根付きラベル付きキャタピラのパスヒストグラム距離
Path Histogram Distance for Rooted Labeled Caterpillars
川口 泰雅
1∗芳野 拓也
1平田 耕一
2Taiga Kawaguchi
1Takuya Yoshino
1Kouichi Hirata
21
九州工業大学大学院情報工学府
1
Graduate School of Computer Science and Systems Engineering,
Kyushu Institute of Technology
2
九州工業大学大学院情報工学研究院
2
Department of Artificial Intelligence, Kyushu Institute of Technology
Abstract: In this paper, we focus on a caterpillar as a rooted labeled unordered tree (a tree, for short) transformed to a path after removing all the leaves in it. Also we introduce a path
histogram distance between trees as an L1-distance between the histograms of paths from the root
to every leaf. Whereas the path histogram distance is not a metric for trees, we show that, for caterpillars, it is always a metric, simply linear-time computable and incomparable with the edit distance. Furthermore, we give experimental results for caterpillars in real data of comparing the path histogram distance with the isolated-subtree distance as the most general tractable variation of the edit distance.
1
はじめに
木構造データのデータマイニングや機械学習では, 2 つの木構造データの非類似度を計算する必要がある. 木 の非類似度として有名なものに木編集距離 [7] がある. 木編集距離は一方の木から他方の木への変換に要する 編集操作の最小回数で定義される. 木編集距離の計算 は MAX SNP 困難であることが知られている [11]. こ れは木構造が二分木でも同様である [3]. 木編集距離には, さまざまな変種が提案されており [5, 9], その多くがメトリック [5] かつ多項式時間計算可 能である [8, 9, 10]. 特に, 孤立部分木距離 [10] は, 多項 式時間計算可能な変種の中でも最も一般的である [9]. 木編集距離以外の木の非類似度に木の局所情報を基 にしたヒストグラム距離がある [1, 4, 6]. これらは, 木 編集距離の定数下限を与えることが多く, 木編集距離と 比較して高速に計算することができるが, 一般にメト リックとはならない. そこで本論文では, メトリックであることと計算効率 がよいことを両立した木の比較を目的として, パスヒス トグラム距離とキャタピラを導入する. パスヒストグラム距離とは, 木に出現する根から葉ま でのパスとその頻度の組によって構成されるパスヒス ∗連絡先:九州工業大学大学院情報工学府 〒 820-8502 福岡県飯塚市川津 680-4 E-mail: [email protected] トグラム間の L1距離で定義される距離である. キャタピラとはすべての葉を取り除いたときにパス になる木である [2]. 非常に制限された単純な構造であ るが, 4 節の表 1 に示すように, 実データの中に多く存 在する. したがって, キャタピラ間のメトリックな距離 の定式化は有用であるといえる. 本論文では, キャタピラ間のパスヒストグラム距離に ついて議論する. はじめに, キャタピラ間のパスヒスト グラム距離がメトリックになること示す. 次に, この距 離が線形時間で計算可能であり, 木編集距離およびそ の変種と比較不能な距離であることを示す. さらに, 実 データにおける孤立部分木距離とパスヒストグラム距 離の比較をすることで, その特徴について解析する.2
準備
