A Study on Interaction
between Human and Digital Content
December 2015
Tatsunori HIRAI
A Study on Interaction
between Human and Digital Content
December 2015
Waseda University
Graduate School of Advanced Science and Engineering Department of Pure and Applied Physics
Research on Image Processing
Tatsunori HIRAI
Contents i
List of Figures v
List of Tables vii
1 Introduction 1
1.1 Background . . . 2
1.2 Research Goal . . . 3
1.3 Human–Content Interaction . . . 4
1.3.1 Definition of Human–Content Interaction . . . 5
1.3.2 Scope of Human–Content Interaction . . . 6
1.3.3 Mission of Human–Content Interaction . . . 6
1.3.4 Human–Content Interaction Research Topics . . . 7
1.4 Human–Content Interaction in this Thesis . . . 8
1.4.1 Our Human–Content Interaction Approach . . . 9
1.4.2 Future Vision of our Research . . . 10
1.5 Thesis Organization . . . 10
2 Music Video Generation based on Audio-Visual Synchronization 13 2.1 Background . . . 13
2.2 Synchronization of Music and Video . . . 14
2.3 Music Video Generation . . . 17
2.3.1 Database Construction Phase . . . 17
2.3.2 Music Video Generation . . . 18
2.4 Evaluation . . . 20
2.5 Conclusion . . . 21
3 Music Video Generation via Mashup of Singing Video Clips 23 3.1 Background . . . 23
3.2 Related Work . . . 25
3.3 System Implementation . . . 26
3.4 Singing Scene Detection . . . 28
3.4.1 Vocal Activity Detection (VAD) . . . 28
3.4.2 Mouth Aperture Detection (MAD) . . . 28
3.4.3 Combination of VAD and MAD . . . 29
3.5 Singing Video Generation . . . 30
3.5.1 Database Construction . . . 31
3.5.2 Video Fragment Retrieval . . . 32
3.5.3 Non-singing Scene Generation . . . 33
3.5.4 Mixing Singing and Non-Singing Scenes . . . 34
3.6 Evaluation . . . 34
3.7 Conclusion . . . 35
4 Music Generation based on a Mixture of Existent Songs 39 4.1 Background . . . 39
4.2 Related Work . . . 41
4.3 Proposed System . . . 42
4.4 Fusion Method . . . 43
4.4.1 Scope of Consideration in MusicMean . . . 43
4.4.2 Musical Note Averaging Operation . . . 44
4.4.3 Melody Averaging Operation . . . 45
4.4.4 Generating Musical Sound . . . 45
4.4.5 Drum Averaging Operation . . . 46
4.4.6 “In-betweening” of More than Two Songs . . . 48
4.4.7 Extrapolation Song . . . 48
4.5 Results and Conclusion . . . 48
5 Mixing Video Content and Real World 51 5.1 Introduction . . . 51
5.2 Applications of VRMixer . . . 53
5.3 Related Work . . . 54
5.4 System Implementation . . . 55
5.5 Construction of 2.5D Space . . . 56
5.5.1 Video Segmentation . . . 56
5.5.2 2.5D Space Construction . . . 60
5.6 Mixing a Video Clip and the Real World . . . 61
5.6.1 Summon a 2D Person to a 3D Space . . . 62
5.6.2 Application to Dance Practice . . . 63
5.7 Early Reactions . . . 63
5.7.1 Limitations and Future Work . . . 64
5.8 Conclusion . . . 65
6.1 Introduction . . . 67
6.2 Related Work . . . 68
6.3 Frame-Wise Video Summarization . . . 71
6.3.1 Frame-wise Thinning out based on a Visual Transition . 71 6.3.2 Frame-wise Thinning out based on an Audio Transition . 73 6.3.3 Frame-wise Thinning out based on an Audio-Visual Transition . . . 74
6.4 Video Stretching via Frame Insertion . . . 75
6.5 Subjective Experiment . . . 76
6.6 Applications of the Proposed Method . . . 77
6.7 Conclusion . . . 78
7 Automatic DJ System Considering Beat and Latent Topic Similarity 81 7.1 Introduction . . . 81
7.2 Related Work . . . 83
7.2.1 Music Mixing and Playlist Generation . . . 83
7.2.2 Topic Modeling . . . 84
7.3 System Overview . . . 85
7.4 Beat Similarity . . . 86
7.5 Latent Topic Similarity . . . 86
7.5.1 Topic Modeling . . . 87
7.5.2 Calculation of Latent Topic Similarity . . . 90
7.5.3 Evaluation . . . 90
7.6 Mixing Songs . . . 92
7.7 Implementation of MusicMixer . . . 92
7.7.1 System Design . . . 92
7.7.2 Interface . . . 93
7.7.3 Personalization to the Mixing Preference . . . 95
7.7.4 Early Reactions . . . 95
7.8 Discussion . . . 96
7.8.1 Limitations . . . 96
7.8.2 Applications of MusicMixer . . . 96
7.8.3 Conclusion . . . 97
8 Continuity-based Face Recognition 99 8.1 Introduction . . . 99
8.2 Related Work . . . 100
8.3 Construction of Facial-Temporal Continuum . . . 102
8.3.1 Shot Detection . . . 103
8.3.2 Face Detection . . . 105
8.3.3 Tracking of Face Area . . . 106
8.3.4 Clustering of Facial-temporal Continua based on Facial
Similarity . . . 106
8.3.5 Face Identification . . . 108
8.4 Experiment . . . 109
8.5 Conclusion . . . 110
9 FaceXplorer: A Video Browsing Interface based on Face Recognition113 9.1 Introduction . . . 114
9.2 Related Work . . . 115
9.3 Interface Overview . . . 117
9.4 Video Analysis . . . 118
9.4.1 Overview of the Face Recognition . . . 119
9.4.2 Extraction of Facial Parameters . . . 119
9.5 Interfaces . . . 120
9.5.1 Video Retrieval Interface . . . 121
9.5.2 Video Playing Interface . . . 122
9.6 Conclusion . . . 123
10 Conclusion 127 10.1 Summary . . . 127
10.2 Human–Content Interaction Revisited . . . 128
10.2.1 Position of our Research within a Human–Content In- teraction . . . 128
10.2.2 Orientation of our Research . . . 128
10.3 Future Work . . . 130
10.4 Outro. . . 130
References 132
List of Publications 145
Publications related to each Chapter 153
Acknowledgment 157
2.1 Audio-visual synchronization. . . 15
2.2 System flow. . . 17
2.3 Conceptual image of the system. . . 18
2.4 Music video generation. . . 19
3.1 Conceptual image of the system. . . 24
3.2 Overview of the system. . . 27
3.3 Transition of the mouth aperture degree in an experimental environment and a real video clip. Manually labeled singing scenes are shown in red. . . 29
3.4 Combination of detected results. . . 30
3.5 Video generation results. . . 33
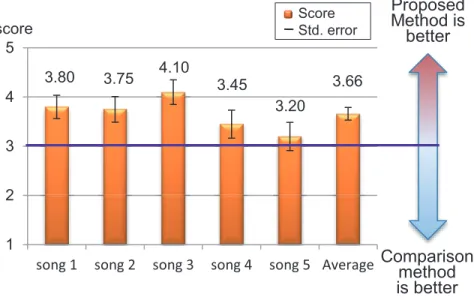
3.6 Subjective evaluation results comparing proposed method and Hiraiet al. 2012. . . 35
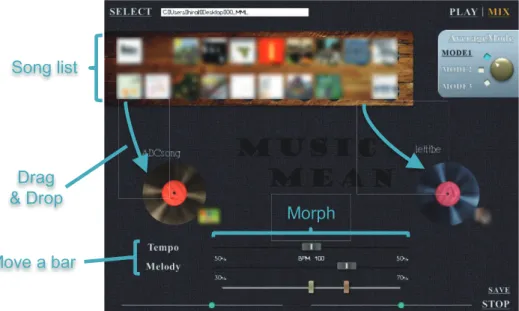
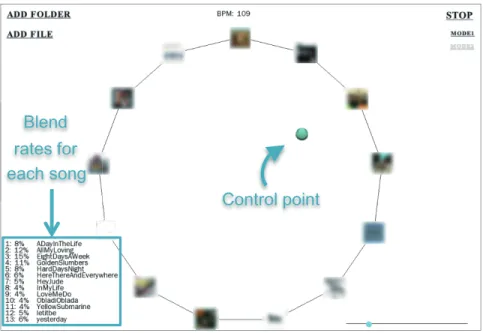
4.1 MusicMean screen capture. . . 43
