Statistical Sound Source Identification in a Real Acoustic Environment for Robust Speech Recognition Using a Microphone Array
4
0
0
全文
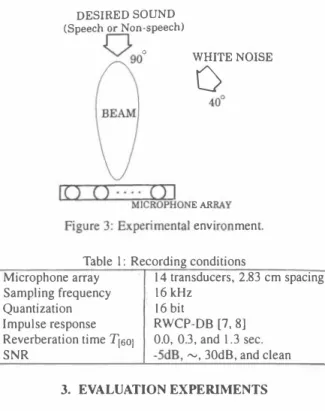
(2) DESIRED SOUND (Speech or NOIトspeech) 、、/. 0. 工、9 0. WHITE NOISE. O. Figure 2: Talker localization algorithm overview. fL. n e m. F. wards ta1ker localization目If the talker can be 10ca1ized,then his/her speech can be recognized. 川 Y 品 貼問 山M m E E N u 肘 U n ui 1JH E P n J 「 『dゆ m ゴm .m 一 一 一一 M却 - RU 一 一 マ}'副作3 7L 陀 u -b ι o B V. ing statistical speech and environmental sound mode1s and micro phone aπay steering among localized multip1e sound sources to. zåble 1: Re氾ording conditions. 2.1. Microphone array steering for speech enhancement. I I I Quantization I Impulse response Reverberation time TI601 I Microphone aπay. Microphone array steering is necessary to capture distant signals. Sampling frequency. e仔'ectively. In this paper, a delay-and-sum beamformer [ 1] is used to steer the microphone aπay to the desired sound direction. Lo calized sound signa1s are enhanced by the microphone aπay steer ing because the delay-and-sum beamformer can form directivity to. 16 kHz 16 bit RWCP-DB [7, 8] 0.0, 0.3, and 1 .3 sec.. I・5dB,�, 30dB,and clean. SNR. the localized sound sources.. 14 transducers, 2.83 cm spacing. 3. EVALUATION EXPERlMENTS 2.2. Statistical sound source identification based on GMMs. We白rst evaluate the basic p巴rformance of statistica1 sound mod. Multiple sound signals ar巴 captured effectively and enhanced by. eling though environmental sound recognition.. microphone aπay steering. Therefore, the talker can be localized by identifying the enhanced multiple sound signals. Until now, a. robust speech recognition.. speech model alone was usually used for speech / non-speech seg mentation [5] or identification. However, a single speech model. 3.1. Preliminary experiment: environmental sound recogni. has prob1ems in that it not only requires a threshold to identify be. tion. tween“speech" and“non-speech", but a1so degrades the identifica tion performance in noisy reverberant environments. To overcome. Environmenta1 sound recognition experiments are carried out with. these prob1ems, we propose a new speech / non-speech identifica. 20 samples for 92 kinds of environmental sounds and a single. tion algorithm that uses statistical speech and environmental sound. transducer in a clean environment. The feature vectors ar巴MFCC,. GMMs. The multiple sound signals enhanced with the microphone aπay steering are identi fied by Equation. �MFCC,andムpower. As a result,the environmental sound recog. (1). 入 = argmax P(S(ω) I入3,入η), λ. Then, the sound. source identi自cation performance is evaluated in distant-talking. nition performance is an average rate of 88.7% in mu1tip1e occur rence environments of the same sounds. This result con自rms that. (1). the statistica1 modeling is very effective not on1y for speech recog nition but a1so for environmenta1 sound recognition.. where S(ω) is the enhanced signal with the microphone array steering (frequency domain),入3 represents the statistical speech mode1, and入n represents the statistical environmenta1 sound model. The enhanced signals are identified as “speech" or“non-speech". 3.2. Experimental conditions The sound source identi自cation performance is evaluated with known. by estimating the maximum 1ikelihood in Equation ( 1). 百11S aト. mu1tip1e sound source positions. F igure 3 shows the experimental. gorithm allows the talker to be localized among 10calized multiple. environment.. The desired signa1 comes from the front directioll and white Gaussian noise comes from the right direction. The dis帽. sound sources.. tance between the sound source and the microphone aπay is two meters. In this situation, the statistica1 sound source identification. 2.2.1. Speech and environmental sOllnd database. performance and ASR performance are evaluated subject to varia tions in the SNR (Signa1 to Noise Ratio) and the environment. Num巴rous sound sources are necessary to design the speech and environmental sound GMMs. Therefore, we use the ATR speech. Table 1 shows data recording conditions and Table 2 shows. Database (ATR-DB) [6] to design the speech model and the RWCP. experimental conditions for statistical sound source identi自cation. (Rea1 World Computing Partnership) sound scene database (RWCP. We evaluate the statistical sound source identi自cation performa nce. DB). using a sing1e transducer、and a microphone array, subject to SNR. [7,. 8] which includes various environmenta1 sounds to de-. sign the non-speech model.. of・5dB,�, 30dB, and clean, and the reverberation times are. RWCP-DB also includes numerous. TI601 .-. 0.0, 0.3, and 1 .3 sec. We also evaluate the ASR performance with. impu1se responses measured in various acoustical environments These impu1se responses are used to conduct evaluation experi. the experimental conditions for ASR which are shown in Tabl巴2. ments in various acoustical environments.. In this paper, we evaluate the statistica1 sound source identification. 2612. - 184 -.