本節では, キャタピラのパスヒストグラム距離の定式 化のための諸定義を導入する. 閉路を持たない連結無向グラフを木という. ノード の集合 V , 辺集合 E からなる木 T = (V, E) に対して, v∈ V を単に v ∈ T と表す. 木 T に含まれるノードの 数|V | を T のサイズといい, |T | で表す. ある特定のノード r を根として持つ木を根付き木と いい, そのノード r を根という. 根付き木 T の根を r(T ) と表す. 人工知能学会研究会資料 SIG-FPAI-B508-06T を r = r(T ) となる根付き木とし, u, v ∈ T とす る. r から v までのパスを, 以下のように定義される木 (V, E) とし, これを UPr(v) と表す. UPr(v) = (V, E), V ={v1, . . . , vk} , v1= r, vk = v, E ={(vi, vi+1)| 1 ≤ i ≤ k − 1} . UPr(v) 上のノードのうち v でないものを v の先祖と いう. v の先祖がノード u であることを v < u と表し, v = u または v < u であるとき, v≤ u と表す. また, v を先祖に持つノードを v の子孫という. 特に, v < u か つ v と u が隣接しているとき, u を v の親といい, par(v) で表し, v を u の子という. また, 子を持たないノード を葉といい, T に含まれるすべての葉の集合を lv(T ) と 表す. さらに, ノード v と u の共通の先祖のうち, v(あ るいは u) へのパスが最も短い先祖を最近共通先祖とい い, v⊔ u で表す. ノード v の子の数を次数といい, d(v) で表す. また, d(T ) = max{d(v) | v ∈ T } で定義され る d(T ) を T の次数という. 木に関する基本的な操作は, 木の各ノードを一つず つ調べることである. これを木の走査という. 走査の 手順として, 親を走査してから, 子を走査する先行順走 査と子をすべて走査してから, 親を走査する後行順走 査を考える. ノード v∈ T に対して, v の先行順走査に おける順番を pre(v), 後行順における順番を post(v) と 表す. このとき, u∈ T に対して, pre(v) < pre(u) かつ post(v) < post(u) のとき, v は u の左にあるといい, u は v の右にあるという. 各ノードの子に左右の順序を指定している根付き木 を根付き順序木といい, 指定していない根付き木を根付 き無順序木という. また, 各ノードがアルファベット Σ によってラベル付けされている木をラベル付き木とい い, ノード v のラベルを l(v) と表す. 本論文では, 根付 きラベル付き無順序木を単に木という. 次に, パスヒストグラム距離と比較するために, 木編 集距離を導入する. 定義 1 (編集操作 [7]). 以下の 3 つの操作を編集操作 という. 1. 置換:ノード v∈ T のラベルを置き換える. 2. 削除:T のノード v を削除し, v のすべての子を v の親 v′と連結する. 3. 挿入:ノード v にノード v′の子の一部分を連結 し, v を v′に連結する. ε /∈ Σ とし, Σε = Σ∪ {ε} とする. ここで, ラベル の組 (l1, l2)∈ (Σε× Σε)\ {ε, ε} に対して, 編集操作を (l1 → l2) と表す. ここで, l2 = ε のとき削除, l1 = ε のとき挿入, l1 ̸= ε, l2 ̸= ε のとき置換を表す. また, ノード v, w に対して, (l(v)→ l(w)) を (v → w) とも表 す. γ : (Σε× Σε)\ {ε, ε} → R+ を 2 つのラベル間の コスト関数とするとき, 編集操作 (l1→ l2) のコストを γ(l1→ l2) で表す. 特に断らない限り, コスト関数には 以下が成り立つ単一コスト関数 γ を用いる. γ(l1→ ε) = γ(ε → l2) = γ(l1→ l2) = 1. 定義 2 (木編集距離). 編集操作列 E = e1, e2, . . . , enの
コストを γ(E) = ∑ni=1γ(ei) とするとき, 木 T1と T2
の木編集距離 τTai(T1, T2) を以下のように定義する. τTai(T1, T2) = min { γ(E) E は T1から T2を得る ための編集操作の列 } . 定義 3 (マッピング). T1と T2を木とし, M⊆ T1×T2と する. このとき, 任意の (u1, v1)(u2, v2)∈ M が (1)u1= u2 ⇐⇒ v1= v2(一対一対応), (2)u1≤ u2 ⇐⇒ v1≤ v2(先祖子孫関係) を満たすとき, 3 つ組 (T1, T2, M ) を Tai マッピングという. 誤解のない限り, (T1, T2, M ) を 単に M と書く. また, Tai マッピングを単にマッピン グといい, M ∈ MTai(T1, T2) と書く. M を T1から T2へのマッピングとし, γ をコスト関 数とする. IM と JM をそれぞれ T1と T2のノードの うち, M には含まれないノードの集合, すなわち IM = {u ∈ T1| (u, v) /∈ M}, JM ={v ∈ T2| (u, v) /∈ M} と する. このとき, M のコスト γ(M ) を以下のように与 える. γ(M ) = ∑ (u,v)∈M γ(u, v) + ∑ (u,v)∈IM γ(u, ε) + ∑ (u,v)∈JM γ(u, ε). 定理 1 (Tai[7]). 以下が成り立つ.
τTai(T1, T2) = min{γ(M) | M ∈ MTai(T1, T2)}.
