DEIM Forum 2013 F10-6
VAST
木における圧縮による CPU ペナルティの実験と考察
山室
健
†鬼塚
真
†小西
史和
††
NTT
サービスイノベーション総合研究所, 180-0012 東京都武蔵野市緑町 3-9-11
E-mail:
†{
yamamuro.takeshi,onizuka.makoto,konishi.fumikazu
}
@lab.ntt.co.jp
あらまし CPU・メモリのハードウェア(HW)技術の進展を背景に,これらの HW の特性を考慮したアルゴリズムの
研究が注目されている.その中でも著者らは昇順の固定長データ列の中から,指定されたデータを高速に探索する手
法に着眼し,HW に最適化された探索手法である VAST 木を提案している.VAST 木では圧縮による探索木内部構造の
コンパクトな表現,探索処理の SIMD 命令によるデータ並列化,また CPU キャッシュミス・TLB ミスを減らすための
メモリレイアウト等を特徴としている.内部構造のコンパクトな表現のために,探索木内に存在する比較キーの上位・
下位 bit を削除する非可逆な圧縮手法を適用することで圧縮を行っている.しかし,この非可逆な圧縮の影響により低
い確率で誤った比較処理が行われ,結果的に得られた探索位置が,目的の位置からずれる可能性がある.そこで探索
処理後に,探索データと葉ノード上のデータを逐次的に比較して訂正(エラー訂正処理)することで,この問題に対
処している.葉ノード上のデータは昇順の固定長データで,それらは可逆な圧縮手法である整数列圧縮を適用した状
態で保持していることを想定している.そのため,VAST 木の探索後に発生するエラー訂正処理は,データ参照・比
較のために圧縮されたデータの復元処理が必要になるため整数列圧縮手法の選択は VAST 木の性能に大きく影響する.
そこで本論文では,VAST 木のエラー訂正処理で発生する復元処理のペナルティが整数列圧縮手法の選択によってどの
ように変化するかを分析し,どの手法が VAST 木の葉ノードの圧縮手法に適しているかを考察することが目的となる.
キーワード CPU 最適化,SIMD,ベクトル化,探索木,圧縮
VAST-Tree Compression Penalty on Modern Processors
- Experiments and Observations
Takeshi YAMAMURO
†, Makoto ONIZUKA
†, and Fumikazu KONISHI
††
NTT Service Innovation Laboratory Group, 3-9-11 Midori-machi, Musashino-shi Tokyo, 180-0012 Japan
E-mail:
†{
yamamuro.takeshi,onizuka.makoto,konishi.fumikazu
}
@lab.ntt.co.jp
1.
Introduction
マルチCPU,マルチコアCPUや,メモリサイズの増大など のハードウェア(HW)技術の進展を背景に,これらのHWの 特性を考慮したアルゴリズムの研究が盛んにおこなわれている. その中でも特に,昇順に並べられたN個の固定長データ(e.g., 固定長整数)di(d1 <d2 <...<dN)の中から任意のデータdk を探索する処理を本論文では扱う.この操作の利用法としては, 日々出力される大量のログデータの中から任意のタイムスタン プを持つデータを取り出すような処理や,ID(e.g.,転置索引に おけるドキュメントID)などの集合が与えられた場合に特定の IDのみを探索するような場合が考えられる.この操作を高速 に行う代表的な手法としては2分木や多分木の代表であるB+ 木などが挙げられる.しかし,これらの古くからある手法は近 年のHWの特性を考慮していないため,分岐ミス,CPUキャッ シュミスや,TLBミス等のペナルティが多く発生し,その結果, 探索性能を著しく悪化させることが指摘されている[1].そこ で著者らはHWの特性を考慮した探索手法であるVAST木[2] を提案している.VAST木では,CPUとメモリ間で発生するペ ナルティを最小化することを目的としているため,B+木等とは 異なりオンメモリ上のデータ構造を前提としている.探索木の 内部構造(分岐ノードと葉ノード)に圧縮を適用することで探 索対象のデータが大規模化した場合にでも,コンパクトなデー タ構造を保ちながら,探索時のデータ並列化(SIMD命令の適 用),CPUキャッシュミス・TLBミスを減らすためのメモリレ イアウト等により,ペナルティの最小化を実現している. VAST木では,コンパクトなデータ構造を実現するために分 岐ノードに対して非可逆な圧縮手法を適用している.より具体的には,分岐ノード内に存在する比較キーの上位・下位bit を削除することで圧縮を行っている.これは木構造内の探索に おいて,木の根ノードから葉ノード方向に探索が進むにつれ て,探索範囲が徐々に狭くなり,比較キーの値間が近づくこと によって本質的に比較を行うために必要なbitが少なくなる特 性を利用している.