平成 29 年度修士論文
シミュレーションにもとづく
ES バックテスティング手法の比較分析
首都大学東京大学院
社会科学研究科 経営学専攻 学修番号 16877271
小松 勇介
指導教員 室町幸雄教授
2018 年 1 月
【要旨】
2016
年1
月にバーゼル委員会が公表した資料の中で,資本計算のリスク指標がVaR(
バリュー・アット・リ スク)
からES
(期待ショートフォール)
へと変更されているように,近年ではES
への注目が高まっている.VaR
は概念的なわかりやすさ,計算の簡便さなどから金融機関のリスク管理実務で最も標準的に使用されて いるが,劣加法性を持たず,テールリスクを捉えることができないなど,リスク指標として幾つかの欠点を抱 えている.一方ES
は,これらの問題点を内包せず,VaR
よりも優れたリスク指標であると考えられている が,バックテスティングの構成が難しいという欠点が指摘されてきた.そこで,本研究ではES
のバックテス ティング手法について検討する.ES
のバックテスティングの構成は難しいとはいえ実際には可能であり,す でに幾つかの手法が提案されている.本論文では,理論的な制約が少なく,リスク管理実務での適用に適して いると思われるKratz et al. (2016)
とAcerbi et al. (2014, 2017)
によるノンパラメトリックアプローチに 焦点をあてて分析する.Kratz et al. (2016)
は,複数の異なる信頼水準のVaR
を同時にバックテスティング することで,間接的にES
のバックテスティングをおこなう.Acerbi et al. (2014, 2017)
は,モンテカルロ シミュレーションにより仮説検定のp
値を計算する.本論文では,これらの検定の有効性や性質を同じ枠組み の下で数値的に調査し,実務において最も有効な検定について検討し考察する.実務のリスク管理手順を模倣 した数値実験からは,正規分布を使用しているためリスクを過小評価するモデルを検出する場合,Acerbi et
al. (2014, 2017)
が提案した手法の一つが優れた性能を示すことがわかった.目次
1
はじめに3
2 ES
バックテスティングの既存研究6
2.1 VaR
,ES
の定義. . . . 6
2.2
バックテスティングとは. . . . 7
2.3 VaR
バックテスティング. . . . 7
2.4 ES
バックテスティング1 : Kratz et al. (2016)
によるアプローチ. . . . 8
2.5 ES
バックテスティング2 : Acerbi et al. (2014
,2017)
によるアプローチ. . . . 11
2.6 Kratz
アプローチとAcerbi
アプローチの比較. . . . 18
3
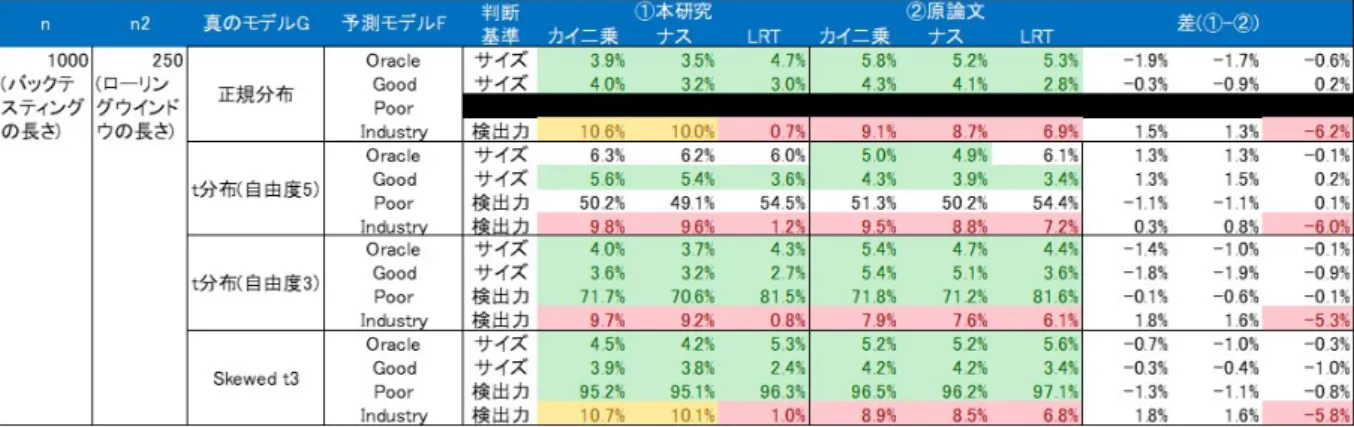
静的バックテスティング実験20 3.1
実験設定. . . . 20
3.2
結果. . . . 21
