DEIM Forum 2016 D5-1
汎用分散処理システムでの大規模分散システムシミュレーション
加藤 裕也
†杉野 好宏
†華井 雅俊
†首藤
一幸
††
東京工業大学情報理工学研究科 〒 152-8552 東京都目黒区大岡山 2-12-1
E-mail:
†
[email protected]
あらまし
今日,インターネット上では様々な分散システムが運用されている.大規模なネットワークで動作する分
散システムの場合,システムの挙動を把握するために,しばしばシミュレーションによる検証が行われる.大規模な
シミュレーションのために,複数の計算機を用いる場合,汎用分散処理システムを利用することで耐故障処理やジョ
ブスケジューリングといった機能を享受できる.本研究では,汎用分散処理システム上で分散システムシミュレーショ
ンを行い,その妥当性を評価した.また,楽観的時刻管理アルゴリズムを用いた場合のメモリ不足への対応策として,
投機的実行を時間窓で制限する手法を適用し,その評価を行った.
キーワード
シミュレーション,MapReduce,分散システム,並列離散事象シミュレーション
1.
は じ め に
今日,インターネット上では様々な分散システムが運用され ている.他の情報システムがそうであるように,分散システム においても,開発時点でシステムが運用先でも正しく動作する ことを確認する必要がある.システムの運用先での挙動を確認 するためには,実環境に近い環境を構築した上で検証を行う 方法と,実環境に近い仮想環境をシミュレータ上に構築してシ ミュレーションを行う方法の2つが考えられる. 現在動作している分散システムの1つである BitTorrent Mainline DHT のノード数は1,000万ノード規模に達してい る[1].また,インターネットに接続している機器は2013年時 点で100億台を突破しており,2020年には約500億台に達す ると予測されている[2].現在インターネットに接続されてい ないモノが今後接続されるようになることを想定すると,分散 システムの規模は今後も更に大きくなっていくものと考えられ る.大規模な分散システムの場合,実環境に近い環境を構築す ることは困難である.シミュレータを用いる場合も,複数の計 算機による分散処理が必要となる.Hadoop MapReduceやSparkのような汎用分散処理システ ムは,耐故障処理やジョブスケジューリングといった機能を提供 する.汎用分散処理システム上でシミュレータを実現すること で得られるメリットは多い.今回,汎用分散処理システム上で の大規模分散システムシミュレーションの評価として,Hadoop MapReduce及びSpark上での分散システムシミュレータの評 価と比較を行った.また,汎用分散処理システム上での大規模 シミュレーションにおけるメモリ不足への対応策として,時刻 管理アルゴリズムの最適化手法を適用し,その評価を行った.
2.
関 連 研 究
アンダーレイネットワークを対象としたシミュレータに ns-2 [3],ns-3 [4]がある.その延長上として分散システムシミュ レーションが可能である.アンダーレイネットワークのシミュ レーションには大きな計算リソースが必要であり,これにより シミュレーション規模の拡大が制限されうる.本研究では,現 在アルゴリズムレベルのシミュレーションを想定しているが, アンダーレイネットワークも含めた詳細なシミュレーションに も今後取り組んでいく. オーバーレ イネットワークを対象とし たシミュレータにOverlay Weaver [5], [6]やPeerSim [7], [8], dPeerSim [9]があ る.Overlay Weaverでは,シミュレーションのために実装し たアルゴリズムをそのまま実ネットワーク上で動作させること ができる.最大100万ノード程度のシミュレーションが可能で あり,複数の計算機での分散シミュレーションも可能である. PeerSimでは,100万ノードでのクエリ・サイクル・シミュレー ションが可能である.PeerSimの分散版であるdPeerSimはシ ミュレート対象の大規模化に対応するため,効率よくスケール アウトするよう改良された.しかし,非分散のPeerSimがシ ミュレート可能な範囲では,dPeerSimは同じシミュレーショ ンの実行に100倍以上の時間を要することもある. 大規模な分散システムを現実的な時間でシミュレートするに は,シミュレーションに用いる計算機を増やしてメモリ容量や 処理速度を稼ぐ必要がある.多くの既存シミュレータでは数 十台を超える規模の計算機クラスタで動作することを想定し てない.dPeerSimの例から,性能を保ちながら既存のシミュ レータを大規模なシミュレート対象に対応できるよう分散化す ることは困難である.また,規模の大きな計算機クラスタで は,シミュレーション中に一部の計算機が停止することも考え られる.その場合,一部の計算機が停止したのがどのタイミン グであっても,シミュレーションを最初から実行し直すことと なる.そのため,大規模分散システムを対象としたシミュレー タは,スケーラビリティと耐故障性が不可欠である.その点で 汎用分散処理システム上で動作するシミュレータに価値がある と考える.汎用分散処理ステム上のシミュレータにはHadoop MapReduceでの実装[10]があり,本論文で用いる. 時刻管理アルゴリズムに関する研究は様々あり,本研究でも それらの扱う手法の内,いくつかを適用している.それらにつ いては付録や提案手法の項で言及する.
