Information-Centric Networking
February 2015
Yao HU
Information-Centric Networking
February 2015
Waseda University
Graduate School of Fundamental Science and Engineering
Department of Computer Science and Engineering, Research on Information
Systems
Yao HU
Contents i
List of Figures iv
List of Tables vi
1 Introduction 1
1.1 Contribution . . . 8
1.2 Dissertation Organization . . . 9
2 Background 13 2.1 IP Architecture . . . 13
2.2 ICN Architecture . . . 15
2.2.1 TRIAD . . . 16
2.2.2 DONA . . . 16
2.2.3 CCN/NDN . . . 17
2.2.4 PSIRP/PURSUIT . . . 17
2.2.5 NetInf . . . 18
2.2.6 COMET . . . 18
2.3 Overview of CCN . . . 19
2.3.1 Packet Exchange . . . 19
2.3.2 Naming . . . 21
2.3.3 Forwarding . . . 21 i
2.3.4 Routing . . . 25
3 Related Work 27 3.1 ICN Forwarding . . . 27
3.2 ICN Routing . . . 29
4 Forwarding by Learning 32 4.1 Motivation . . . 33
4.2 Proposed Method . . . 36
4.2.1 Forwarding Interest Base . . . 36
4.2.2 Method for Forwarding Interest Packets . . . 37
4.3 Evaluation of the Proposed Method . . . 40
4.3.1 Space and Time Tradeoff . . . 40
4.3.2 Link Failure . . . 41
4.3.3 Application . . . 44
4.4 Discussion . . . 46
4.5 Conclusive Review . . . 47
5 Name-based Routing Mechanism 49 5.1 Motivation . . . 50
5.2 Comparison with ICN Architectures . . . 52
5.2.1 Routing Mechanisms . . . 52
5.2.2 Mobility Challenges . . . 54
5.3 Comparison with CCN Approaches . . . 56
5.4 Name-based Packet Delivery . . . 58
5.4.1 Standard CCN . . . 58
5.4.2 Proposed RGN and Scheduler . . . 60
5.4.2.1 Configuration . . . 63
5.4.2.2 Packet Forwarding . . . 68
5.4.2.3 Pre-scheduled Caching . . . 71
5.4.2.4 Mobility Support . . . 73
5.5 Evaluation . . . 75
5.5.1 Overhead and Resource Consumption . . . 75
5.5.2 Data Provider Mobility . . . 78
5.5.3 Data Client Mobility . . . 80
5.6 Discussion . . . 85
5.6.1 Interest Aggregation . . . 85
5.6.2 Multipath Forwarding . . . 86
5.6.3 Security . . . 87
5.6.4 Scalability . . . 88
5.7 Conclusive Review . . . 89
6 Conclusion 90 6.1 Summary . . . 90
6.2 Future Work . . . 93
Acknowledgements 95
Bibliography 96
List of Research Achievements 102
2.1 CCN Node Structure . . . 22
4.1 CCN Packet Processing . . . 34
4.2 CCN Forwarding Plane . . . 37
4.3 Processing Procedure with the New Forwarding Mechanism . . 38
4.4 Learning Forwarding Information Base . . . 39
4.5 Topology . . . 41
4.6 Forwarded Interest Packets and Total Flooded Packets . . . . 42
4.7 Topology . . . 43
4.8 RTT-first Method and Our Method in Case of A Link Failure 43 4.9 Delay Between First Interest Sent and Data Received . . . 44
4.10 Topology . . . 45
4.11 Request-data Message Delay . . . 46
5.1 Layered Routing Hierarchy . . . 61
5.2 Bootstrap Process (a) Presence Notification . . . 63
5.3 Bootstrap Process (b) Scheduler Discovery . . . 64
5.4 Bootstrap Process (c) Router Registration . . . 66
5.5 Bootstrap Process (d) Data Registration . . . 67
5.6 New Name-based Routing . . . 69
5.7 Data User Mobility with Pre-scheduled Caching . . . 72
5.8 Data User Mobility . . . 74
5.9 Data Source Mobility . . . 74 iv
5.10 Overhead and Resource Consumption Evaluation on PlanetLab 75
5.11 Number of Packets in the Network . . . 76
5.12 Average Number of Packets Received by the Data Provider . . 77
5.13 Data Source Mobility . . . 78
5.14 Received Data Packets for the Data User . . . 79
5.15 Data Sequence Number and Receiving Time . . . 80
5.16 Data User Mobility Scenario . . . 81
5.17 Comparison of the Standard CCN and the New Method . . . 83
5.18 Comparison of Average Latency at Each Station . . . 85
5.1 Standard CCN, other ICN approaches and our proposal . . . . 55 5.2 Comparison of different routing and mobility schemes in CCN 59 5.3 Requested data segment IDs at each station . . . 82
vi
Introduction
The IP-based network architecture was originally invented in the middle of last century. At that time, there were no web surfing or current popular online social network applications. The primary use of the Internet was to share remote network resources which are expensive. For example, a user could telnet to a remote computer to conduct sophisticated computation tasks.
Thus, the Internet was designed in a host-to-host or end-to-end fashion to facilitate this kind of point-to-point conversation model, because people were interested in where the network resources are located. In this model, Internet Protocol (IP) performs as the core protocol of the Internet. The current IP- based networks are still based on the initial concept: IP addresses are given to host machines. All the packets delivered from a host to another host have a source IP address and a destination IP address. The IP address specifies the location of a host machine in a network.
Network applications have changed from the initial Internet. With the recent proliferation of personal computers and portable devices like smart phones and tablet PCs, computing resources become very cheap. Hence, the main
1
use of the Internet is to share various digital information rather than physical network resources. In some applications like VoD services, users care about what information is or what content is rather than where the information or content is located. There are certain areas of applications which are called information-centric.
Problems arise when the current Internet architecture can not satisfy the needs of these kinds of information-centric applications. In IP-based networks, a user’s client machine maps the requested content to a specified host name (domain name) that provides the content. Then the domain name is translated into the corresponding IP address by domain name system (DNS). If people need to get some content, they have to map the content to a specified host (IP address) that provides the content. For example, when a user wants to browse a web page, the usual action is to type the web address which is called URL (Uniform Resource Locator) into the address bar of a web browser. Then the browser needs to utilize DNS to resolve the included domain name within the URL into the web server’s destination IP address and thus create a TCP connection at port 80 with the web server to fetch the requested content. Such procedures are quite natural for people to use today’s Internet applications.
However, some problems may arise because of these kinds of operations. For instance, it may cause more traffic burden and server load, or even incur denial-of-service (DoS) attacks in the network. There also exists a single point of failure if the specific web server is the only one to be connected.
Besides, IP may introduce a number of extra traffic overhead into the network because an end-to-end connection is needed for each content delivery process.
Any intermediate router on path can not be aware that the same content is fetched by multiple hosts (users) if it does not conduct expensive deep packet
inspection (DPI) [8].
To deal with the inconsistency of the information-centric or content-centric applications running on the IP-based host-centric network architecture, a number of new systems or techniques have been proposed, such as content delivery networks (CDN) [52], web caching [36], URL redirection [16] and peer-to-peer (P2P) system [51]. However, these add-on systems or techniques are application-specific and bring new issues or side effects to the current IP Internet.
Differentiated from these add-on systems or techniques, information-centric networking (ICN) is proposed to try to address the problems by changing the network architecture. In ICN, information becomes the first-class object.
Information is assigned a globally unique name which is location-independent.
ICN fundamentally changes the current Internet architecture but offers the Internet users broader prospects for various information-centric applications.
There are several active projects based on the concept of ICN, such as TRIAD [38], DONA [42], content-centric networking (CCN) or named data networking (NDN) [38] [62], Network of Information (NetInf) [18], Scalable and Adaptive Internet Solutions (SAIL) [14], PSIRP/PURSUIT [29], and COMET [30]. We will survey them in Section 2.2. While these projects have been initiated by various organizations, they share some common essential ICN concepts as follows.