しかし,このbit削除の影響により低い確 率で誤った比較が発生し,結果的に得られた探索位置が,目的 の探索位置からずれる可能性がある.そのためVAST木では探 索後のエラー訂正処理として,目的の探索データと葉ノード上 のデータを逐次的に比較することで探索位置の訂正を行ってい る.具体的な例として,探索対象のN個の固定長データ列がdi (d1<d2<...<dk<...<dN)であるとして,探索データがdkで ある場合を考える.VAST木内の比較処理で誤った比較が発生 した結果,探索された葉ノード上の位置がdk−3であった場合 に,目的の探索位置までのエラー訂正処理としてdk−3,dk−2, dk−1,dkの4回分のデータ参照・比較(この目的の探索位置ま でのエラー量を∆wで表す,ここでは∆w=4となる)が必要に なる.この葉ノード上のデータは昇順に並び替えられた固定長 データで,整数列圧縮が適用されていることを前提としている ため,データの参照・比較処理に復元処理が必要になる. 整数列圧縮は,古くからデータベースや情報検索の分野で研 究がされており,上記のHW技術の進展を背景にHWに最適化 された手法が同様に数多く提案されている.整数列圧縮は,連 続する同じデータ型の配列(例えば32bit符号無し整数型)を 圧縮するもので,有名な手法にγ符号やδ符号[4]があり,よ り最近ではカラム志向データベースや転置索引内部の圧縮手法 として広く使われているPForDelta [3]などのHWに最適化さ れた手法が存在する.これらの手法は,データを参照する際に 余剰な復元処理が必要であるためCPUペナルティが発生する. そのため,上記で説明したVAST木の探索後に発生するエラー 訂正処理は選択する整数列圧縮手法によってVAST木の性能に 大きく影響する. 本論文では,VAST木のエラー訂正処理で発生する葉ノー ド上の逐次探索によるCPUペナルティを,選択する整数列圧 縮手法によってどのように変化するのかを分析・考察するこ とが目的となる.今回評価対象とする既存の整数列圧縮手法 として,単体整数に対して1つの符号を割り当てるγ 符号, δ符号,Variable-Byte符号[4]を,複数の整数をまとめて符号 化するVarint-G8IU [19],Simple9 [13]/16 [14]/8b [17],BP [15], PForDelta [3],VSEncoding [16]を取り扱う.また,これらの手 法は任意の位置の整数を復元することができない(注 1)ため,こ れを可能にするために整数列を固定長のブロックで分割して, それぞれを個別に圧縮することで任意位置の復元に対応する. 本論文の構成は,まず2.節において探索木に関する研究動向 を俯瞰し,3.節で本論文が前提としているVAST木の概要を説 明する.続く4.節で本論文において評価を行う整数列圧縮手法 と,VAST木の探索に必要な任意の位置からの復元に対応する (注 1):たとえば,n 個の圧縮されている整数列から先頭から k 個目の整数を復 元したい場合に,必ず先頭から逐次的に復元する必要があるという意味である. ための方法について述べ,5.節以降で実験・考察を行う.
2.
Related Works
データベース性能のボトルネックがディスクから,CPU(特 にメモリとCPU間)に変化してきているという指摘[5]から, それ以降データベース研究分野では様々なCPUの特性に最適化 された手法が提案されてきた.探索もその中の1つであり,特 に2000年前半にB+木の探索中に発生するCPUキャッシュミス を低減し,性能向上を図る手法が多く提案された[6] [7] [8] [9]. これらの研究の結論として得られた知見は,オンメモリ上の B+木における分岐ノードのサイズをキャッシュライン(注 2) と同 じにした場合,木の高さが高くなりTLB(注 3)ミスが大きくなる ため,TLBミスのペナルティを考慮してノードサイズをキャッ シュラインのサイズより多少大きい値に設定することで性能を 改善できるというものであった.また,この他にもCPUキャッ シュミスを低減する手法として,探索処理を分岐ノード上に一 時的に留め,後でまとめて処理する手法[11]や,次の探索ノー ドをプリフェッチする手法[10]などが提案されている.さらに 最近では,データ並列化のためのSIMD命令を利用した探索手法が提案[12]され,特にIntel Lab.が提案しているFAST [1]
は,キャッシュミス・TLBミスを考慮したメモリレイアウト, SIMD命令を用いた探索の並列化と分岐命令を排除などを適用 した手法を提案している.著者らが提案しているVAST木[2] はFASTを参考にして提案したものであり,FASTに対して探 索対象データが大きくなった場合の内部構造肥大化の圧縮によ る抑制,SIMD命令によるデータ並列数の向上,葉ノード上の データ圧縮などを適用した手法である.
3.