定理 2 ([3, 11]). T1, T2を木とする. τTai(T1, T2) を計 算する問題は MAX SNP 困難である. これは T1と T2 が二分木でも成り立つ. 最後に, Tai マッピングと木編集距離の変種の一つで ある, 孤立部分木マッピングと孤立部分木距離を導入 する. 定義 4 (孤立部分木マッピング). T1と T2を木とし, M ∈ MTai(T1, T2) とする. M が以下の条件を満たすと き, M を孤立部分木マッピングといい, M ∈ MIlst(T1, T2) で表す.
∀(u1, v1)(u2, v2)(u3, v3)∈ M
定義 5 (孤立部分木距離). 孤立部分木距離 τA(T1, T2)
を, 孤立部分木マッピングMIlst(T1, T2) の最小コスト
として, 以下のように定義する.
τIlst(T1, T2) = min{γ(M) | M ∈ MIlst(T1, T2)}.
定理 3 ([8]). τIlst(T1, T2) は O(n2d) 時間で計算できる. ここで, n = max (|T1|, |T2|), d = min {d(T1), d(T2)} で ある.
3
キャタピラのパスヒストグラム距
離
本節では, キャタピラとパスヒストグラム距離を導入 する. C を r = r(C) となる木とする. C からすべての葉 lv(C) を取り除くと UPr(v)(ただし v は C のあるノー ド) となるとき, C をキャタピラという. キャタピラ C について, 残るパス UPr(v) を C のバックボーンといい, bb(C) で表す. すなわち, V (C) = V (bb(C))∪ lv(C) が 成り立つ. 木 T がキャタピラであるかどうかは O(|T |) 時間で判定可能である. T を r = r(T ) となる木とする. T のノード v∈ T に ついて, 以下のようなパス UPr(v) = (V, E) を考える. V ={v1, . . . , vk} , v1= r, vk= v, E ={(vi, vi+1)| 1 ≤ i ≤ k − 1} . このとき, パス UPr(v) を Σ 上の文字列 l(v1) . . . l(vk) とみなし, これを s(r, v) で表す. また, 文字列 s ∈ Σ∗ について, s = s(r, v) となる葉 v∈ lv(T ) が存在すると き, s は T に出現するといい, s が T に出現する頻度を f (s, T ) と表す. さらに, T に出現するすべての文字列の 集合を S(T ) ={s(r, v) | r = r(T ), v ∈ lv(T )} と表す. 定義 6 (パスヒストグラム). 木 T のパスヒストグラム H(T ) を以下のように定義する. H(T ) ={⟨s, f(s, T )⟩ | s ∈ S(T )} . 定義 7 (パスヒストグラム距離). 木 T1と T2のパスヒ ストグラム距離 δPh(T1, T2) をパスヒストグラム H(T1) と H(T2) 間の L1距離として, 以下のように定義する. δPh(T1, T2) = ∑ s∈S(T1)∪S(T2) |f(s, T1)− f(s, T2)|. 例 1. 木同士の δPhはメトリックでない. T1 ̸≡ T2で あるが δPh(T1, T2) = 0 となる以下のような木 T1と T2 が存在し, メトリックの条件である非退化性の反例とな るからである. このとき, H(T1) = H(T2) ={⟨aba, 2⟩} である. a b a a a b a b a T1 T2 例 1 において, T1はキャタピラであるが, T2はキャ タピラでない. しかし, 両方がキャタピラであれば以下 の定理が成り立つ. 定理 4. キャタピラ間の δPhはメトリックである. 証明. この定理の証明のためには, キャタピラ C1と C2 について, δPh(C1, C2) = 0 ⇐⇒ C1≡ C2 であること を示せば十分である. これは, H(C) から C を一意に構 築できることを示せばよい. C を r = r(C) となるキャタピラとする. C のバッ クボーン bb(C) は r = v1, . . . , vk から構成されてい ると仮定する. s(C) = l(v1) . . . l(vk) とする. このと き, 任意の葉 v∈ lv(C) に対して, s(r, v) は v = vkで, l(v1) . . . l(vk−1) が s(C) の接頭辞となる l(v1) . . . l(vk) の形で表すことができる. また, キャタピラにはちょう ど 1 つのバックボーンしかない. このことより, 下記の 手続きによる H(C) から C の構築は一意である. 