Location Independent:
Data name is location-independent. When a user wants to fetch data, the only operation in ICN is to specify the requested data name. The network then retrieves the data from anywhere for the user. This feature facilitates
data distribution especially in large-scale networks. Thus the network traffic in ICN can be utilized more efficiently than that in IP. For example, in ICN the requested data can be retrieved from the cache of the nearest router. Due to this native advantage of ICN, the user-perceived latency can be reduced.
Furthermore, the traffic load on multiple data providers can be balanced to avoid the overload on a single data server caused by a sudden traffic storm.
Besides, it eliminates the early binding of the data with a specific destination like in IP-based networks, which may cause the traffic storm problem and difficulty in mobility. We will make full use of this feature to design our learning forwarding scheme in Chapter 4.
Receiver Driven:
Packet deliveries in ICN are carried out in a receiver-driven pattern. ICN routers deliver packets relying on the names of the requested data instead of specific addresses, e.g., IP addresses. Therefore, any pure source routing mechanism in IP may be infeasible in ICN. There are many benefits for this kind of name-based routing design in ICN, but also there may exist various scalability problems. This makes the name-based routing at a large scale in ICN difficult. We will address the routing design problem via the new receiver-driven architecture in Chapter 5.
In-network Caching:
ICN claims that each content can reside anywhere and be served to anyone in the network. In ICN, each content is assigned a globally unique data name which is signed together with the content information by the original data provider. Due to the location-independent data name, users can refer to the data at any time without caring about where the data resides, and also can verify the data integrity via the included digital signature without regard to
where the data is derived. Since in-network caching is inherently supported by ICN networks, any ICN router can cache the incoming data packets from anywhere in the network. This native advantage potentially could mitigate the traffic load on data providers that hold popular contents. Thus the redundant traffic and user-perceived latency in the network can be decreased. Each of our mechanisms in Chapter 4 and Chapter 5 can benefit from the deployment of in-network caches.
Data-centric Security:
Data is digitally signed by the data provider in ICN. ICN claims that the end user or intermediate routers can verify the integrity of the received data based on the digital signature. This fundamentally differs from the existing IP- based security countermeasures that aim to secure end-to-end communication channels. This data-centric security model is also an important component of ICN. In this model, a basic digital signature does not satisfy all security requirements for today’s applications. Hence, an effective security mechanism should be considered to provide ICN with reliable data services. For example, a safe online social network application in ICN should cover the permission management problem. In this dissertation, we do not deal with a concrete ICN security topic, however we keep the data-centric security principle in mind all the time while figuring out new mechanisms.
This dissertation deals with the leading design among the proposed ICN ar- chitectures, which is called content-centric networking (CCN). CCN replaces the end-to-end data delivery model in IP by a receiver-driven data retrieval model. As a result, CCN users do not deliver packets to given addresses, e.g., IP addresses, but retrieve data by specifying data names. CCN packets include the requested content names rather than packet IP addresses. Thus, network
users do not need to indicate where the desired data may be located , but only need to express the required data names. The data names are encapsulated in data request packets which are called Interest packets. The corresponding Data packets are returned from original data producers or intermediate router caches to satisfy the Interest packets. As mentioned previously, the CCN ar- chitecture can offer a wide range of benefits from the ICN concept, including built-in multicast data delivery, in-network caching, as well as data-centric se- curity. This dissertation studies adaptive forwarding and routing mechanisms, which are unique and powerful features introduced by CCN.
The architecture of a network determines the design of the forwarding and routing mechanisms in the network. A typical router today contains a routing plane and a forwarding plane. The routing plane defines the construction of its routing tables, while the forwarding plane makes forwarding decisions for incoming packets. In IP-based networks, packet deliveries are accomplished in two stages. The first stage is called routing, where nodes exchange rout- ing updates and construct the routing table with the best route towards the destination; the second stage is called forwarding, where nodes forward data packets strictly based on the routing table. Hence, although IP forwarding is simple and lack of adaptability for dynamic network environments, IP routing is adaptive and stateful. As a result, the routing design independently takes the responsibility of constructing robust and reliable data delivery mechanisms in IP-based networks.
In an ICN architecture, while routing plays a similar role to that in an IP- based network to help construct a forwarding information base (FIB) table, forwarding is performed in two steps: a user first sends an Interest packet, then the corresponding Data packet returns along the reverse path. In ICN, on-path
routers keep states of forwarded pending Interest packets to guide reply Data packets to go back to requesting users. This state keeping function for pending Interest packets, together with the symmetric exchange of Interest and Data, enables routers to calculate metrics of multiple routing paths. Therefore, it can also detect a link failure and retry an alternative path to fetch data in the network. Unlike IP, ICN provides us a chance to design an adaptive forwarding plane.
With the powerful feature of the adaptive forwarding, ICN routers can de- tect and recover from network problems quickly without waiting for global routing convergence. For example, ICN routers can estimate the round-trip time (RTT) for each interface or name prefix by recording outgoing Interest packets and observing incoming Data packets. Network problems can be de- tected based on the RTT estimation: if Data is not received within a specified timeout period, there may be potential network problems, e.g., link failures.
Once problems are detected, ICN routers can start exploring alternative paths immediately by using local state information. Since routers can record multi- ple interfaces for one name prefix entry and Interest forwarding is loop-free in ICN, routers can effectively utilize the multipath forwarding to recover from various network problems.
A seminal paper is written by Jacobson et al. [38] which sketches out a blueprint for an ICN architecture. They called it CCN. However, their pa- per did not fully explain the operations of forwarding and routing methods which are essential mechanisms in ICN. This thesis proposes new adaptive forwarding and routing mechanisms to realize an efficient and reliable ICN architecture. To address the issue of forwarding information base (FIB) auto- matic configuration rather than manual operation with static routes in large
scale networks, the proposed forwarding mechanism is equipped with an FIB learning capability to make best use of the adaptive forwarding feature in ICN. The new routing mechanism enhances the hop-by-hop ICN architecture (CCN) with global dynamic adjustment. It deals with mobility concerns based on the new name-based routing mechanism under the guidance of a special scheduler node in the network. The new routing service runs on top of the standard ICN architecture by providing a new naming scheme for packets.
Our proposals give ICN a step further towards a practically working system.
1.1 Contribution
The works and contributions of this dissertation are summarized below:
1. We proposed a new FIB learning mechanism in ICN. By learning efficient faces to forward incoming packets, we concluded that FIB table filling and Interest forwarding are optimized due to adaptive path discovery for requested data. We verified that the new FIB learning mechanism is adaptive to changing network configurations. Besides, unnecessary traffic is reduced because an Interest packet is forwarded to only one face to find potential data providers or holders. We also showed the resilience of the new proposal when handling mobile nodes in ICN.
2. We designed a new name-based routing protocol, which is network topol- ogy aware in ICN. Within the new routing mechanism, we proposed a new naming scheme for Interest and Data packets and a new FIB instal- lation method for ICN routers. We showed that ICN users or requesters
totally do not need to care about the configuration change from the stan- dard ICN architecture. We concluded that the new proposal smoothly supports mobility in ICN, because a mobile node just needs a simple reg- istration process at the scheduler after the movement. We also pointed out that the new routing protocol can be extended easily to support multipath or alternative paths to deal with issues such as congestion control in the network.
1.2 Dissertation Organization
Chapter layout of this dissertation is organized as follows:
• Chapter 1: Introduction to this dissertation
• Chapter 2: Background information and theory
• Chapter 3: Related work
• Chapter 4: A new FIB learning mechanism in CCN
• Chapter 5: A new name-based routing protocol in CCN
• Chapter 6: Conclusion and future directions
Chapter 1 presents a brief introduction to this thesis, which includes the thesis organization, original works and contributions.