VAST-Tree
ここでは32bitの固定長データ列に対するVAST木の概略図 をFig.4に示し,この図の概要を説明する(注 4). VAST木では分 岐ノード(図4の上部三角形で示されている部分)内の比較 キーを上位・下位bitを削除する非可逆な手法で圧縮し,葉ノー ド(図4の下部長方形で示されている部分)上のデータ列に 対しては可逆な整数列圧縮手法を適用している.図中の各H, PH,CH,SHは各三角ブロック内に存在する2分木上での高 さを表し,それぞれの添え字はそのブロック内に存在する比較 キーのbit長を表している.例えば,SH32=3の場合には,SH ブロックが32bit長の比較キーを保持し,そのブロックは高さ 3(ブロック内の総比較キー数が7)の比較キーで構成されると いう意味である. SHブロックはCPU内に実装されているSIMDの比較命令に よって,CPUの1命令で実行される比較キーの集合を表している.現在広く使われているIntel互換x86のCPUには128bit長
(注 2):CPU のキャッシュとメモリ間のデータ転送最小単位で,一般的な CPU で は 64B 程度である.
(注 3):Translation Look-aside Buffer の略で,良く利用するページの論理アドレ スと物理アドレスの対応関係をキャッシュしている CPU 内の機構である. (注 4):64-bit のデータ列に対する VAST 木の場合は,最上端部に P64を追加し
のレジスタが数本実装されているため,32bit長の比較キーであ
れば最大4データ,16bit長であれば8データ,32bit長であれ
ば16データを同時に比較可能である.実際のVAST木の実装
では,SH32=2として同時に3つの比較キーを,SH16=3として
同時に7つの比較キーを,SH8=3として同時に3つの比較キー
をそれぞれ並列比較する.次期IntelのCPUであるHaswellで
は256bit長のレジスタ上での整数比較命令が実装予定であり,
それを利用すればSHブロック内の比較キーの並列実行数の向
上が期待できる.CHブロックは同じ上位・下位bitが削除さ
れた比較キーの集合を表している.CH32のブロックでは比較
キーの圧縮を行わず,CH16とCH8のそれぞれのブロックでは
上位・下位bitの合計16bitと24bitをそれぞれ削除して圧縮を
行っている.同じCH内に含まれる比較キーは同じ位置の上位・ 下位bitが削除され,その削除されたbit位置情報は各CHブ ロックのヘッダ情報として記録される.このヘッダ情報を利用 することで,探索キーに対して同じbit削除処理を適用するこ とで比較を行うことができる.このキーの上位・下位bitの削除 によって前節で説明した目的の探索位置からのずれるエラーが 発生する.PHブロックは隣接したページ揃える(アラインす る)ための比較キーの集合をそれぞれ表している.このアライ ン処理によって,ページ境界を跨ぐブロックを少なくし,CPU キャッシュとTLBのミスの最小化を図っている. 図 1 P32,P16,P8の 3 レイヤから構成される VAST 木の概略図
4.
Leaf Compression
前節で説明したように,P16とP8レイヤでは分岐ノード内の 比較キーを16bitと8bitに削除する影響で目的位置からのずれ ∆w(>= 0)が発生する.この∆wのエラー訂正処理の逐次的 な参照と比較のために葉ノード上の圧縮されたデータの復元処 理が必要になる.そのため,葉ノードに適用する整数列圧縮手 法によってエラー訂正処理のペナルティが変化し,VAST木の 性能に大きく影響することが推測される.この節では,本論文 で評価対象とする既存の整数列圧縮手法の概要を説明する.4. 1 γ, δ, and Variable-Byte codes
γ符号とδ符号は古くからある整数圧縮手法[4]であり,γ 符号は任意の符号無し整数dの2進数でのbit長より1つ少 ない’0’を出力した後に,整数dをそのまま出力する.例えば d=9(10012)とした場合,bit長が4であるため3つの’0’を出 力し,その後に’1001’を出力する.結果的に得られるγ符号 は’0001010’となる.γ符号では先頭の連続した’0’が元の整数 の桁数を表しているため,復元処理は先頭から’1’が出現する まで’0’を読み込み,読み込んだ’0’の数+1の後続bitを読み込 んで元の整数を復元する.δ符号はγ 符号を改良したもので あり,桁数を先頭の連続する’0’で表す代わりにγ符号で記録 し,その後続に元の整数の最上位bitを取り除いたbit列を格 納する方式である.再度d=9を例に挙げるとbit長は4である ため,これをγ符号で変換すると’00100’となるため,結果的 に’00100001’となる.γ符号とδ符号は与えられた整数をbit 単位で符号化を行うが,この符号化をbyte単位で行う手法が
Variable-Byte符号である.一般的なCPUはbit単位よりもbyte
単位の操作のほうが効率的に扱えるためVariable-Byte符号は
