>行 目」の様にパターンで辞書登録可能である。
・ 用例の追加
本機能は規則ベース機械翻訳に「用例ベース機械翻訳」を加えたものである。適用 方法は各社が工夫している。基本的には自動翻訳時は文全体が完全に一致した場合に 対訳が採用され、対話的に実行する場合は類似した文と対訳が参考として一致度順に 表示される。
辞書以外に機械翻訳の精度向上させる方法は前編集と規則の追加があるが、前編集はコ ストと時間を要する上に自動翻訳的な使い方では適用できず、規則の追加はユーザには難 しい。
・ 人手による前編集
機械翻訳システムの推奨にしたがって入力文を短くする、括弧による係り受けを明 示するなど、機械翻訳の規則に適合させるための人手作業を行う。
機械翻訳システムのマニュアルにしたがって作業することになるが、ユーザにとっ て機械翻訳の規則がブラックボックス化していることもあり、文法チェックなど機械 の支援無しに前編集するのは難しく、現実的には機械翻訳された結果を確認しながら、
入力文を編集・修正する作業になってしまう。
・ 規則の追加
分野により特有の表現が使われる場合、機械翻訳システムに規則を追加して対応す
る。その際、既にうまく翻訳されている文が新しく追加した規則に適合してしまい、
誤訳となるなど、副作用の管理が必要で規則の追加は容易でない。
更に、機械翻訳に既に組み込まれている規則及び副作用を検証するためのデータは ユーザに開示されないため、ユーザが規則を追加することは難しい。
⑤ 技術用日本語と機械翻訳
技術用日本語が広くユーザに受け入れられ、更に技術用日本語の規則が機械翻訳システ ムに組み込まれた場合、下記の理由で機械翻訳の精度向上が期待できる。
1. 前編集不要:技術用日本語で書かれた文書そのものが前編集済みの文となる 2. 規則の開示:技術用日本語用の規則がユーザに開示された機械翻訳規則となる
技術用日本語という規則を人間と機械翻訳が共有することで、文の作成基準が明確とな ると共に、入力文の解析が正確になり飛躍的に機械翻訳精度が高まることが期待できる。
これは機械翻訳の恩恵を受ける人の利用範囲の拡大と共に機械翻訳の適用範囲の拡大につ ながる。技術用日本語が機械翻訳の精度を向上させることを期待する。
(3)文書検索
テキスト情報を含む大量の文書集合の中から、利用者が必要とする文書を検索する文書 検索システムの技術動向と、文書検索精度向上の観点から検討を行い、技術用日本語への 期待と課題をまとめた。
① 文書検索の定義と社会的位置付け
「情報検索」は本来、「利用者の抱える問題を解決できる情報を探し出すこと」をさす。
しかし、この言葉を「利用者の検索要求に適合する文書を文書集合の中から探し出すこと」
という狭義の意味として捉えるようになり、これを「文書検索」と呼ぶようになった。
1990年代以降、インターネット及びWebブラウザの普及と、パソコン上で動作する文 書エディタの普及により、我々は様々な文書情報を手軽に発信・閲覧できるようになった。
しかし一方で、自分が必要とする文書を探すのに、多大な時間と労力を費やさなければな らなくなった。
1990年代後半に普及したGoogleやYahoo!をはじめとするWeb検索エンジンは、文書 を探す作業の効率を飛躍的に向上させた。これらのシステムは、今や我々の生活に欠かせ ない道具となっている。
現在の文書検索システムでは、「キーワードの組み合わせからなる論理演算式を満たす 文書を出力する」という検索方式が主流である。また、検索したい内容を自然言語文で入 力して検索する「概念検索(連想検索)」という検索方式も普及してきている。
しかし、いずれの検索方式においても、文章の表層レベルでの検索にとどまっているた め、検索精度に限界が生じている。特に、同じ意味だが表記の異なる同義語・異表記語や、