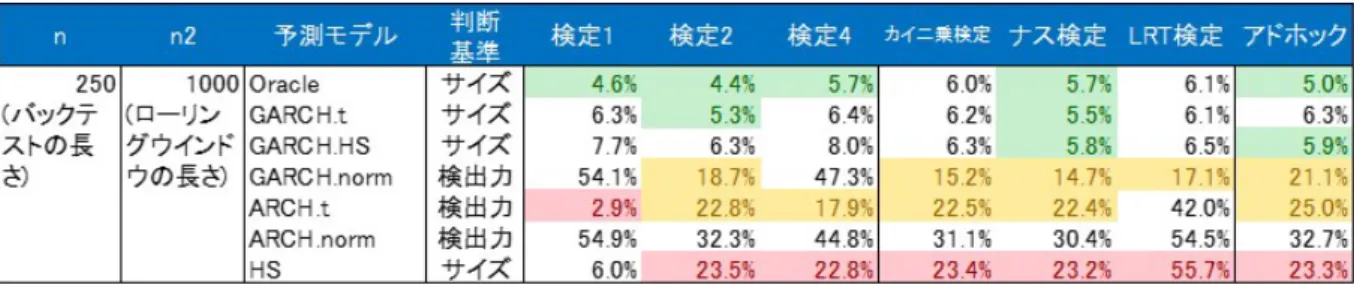
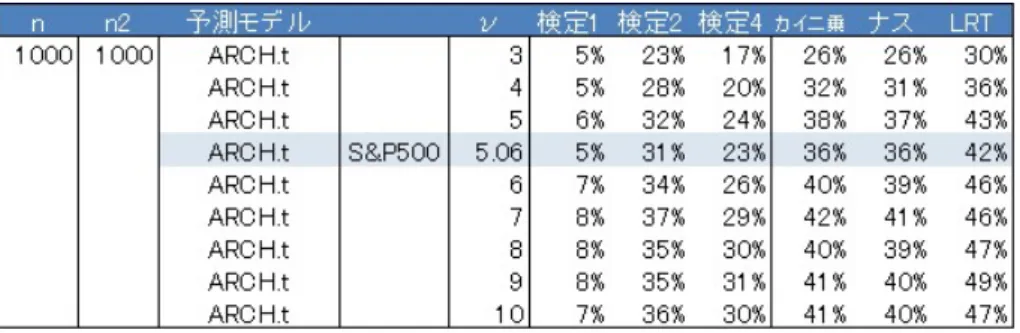
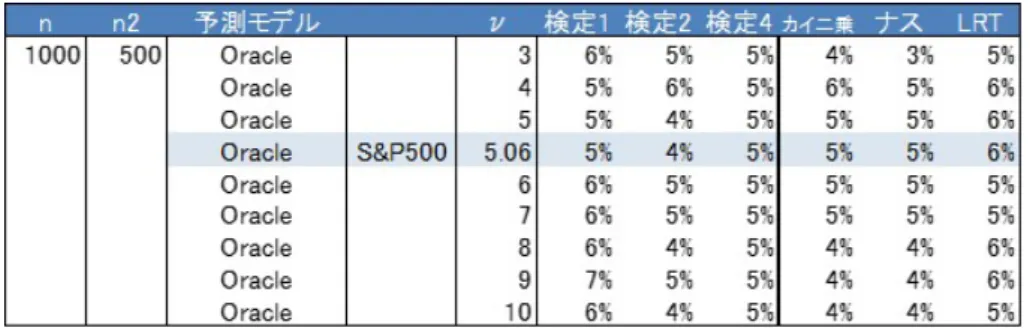
4
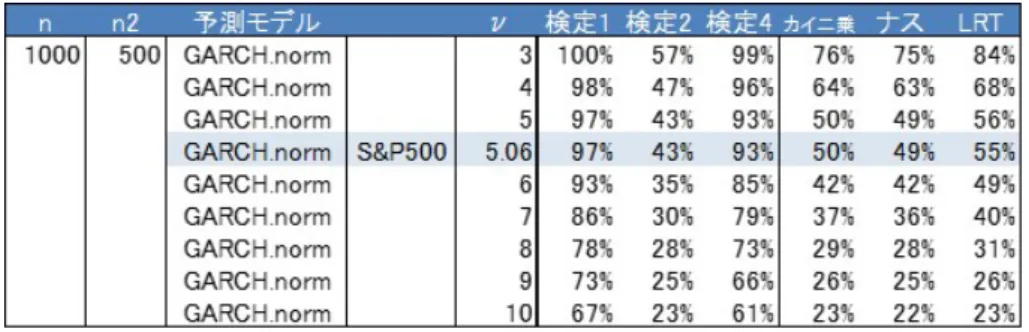
動的バックテスティング実験27 4.1 S&P500 . . . . 27
4.2
イノベーションの自由度に対するES
バックテスティングの頑健性. . . . 30
4.3
様々な金融資産に対するES
バックテスティングの頑健性. . . . 34
5
実データへの適用39 6
両側検定41 6.1
両側検定の可否. . . . 41
6.2
実験. . . . 44
7
結論50 8
謝辞52 9 Appendix 53 9.1
多項分布. . . . 53
9.2 Skewed t
分布. . . . 53
9.3
エリシタブル. . . . 53
9.4
エクスペクタイル. . . . 54
1 はじめに
2016
年1
月にバーゼル委員会により公表された,マーケット・リスクの最低所要自己資本(Basel Committee (2016))
で,資本計算のリスク指標がVaR(
バリュー・アット・リスク)
からES
(期待ショートフォール)
へと 変更されているように,近年ではES
への注目が高まっている.VaR
やES
などのリスク指標は,確率分布として表される将来の損失予測を1
つの数値に要約したものであ る.このようなリスク指標としては,他にも分散や標準偏差などが挙げられる.VaR
は概念的なわかりやす さ,計算の簡便さなどから金融機関のリスク管理実務で最も標準的に使用されているが,VaR
はリスク指標 としての欠点を抱えており,しばしば批判される.よく言われる欠点は,VaR
はポートフォリオの分散効果 を常に適切に表現できるとは限らないということである.例えば,デフォルト確率が0.7%
の企業に10
億円 融資するポートフォリオA
と,同じ確率でデフォルトが独立に発生する企業2
社に5
億円ずつ融資するポー トフォリオB
を考える.一般的にはポートフォリオB
のほうがリスクは低いと考えられるが,信頼水準が99%
のVaR
を計算すると,ポートフォリオA
のVaR
は0
円,ポートフォリオB
のVaR
は5
億円となる.つまり
VaR
をリスク指標として使うと,ポートフォリオB
のほうがリスクは高いということになる.この直 観に反する結果は,VaR
はその定義上,信頼区間外のリスクを捉えられないことに起因する.このようによく使われている
VaR
のようなリスク指標でも,それがリスク管理上の直観に合致するとは限 らない.リスク指標がもつべき合理的な性質を公理として整理し議論したのがAltzner et al. (1999)
である.Altzner et al. (1999)
はリスク指標が満たすべき性質として,1.