効率的に圧縮・復元が可能であるが,符号化がbyte単位で行わ
れるため圧縮率が悪くなる傾向がある.Variable-Byte符号は整
数を7bit単位に分割して,各7bitを1byteに格納する.最上位
1bitは後続のbyteが存在するかを表すフラグで,後続のbyte
が存在する場合は最上位bitを’1’に設定する.例えばd=553
(10001010012)とした場合に,7bitずつに分割すると’0101001’
(下位bit)と’100’(上位bit)になり,これらをbyteに格納す
ると’10101001’と’00000100’となる.下位bitが格納されてい るbyteの最上位bitに’1’を設定しているが,これは先程の説 明通り後続のbyteが存在していることを表している. 4. 2 Varint-G8IU Variable-Byte符号は整数毎に符号化を行うが,複数の整数 をまとめて符号化するように拡張したものがVarint-G8IU [19]
である.Varint-G8IUはGoogleのGroup Variant [18]を改良し
たもので,2∼8個の整数をまとめてVariable-Byte符号で圧縮 を行う.1Bのディスクリプタと,それに続く固定の8B領域 で符号化され,8Bに入る最大の整数(2∼8個)個数が格納さ れる.先頭のディスクリプタには,Variable-Byte符号の上位 1bitと同じ意味を持ったbitが,後続の8B領域に格納されて いる整数分だけ集められて格納される.例えばd[4]={215(2B), 223(3B), 27(1B), 215(2B)}の整数列を圧縮する場合を考える.そ れぞれに対応したVariable-Byte符号の上位1bitだけを取り出 すと,’01’,’011’,’0’,’01’になる.結果的に,このbitを連 結した’01001101’を先頭のディスクリプタとして,後続に必要 byte数に切り詰めた整数列8Bを連結して符号化する. 復元処理は先頭のディスクリプタを取り出して,後続の8B 領域に格納されている先頭(’0’で埋められた)byteを切り詰 められた整数を32-bit長に戻すことで容易に実現できるが,
Varint-G8IUではSIMD命令であるIntelのSSE3(注 5)で実装され
ているpshufbを利用することで,先頭の’0’を復元する処理を
高速化している(図2,図中の整数値は16進数で表記).pshufb
は入力用のSIMDレジスタ(図中のIN)とmask値が書き込ま
れた出力用のSIMDレジスタ(図中のOUT)を受け取り,mask
値に従い入力レジスタから出力レジスタにbyte単位で複製を
(注 5):shuffle と呼ばれる SIMD 命令では一般的な処理で,ARM の SIMD 命令 である NEON においても同等の処理を実現可能である.
行う命令である.pshufbを利用することで図のように32-bit長 の拡張処理がSIMDレジスタ上で容易に実現でき,8B領域を SIMDレジスタに読み込みと,1∼2回のSIMDレジスタの書き 出しで処理が完了できる. 図 2 pshufbを用いた Varint-G8IU の復元処理概要 4. 3 Simple9/16/8b
一般的なCPUで効率的に扱える単位は32bit(もしくは64bit)
のword単位である.そのため,この32bitのwordを効率的
に扱うように設計されたものがSimple9 [13]とSimple16 [14]
で,64bit向けに設計されたものがSimple8b [17]である.これ
らの手法はwordの先頭4bitと後続のbit(Simple9/16は28bit,
Simple8bは60bit)に分割し,先頭4bitのディスクリプタで後
続bitの分割方法を変更する方式である.この分割方法は事前
に定められており,例えばSimple9/16において連続する28個
の整数が全て1bitで符号化可能であれば,後続28bitを28分
割して符号化し,連続する7つの整数が4bitで符号化可能であ
れば後続28bitを4bitずつに分割して利用する.Simple9では
分割方法が9通りで,Simple16/8bは16通りである. 4. 4 BP: block packing BP [15]は連続する128個の整数列をまとめて符号化する方 式で,128個の整数列を32個の整数ブロック4つに分割して, 各整数ブロックの最大bit長で符号化する方式である.各整数 ブロックを符号化したbit長を8bitで記録することで,4つ集め て32bitのディスクリプタとして格納し,後続に符号化した整 数ブロックを連結する.各整数ブロックの符号化と復元処理の ための疑似コードをAlgorithm 1とAlgorithm 2に示す.これら
の疑似コードから分かるように,bitのshift処理とmask処理の
組み合わせで容易かつ高速に実現することができる.疑似コー
ドのように一般的な命令だけで実装されたものがBP32,復元
処理をSIMD命令で高速化したものがSIMD-BP32である.