同じ表記だが意味や使われる文脈が異なる多義語の存在は、検索精度を低下させる大きな 原因となっている。これらの原因による精度低下を防ぎ、人間の直感により近い検索を実 現することが、次世代の文書検索システムに課せられた大きな技術課題である。
② 検索対象となる文書の分類と特性
文書検索の技術動向を調査するにあたって、検索対象となる文書の種類とその特性を整 理しておくことは有用である。我々が日常アクセスしている文書とその特性を表 1.1.1-1 にまとめる。表1では、検索精度に影響を及ぼす特性として以下の5種類を挙げ、比較し ている。
a.文書の構造化の度合い
文書中のどこに何が記載されているかを特定できるかに関する特性である。構造化の度 合いが高い文書の場合、所望の情報を検索する際に、特定の記載個所を検索対象とするこ とにより、検索精度を向上できる。例えば、「ある発明課題に関する特許を検索する際に は、【発明が解決しようとする課題】タグに記載された文章のみを検索対象とすれば良い」
といった具合である。
b.文書の執筆に係る制約
文書の執筆者の不特定性や、使用する語彙・構文に係る制約に関する特性である。日記
# 文書種別 構造化度 文書執筆の制約 一文書の長さ 語調 検索目的 01 特許 明細書
タグあり
請求項の構成に 若干の制約あり
長い
ばらつきあり
書き 言葉
公知例調査、
技術動向分析 02 論文 論理構造
あり 特になし 長い 書き
言葉 技術動向分析 03 ニュース文・
新聞記事
5W1H
で構成 語彙の統一 短い 書き 言葉
トピックス情報 の収集
04 法律文 定型構文 語彙・構文の 統一
長い
ばらつきあり
書き 言葉
法律の内容理解 旧法律との差分 05 設計書 記載項目
あり 特になし 長い
ばらつきあり
書き
言葉 設計仕様の理解 06 議事録 記載項目
あり 特になし 短い 書き
言葉
結論と根拠理解 発言者の特定 07 マニュアル なし 誤解を与えない
語彙の使用
長い
ばらつきあり
書き 言葉
正しい操作方法 の理解
08 辞典・事典 見出しと
内容 特になし 短い 書き 言葉
言葉の意味の 調査
09 チャット なし 特になし 短い 話し 言葉
情報収集 マーケティング 10 宣伝・広告 なし 特になし 短い 混在 製品・サービス
情報の収集 11 日記(ブログ) なし 特になし 短い 混在 マーケティング
トレンド分析 12 クレーム・
アンケート なし 特になし 短い 混在 マーケティング トレンド分析 13 手紙(メール) なし 特になし 短い 混在 やりとり内容と
その時系列変化 14 問合せ
(Q&A)
質問と
その回答 特になし 短い 混在 質問に対する 適切な回答取得 表 1.1.1-1 文書検索で扱われる文書とその特性
やチャットのように、誰でも自由な形式で執筆できる文書の場合、使用される語彙や構文 のバリエーションが増えるので、検索漏れが生じやすくなる。一方、法律文書や新聞記事 のように、文章を書く教育を受けた人が、特定の制約のもとで執筆する文書の場合、使用 できる語彙や構文は制限されるので、検索精度は比較的高くなる。
c.一文書の長さとそのばらつき
一つの文書がどのくらいの長さの文章で書かれているかに関する特性である。文章長の ばらつきが激しい文書集合を検索する場合、キーワードの出現頻度に基づく検索方式では、
文章の長い文書ほど検索されやすくなるため、検索精度に悪影響を及ぼすことが多い。
d.語調
文章が話し言葉であるか書き言葉であるかに関する特性である。現在普及している日本 語解析ツールのほとんどは、書き言葉を対象としているものである。そのため、話し言葉 による文章の解析精度は、書き言葉による文章に比べて悪く、その分、検索精度にも悪影 響を及ぼす。
e.検索目的
その文書集合をどのような目的で検索するかに関する特性である。検索目的が異なれば、