4.2 Generating an average song with more than two songs (Creat- ing an average song of a specific artist). . . 44
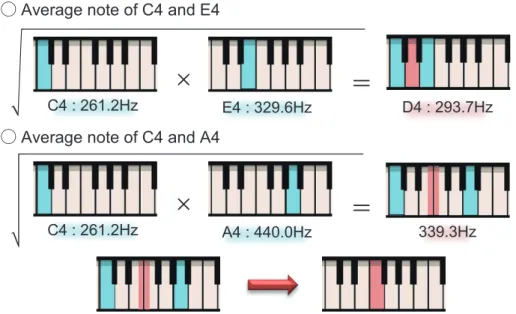
4.3 Musical note averaging operation. . . 45
4.4 Melody averaging operation. . . 46
4.5 Drum pattern averaging operation. . . 47
5.1 Image generated by VRMixer. . . 52
5.2 System overview of VRMixer. . . 56
5.3 Comparison of human extraction methods: (a) original video frame, (b) frame-by-frame graph cut segmentation, (c) inter- active human area segmentation with GrabCut [Rother et al. 2004], (d) adaptive binarization, (e) proposed automatic hu- man area segmentation. . . 58
5.4 F score for each method (30 frames). . . 59
5.5 Simply layering a video frame in 3D space. . . 60 5.6 Top view of mixed real world and video content using VRMixer. 61
5.7 The user in constructed 2.5D space, standing between the per-
son and the background. . . 62
5.8 A person in a video clip entering the 3D world. . . 63
6.1 Transition of SSD value in a video clip. . . 72
6.2 Transition of spectral flux value. . . 74
6.3 Transition of audio-visual thinning out cost. . . 75
7.1 Conceptual image of mixing songs with similar latent topics and beats using MusicMixer. . . 83
7.2 System flow. . . 85
7.3 Extracting peak distance features from the envelope of low fre- quency audio signal. . . 87
7.4 Extraction of ChromaWords from chroma vector. . . 88
7.5 Results of latent topic analysis applied to a 7-s fragment of the song “Let it Be”. . . 90
7.6 Result of subjective evaluation experiment. . . 91
7.7 The system design of MusicMixer. . . 93
7.8 MusicMixer user interface. . . 94
8.1 The image of facial-temporal continuum. . . 101
8.2 Outline of the method. . . 103
8.3 An example of transition of shot feature in a video stream. . . . 104
8.4 Example of face detection and detected facial feature points (green plots). . . 105
8.5 Normalization of face direction by reconstructing 3D face form. 107 8.6 HOG feature around the facial feature points and reactions to facial expression by changing cell size. . . 107
9.1 FaceXplorer. . . 115
9.2 System overview. . . 117
9.3 Examples of extracting facial parameters (0-100). . . 119
9.4 Face retrieval interface. . . 120
9.5 Video retrieval interface with visualization of face. . . 121
9.6 Face playing interface. . . 122
9.7 Viewing the face appearing at a certain point on the timeline. . 123
10.1 Orientation of our research within the human–content interac- tion. . . 129
2.1 Evaluation items. . . 16
2.2 Experimental results (score). . . 16
2.3 Result of subjective evaluation (score). . . 21
3.1 The accuracy of singing scene detection. . . 30
5.1 Accuracy comparison of segmentation methods. . . 59
6.1 The result of subjective evaluation experiment. . . 77
7.1 Examples of top-5 ChromaWords allocated to each topics. . . 89
8.1 Performance of face detection. . . 109
8.2 Performance of face detection after face tracking. . . 110
8.3 Comparison of face identification rate (IDR). . . 110
Chapter 1 Introduction
People have been enjoying media content, such as music and video content, since the invention of the gramophone and cinematography. Currently, we are living in a digital age and most media content is digitalized. The development of platforms such as the Internet and social networking services has made it possible for people all over the world to enjoy digital content, and the development of devices such as recording devices and portable players has made it easier for people to enjoy digital content.
In this age of digital content, people do not have to go to a store to buy music, video content, or books. We can download them from a web store with only one or two clicks. Such downloaded content can be enjoyed on many devices and is easy to share with family or friends. Transmitting personal content has also become easier. We can send photos taken with a smartphone to our friends with just one click, and we can share them with people all over the world through the Internet just as easily. Information technology hardware and software are advancing rapidly, and many platforms to support digital content have been recently developed. The situation surrounding digital content is rapidly changing, and such rapid growth is expected to continue. As the situation changes, new requirements for interacting with content emerge.
Through study cases, this thesis presents a comprehensive investigation of how humans interact with digital content, which we define as “Human–
Content Interaction.” We explore possible ways that people can interact with digital content in the current digital age and in future.
Specifically, our exploration focuses on how to
1.1. BACKGROUND
• support people’s creativity,
• support people’s appreciation of digital content,
• explore new interactions between humans and digital content beyond creation and appreciation.
Focusing on these aspects, we introduce study cases and depict “human–
content interaction.”
This thesis defines and stipulates human–content interaction research as it relates to people and digital content. This thesis also clarifies the research area by introducing our specific study cases.
1.1 Background
The development of information technologies has facilitated digital con- tent. Information technologies have changed people’s lifestyles and have influenced the technology associated with digital content. Thanks to the development of information technologies, people can live their lives more ef- ficiently, which has resulted in more spare time to enjoy media content. Such technologies have also made it possible to efficiently enjoy the content. We can enjoy music and video content through the Web, and we can create our own content and send it to people all over the world. In addition, we can interact with other people through content or interact with the content directly.
