論文書誌情報の俯瞰とキーワード抽出技術の検証
Key term detection in academic paper: application of meme
detection method
浅谷 公威
1∗坂田 一郎
1,2Kimitaka Asatani
1Ichiro Sakata
1,21
東京大学工学系研究科
1
Department of Engineering, The University of Tokyo
Abstract: Recently, information on science and technology has exponentially increased and the number of academic papers increases exponentially. Thus, it is necessary to make decisions regarding policy and strategy planning using the latest scientific and technological information. In this research, we extract important words in the collection of the academic papers by applying the recently proposed method. We also combined with the result of clustering by quoted network analysis. As the result, in some aspect, the detected keywords are better than the widely used method (TF - IDF). Finally, we discuss the application of keyword detection method of making a landscape of academic domain.
1
はじめに
近年,学術論文の数は指数関数的に増加している [1]. また,最新の科学技術情報を用いて政策や戦略立案に 関する意思決定を行うことが必要とされている.その ため,爆発的に増加する学術文献の大量の情報から有 用な情報を抽出することを目的とした,大規模な学術 文献情報を分析するための技術やそのプラットフォーム 開発に関する研究が近年特に盛んに行われている.こ れらの技術は,科学技術のロードマッピングやフォー サイト・ホライゾンスキャンニング [2] のような意思決 定支援に活用されている. 学術論文が大量に増えている中で,知識の量はそれ ほど増えていないことを示唆する研究もある [1].この 論文の著者らは,学術論文中の文章を解析することで, 新たに出現するタームの数は指数関数的ではなく線形 に増加していることを発見した.このことが正しいと 言えるならば,指数関数的に増加する情報の中から適 切に知識を抽出するシステムがあれば多くの時間を掛 けることなく学術分野の俯瞰・理解が行うことができ ると考えられる. これまで開発されてきた,引用ネットワーク解析の 手法は複雑に細分化する学術分野の構造化に有用に機 能している.例えば,学術俯瞰システム [3] ではモジュ ラリティ最大化などの方法で引用ネットワーク解析を ∗東京大学工学系研究科 〒 113-0033 東京都本郷 7-3-1 E-mail: [email protected] クラスタリングし,各クラスタな簡単な基礎統計料(頻 出ワード,平均出版年,高頻度著者や高頻度組織)を 観察することで学術領域全体を俯瞰することが可能で ある.また,同様のシステムが様々なところで提供さ れている [4].さらに,引用ネットワークの情報やテキ スト分析を組み合わせて数年後の出版の引用数を予測 する手法の開発が行われている [5, 6, 7].しかしなが ら,これらの手法で提示された情報はマクロすぎるか ミクロすぎるために具体的な科学技術政策や投資の意 思決定に直接的に結びつけることは難しい.具体的に は,引用ネットワーク解析の俯瞰によりもたらされる 機械学習の分野の論文数が伸びているという予想を超 えない示唆や,引用数予測により抽出した今後引用数 が伸びそうな有力な論文のリストである.これらは意 思決定のための支援となるが,これらの技術で抽出さ れた情報に加えて論文の読み込みを大量に行う必要が ある.具体的には「Deep learning」の分野が成長して いる,もしくは特定の論文が大量に引用されている情 報は,国家機関や企業の意思決定者に有用な情報とな るとは限らない. 本論文では上記のような俯瞰的な分析や将来予測を, クラスタ単位や論文単位で行うことではなくキーワー ド単位で行えると,意思決定者が理解しやすいと考え た.具体的には,学術論文のデータセットから特定の分 野で集中的に使われるキーワードを抽出することを目 標とする.このような分析は,メゾなレベルでの分析 は実用的な観点での結果の了解性が高いと想定される. 例えば,機械学習の分野で「Network convolution」な 人工知能学会研究会資料 SIG-KBS-B801-05どの将来成長が見込まれるキーワードを予測できれば 結果の了解性が高いと考えられる. 萌芽的なキーワードの予測は,自然言語処理による キーワード抽出に加え,ネットワーク分析による各論 文の特徴量を用いる.具体的に使用する手法は,[8] ら によるキーワード抽出の手法である.この手法では,引 用先・元の双方の論文の中にあるタームが含まれてい るときに,特定の論文の引用関係の中をそのタームが ミームとして伝わったとして解釈する.そのことによ り,引用ネットワークの中でミームとして伝播しやす いタームの集合を取り出す.このようなターム抽出の 手法により得られた結果と論文の引用ネットワークの 手法を組み合わせることで,学術領域の俯瞰や将来予 測につながるかどうかを議論した.