単調性(monotonicity) : X ≥ Y ⇒ ρ(X ) ≤ ρ(Y )
2.
移動不変性(translation invariance) : ρ(X + k) = ρ(X ) − k k
は定数3.
正の1
次同次性(positive homogeneity) : ρ(λX) = λρ(X), λ ≥ 0 4.
劣加法性(subadditivity) : ρ(X + Y ) ≤ ρ(X) + ρ(Y )
を挙げ,これらの性質を満たすリスク指標をコヒレント・リスク指標と呼んだ.
X, Y
はポートフォリオの損 益を表す確率変数,ρ(X ), ρ(Y )
がリスク指標である.劣加法性とは,「リスク指標はポートフォリオ分散によ るリスク削減効果を織り込むべき」という考え方を表現したものであり,VaR
はこの性質を常に満たすとは 限らない.一方,
ES
はコヒレントなリスク指標である.簡潔に言うと,VaR
は損失分布の分位点(
一定の確率で発生 しうる最大損失額)
として定義されるが,ES
は損失額がVaR
以上となることを条件とした損失額の条件付期 待値として定義される.ES
はVaR
の劣加法性を満たさないという欠点を克服しており,理論的にはVaR
よ り優れたリスク指標であると考えられている.しかしリスク指標をリスク管理実務で使う場合には,理論的な性質の良さ以外にも,様々な観点を考慮する 必要がある.最も不可欠な点は,リスク指標を正しく推定できることと,推定したリスク指標の有効性を事後 に観測された損失から確認できることである.リスク指標の推定に関しては,損失分布の裾部分での条件的期 待値を扱う
ES
は,裾部分の分位点を扱うVaR
よりも正確に推定することが難しい.そしてもう一方のリス ク指標の有効性の確認が,本研究で扱うテーマである.事前に予測したリスク指標の予測値と,事後に観測し た損失を比較することによって,リスク管理の手順を評価することはバックテスティングと呼ばれる.VaR
のバックテスティングを構成することは容易であるが,ES
のバックテスティングを構成することは難しいこ とが知られている.2011
年には,Gneiting (2011)
がES
はエリシタブル(elicitable)
でないことを示した.詳細は9.3
節で述 べるが,エリシタブルとはある種の最適化問題の解としてリスク指標が表現できることを指す.そのような表 現を使えば,様々なモデルから推定したリスク指標を直接比較することができ,モデルの優劣を検討するこ とができる.そして,この議論の中で,ES
のバックテスティングを構成することは,そもそも不可能ではな いのかという疑問が生じた.その後,Acerbi et al. (2017)
が,バックテスティング可能な統計量のフォーマ ルな定義を提案し,エリシタブルとバックテスト可能性は異なる概念であることが示されて,理論的にはこ の問題は解決した.しかしながらES
バックテスティングの構成が難しいという点は変わらない.エリシタ ブルの定義や,この議論の中で注目されたエクスペクタイル(expectile)
というリスク指標については9
節のAppendix
に簡単な説明を載せた.VaR
のバックテスティングに関する文献は多い.例えばKupiec (1995)
やChristoffersen (1998)
などがあ る.Christoffersen (1998)
は,VaR
の予測モデルが正確であるかどうかを判定することは,事後的に実現し た損失がVaR
を超過するか否かの事象の時系列(
以下,VaR
超過時系列と呼ぶ)
が「無条件カバレッジ仮説」「独立性仮説」を満たしているかどうかを判定することに単純化できると述べた.
VaR
バックテスティングの 多くは,VaR
超過時系列がこの2
つ(
または1
つ)
の仮説を満たしているか否かを調べることで,予測モデル の正確性を判定している*1.バーセル規制のトラフィックライトシステムも,この考え方をもとにしている.ES
のバックテスティングに関する文献はVaR
に比べてはるかに少ないが,すでにいくつかの方法が提案さ れている.McNeil et al. (2000)
は残差アプローチと呼ばれる手法を提案し,Kerkhof et al. (2004)
は確率積 分変換(probability-integral-transform, PIT)
にもとづく方法を提案したが,これらの手法が有効に働くには 大標本が必要であり,あまり多くの標本数を確保できない実務では活用することが難しい.Wong (2008)
は 按点技術を使ったパラメトリックな方法を提案した.この手法は小標本でも良い結果を出力するが,損益分布 に正規分布を仮定するなどモデルに対する制約が強く,これも実務では好ましくない.パラメトリックな手法 は他にもRighi et al. (2013)
による方法が挙げられるが,これも依然として制約が強い.ところが近年,
Kratz et al. (2016)
やAcerbi et al. (2014, 2017)
が注目すべきES
のバックテスティング 手法を提案した.これらの手法はノンパラメトリックな検定であり,理論的な制約が少なく,実際のリスク管 理実務に適していると考えられる.なお,実務で有望な手法として他にもCostanzino et al. (2015)
による方 法も挙げられるが,この手法の検討は後日行いたいと考えている.このように
ES
バックテスティングの構成は難しいながらも様々な手法が提案されているが,学者や実務家 の間でコンセンサスを得られた手法はまだ存在しない.これは,各ES
バックテスティングの有効性や性質(
長所,短所)
が十分に整理されていないためと考えられる.本論文では,理論的な制約が少なく,実務に適していると考えられる
Kratz et al. (2016)
とAcerbi et al.