Chapter 2 first summarizes the current IP architecture and then introduces the ICN concept. Among several ICN on-going projects, we pick CCN as the basis of our architecture due to their leading design and popularity. It should
be noted here that many of our findings and schemes in this thesis are also applicable to other ICN architectures. We describe the CCN architecture in some detail, including the three essential structures of a CCN node, namely forwarding information base (FIB), content store (CS), and pending interest table (PIT). We identify the missing pieces or mechanisms in the current ICN design and explain how our works fill in these research gaps. We design a new FIB learning forwarding mechanism to deal with the issue of FIB automatic configuration in large scale networks rather than manual operation with static routes. We propose a new name-based routing mechanism to provide the ICN/CCN architecture with global dynamic adjustment. It includes a new naming scheme for packets and a new dynamic FIB configuration method.
Chapter 3 discusses the related works. We survey alternative solutions pro- posed by related projects. We emphasize two specific topics of ICN forwarding and routing, in that they are distinguished features in ICN from those in IP, but they are still not well-documented or developed in the current ICN re- search area. While routing in an ICN architecture plays a similar role to that in an IP network, i.e. computing a routing table, forwarding in ICN is performed in two steps: a user first sends an Interest packet, then the corresponding Data packet returns along the same path but in the reverse di- rection. In ICN, on-path routers keep states of forwarded Interest packets in order to direct Data packets to go back to data requesters. This state keeping function for pending Interest packets, together with the symmetric exchange of Interest and Data, enables routers to calculate metrics of multiple routing paths. It can be also used to detect link failures and retry an alternative path afterwards.
Chapter 4 details our design of FIB forwarding with learning capability in ICN. We start with presenting the motivation for our work. According to the original ICN protocol, it is possible for a name-prefix to have multiple outgoing faces in FIB. Naive manual configuration with static routes is feasible for small ICN networks. However, it may introduce much traffic wastage in large-scale networks. We need more sophisticated mechanisms to fill in the FIB with promising forwarding entries. Traditional IP routing algorithms like OSPF may be a possible solution for this issue. However, they do not make use of the cached data in ICN. In ICN, an intermediate node (router) on a path has the responsibility of returning the requested data to the end user. ICN provides us a chance to design an adaptive forwarding mechanism.
With this powerful feature of our adaptive forwarding, ICN routers can detect and recover from network failures quickly without waiting for global routing convergence. For example, ICN routers can estimate the round trip time (RTT) for each interface or name-prefix by recording outgoing Interest packets and observing incoming Data packets. Network problems can be detected based on the RTT estimation. For example, if Data is not received within a certain timeout period, there may be potential network failure. Once a network problem is detected, ICN routers can start exploring alternative paths immediately by using local state information and effectively utilize multipath forwarding to recover from the problem.
Chapter 5 proposes a new name-based routing mechanism in ICN. We mo- tivate the research by addressing the shortcomings in the existing routing schemes in ICN. In our proposal, a new scheduler node assists routing as an additional function to the existing ICN architecture. The proposed method still retains basic characteristics of ICN. The scheduler is a special ICN node,
which can be implemented upon a standard ICN router. It has knowledge of the network topology and location of specific named data. Therefore, it can play a role as a scheduler to calculate and assign the best routes towards data providers for data requesters. Basically, there are four steps for the configura- tion of ICN nodes. First, each participant router sends a greeting message to its adjacent routers. This is to let all routers know their neighbors including information of link metrics such as RTT values. Second, if a router does not know the location or ID of the scheduler in the network, it sends an Interest packet and uses a flooding method to discover routes towards the scheduler.
This is to let all routers know how to reach the scheduler in the network.
Third, the router sends a registration message to register itself at the sched- uler. This is to let the scheduler be aware of the network topology. Fourth, if a data provider wants to register the named data or served name prefix, it sends a registration Interest packet to register the data or name prefix at the scheduler. That indicates that the data provider will be responsible for serving requests for the registered named data or name prefix. Then, the scheduler knows the location where the registered data is in the network.
Chapter 6 summarizes the entire thesis and explains a few possible directions for further research.
Background
In this chapter, we briefly review the IP architecture. Then we introduce CCN architecture because it is the most popular proposal among ICN re- search projects. Section 4.1 explains key elements in CCN which cover names, Interest and Data, cache and forwarding mechanism, PIT and FIB. This thesis is based on the CCN architecture, and proposes our new method on it.
The CCN architecture apparently looks nearly complete. However, there are still missing or undefined parts in the basic design. We identify two important parts of them, forwarding and routing, and addressed them one by one in this dissertation.
2.1 IP Architecture
Today’s IP Internet has a layered architecture. Each layer in the architecture provides a different functionality. Protocols on each layer define communica- tion functions and provide interfaces to be used by upper-layer protocols. IP,
13
the primary network layer protocol, is at the middle layer of the architecture.
On top of IP are transport layer protocols (e.g., TCP) and application layer protocols (e.g., HTTP), while link layer protocols (e.g., Ethernet) resides be- low IP. This architecture allows protocols at both upper and lower layers of IP to evolve independently and thus brings continuous success of the Internet architecture up to now.
As an essential network layer protocol, IP is responsible for delivering packets between network users. Since IP was designed for point-to-point or end-to-end communications, it gives end points names by assigning them globally unique IP addresses. IP communication is sender-driven: a sender constructs an IP packet for data, puts both source and destination addresses into the packet header and sends it to the network. Each intermediate IP router forwards the packet according to the destination address by looking up in the routing table, which is constructed by some IP routing protocol.
For example, routers announce IP prefixes they serve in the network. On receiving the annunciation, the next-hop router distributes the prefix infor- mation as well as connectivity information to the rest of the network. Upon receiving routing information from its neighbors, a router may update the routing table and update the routing table accordingly. IP routing table pro- vides mapping from IP prefixes to the best next hops. When the destination application receives an IP packet, it can simply swap the source and desti- nation addresses of the packet and send a reply packet back to the network afterwards.
With the emergence of new applications such as e-commerce, digital media and social networking, Internet service is becoming increasingly content-centric or
information-centric. However, the current Internet has many limitations in the attempts to address the content distribution problem with such a point-to- point or end-to-end communication protocol as IP. For example, if users want to acquire contents by inputting URLs through some web browser, the browser application will first have to spend time using a DNS system to translate the data names (included in the URLs) into the IP addresses. Since IP multicast is not widely deployed due to its complexity, this leads to tremendous traffic waste when multiple users are accessing the same data. IP does not support in-network caching either. An add-on solution for a large data provider is to use the content distribution networks (CDN) to provide temporary caching of data, but it is expensive. Besides, IP is far from security against malicious attacks, although many efforts have been devoted to securing communication channels between two end points.
ICN/CCN is proposed to deal with the limitations and better accommodate the current emerging information-centric or content-centric communication patterns.
2.2 ICN Architecture
ICN is designed to make data the first-class object and facilitate data distri- bution in large-scale networks. However, the current IP-based networks are designed to provide end-to-end packet delivery services to accommodate var- ious information-centric applications which are running based on IP. Because of the inconsistency of the application model and the networking model, we have to conduct a lot of inelegant translations or mappings which may lead to some network problems such as traffic storm and DoS attack.
In this section, we provide a survey of the most prominent ICN architectures in the literature.
2.2.1 TRIAD
The concept of information-centric or content-centric network initially ap- peared in the TRIAD project [33] at the very beginning of this century. It realized the difficulty for the IP-based network architecture in supporting data deliveries at large-scale networks. It also pointed out the inadequacy of some add-on solutions such as web caching and dynamic DNS. Therefore TRIAD proposed a novel network architecture where delivered data is identified by the data name rather than any address. In this new network model, data name is resolved into the corresponding address by intermediate routers rather than location-specified DNS servers in the network. In TRIAD routing is conducted according to server names rather than content names, it covers some key el- ements of the current ICN concept like location-independent naming as well as somewhat name-based routing.