2
手法
2.1
前処理
論文の書誌情報より引用ネットワークを作成し,モ ジュラリティを最大化するように Louvain 法でクラス タリングを行う.また,論文のタイトル,アブストラク トから Stopword を除き N-gram(n=1,2,3) によりター ムを抽出する.2.2
手法
論文のタームが引用ネットワーク上でどれだけ伝わっ ているかを先行研究の手法 [8] で測定する.この手法で は,以下の式.1 で各タームの Meme Score M を測定す る.式.1 において,タームを含む論文のセットを m と し,タームを含まない論文のセットを ¯mと定義してい る.dm→mは,タームを含む論文のセット間での引用 の数であり,タームが引用をたどってどれだけ先に伝 わったかを示している.d→mタームを含む論文を引用 している論文数である.これらの2つの変数の割り算 は,タームの可能な伝わる先にどれだけの確率でター ムが伝わったかを示している. M (t) = dm→m d→m / dm¯→ ¯m d→ ¯m (1) 式.1 の右側の部分は,タームを含むがタームを含む 論文を引用していない論文数 dm¯→ ¯mと,タームむ論文 を引用していない論文数 d→ ¯mで構成されている.前者 は,タームが論文の集合内で伝わりだした始点の数を 意味しており,論文を引用していない論文数である後 者で割ることにより,タームが伝わりだす始点ができ る確率を意味している. このようにして,式.1 で各タームの Meme Score M はあるタームがどれだけの確率で引用先に伝わったか ということと,タームを含む論文がどれだけデータセッ ト内に発生しやすいかの確率で割ったものとなってい る.このことがあるタームがそのデータセット内でミー ムとして存在しているかを示している.そのうえで,あ るタームがデータセット全体でどれだけのインパクト を持っているかをしめす Meme Spred ScoreM S(t) は, Meme ScoreM (t)とタームの出現頻度 N (t) の掛け算で 表される.本論文では,M S(t) が大きいタームを取り 出すことによりあるデータセット内やそのデータセッ トの特定の領域におけるミームを取り出す. M S(t) = M (t)∗ N(t) (2)2.3
比較手法
比較手法として,TF-IDF により抽出されたドキュ メント内のタームの重要度スコアの全ドキュメントで の合計をあるタームの tf-idf score として用いる.3
データ
本論文では ACL Anthology から提供されている論文 の書誌情報(タイトル,アブストラクト,引用)を分析 に使用する.ACL Anthology は,会議,ワークショッ プ,雑誌を含む 33 以上の自然言語処理関連の論文で発 表された 4 万件を超えるリサーチ記事で構成されてい ます.表 1 にデータセットの一般的な統計を示す. #Papers 43,563 #Citations 222,577 #Year 1968-2018 #Average Year 2007.1 表 1: データセット (ACL Anthology の基礎的な統計量) また,各タームはスコアを計算した後にデータセッ トの全体の 5%の 2,178 以下の論文で出現するタームに 絞って分析を行った.4
結果
4.1
データセット全体におけるミームの伝播
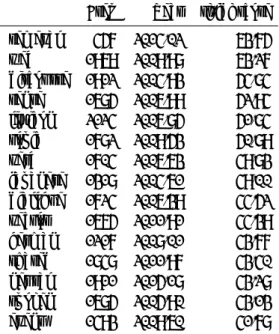
ここではデータセット全体において検出した,Meme Scoreが高いタームに関して結果を示す.はじめに,結 果を示す前に手法の妥当性を考察する意味で,ミームと して機能しているタームとそうでないタームそれぞれに 対して,引用ネットワーク内でのタームの伝播の様子を 図示する.図.1 の左には better peformance というタームの引用ネットワーク内での伝播の様子を示している. このタームは 240 の論文に出現しているが,それらの論 文の間に引用関係が存在するのはわずか 30 論文であり タームは引用ネットワーク内で伝播しているとはいえ ない.一方で,図.1 の右の texutual entailment という タームを含む論文同士は引用ネットワークでつながって おり,引用ネットワークを texutual entailment という タームが伝播したと捉えることも可能である.算出され た Meme score M (betterpef ormance) = 0.017 と低い 値になっているが, M (texutualentailment) = 0.339 と高い値となっている. 図 1: 引用ネットワーク上のタームの伝播の例 次にデータセット全体で検出されたミームとなるター ムの上位 20 件を,比較手法となる TF-IDF により検 出された重要ターム 20 件とともに表.2 と表.3 に示す. それぞれの結果において客観的にどちらが ACL の論文 内で研究されているデータかどうかの検証は難しいが, 表 3 の Meme Spred ScoreM S(t) で並び替えたほうが 比較的一般的でないタームを検出しているように思え る.表 2 における Semeval を除いて殆どが高頻度 (閾値 となる 5%の 2,178 論文以下) の論文であるが,表 3 で は Sentiment analysis や word sence などの比較的低頻 度のタームも検出できている.表 2 における Semeval は Semeval–2011–task5 などの複数のバリエーションが あり曖昧な意味合いであるが,固有名詞として一つの 論文内で複数回使われることが多いことが tf-idf スコ アの向上につながったといえる.