最適な検索方式も必然的に異なるはずである。例えば、「発明の課題が類似する特許」を 検索する場合と、「発明の実現方法が類似する特許」を検索する場合とでは、着目する記 載個所や使用するキーワード、検索結果の順位付け方法などは、変わってくるであろう。
このように、我々の周りには、特性の異なる様々な文書が混在している。したがって、
文書検索精度を向上させるためには、検索対象とする文書の特性を最大限に活用する必要 がある。
③ 文書検索の技術動向
まず、文書検索に関係する国内の研究プロジェクトについて概観する。
2000年代になり、文書検索に関係する研究プロジェクトが、政府主導でいくつか推進さ れてきている。文部科学省の科学研究費補助金(科研費)による研究プロジェクト「ITの 深化の基礎を拓く情報学研究(2001-2005)」、及び、これに続く「情報爆発時代に向け た新しいIT基盤技術の研究(2006-2010)」では、情報の管理・融合・活用の観点から、
必要とする情報を、効率良くかつ偏りなく安心して取り出す技術の研究が進められている。
経済産業省が推進している「情報大航海プロジェクト(2007-2009)」では、多種多様 な情報の中から必要な情報を的確に検索・解析するための「次世代検索・解析技術」を開 発している。そして、それらを用いた先進的な事業について実証することにより、技術の 普及・展開を図ろうとしている。
国立情報学研究所(NII)では、情報検索を含むテキスト処理技術の研究の更なる発展 を図るワークショップ型共同研究NTCIRを1997年より約1年半おきに開催してきてい る。大規模かつ再利用可能なテストコレクションの構築と、研究者フォーラムの展開、情 報アクセス技術の評価手法及び評価指標に関する研究の推進を目的としている。特許検索 や質問応答、多言語検索などのタスクを展開するとともに、文書データを含む実験評価環 境を提供している。
次に、現在の文書検索技術のトレンドについて述べる。文書検索技術は広範囲にわたる ので、ここでは、以下の8つの観点に絞って概観する。
a.概念検索/連想検索
概念検索(自然言語文検索)は、検索条件を自然言語文で入力する検索である。特に、
文書そのものを入力とする場合、連想検索と呼ばれることもあるが、これらは技術的には ほぼ同一のものとして扱われる。
今日に至るまでの文書検索システムでは、キーワードの組み合わせ(AND/OR/NOT)
からなる論理演算式を入力とするものが主流である。論理演算式による検索では、検索結 果として出力すべき文書集合を一意に特定できるという長所がある。しかし、検索で使用 するキーワードを選定し、論理演算式を組み立てるのに、利用者の手間がかかるという短 所がある。また、論理演算式から利用者の検索意図を特定するのが難しいという短所もあ る。
これに対して概念検索では、利用者の検索意図に合致した文書を検索結果の上位に出力 することが、論理演算式による検索に比べて容易であるという長所がある。しかし、検索 結果として出力される文書集合は、検索アルゴリズムに大きく依存するという短所がある。
また、検索結果が大量に出力されるため、検索結果のどこまでチェックすれば所望の文書 がないと判定できるのかが分からないという短所もある。
概念検索においては、ベクトル空間モデルと呼ばれる検索モデルが主流である。入力さ れた自然言語文及び検索対象文書の記載内容を、それぞれ複数の重み付き単語からなるベ クトルとして表す。そして、文書間の類似度を算出する際には、ベクトル間の余弦値を用 いる。また、個々の単語の重要度(重み)を算出する方式として、文書中の単語出現頻度 及び単語出現文書数を用いるTDIDF法が広く採用されている。
概念検索を用いたシステムとしては、汎用連想計算エンジン「GETA」が有名である。