2.2.2 DONA
At the content level, the ICN concept was first adopted in a project called Data-Oriented Networking Architecture (DONA) [42]. In DONA, data is as- signed a self-certified flat name. Resolution handlers (RH) conduct name resolution in the network. There is a logical RH in each domain. Multiple RHs form a hierarchical system among these domains. Data names are pub- lished in REGISTER messages by data providers towards their local RHs.
The REGISTER messages help create a registration table on each RH, which
guides the following FIND messages to be forwarded effectively by matching data names in the registration table afterwards. If there is a matching entry with one FIND message in the registration table, it indicates the next hop to forward the incoming FIND message. If no matching is found in the registra- tion table, this FIND message is guided towards its upper-level RH. Totally different from the IP-based network architecture, the DONA architecture is a completely new design for the naming scheme and name resolution. How- ever, in DONA once data is located, the actual data packet deliveries are still conducted by IP.
2.2.3 CCN/NDN
Currently, the CCN architecture [38] is proposed, which has stimulated wide- spread interests in content-centric network research. Named Data Networking [62] is the new name of CCN, which is now funded by National Science Foun- dation (NSF) as one of the Future Internet Architecture (FIA) projects. We will explain the CCN/NDN system further in Chapter 4.1. Although this dis- sertation takes CCN/NDN as our base architecture, many of the new findings or mechanisms can be extensible to other ICN architectures as well, including the new designs in Chapter 4 and Chapter 5.
2.2.4 PSIRP/PURSUIT
The project of Publish-Subscribe Internet Technology (PURSUIT) [29], which succeeded Publish-Subscribe Internet Routing Paradigm (PSIRP), is sup- ported by the seventh framework programme (FP7) of European Union. In PSIRP/PURSUIT, publications and subscriptions are matched in a rendezvous
system which resolves a subscription request into a forwarding identifier (FI) and then sends the FI to the data provider. The FI is actually composed by a bloom filter which helps deliver requested data to all the subscribers.
It is then put into a reply packet header and sent back, which is utilized by intermediate nodes to return the data packet to the subscribers [39].
2.2.5 NetInf
NetInf [18] was initially conceived in the FP7 4WARD project [1]. Now, it is included in the FP7 SAIL project [14]. NetInf has a two-layer representation when referring to information and data. One representation is called infor- mation object (IO), which covers a high-layer semantic of information, e.g., a file. The other representation is called data objects (DO) which covers mul- tiple low-level DOs regarding an IO, e.g., .docx suffix of a file, or .pdf suffix of the same file. Thus when users intend to require data from the network, the NetInf system allows the requirement to be more expressive and flexible to reflect users’ exact demands. MDHT [24] is used for name resolution in NetInf.
2.2.6 COMET
Another famous FP7-funded project on ICN is called COntent Mediator archi- tecture for content-aware nETworks (COMET) [30], which adopts a mediation plane that lies between the physical network and the upper content layer. This mediation plane is aware of the information or conditions of data providers and paths in the network so that it can ensure content deliveries with guaranteed
Quality-of-Service (QoS). COMET proposes alternative methods for imple- mentation, namely decoupled and coupled. In the decoupled proposal, name resolution is conducted before data routing, while in the coupled proposal, data is routed by name.
2.3 Overview of CCN
CCN is a receiver-driven communication protocol. CCN is also seen as a new network-layer protocol. The IP network-layer and transport-layer protocols are pushed down as link-layer protocols in this new architecture. Therefore, traditional applications need to be re-designed to work with the new network layer. This section provides an overview of the CCN architecture.
2.3.1 Packet Exchange
CCN emphasizes named data rather than communication endpoints. This fundamental change from IP leads to the paradigm shift from location-centric to data-centric. In CCN communication, delivered packets are divided into two types: Interest and Data. A name is used in either Interest or Data packet to uniquely identify a piece of data which is loaded in the data field of a Data packet. To retrieve a Data packet, a user uses the requested data name to name an Interest packet and issues the Interest packet to the network. Intermediate routers forward the Interest packet towards the potential data provider(s) according to the specified Interest name. Upon receiving the Interest packet, a data provider or intermediate router keeping the requested Data returns a Data packet to the data requester.
An Interest packet also can carry a selector field that provides more specific descriptions of desired Data, and a nonce field that is filled by a random number generated by its sender. A more detailed explanation of the nonce value can be found in Section 5.6. A Data packet carries the actual data, descriptions about the data, as well as a digital signature that associates the data with the data name. A Data packet is signed by its producer when the Data packet is generated. The signature allows any requester or intermediate router to check the integrity of the Data packet. Hence, trust in a Data packet is decoupled from how it is obtained or where it is from. This kind of built-in security is called data-centric security.
Similar to IP/UDP, CCN performs best-effort packet delivery. If an Interest or Data packet is lost, or the desired Data packet does not return to the data requester within an estimated RTT and the user still wants the Data, it is the responsibility of the end user to retransmit the Interest packet.
CCN packets carry data names rather than IP addresses, thus there are two fundamental differences for packet delivery procedures between the location- centric approach in IP and the data-centric approach in CCN. First, a CCN packet is forwarded according to the specified packet name, while an IP packet is forwarded according to the destination address of the IP packet. As a result, in CCN an Interest packet may bring the corresponding Data packet back from the data provider or an intermediate router, while an IP packet can be always transferred to the destination node unless it drops on the way. Second, unlike in IP, in CCN an Interest packet does not carry an address or name identifying the data requester, thus no information could be referred to as a guidance to return the corresponding Data packet. The forwarding state is kept by each intermediate CCN router to keep tracks of every forwarded Interest packet and
to use its incoming face (interface) to guide the corresponding Data packet back to the requester.
2.3.2 Naming
CCN enables the applications to define their own naming schemes. CCN names are hierarchically structured and human-readable. For example, this dissertation file can be named /ccn/edu/waseda/cs/huyao/dissertation.pdf as a CCN name, where / is the delimiter between name components. This hi- erarchical structure has an advantage of allowing name aggregation, which is especially essential in routing scalability. For example, the name prefix /ccn/edu/waseda/ can be distributed to the network through some routing protocol like the way to distribute IP prefixes in today’s IP Internet. We will discuss further the naming issue and propose a new naming scheme for Interest and Data packets in Chapter 5.
2.3.3 Forwarding
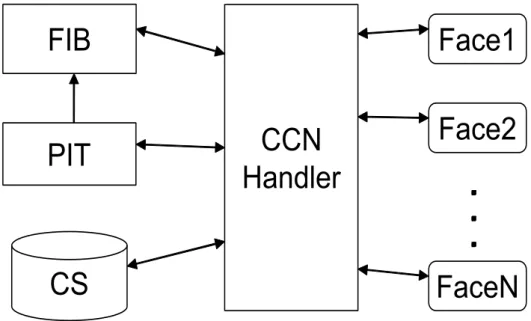
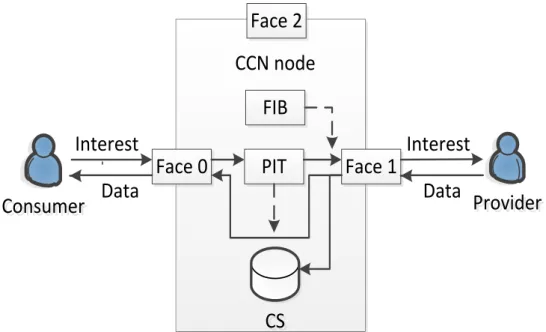
To implement the functions for forwarding the incoming Interest and Data packets, each CCN router is equipped with three important components (see Fig. 2.1): a Forwarding Information Base (FIB), a Pending Interest Table (PIT), and a Content Store (CS). Although the FIB in a CCN router is roughly similar to the routing table in an IP router, there are two signifi- cant differences. First, CCN FIB uses name prefixes, while IP routing table uses IP address prefixes. Second, CCN FIB can include multiple faces (in- terfaces) for a given name prefix, while IP routing table always uses a single best outgoing interface for a specified IP address prefix. A CCN router’s PIT
stores all the names of the Interest packets that have been forwarded but not yet satisfied by returned corresponding Data packets. Each PIT entry records the pending Interest name and incoming face(s) or interface(s) of the Interest packet, as well as optionally the outgoing face(s) or interface(s) of the for- warded Interest packet. A CCN router’s CS provides temporary in-network storage for received Data packets. To forward an incoming Interest or Data packet, each CCN router should follow a forwarding strategy, which specifies whether, when and where to forward the packet based on the information stored in these data structures.