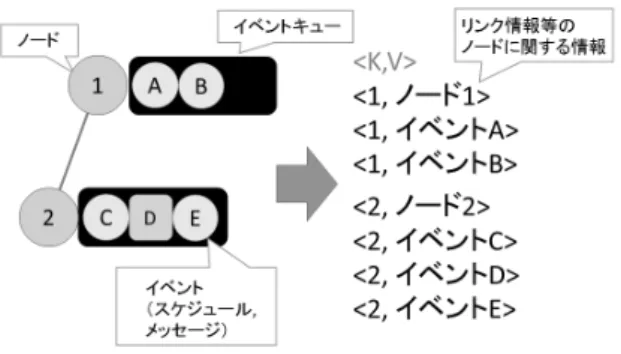
図 1 key-value ペアによる分散システム表現
3.
汎用分散処理システムでのシミュレーション
手法
本章では今回用いたシミュレータにおける分散システムの表 現方法について述べる.今回用いたシミュレータでは,ネット ワーク上のノードが離散事象シミュレーションにおける論理プ ロセスと対応する. 3. 1 分散システムの表現 現実の分散システムでは,各ノードが自身の持つ情報を基に 自律的に動き,インターネットを介したノード間通信により相 互作用することでシステム全体が機能する.汎用分散処理シス テム上で分散システムのシミュレーションを行うためには,こ れをシステムが処理可能な計算モデルに落とし込む必要がある. 今回用いたシミュレータでは計算モデルMapReduce上で分散 システムを表現し,その挙動をシミュレートする. 3. 1. 1 データ形式 MapReduceが扱うデータの形式はkey-valueペアであるた め,分散システムの表現もこの形式をとっている.keyにはノー ドのID,valueには表現対象のそれぞれに必要な情報を割り当 てる.分散システムを表現するために必要な情報は,ノードが 保持する情報,ネットワーク情報,シミュレーションのイベン ト情報である.ノードが保持する情報には隣接ノードのIDや, ノードの持つアプリケーションデータ等が含まれる.シミュ レーションのイベント情報には,特定の操作の実行スケジュー ルや,ノード間通信の抽象化であるメッセージを含む.シミュ レーションはイベントの発生順に従って進むため,イベントに はタイムスタンプを付与する. 3. 1. 2 処理フロー シミュレーションは MapReduceに従い,Map フェーズ, Shuffleフェーズ,Reduceフェーズを繰り返すことで進行する. Mapフェーズでは,そのiterationで扱うデータをすべて観測 し,最小のタイムスタンプを割り出し,各Reducerに配布する 仮想時刻データを作成する.Shuffleフェーズでは,Mapフェー ズで作成した仮想時刻データとともに,ノード情報やイベント 情報データ群をノードIDごとにまとめられるようにReducer へ送信する.Reduceフェーズでは,ノードIDごとに仮想時 刻データとノード情報の処理を行った後,そのノードに関す るイベントをタイムスタンプに従って処理を行う.このように iterationごとにノードID単位でのデータの集約とイベント処 理を行うことで,メッセージの送受信を表現することができる. 最終的に未実行イベントがなくなるか,iteration回数が一定の 値に達するまで繰り返す. 3. 2 実 装 本論文では,汎用分散処理システムとして,Hadoop MapRe-duceとSparkを採用した.それぞれの詳細は付録で述べる.ま た,Hadoop MapReduce上のシミュレータは先行研究[10]の ものを用い,Spark上のシミュレータは同様の処理フローとな るよう新たに実装した. 前述の分散システムの表現形式では,Reduceフェーズにお けるデータの処理順が重要である.データがタイムスタンプ順 に並んでいなければ正しいシミュレーション結果は得られない. また,Reduceフェーズにおいてノード情報の処理を完了する 前にイベント処理を開始してしまった場合にもシミュレーショ ン結果に矛盾が生じるため,ノード情報がイベント情報よりも 先に処理されるように順序付けしなければならない. Hadoop MapReduceではセカンダリソートがサポートされ ており,keyにノードIDだけでなく,タイムスタンプやデータ の種類といった情報を付加することで,Shuffleフェーズの時点 で正しい順序付けを可能としている.Sparkでは別途,Reduce フェーズにおいて受信したデータすべてに対して順序付けを行 うためのソートを実装している.両者の基本的な処理の流れは 前述の分散システムの表現形式に従うが,このような些細な差 異は存在する.4.