Algorithm 1連続する32個の整数を8bitで符号化する関数 1: PACK8 32(uint32 t src[32], uint32 t dst[8])
2: for i = 0→ 7 do
3: dst[i] = src[i * 4] & 0x0F;
4: dst[i]∥= (src[1 + i * 4] & 0x0F) << 8; 5: dst[i]∥= (src[2 + i * 4] & 0x0F) << 16; 6: dst[i]∥= (src[3 + i * 4] & 0x0F) << 24; 7: end for
Algorithm 2連続する32個の整数を8bitで復元する関数 1: UNPACK8 32(uint32 t src[8], uint32 t dst[32])
2: for i = 0→ 7 do
3: dst[i * 4] = src[i] & 0x0F;
4: dst[1 + i * 4] = (src[i] >> 8) & 0x0F; 5: dst[2 + i * 4] = (src[i] >> 16) & 0x0F; 6: dst[3 + i * 4] = (src[i] >> 24) & 0x0F; 7: end for
4. 5 PForDelta and the variants
PForDelta [3]はSimple9/16やBPと同じように複数の整数を まとめて符号化する手法である.PForDeltaでは連続するm個 の整数の大半(90%∼)が符号化可能なbit長bを決定し,b-bit で符号化可能なものは固定長で格納して,b-bitを超える整数は 最後の例外領域に元のbit長のまま格納する.例えば,以下の ような整数列(m=10)がある場合を考える. 1, 3, 2, 3, 1, 2, 203, 3, 0, 2 この場合は’203’以外の90%の整数は2bitで符号化可能であ るため,b=2となる.そのため’203’はそのままのbit長で例外 領域に格納され,それ以外の整数は2bitの固定長bitで以下の ように符号化されることになる. 12, 32, 22, 32, 12, 22, 32, 02, 22, 20332 各整数の添字は符号化されているbit長を,最後のアンダー ラインの整数が例外領域をそれぞれ表している.’203’の出現 位置が移動しているが,元の位置情報は別途保存しているため, 復元時に元の位置に並べ替えることができる.OPTPForDeltaは PForDeltaの例外領域の効率を改善したもので,OPTPForDelta では,例外として扱われた整数のb-bit以下の値は元の位置に 格納して,b-bitを超えているbit部のみを例外領域に格納す る.さらに例外領域の整数列に対してSimple16で符号化する ことで圧縮率の向上を測った設計になっている.OPTPForDelta に対して,b-bitの固定長で符号化された整数列を復元する処 理をSIMD-BP32と同じようにSIMD命令で高速化した手法が SIMD-FastPFor,例外領域の符号化手法にSimple8bに変更した ものがSimplePForである[15]. 4. 6 VSEncoding 前節で説明したPForDeltaではmとbの値がパラメータと なっており,これらの値は圧縮対象の整数列によって最適値が 異なるため最適なパラメータ設定が難しい課題がある.そこ で圧縮対象の整数列をk個のブロックに分割(B1, B1, ..., Bk) して,各ブロックはブロック内に存在する最大bit長を持つ整 数に合わせて固定長bitで符号化するものとする.そのような 前提のもとで,各ブロック長を動的計画法で決定する手法が VSEncoding [16]である.最適なブロック長を動的計画法で計 算するために圧縮時に2パス以上の読み込みが発生するものの, 圧縮率と復元速度の観点で良いトレードオフを実現しているこ とが特徴である. 4. 7 Block compression 今までに説明した整数列圧縮手法は研究背景で説明した通 り,任意の位置の部分整数列だけを復元することができない.
そこで本評価においては,整数列を固定k個の整数ブロックに 分割し,分割された個々の整数ブロックに対して上記で説明し た整数列圧縮手法を適用する.そして各整数ブロックの先頭位 置を別途記録しておくことで,先頭からg個目の整数を復元し たい場合に,g/k個目の整数ブロックのみを復元するだけで目 的の整数が復元できるようなる.例えば,ある整数列に対して 単体整数を平均的に4bitで表現可能な圧縮手法を前提に,kを 256で整数列をブロック化した場合を考える.この時,整数ブ ロック当たりに必要な平均的な領域は128B(各ブロックの先 頭位置を記録している領域を除く)となる.キャッシュライン サイズが64Bの一般的なCPUにおいて,エラー量∆wが平均 的に128である場合に,エラー訂正処理に読む込む必要のある キャッシュラインの平均的な数は1.5となる.近年のCPUの傾 向として,CPU内の演算性能の向上に対して,CPU-メモリ間 の転送帯域の向上は緩やかであるという指摘[1]から,処理が 参照するメモリ上のデータ量(footprint)は最小化することが 望ましい.逆にkを小さくした場合,先頭位置を記録している 領域のオーバヘッドにより圧縮率が悪化する.そのため探索処 理のfootprintと圧縮率の観点からkを256に設定して,本評価 を行っている.
5.
