招待論文
シミュレーテッド分岐アルゴリズムを用いた大規模組合せ最適化
後藤
隼人
†a)辰村 光介
†Large-Scale Combinatorial Optimization based on Simulated Bifurcation Algorithm
Hayato GOTO
†a)and Kosuke TATSUMURA
†あらまし 組合せ最適化は社会や産業の様々な場面で頻繁に現れる重要課題である.組合せ最適化問題に特化 した量子コンピュータである量子アニーラが商用化されて以来,量子コンピュータに限らず,組合せ最適化問題 に特化した計算機ハードウェアの研究開発が活発化している.本論文では,著者らが考案した量子インスパイア ドの組合せ最適化アルゴリズムであるシミュレーテッド分岐アルゴリズムと,それを並列計算機で高速実装した 組合せ最適化マシンについて解説し,シミュレーテッド分岐アルゴリズムを用いた大規模組合せ最適化の将来を 展望する. キーワード 組合せ最適化,イジングマシン,量子コンピュータ,並列計算,ドメイン指向コンピューティング
1.
ま え が き
近年注目を集めている量子コンピュータの一種に 量子アニーラ(Quantum Annealer, QA)がある.QAは1998年に門脇正史と西森秀稔によって提案された量 子アニーリング[1], [2]を超伝導回路で実装したもの である[3], [4].QAは組合せ最適化問題に特化したイ ジングマシンと呼ばれる計算機の一種である.イジン グマシンとは,磁性体の簡易モデルであるイジングモ デルの基底状態を求める問題(イジング問題)を解く 専用計算機のことである.イジング問題は計算機科学 においていわゆるNP困難問題と呼ばれるクラスに属 し[5],様々な組合せ最適化問題がイジング問題に数学 的にマッピングできることが知られているため[6],イ ジングマシンは広く役に立つものと期待されている. カナダのD-Wave Systems社がQAを商用化したこ とをきっかけに,様々な方式のイジングマシンの研 究開発が活発化した.これは,人工知能分野でも注目 されているドメイン指向コンピューティング(Domain Specific Computing)の新たな方向性とみなすことがで きる.QAと異なるイジングマシンの代表例として,光 パラメトリック発振器の光パルスの二つの位相をイジ †(株)東芝研究開発センター,川崎市
Corporate R&D Center, Toshiba Corporation, Kawasaki-shi, 212–8582 Japan a) E-mail: [email protected]
DOI:10.14923/transelej.2020JCI0015
ングモデルのスピンに見立てるコヒーレントイジング マシン(Coherent Ising Machine, CIM)がある[7], [8].
QAではスピン(量子ビット)間の結合が近接間に限定 されるという回路実装上の問題点があったが,CIMで は測定・フィードバック方式によって大規模な全結合イ ジングマシンが実現された[9], [10].この測定・フィー ドバック方式とは,光パルスから光を一部取り出して その位相を測定し,その測定結果に結合係数をかけ て総和を取る計算をFPGA (Field-Programmable Gate
Array)で実行し,その計算結果を光パルスへフィード バックすることで結合を実現するというものである. こうして,2000スピン・全結合を有する大規模イジン グマシンが実現された[9].全結合を直接扱えるという CIMの特長を生かすことで,全結合問題においてCIM がQAを凌駕したという報告もある[11] (QAでも一種 のマッピングを行うことで全結合問題を扱うことは可 能だが,そのマッピングによる冗長性のため,約2000 量子ビットを有するQAで扱える全結合イジング問題 は高々60スピン程度に限られてしまう[11]).CIMの 成功をきっかけに,異なる方式の光イジングマシンも 提案され,近年活発に研究されている[12]∼[15]. CIMはもともと光の量子性を生かした新型の量子 コンピュータを目指したものだが[16],上記の測定・ フィードバック方式のCIMは,物理的な相互作用を 用いず,独立した光パルスに対する測定結果を用いた 古典計算及び古典通信(量子でないものを「古典」と
いう)のみで結合を実現しているため,光パルス間の 量子力学的な相関(いわゆるエンタングルメント)を 有しない.一方,量子計算は多くの場合エンタングル メントを生かすことでその超高速性を実現する.つま り,CIMは,エンタングルメントという量子計算特有 の性質をあえて捨てることにより,大規模化を実現し たと言えるだろう.それでも上記のように,QAに負 けない高い性能を実現できたのである.このように, 真の量子計算にこだわらずとも,高性能なイジングマ シンを実現できる可能性はある.そのような方向性と して,従来計算機と同様の電子回路技術を利用したイ ジングマシンの研究開発も盛んである[17]∼[22]. このような従来のデジタル計算機技術を生かした イジングマシンとして,著者らは2019年にシミュ
レーテッド分岐マシン(Simulated Bifurcation Machine, SBM)を新たに提案した[23].これは,シミュレーテッ ド分岐(SB)アルゴリズムという並列計算に適した独自 のアルゴリズムを,FPGAやGPU (graphic processing
unit)などを用いて超並列実装したものである.商用プ
ロセッサを用いているにもかかわらず,その性能は上 記のCIMをも凌ぐことが示された[23].