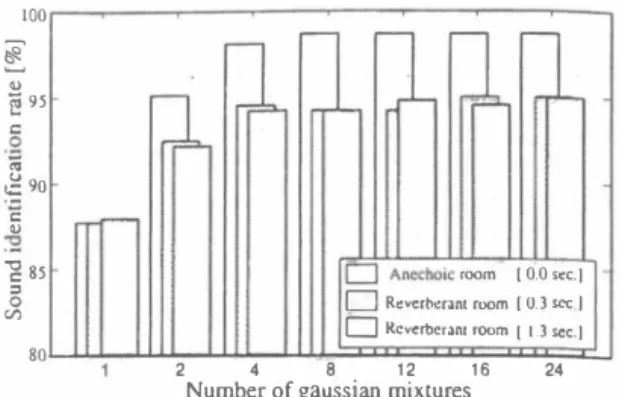
(3) =. _. � � ��n!. (2). l O Q[ηlヂQ[n], whereQ[n] is the co汀ect answer, Q[n] is the sound source identi fication result, and N is the number of all sounds. The ASR per formance is also evaluated by the word recognition rate (WRR). 3ふExperimental resu1ts. Figure 4(a)(b) show experimental results using a single transducer and a microphone aπay that steers the directivity to the known desired sound source position. In these 自gures, the bar graphs rep resent sound source identification rates (SIR), and the line graphs represent word recognition rates (WRR). First, we focus the bar graphs in Figure 4(a)(b). In these fig ures, by comparing the results using the single transducer and us mg the microphone a町ay steering, we can con自rm that the micro phone aπay steering results give a higher sound source identifica lion perfo口nance than the single transducer results especially in lower SNR environments. We therefore confirm that the proposed algorithm can achieve a higher sound source identification perfor mance by using the microphone a汀ay steering. Second, we describe the robustness against reverberation on the sound source identification. In Figure 4(b), the sound source identification performance using the microphone a汀ay steering is almost the same in each reverberant environment while the per formance tends to deciine slightly in the lower SNR and higher reverberant environments. With these results, we confirm that the proposed a1gorithm can distinguish“speech" or“non-speech" ac curately in higher reverberant environments.. 70云 円 60� 0 50� 40õ 2 30 ; 20� 10�. Z. 伺. � 50 E 40. 苦30. 30 20 的10. ‘5. 10. 15. 20. SNR [dB]. 25. 30. Ck胡. (a) Single transducer. .. 同ユ� ド ド 1.-". ν. �. If. v. ト 4・. v. 」凶円」 .5. 10. 15. 2u. SNR [dB]. lS. llUl JU Clean. 。. (b) Microphone aπay Figure 4: Experimental results.. N. r - , Ico,.[n] �: = 己川. '" 80高. e 70. perfoπnance with 616 sounds consisting of speech (216 words x 2 subjects (1 fema1e and 1 ma1e)) and environmental sounds (92 sounds x 2 sets). The ASR performance is also evaluated with speech (216 words x 2 subjects). Equation (2) shows a definition of the sound source identification rate (SIR). SIR. 90. !2 60. Experimental conditions for ASR 25 msec. (Hamming window) 10 msec. MFCC, ð.MFCC, ð.power (+ CMS [ 9]) 216 words x 2 subjects(l female and 1 male). ) .1印 ,.[n]. 100. ∞ ω ω 羽 田 日山崎 町剖初 叩 1[dF ]SEE M EEZE32 2 0凶. 1àble 3: Frame length I Frame interval I Feature vector I Test data (open) I. 100 90 í,ii' }80 ω 】. 的 自u zn F 百円 。 四 3 E O ロ E Z{ 4F } D O O D O UFD 恥 CO m dD 町内 aA e。e 'O 00ヲ 3D n uO n. 11able 2: Experimental conditions for sound source identi自cation Frame length -----:3 -r 2 msec. (Hamming window) Frame interval I 8 msec. Feature vector I MFCC (16 orders, 4 mixtures), ð.MFCC (16 orders, 4 mixtures), ムpower (1 order, 2 mixtu陀s) Number of models Speech: I model Non-speech: 1 model Speech DB ATR speech DB SetA [6] Speech model training 150 words x 16 subjects (8 female and 8 male) RWCP-DB [7,8] Non齢speech DB Non-speech model training 92 sounds x 20 sets Test data (Open) Speech: 216 words x 2 subjects (1 female and J maJe) Non-speech: 92 sounds x 2 sets. Next, we compare the proposed method with a conventional method using only speech GMM. Statistical sound source identi fication was ca出ed out with the conventional method by distin guishing“speech" or“non-speech" using a threshold. Figure 5 shows the threshold estimation. As shown in the figure, we calcu late accumulated Iikelihood histograms with training data. Then, we estimate the threshold for the conventional method by finding the equal