GETAは、情報処理振興事業協会(IPA)が実施した「独創的情報技術育成事業」の研究 成果である。GETAは、どの文書にどの単語が何回出現するかというデータを行列として 保持し、文書間あるいは単語間の類似度を高速に計算するツールである。GETAを用いた 検索システムとして、図書・雑誌の書誌・所在図書館情報を検索できるWebcat Plusや、
書籍・文化遺産・Wikipediaなどの複数データベースを横断検索できる検索サービス「想
-IMAGINE Book Search」などがある。
b.対象文書を限定したより高度な検索
特許、論文、Q&A など、ある特定の種別の文書のみを対象とした検索である。対象文 書を限定することにより、文書構造や構文など、その文書に特化した情報を活用した、高 精度・高効率の検索が期待できる。
例えば、特許検索では、請求項文章を自然言語解析して発明構成要素に分割し、それぞ れの要素を入力とした概念検索結果をマージすることによって、類似する特許を特定する 研究がある。また、機器の操作などに関するQ&Aの検索では、「AをBしたら、CがD した」など、問合せ文の中でよく使われる構文情報を手掛かりとして、過去のQ&A と高 精度に照合させる研究がある。更に、対象とするドメインに関するオントロジーを構築し て、意味に踏み込んだ検索を行う研究もある。
c.文書の集約化(関連付け)
検索対象となる文書を単独に扱うのではなく、互いに関連付けられたものとして扱うこ とにより、所望の文書に早く辿り着けるようにするというアプローチである。文書間の関 連を解析して予めリンクをはっておき、検索時にこのリンク情報を活用する。文書を予め
ジャンル毎に分類しておくこともこの集約化に該当する。
Google では、Web ページ間の引用・被引用関係から、そのページの重要度を判定して いる。また、特許や論文では、従来技術として引用している文献を用いて、重要な特許・
論文を特定したり、技術マップを生成したりする研究がある。電子メールやチャット、議 事録などでは、議論内容の時系列変化の観点から、文書を関連付けたり、内容を要約した りする研究がある。
文書間の関連付けには、文書種別や執筆者などのように書誌的な観点によるものと、分 野や主題の共通性などのように意味的な観点によるものがある。どちらも人間の介在があ る程度必要であるが、これをいかに自動化し、作業負荷を軽減するかが技術課題である。
d.メタ検索
メタ検索は、利用者の必要とする文書を検索する際に、どの文書データベースを検索し たら良いのかをシステム側で選択する、「検索システムを検索する」システムである。
メタ検索システムには2種類の型がある。一つは、検索条件を複数の検索システムに送 信して実行し、それらの検索結果を統合して、一つの検索結果として出力する「統合型」
である。統合型のメタ検索では、各検索システムから得られる検索結果をどのように順位 付けして統合するのか、検索結果をどのように利用者に提示するか、といった技術課題が ある。
もう一つは、検索する内容に応じて、最適な文書データベースを選択し、検索を実行す る「非統合型」である。非適合型は更に、各文書データベースに対して共通のメタデータ を定義して、これを検索するものと、各文書データベースに登録されている文書の内容を 照合するものがある。国立国会図書館が運営しているデータベースナビゲーションサービ スDnaviは、共通のメタデータを定義するアプローチのメタ検索システムである。
e.質問応答
質問応答は、自然言語文によって表現された質問に対して、回答の含まれる文書ではな く、回答そのものを出力する形態の検索である。質問応答の研究は、対話的な情報アクセ スを支援する手段の一つとして注目されている。