本論文では,まずSBアルゴリズムについて説明す
る.これは著者の一人が提案した量子コンピュータ である量子分岐マシン(Quantum bifurcation Machine, QbM) [24], [25]の理論から生まれた,真に量子インス パイアドの古典アルゴリズムである.次に,FPGAで 実装されたSBMの性能,及び,その特長について解 説する.続いてより大規模なマシンとして,GPU実装 のSBMについて述べる.最後のむすびでは,SBMに よる大規模組合せ最適化の将来について展望する.
2.
シミュレーテッド分岐アルゴリズム
SBアルゴリズムの発見のきっかけとなったQbMは, CIMをより量子コンピュータに近づける試みの中で発 見された[25].実際,QbMは量子ゲート方式の万能量 子コンピュータにも利用できることが理論的に示され ている[26], [27].これは,QbMを古典コンピュータ でシミュレートすることがほぼ不可能であることを意 味する(もしもQbMが古典シミュレート可能ならば, 量子コンピュータが古典シミュレート可能となるが, それは不可能であると信じられている).QbMを提案 した論文[24]において,比較相手としてQbMを古典 近似して得られる古典分岐マシン(Classical bifurcation Machine, CbM)も提案され,CbMもイジングマシンと して動作することが確認された.CbMは古典力学に 基づくため,そのシミュレーションは古典コンピュー タでも可能である.これは古典イジングマシンの新た な実現方法を示唆していた.そこで著者らは,CbMの 運動方程式を高速シミュレーションに適した形へ改変 し,SBアルゴリズムを発見した[23]. 通常,量子力学は古典力学の量子化によって定式化 されるが,SBアルゴリズムの発見ではその順序は逆 であり,量子コンピュータの「古典化」によって古典 力学に基づくアルゴリズムが発見されたのである.そ の結果,その原理も興味深いものとなった.もともと QbMがイジングマシンとして動作する原理は量子断 熱定理という量子力学の定理に基づいていた[24].こ こで量子断熱定理とは,量子系の時間発展を規定する ハミルトニアンの時間変化が十分ゆっくりであれば, その量子系の状態は離散的なエネルギー準位のうちの 一つに留まり続ける,という量子系一般に対して成り 立つ定理である.このことから,SBアルゴリズムも何 らかの断熱定理に基づくと予想されるが,量子力学と は異なり,古典力学には離散的なエネルギー準位もな ければ,一般的に成り立つ「古典断熱定理」というも のも知られていない.にもかかわらず,後述するよう に,SBアルゴリズムは大規模なイジング問題に対し ても不思議なくらいよく動作するのである.その理由 を調べるためにSBMの実際の動作を観察すると,系 の状態はポテンシャルエネルギーの極小点を追随する ように見える[23].また,複数の極小点を動き回る場 合は,位相空間内をまんべんなく動き回るという古典 力学系のエルゴード性から予想されるように,エネル ギーの低い極小点の周りをより頻繁に訪れる[23].こ うした「古典断熱定理」を示唆する結果はあるものの, SBアルゴリズムの原理の数学的に厳密な証明は未解 決問題である. 以下,SBアルゴリズムの詳細について述べる.ま ず,イジング問題とは,次式で定義されるイジングエ ネルギーを最小化する組合せ最適化問題である. EIsing= −1 2 N ∑ i=1 N ∑ j=1 Ji, jsisj (1) ここで,si= ±1はi番目のスピン,Nはスピンの総数 を表す.このイジング問題を解くためのSBアルゴリ ズムは,以下のハミルトンの運動方程式に基づく. Ûxi=∂H∂ySB i =∆yi (2)電子情報通信学会論文誌 2021/4 Vol. J104–C No. 4 Ûyi=−∂H∂xSB i = ( p−∆−K xi2 ) xi+ ξ0 N ∑ j=1 Ji, jxj (3) HSB= N ∑ i=1 ∆ 2y 2 i + VSB (4) VSB= N ∑ i=1 ( K 4x 4 i+ ∆−p 2 x 2 i ) −ξ0 2 N ∑ i=1 N ∑ j=1 Ji, jxixj (5) ここで,xi とyiはスピンsiに対応する仮想的な粒子 の位置と運動量,ドットは時間微分,HSBは系のハミ ルトニアン,VSBはポテンシャルエネルギーを表す. また,K, ∆,ξ0は正定数,pは制御パラメータであり, 通常pは0から∆に増加させる(本論文では線形に増 加させる).pを0から∆へと増加させると系は分岐 現象[28]を起こし,各xは正または負の値へ分岐して いく[図3 (b)参照].そして,xiの最終的な符号が解 きたいイジング問題の解のsiを与える. 上記の運動方程式はハミルトニアンがxとyで分離 した分離型ハミルトン方程式になっており,シンプレ クティック・オイラー法と呼ばれるシンプルで安定な 数値積分法を適用できる[29].