probability point with the accumulated Iike1ihood his tograms. Figure 6 shows results of the proposed method and the conventional method with microphone aπay steering in 1ì60) = 0.3sec. environments. The sound source identification rate (SIR) is only about 70% with the conventional method in the higher SNR environments, although the identification performance improves where the SNR is higher. However, the sound source identi自ca tion rate is more than 90% with the proposed method not only in the higher SNR environments but a1so in the lower SNR environ ments. 百le performance of the conventional method using only speech GMM depends a 10t on the threshold. However, the pro posed method using speech and environmental sound GMMs can distinguish“speech" or“non-speech" accurately because its uses the di仔erence of two GMM's likelihoods. We also eva1uate the relationship of the number of Gaussian mixtures for feature vectors MFCC andムMFCC and the sound source identification rate. Figure 7 shows the resu1ts. In the figure, we can confirm that the sound source identification performance is a1most the same with more than four mixtures, whil巴 the per・ formance degrades with 1ess than two mixtures. Therefore, the proposed method may be able to distinguish“speech" or“non speech" even if speech and environmental sound GMMs consist of few mixtures.. 司O FヘU o 川 1ょ け a -・D nt.
(4) 100. { t'< ]. E 2 。 υ. ‘B. ë 9S z o. -. 2】同 90 巴 ‘' てコ. 亡コAnechoic r,∞m (0.0 sec.(. 8S 吉 2 O CIl. Figure 5: Threshold estimation by a conventional method ハu 《υ 内Uハu nυ《U 内u内4 nu旬a nu内U ハUnυ 内ud oo'' e。E3 aa守 内O ー{ J F ] ggzo z gq z Eヨ宮2 D m. 戸明.. F・帽. 一 四ー四. ,..--,. rー・・. ,...-,. r-. 80. 「ー. 15. 20. SNR [dB]. 25. 30. 4. 8. 12. 16. Number of gaussian mixtures. 24. recognized robustly with the microphone aπay in noisy reverber ant environments. In future works, we wilJ evaluate the proposed algorithm by using multiple sound source positions localized by the CSP coefficient addition method 5. REFERENCES. Non-$peech GMM. 10. 2. Figure 7: Relationship of the number of Gaussian mixtures for GMMs and sound source identification rate at SNR = 30 dB.. にコ Spe帥GMM にコ Sp蹴h GMM and .5. 口R叩beran( room [0.3町l EコRcve巾er3nl剛間 (1.3阻c.). Cl<an. Figure 6: Comparison of sound source identi白cation performance levels using the proposed method and conventional method. Finally, we focus on the line graphs showing the word recogni tion rates (WRR) in Figure 4(a)(b). In these figures, by comparing the results using the single transducer and using the microphone aπay steering, we can confirm that the microphone aπay steering results give a higher ASR performance especially in lower SNR environments than the single transducer results. As an example, we explain the ASR performance in the SNR = 10 dB environment. In the T[60J = 0.0 sec. and SNR = 10 dB environment, WRR is 58.3% for the single transducer. However, WRR improves from 58.3% to 92.6% using the microphone aπay. ln addition, in the TJ60J = 1.3 sec. and SNR = 20 dB environment, WRR is 37.1 % for the single transducer. However, WRR improv巴s from 37.1% to 64.3% using the microphone aπay. This con自rms that the pro posed algorithm using the microphone aπay results in a higher ASR performance than that using the single transducer not only in anechoic environments but also in reverberant environments According to the abov巴evaluation experiments, we confirm that the talker can be 10calized accurately by sound source identi fication using statistical speech and environmental sound GMMs and microphone aπay steering among known multiple sound sources We also confirm that the talker's speech can be recogniz�d robustly with the microphone aπay in noisy reverberant environments. 