Experimental
本実験ではVAST木の葉ノードに適した整数列圧縮手法を分 析することが目的である.具体的には,この実験項では以下2 点の分析を行う. (1) 各整数列圧縮手法の圧縮/復元速度と圧縮率 (2) 部分復元量(∆w)を変化させた場合の性能 1つ目の項目は整数列圧縮の基本的な性能を測る目的であり, 2つ目はVAST木のエラー訂正処理(任意位置に存在する∆w 個の部分整数列復元)の性能を表す評価である. 評価に用いるデータセットは人工データと実データの両方を 扱う.人工データにはUniformDataとClusterData [17]を,実 データにはGov2とClueWeb09(注 6) を用いた.UniformData(一 様な整数列)とClusterData(偏りのある整数列)はgithub上に 公開されているコード(注 7) を参考に,[0,229)の範囲から225個 の昇順の整数列を生成[15]して使用した.実データのGov2はTREC Terabyte Trackで利用可能な評価用データの1つで,gov
のドメインに含まれるhtml/textのドキュメントを収集したもの である.それらをURLで辞書順に並び替え,得られた昇順の ドキュメントIDの整数列を本評価に用いた.またClueWeb09 は,カーネギーメロン大学が収集して公開(注 8)している Web上 のドキュメント集合であり,Gov2と同じように生成した昇順 のドキュメントIDの整数列(URLによる並び替えの前処理は 適用しない)を本評価に用いた.これら人工データと実デー タは昇順の整数列であるため,整数列圧縮の慣例に従って前 後の差分値δi(=xi-xi−1-1)に対して圧縮手法を適用する.その (注 6):http://boytsov.info/datasets/clueweb09gap/ (注 7):https://github.com/lemire/FastPFor (注 8):http://lemurproject.org/clueweb09.php/ ため実際には,元の整数を復元するためにprefix-sumの処理 (xi=δi+xi−1)が復元処理後に必要になるが,これは全ての整 数列圧縮手法において共通の処理であるため今回の実験におい ては除外している.
性能評価に用いたマシンはCPUがコア数6のIntel Xeon 5670
で,総メモリサイズが16GiBである.Xeon 5670のL1/L2/LL
(Last-Level)キャッシュは そ れ ぞ れ ,32KiB/256KiB/12MiB の
容量を備えている.Xeon 5670のマイクロアーキテクチャは
Westmere-EPで,加減算やビット演算などの一般的な整数に対
するSIMD命令を実装しているSSE2,pshufbを実装している
SSE3が命令体系に含まれている.前節で説明した整数列圧縮
手法は全てC++で実装され,それらのコードはGNU Compiler
Collection v4.7.1の-O2 -march=noconaでコンパイル(注 9)して評 価に用いた.
5. 1 Comparison Results
人工データUniformDataとClusterDataを用いた圧縮(
cod-ing)/復元速度(decoding)と圧縮率(bits/int)の結果を表1と
表2に,実データGov2とClueWeb09を用いた結果を表3と
表4に示す.圧縮と復元速度は秒間あたり圧縮/復元できた整数
数を1,000,000で割った値mis(million integers per second)で,
圧縮率は整数毎に必要な平均bit数を表している.まず人工デー タの結果に関しては,[0,229)の整数範囲から225個の昇順の整 数列を生成して用いているため,平均的には24(229−25)bits/int となる.UniformDataとClusteredDataを比べると,値の分布 が偏っているClusteredDataのほうがδiは部分的に小さくな ることから圧縮性能が良い結果になっている.個々の結果を 見てみると,符号化をbyte単位で行うVariable-Byte符号と Varint-G8IUは,その他の手法と比べて圧縮性能が劣る結果に なっている.圧縮率の観点では,γ符号やδ符号などの整数 毎に符号化を行う手法のほうが複数の整数をまとめて扱う手 法に比べて(値にばらつきがある場合にオーバヘッドが高く なる特徴のため)有利な傾向にあるが,それでも一部の結果 (UniformDataのおけるSimple16/Simple8b/BP32,ClusteredData
におけるBP32/SimplePFor/VSEncoding)においてはγ符号やδ 符号の圧縮率より高い結果となっている.圧縮速度に関しては, OPTPForDeltaとVSEncodingは圧縮率を最適化するために2パ ス以上の処理を圧縮処理中に行うため,圧縮速度が非常に劣化 している.復元速度に関しては,全体的に整数毎に符号化を行 う手法に比べ,まとめて符号化を行う手法が有利な傾向にあり, 特にVarint-G8IUはUniformDataとClusteredDataの両方におい て最も復元性能が高い結果になった.これらの結果をもとに実 データGov2とClueWeb09の表3と表4を見ると,次のこと が分かる.1.圧縮率に関しては,byte単位に符号化を行う手法 は同様に性能が悪く,一方で(一部を除き)まとめて符号化を 行う手法のオーバヘッドが人工データと比べて小さくなってい る.2.圧縮速度は人工データと概ね同じ傾向を示しているため, データの分布の影響が小さいものと考えられる.3.復元速度は, (注 9):また使用する整数列圧縮手法が SSE を利用している場合には,対応した SSEを有効化するオプションを追加している.