その結果,次のSBア ルゴリズムの更新規則を得る. y(k+1)i = yi(k)+ ∆t [ p(k)− ∆ − K xi(k)2 ] xi(k) + ∆tξ0 N ∑ j=1 Ji, jx(k)j (6) xi(k+1)= xi(k)+ ∆t∆yi(k+1) (7) ここで,∆tは離散化された時刻の時間ステップ,x(k)i , yi(k), p(k)はそれぞれ離散時刻tk = ∆tk (kは非負整 数)におけるxi,yi, pを表す.このようにシンプレク ティック・オイラー法では,まずyをオイラー法的 に更新し,続いて更新されたyを用いてxを更新す る(注1). このSBアルゴリズムには様々な利点がある.まず, 全てのx,全てのyは同時に更新可能であるために高 い並列性を有する.これは,イジング問題を従来コン ピュータで解く際によく用いられるシミュレーテッド アニーリング(Simulated Annealing, SA) [30], [31]とは
対照的である.つまり,SAアルゴリズムでは一般に スピンを一つ一つ逐次的に更新する必要があり,並列 化しにくいという欠点がある.この高い並列性を生か (注1):x を先に更新し,更新された x を使ってy を更新してもよい. すことで,SBアルゴリズムは並列計算機によって容 易に高速化できる.ここで,式(6)右辺に現れる行列 Jに関する積和演算(最も計算量の大きい部分)もでき る限り並列に計算することで高速化する.また,必要 な演算が和と積だけであり,特殊な関数の計算などが 不要であることも,FPGAなどによるアルゴリズムの ハードワイヤ化にとって望ましい.更に,SAアルゴ リズムとは異なり,疑似乱数の生成も不要で,確定的 な積和演算を実行するのみである(乱数は初期値の設 定のみに用いる).以上の特長を生かすことで,商用プ ロセッサを用いながらも高性能なイジングマシンを実 現することが可能となる.
3.
SB
アルゴリズムのハードワイヤ化
SBアルゴリズムは高い計算並列度を有しており, それを高速実行する専用の並列処理回路を設計するこ とができる.SBアルゴリズムに内在する並列度の範 囲で回路の演算並列度を最大化することで,解を得る までの時間を最短にできる.SBアルゴリズムの計算 とメモリアクセスのパターンはイジング問題の結合行 列Jの構造(全結合,ランダムスパース,隣接接合)に 依存し,最適な回路の構造もまたそれに依存する.こ こでは全結合を対象とした専用回路の設計例を紹介す る[23], [32] (疑似コード及びタイミングチャートに関 しては[32]を参照). 3. 1 SBアルゴリズムのデータ構造と並列性 図1は,全結合SBアルゴリズムのデータ依存関係 を示す.SBアルゴリズムでは,Nスピンサイズのイ ジング問題に対して,Nサイズの位置データxと同じ くNサイズの運動量データyを内部変数として用意 する.xとyは実数であり,xは直接的にs (2値)と関 係する.i番目の仮想粒子の運動量yiは,式(6)にあ 図 1 SB アルゴリズムのデータ依存関係るように他の粒子位置xj (多体の相互作用,∑Ji, jxj) と自身の位置xiに依存して更新される.i番目の仮想 粒子の位置xiは,式(7)にあるように自身の運動量yi に依存して更新される. SBアルゴリズムの最上位の並列性は,N個の粒子 を同時に更新可能である点(同時更新性)にある.時刻 tk+1の一つの粒子の状態(xi,yi)は,一つ前の時刻tk のその他の粒子位置xjには依存するが,現時刻(tk+1) の他の粒子の状態には依存しない.そのため,何かし らの方法(注2)で一つ前の時刻の粒子位置の情報を参照 可能とすれば各粒子の状態は独立に,並列更新して よい. SBアルゴリズムの同時更新性は,SAアルゴリズム の逐次更新則とは対照的である.SAアルゴリズムで はNサイズのsのみを内部変数と用意し,これを多 体相互作用評価を通じて逐次更新する.i番目のスピ ンをある時刻の状態(s1, · · · , si, · · · , sN)に基づきsiか らsi′に更新した場合,次のスピンはその更新後の状 態(s1, · · · , si′, · · · , sN)に依存して更新されなければな らない(一つの状態に基づき二つ以上のスピンを同時 に更新してはならない). SAアルゴリズムにおいて,もしもスピン結合が特定 の隣接スピンに限定されているならば,互いに独立な スピンは同時に更新することが許される.Yoshimura ら[34]は,スピンユニット回路をキングズグラフと 呼ばれる隣接接続様式で2次元格子状に配置したSA ベースアクセラレータを報告している.そこでは,ス ピン変数は四つの独立グループに分けられ,各グルー プに属するスピンは四つの動作フェーズのうち一つで 同時に更新される. SAアルゴリズムの高速化手法[31]の一つに,∆Eの 前方計算と呼ばれる手法がある.この手法では,ある スピンiが反転したと仮定した場合の系のエネルギー 差(∆Ei)を全スピンについて計算し,それを保持・更 新し続ける.試行スピン反転のエネルギー計算は全 スピンについて同時に実施してよい.