Nowadays, many people upload original video content to YouTube, which allows them to demonstrate their creation to people they do not know. This environment has made it possible for amateur creators to create their own content. Anyone can be a creator and anyone can watch the uploaded con- tent. However, things are still complicated for people who lack experience creating content. This is because creating content is not only a matter of tools, it also involves supporting creativity. It might be possible to overcome such a difficulty with the information technology that has made the current envi- ronment possible. A future in which everyone, from children to the elderly, can create their own digital content may be possible. How can information technology help people create content and make this dream come true?
Almost all information is available on the Internet. If you want to know something, the Internet is the best place to search in many cases. Leaving accessibility aside, the World Wide Web is the largest repository of human knowledge ever constructed. However, information on the Internet is messy.
The Internet is a library without rules for organizing books. Therefore, search engines, such as Google, Bing, and Yahoo, are required to find information on the Internet effectively. Whether we can find the information that we
need depends on the effectiveness of such search engines. Search engines are improving as information technology improves. However, methods for searching digital content remain insufficient for us to find the content that we want. For example, when we want to search for a video of The Beatles, we enter “The Beatles” in the YouTube search bar and click “search.” The search returns 1,780,000 video clips. How can we determine the video content that we really want to watch? What key word could we include in the search string to narrow the candidates? Is the content that we want to watch included in the 1,780,000 clips? Nobody knows the answer to these questions. We need a new technology to find the answers to these questions.
We are addicted to media content, and many people cannot enjoy their life without such content. Many people use smartphones during their commute, our daily conversations are frequently about media content, and many people access the Internet and appreciate web content throughout the day. Although the technology to receive and send content has changed considerably, the way we enjoy such content has not changed significantly. Only the format has changed from analog to digital. Since the invention of the gramophone, the only thing we can do with music content is to listen to it. Similarly, from the invention of cinematography, the only interaction we can have with motion pictures or video content is to watch it. Of course, there are many other interactions, such as sharing content or editing such content, but the main interaction with the content remains unchanged. The development of new formats, such as MP3 or MP4, and new devices, such as digital audio players or high-resolution display devices, has not changed the style of interaction.
Considering the drastic changes that we have experienced in our daily lives due to the Internet and other advances in information technology, it might be possible to enjoy digital content in different ways.
These issues are the key problems that we discuss in this thesis.
1.2 Research Goal
The goal of our research is to clarify human–content interaction research by addressing the previously mentioned issues with regard to digital content and to find a solution or an approach to address these issues. These issues can be expressed using other words, for example, supporting people’s creativity, supporting people’s appreciation of content, and exploring new interactions between people and digital content. Although these issues differ, they are all related to content. Therefore, we define these three issues as the basic topics that should be discussed in the human–content interaction research.
Although human–“computer” interaction is a major research area and interaction related to digital content is often included in such research, dig-
1.3. HUMAN–CONTENT INTERACTION ital content has not been the primary target. The technologies presented in this thesis are closely related to content, and therefore, we refer to them as
“human–content interaction,” differentiated from human–“computer” inter- action.
Human–content interaction research has not been defined clearly; there- fore, one of the goals of this thesis is to define this area of research. This research area needs to be defined because research that deals with content in- cludes various fields (e.g., multimedia, human–computer interaction, signal processing, the World Wide Web, databases, information retrieval, machine learning, etc.). Therefore, it is difficult to follow the research stream, and the research related to content can be overlooked. Generally, research that focuses on content includes multiple research perspectives, for example, sig- nal processing and human–computer interaction perspectives can be involved simultaneously in content research. In this case, content is just a subject and is just one property of the overall research. This can be an advantage for content-related research but it is not always an advantage. Sometimes the same topic is discussed differently in different research communities. This makes it difficult to determine which approach should be followed in future research. On the other hand, this indicates that research related to content has a wide range of fields, which widens the possibility of future research. There- fore, it is important to consider the whole research area from the perspective of content. In this thesis, we will consider such widely spread research topics.
However, to identify such research topics, we must first define human–content interaction research.
1.3 Human–Content Interaction
Human–“computer” interaction is a well-established research area. Since it focuses on the interactions between humans and computers, the mission of human–content interaction should be similar. To clarify the difference between human–computer interaction and human–content interaction, we review the definition of human–computer interaction. In a technical re- port [33], the Association of Computer Machinery, Special Interest Group on Computer–Human Interaction (SIGCHI), which is the most representative human–computer interaction research community, defines human–computer interaction as... a discipline concerned with the design, evaluation and implemen- tation of interactive computing systems for human use and with the study of major phenomena surrounding them.
This report carefully defines the research area by introducing a classification of topics and specific study cases. Although human–content interaction cannot
be defined by simply changing “computer” to “content,” we refer to this report to facilitate a definition of human–content interaction.
1.3.1 Definition of Human–Content Interaction
Before defining human–content interaction, we must define “digital con- tent.” The word “content” has various meanings. In the context of human–
content interaction research, we define “content” as “information that can be duplicated.” This definition does not always match the definitions given by other researchers; however, it overlaps with these other definitions in most cases. In our definition, typical content is music, video content, images, and text. Of course, our definition can include many other different types of con- tent. However, our main target is limited to such media content. Although a musical performance can be seen as content in a broad sense, it is not content in our definition unless it is recorded as digital music or a music video. Simi- larly, a photograph is content but is not digital content if it is not captured in a digital format. In this thesis, we simply refer to all digital content as “content,”
and music, video content, images, and text are assumed to be digital, except where noted otherwise. Taken together, the definition of digital content in this thesis is “information that can be digitally duplicated.”
We define human–content interaction based on the definitions of “human–
computer interaction” and “digital content.” In the definition of human–
computer interaction, the computer is not the core concern; the phenomena surrounding the human and the computer is the core concern. In contrast, content plays a larger role in human–content interaction, and the core factors are humans and the content. The factors involved in interaction between a human and content are simple when we watch content as a static concept that does not change during the interaction. Human to content (creation) and content to human (appreciation) are the two basic interactions. In addition to these factors, we also consider new interactions. From this third factor, we comprehend content as dynamic, i.e., content can be changed through interaction. Taken together, we define human–content interaction as
a discipline that considers how people create, appreciate, and interact with content.
As noted in a SIGCHI community technical report [33], this definition should change over time. Since the technology related to digital content changes frequently, it is natural to modify the definition and its scope. Cur- rently, the technology used to listen to music is very different from the technol- ogy used 20 years ago. For example, subscription music services are becoming increasingly common. Such services might drastically change the way people appreciate music. Our definition of human–content interaction is an initial
1.3. HUMAN–CONTENT INTERACTION basic definition, and it is likely to be updated as the situation changes.
1.3.2 Scope of Human–Content Interaction
Variations of human–content interaction originate from the target. If the types of content differ, the interaction also differs. In addition, if the peo- ple who interact with the content are different (e.g., inexperienced people, amateurs, professionals, and people with disability), the requirements for in- teraction also differ. Basically, content is related to visual and auditory senses, i.e., music and video or images, respectively. Although text changes form depending on how it is used, it can be viewed as visual content and heard as audio content. It might be possible to consider content related to other senses, e.g., haptic sense, smell, and taste. However, to simplify the definition, we focus on visual and audio content for the current scope.