?;@
<;A
5B
55, C)4/*09
?)D0"
?)D0
?)D0,
!! !! !! !! !! !! !! !!
!"#$%&"&'$%()&
!"#$%&"&'$%()& !"#$%&"&'$%()& !"#$%&"&'$%()&
Figure 2.1: CCN node structure
As following the standard forwarding process in CCN, upon receiving an In- terest packet, a router first checks its CS for an existing corresponding Data entry. If there is a matching entry, the router returns the Data packet imme- diately via the face (interface) from which the Interest packet was received.
Otherwise, the router checks its PIT using the Interest name. If there is a matching entry with the Interest name in the PIT, there are two possible sit- uations to be considered. First, if the Interest packet is a duplicate one, then
it is dropped. Second, the Interest packet can be from another face (interface) to retrieve the same Data. Then the incoming face (interface) of the Interest packet is added into the face field of the existing PIT entry. This effectively constructs a multicast tree for multiple Interest requests for the same Data at the same time. If there is no matching entry with the Interest name in the PIT, the Interest name together with the incoming face (interface) is added as a new PIT entry. Then the Interest packet is forwarded to the face (interface) chosen by both the FIB and an implemented forwarding strategy. The CCN router performs longest prefix match (LPM) for Interest names in the FIB.
When a router receives a Data packet, it first looks up the Data name in the PIT. If there is a matching Data name entry in the PIT, the router sends the Data packet to the face(s) or interface(s) recorded in this PIT entry and removes the entry afterwards. If there is no matching PIT entry, the router simply discards the Data packet since it was unsolicited. As a result, each Interest packet and its corresponding Data packet take the reverse paths. Each pending Interest entry in the PIT keeps an associated lifetime respectively. If the according reply Data packet does not arrive before the lifetime expires, this PIT entry is also removed.
A CCN router can choose to cache an arrived Data packet or not cache it depending on its caching policy. Since a Data packet includes a data name together with a digital signature, it can exist in in-network caches independent of its source and destination. The Data packets cached in CSs will be used to satisfy future Interest packets. This is totally different from the use of the buffer memory in IP routers, because a data packet can not be reused by IP routers after it is forwarded. Such in-network caching is useful under many circumstances. For example, a Data packet may get dropped by the network
due to congestion after being cached by some intermediate router. When the requester retransmits the Interest packet, the according Data packet can be directly fetched from the intermediate router without being further forwarded to the original data provider.
Forwarding in CCN is loop-free, because each Interest packet is assigned a nonce field together with the Interest name, which uniquely identifies the Interest. A router records the nonce value of each Interest it receives in its PIT entry so that it can distinguish a newly received Interest packet from a previously issued Interest packet that looped back even though its name is the same as an existing pending Interest entry. A duplicate newly arrived Interest packet will be dropped. Forwarding loop can be thus avoided for Interest packets in the network. Data packets do not loop either since they take the reverse paths of the Interest packets. The feature of loop-free forwarding enables routers to send packets via multiple faces in some adverse cases such as link congestion and failure. However, this kind of retry should be restrained by scope and duration, in that in CCN not routers, but end users (requesters) are ultimately responsible for retrieving Data packets. Also, the potential overhead due to the Interest packet retries should be considered.
In CCN, because one Interest packet retrieves at most one Data packet, there is a flow balance due to this kind of one-to-one correspondence for each network entity such as node and link, unless packets get lost on the way or requested Data packets do not exist in the network.
Besides, each CCN router can make the independent decision on selecting which face (interface) to forward an Interest packet. In case of a failure or crash of some node or link in the network, the adjacent router can detect
the problem and take a quick action to get around the failed area. As a result, the Interest forwarding only at that specific location is influenced by the network failure. This fundamentally differs from the way of the virtual circuit state in IP, where if a node or link fails or gets overloaded, the virtual circuit state needs to be re-established for the whole previously established connection between source and destination and thus there is no way for the intermediate nodes to change its forwarding decision to adapt to the dynamic network configuration change.
As mentioned previously, a CCN router forwards an incoming Interest packet according to the matching FIB entry by some forwarding strategy. The for- warding strategy can selects the current best face(s) based on statistical infor- mation, e.g., RTT, from all connected faces when making forwarding decisions.
Compared to IP forwarding, CCN forwarding can be more smart and adaptive because it can conduct fast fault detection and it is loop-free as well.
We will discuss further the CCN forwarding issue in Section 3.1 and propose a new FIB learning forwarding scheme in Chapter 4.
2.3.4 Routing
Defaultly, CCN routes and forwards packets by referring to packet names.
Therefore, CCN does not have address-related routing issues as in IP. For example, since namespace is unlimited, the address exhaustion problem as in IP does not exist in CCN. The network address translation (NAT) traversal problem does not exist either, because neither public nor private addresses are needed in the CCN routing system. Furthermore, CCN does not require address assignment and management any more in local area networks.
Conventional routing algorithms including distance-vector and link-state rout- ing protocols can be used in CCN. Instead of IP prefixes, CCN routers an- nounce name prefixes that they are willing to serve to the network. These an- nouncements are then propagated to update routing tables (FIBs) of routers in the network. Multiple routers can announce the same name prefix, leading to a routing method similar to anycast in IP. Traditional IP routing proto- cols such as Open Shortest Path First (OSPF) can be adapted to conduct name-based routing. OSPF for NDN (OSPFN) [54] is such an example.
Although CCN supports in-network caching or enables intermediate routers to cache incoming Data packets to facilitate subsequent data retrieval, it is still quite meaningful to have a routing policy when there is no data cached in the intermediate routers in the network. Actually, routing in CCN is important to guide the forwarding strategy to make wiser forwarding decisions to retrieve data effectively, and to probe new links or recovered links quickly. CCN routing does not have to converge fast to reflect network configuration changes, because adaptive forwarding can detect and handle the dynamic situations more promptly [61]. In other words, in CCN routing can support forwarding or provide an efficient starting point for forwarding so that forwarding can take the starting point as reference to take more efficient alternative forwarding actions. CCN routing benefits from forwarding as well since the demands on fast failure detection and network convergence delay could be relaxed. As a result, thanks to adaptive forwarding, the routing stability and scalability could be significantly improved in CCN.
We will discuss further the CCN routing issue in Section 3.2 and propose a new name-based routing mechanism in Chapter 5.
Related Work
This dissertation studies ICN forwarding and routing. In this chapter we collect a number of existing works related to this dissertation. Section 3.1 demontrates forwarding design and research directions in IP and ICN. Current popular ICN routing mechanisms are summarized in Section 3.2.
3.1 ICN Forwarding
In IP, the forwarding decisions strictly follow the routing state. However, there are already research efforts devoted to introducing adaptability to IP forward- ing. M. Caesar et al. [21] and D. Wendlandt et al. [55] advote that end hosts in the network should be provided with multiple forwarding path choices and capable of selecting alternative paths on the basis of the observed forwarding performance. The proposals such as Path Splicing [46], Routing Deflections
27
[57] and Pathlet Routing [32] cover different concrete designs and implemen- tations along this research direction. Their works focus on how alternative paths are determined and then used.