しかし,一度あ るスピンの反転が決定された場合,全ての試行スピ ン反転のエネルギーは更新されなければならない(こ の場合も,逐次更新則は順守されなければならない). Tsukamotoら[20]は,∆Eの前方計算手法に基づくSA アルゴリズムのアクセラレータを報告している. (注2):二つ方法がある.一つは,全てのy 更新の終了を待ってから, x 更新を開始する.この場合,y がバッファの役割を果たす.もう一つ は,本文の例にあるように x をダブルバッファリングすることである. 3. 2 SBアクセラレータの回路アーキテクチャ 図2に,SBアクセラレータの回路アーキテクチャ を示す.SBアクセラレータの並列化ストラテジを説 明した後,具体的な回路アーキテクチャを概説する. SBアルゴリズムの時間発展手続き[式(6, 7)]は,計 算の量とパターンの観点から,行列積部(MM)と時間 発展部(TE)に分けることができる.MM部とTE部 は,それぞれ式(6)の∑Ji, jxj に相当する行列・ベク トル積とそれ以外の部分とに対応する.MM部とTE 部の計算複雑度は,それぞれO(N2)とO(N)である. まず,MM部の高速化を考える.積和演算(MAC) を行う処理エレメント(PE)回路を並列に配置し,それ に十分なデータ供給ができるメモリサブシステムを構 築することによって,MM部の処理を高速化する(空 間並列化).MM部の並列度を向上させていくと,MM 部の処理に必要なクロックサイクルはTE部のそれと 同等若しくはそれより小さくなる.TE部は逐次的で あるが各仮想粒子に対して独立である.このため,TE 部はパイプライン化(時間並列化)によって加速する. TE部は,そのパイプラインを複数備えることで,更 に加速する.最終的に,TE部の処理とMM部の処理 とを時間軸においてオーバーラップさせることで,TE 部の処理に必要なクロックサイクルを隠ぺいする. 図 2 SB アクセラレータの回路アーキテクチャ
電子情報通信学会論文誌 2021/4 Vol. J104–C No. 4 図2のSBアクセラレータは,仮想粒子のサブグルー プ一つの更新を担当するモジュール(MMTE)を複数 備える(SBの同時更新性の並列度に対応).各MMTE モジュールは,MM部の処理モジュール(MM)とTE 部の処理モジュール(TE)を備える.MMモジュール は,多入力のMACプレーン(乗算器MULアレー,加 算器ADDツリー,蓄積器ACC)を複数含む.TEモ ジュールは,y更新[式(6)]とx更新[式(7)]をパイプ ライン方式で行うデータパスである.複数のMMTE モジュールはグローバルxメモリモジュール(X’mem) と相互接続され,全体として循環構造をなす(更新手続 きの繰り返しに対応).ここで,X’memモジュールは Nサイズのxを格納するが,粒子の同時更新と並びに MM部とTE部の処理のオーバーラップを実現するた めにダブルバッファ構造を取る.X’memモジュール は,ダブルバッファの一方からxデータを全MMTE モジュールにブロードキャストし,各MMTEから時 間発展したxデータを受け取り,ダブルバッファのも う一方に格納する.各MMTEモジュールは,担当す る仮想粒子に対応するxのサブデータをローカルメモ リ(Xモジュール)に保持し,それをTEモジュールに 供給する.これは,xデータへのアクセスパターンが, MMモジュールとTEモジュールで異なるためである (高速化のために,結局,xデータは3重に保持される). 3. 3 全結合4096スピンのFPGA実装SBアクセラ レータ 前節で述べたSBの回路アーキテクチャに従い,全 結合4096スピンのSBベースイジングマシンをFPGA に実装した例を示す[32].同実装は最大4096スピン までの問題を扱うことができる(注 3).ここではベンチ マークとして,K4000問題と名付けられた全結合4000 ノードのMAX-CUT問題[32]を解く. 図3は,K4000問題を同FPGA実装で解いた際のイ ジングエネルギーと仮想粒子位置の時間発展を表す (横軸は,SBアルゴリズムの離散時刻).仮想粒子は最 初原点付近にあり,その後徐々にx= ±1の点の一方に 移動する(分岐).図3 (b)に示されるように,幾つかの 仮想粒子は原点を何度も行き来する複雑な振る舞いを 示す.これは,一つの仮想粒子に働く相互作用は他の 全ての仮想粒子の位置に依存するためである.各粒子 は複雑な振る舞いを示しつつも,図3 (a)に示すように (注3):マシンサイズより小さい問題を扱う場合は,余分なスピンに関 する相互作用係数をゼロに設定する. 図 3 SB アルゴリズムの古典力学系の時間発展 (K4000 問 題): 離散時刻の関数としての (a) イジングエネルギー と (b) 仮想的粒子の位置の変化 イジングエネルギーは(微小な振動はあるが基本的に) 単調に減少している.ここで,水平破線は局所探索法 であるHopfield Neural Network (HNN) [35]によって 得られる値(−176,626)であり,SBはそれよりも低い エネルギーに到達している(K4000問題のような巨大な
イジング問題では,厳密解を知ることは事実上不可能 なため,本論文では基準値としてHNN値を用いる).