We consider various types of people depending on the research topic.
Interaction methods for people with disability and professional people are completely different. If the research is customized for Japanese content, the target must be Japanese speakers. We do not define the scope of the target human here. As long as the target of the research is human, we refer to the research area as human–content interaction.
1.3.3 Mission of Human–Content Interaction
As the scope of human–content interaction has many variations, the mis- sion for each research topic in human–content interaction research also differs.
However, the foundation of the research must involve common aspects. Thus, the mission must be something that all human–content interaction topics should be part of in any form.
Before we establish the mission, we introduce an example, i.e., the rela- tionship between humans and cooking, to explain the future of interaction between humans and digital content. Although there are professional cooks, everyone can cook their own daily meals. In a restaurant, although food is made for the customers, they can change the taste to suite their preferences by adding seasoning (or sometimes by mixing meals). Everyone can cook as they like, regardless of their skills, and everyone can eat what they want.
Dishes at famous restaurants are usually delicious. On the other hand, dishes made by a family member for a person’s special day satisfy the heart as well as the stomach. The quality does not always matter. If someone is in rush and does not have enough time to cook or go to the restaurant, they can eat a quick microwavable meal. The important factor is that we can choose from variety of choices.
We believe that the same considerations as to cooking are applicable to content as well. However, currently, this is not the case. Only professionals and some amateur creators produce content. The content that people appre- ciate is primarily produced by such creators. Moreover, we appreciate such content as is. Since individual tastes differ, it is more natural to enhance the appreciation of content by modifying existing content to suit our preferences.
Taking the example of cooking into consideration, here, we define the mission of human–content interaction. Note that this definition may not be applicable in all circumstances. However, we believe that research goals can be oriented in the same direction as long as we focus on the interaction between humans and content. We define the mission of human–content interaction research asmaking things efficient, convenient, easier, more enjoyable, or more freely related to the interaction between humans and content.
In summary, the mission is “to improve the relationship between humans and content.(( This mission might be vague, but it is applicable to many aspects of content research. The factors listed do not always correspond to improve- ment because content has many aspects that are difficult to observe from a single perspective. For example, a technology that makes listening to music more convenient may destroy the value of the music from the perspective of the creator of the music. Since content often include artistic perspective, we have to be careful not to intentionally destroy such value.
It might not be appropriate to set a universal goal for the research area an artistic perspective. Therefore, we do not define the mission precisely and leave room for interpretation.
In particular, the mission of our study is to make interactions between humans and content easier and more freely.
1.3.4 Human–Content Interaction Research Topics
Research topics related to human–content interaction are listed below.
Although these are representative research topics, human–content interaction research is not limited to these topics. Note that the word content in this list refers to any form of content, some types of content might not be applicable to a specific topic.
• Creation
– Computer-aided creation – Content generation – Content manipulation – Human factors in creation
1.4. HUMAN–CONTENT INTERACTION IN THIS THESIS – Applications for content creation
• Appreciation
– Content retrieval – Content thumbnailing – Content summarization – Content recommendation – Human factors in appreciation – Visualization for content browsing – Applications for content appreciation
• New interactions
– Human and content interaction – Fusion of creation and appreciation – New experience related to content
– Human communication related to content – Human factors in interaction
– Content platform
Creation and appreciation topics tend to be presented by the multime- dia research community, and new interaction research topics are primarily presented by the human–computer interaction and entertainment computing communities. Note that if the target content is focused on a specific media type, the research community is completely different. Thus, it is important to clarify the research area.
The list of research topics represents general topics for digital content.
Each topic has many sub-topics. Note that the list is not inclusive and might be updated as the situation changes.
1.4 Human–Content Interaction in this Thesis
As defined in Section 1.3.1, human–content interaction is a discipline re- lated to how people create, appreciate, and interact with content. In this thesis, we will cover these three issues; however, the scope is limited. The ob- jective of the research presented in this thesis is to introduce these definitions by introducing specific cases.
In the following, we provide additional information to help readers under- stand the relationship between our specific study cases and human–content interaction. Specifically, we clarify our research target and compare it to the target of human–content interaction research.
1.4.1 Our Human–Content Interaction Approach
As described in Section 1.3.2, there are many variations of humans and content. Everyone and every type of content can be the target. However, it is not realistic to handle all targets simultaneously.
There are two representative approaches for human support in human–
content interaction, i.e., helping end users or inexperienced people create or appreciate content, and helping amateur or professional creators enhance their abilities. Since the technologies and environments in which humans interact with content are developing and making it possible for everyone to enjoy content more than before, our primary interest is examining how to support end users or inexperienced people. Our objective is to break through the barrier in interaction between humans and content and facilitate an environment in which anyone can enjoy content. Supporting experienced people is an important approach. However, it is not considered in the study cases presented in this thesis. Although it is important to consider other targets such as people with disabilities, this consideration is also beyond the scope of our current research.
The types of content continue to grow. All types of content can be targets of human–content interaction. However, as mentioned previously, it is not realistic to handle all of them simultaneously. As initial target content, we focus on music and video content. In particular, we present technology related to music video content, which is representative content because it includes both audio and visual elements. In this thesis, we focus on music video content, music and video content respectively.
There are many variations within the target content. For example, there are many video genres. Music video content are one such genre. Similarly, there are many variations in music. Our studies are not restricted to a specific genre. However, there are some strong and weak points depending on the genres because technologies always have limitations.
One of the most important things that must be considered before handling content as a study object is to keep in mind that content has many aspects.
When we treat content as an entertainment tool, we can simply focus on how to enhance the entertainment aspect. For example, how to interact with content conveniently and how to create and appreciate content efficiently might be research subjects. The artistic aspect of content is most difficult. If we treat content as art, it does not make sense to generate content automatically or
1.5. THESIS ORGANIZATION provide an efficient tool to support creativity. As described previously, our interest is in how to help end users or inexperienced people enjoy interacting with content. Therefore, we try to avoid artistic considerations in this thesis.
Many technologies have multiple aspects and can be used in ways other than intended. We do not intend to consider the artistic aspect of content. Our study cases focus on the entertainment aspect of content, and we attempt to enhance this aspect using technology that enhances the interactions between humans and content. In future, we intend to expand the research target and explore each technology in greater depth. We believe that further research could lead to a more comprehensive understanding of human–content inter- action research.
1.4.2 Future Vision of our Research
In future, we intend to explore other aspects of human–content interaction and will inevitably need to deal with the artistic aspect of content. In fact, many research cases support the creation of content by professional artists.