4. CONCLUSION. ln this paper, we propose a new talker localization algorithm and focus on sound source identi自cation among localized multiple sound sources with statistical speech and environmental sound models based on GMMs towards talker localization. ln evaluation experimental results, we confirm that the talker is localized accurately by the proposed algorithm with known sound source positions in reverberant noisy environments. In addition. the talker's speech is. [1] J.L. Flanagan, J.D_ Johnston, R. Zahn, and G.w. Elko, “Comput巴r-steered !TÚcrophone aπays for sound transduc tion in large rooms," J. Acoust. Soc. Am_, Vol. 78, No. 5. pp. 1508-1518, Nov. 1985. [2] M. Omologo, M. Matassoni, P. Svaizer, and D. Giuliani. “Microphone aπay based speech recognition with differt!nt talker-array position," Proc. ICASSP97, pp. 227-230, 1997 [3] E. Lleida, J. Fernandez, and E. Masgrau,“Robust Contin uous Speech Recognition System Based on a Microphone A汀ay," Proc. ICASSP98, pp. 241-244, May 1998. [4] T. Nishiura, T. Yamada, S. Nakamura, and K. Shikano.“Lo・ calization of Multiple Sound Sources Based on a CSP Analy sis with a Microphone Array," Proc. ICASSP2000, pp. 10531056. Jun. 2000 [5] R. Singh, M.L. Seltzer, B. Raj, and R.M. Stem, “Speech in Noisy Environments: Robust Automatic Segmentation. Feature Extraction, and Hypothesis Combination." Proc ICASSP2001, May 2001 [6] K. Takeda. Y. Sagisaka. and S. Katagiri, '‘Acoustic-Phonetic Labels in a Japanese Speech Database," Proc. European Con ference on Speech Technology, Vol. 2. pp. 13-16. Oct. 1987 [7] S. Nakamura. K. Hiyane. F. Asano. T. Yamada. and T. Endo. “Data Collection in Real Acoustical Environments for Sound Scene Understanding and Hands-Free Speech Recognition. Proc. Eurospeech99. pp. 2255-2258, Sep. 1999. [8] S. Nakamura, K. Hiyane. F. Asano. T. Nishiura. and T. Ya mada“ , Acoustical Sound Database in Real Environments tor Sound Scen巴Understanding and Hands-Free Speech Recog nition, " Pr∞. LREC2000. pp. 965-968,May. 2000. [9] B. Atal,“E仔'ectiveness of linear prediction charactenS(lc、 of the speech wave for automatic speaker identi自cation a"J verification." J. Acoust. Soc. Am., Vol. 55, pp. 1304-1312. 1974. 2614. - 186-.
(5)
図

関連したドキュメント
ICレコーダーの本体メモリーには、ソフトウェアSound Organizer 2が保存されて います。Sound Organizer 1.6をお使いの方も、必ずSound Organizer
On a theoretical side, we state a sound probability space for lucidity and thus for modularity and prove that in this paradigm of lucidity, using a subtractive trade-off and either
Apalara; Well-posedness and exponential stability for a linear damped Timoshenko system with second sound and internal distributed delay, Electronic Journal of Differential
The statistical procedure proposed in this paper has the following advantages over the existing techniques: (i) the estimates are obtained for covariate dependence for different
Economic and vital statistics were the Society’s staples but in the 1920s a new kind of statistician appeared with new interests and in 1933-4 the Society responded by establishing
After introducing a new concept of weak statistically Cauchy sequence, it is established that every weak statistically Cauchy sequence in a normed space is statistically bounded
Discrete holomorphicity and parafermionic observables, which have been used in the past few years to study planar models of statistical physics (in particular their
In this chapter, we shall introduce light affine phase semantics, which is meant to be a sound and complete semantics for ILAL, and show the finite model property for ILAL.. As