使用したFPGAはIntel Arria10 GX 1150であり,そ
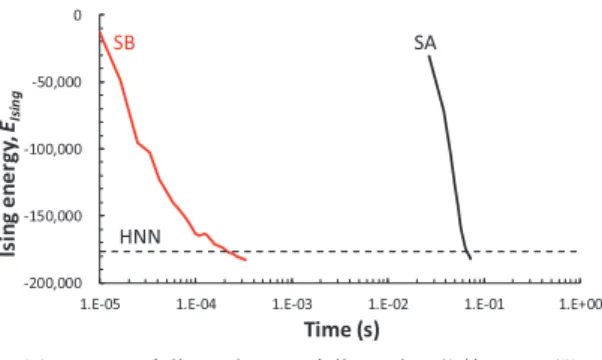
れは854,400個のアダブティブルックアップテーブル (ALUT, 5入力LUT相当)を含む.取り扱い可能な最大 スピン数は4,096, MM部の回路並列度(MAC演算を行 うPEの数)は8,192(注4),クロック周波数は269 MHz である.8,192個のPEの有効活性化率(全計算時間の うち,PEが有効な計算を行っている時間の割合)は 92%(注5)で,4,096×4,096回の積和演算を含む1回の SB時間発展ステップを2,224クロックサイクルで完 了する.1回のSB時間発展ステップの実行時間と計 算スループットは,それぞれ8.3µsと2,027 GMAC/s である.計算中におけるMMモジュールに対するJ データとxデータのデータ転送レート(ピーク)は,そ れぞれ275 GB/sと4,403 GB/sである. 図4は,K4000問題についてのFPGA実装SBとCPU 実装SA (Optimized SA法[31]に従う)の計算時間の比 較を示している[32].縦軸はイジングエネルギーで, (注4):MMTEモジュールは8個.各MMモジュールは32入力のMAC プレーンを32枚備える. (注5):マシンサイズよりも小さい問題を扱う場合でも,余分なスピン に関する相互作用計算は実施される.
図 4 FPGA 実装 SB と CPU 実装 SA との比較 (K4000問 題): イジングエネルギー対計算時間 横軸は計算時間の実測値である.上記のHNN値を基 準値に取った場合,SBの基準エネルギー到達時間(100 回試行の平均)は211µsであり,これはSA (66 ms)よ りも313倍高速である.これは,イジング問題を解く 際によく行われているCPU上でSAを走らせる場合 に比べ,FPGA実装SBがはるかに高速であり,その 意味で役立つであろうことを意味している. 最後に,本FPGA実装SBの特徴を3点議論する. (1)本FPGA実装は,問題サイズ(N=4000)以上の 回路並列度(8,192)を実現している[SBの最大並列度 はO(N2)である].一方,∆Eの前方計算法に従うSA の最大並列度は,問題サイズ(N)に留まる. (2)本FPGA実装は,最適化されたメモリサブシス テムをオンチップに備えることによって,メモリ律速 (memory-bound)でなく計算律速(computation-bound) の計算スループットを実現している.上記のxとJ のデータ転送レートは,オフチップのメモリバンド 幅(cf.最新のGPUなどで用いられているHBM2は 900 GB/s)よりも大きい.SBは,長距離2体相互作用 (例えば,重力若しくはクーロン力)に基づくN-body シミュレーションと類似のアルゴリズム構造をもつ. 重力若しくはクーロン力の2体相互作用計算が38か ら40の浮動小数点演算を必要とする[36]のに対して, イジングモデルにおけるそれは1回のMAC演算(J とxの積和)である.この単純な相互作用のために1 チップ当たりの回路並列度を大幅に増大させることが 可能であるが,一方でそれに見合うデータ供給システ ムを構築することが必要となる(そうでなければ,メ モリ律速になる). (3)イジングモデルの相互作用行列Jを表現するの に必要なビット精度(注 6)は,問題の性質と規模に依存 (注6):K4000問題を解く本FPGA実装では,Ji, jを1ビットに符号化 している.詳細は[32]参照. し,それは最適な回路の必要ハードウェアリソースに 大きく影響する.本SBアクセラレータは,様々な種 類や規模のイジング問題に柔軟に適合できるように高 位合成言語(HLS, Intel FPGA SDK for OpenCL)で記述 されている.本FPGA実装は,柔軟なHLSで記述さ れながら且つ,細粒度(bit-by-bit/cycle-by-cycle)のレ ベルの回路最適化を実現し,極めて高い回路活性化率 (92%)を達成している. 3. 4 瞬時最適応答システムへの応用 ハードワイヤ化されたSBベースのイジングマシン は一つの回路モジュールとして,インタフェースやア プリケーションなどの他の回路モジュールと一緒に 一つのチップに実装することができる(システムオン チップ実装).このことは,極めて短いレイテンシ性能 が求められるリアルタイムシステムにおいても,NP 困難な組合せ最適化問題を解き,その解に基づいた最 適な応答を実現できる可能性を示している.著者ら は,この瞬時最適応答システムのコンセプト実証とし て,外国為替市場における裁定取引マシンを報告して いる[37].このシステムは,市況パケットを取り込み, 最短経路探索問題として定式化された為替の裁定取引 問題をSBベースのイジングマシンで解くことで最適 な取引経路を検出し,注文パケットを発行する.市況 パケットの受信から注文パケットの発行までのシステ ムワイドレイテンシは30µs以下で,全解空間の中か ら最良の取引経路を見つける確率は90%を超える.こ のような瞬時最適応答システムは,金融の他,制御, ロボティクス,情報通信の分野で有益なものとなろう.