Investigating content creation technologies is one way to handle the artistic aspect. Another approach is to investigate computer-generated art, which could be considered in relation to the technological singularity.
Regardless of whether we consider non-human produced content as art, technology to produce computer-generated art exists. Thus, in future, human–
content interaction research will have a very important role. Although our work is limited in many aspects, we believe that our research is linked to such a future work.
1.5 Thesis Organization
To clarify the overview of our human–content interaction research, we introduce specific study cases. Specifically, two chapters present studies on supporting people who create content, four chapters present studies of in- teraction between humans and digital content from an extensive perspective, and two chapters present studies of supporting appreciation of content.
As an introduction to specific study cases, we begin with the support of creativity by focusing on the automatic creation of music video content in Chapters 2 and 3. These chapters present a specific study that examines helping people create content. We specially focus on music video creation.
Music video content is multimedia content related to both music and video;
therefore, the creation of this type of content relates to the creation of a variety of content. Music video content is the first target of research that supports content creation. We address two types of music video generation
methods and the related systems. We describe music video generation based on an audio-visual synchronization method in Chapter 2 and a music-driven singing video generation method in Chapter 3. The systems are automatic content generation systems, but our approach is designed to support user creativity by allowing users to create content for the first time easily.
Chapters 4 to 7 describe an interdisciplinary interaction technique that cannot be classified as solely creation or appreciation. These chapters de- scribe study cases related to what we called “new interaction” in Section 1.3.4.
Chapter 4 describes a method to create music content by fusing existing music, which corresponds to the mixture of appreciation and creation. In Chapter 4, we introduceMusicMean, a system that supports people creating music and provides a new music appreciation experience. Chapter 5 describes a new way to enjoy video content by mixing real-world content and video content, which is one possible way to produce new interactions with digital content.
We presentVRMixer, a system that allows a user enter a video clip or remove people from the clip to realize a virtual co-starring role with people appear- ing in the clip. Chapter 6 and Chapter 7 discuss appreciation and creation.
This mixed topic shows a new aspect to consider how we can interact with digital content. Chapter 6 describes a method to change the length of a video clip while preserving the content. In Chapter 7, we present MusicMixer, a computer-aided DJ system that helps DJ performance in terms of song mixing to realize collaborative performance between the user and the system.
We introduce a study case to support content appreciation in Chapters 8 and 9. When the amount of content increases significantly, we must have a method to deal with such content. Specifically, we support a video browsing experience that includes video retrieval. Our approach employs facial recog- nition and supports video browsing from the perspective of people appearing in the content. Although the approach focuses on video retrieval, particularly related to people appearing in the video, the main framework can also be applied to many other visual objects in video clips. We have explored the possibility of appreciation in human–content interaction by focusing on the video browsing experience.
Finally, we conclude this thesis in Chapter 10 and clarify the human–
content interaction research field. In Chapter 10, we also clarify the orientation of our study cases within the human–content interaction research context and discuss future work.
These specific study cases are the starting point for future human–content interaction research. They are topics that we tackled almost accidentally. The necessity to choose each topic is described in each chapter. However, the ultimate goal of each research topic is what we have described in this chapter.
In summary, this thesis represents a starting point in our human–content interaction research.
Chapter 2
Music Video Generation based on Audio-Visual Synchronization
Here, we present an automatic mashup music video generation system that segments and concatenates existing video clips. To create a music video that is synchronized automatically with input music, we have performed an experiment to subjectively evaluate the optimal synchronization conditions between accents in a video and the music. The method synchronizes the accents of a video, such as movement and flicker, with the root mean square (RMS) energy of the input audio. The system calculates the RMS energy of the input music for each musical bar and searches for a video sequence that provides the best synchronization from a database of music video clips. The generated music video clips are based on the results of the subjective evalua- tion, wherein which we found that changes in brightness and the movement of an object are effective synchronization criteria. We also performed a subjective evaluation to evaluate the music video clips output by the system.
2.1 Background
Recently, video sharing web services have been increasing in popularity, especially for music video content. As a result, music video creation by in- experienced people is increasing rapidly. The content generated by a user is referred to as consumer-generated media (CGM) or user-generated content (UGC). The growth of CGM shows us the possibility of a future in which ev- eryone can become a creator. However, it is difficult for inexperienced people
2.2. SYNCHRONIZATION OF MUSIC AND VIDEO to create music video because editing music video content requires significant skill and expensive software. Regardless of the development of easy-to-use software and the spread of free tools, not everyone is creating their own content. Our opinion is that there is still a barrier between inexperienced people and content creation. Creating video content has become easier, but it still requires inconvenient effort, such as cutting and pasting video material.
Therefore, we propose a system to perform such tasks so that the user can concentrate on creative tasks, such as selecting materials and considering the overall theme of the final video clip. We focus especially on music video generation. With our system, the user only needs to select a song and choose music video clips to create a new music video. To create a music video that is automatically synchronized with the input music, we performed an ex- periment that subjectively evaluated the optimal synchronization conditions between motion in video and music.
Although it may be difficult to feel significant attachment to automatically generated video content, the first original content can mean a lot to a non- creator. The first original content makes the non-creator a creator. The first step of content creation is the most difficult for inexperienced people. An automatic content generation system can provide a boost to such people.
Such an automatic content generation system can enhance people’s creativity.
For example, the impression, such as the discontent a user may feel toward automatically generated content, can be a source of creativity. People can refine automatically generated content, which is a creative process, and it is easier than creating content from scratch. Our system helps with the first step in music video creation.
Previous studies have examined automatic music video generation [26,39, 60, 68, 96]. The synchronization between music and video is the most im- portant factor in music video generation. Therefore, most previous research defines the audio-visual synchronization criteria and generates a music video by optimizing such criteria. However, these studies have not examined hu- man perception of audio-visual synchronization. Therefore, we performed a subjective evaluation to explore the audio-visual synchronization criteria that affect human perception. Our system generates music video clips using such criteria.
2.2 Synchronization of Music and Video
Suganoet al.[87] reported that according to a psychophysical experiment, when the tempo of music corresponds to an accent in a video, such as move- ment or flicker, people feel that the music video has been synchronized well.
However, tempo information is not sufficiently detailed to consider the tem-
RMS energy → Flicker RMS energy → Movement
time [s]
RMS energy
Figure 2.1: Audio-visual synchronization.
poral transition of music. To synchronize video with music in a manner that is more suited to human perception, we consider synchronization between the accents of the video and the temporal transition of the music. We have used the RMS energy of sound, which corresponds to loudness, in our synchro- nization method. By using RMS energy, it is possible to extract the temporal transition of music. The RMS energyEcan be calculated as follows:
E =
vu ut1
n
∑n
i=1
x2i. (2.1)
wherenis the number of samples andxi is theith sample value.
For the video accents, we used the acceleration of each object in a video frame and the temporal transition of the luminous value of the whole frame, which correspond to movement and flicker in the video, respectively.