投機的実行への制限
MapReduceモデルでのシミュレーションでは,データの送 受信がShuffleフェーズに限定されるため,メッセージのやり取 りが生じるたびに同期が必要となる.汎用分散処理システム上 でのシミュレーションにおいて,同期によるオーバーヘッドは 実行時間に大きく影響する.そのため,同期回数を抑制できる 楽観的時刻管理アルゴリズムを採用するメリットが大きい.し かし,汎用分散処理システムが動作するマシンはコモディティ であることが多く,メモリを始めとする計算リソースには制限 がある.このような場合に,メモリを大量に消費する楽観的時 刻管理アルゴリズムを用いると,問題が生じることもある.特 にSparkはオンメモリ処理であるため,楽観的時刻管理アル ゴリズムを採用する場合に,メモリ不足が原因で,シミュレー ションが失敗する,あるいは実行時間が非常に長くなるといっ た事態が起こりやすいと予想される. 楽観的時刻管理アルゴリズムを用いたシミュレーションにお いて,リソースを消費する主な原因となっているのは,イベン トキュー内のすべてのイベントを処理することによって発生す る大量のメッセージとアンチメッセージ,ロールバック先の状 態を保存するための状態のスナップショットである.メッセー ジが抑制されれば,新たに発生するイベントが少なくなり,管 理しておく必要のあるスナップショットも必然的に少なくなる. よって,リソースの消費を抑えるには,まずメッセージの大量発生を防ぐ必要がある.また,汎用分散処理システムにおいて 問題となるのは全体のメッセージ数よりも,iterationごとの メッセージ数である. 今回,iterationごとのメッセージ数を抑制するため,Time Warpの処理範囲を限定したアルゴリズムをシミュレータに適 用し,シミュレーション性能の変化を評価する.
4. 1 Moving Time Window
Moving Time Window (MTW) [22]はbounded lagアルゴ リズムとTime Warpを組み合わせたアルゴリズムである. MTWは論理プロセス全体の最小時刻T 一定の時間窓W の間 のイベント,つまり[ T , T + W ]のタイムスタンプを持つイ ベントのみを投機的に処理する.この間のイベント処理では, Time Warpと同様,イベントの処理順序に矛盾が生じること を許容する.これにより,イベントキューの一部のみを楽観的 時刻管理アルゴリズムで処理することとなり,iteration回数を 抑えながらメッセージ発生量も抑えることができる.MTWで は,投機的実行を制御する時間窓 W のサイズは一定であり, シミュレーション実行前に静的に決定する.しかし,時間窓の サイズを動的に変更すること自体は容易である.
4. 2 Adaptive Time Warp
投機的実行の有効範囲に制限を与えるアルゴリズムとして,
Adaptive Time Warp (ATW) [23]がある.ATWでは,シミュ レーション実行中のパラメータを基に,投機的実行の基準を調 整する.参照するシミュレーション実行中のパラメータとして は,ある期間内における送信メッセージやアンチメッセージの 数,ロールバックの有無や多寡,ロールバック元とロールバッ ク先の時間的距離といった様々な要素が挙げられる.投機的実 行の有効範囲の基準には,時間窓のサイズや処理可能な未処理 メッセージ数の上限が挙げられる.参照するパラメータや投機 的実行の有効範囲の基準によって,シミュレーション実行に及 ぼす効果に差異がある.メッセージやアンチメッセージ,ロー ルバック発生の有無に注目し,時間窓や処理可能なメッセージ 数に制限をかけることでメモリ消費を抑えたシミュレーション 実行が期待できる.
MTW,ATWはTime Warpを用いたシミュレーションの 高速化を目的としたものだが,本論文では,汎用分散処理シス テムで問題となりうるメモリ不足への対応策として適用した.
5.
実験・評価
今回,シミュレータ上でfloodingによるファイル検索を行う Gnutellaプロトコル[24]のシミュレーションを行った.実験で は,各ノードに固有のアプリケーションデータを与えている. 実験環境は表1の通りで,マスター1台,スレーブ10台の計 11台で実験を行った.本実験で用いたHadoop MapReduce及 びSparkのパラメータを表2,表3に示す. 5. 1 2次元正方メッシュネットワークでの評価Hadoop MapReduceとSpark上に実装されたシミュレータ の性能を比較するため,まずiteration ごとのイベント数の増 加数が少ないシミュレーションで比較を行う.ネットワーク遅 延は一定で,すべてのデータ検索を同時に行う.また,シミュ
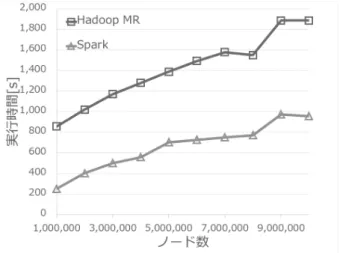
表 1 実験環境と共通パラメータ OS Ubuntu 14.04.2 LTS CPU 2.40 GHz Intel Xeon E5620 × 2 Java 仮想マシン Java SE 8 Update 45
Scala 2.11.6 yarn.nodemanager 30000 .resource.memory-mb 表 2 Hadoop MapReduce のパラメータ mapreduce.map.memory.mb 2048 mapreduce.map.java.opts -Xmx1500M mapreduce.reduce.memory.mb 3072 mapreduce.reduce.java.opts -Xmx2500 表 3 Spark のパラメータ spark.executor.instances 19 spark.executor.memory 12G spark.executor.cores 4 spark.driver,memory 5G spark.serializer org.apache.spark. serializer.JavaSerializer spark.shuffle.manager sort spark.task.cpus 1 図 2 2 次元正方メッシュネットワークシミュレーションの実行時間 レーションは最もタイムスタンプの小さいイベントを追いかけ るように進行する保守的な時間管理に基づく. 2次元メッシュネットワークにおいて,1辺のノード数が1,000, 1,500,2,000,2,500,3,000である2次元正方メッシュネット ワーク上で,20%のノードが同時にデータ検索をシミュレート する.実験結果を図2に示す.Hadoop MapReduce,Sparkシ ミュレータともにノード数の増加に伴って同じように実行時間 が伸びている.両者の実行時間の差は,Hadoop MapReduce の欠点であるジョブごとの分散ファイルシステムへの読み書き や,ジョブの準備処理によるものが大きい. 5. 2 複雑ネットワークでの評価 次に,iterationごとのイベント数の増加数が非常に大きくな りうるシミュレーションで両者の比較を行った. m=1,2のBarabasi-Albert (BA)モデル[25]において100