4.
GPU
クラスタを用いた大規模
SBM
最後に,大規模なイジングマシンの例として,GPU クラスタを用いたSBMについて紹介する. 3. 3で述べたように,メモリバンド幅による律速の ために,理想的にはGPUよりもFPGAを用いたほう が計算律速に近づき,SBMのパフォーマンスを最大 限引き出せる.しかし,現状のFPGAのオンチップメ モリは小さいため,1万スピンを超えるようなイジン グマシンを扱うことは困難である.そこで,大規模イ ジングマシンの実装にはGPU,または,GPUを複数 リンクさせたGPUクラスタを用いるのがよい.著 者 ら は8台 のGPU (Nvidia Tesla V100-SXM2-16GB)を高速リンク(NVLink)でつないだGPUク ラスタを用いてSBMを実装し,10万スピン・全結合
電子情報通信学会論文誌 2021/4 Vol. J104–C No. 4
は4バイトの単精度浮動小数点実数で表される(この 場合,Jに必要なメモリサイズは40GBにもなり,1台 のGPUではもはや扱うことはできない).その結果,
論文で提供されている標準的なSAソフトウェア[31]
をCPU (Intel Xeon E5-2697 v3)で実行した場合に比 べ,約1000倍高速に同程度の精度の解を得た[23]. GPUの高い並列度を考えれば自然な結果と思われるか もしれないが,そう単純ではない.同じ8GPUクラス タを用いてSAアルゴリズムを実装したところ,CPU よりもむしろ遅くなった[23].これは,SAアルゴリ ズムではスピンを逐次的に更新しなければならないた め,10万スピン全てを更新するまでに10万回のGPU 間通信が発生することによって生じる大きな通信コス トが原因である(つまり,通信律速).一方,SBアル ゴリズムでは全ての変数を同時に更新できるため,10 万スピン全てを更新する間にGPU間通信を一度しか 行う必要がない.結果として,GPUクラスタ実装SB はGPUクラスタ実装SAに比べ,約1000倍高速と なった[23].このように,SBアルゴリズムはマルチ プロセッサ構造の計算システムにも適したアルゴリズ ムとなっている(SAアルゴリズムを並列化できるよ うに改良したモーメンタムアニーリング(momentum anealing, MA)というものも提案されており,同じく GPUクラスタを用いて10万スピン・全結合のイジン グ問題が解かれている[38].SBとMAの比較は今後 の課題である).
5.
む す
び
量子コンピュータの研究から発見された,並列計算 に適した組合せ最適化アルゴリズムであるシミュレー テッド分岐アルゴリズム,及び,それを既存のデジタ ル計算機で超並列実装したシミュレーテッド分岐マ シン(SBM)について解説した.FPGAを用いたSBM は,最適化計算だけでなく,入出力まで高速化でき,超 高速応答できるシステムであることを説明した.これ は,高速な金融自動取引やロボットなどにおけるリア ルタイム制御など,組合せ最適化の新しい応用可能性 を拓くものである.また,GPUを用いたSBMによっ て大規模なイジングマシンを実現できることを述べた. これは,大規模かつ高性能なイジングマシンのクラウ ドサービスを早期に実現できる可能性を拓く.本論文 ではGPUクラスタ実装について紹介したが,より高 速な大規模マシンの実現可能性として,FPGAクラス タ実装も有望である.今後は組合せ最適化マシンとし ての性能改善に加え,社会実装を見据えた研究開発が 重要となる. 文 献[1] T. Kadowaki and H. Nishimori, “Quantum annealing in the trans-verse Ising model,” Phys. Rev. E, vol.58, pp.5355–5363, 1998. [2] A. Das and B.K. Chakrabarti, “Colloquium: Quantum
anneal-ing and analog quantum computation,” Rev. Mod. Phys., vol.80, pp.1061–1081, 2008.
[3] M.W. Johnson, M.H.S. Amin, S. Gildert, T. Lanting, F. Hamze, N. Dickson, R. Harris, A.J. Berkley, J. Johansson, P. Bunyk, E.M. Chapple, C. Enderud, J.P. Hilton, K. Karimi, E. Ladizinsky, N. Ladizinsky, T. Oh, I. Perminov, C. Rich, M.C. Thom, E. Tolkacheva, C.J.S. Truncik, S. Uchaikin, J. Wang, B. Wilson, and G. Rose, “Quantum annealing with manufactured spins,” Nature, vol.473, pp.194–198, 2011.