(2014, 2017)
によるノンパラメトリックなアプローチに焦点をあてる.この2
つのアプローチには様々な検定が含まれる.これらの検定の有効性や性質を同じ枠組みの下で調査をし,実務において最も有効な検定は何 かを検討する.具体的には,
(1)
どのような状況でどの手法が最も優れているのか,それぞれの手法の特性を分析する.(2)
そのうえで,実務において好ましい手法はどれか.(3)
リスク量が保守的すぎる(過大評価する)モデルを検出する両側検定に適した手法はどれか.を調べる.特に
(1)
では,実際に用いる時系列データは独立でないと考えられるため,この点に注目した分析*1この2つの仮説を同時に満たす場合,VaR超過時系列は互いに独立なベルヌーイ試行の列になる.
を行う.
(3)
は,バーセル規制の根底には,過度に保守的なモデルも望ましくないという考えがあると思われ ることから生じる.Acerbi et al. (2014, 2017)
によるアプローチはリスク量を過小評価するモデルのみを排 除する片側検定であり,そのままでは過度に保守的なモデルを排除することはできない.そこでAcerbi et al.
(2014, 2017)
によるアプローチが両側検定に拡張できるかどうかも検討する.本論文の構成は以下の通りである.まず
2
節では,バックテスティングとは何か,なぜバックテスティング は難しいのかを説明し,本論文で焦点を当てるKratz et al. (2016)
とAcerbi et al. (2014, 2017)
によるノン パラメトリックなアプローチについて概観する.3
節では,損益のデータ生成構造が時間と共に変化しない静 的な状況を想定し,各ES
バックテスティング手法の有効性や性質を調べる.4
節では,損益のデータ生成構 造に時系列構造がある状況を想定し,各ES
バックテスティングの有効性や性質を調べる.5
節では,実デー タに対してES
バックテスティングを適用する.6
節では,Acerbi et al. (2014, 2017)
によるアプローチが両 側検定に拡張できるかどうかを調べ,7
節で結論を述べる.2 ES バックテスティングの既存研究
本節では
ES
バックテスティングの既存研究を紹介する.はじめにVaR
,ES
の定義を示し,次にバック テスティングについて説明する.そしてバーゼル規制にも関連する,有名なVaR
バックテスティングを紹介 した後,本論文で焦点を当てているES
バックテスティングのKratz et al. (2016)
とAcerbi et al. (2014,
2017)
によるアプローチを説明し,この2
つのアプローチを比較検討する.2.1 VaR
,ES
の定義はじめに
VaR
,ES
の定義を述べる.VaR
は金融機関のリスク管理で幅広く使われているリスク指標であ り,バーゼル規制でも大きな役割を担っている.まず分布関数F
の一般化逆関数F
←をF
←(y) := inf { x ∈ R : F(x) ≥ y } (2.1)
と定義する.一般化逆関数F
←を使うと,分布関数F
のα
分位点はq
α(F) := F
←(α)
で与えられる.この 表記を使うと,VaR
の定義は以下のようになる.定義
2.1 VaR
信頼水準を
α ∈ (0, 1)
,ポートフォリオの損失L
の分布関数をF
Lとする.このとき信頼水準α
のVaR
α(L)
は,VaR
α(L) := F
L←(α) (2.2)
として与えられる.
簡潔に述べれば,
VaR
は損失分布の分位点である.信頼水準にはα = 0.99
がよく使われる.ES
は,劣加法性を満たさないというVaR
の欠点を克服しており,理論的にはVaR
より優れたリスク指標 であると考えられている.ES
の定義は以下のようになる.定義
2.2 ES
損失
L
の分布関数をF
Lとする.さらにE( | L | ) < ∞
とする.信頼水準α
のES
α(L)
は,ES
α(L) = 1 1 − α
∫
1 αq
u(F
L)du (2.3)
として与えられる.
E( | L | ) < ∞
は,(2.3)
式の積分がwell defined
であることを保証する.これらの定義により,ES
とVaR
にはES
α(L) = 1 1 − α
∫
1 αVaR
u(L)du (2.4)
という関係がある.
ES
はα
を超える信頼水準のVaR
の平均値である.これがES
はテールリスクを捕捉し ていると言われる所以である.損失分布が連続の場合は,より直感的な表現で
ES
をあらわすことができる.補題
2.1
損失L
の分布関数F
Lが連続と仮定する.このとき信頼水準α
のES
α(L)
は,ES
α(L) = E[L | L ≥ VaR
α(L)] (2.5)
として与えられる.これは「
ES
はα
を超える信頼水準のVaR
の平均値」という解釈により近い表現である.2.2
バックテスティングとはバックテスティングとは,事前に予測したリスク指標の推定量と事後に実際に実現した損失や収益を比較す ることによって,リスク計測手順を評価することである.バックテスティングを行うことで,与えられたリス ク指標の推定手順(つまり予測モデル)が,信頼できるリスク指標の推定値を出力するか否かという疑問に答 えることができる.