We performed a subjective evaluation to compare our synchronization method and Sugano’s method, which matches the accents of a video with the tempo of a song. The experiment was performed by showing simple music video clips created using each synchronization method to 22 participants.
After watching each video, the participants were asked to select the video (video A or video B) that was more suited to their perceptual feeling about audio-visual synchronization. Figure 2.1 shows the music video shown to the participants. The clips were created by adding video accents based on the
2.2. SYNCHRONIZATION OF MUSIC AND VIDEO Table 2.1: Evaluation items.
Evaluation items Score
Video A is suited to the music 5 Video A is rather suited to the music 4 Both videos are equally suited to the music 3 Video B is rather suited to the music 2 Video B is suited to the music 1
RMS or the tempo. The accents were added by adding flicker or motion to a simple white rectangle. Table 2.1 shows the evaluation items. Here, the score is 1 to 5, and higher scores indicate that the participant felt that our method was more suited to their perceptual impression. The order in which the video clips were displayed was random.
Table 2.2: Experimental results (score).
songs Type of accent in a video Average movement flicker movement
+flicker
Irregular beat song 1 4.82 4.82 4.91 4.85
Irregular beat song 2 4.36 4.64 4.50 4.50
Regular beat song 1 1.77 1.86 1.73 1.79
Regular beat song 2 2.82 2.36 3.41 2.86
Regular beat song 3 3.23 2.86 3.82 3.30
Regular beat song 4 2.64 4.18 2.65 3.16
Irregular beat drum sound 4.41 4.55 4.41 4.56
Regular beat drum sound 3.82 2.95 3.23 3.33
Average 3.48 3.53 3.58 3.53
The input songs included six songs and two drum beats, and the types of accents used were movement, flicker, and simultaneous movement and flicker. The participants watched 16 video clips per accent (48 clips in total).
Table 2.2 shows the experimental results. A score of 3 indicates that our syn- chronization method is as good as Sugano’s method. The average score was greater than 3; thus, we can say that people tended to prefer synchronization when the accents of a video correspond to the tempo and the RMS energy.
Note that our results were particularly effective when the beat was irregular.
Input music
Extract RMS in each bar
Tempo detection Music Video
Content
Extract video accents
Calculate Synch. Rate Tempo
detection emp
Music video generation phase Database construction phase
Generated music video
music
Video
Music video content
Figure 2.2: System flow.
2.3 Music Video Generation
We designed an automatic mashup music video generation system based on the results of the subjective evaluation. The system is composed of a database construction phase and a music video generation phase. Figure 2.2 shows the system flow. In the system, the users only need to select a song and choose music video clips that they want to use to create a new music video.
This section describes our automatic music video generation method.
2.3.1 Database Construction Phase
An object’s accents in an existing music video clip are extracted in the database construction phase. The accents are the movements of objects and changes in luminosity based on the subjective evaluation result. For move- ment information, we use the differential of optical flow in each moving area of the video frame, which corresponds to the acceleration of each moving object in the music video clip. The block size for extraction of the optical flow is 5 ×5 pixels, and the shift length is two pixels. We calculate the area of a moving object and use it to divide the value of the optical flow. This corresponds to normalization of the size of the moving object. This operation is applied to ignore the size of a moving object and allows us to focus on how an object moves. The change in luminosity is calculated using the average
2.3. MUSIC VIDEO GENERATION
Music Video Content
Input music
Extract accents in video (Acceleration, Luminous)
Extract RMS energy In each bar of the music
1 bar 1 bar 1 bar
Music video fragment with best synchronization rate
Calculate Synchronization rate between music and video
Database construction phase
Music video generation phase
Figure 2.3: Conceptual image of the system.
luminous value of each frame. Thus, the accents in the video are extracted.
We also detect the tempo of the music in the original music video. We de- tect tempo by measuring the distance between the peaks of a down-sampled audio waveform. By detecting tempo, the system can consider synchroniza- tion using tempo and detailed temporal transition information. Consideration of tempo corresponds to Sugano’s audio-visual synchronization method. We combine Sugano’s method with our method to realize better synchronization.
2.3.2 Music Video Generation
Figure 2.3 shows the flow and a conceptual diagram of the system. In the music video creation part, the user provides a song and the system calculates the RMS energy of the sound in each bar. The tempo of the song is estimated simultaneously using the method described above.
For the selection of a music video scene from the database, we define synchronization rateS in Eq. (2.2). The synchronization rateS is calculated as follows:
Sjk =wRjk + (1−w)
{
1−√(x−yjk)2
}
. (2.2)
RMS of an ・・・
input song
bar 1 bar 2 bar 3 bar N
Generated video
S
max・・・
Video 1, bar 1 Video 1, bar N ・・・Video N-1, bar N Video N, bar N Acceleration
of video
Luminance of video
Database (non-singing scenes)
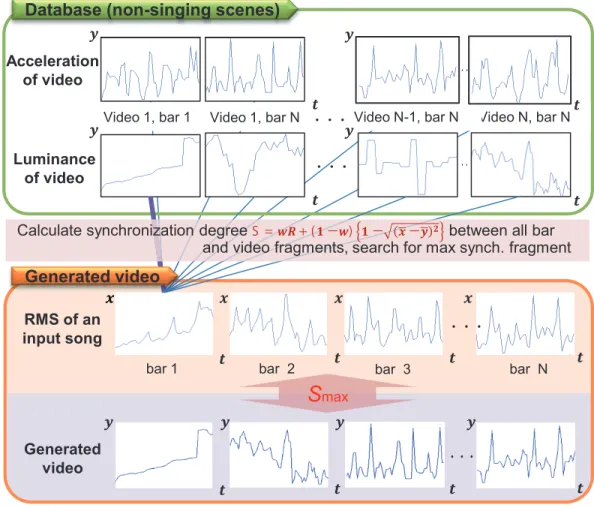
Calculate synchronization degree S = + ( − ) − − between all bar and video fragments, search for max synch. fragment
・・
・・
Generated video
・・・
Figure 2.4: Music video generation.
Here, x is the RMS energy of each bar in the song, y is the acceleration or luminosity in the music video stored in the database, R is a correlation coefficient between x and y, and w is a weight parameter. At this point, x and yare standardized using the average value and variance. Indexj is the database video ID, and k is the index of a musical bar. When S is large and close to 1, the transition and value between the RMS energy and either acceleration or luminosity in the video frames from the music video database are best synchronized. To select a music video fragment that best suits each bar of music, the system calculates synchronization rateSfor allxandypairs and searches for a video fragment that maximizesSin each bar of input music.
We experimentally setw= 0.5.
Figure 2.4 visualization of selecting a music video fragment with maxi- mum synchronization rate S. To avoid frequent scene changes in every bar, we added the time decaying coefficient valueα(k)to the synchronization rate of a continuous video sequence. If a video fragment with yjk is selected, the
2.4. EVALUATION synchronization value ofyjk+1will raise the standard byα(k). This increases the probability that a continuous video fragment will be chosen. α(k)atten- uates as the length of a continuous video fragment increases. This prevents a specific music video sequence from being selected too often. α(k)restricts the scene change until a match with better synchronization is obtained.