[4] S. Boixo, T.F. Rønnow, S.V. Isakov, Z. Wang, D. Wecker, D.A. Lidar, J.M. Martinis, and M. Troyer, “Evidence for quantum an-nealing with more than one hundred qubits,” Nat. Phys., vol.10, pp.218–224, 2014.
[5] F. Barahona, “On the computational complexity of Ising spin glass models,” J. Phys. A, vol.15, pp.3241–3253, 1982.
[6] A. Lucas, “Ising formulations of many NP problems,” Front. Phys., vol.2, no.5, 2014.
[7] Z. Wang, A. Marandi, K. Wen, R.L. Byer, and Y. Yamamoto, “Coherent Ising machine based on degenerate optical parametric oscillators,” Phys. Rev. A, vol.88, 063853, 2013.
[8] A. Marandi, Z. Wang, K. Takata, R.L. Byer, and Y. Yamamoto, “Network of time-multiplexed optical parametric oscillators as a coherent Ising machine,” Nat. Photon., vol.8, pp.937–942, 2014. [9] T. Inagaki, Y. Haribara, K. Igarashi, T. Sonobe, S. Tamate, T.
Honjo, A. Marandi, P.L. McMahon, T. Umeki, K. Enbutsu, O. Tadanaga, H. Takenouchi, K. Aihara, K. Kawarabayashi, K. Inoue, S. Utsunomiya, and H. Takesue, “A coherent Ising machine for 2000-node optimization problems,” Science, vol.354, pp.603–606, 2016.
[10] P.L. McMahon, A. Marandi, Y. Haribara, R. Hamerly, C. Langrock, S. Tamate, T. Inagaki, H. Takesue, S. Utsunomiya, K. Aihara, R.L. Byer, M.M. Fejer, H. Mabuchi, and Y. Yamamoto, “A fully-programmable 100-spin coherent Ising machine with all-to-all con-nections,” Science, vol.354, pp.614–617, 2016.
[11] R. Hamerly, T. Inagaki, P.L. McMahon, D. Venturelli, A. Marandi, T. Onodera, E. Ng, C. Langrock, K. Inaba, T. Honjo, K. Enbutsu, T. Umeki, R. Kasahara, S. Utsunomiya, S. Kako, K. Kawarabayashi, R.L. Byer, M.M. Fejer, H. Mabuchi, D. Englund, E. Rieffel, H. Takesue, and Y. Yamamoto, “Experimental investigation of perfor-mance differences between coherent Isingmachines and a quantum annealer,” Sci. Adv., vol.5, eaau0823, 2019.
[12] D. Pierangeli, G. Marcucci, and C. Conti, “Large-scale photonic ising machine by spatial light modulation,” Phys. Rev. Lett., vol.122, 213902, 2019.
[13] D. Pierangeli, G. Marcucci, D. Brunner, and C. Conti, “Noise-enhanced spatial-photonic Ising machine,” Nanophotonics, vol.9, no.13, pp.4109–4116, 2020.
a spatial-photonic Ising machine,” Optica, vol.7, no.11, pp.1535– 1543, 2020.
[15] D. Pierangeli, M. Rafayelyan, C. Conti, and S. Gigan, “Scalable spin-glass optical simulator,” arXiv:2006.00828, 2020. [16] Y. Yamamoto, K. Aihara, T. Leleu, K. Kawarabayashi, S. Kako, M.
Fejer, K. Inoue, and H. Takesue, “Coherent Ising machines–optical neural networks operating at the quantum limit,” npj Quantum Inf., vol.3, no.49, 2017.
[17] M. Yamaoka, C. Yoshimura, M. Hayashi, T. Okuyama, H. Aoki, and H. Mizuno, “A 20k-spin Ising chip to solve combinatorial op-timization problems with CMOS annealing,” IEEE J. Solid-State Circuits, vol.51, pp.303–309, 2015.
[18] K. Yamamoto, W. Huang, S. Takamaeda-Yamazaki, M. Ikebe, T. Asai, and M. Motomura, “A time-division multiplexing Ising machine on FPGAs,” Proc. 8th Int. Symp. Highly Efficient Ac-celerators and Reconfigurable Technologies, Bochum, Germany, Article 3, pp.1–6, June 2017.
[19] Y. Kihara, M. Ito, T. Saito, M. Shiomura, S. Sakai, and J. Shirakashi, “A new computing architecture using Ising spin model implemented on FPGA for solving combinatorial optimization problems,” Proc. 17th IEEE Int. Conf. Nanotechnol., Pittsburg, PA, USA, pp.256–258, July 2017.
[20] S. Tsukamoto, M. Takatsu, S. Matsubara, and H. Tamura, “An accelerator architecture for combinatorial optimization problems,” FUJITSU Sci. Tech. J., vol.53, pp.8–13, 2017.