図 3 複雑ネットワークシミュレーション (m=1) の実行時間 件のデータ検索をシミュレートした.ネットワーク遅延は一定 で,すべてのデータ検索を同時に行った.また,シミュレーショ ンは最もタイムスタンプの小さいイベントを追いかけるように 進行する保守的な時間管理に基づく. ネットワーク上のノード数は106から107まで,106ノード 間隔で実験を行った.実験結果を図3,図4に示す.2次元メッ シュネットワークでの実験と同様,Hadoop MapReduceのオー バーヘッドが顕著である他,Sparkシミュレータにおいて,特 にm=1において処理時間の伸び方が不安定になっている.タ スクごとの実行時間を調査したところ,ネットワークのハブに 該当するノードを割り当てられたごく一部のタスクの実行時間 が他のタスクの実行時間に比べて非常に長くなっていた.複雑 ネットワークでは,リンクが集中しているノードが存在し,そ のノードが隣接ノードすべてにメッセージを送るような場合, イベント数が爆発的に増加した.この性質が,タスクごとの実 行時間に大きな影響を与えている.m=2のケースにおいては, ハブに該当するノードが多く存在するため,他のタスクよりも 実行時間が非常に長くなるというケースが起きにくかったもの と考えられる. 汎用分散処理システムの想定するアプリケーションでは,基 本的には処理を行ってもデータサイズが増加しない,あるい は処理を繰り返すたびにデータサイズが小さくなる.一方で, floodingを行うアプリケーションのシミュレーションような, 処理中に全体データサイズが大きくなっていく場合においては, 想定外の負荷がかかる可能性がある.特に,爆発的にメッセー ジ数が増加し得る複雑ネットワークとリソース制約の大きい Sparkの組み合わせでは影響を受けやすいものと考えられる. Spark上のシミュレータでは,シミュレーション内容によって は完了までの時間の予測が困難になるという問題が浮かぶ. また,m=2のBAモデルにおいて,Hadoop MapReduceと Spark,双方のシミュレータで108ノードまでの動作を確認し た.その際の実行時間を図5に示す. 5. 3 時間窓による投機的実行制限 本項では,シミュレータに楽観的アルゴリズムを適用した状 態で投機的実行に制限を設け,その影響を測る.投機的実行の 図 4 複雑ネットワークシミュレーション (m=2) の実行時間 図 5 大規模複雑ネットワークシミュレーションの実行時間 制限方法はMTWとATWを用いる.ネットワークトポロジ は1辺のノード数が1,000ノードの2次元正方メッシュネット ワークを用いる.合計100万ノードの上で,100秒間の間にラ ンダムなタイミングで1万件のデータ検索を行う. 5. 3. 1 MTWによる制限
Lazy Cancellationを適用したTime WarpにさらにMTW
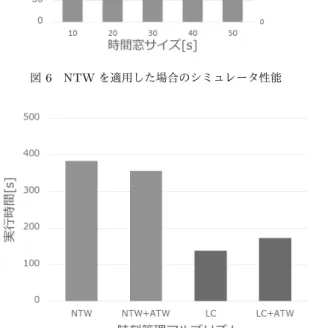
を適用した.時間窓サイズは,10秒から50秒の間で10秒刻 みで変化させた.実行時間の変化やシミュレーション中に同時 にシミュレータ上に存在したメッセージ及びアンチメッセージ の数(メッセージ数)を測定した.その結果を図6に示す. 今回,データ検索を行うタイミングは一様乱数により決定 されており,一定の期間に大きくイベントが集中するような偏 りは生じていない.そのため,時間窓サイズに応じて,線形に メッセージ数が増加していく.実行時間も時間窓サイズに応じ て減少していく.しかし,時間窓サイズを大きくするとイベン ト処理が多く発生する.さらに時間窓の外に存在するイベント は未処理のまま残されるため,最終的なiteration回数の抑制 は頭打ちとなる.そのため,実行時間の減少は線形にならず, 時間窓のサイズが一定の値に到達するとほぼ減少しなくなった か,やや増加した. 5. 3. 2 ATWによる制限
Can-図 6 NTW を適用した場合のシミュレータ性能
図 7 ATW を適用した場合のシミュレーション実行時間
図 8 ATW を適用した場合の iteration 回数
cellation(図中ではLC)を適用したTime WarpにATWを
適用した.ATWにおける投機的実行の有効範囲には,処理可 能メッセージ数や時間窓等,いくつかのパラメータが考えられ るが,今回はMTWとの比較を考慮し時間窓を用いた.時間 窓に影響を与えるパラメータは前iteration中のメッセージ及 びアンチメッセージの総数とした.この数が300万件を超える と,時間窓サイズが半分になり,そうでない場合は時間窓サイ ズが10秒ずつ拡大する.時間窓サイズの初期値は100秒とし た.その上で,実行時間の変化やメッセージ数を測定した.そ の結果を図7,図8,図9に示す. 図 9 ATW を適用した場合の最大メッセージ数
ナイーブなTime Warpにおいては,ATWを用いた場合に
若干の実行時間の減少が見られた.Lazy Cancellationにおい ては実行時間が増加する結果となった.今回はイベント処理順 の矛盾がその後のメッセージ送信に大きく影響しないアプリ ケーションを用いたため,このような結果となったが,Lazy Cancellationが上手く働かないようなアプリケーションを用い た際には,ATWを利用することで,実行時間が減少する可能 性がある.