リスク指標には
VaR
,ES
,標準偏差などが挙げられるが,これらに対してバックテスティングを行うこと は,単純ではない.その理由を競馬の予想を例に説明する.1
年を通して,1
着になる馬を都度予想すること を考える.1
年後に,あなたの予想の精度を評価することは簡単である.なぜならばレース終了後に,毎回,1
着となった馬が公に宣言されるからである.公に宣言された内容と,自らの予想を比較することで,予想精 度を簡単に評価することができる.しかしリスク指標のバックテスティングの場合,予想精度の評価は競馬予想のように簡単ではない.日々,
翌日の
ES
を予想するという例から説明する.将来の損失分布をF
tとし,そのES
をES
Ft とする.競馬予想 と対応させると,将来の損失分布F
tは競馬のレースに対応し,ES
Ftは1
着になる馬に対応する.仮に私達 が日々ES
Ft に対する予想を行ったとしても,予想精度を評価することは難しい.なぜならば,F
tもES
Ftも 日々の終わりに観測することができないからである.私達が日々観測できるものは,(
未知の)
真の損失分布F
tからのたった1つの実現値だけである(
図1
参照)
.これがリスク指標のバックテスティングを構成するこ とが難しい理由である.基本的にはリスク指標のバックテストを構成することは単純ではない.バックテスティングの構成が容易な
VaR
は特別なケースである.図
1
2.3 VaR
バックテスティングVaR
のバックテスティングとしてよく使われる方法は,二項分布を用いてVaR
超過回数を評価する方法で ある.バーゼル規制によるVaR
バックテスティングもこの方法をもとにしている.事前に予測した信頼水準α(
例えば,α = 0.99)
のVaR
をV aR
α,t,事後に実現した損失をL
tとする.そして損失がVaR
を超過した かどうかを示す違反インディケータをI
t,α:= 1
{Lt>VaRα,t}(2.6)
と定義する.
1
Aは定義関数であり,事象A
がおきたら1
を,さもなくば0
をとる.違反インディケータの列 は,例えば(1, 0, 0, 1, 1, 0, . . . , 0)
となる.これは日々の損失がVaR
を超過したか否かを記録したものである.Christoffersen (1998)
は,VaR
の予測モデルが正確であるかどうかを判定することは,違反インディケータの列
{ I
t,α, t = 1, . . . , n }
が,以下の2
つの仮説を満たしているかどうかを判定することに単純化できると 述べた.•
無条件カバレッジ仮説(unconditional coverage hypothesis) : E[I
t,α] = 1 − α,
∀t
•
独立性仮説(independence hypothesis) : s ̸ = t
ならばI
t,αとI
s,αは独立.VaR
バックテスティングに関する多くの手法は,違反インディケータの列がこの2
つ(
または1
つ)
の仮説を 満たしているかどうかを調べることで,VaR
予測モデルが正確であるかどうかを判定している.この
2
つの仮説を同時に満たす場合,違反数I
α= ∑
nt=1
I
t,αはI
α∼ B(n, 1 − α) (2.7)
となる.
B(n, 1 − α)
は成功確率が1 − α
,試行数がn
の二項分布を表す.二項分布を用いてVaR
超過回数を 評価する手法では,(2.7)
式から仮説検定のp
値を計算する.例えば,VaR
超過回数がk
回ならば,p
値はp
k=
∑
k i=0P (I
α= k) =
∑
k i=0n
C
i(1 − α)
iα
n−i(2.8)
となる.2.4 ES
バックテスティング1 : Kratz et al. (2016)
によるアプローチ本節では
Kratz et al. (2016)
により提案されたES
バックテスティング(以下,Kratz
アプローチと呼ぶ)を紹介する.
Kratz
アプローチは,ES
が複数の信頼水準のVaR
で近似できることを利用してES
のバックテ スティングを間接的に構成するというEmmer et al. (2015)
の考え方にもとづく.損失分布をL
とし,信頼 水準α
のES
とVaR
をES
α(L)
,VaR
α(L)
と記す.Emmer et al. (2015)
はES
の近似値をES
α(L) ≈ 1
4 [q(α) + q(0.75α + 0.25) + q(0.5α + 0.5) + q(0.25α + 0.75)]
= 1 4
[
q(α) + q
( 3α + 1 4
) + q
( 2α + 2 4
) + q
( α + 3 4
)]
(2.9)
とした.但しq(γ) = VaR
γ(L)
である.(2.9)
式は(2.3)
式を離散近似したものである.(2.9)
式からは,損失 分布L
に対する4
つのVaR
推定値q(aα + b)
が十分妥当であるならば,ES
の推定値ES
α(L)
も妥当である と考えることができることが示唆される.この考え方をもとに,Kratz
アプローチは複数の異なる信頼水準のVaR
を同時にバックテスティングすることで,間接的にES
のバックテスティングをおこなう.2.4.1 Kratz
アプローチの設定事前に予測したモデルの列を
{ F
t, t = 1, . . . , n }
,事後に実現した損失の列を{ L
t, t = 1, . . . , n }
,フィルト レーションを{F
t, t = 1, . . . , n }
とする.F
tは確率分布でF
t−1-
可測,L
tはスカラー値F
t-
可測である.モデル
F
tは,各時点t
で様々な信頼水準α
のVaR
α,t,ES
α,tを予測(
推定)
するために使われる.VaR
の予測値VaR
α,tと損失の実現値L
tを比較することで,モデルの妥当性を評価する.(2.9)
式の発想を一般化するために,出発水準α
*2に対して,複数の信頼水準をα
j= α + j − 1
N (1 − α), j = 1, . . . , N, N ∈ N
= (N − j + 1)α + (j − 1)
N (2.10)
と定義する.