Web上での検索エンジンとしては、Ask.comが有名である。例えば、「アメリカの初代 大統領は誰ですか?」という質問文を入力すると、「ジョージ・ワシントン」という端的 な回答を出力する。また、上述したワークショップ型共同研究NTCIR では、質問応答タ スクが開催されており、質問応答に関する研究を行うための実験環境も整備されつつある。
質問応答の研究では、文章から5W1Hなどの固有情報を抽出する技術や、文書の部分的 な記載の照合に基づいた検索技術、検索した結果から回答を生成するための文生成・要約 技術など、自然言語処理に関する様々な技術と密接に関係している。
f.検索システムのパーソナライズ
検索システムを利用者個人向けにカスタマイズすることによって、システムの使い勝手 の向上を図ろうとするアプローチである。
本アプローチには、画面構成などのユーザインタフェースからの個人カスタマイズと、
利用者の行動履歴を反映させたコンテンツの提供という2種類がある。前者では、Google が、自社で提供するツールやコンテンツを駆使して、Googleのホームページを個人用にカ スタマイズできる個人向けのパーソナライズサービスiGoogleを提供している。また、後 者では、書籍などのオンラインショッピングサイトであるAmazonが、購買者の行動履歴 を分析してサービスにフィードバックする手法を導入している。購買者がどんなジャンル の書籍を購入したかという履歴データをマイニングして、関連する別の書籍を推薦したり、
同じ書籍を購入した別の購買者が購入した書籍を紹介したりするなどの機能である。
g.検索アルゴリズムの改善
検索精度を向上させるための検索アルゴリズムの研究も地道になされている。その一つ として、キーワードを単独に扱うのではなく、共起関係や複合語、係り受け関係など、そ のキーワードと関係の深いキーワードを対にして一つのキーワードとみなす方式がある。
例えば、「情報を検索する」という文があった場合、キーワード「情報」と「検索」をそ れぞれ単独に扱うだけでなく、「検索(情報)」というように、述語と目的語を対にして 一つのキーワードとして扱うことにより、個々の単語の持つ曖昧性を解消し、低ノイズの 検索結果を得るものである。しかし、使用する語彙のばらつきが激しい文書では、キーワ ードの照合が更に難しくなるという技術課題がある。
h.対話による検索
検索の全自動化を諦め、検索に必要な情報を、利用者との会話によって適宜獲得しなが ら検索するというアプローチである。具体的には、以下の3種類の検索支援があげられる。
1)検索条件作成支援
検索条件を作成する際に、シソーラス辞書や検索対象文書集合から得られる関連キ ーワードを提示することによって、より適切な検索条件の作成を促進する。上述の Webcat Plusでは、検索結果文書を動的に解析して、その中に含まれるキーワード の一覧を利用者に提示し、次の検索を支援している。
2)検索結果理解支援
検索された文書集合を、文書クラスタリングなどにより分析・整理した結果を利用 者に提示し、検索結果の絞り込みまたは拡張を促進する。
3)適合性フィードバック
所望の文書に近い文書を、検索結果の中から利用者に選択させ、その文書データを 解析して検索にフィードバックする。
④ 文書検索の技術課題と技術用日本語への期待
文書検索の研究は、全体としては、検索精度そのものを向上させる研究アプローチから、
検索精度の向上を間接的に支援する研究アプローチにシフトしてきている。その一方で、
検索精度の向上に関する研究も地道に行われている。しかし、精度向上方式の有効性を実 際に評価してみると、その度合いは期待していたよりも小さいことが多い。この最大の原
因は、そもそも扱う文書が語彙的・構文的に明晰でないため、言語の表層レベルでは、文 書内容を表す概念を正しく解析・照合できないことにあるといえる。
技術用日本語は、今まで計算機にとって不得手だった、単語間あるいは文間の構文的・