また,ナイーブなTime Warp及びLazy Cancellationとも に,ATWを用いた場合の方がiteration回数に対する実行時間 が短くなっている.これは,投機的実行可能な範囲に制限を設 けることによって,1iterationごとのイベント処理が減少した ことによる. シミュレート中の最大メッセージ数に関しては,どちらの ケースにおいても20∼ 30%の抑制が確認された.300万メッ セージという値は,ナイーブなTime Warpにおける最大メッ セージ数の約50%の値である.この値の周辺に収まらなかっ た理由として,Gnutellaのようなfloodingを行うアプリケー ションでは,メッセージの増加が爆発的であり,閾値を一度に 大きく上回ることが挙げられる. 5. 3. 3 MTW vs. ATW MTW,ATWの双方において,目的であったメッセージ数 の抑制は確認できた.ここではMTWとATWを用いたシミュ レーションについて議論を行う. ATWの実験は,閾値からMTWにおける時間窓サイズ50 秒でのシミュレーションに相当する.ATWではメッセージの 抑制は20%程度であり,実行時間もメッセージ抑制の効果も MTWに劣る.しかし,実際の運用を考えると,MTWで時間 窓サイズを適切な値に設定するためには,1度シミュレーショ ンを実行し,メモリ使用量のピーク値を把握しなければならな い.同じアプリケーションを用いたシミュレーションでも,メ モリ使用の状況はシナリオごとに大きく変化し得る.そのため, 実行したことのないシナリオのシミュレーションでは,時間窓 サイズの設定は困難である.一方で,一度大きな計算機クラス タで実行したことのあるシナリオまたはその類似シナリオを, 規模を縮小した計算機クラスタで実行する等の場合には有効で
ある.また,今回のシミュレーションではイベント処理のタイ ミングに偏りがなかったため問題とはならなかったが,時間窓 に収まる一定期間内にイベントが集中すると,MTWではメッ セージ数を抑制することはできない. ATWの場合,アプリケーションからシミュレーションで扱 うことのできるメッセージ数の上限を計算し,それを閾値のヒ ントとすることが可能である.時間窓のサイズは適当であって も,実行中に調整されていくため,実行したことのないシナリ オのシミュレーションでも対応できる.さらに,ATWでの投 機的実行可能な範囲の制限は時間窓に限ったものではないため, 処理可能なイベント数や送信可能なメッセージ数を加味するこ とで,メッセージ抑制能力は向上する.また,イベントの発生 時刻の偏りにも柔軟に対応できる.
6.
ま
と
め
本論文では,汎用分散処理システムによる大規模分散システ ムシミュレーションを目的に,Hadoop MapReduceとSparkで のシミュレーションとその比較を行った.その結果から,Spark 上のシミュレータがHadoopのものより高速であるが,実行時 間の予測が困難になりうることを指摘した. また,Time Warpを利用したシミュレーションを汎用分散 処理システムで行う上で課題となりうるメモリ不足の問題に対 して,時間窓による投機的実行の制限により,メッセージ数を 削減することで対応することを提案した.MTW,ATWの2 つの手法で,シミュレーション中のメッセージ量が抑制できる ことを確認した.今回の実験の対象としたシステムの規模は大 きくはないが,同手法は規模を大きくした場合にも適用できる. ATWにより投機的実行を制限する上で適切なパラメータと アルゴリズムの模索は今後の課題である.様々なパラメータか らその都度適切なものを選択し,それを用いてシミュレーショ ンを操作することができれば,メモリ消費を抑えつつ,シミュ レーションの高速化も狙える.また,シミュレータ上に様々な プロトコルを実装した上で,既存シミュレータとの比較を行う こともシミュレータの立ち位置を示すために必要である.負荷 分散や,多くの計算機を用いたさらに大規模なシミュレーショ ンも今後の課題である.シミュレート対象となるネットワーク トポロジやアプリケーションアルゴリズム,シナリオの内容を 考慮して負荷分散を行い,計算リソースを効率よく運用するこ とで,更なる高速化が見込めるものと考える.また,より多く の計算機を用いることで,シミュレーションの高速化と対象シ ステムの大規模化が可能であると考える.7.