To fit the length of a single musical bar in the video to the length of a single musical bar of the input music, we expand and contract the database video clips based on the original tempo. This corresponds to Sugano’s synchro- nization method. When all video fragments are chosen relative to the input music, the system concatenates all fragments. Thus, a new music video clip with synchronized music and video can be generated.
2.4 Evaluation
We evaluated the music video clips output by our system in a subjec- tive evaluation. The experiment was performed in the same manner as the experiment discussed in Section 2.2. We compared our results with automat- ically generated music video clips obtained by considering only the tempo of the input music. The comparison method considered only the length of a single musical bar, which corresponds to the consideration of tempo. Note that video fragment selection was random. Our method considers tempo and selects video fragments based on temporal transition, as described in Section 2.3.
We used six Lady Gaga music video clips and six Michael Jackson music video clips for the database clips of the evaluation video. The input music was six randomly selected songs from the RWC music database [29]. These songs were selected from different genres. With three of the six songs, we generated new music video clips using the Lady Gaga database. For the remaining three songs, we generated clips using the Michael Jackson database.
In total, 12 music video clips were generated (six by our method and six by the comparison method). Seventeen participants watched the 12 video clips and responded (score 1 to 5) to the question which video is better in terms of audio-visual synchronization.
Table 2.3 shows the experimental results. If the score is greater than 3, our method is better in terms of audio-visual synchronization. However, on average, the result was less than 3.
We analyzed the scores of each participant song-wise. Although scoring was done on a 5-point scale, the song-wise variance value of the score was 1.5 on average for the six songs. This variance indicates that the participants’
scores varied significantly. This shows that this subjective evaluation was insufficient to demonstrate the effectiveness of our music video generation
Table 2.3: Result of subjective evaluation (score).
Input song Score In Your Arms 3.12 Waiting for Your Love 2.00 Guess Again 2.82 Secret Dreams 3.00
Kitchen 3.65
Desperate Little Man 2.76
Average 2.89
method because actual music video clips include many factors such as the semantics of visual objects and each participant focused on different factors.
In future, we plan to design and implement a better evaluation experiment that can ignore such factors.
2.5 Conclusion
We have proposed a system to generate a new music video from input music and existing music video clips. The music video clips are generated based on the results of a subjective evaluation in which luminous change and the movement of a video object were synchronized with sound. In many music video clips, such as dance video clips, synchronization between music and movement is important. Dance video in which a dancer’s motion corresponds to sound accents can be generated by our system. We have clarified the criteria for audio-visual synchronization in music video generation through a subjective evaluation. However, we could not demonstrate the effectiveness of our generated video clips.
Further evaluation of our generated music video clips is future work. After the evaluation, we plan to develop a user interface to support the creation of music video clips. The goal of this research is to support people in creating content for the first time. We will also explore the possibility of an automatic content generation approach to support content creation.
Chapter 3
Music Video Generation via Mashup of Singing Video Clips
To further explore possibilities in music content generation, we use vo- cal signals (i.e., singing voices) as a basis to generate music video clips. In this chapter, we describe a method to automatically synthesize music video mashups by leveraging vocal signals of a song. Given a database of music video clips and an audio recording, our approach can match the vocal content with appropriate video segments. Thereby allowing us to generate a music video with semantically synchronized visual and audio.
3.1 Background
Many people consume music by not only listening to audio recordings, but also watching video clips via video streaming services (e.g., YouTube1).
Thus, the importance of music video clips has been increasing. Although a lot of music video clips have been created for promotional purposes, not all existing songs have their own video clips. If a video clip could be added to an arbitrary song, people could enjoy their favorite songs much more. Note that one of the most important parts of popular music is the vocal part. Thus, to enrich music listening experience, the automatic generation of “singing”
video clips for arbitrary songs is a big challenge worth tackling.
Since there are a large number of music video clips available on the Web, these clips can be considered as an audio-visual dictionary covering almost
1http://www.youtube.com/
3.1. BACKGROUND
Polyphonic audio with singing voice
Music video clips of a specific singer
Singing voice separation
Non-singing scenes Singing scenes
New music video clip Vocal
section
Inst.
section +VAD
/a/
Figure 3.1: Conceptual image of the system.
all sound events. Given an audio clip, we could figure out what happens in a visual manner by searching for a video clip including similar sounds. The key idea of this study is that we could make a music video clip for an arbitrary song by searching for video clips including singing voices that are acoustically similar to that in the target song.
To achieve automatic video generation, it is important to search for similar singing voices in a database of existing music video clips. If a similar singing voice can be found in an existing clip within the database, the singing actions of the singer in the clip can be expected to match the input singing voice.
In this chapter, we try to find multiple short video fragments that match the input singing voice and concatenate these fragments together to make a new singing video clip. As typical music video clips include a number of scene changes, the system output is allowed to contain frequent scene changes in output clips, as long as the singer remains unchanged.
Another solution to automatic singing video generation is to construct an audio-visual association model for lip sync. This approach requires clean video clips (e.g., simple background, stabled camera and target) recorded in an ideal environment for the precise analysis of audio-visual association. How- ever, real video clips are noisy and are difficult to construct a reliable model.
We aim to deal with real video clips rather than video clips recorded in an ideal environment. It is extremely difficult to precisely detect objects in real video clips. Therefore, constructing a model from such clips is an unreasonable approach. We achieve automatic “singing voice to singing video" generation by focusing on singing voices and acoustic similarity between these voices.
Figure 3.1 shows a conceptual image of our system. Given an input song
sung by an arbitrary singer and existing music video clips in which the singer appears, our system automatically generates both singing and non-singing scenes by mashing up2 existing singing and non-singing scenes. This study has two main contributions: audio-visual singing scene detection for music video clips, and singing video generation based on singing voice similarity and dynamic programming (DP).
3.2 Related Work
The research topic of automatic music video generation has recently be- come popular, in fact a competition was held at the ACM International Con- ference on Multimedia 2012. Several methods have been proposed for the au- tomatic generation of music video clips by focusing onshallow[26, 39, 60, 68].
Foote et al.[26] proposed an audio-visual synchronization method based on audio novelty and video unsuitability obtained from camera motion and ex- posure. Huaet al.[39] proposed a system of automatic music video genera- tion based on audio-visual structures obtained by temporal pattern analysis.
Liao et al. [60] proposed a method to generate music video by extracting temporal features from the input clips and a piece of music, and casts the synthesis problem as an optimization. Although these methods consider audio-visual suitability [26], temporal patterns [39], or synchronization [60], higher-level information (e.g., the semantics of video clips) was not taken into account. Nakano et al.[68] proposed a system calledDanceReProducerwhich automatically generates dance video clips using existing dance video clips.
For audio-visual association, the system uses an audio-to-visual regression method trained using a database of music video clips. Since they use low- level audio and visual features for regression, higher-level information (e.g., dance choreography) was not taken into account. Our prior work which we described in Chapter 2 is also the shallow synchronization.