N = 4
のとき,(2.10)
式は(2.9)
式に一致する.さらに便宜上α
0= 0, α
N+1= 1
と定義する.そして時点
t
の信頼水準α
jの違反インディケータをI
t,j:= 1
{Lt>VaRαj ,t}(2.11)
と定義する.
VaR
の予測モデルが正確であるか否かを判定することは,違反インディケータの列(I
t,j)
t=1,...,nが以下の2
つの仮説を満たすか否かを判定することに単純化できる.•
無条件カバレッジ仮説: E[I
t,j] = 1 − α
j,
∀t
•
独立性仮説: s ̸ = t
ならばI
t,jとI
s,jは独立.もし
VaR
の予測値が両方の仮説を満たすならば,違反数∑
nt=1
I
t,j は成功確率(
違反確率)
が1 − α
jの二項 分布に従う.上述のように単一の
VaR
の予測値の検定では二項分布が使われるが,複数のVaR
の予測値の同時検定では 多項分布が使われる.X
t= ∑
Nj=1
I
t,jと定義すると,これは設定した複数の信頼水準のVaR
αj,tを,損失L
t が何個超過したかを示し,(X
t)
t=1,...,nはその時系列である.もしVaR
の予測値が適切なモデルから予測さ れているならば,(X
t)
t=1,...,nは以下の2
つの条件を満たす.•
無条件カバレッジ仮説: P (X
t≤ j) = α
j+1, j = 0, . . . , N,
∀t
•
独立性仮説: s ̸ = t
ならばX
tとX
sは独立 これらの特性はX
t∼ MN(1, (α
1− α
0, . . . , α
N+1− α
N)),
∀t (2.12)
と書くこともできる.但し,MN(n, (p
0, . . . , p
N))
は,試行n
の多項分布*3である.ここで,セルカウントをO
j=
∑
n t=1I
{Xt=j}, j = 0, 1, . . . , N (2.13)
で定義すると,上述の2
つの条件を満たす場合,セルカウントのベクトル(O
0, . . . , O
N)
は多項分布(O
0, . . . , O
N) ∼ MN(n, (α
1− α
0, . . . , α
N+1− α
N)) (2.14)
に従う.多項分布については9.1
節を参照されたい.*22.4節ではKratz et al. (2016)にあわせてα= 0.975とする.
*31回の試行では,{0,1, . . . , N}からp0, . . . , pNの確率で要素を1つ出力する.
より形式的には
0 = θ
0< θ
1< · · · < θ
N< θ
N+1= 1
を任意のパラメータとし,(O
0, . . . , O
N)
はMN(n, (θ
1− θ
0, . . . , θ
N+1− θ
N))
というモデルからの実現値と考える.そして帰無仮説と対立仮説がH
0: θ
j= α
j,
for j = 1, . . . , N
H
1: θ
j̸ = α
j,
for at least one j ∈ { 1, . . . , N } (2.15)
で与えられる検定を行うことで予測モデルの妥当性を評価することができる.2.4.2 Kratz
アプローチの検定(2.15)
式の仮説を評価するために様々な検定統計量を使うことができる.Kratz et al. (2016)
は,Cai &
Krishnamoorthy (2006)
で使われた5
つの手法の中から,以下の3
つの手法を使用した.1.
ピアソンのカイ二乗検定2.
ナス検定(Nass test)
3. LRT
検定(likelihood ratio test)
ピアソンのカイ二乗検定では,検定統計量はS
N=
∑
N j=0(O
j+1− n(α
j+1− α
j))
2n(α
j+1− α
j)
∼
dH0
χ
2N(2.16)
となる.