謝
辞
本研究はJSPS科研費25700008,26540161の助成を受けた ものである. 文 献[1] Decentralized Systems and Network Services Research Group in Karlsruhe Institute of Technology, “Live Moni-toring of the BitTorrent DHT”.
http://dsn.tm.unikarlsruhe.de/english/2936.php .
[2] J. Bradley, J. Barbier, D. Handler, “Embracing the Inter-net of Everything To Capture Your Share of $14.4 Trillion” , 2013-2. http://www.cisco.com/web/about/ac79/docs/innov /IoE Economy.pdf .
[3] “ns-2”. http://www.isi.edu/nsnam/ns/ . [4] “ns-3”. https://www.nsnam.org/ .
[5] K. Shudo, “Overlay Weaver: An Overlay Construction Toolkit”, http://overlayweaver.sourceforge.net/.
[6] K. Shudo, Y. Tanaka, S. Sekiguchi: “Overlay Weaver: An Overlay Construction Toolkit”, Computer Communica-tions, Vol. 31, No. 2, pp.402–412, 2008.
[7] “PeerSim: A Peer-to-Peer Simulator”, http://peersim.sourceforge.net/
[8] A. A. Jamal, W. S. W. Awang, M. F. A. Kadir, A. A. Aziz, W. J. Teahan, “Implementation of Resource Discov-ery Mechanisms on PeerSim: Enabling up to One Million Nodes P2P Simulation”.
[9] T. T. A. Dinh, M. Lees, G. Theodoropoulos, R. Min-son, “Large Scale Distributed Simulation of p2p Networks”, Proc. Parallel, Distributed and Network-Based, 2008. PDP 2008. 16th Euromicro Conference on. IEEE, 2008. [10] 杉野 好宏, 華井雅俊, 首藤一幸, “MapReduce による大規模分散
システムのシミュレーション” , 電子情報通信学会技術研究報告. NS, ネットワークシステム 113(244), pp.99–104, 2013-10-10 . [11] “Apache Hadoop”, http://hadoop.apache.org/.
[12] “Apache Mesos”, http://mesos.apache.org/ .
[13] J. Dean, S. Ghemawat, “MapReduce: Simplified Data Pro-cessing on Large Clusters”, Proc. OSDI ’04, 2004. [14] “MapReduce NextGen aka YARN aka MRv2”.
https://hadoop.apache.org/docs/current/hadoop-yarn/ hadoop-yarn-site/index.html .
[15] “Apache Hadoop Project: Hadoop Wiki - PoweredBy”, 2012. http://wiki.apache.org/hadoop/PoweredBy.
[16] “Apache Spark - Lightning-Fast Cluster Computing”, http://spark.apache.org/ .
[17] M. Zaharia, M. Chowdhury, T. Das, A. Dave, J. Ma, M. McCauley, M. J. Franklin, S. Shenker, I. Stoica, “Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing”, Proc. 9th USENIX confer-ence on Networked Systems Design and Implementation, April 25–27, 2012, San Jose, CA .
[18] M. Dobashi, K. Saruta, T. Shimogaki, M. Tsuzuki, “NTT DATA: Operating Spark clusters at thousands-core scale and use cases for Telco and IoT”, 2015. https://databricks.com/blog/2015/05/14/ntt-data-operating- spark-clusters-at-thousands-core-scale-and-use-cases-for-telco-and-iot.html .
[19] B. D. Lubachevsky, “Bounded lag distributed discrete event simulation”. SCS Multiconference on Distributed Simula-tion, 1988.
[20] D. R. Jefferson, “Virtual time”. ACM Transactions on Pro-gramming Languages and Systems (TOPLAS), Vol 7 Issue 3, pp. 404–425, July 1985.
[21] A. Gagni, “Space management and cancellation mecha-nisms for Time Warp”. Tech. Rep. TR-85-341, University of Southern California, Los Angeles (Ca, USA), 1985. [22] L. M. Socol, D. P. Briscoo, A. P. Wieland , “MTW: A
strat-egy for scheduling discrete simulation events for concurrent execution”, SCS Multiconference on Distributed Simula-tion. 1988.
[23] K. S. Panesar, and R. M. Fujimoto, “Adaptive flow control in time warp.” Proc. 11th IEEE’s Workshop on Parallel and Distributed Simulation, 1997.