[21] M. Aramon, G. Rosenberg, E. Valiante, T. Miyazawa, H. Tamura, and H.G. Katzgraber, “Physics-inspired optimization for quadratic unconstrained problems using a digital annealer,” Front. Phys., vol.7, no.48, 2019.
[22] K. Yamamoto, K. Ando, N. Mertig, T. Takemoto, M. Yamaoka, H. Teramoto, A. Sakai, S. Takamaeda-Yamazaki, and M. Motomura, “STATICA: A 512-spin 0.25 M-weight full-digital annealing pro-cessor with a near-memory all-spin-updates-at-once architecture for combinatorial optimization with complete spin-spin interac-tions,” 2020 IEEE Int. Solid-State Circuits Conf.-(ISSCC), IEEE, pp.138–140, 2020.
[23] H. Goto, K. Tatsumura, and A.R. Dixon, “Combinatorial optimiza-tion by simulating adiabatic bifurcaoptimiza-tions in nonlinear hamiltonian systems,” Sci. Adv., vol.5, eaav2372, 2019.
[24] H. Goto, “Bifurcation-based adiabatic quantum computation with a nonlinear oscillator network,” Sci. Rep., vol.6, 21686, 2016. [25] H. Goto, “Quantum computation based on quantum adiabatic
bi-furcations of Kerr-nonlinear parametric oscillators,” J. Phys. Soc. Jpn., vol.88, 061015, 2019.
[26] H. Goto, “Universal quantum computation with a nonlinear oscil-lator network,” Phys. Rev. A, vol.93, 050301(R), 2016. [27] S. Puri, S. Boutin, and A. Blais, “Engineering the quantum states
of light in a kerr-nonlinear resonator by two-photon driving,” npj Quant. Inf., vol.3, no.18, 2017.
[28] S.H. Strogatz, Nonlinear Dynamics and Chaos, Westview Press, ed. 2, 2015.
[29] B. Leimkuhler and S. Reich, Simulating Hamiltonian Dynamics, Cambridge Univ. Press, 2004.
[30] S. Kirkpatrick, C.D. Gelatt Jr., and M.P. Vecchi, “Optimization by simulated annealing,” Science, vol.220, pp.671–680, 1983.
[31] S.V. Isakov, I.N. Zintchenko, T.F. Rønnow, and M. Troyer, “Opti-mised simulated annealing for Ising spin glasses,” Comput. Phys. Commun., vol.192, pp.265–271, 2015.
[32] K. Tatsumura, A.R. Dixon, and H. Goto, “FPGA-based simulated bifurcation machine,” Proc. IEEE Int. Conf. Field-Programmable Logic and Applications (FPL), pp.59–66, 2019.
[33] Y. Zou and M. Lin, “Massively simulating adiabatic bifurca-tions with FPGA to solve combinatorial optimization,” The 2020 ACM/SIGDA Int. Symp. Field-Programmable Gate Arrays, pp.65– 75, 2020.
[34] C. Yoshimura, M. Hayashi, T. Okuyama, and M. Yamaoka, “Im-plementation and evaluation of FPGA-based annealing processor for Ising model by use of resource sharing,” International J. Net-working and Computing, vol.7, pp.154–172, 2017.
[35] J.J. Hopfield, “Neural networks and physical systems with emer-gent collective computational abilities,” Proc. National Acad. Sci., vol.79, pp.2554–2558, 1982.
[36] E.D. Sozzo, M. Rabozzi, L. Di Tucci, D. Sciuto, and M.D. Santambrogio, “A scalable FPGA design for cloud n-body simula-tion,” IEEE Int. Conf. Application-specific Systems, Architectures and Processors (ASAP), pp.1–8, 2018.
[37] K. Tatsumura, R. Hidaka, M. Yamasaki, Y. Sakai, and H. Goto, “A currency arbitrage machine based on the simulated bifurcation algorithm for ultrafast detection of optimal opportunity,” IEEE Int. Symp. Circuits Syst. (ISCAS), pp.1–5, 2020.
[38] T. Okuyama, T. Sonobe, K. Kawarabayashi, and M. Yamaoka, “Bi-nary optimization by momentum annealing,” Phys. Rev. E, vol.100, 012111, 2019. (2020 年 10 月 1 日受付,12 月 11 日再受付, 12 月 29 日早期公開) 後藤 隼人 2001 東京大学理学部物理学科卒.2003 同 大学大学院理学系研究科物理学専攻修士課 程了.2003 (株) 東芝入社.量子コンピュー タの研究開発に従事.2007 東京大学大学院 理学系研究科にて博士 (理学) 取得 (論文博 士).日本物理学会,応用物理学会各会員. 辰村 光介 2004 早稲田大学大学院電子・情報通信 学専攻博士課程了.博士 (工学).2004 早 稲田大学博士研究員.2006(現) 東芝研究開 発センター.ドメインスペシフィックコン ピューティングに関する研究開発に従事. 2013(現) 早稲田大学非常勤講師.2015 トロ ント大学客員研究員.2016 IEEE FPT Best Paper Award.