意味的関係を解析して、概念のレベルに踏み込んでいく起爆剤的な役割を担っている。技 術用日本語によって書かれた文書が蓄積されるようになれば、人間の直感により近い文書 検索を実現できる可能性は高い。
一方、技術用日本語を文書検索に適用する際の課題もある。文書検索は、ある人が執筆 した文書を翻訳できれば良いという機械翻訳と異なり、過去に多くの人によって作成され た大量の文書を検索対象としている。このような大量の既存文書を、どのようにして明晰 化するかという課題がある。検索の入力となる文章と、検索対象となる文書の両方が明晰 化されなければ、技術用日本語による検索精度の飛躍的向上は見込めない。大量の文書を 高速に明晰化するエンジンの開発や、誰でも使いこなせる技術用日本語エディタの普及が、
文書検索への適用には不可欠であろう。
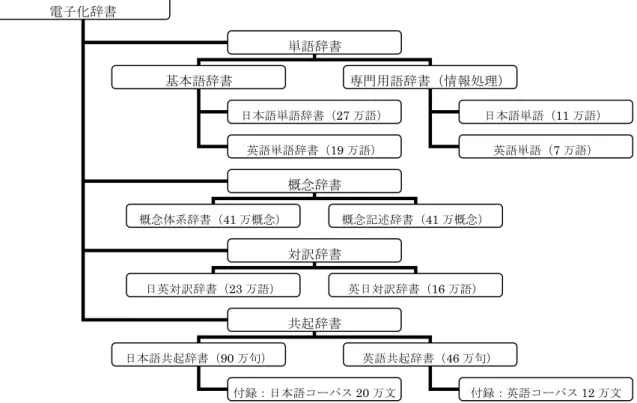
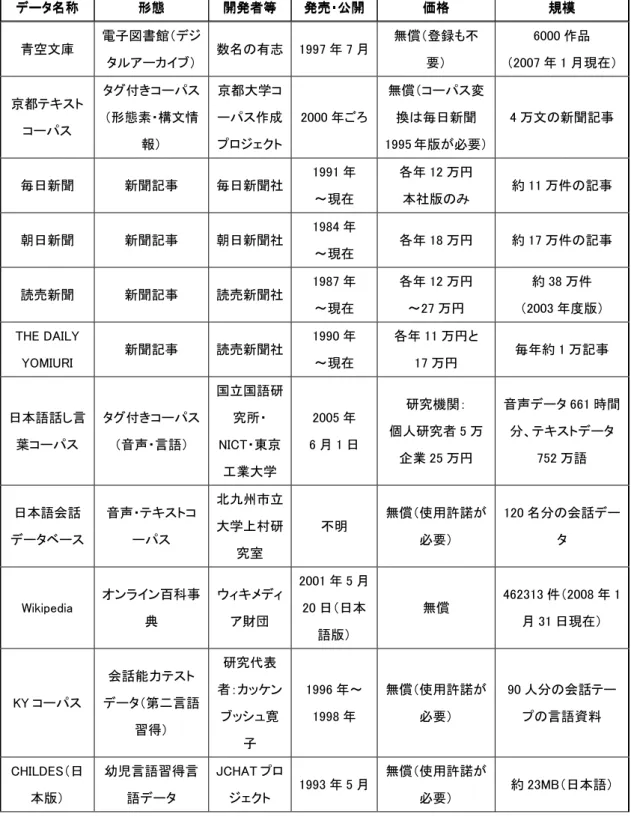
(4)辞書サーバと言語資源
辞書サーバ関連プロジェクトと言語資源について調査し検討を行った。まず辞書関連プ ロジェクトとして、言語グリッドプロジェクトとコミュニティ辞書の取り組みについてま とめた。次に、言語資源の項として新聞記事などの書き言葉や話し言葉などのテキストや 音声のコーパスや、シソーラス、下位範疇化(格パターン)情報などの電子化された言語 資源についてまとめた。
① 辞書サーバ関連プロジェクト
この辞書サーバ関連プロジェクトの項は、言語グリッドプロジェクトとコミュニティ辞 書についての調査結果である。これまで言語資源は書籍や記録メディアとして公開される ことが多かったが、これらの取り組みではシステムやデータをサーバが提供することによ り、ユーザが資源の構築に参加していくことなど新しい取り組みが期待されている。
a.言語グリッドプロジェクト
言語グリッドプロジェクト[Ishida 06][NICT 07]とは、2006年度より始まったNICT と大学、NTTなどの研究グループが産官学民の体制で取り組んでいるプロジェクトであり、
既存の言語資源や言語処理を行うツールを大規模に共有して機能するインフラを整備し、
多言語間のコミュニケーションを支援することなどを目指して進められている。
言語グリッドには、大きく分けて2種類があり、水平型言語グリッドと呼ばれる取り組 みでは、言語間をアジア10程度の言語や、欧州研究機関との連携によって世界全体で20 言語程度カバーし、対訳辞書や機械翻訳を組み合わせたものとなっている。もう一方は垂 直型言語グリッドと呼ばれる取り組みであり、言語処理技術を用いた様々な応用へ向けた ものとなっている。
b.コミュニティ辞書
コミュニティ辞書とは、NIIの相澤氏[Aizawa 06]によれば、特定の分野やコミュニ ティにおける語彙や用語の特徴を反映させて構築される辞書であり、コミュニティ間での 意味や用法の違いを考慮した辞書である。
言語資源としての辞書にとって、語と語の関係やある語との同義表現について定義する 際、分野を考慮することは有効である。例えば、語義に曖昧性を持つ語の場合、その分野 においてより用いられやすい語義について分かっていれば、システムの語義選択における 性能を改善できる可能性がある。同様にして、機械翻訳の技術においては、対訳辞書にあ たるものを分野ごとに作成することで、より適した翻訳を行えると考えられる。
また、コーパスを用いた統計的な方法だけではなく、ユーザが参加して対訳辞書を構築 していく研究も存在している[Oki Electric Industry Co. 06]。この研究では、社会科学 やコンピュータ、スポーツといった階層的に用意されたコミュニティを選択し、そのドメ インで用いられる辞書を用いて翻訳を行う。