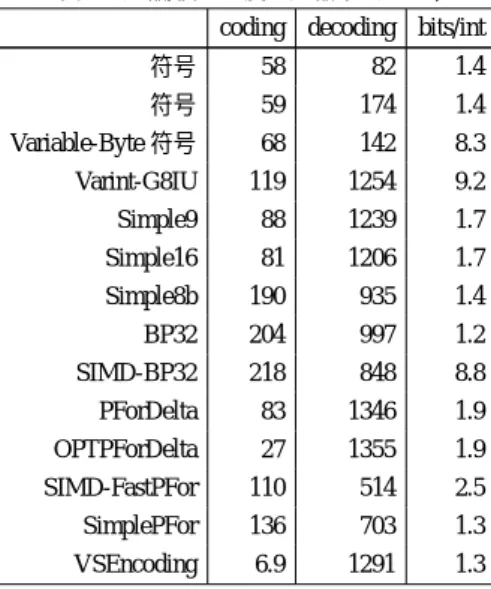
平均bits/intが小さいGov2においてはSimle9/16,PForDelta,
OPTPForDelta,VSEncodingの性能がVarint-G8IUと同等,も
しくはそれ以上の高い性能を出している,一方で平均bits/intが
Gov2に比べて高いClueWeb09では優劣の差は小さくなってい
るもののVarint-G8IUが最も性能が良くなっている.
表 1 圧縮/復元速度と圧縮率(UniformData)
coding decoding bits/int
γ符号 45 34 7.2 δ符号 46 127 7.2 Variable-Byte符号 60 139 8.4 Varint-G8IU 117 1267 9.3 Simple9 56 404 7.3 Simple16 30 381 6.4 Simple8b 101 521 6.9 BP32 197 1189 7.0 SIMD-BP32 221 826 8.8 PForDelta 46 743 7.8 OPTPForDelta 4 811 7.7 SIMD-FastPFor 94 372 8.7 SimplePFor 115 960 7.2 VSEncoding 7 527 7.8 表 2 圧縮/復元速度と圧縮率(ClusteredData)
coding decoding bits/int
γ符号 46 38 5.7 δ符号 47 113 5.7 Variable-Byte符号 57 130 8.7 Varint-G8IU 115 1241 9.3 Simple9 56 491 5.9 Simple16 34 456 5.4 Simple8b 109 522 5.8 BP32 57 130 8.7 SIMD-BP32 210 683 8.9 PForDelta 50 752 6.7 OPTPForDelta 5 927 5.1 SIMD-FastPFor 85 368 7.6 SimplePFor 103 695 6.0 VSEncoding 7 562 6.6 次にそれぞれのデータを用いて復元量(∆w)を変化させた 場合の部分復元性能測定結果を図3,図4,図5と,図6に示 す.これらの部分復元性能の性能結果は,各整数列圧縮の全体 復元性能を概ね反映した結果になっており,復元量∆wが小さ い場合に性能が高くなる傾向を持つ手法はないことが分かる.
6.
Discussion
この節では評価を行った整数列圧縮手法の圧縮率と復元速度 のトレードオフに関する分析を行う.圧縮速度に関しては,一 般的に復元処理に対して圧縮処理は1度しか行わないため,今 回は分析対象外としている.実データGov2とClueWeb09の 評価結果をもとにトレードオフ分析を行ったものを図7と図8 に示す.図では圧縮率・復元速度それぞれの最大値で0.0∼1.0 表 3 圧縮/復元速度と圧縮率(Gov2)coding decoding bits/int
γ符号 58 82 1.4 δ符号 59 174 1.4 Variable-Byte符号 68 142 8.3 Varint-G8IU 119 1254 9.2 Simple9 88 1239 1.7 Simple16 81 1206 1.7 Simple8b 190 935 1.4 BP32 204 997 1.2 SIMD-BP32 218 848 8.8 PForDelta 83 1346 1.9 OPTPForDelta 27 1355 1.9 SIMD-FastPFor 110 514 2.5 SimplePFor 136 703 1.3 VSEncoding 6.9 1291 1.3 表 4 圧縮/復元速度と圧縮率(ClueWeb09)
coding decoding bits/int
γ符号 55 79 1.7 δ符号 57 147 1.7 Variable-Byte符号 73 144 8.2 Varint-G8IU 119 1280 9.3 Simple9 79 930 2.2 Simple16 64 927 2.1 Simple8b 142 716 2.3 BP32 207 883 2.2 SIMD-BP32 225 843 8.8 PForDelta 74 1021 2.8 OPTPForDelta 19 1000 2.6 SIMD-FastPFor 87 365 4.5 SimplePFor 111 677 2.3 VSEncoding 7.1 846 2.2 図 3 部分復元性能の評価(UniformData) に正規化した結果をプロットしている.復元速度に関しては, ∆wの値で速度差に優劣が大きく発生しなかったため,中央値 である∆w=27の結果を用いている.圧縮率が高く,復元速度 が速いものが図中の右下にプロットされるため,トレードオフ という観点ではGov2とClueWeb09の両方の実験データにおい てVSEncodingが最も良い,という結果になった.一方で,圧 縮率が優先される環境ではγ符号とδ符号が,逆に復元速度が 優先される環境ではPForDeltaとOPTPForDeltaが良いという ことも併せて判断できる.