[24] “The Annotated Gnutella Protocol Specification v0.4”, http://rfc-gnutella.sourceforge.net/developer/stable/index.html .
networks”. Science, Vol. 286, No. 509, 1999.
A
付録・汎用分散処理システム
本論文では,Apache Hadoop [11] やApache Mesos [12]と いった信頼性とスケーラビリティを備えた汎用的な分散並列処 理基盤の上で動作するシステムのうち,用途の広いシステム を汎用分散処理システムと呼ぶ.今回評価対象としたHadoop MapReduceやSparkが汎用分散処理システムに該当する. A 1 Hadoop MapReduce Hadoop MapReduceは,大量データ処理向けプログラミング モデルMapReduce [13]のオープンソース・ソフトウェア実装で ある.現在のHadoop MapReduce 2.0はHadoop YARN [14]
ベースの大規模データ向け分散処理システムである.ジョブの 実行中に一部の計算機が故障した場合にも,計算途中で失われ たタスクを再実行することで高い耐障害性を達成している.大 規模な計算クラスタでの実用例として,4,500台での運用実績 がある[15]. Hadoop MapReduce を繰り返しの計算処理に用いる場合, ジョブに必要なファイル群の配布や Java 仮想マシンの起動, 分散ファイルシステムへの中間データの読み書きといった,実 際の計算とは関係のない部分に時間がかかってしまう.このた め,反復処理が必要なアプリケーションには適していない. A 2 Spark Spark [16]はHadoop同様,汎用的なオープンソースデー タ処理フレームワークである.SparkはDAGという計算モ デルを採用しており,中間データの書き込みのようなディス クI/Oを極力起こさないように動作する.そのため,Hadoop MapReduceのようにデータを処理してその都度ディスクに書き 出す方式よりも高速である.SparkではResilient Distributed Dataset (RDD) [17] という不変なコレクションを導入してい る.RDDを用いることで,ジョブの実行中に計算機の故障等 の原因でデータの一部が失われたとしても再構築が可能である. これにより,耐故障性を達成している.4,000コアの大規模な 計算機クラスタで試行が行われた例もある[18]. Sparkでは,ジョブ実行中のJava仮想マシンの常駐化,一般 化された計算モデル,データキャッシング等の恩恵により,反 復処理を効率よく行うことが可能である.一方で,オンメモリ 処理を行う以上,計算機クラスタの総メモリ容量を大きく上回 るサイズのデータを扱うことはできない.
B
付録・時刻管理アルゴリズム
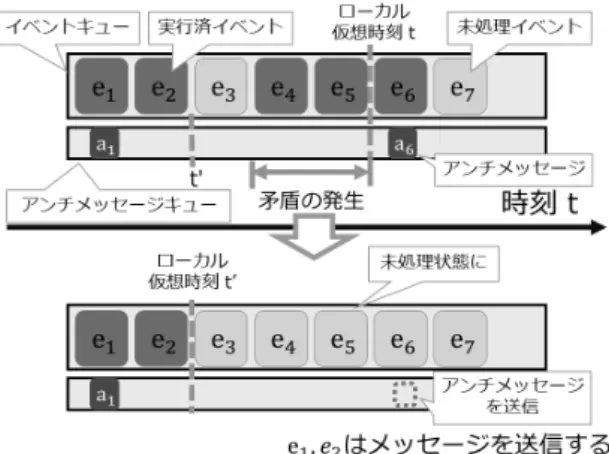
今回扱うネットワークシミュレーションのような離散事象シ ミュレーションは,シミュレート対象の構成単位である論理プ ロセスと論理プロセスの状態を変化させるイベントから構成さ れる.各論理プロセスはイベントを収容するイベントキューを 持つ.シミュレーション実行時にはイベントキューの先頭のイ ベントから順に処理を行う.イベント処理の時刻管理アルゴリ ズムには,大きく分けて保守的アルゴリズムと楽観的アルゴリ ズムの2つがある. B 1 保守的アルゴリズム:bounded lag 保守的アルゴリズムでは,シミュレーション中のイベントの 発生順を正確に追いかける形で処理を進める.そのため,イベ ントの処理順序に矛盾が生じないようにシミュレーション全体 を監視し管理する必要がある.一般に,シミュレーション全体 を監視するには,全論理プロセスの同期を頻繁に行う必要が ある.しかし,分散処理において,全体を同期するコストは大 きく,頻繁な同期は多大なオーバーヘッドを招く.保守的アル ゴリズムの例として,bounded lagアルゴリズム[19]が挙げら れる. bounded lagアルゴリズムは,論理プロセス全体の最小時刻 Tから一定の時間Dminの間,つまり[T ,T + Dmin]のタイム スタンプを持つイベントの処理のみを許可する時刻管理アルゴ リズムである.Dminはネットワーク遅延の最小値であるため, この間におけるイベント処理は処理順序の矛盾を生じさせない. これにより,最小のタイムスタンプのみを追いかけるよりは一 度に多くのイベントを処理できる.しかし,ネットワーク遅延 の最小値に対し,ネットワーク遅延の最大値が非常に大きい場 合には,非効率である. B 2 楽観的アルゴリズム:Time Warp 楽観的アルゴリズムでは,シミュレーション中のイベント処 理順序の矛盾を許容し,投機的にイベントを処理することで同 期回数を抑制する.