4.2
クラスタごとのタームの伝播
また,引用ネットワークのクラスタリングにより分割 したクラスタ内で伝播しているタームのリストを表.4 に まとめた.各タームが出現する論文がもっとも多く含ま れているクラスタをタームの所属クラスタとした.表.4 を上から見ていくと,Parsing,Machine Translation, CCG, Sense disambiguationなどと各クラスタの特徴 がはっきりと読み取れると考えられる.このようにター ムの出現頻度に適切な閾値(全体の 5%以下の論文で出Freq Year tf-idf score semeval 457 2014.02 63.75 web 1969 2009.98 63.27 discourse 1912 2004.93 54.84 sense 1685 2006.99 52.94 lexicon 2124 2006.85 51.84 topic 1782 2009.53 50.89 verb 1704 2006.63 49.83 japanese 1318 2004.61 49.00 dialogue 1724 2006.39 44.52 vector 1675 2011.91 44.39 german 1217 2008.01 43.77 shared 1848 2011.97 43.40 neural 1911 2015.18 43.28 spoken 1685 2005.90 43.13 event 1493 2009.60 41.78 表 2: TF-IDF で計算した重要キーワードの上位 15 個. 5%以上のドキュメントに出現する頻出キーワードは 除く
Freq Year Score neural 1911 2015.18 1157.37 sentiment 1356 2013.68 1132.97 statistical machine translation 1428 2010.90 1091.77 statistical machine 1462 2010.85 943.58 bleu 891 2011.95 726.12 dialogue 1724 2006.39 716.59 sentiment analysis 860 2013.95 555.24 neural network 1248 2014.83 493.42 twitter 759 2014.63 480.71 alignment 1561 2009.65 465.67 discourse 1912 2004.93 444.74 sense 1685 2006.99 418.13 disambiguation 1619 2006.62 405.75 unsupervised 1761 2010.81 384.46 word sense 930 2007.87 380.06 表 3: Meme Spread Score で計算した重要キーワード の上位 15 個.5%以上のドキュメントに出現する頻出 キーワードは除く
現するタームに絞る)ことで適切に論文内を流れるキー ワードが検知でできたと言える.