∼
dH0
は帰無仮説のもとで分布収束することを意味する.仮説検定の有意水準を
κ
,χ
2N(1 − κ)
をχ
2N 分布の(1 − κ)
分位点とすると,S
N> χ
2N(1 − κ)
ならば,帰無仮説は棄却される.ナス検定は,
(2.16)
式で定義された統計量S
N の分布を改良した方法である.検定統計量の定義は以下の通 りである.cS
N∼
dH0
χ
2ν, c = 2E[S
N]
V[S
N] , ν = cE[S
N] E[S
N] = N
V[S
N] = 2N − N
2+ 4N + 1
n + 1
n
∑
N j=01 α
j+1− α
j(2.17)
cS
N> χ
2ν(1 − κ)
ならば,帰無仮説は棄却される.ナス検定はセル確率*4が低い時,カイ二乗検定より優れて いることが多い.LRT
検定は,まず対立仮説H
1のもとでパラメータθ
jの最尤推定量θ ˆ
jを計算する.そして検定統計量G
N= 2
∑
N j=0O
jln
( θ ˆ
j+1− θ ˆ
jα
j+1− α
j)
(2.18)
を形成する.(O
0, . . . , O
N) ∼ MN(n, (θ
1− θ
0, . . . , θ
N+1− θ
N))
のもとでは,セル確率はθ ˆ
j+1− θ ˆ
j= O
j/n
と推定でき る.しかしO
jがゼロの時は,θ ˆ
j+1− θ ˆ
j がゼロになるため,この場合は検定統計量を定義することができな い.そのためN ≥ 2
の時は,Cai & Krishnamoorthy (2006)
によって提案されたLRT
の別手法を使用する.*4多項分布の成功確率
その方法ではパラメータが
θ
j= Φ
( Φ
−1(α
j) − µ σ
)
, j = 1, . . . , N (2.19)
によって与えられると仮定して
H
0: µ = 0 and σ = 1
H
1: µ ̸ = 0 or σ ̸ = 1 (2.20)
として検定を行う.この場合
θ ˆ
j+1− θ ˆ
j= Φ
( Φ
−1(α
j+1) − µ ˆ ˆ σ
)
− Φ
( Φ
−1(α
j) − µ ˆ ˆ σ
)
(2.21)
となる.µ ˆ
とσ ˆ
は対立仮説H
1のもとでの最尤推定量である.そのためセル確率の推定値がゼロになることは ない.この検定統計量をG
N とすると,G
N は漸近的に自由度が2
のカイ二乗分布に従う.G
N> χ
22(1 − κ)
ならば,帰無仮説は棄却される.LRT
検定は,(2.21)
式のとおりθ
j, j = 0, 1, . . . , N
をµ, σ
の2
パラメータに縮約する.これは大胆な仮定 であり,現段階ではLRT
検定が本当に適切に機能するかどうかは疑わしいが,以降の実験では,この点にも 留意しながら分析を行う.2.5 ES
バックテスティング2 : Acerbi et al. (2014
,2017)
によるアプローチ本節では
Acerbi et al. (2014
,2017)
により提案されたES
バックテスティング(以下,Acerbi
アプロー チと呼ぶ)を紹介する.Acerbi
アプローチではKratz
アプローチと異なり,検定統計量が従う分布を解析的 に求めることができない.そのため帰無仮説のもとでモンテカルロシミュレーションを行い,検定統計量が 従う分布を手に入れる.Kratz
アプローチより計算時間が長いという欠点があるが,Acerbi
アプローチではKratz
アプローチと異なりES
を直接検定することができる.Acerbi et al. (2014)
では3
つの異なる方法が提案されている.本稿ではこれらの方法を検定1
,検定2
,検 定3
と呼ぶ.検定3
は検定1
,検定2
より計算時間がかかるため後述する実験が現実的な時間で終わらないこ と*5,Acerbi et al. (2014)
によると検定3
のパフォーマンスは検定1
,検定2
に比べて劣後することなどか ら,本論文では検定3
を分析の対象から外す.さらにAcerbi et al. (2017)
では,VaR
の推定精度によって検 定の結果が左右されるという検定2
の欠点を改良した方法が提案されているので,この方法を検定4
と呼び,本論文では検定
1
,検定2
,検定4
に焦点を当てる.2.5.1 Acerbi
アプローチの設定Acerbi
アプローチは損失分布ではなく損益分布をもとにバックテスティングを構成する.そのためKratz
アプローチにおける信頼水準
97.5%(α = 0.975)
は,Acerbi
アプローチでは信頼水準2.5%(α = 0.025)
に対 応するなど,両アプローチ間で表記法が異なる.本来であればKratz
アプローチ,Acerbi
アプローチともに 同じ表記法を使うほうが好ましいが,各アプローチ内の説明を分かりやすくすることを優先し,異なる表記法 を使用する.*5Clift et al. (2016)によると,検定3の計算コストは検定1,検定2の4倍.厳密に計算時間を計測したわけではないが,筆者の 感覚ではそれ以上の差があるように思われる.
時点を
t = 1, . . . , T
,損益を表す確率変数をX
tとする.{F
t}
t∈Nをフィルトレーションとする.時点t − 1
までの情報をF
t−1を所与とした時,X
tは(
未知の)
真の分布F
tをもつと仮定する.同様に時点t − 1
までの 情報をF
t−1を所与とした時,モデルによる損益の予測分布をP
tとする.確率変数の集合
X ⃗ = { X
t}
は互いに独立と仮定するが,同分布ではないとする.X
t∼ F
tの時,信頼水準α
のVaR, ES
をVaR
Fα,t, ES
Fα,tと記す.さらに損益分布は連続で厳密に増加すると仮定する.違反インディ ケータをI
t= 1
{Xt+VaRα,t<0}(2.22)
と定義する.
I
tFt はI
tFt:= 1
{Xt+VaRFtα,t<0}とする.