In this chapter, we tackle the problem of audio-visual synchronization be- tween a singing voice and a singer’s singing action (e.g., lip motion). This en- ables more semanticsynchronization than conventional methods. Yamamoto et al. [103] proposed a method that automatically synchronizes band sounds with video clips in which musical instruments are being played. Although this method can be considered as semantic synchronization, it does not men- tion synchronization of the vocal part, and requires manual input for sound source separation. In contrast, we focus on the vocal parts of a song and automate all processes.
In terms of synchronizing voice and lip motion, lip sync animation has been intensively studied in the field of computer graphics (CG). Various lip
2The term “mashup" refers to the mixture of multiple existing video clips.
3.3. SYSTEM IMPLEMENTATION sync methods have been applied to 3DCG characters, including image-based photo-realistic human talking heads [2, 11, 49, 97]. Basically, these talking heads are obtained by 3D face reconstruction or 3D face capture, methods that are not easily applicable to general video clips. Therefore, to make a video clip of a specific singer, users must prepare an ideal frontal face image or a sufficient amount of ideal video sequences of the singer. Our goal is to use the abundance of existing video clips so that users do not need to record new data to generate a video clip.
To mash up existing music video clips for synthesizing new singing video clips, we require a method to automatically detect singing scenes. Video event detection is a popular research topic in both the multimedia and pattern recog- nition communities. Many promising video analysis methods have been pre- sented at the International Workshop on Video Retrieval called TRECVid [83].
The test data for the semantic indexing task in TRECVid include video clips with the label “Singing." To distinguish singing events from other events, most teams used acoustic features such as the mel frequency cepstral coeffi- cient (MFCC) in addition to video features. These methods were designed for general-purpose event detection, not for the specific detection such as singing scene detection. To extract a target activity (e.g., singing) from music video clips, we propose an automatic singing scene detection method that constructs a database of such scenes from existing music video clips.
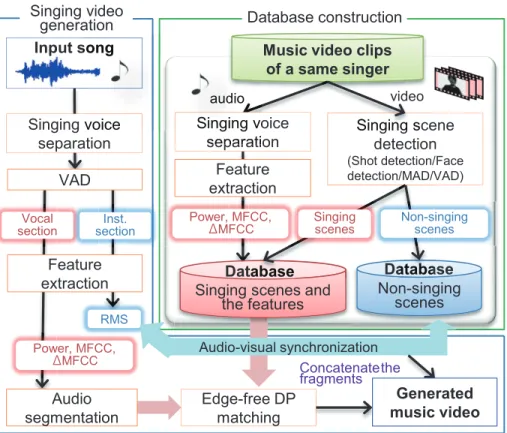
3.3 System Implementation
Our system consists of two processes: database construction and singing video generation. The system flow is shown in Figure 3.2. The only data required by the system are the input song and music video clips for a database.
The database video clips must include singing scenes of the singer of the input song. A larger number of database clips will result in better output video quality.
To construct the database, singing scene detection will be applied to music video clips. Specifically, we employ an algorithm that combines vocal activity detection (VAD) from polyphonic musical signal and mouth aperture detec- tion (MAD) based on facial recognition in a video clip. At the same time, singing voice separation is applied to the audio part of the database music video clips, and the singing voice feature is extracted. As a result, the singing scenes in the database clips and the singing voice and the features will be stored as a database for the system.
The singing video generation starts with singing voice separation and VAD. At this point, an input singing voice and the singer’s singing scenes with the singing voices are available. For the vocal section of an input song,
Music video clips of a same singer
Singing scene detection
(Shot detection/Face detection/MAD/VAD)
Singing scenes and the features
Database
Singing s
tabase
Power, MFCC, ΔMFCC
Singing voice separation
Feature extraction
Singing scenes
Non-singing scenes Database Databas
Non-singing scenes
audio video
Input song
Singing voice separation
VAD
Vocal
section Inst.
section
RMS
Feature extraction
Power, MFCC, ΔMFCC
Audio-visual synchronization
Edge-free DP matching Audio
segmentation
Concatenatethe fragments Singing vo
separati audidio au
Database construction Singing video
generation song
voice
Generated music video
Figure 3.2: Overview of the system.
the system searches for acoustically similar singing voices from a database of singing scenes. For example, if part of the input singing phrase (query) is
“oh," the system searches for a singing voice with a similar sound, such as the “o" from the word “over" or “old," on the basis of the similarity of singing voice features. Note that the system does not consider lyrics. It is difficult to find good matches between longer queries and the database. Therefore, the output singing video will be a mashup of small fragments of singing scenes.
The length of each fragment will be automatically determined on the basis of the automatic singing voice segmentation. For the instrumental section of an input song, the system automatically adds the best synchronized video fragments. These are calculated on the basis of the matching between the accents of both the input song and the database clips. In this case, reference video scenes will be narrowed down to the non-singing scenes in the database clips. By mixing separately generated singing scenes and non-singing scenes, system generates a new music video clip. Further details of each process will be described later.
3.4. SINGING SCENE DETECTION
3.4 Singing Scene Detection
We apply singing scene detection to music video clips for database con- struction. The singing scenes in a music video clip are one of the highlights of the clip. We define a singing scene as one in which a singer’s mouth is mov- ing, and the corresponding singing voice is audible. Therefore, not only audio analysis but also video analysis is necessary to detect such scenes. Our ap- proach is to combine the existing VAD method [27] with a new MAD method that is customized for handling faces in a video clip by using continuity of video frames.
3.4.1 Vocal Activity Detection (VAD)
VAD is applied to the polyphonic audio signal of a music video clip. We apply the HMM-based VAD method proposed by Fujihara et al. [27]. This method trains models for both vocal and non-vocal states by GMM. Using HMM to express the audio signal as a transition of both states, the method detects vocal sections on the basis of probability.
3.4.2 Mouth Aperture Detection (MAD)
To detect mouth activity, we require a face recognition method for video clips. For facial detection, we apply the method proposed by Irie et al.[46].
This method uses a global fitting of the active structure appearance model (ASAM) to find face areas and a local fitting model to detect each facial part and facial feature points. Therefore, the feature points of the mouth can be detected.
This face detection method is comparatively robust to facial expressions and transitions in the direction of the face. However, the detection of facial feature points in a music video clip is difficult, as there is considerable noise in the detected results. Figure 3.3 illustrates the appearance of noise in a real music video clip by comparing with the mouth aperture degree in a video recorded in an experimental environment. Hence, we cannot directly use the mouth aperture degree based on the mouth feature points to detect singing scenes in a real video clip. Instead of directly using the mouth aperture degree, we use the standard deviation of the distance between the upper and lower lip in each consecutive sequence of the same person’s face as a mouth feature.
To acquire suitably consecutive face sequences, the system detects shot boundaries of a video clip. A shot is a consecutive video sequence that has no scene changes or camera switches. According to the continuity of video frames, a person in one shot is always the same when there is no movement