図 4 部分復元性能の評価(ClusteredData) 図 5 部分復元性能の評価(Gov2) 図 6 部分復元評価(ClueWeb09) 図 7 圧縮率/復元速度のトレードオフ評価(gov2)
7.
Conclusions
本論文では,VAST木の葉ノードに用いる整数列圧縮手法の 実験と考察を行った.VAST木の分岐ノードでは比較キーのbit 削除の影響により低い確率で誤った比較が行われる可能性があ る.その結果,目的の探索位置からのずれるエラーが発生する ため探索後に訂正処理が必要になる.そのため葉ノードに用 いる整数列圧縮手法によって,この訂正処理のペナルティが大 きく変化して,VAST木の探索性能に影響することが考えられ る.そこで本実験ではVAST木の葉ノードの圧縮手法に適し た圧縮手法を分析することが目的となる.結果的に,圧縮性 図 8 圧縮率/復元速度のトレードオフ評価(ClueWeb09) 能を優先した場合にはγ符号とδ符号が,性能面(単位時間 当たりの展開可能な整数数)を優先した場合にはPForDeltaと OPTPForDeltaが良く,また圧縮率と復元速度のトレードオフ の観点ではVSEncodingが葉ノードに適用する整数列圧縮手法 として適していることが分かった. 文 献[1] Changkyu Kim et al. “Designing Fast Architecture Sensitive Tree Search on Modern Multi-Core/Many-Core Processors”, ACM Trans-actions on Database Systems, 9(4), 2011.
[2] Takeshi Yamamuro et al. “VAST-Tree: a vector-advanced and com-pressed structure for massive data tree traversal”, Proc. of EDBT’12, pp. 396-407, 2012.
[3] Marcin Zukowski et al. “Super-Scalar RAM-CPU Cache Compres-sion”, Proc. of ICDE’06, pp. 59-71, 2006.
[4] Ian H. Witten et al. “Managing Gigabytes: Compressing and Index-ing Documents and Images”, Morgan Kaufmann, 1999
[5] P. A. Boncz et al. “Database Architecture Optimized for the New Bottleneck: Memory Access”, Proc. of VLDB’99, pp. 54-65, 1999. [6] J. Rao and K. A. Ross. “Cache Conscious Indexing for
Decision-Support in Main Memory”, Proc. of VLDB’99, pp. 78-89, 1999. [7] J. Rao and K. A. Ross. “Making B+-trees cache conscious in main
memory”, Proc. of SIGMOD’00, pp. 475-486, 2000.
[8] G. Graefe and P.-A. Larson. “B-Tree Indexes and CPU Caches”, Proc. of ICDE’01, pp. 349-361, 2001.
[9] R. A. Hankins and J. M. Patel. “Effect of node size on the perfor-mance of cache-conscious B+-trees.”, Proc. of SIGMETRICS’03, pp. 283-294, 2003.
[10] S. Chen, P. B. Gibbons, and T. C. Mowry. “Improving index perfor-mance through prefetching.”, SIGMOD Record, 30(2), pp. 235-246, 2001.
[11] J. Zhou and K. A. Ross. “Buffering accesses to memory-resident in-dex structures.”, Proc. of VLDB’03, pp. 405-416, 2003.
[12] B. Schlegel, R. Gemulla, and W. Lehner. “k-ary search on modern processors.”, Proc. of DaMoN’09, pp. 52-60, 2009.
[13] Vo Ngoc Anh and Alistair Moffat. “Inverted Index Compression Us-ing Word-Aligned Binary Codes”, Journal of Information Retrieval, Vol. 8, Issue. 1, pp. 151-166, 2005.
[14] Hao Yan et al. “Inverted index compression and query processing with optimized document ordering”, Proc. of WWW’09, pp. 401-410, 2009.
[15] D. Lemire and L. Boytsov. “Decoding billions of integers per second through vectorization”, Journal of CoRR, 2012.
[16] Fabrizio Silvestri and Rossano Venturini “VSEncoding: efficient coding and fast decoding of integer lists via dynamic programming”, Proc. of CIKM’10, pp. 1219-1228, 2010.
[17] Anh VN and Moffat A. “Index compression using 64-bit words. Soft-ware”, Practice and Experience, Vol. 40, Issue. 2, pp. 131-147, 2010. [18] Dean J. “Challenges in building large-scale information retrieval
sys-tems”, Proc. of WSDM’09, 2009.
[19] Stepanov AA. and et al. “SIMD-based decoding of posting lists”, Proc. of CIKM’11, 2011.