初めに, H(C) に含まれる最長文字列 l(v1) . . . l(vn) を選び, v1, . . . , vn−1 を C のバックボーン bb(C) とする. 次に, s = l(v1) . . . l(vk) とな る任意の⟨s, f(s, C)⟩ ∈ H(C) に対して, vk を vk−1 ∈ bb(C) の子として, f(s, C) 回追 加する. 定理 5. δPh(C1, C2) は O(|C1| + |C2|) 時間で計算で きる. 証明. C をキャタピラとし, bb(C) は v1, . . . , vnから構 成されているとする. 以下の手続きを i = 1 から n ま で繰り返す. viの子である葉 v について, l(v1) . . . l(vi)l(v) を s とし, viの子のうちラベルが l(v) であ る葉の数を f (s, C) とする. V (C) = V (bb(C))∪ lv(C) かつ V (bb(C)) ∩ lv(C) = ∅ であり, 上記の手続きは C のノードをちょうど 1 回走査 するだけである. よって, C から H(C) の構築は O(|C|) 時間で可能である. 定理 6. 以下の性質を満たすキャタピラ C1と C2が存 在する.1. τTai(C1, C2) = 1 だが δPh(C1, C2) = O(λ) であ る. ここで, λ = max{|lv(C1)|, |lv(C2)|} である. 2. δPh(C1, C2) = 2 だが τTai(C1, C2) = O(n) であ る. ここで, n = max{|C1|, |C2|} である. 証明. 根同士のラベルが異なる同型のキャタピラ C1と C2は, 性質 1 を満たす. 一方, 同じ長さのパス C1と C2について, C1のすべ てのノードのラベルが a で, C2のすべてのノードのラ ベルが b のとき, 性質 2 を満たす. 定理 6 より, δPhと τTaiは比較不能であることがい える.
4
実験
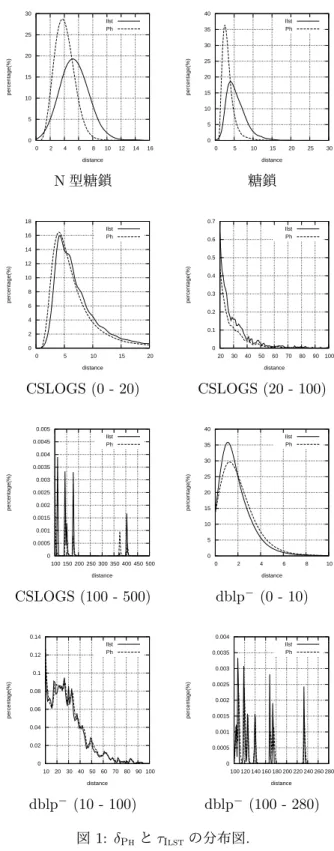
本節では, δPhを計算するアルゴリズムを実装し, キャ タピラに適用した結果を τIlstと比較する. τIlstのコス ト関数には単一コスト関数を使用する. データセット には KEGG1が提供する N 型糖鎖と糖鎖, CSLOGS2, dblp3を使用する. 表 1 に各データセットにおけるキャ タピラの数 (#cat) を示す. 表 1: データセットにおけるキャタピラの数. データセット #cat データ数 % N 型糖鎖 514 2,142 23.996 糖鎖 7,984 10,704 74.785 CSLOGS 41,592 59,691 69.679 dblp 5,154,295 5,154,530 99.995 計算に用いるキャタピラは, N 型糖鎖, 糖鎖, CSLOGS のすべてのキャタピラと, dblp からキャタピラを 50, 000 件を選んだもの (dblp−) である. これは, dblp のすべ てのキャタピラの数が, すべてのキャタピラの組合せ間 の距離を計算するには大きすぎるためである. 表 2 に キャタピラの情報を示す. 表 2 における ([a, b]; c) とい う表記について, a は最小値, b は最大値, c は平均値を 表す. 表 3 に表 2 の各データセットのすべてのキャタ ピラの組合せ間の距離計算の実行時間を示す. 実験環 境は, OS が Ubuntu Linux 14.04 (64bit), CPU が Intel Xeon E51650 v3 (3.50GHz), RAM が 1GB である.表 3 より, τIlstより δPhの方が実行時間が小さいこ とがわかる. これは, τIlstの計算時間が O(n2d) であり,
δPhの計算時間が O(n) であることに合致する.