As one outstanding project of the ICN architectures, PURSUIT [29] con- structs its forwarding scheme on the basis of a publish/subscribe network de- sign, which is drastically different from the way in CCN. PURSUIT conducts packet forwarding based on source routing. Each packet header carries a bloom filter which encodes the forwarding path information to help routers to make forwarding decisions for incoming packets [40]. In case of network failures, the adaptability of PURSUIT is limited because it relies on pre-determined backup paths to resume delivering packets. Since the forwarding state is recorded in the packet, PURSUIT routers do not maintain any forwarding state as CCN routers do. Therefore, PURSUIT routers can not measure forwarding perfor- mance nor collect metric feedback to recover quickly from network failures as CCN routers do.
An Interest forwarding strategy is implemented in CCNx [2], which is an open source implementation of the CCN protocol. CCNx is currently deployed on the NDN Testbed [10], where some CCN applications, such as CCN Chat [64], Lighting Control [20], and CCN Video [43], are running. The successful deployment of CCNx on the NDN Testbed proves that the CCN architecture works well in real world communications. In CCNx, the forwarding strat- egy tries to send an incoming packet first through the RTT-shortest outgoing face (interface). If the corresponding Data packet is not received within an estimated RTT, the value of the estimated RTT is increased by 1/8 and the second RTT-shortest outgoing face (interface) is tried. Then if the correspond- ing Data packet still does not arrive, the rest of the faces (interfaces) are tried
one by one in the corresponding FIB entry until the reply Data packet re- turns. In the worst case, all available faces (interfaces) are needed to be tried.
If the corresponding Data packet is received through some face (interface), the estimated RTT value is decreased by 1/128. Therefore, the setting of the estimate RTT is essential to the performance of the forwarding algorithm in CCNx, as a large RTT value may lead to long failure recovery time while a small value could cause extra overhead in the network.
CCNx is designed to work without routing protocols, thus it is important to select the best forwarding algorithm to realize the best performance. First, because each CCNx router needs to periodically send extra probing Interest packets for each name prefix to learn about changes in the network, these periodical probing Interest packets lead to extra overhead, which may lead to waste of network resources when there is no change in the network. Second, since a CCNx router detects potential network failures and retries alternative faces (interfaces) one by one, the failure recovery time may be slow under some adverse situations. In other words, a new face (interface) would be tried only if the previous one is not available nor effective. The BestRoute [59]
[60] proposal is another adaptive forwarding strategy similar to the way in CCNx. We will show in Chapter 4 that each available face (interface) always has a chance to be tried for forwarding incoming packets in our proposed FIB learning forwarding mechanism.
3.2 ICN Routing
As mentioned previously, conventional routing algorithms such as distance vector and link state could be applied into CCN. Instead of announcing IP
prefixes, a CCN router announces name prefixes which it is willing to serve.
These announcements are propagated among routers in the network to con- struct their FIBs. Conventional routing protocols, such as OSPF and BGP, can be adapted to route on name prefixes by performing longest prefix match (LPM) of an Interest name in the FIB.
The first routing protocol for CCN is an OSPF extension, OSPFN [54], which defines a new type of link state advertisement that announces name prefixes and helps routers to build FIBs. However, this simple adaptation of an IP- based routing protocol has obvious limitations, e.g., managing underlying IP addresses and supporting only single path forwarding. CCN natively supports name-based multi-path forwarding.
A newly designed routing protocol for CCN is NDN-based link-state rout- ing (NLSR) [35], which uses names to identify networks, routers, data, and keys. NLSR uses an underlying communication channel, e.g., Ethernet, IP, to exchange routing messages. The routing updates are encapsulated in Data packets that are signed by the data providers to allow verification of authen- ticity. To retrieve the routing updates, routers send Interest packets. Different from OSPFN, NLSR supports adaptive multi-path forwarding for each name prefix.
The shift from OSPFN to NLSR shows the routing protocol evolution in CCN research works. There are also other researches or proposals on routing schemes which can be applied in CCN. Their works are introduced below.
A two-layer routing protocol [23] in CCN is proposed. The underlying layer is called Topology Maintaining (TM) layer, which maintains network topology information and calculates the shortest-path tree rooted at each node. The
TM layer provides the calculated shortest-path information to its upper layer which is called Prefix Announcing (PA) layer. The PA layer runs above the TM layer and announces data name prefixes that the router wants to serve in the network. Along the maintained shortest-path tree rooted at this node, the announcements can be efficiently delivered to all the other routers and thus help them construct the FIBs.
A good routing design should cover mobility management. Especially mobile devices such as smart phones and tablet PCs are becoming increasingly pop- ular in today’s daily lives, thus the mobility issue becomes a major concern in the current CCN research field.
We will show in Chapter 5 that our proposed name-based routing protocol essentially observes the standard CCN scheme and extends it. The new ap- proach can handle multiple routes because it has explicit routing information that can be dealt with explicitly by our new naming scheme. It realizes effi- cient mobility support as well. Section 5.3 gives a detailed discussion on the related works in CCN mobility and presents a comparative table between our proposal and them.
Forwarding by Learning
In CCN, data names are carried in packets without specifying IP addresses.
This change leads to a new network forwarding model: CCN routers for- ward Interest (request) and Data packets using only their names. One major challenge is realizing intelligent forwarding of Interest packets over multiple available paths according to a FIB, which is typically configured manually with static routes. In this chapter, to address this issue, we propose a new FIB learning method by extending the current CCN prototype. With this new method, FIB entries can be automatically generated based on earlier successful data retrievals. We demonstrate that the proposed FIB learning forwarding mechanism is efficient and self-adaptive in adverse conditions such as link failure. This chapter also illustrates an application example to demonstrate resilience when handling mobile nodes and effectiveness in changing network configurations.
The remainder of this chapter is organized as follows. Section 4.1 presents the motivation of our work in this chapter. Section 4.2 proposes our new method.
Section 4.3 examines an experiment to evaluate the new method. Section 32
4.4 gives a discussion about the new method and Section 4.5 concludes this chapter.
4.1 Motivation
According to a recent prediction [22], global traffic in IP would reach nearly 1000 exabytes per year by 2015. The increase will be mostly attributed to peer-to-peer (P2P) communications and various forms of video traffic, such as TV and video on demand (VoD) services, which will account for approximately 90% of global consumer IP traffic. Global mobile data traffic is also expected to enormously grow in the same time frame.
To deal with the problems caused by the enormous growth of data and de- vices, one solution is to deploy application-layer add-on systems such as P2P applications and Content Delivery Networks (CDNs) [47] that cache content, to provide location independent access to data, and to optimize the delivery of data. These solutions may provide access to objects or named data, includ- ing replicated web resources, rather than the traditional end-to-end packet delivery pattern. However, these techniques would reside in overlay networks and it is difficult to reach the full potential of content-based distribution in today’s IP-based platform.
CCN is a new network architecture that takes objects or named data as the first-class network entity [38] [62]. It aims to use location-independent naming and in-network caching to utilize network resources more efficiently. CCN will shift address space from one billion IPs to at least one trillion content names [15]. CCN is perceived as an extension of CDN solutions, and CCN
deployment is feasible on a scale similar to CDN [48]. In addition, CCN can be utilized not only for media distribution scenarios, but also for other scenarios such as data collection.
There are two message types in CCN: Interest and Data (Content), as shown in Figure 4.1. The Interest message is used to request data by name. Data (also called Content or Content Object) carries the requested data. An Interest message should identify a data chunk (piece) to retrieve it by specifying a full name or a name prefix with other restrictions that indicate acceptable data.
A Data (Content Object) message contains a data payload, the identifying name of the data chunk, and the identification of the publisher.
Figure 4.1 illustrates a CCN node that contains the following data structures to provide ubiquitous caching and loop-free forwarding: content store (CS), in- terface (Face), forwarding information base (FIB), and pending interest table (PIT).