#Papers Top 10 memes C
0 4255 unsupervised dependency parsing treebank tagging german random
cross-lingual conditional random random field conditional random field induction tagger 1 3715 neural statistical machine translation statistical machine bleu alignment shared
shared task parallel phrase-based smt bilingual neural machine 2 3380 japanese ccg hpsg categorial adjoining categorial grammar
tree adjoining adjoining grammar tree adjoining grammar sign quantifier lfg
3 3219 sense disambiguation word sense lexicon sense disambiguation word sense disambiguation wordnet verb semantic role argument sens role labeling
4 2937 named entity named web entity recognition named entity recognition biomedical wikipedia relation extraction clinical knowledge base mention compound 5 2925 sentiment sentiment analysis neural network twitter detection topic
tweet social polarity opinion medium social medium
6 2840 dialogue spoken dialogue system speech recognition spoken dialogue conversation multimodal language generation act visual referring expression referring
7 2828 embeddings vector distributional answering answer question answering
semantic textual similarity semantic textual entailment paraphrase textual similarity word embeddings 8 2385 summarization summary image topic model multi-document simplification
sentence compression multi-document summarization readability extractive keyphrase extraction compression 9 1630 resolution coreference coreference resolution pronoun anaphora antecedent
anaphora resolution resolution system abstract of current current literature coreference resolution system african 10 1533 morphological arabic morphology native language identification language identification finite-state
dialect native language standard arabic modern standard authorship attribution modern standard arabic 11 1397
transliteration comparable corpus machine transliteration bilingual lexicon cognate bilingual lexicon extraction lexicon extraction transliteration system bilingual terminology grapheme-to-phoneme articulatory transliteration model
12 1076 expression multiword expression multiword metaphor mwes mwe
light verb verb construction metonymy light verb construction automatic term deaf 13 1071 segmentation word segmentation chinese word segmentation chinese word bakeoff thai
sighan chinese named chinese named entity
14 1042 discourse event temporal discourse relation discourse parsing narrative
temporal relation connective rhetorical discourse connective penn discourse discourse treebank
5
考察
本研究では,論文書誌情報の集合における重要なター ムを情報を引用ネットワーク解析により算出し,引用 ネットワーク分析によるクラスタリングの結果と合わ せることで効率的に論文の集合から知識を抽出できる ことを示した.算出した結果は定量的ではないものの 既存手法である TF-IDF よりもよく論文の集合内で重 要なタームを検出していることが示唆された.この結 果に関しては今後定量的な考察を実施していく. 本研究では新しいキーワード抽出とランキングの方 法を定義する前に,既存手法の検証を行い改善点を発 見する段階である.重要なキーワード抽出の定量的な 検証手法を定義した上で,本手法の改善を実施してい く.例えば,先行研究における Meme Spread Score の 式は必ずしもキーワード抽出のタスクに最適とは言え ない.例えば,Meme Score に Meme が出現する論文数 をかけて Meme Spread Score としているが,このスコ アは出現する論文数に大きく依存する.特定の領域に のみ出現しているタームを検出したいのであれば,先 行研究の式を見直す必要がある.さらに,図 1 のよう なターム伝播のネットワークから抽象化したスコアを 算出することも視野に入れている. 本研究の結果は,様々な専門家による検証が必要で ある.論文のデータセットから特定の領域で伝播して いるタームを検出する手法の有効性を示すために,様々 な領域の研究開発担当者や国家機関の政策策定の担当 者とディスカッションを実施していく.謝辞
この成果は,国立研究開発法人新エネルギー・産業 技術総合開発機構(NEDO)の委託業務の結果得ら れたものです.参考文献
[1] S. Milojevi´c, “Quantifying the cognitive extent of science,” Journal of Informetrics, vol. 9, no. 4, pp. 962–973, 2015.
[2] E. Amanatidou, M. Butter, V. Carabias, T. K¨onn¨ol¨a, M. Leis, O. Saritas, P. Schaper-Rinkel, and V. van Rij, “On concepts and methods in horizon scanning: Lessons from initiating policy dialogues on emerging issues,” Science and Public Policy, vol. 39, no. 2, pp. 208–221, 2012.
[3] Y. Kajikawa, J. Ohno, Y. Takeda, K. Matsushima, and H. Komiyama, “Creating an academic land-scape of sustainability science: an analysis of the citation network,” Sustainability Science, vol. 2, no. 2, p. 221, 2007.
[4] J. Tang, “Aminer: Toward understanding big scholar data,” in Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, pp. 467–467, ACM, 2016.
[5] F. Davletov, A. S. Aydin, and A. Cakmak, “High impact academic paper prediction using temporal and topological features,” in Proceedings of the 23rd ACM International Conference on Confer-ence on Information and Knowledge Management, pp. 491–498, ACM, 2014.
[6] E. Garfield, “The history and meaning of the jour-nal impact factor,” Jama, vol. 295, no. 1, pp. 90– 93, 2006.
[7] R. Yan, J. Tang, X. Liu, D. Shan, and X. Li, “Ci-tation count prediction: learning to estimate fu-ture citations for literafu-ture,” in Proceedings of the 20th ACM international conference on Informa-tion and knowledge management, pp. 1247–1252, ACM, 2011.
[8] T. Kuhn, M. Perc, and D. Helbing, “Inheri-tance patterns in citation networks reveal scien-tific memes,” Physical Review X, vol. 4, no. 4, p. 041036, 2014.