本論文では楽観的時刻管理アルゴリズムで あるTime Warp [20]を用いる.ここではTime Warpの概要 を述べる. 各論理プロセスは,自身の持つイベントキュー内のイベント をタイムスタンプの昇順で処理する.時刻の管理は論理プロセ スごとに独立して行い,イベントキュー内のすべてのイベント を投機的に処理する.処理を行ったイベントには処理済みを意 味するラベルを付ける.論理プロセス間での通信により,イベ ントキューに追加されたイベントのタイムスタンプが処理済み のイベントのタイムスタンプよりも小さかった場合,イベント の処理順序に矛盾が生じたこととなる.このようにしてイベン トの処理順序に矛盾が生じた場合,新たにイベントキューに追 加された未処理のイベントのタイムスタンプの時刻まで論理プ ロセスの状態を戻す.その後,その時刻を論理プロセスの保持 するシミュレーション時刻とする.シミュレーション時刻の更 新後,イベントキュー内のシミュレーション時刻以降のタイム スタンプを持つ処理済みイベントの実行を取り消す.この操作 をロールバックと呼ぶ.ロールバックの例を図10に示す. 他の論理プロセスへのメッセージ送信の取り消しには,アン チメッセージというメッセージ取り消し通知を用いる.他の論 理プロセスへのメッセージ送信時には,送信するメッセージと 対応するアンチメッセージを生成し,メッセージ送信の取り消 しが必要になるまでそれを保持する.ロールバック発生時,矛 盾が発生した論理プロセスは,ロールバック先の時刻以降のタ イムスタンプを持つアンチメッセージを,対応するメッセージ の送信先論理プロセスへと送信する.アンチメッセージを受信 した論理プロセスは,自身のイベントキューから対応するメッ セージを削除し,アンチメッセージのタイムスタンプの時刻ま図 10 key-value ペアによる分散システム表現 でロールバックを行う.これにより,連鎖的にロールバックが 起こり,投機的な処理によって発生したイベント処理順序の矛 盾は解消される.最終的に,正確なシミュレーション結果へと 収束する. Time Warpは,保守的アルゴリズムを用いた場合よりもシ ミュレーション中の同期回数を抑えることができる一方で,ア ンチメッセージが大量に発生することによりメモリやCPUと いった計算リソースを多く必要とする. B 3 楽観的アルゴリズムの最適化:Lazy Cancellation Time Warpを用いることで,シミュレーション中の同期回 数を抑えることができる.しかし,通常のTime Warpでは, アンチメッセージによるロールバックが連鎖的に発生し,それ に伴うイベントの再実行がオーバーヘッドとなり得る.よって, アンチメッセージの送信を可能な限り回避し,ロールバックの 発生回数を抑えることにより,シミュレーション実行時間を抑 えることができると考えられる.Lazy Cancellation [21]は,こ れを実現したアルゴリズムである. 通常のTime Warpを用いる場合,イベントの処理順序に矛 盾が生じると,その時点で即座にアンチメッセージを送信し, イベント処理の取り消しと再実行を行う.この際,ロールバッ クにより再実行されることとなったイベントの挙動は,必ずし も再実行前のものから変化するとは限らない.ロールバックに よる再実行前と再実行後でイベントの挙動が一致する場合,そ のイベントに対応するアンチメッセージを送信する必要はなく なる. アンチメッセージ送信の必要性は,再実行の前後の他論理プ ロセスへの送信メッセージを比較することで判断できる.再実 行前の送信メッセージの集合をM,再実行後の送信メッセージ の集合をM′とする.この時,再実行後のメッセージmに対 するアンチメッセージ送信の是非は次のように判断される. (1) m∈ M かつm∈ M′ならば アンチメッセージもメッセージmも送信しない (2) m∈ M かつm /∈ M′ならば アンチメッセージを送信する mが存在する場合にはメッセージmを送信する (3) m /∈ M かつm∈ M′ならば メッセージmを送信する 再実行の前後でイベントの挙動が変わらず,送信メッセージの 内容が一致する場合には,イベント処理の取り消しは他の論理 プロセスへ伝搬されなくなる.再実行の前後でイベントの挙動 が変化し,再実行前のメッセージが送信されなくなった場合に は,再実行前のメッセージは取り消される.加えて,再実行後 に内容の異なるメッセージ送信を行う場合には,そのメッセー ジが送信される.再実行後の送信メッセージが存在しない場合 にはまた,再実行前には送信されなかったメッセージは通常通 りに送信を行う. これにより,不要なアンチメッセージの送信とそれによる不 要なロールバックの発生を抑制できる.よって,通常のTime Warpでは不要なロールバックが生じてしまう場合において, より少ない同期回数で正しいシミュレーション結果への収束が 可能となる.