䍜
䍜
Face1
Consumer
Consumer Provider Provider
Face 0 Face 1
Face 2
Interest
CCN node
Data FIB
PIT
CS CS Data
Interest
new
䍜
䍜
䠖
Figure 4.1: CCN packet processing
The CS is a cache storage that maintains content or objects for future retrieval through lookup by names. It is implemented using popular cache replacement algorithms [28] [27] that maximize the possibility of data reuse, such as Least Recently Used (LRU), Least Frequently Used (LFU), and First-in First-out (FIFO). The Face is a generalization of the concept of interface. A face is a connection to a hardware communication link or to a software application process running on the same host as the CCN node. The FIB is a table that maintains outbound face information for Interests. These tables are used for longest-match prefix lookup by name. Each FIB prefix entry has a set of corresponding faces rather than a single face. The PIT is a table for recording unsatisfied (pending) Interests. Each entry in the PIT has a list of source entries represented by incoming faces to the CCN node. The PIT has a timeout interval for unsuccessful Interest requests to avoid maintaining old Interest records indefinitely.
Information-centric network architecture has been developed in Europe as well as in US. PSIRP/PURSUIT [26] [13] preforms forwarding information in packets, while CCN stores routing information in CCN nodes. In CCN, Interest packets are forwarded following the FIB, while Data packets are for- warded according to the PIT which guides Data packets back to consumers or requesting users. Thus, an excellent design of the FIB is essential for both Interest and Data packets transferred in CCN.
4.2 Proposed Method
4.2.1 Forwarding Interest Base
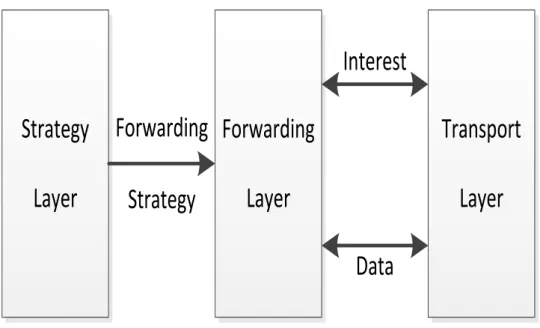
In CCN, an FIB has multiple outbound faces or next-hop destinations. We need an intelligent forwarding strategy to select the best face among multiple faces according to some selection algorithm. Designing a scalable forwarding plan is essential for deploying CCN on a large scale. A popular CCN soft- ware prototype, CCNx [2], has been developed at PARC. The key component of CCNx is called the ccnd daemon, which implements a packet forwarding function. In the latest version of CCNx (0.7.1), the FIB still needs to be configured manually with static routes, which is appropriate for small exper- imental networks. However, manual configuration causes significant trouble or Inefficiency in larger networks. We require more sophisticated mechanisms to manage the FIB forwarding entries. Classical routing algorithms, such as OSPF [12], are possible solutions for this issue. However, OSPF, for example, does not make the best use of cached content (Data) records in the CS.
There are several factors to consider when designing or devising CCN forward- ing strategies. Because CCN is not aware of host location or address, pure source routing, which is popular in IP-based networking, is not feasible. CCN does not specify paths. It specifies only faces, therefore, it only determines the face to which an Interest packet is forwarded. Forwarding strategies should adhere to CCN forwarding principles and should maintain the balance of traf- fic because there is a one-to-one correspondence between Interest and Data packets.
Strategy Layer
Forwarding Layer
Transport Layer Forwarding
Strategy
Interest
Data
䍜
䍜
Face1
䍜
䍜
Figure 4.2: CCN forwarding plane
A scalable forwarding plane is essential for deploying CCN in a large scale to demonstrate its real-world feasibility. Figure 4.2 shows the forwarding plane of CCN. The strategy layer is responsible for making packet forwarding decisions. The forwarding layer follows the decisions to lookup the packet name prefix and its corresponding face(s) in the FIB. Packet transfer and network communication is handled by the transport layer.
4.2.2 Method for Forwarding Interest Packets
We focus on two issues in our proposal. The first issue is how to construct FIB entries with a name prefix and face entries. The second is how to forward Interests to potential content providers or holders according to the FIB entries.
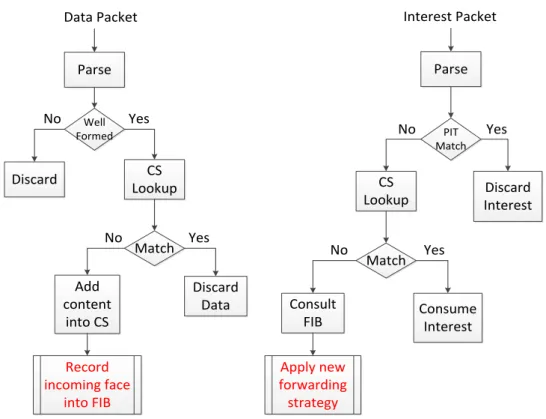
The proposal is built on the standard CCN technique. Figure 4.3 illustrates the whole processing procedure with applying the new forwarding mechanism.
Chapter 4. Forwarding by Learning 38
䍜
䍜 䍜
䍜
Data Packet
Parse
Well Formed
Discard CS
Lookup
No Yes
Match Add
content into CS
Discard Data
No Yes
Record incoming face
into FIB
Interest Packet
Parse
PIT Match
Discard Interest
Yes No
CS Lookup
Match Consult
FIB Consume
Interest
No Yes
Apply new forwarding strategy
Figure 4.3: Processing procedure with the new forwarding mechanism
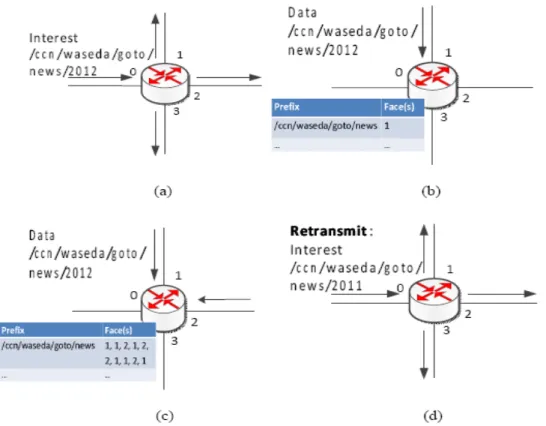
The proposed FIB learning makes forwarding decisions based on FIB lookup results and the network environment such as response time. This FIB learning method is based on the statistics of incoming successful Data packets. It still maintains a persistent ability to send Interests to a new face. Therefore, un- balanced traffic distribution is unlikely in the new FIB learning mechanism. It also responds quickly to changing network configurations in CCN. Figures 4.4 (a), (b), (c), and (d) show the steps in the proposed FIB learning mechanism.
[a] Arrival of New Interest
At the initial stage, the FIB on each CCN node is empty. An incoming Interest packet at Face 0 is propagated to all Faces (1, 2, and 3) except the incoming Face 0. This is an initial flooding.
[b] Arrival of the First Data Packet
Figure 4.4: Learning Forwarding Information Base
When the first Data packet arrives, the corresponding FIB entry is created.
The prefix of the Data name is stored in the Prefix field and the arrival face of the Data is recorded in the Face(s) field, which can maintain N maximum elements (faces).
[c] Arrival of Data Packet with the Same Prefix
When a Data packet with the same name prefix as an existing entry in the FIB arrives, the arrival face will be added to the corresponding Face(s). If N faces are already stored in the set of Face(s), a FIFO operation is performed.
That means that the first oldest arrival face will be deleted.
[d] Interest Forwarding Principle
When a new Interest packet arrives that matches Prefix entries in the FIB, Interest forwarding is performed by selecting one face among the elements
in Face(s) according to the occurrence ratio of the faces. That is, the most successful face is selected. Since the FIB can maintain at most N faces, the learning mechanism adjusts the face selection according to the recent data retrievals. In the case of link failure or packet loss, Data does not return within the timeout period; therefore, the data requester or user returns to step [a], flooding the Interest to all available connected faces to discover a working path quickly.
4.3 Evaluation of the Proposed Method
We design three evaluation scenarios to examine the effectiveness and effi- ciency of the proposed FIB learning forwarding mechanism. The simula- tions evaluate how well the FIB learning forwarding mechanism performs and whether it deliveries packets robustly even under adverse conditions and with changing network configurations. The experimental simulations are conducted in a NS-3 based environment, ndnSIM [11] [17].