1Kyoto Encyclopedia of Genes and Genomes, http://www.
kegg.jp/ 2 http://www.cs.rpi.edu/~zaki/www-new/pmwiki.php/ Software/Software 3http://dblp.uni-trier.de/ 図 1 はキャタピラの組合せ間における δPh(破線) と τIlst(実線) の分布図である. ここで, 横軸は距離, 縦 軸はその距離の値をとるキャタピラの組合せの割合を 表す. 0 5 10 15 20 25 30 0 2 4 6 8 10 12 14 16 percentage(%) distance Ilst Ph 0 5 10 15 20 25 30 35 40 0 5 10 15 20 25 30 percentage(%) distance Ilst Ph N 型糖鎖 糖鎖 0 2 4 6 8 10 12 14 16 18 0 5 10 15 20 percentage(%) distance Ilst Ph 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 20 30 40 50 60 70 80 90 100 percentage(%) distance Ilst Ph CSLOGS (0 - 20) CSLOGS (20 - 100) 0 0.0005 0.001 0.0015 0.002 0.0025 0.003 0.0035 0.004 0.0045 0.005 100 150 200 250 300 350 400 450 500 percentage(%) distance Ilst Ph 0 5 10 15 20 25 30 35 40 0 2 4 6 8 10 percentage(%) distance Ilst Ph CSLOGS (100 - 500) dblp− (0 - 10) 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 10 20 30 40 50 60 70 80 90 100 percentage(%) distance Ilst Ph 0 0.0005 0.001 0.0015 0.002 0.0025 0.003 0.0035 0.004 100 120 140 160 180 200 220 240 260 280 percentage(%) distance Ilst Ph dblp− (10 - 100) dblp− (100 - 280) 図 1: δPhと τIlstの分布図. 図 1 より, N 型糖鎖と糖鎖については, δPhと τIlstが 類似しておらず, どちらも正規分布に近い形をとるこ
表 2: 実験データ. データセット #cat ノードの数 次数 高さ 葉の数 ラベル数 N 型糖鎖 514 ([6,15];6.40) ([1,3];1.84) ([1,9];4.22) ([1,7];2.18) ([2,8];4.50) 糖鎖 7,984 ([1,24];4.74) ([0,5];1.49) ([0,15];3.02) ([1,14];1.72) ([1,9];2.84) CSLOGS 41,592 ([2,404];5.84) ([1,403];3.05) ([1,70];2.20) ([1,403];3.64) ([2,168];5.18) dblp− 50,000 ([7,244];11.96) ([6,243];10.94) ([1,3];1.02) ([6,243];10.94) ([7,13];9.86) 表 3: 実行時間. 単位はミリ秒. データセット δPh τIlst τIlst/δPh N 型糖鎖 300 6,035 20.12 糖鎖 53,170 718,807 13.53 CSLOGS 3,674,530 25,511,072 6.94 dblp− 11,496,570 144,162,902 12.54 とがわかる. 一方, CSLOGS と dblp−については, δPh と τIlstが類似しており, ほとんどのキャタピラの組合 せは小さい値をとるが, わずかに大きい値をとる組合せ もあることがわかる. 図 2 に横軸を τIlst, 縦軸を δPhとしたときの, すべて のキャタピラの組合せによる散布図と, τIlstと δPhの 相関係数 cc を示す. 図 2 より, N 型糖鎖と糖鎖については, 定理 6 で示し た通り, 実験的にも δPhと τIlstが比較不能であること がわかる. 一方, CSLOGS と dblp−については, δPhと τIlstが高い相関係数を示している. この原因として以 下のことが考えられる. 1. CSLOGS と dblp−について, 平均の高さが極端 に小さく, かつ, ノードの数に対して葉の数が極 端に少ないため, δPh ≪ τIlstとなる組合せが存 在しない. 2. dblp−について, キャタピラの根ノードがほとん ど同一であるため, δPh ≫ τIlstとなる組合せが 存在しない. 3. CSLOGS について, 根のラベルが異なるとき, 葉 のラベルのほとんどが異なるため, δPh≫ τIlstと なる組合せが存在しない. 図 3 は, δPh ≪ τIlstもしくは δPh≫ τIlstとなる N 型 糖鎖のキャタピラの組合せである. ここで, δPh(C1, C2) = 2 であるが τIlst(C1, C2) = 5, δPh(C3, C4) = 8 である が τIlst(C3, C4) = 1 である. 定理 6 に関連して次のことがわかる. δPh ≪ τIlstと なるキャタピラの組合わせは, ノードの数に対して葉の 数が少ない傾向にある. 一方, δPh ≫ τIlstとなるキャ タピラの組合わせは, ほとんど同型であるが根に近い部 分の構造が異なる傾向にある. 0 2 4 6 8 10 12 0 2 4 6 8 10 12 14 16 Ph Ilst 0 5 10 15 20 25 30 0 5 10 15 20 25 30 Ph Ilst N 型糖鎖 糖鎖 cc = 0.440433 cc = 0.702997 0 100 200 300 400 500 600 700 800 0 50 100 150 200 250 300 350 400 450 500 Ph Ilst 0 50 100 150 200 250 300 0 50 100 150 200 250 Ph Ilst CSLOGS dblp− cc = 0.934889 cc = 0.996572 図 2: δPhと τIlstの散布図.