この時,興味があるリスク指標は,時点
t − 1
までの情報F
t−1を所与とした場合の時点t
のVaR
,ES
つま りVaR
Fα,tt, ES
Fα,tt である.VaR
Fα,tt, ES
Fα,tt はVaR
Fα,tt= − F
t−1(α) (2.23)
ES
Fα,tt= − E
t−1[X
t| X
t+ VaR
Fα,tt< 0]
= − E
t−1[ X
tI
tFtα ]
(2.24)
と計算することができる*6.但し,E
t−1[X] := E[X |F
t−1]
である.同様に,予測モデル
P
tから計算したVaR
,ES
をVaR
Pα,tt, ES
Pα,tt とする.Acerbi
アプローチは,予測モデ ルP
tから計算した(VaR
Pα,tt, ES
Pα,tt)
t=1,...,T が,真のモデルF
tから計算した(VaR
Fα,tt, ES
Fα,tt)
t=1,...,T に十分 近いかどうかを評価する方法である.現実には(VaR
Fα,tt, ES
Fα,tt)
t=1,...,T を観測することはできない.そのため(VaR
Pα,tt, ES
Pα,tt)
t=1,...,T と実際に観測された損益(X
t)
t=1,...,T から予測モデルの妥当性を判断する.2.5.2
検定1 : testing ES after VaR
検定
1
はVaR
が正しいという前提のもとでES
の検定を行う.検定統計量はES
Fα,tt= − E[X
t| X
t+ VaR
Fα,tt< 0] (2.25)
という関係式をもとに構築される.検定1
の検定統計量Z
1はZ
1= 1 N
TP∑
T t=1X
tI
tPtES
Pα,tt+ 1 (2.26)
N
TP=
∑
T t=1I
tPt> 0 (2.27)
I
tPt= 1
{Xt+VaRPtα,t<0}
(2.28)
と定義される.
*6VaRFα,tt,ESFα,tt はFt−1-可測.
帰無仮説
H
0,対立仮説H
1はH
0: X
t∼ F
t, (2.29)
P
t(x) = F
t(x), x < − VaR
Fα,tt,
∀t (2.30)
H
1: X
t∼ F
t, (2.31)
P
t̸ = F
t,
∃t (2.32)
ES
Fα,tt≥ ES
Pα,tt, for
∀t, > for
∃t (2.33) VaR
Fα,tt= VaR
Pα,tt, for
∀t (2.34)
とおく.
(2.34)
式が不等号ではなく等号であるのは,検定1
の考え方では,別の検定によりVaR
は事前に正しいことが確認されているという前提があるためである.そのため対立仮説のもとでも
VaR
は依然として正 しい.次に検定統計量
Z
1の性質を調べる.具体的には帰無仮説H
0及び対立仮説H
1のもとで,Z
1の期待値を計 算する.検定1
では帰無仮説H
0,対立仮説H
1いずれにしてもVaR
Fα,tt= VaR
Pα,tt であるのでI
tFt= I
tPtとな ることに注意すると,H
0: E[Z
1] = E [
1 N
TP∑
T t=1X
tI
tPtES
Pα,tt+ 1
N
T> 0
]
= E [
1 N
TF∑
T t=1X
tI
tFtES
Pα,tt+ 1
N
T> 0
]
= E [
E [
1 N
TF∑
T t=1X
tI
tFtES
Pα,ttI
1F1, . . . , I
TFT]
+ 1 N
T> 0
]
= E [
1 N
TF∑
T t=1I
tFtE[X
t| I
tFt] ES
Pα,tt+ 1
N
T> 0
]
= E [
− 1 N
TF∑
T t=1I
tFtES
Fα,ttES
Pα,tt+ 1
N
T> 0
]
= E [
− 1 N
TF∑
T t=1I
tFt+ 1 N
T> 0
]
, (
∵ES
Fα,tt= ES
Pα,tt)
= 0 (2.35)
となる.複数の条件
I
1F1, . . . , I
TFT での条件付期待値を単一の条件I
tFt の条件付期待値にするために,確率変 数の集合X ⃗ = { X
t}
が互いに独立であることを用いている.対立仮説
H
1のもとでZ
2の期待値を計算する.(2.35)
式の5
行目までは帰無仮説H
0と変わらない.H
1: E[Z
1] = E [
1 N
TP∑
T t=1X
tI
tPtES
Pα,tt+ 1
N
T> 0
]
= E [
− 1 N
TF∑
T t=1I
tFtES
Fα,ttES
Pα,tt+ 1
N
T> 0
]
≤ E [
− 1 N
TF∑
T t=1I
tFt+ 1 N
T> 0
]
, (
∵ES
Fα,tt≥ ES
Pα,tt)
= 0 (2.36)
以上より検定統計量
Z
1の期待値は,帰無仮説H
0のもとではゼロ,対立仮説H
1のもとでは負になることが わかる.2.5.3
検定2 : testing ES directly
検定
2
は検定1
と異なり,VaR
とES
を同時に検定する.検定統計量はES
Fα,tt= − E
t−1[ X
tI
tFtα ]
(2.37)
⇔ E
t−1[
X
tI
tFtαES
Fα,tt]
+ 1 = 0 (2.38)
という関係式をもとに構築される.検定
2
の検定統計量Z
2はZ
2=
∑
T t=1X
tI
tPtT αES
Pα,tt+ 1
(2.39)
I
tPt= 1
{Xt+VaRPtα,t<0}
(2.40)
と定義される.
帰無仮説
H
0,対立仮説H
1はH
0: X
t∼ F
t, (2.41)
P
t(x) = F
t(x), x < − VaR
Fα,tt,
∀t (2.42)
H
1: X
t∼ F
t, (2.43)
P
t̸ = F
t,
∃t (2.44)
ES
Fα,tt≥ ES
Pα,tt, for
∀t, > for
∃t (2.45) VaR
Fα,tt≥ VaR
Pα,tt, for
∀t (2.46)
とおく.次に検定統計量
Z
2の性質を調べる.具体的には帰無仮説H
0,対立仮説H
1のもとで,Z
2の期待値を計算 する.H
0: E[Z
2] = E [
T∑
t=1
X
tI
tPtT αES
Pα,tt+ 1
]
= E [
T∑
t=1