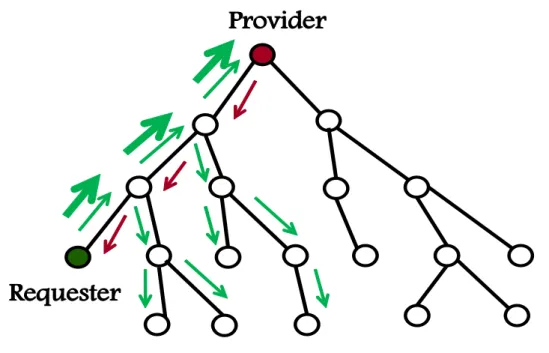
4.3.1 Space and Time Tradeoff
We compare the FIB learning mechanism with a flooding method where the router simply forwards incoming Interest packets to each connected face. In the tree topology, shown in Figure 4.5, the data Requester or consumer at the leftmost node requests data from the data Provider at the topmost root node by issuing 100 Interests per second. The data Provider returns 1024-byte data as a response to each data request. The experiment lasted for 3 seconds.
933/0&=&933/1&=&933/<
933/0&=&933/1&=&933/< 933/0&=&933/1&=&933/< 933/0&=&933/1&=&933/<
9$:"$4!$.
9$:"$4!$. 9$:"$4!$. 9$:"$4!$.
*.);(#$.
*.);(#$.
*.);(#$. *.);(#$.
Figure 4.5: Topology
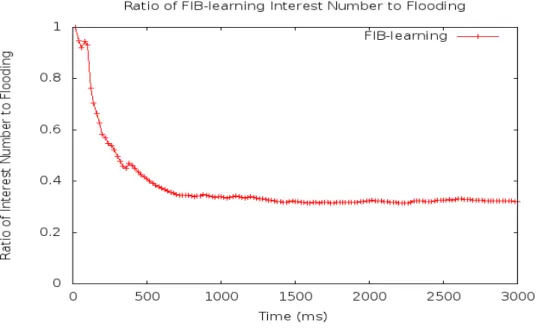
Figure 4.6 shows the results. The vertical axis represents the ratio of the number of forwarded Interest packets to the total number of flooding Interest packets. The proposed FIB learning mechanism forwards a smaller number of Interest packets compared to the simple flooding method. The simple flooding method forwards an incoming Interest packet to all available connected faces (thin green arrows). The Provider returns the required Data packet following the reverse path (red arrows). The FIB learning mechanism gradually learns the most efficient route (thick green arrows) from the initial flooding strat- egy and reaches a stable advantageous space occupancy in a short time, i.e., approximately 700 ms.
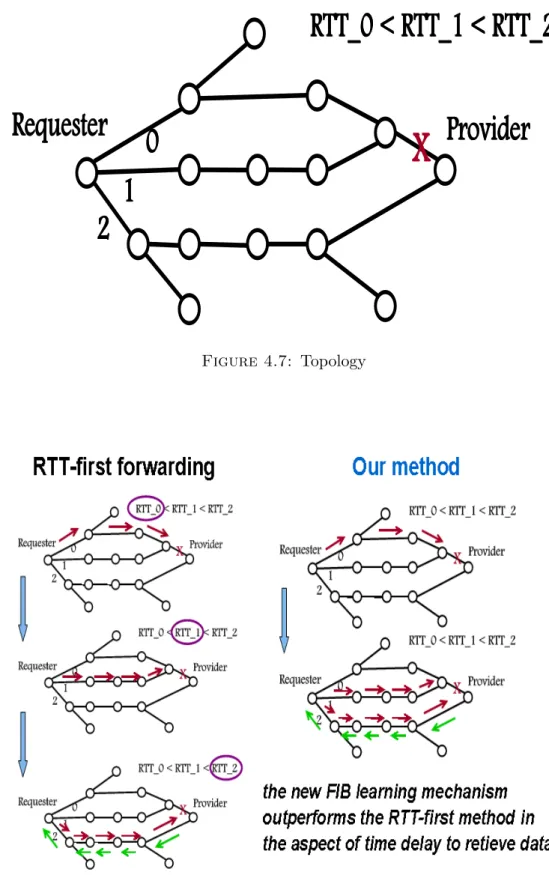
4.3.2 Link Failure
We compare the FIB learning mechanism with the RTT-first method [17] when a link failure occurred in the network during the data transfer as shown in Figure 4.7. The RTT-first algorithm always selects the single face that shows
Figure 4.6: Forwarded Interest packets and total flooded packets
the shortest Round Trip Time (RTT) among available outgoing faces. If a link failure occurs on the RTT-first path, the data consumer will select the face with the second shortest RTT value as the Interest forwarding face. The new FIB learning mechanism reverts to the initial flooding strategy [a] in Section 4.2.2 if the data is not received within the timeout period. Failure to receive data prior to timeout indicates a link failure. The FIB mechanism detects a link failure and attempts to learn a new working face among connected faces.
In this experiment, the timeout period is set to 200 ms.
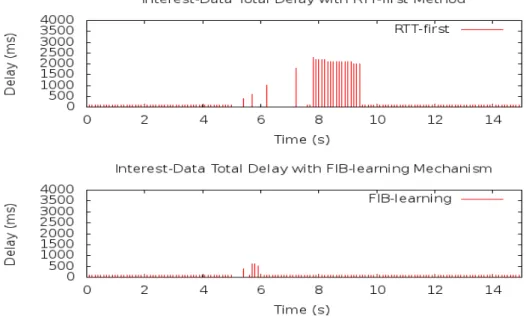
Figure 4.8 illustrates the impressive comparison between the RTT-first method and our proposal. The new FIB learning mechanism should outperform the RTT-first method in the aspect of time delay to retrieve data in case of a link failure. We conduct the following evaluation under such a situation.
We assume that the data consumer continuously issues 10 Interests per second for 10 seconds. The data Provider returns the Data with a 1024-byte payload for each Interest. Suppose that a link failure, denoted by X in Figure 4.7,
9$:"$4!$.
9$:"$4!$. 9$:"$4!$. 9$:"$4!$. 0000 *.);(#$. *.);(#$. *.);(#$. *.);(#$.
1111
<<<<
933/0&=&933/1&=&933/<
933/0&=&933/1&=&933/< 933/0&=&933/1&=&933/< 933/0&=&933/1&=&933/<
>>>>
Figure 4.7: Topology
Figure 4.8: RTT-first method and our method in case of a link failure
occurs 5 seconds after Interests are initiated. Figure 4.9 shows that the new FIB learning mechanism outperforms the RTT-first method; the FIB learn- ing mechanism recovers more quickly from a link failure in such a scenario.
It requires less time to learn an alternative working face for forwarding the succeeding Interests. Total delay refers to the time between the first Interest sent and Data received, including Interest retransmission time.
Figure 4.9: Delay between first Interest sent and Data received
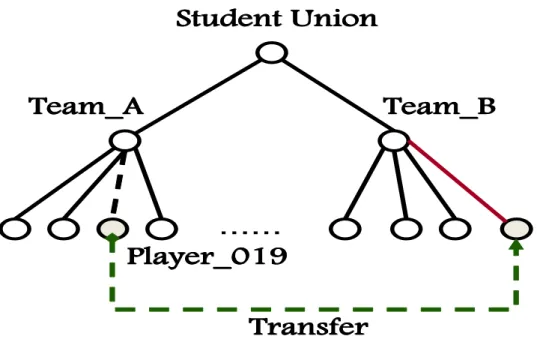
4.3.3 Application
A practical application of the FIB learning mechanism is exemplified. Assume that Student Unions (SUs) from two friendly universities hold an annual foot- ball game. Each player belongs to one team (Team A or Team B). Each player has a unique registered number, e.g., /Football Game/Player No. Each SU can retrieve a variety of statistical information for each player. For example,