I B C D D D E E E E I B C D B G H D C1=G05056 C2=G04815 I B C D D D B D I C D D D B D C3=G10334 C4=G10338 図 3: δPh ≪ τIlstもしくは δPh ≫ τIlstとなるキャタ ピラの組合せ.
5
まとめ
本研究では, キャタピラのパスヒストグラム距離を導 入し, 木編集距離と比較不能かつメトリックな距離で あり, 線形時間計算可能であることを示した. また, 実 データに対して, 孤立部分木距離との比較をすることに より, その特徴を解析した. 今後の課題としては, キャタピラの構造的特徴を生か して, 高速に計算可能なキャタピラの木編集距離計算ア ルゴリズムを設計し, パスヒストグラム距離と比較す ることが挙げられる. さらに, 本研究の発想を基に, 一 般的な木構造における木編集距離と比較不能かつメト リックな距離の定式化も, 今後の重要な課題である.参考文献
[1] T. Aratsu, K. Hirata, T. Kuboyama: Sibling dis-tance for rooted labeled trees, JSAI PAKDD’08
Post-Workshop Proc., LNAI 5433, 99–110 (2009). [2] J. A. Gallian: A dynamic survey of graph labeling ,
Electorn. J. Combin. 14, DS6 (2007).
[3] K. Hirata, Y. Yamamoto, T. Kuboyama: Improved
MAX SNP-hard results for finding an edit distance between unordered trees, Proc. CPM’11, LNCS 6661,
402–415 (2011).
[4] K. Kailing, H.-P. Kriegel, S. Sch¨onaur, T. Seidl,
Ef-ficient similarity search for hierarchical data in large databases, Proc. EDBT’04, 676–693 (2004).
[5] T. Kuboyama: Matching and learning in trees, Ph.D thesis, University of Tokyo (2007).
[6] F. Li, H. Wang, J. Li, H. Gao: A survey on tree edit distance lower bound estimation techniques for similarity join on XML data, SIGMOD Record 43,
29–39 (2013).
[7] K.-C. Tai: The tree-to-tree correction problem,
J. ACM 26, 422–433 (1979).
[8] Y. Yamamoto, K. Hirata, T. Kuboyama: Tractable
and intractable variations of unordered tree edit dis-tance, Internat. J. Found. Comput. Sci. 25, 307–330
(2014).
[9] T. Yoshino, K. Hirata: Tai mapping hierarchy for rooted labeled trees through common subforest ,
The-ory of Comput. Sys. 60, 759–783 (2017).
[10] K. Zhang: A constrained edit distance between unordered labeled trees, Algorithmica 15, 205-222 (1996).
[11] K. Zhang, T. Jiang: Some MAX SNP-hard results concerning unordered labeled trees, Inform. Process.
![表 2: 実験データ. データセット #cat ノードの数 次数 高さ 葉の数 ラベル数 N 型糖鎖 514 ([6,15];6.40) ([1,3];1.84) ([1,9];4.22) ([1,7];2.18) ([2,8];4.50) 糖鎖 7,984 ([1,24];4.74) ([0,5];1.49) ([0,15];3.02) ([1,14];1.72) ([1,9];2.84) CSLOGS 41,592 ([2,404];5.84) ([1,403];3.05) ([1,70];2.20)](https://thumb-ap.123doks.com/thumbv2/123deta/8209223.1279222/5.892.95.797.156.272/表2実験データデータセットcatノードの次数高さラベル型糖糖鎖CSLOGS.webp)
